开发预告:关于改造Hermes-agent这件事,我想说的比上一篇多得多
先声明一点:这不是什么技术布道,更不是产品软文。这篇文章里写的东西,要么是我花了真金白银和睡眠时间换来的,要么是我接下来要去踩的坑。你要觉得哪里不对,直接怼。你要觉得哪里说到你心坎里了,欢迎一起搞。
引言
在真正动手做Hermes-agent之前,我花了大量时间来改进它的能力和本地生态。不是不想立刻开发,是深知一件事——工具链不稳的时候硬上,等于盖房子打的是松木桩。上一篇短文只是开了个头,这篇我想把思路彻底摊开。
下文四个部分,分别对应我过去三个月的真实经历,以及我对下一步开发工作流的思考。每个部分都有坑。
一、关于OpenClaw:摔过跟头,怕疼了
花了超过30亿token,烧了10万次API调用次数。这是我对OpenClaw投入的全部代价。
最后的结果?彻底放弃。
让你wow的瞬间
我必须承认,OpenClaw给我的第一印象确实是惊艳的。多Agent协作跑起来的时候,几个角色分工、对话、迭代,最后吐出一个像模像样的方案——那一刻你会产生一个危险的错觉:"这不就是我要的东西吗?"
我当时的想法是:框架底子不错,我只需要把prompt调精准一点,把边界case处理完善一点,就能投产。
这个想法让我一步步走进了泥潭。
30亿token的沉没成本
5亿token花在prompt工程上。我写了成吨的系统提示词,分场景、分角色、分输出格式。少样本、思维链、递归反思,能加的技巧全加了。结果呢?同样的输入,昨天的输出和今天的输出可能逻辑一致但表述矛盾——LLM的随机性在多Agent协作里被放大了。
15亿token花在源码改造上。状态机卡死、消息路由丢包、Agent之间对"任务完成"的定义不一致……这些问题prompt解决不了,只能改代码。我翻了OpenClaw的核心逻辑,重写了消息队列的超时机制,加了心跳检测,修了状态同步的竞态条件。改完之后确实能跑了,但下一个版本官方更新,我的改动全部冲突。
剩下的token在反复横跳里烧光了——等PR、改适配、测回归,循环往复。
凌晨四点的顿悟
有件事我记得很清楚。某天凌晨四点,又一个协作死锁的日志堆在我面前。我看着屏幕,突然意识到一个事实:
我改OpenClaw源码的速度,可能比官方团队还快。
这不是炫耀。这是恐怖。因为这意味着,如果我继续走下去,最终得到的不是"一个更好用的OpenClaw",而是"一个只有我自己能维护的OpenClaw分支"。小团队开源框架的宿命就在于此:他们给你看了一个可能性,但把"从可能性到产品"的沟壑留给了你。
30亿token买来的教训,可以总结成一句话——
开源智能体框架让你wow的那一下是真的。但要投产?这段路差不多等于你自己改源代码,而且你未必比他们慢。
摔过跟头之后的PTSD
放弃OpenClaw之后,我没有妥协,立刻转向hermes-agent。焦虑、失眠、迷茫,不是修辞,是真实发生过的事。你会反复怀疑自己:是不是我的用法不对?是不是我再调一调就好了?
后来我想通了。不是我不会用,是我把"可能性"和"产品"的距离想得太短了。摔过这一跤之后,我对Hermes-agent的态度变得极度谨慎——不把它当成品,把它当材料。
二、完善Hermes-agent的能力是投产的前提
Kanban深度测试结论
接入Hermes-agent之后,我做的第一个深度测试是它的Kanban多Agent协作板。官方文档写得挺好,demo也能跑。但我按生产环境的标准压了一遍之后,发现几个问题——
状态机在高并发调度下有竞争条件。Agent A正在处理任务的时候被中断,Agent B抢了锁,但A的本地状态没同步,整个板子的任务就进了一个不可恢复的中间态。
任务交接没有原子性。一个Agent认为自己完成了,向另一个Agent发信号,但信号到了,上下文没完整传递过去,接手的人对着半截信息开始干活。
这些不是致命bug,是工程化程度不够的表现。官方搭好了架子——SQLite持久化、状态机定义、任务队列都有了,但从"能跑demo"到"能扛住真实负载",中间缺了一层又一层兜底逻辑。
更讽刺的是,我自己搭的"Ralph Loop + 费曼验证自主循环体",在任务完整性和错误恢复上反而比官方Kanban更稳。
Ralph Loop + 费曼验证自主循环体
Ralph Loop这个名字没什么深意,反正就是借鉴了b站博主“费曼学徒冬瓜”的思路。核心是两个机制:
第一层,任务分解与硬校验。 每个复杂任务进来,先拆成原子步骤。每个步骤配一个校验函数——不是检查返回值对不对,是检查副作用是不是真的发生了。文件写没写进去?数据库状态变没变?网络请求到底发没发出去?
第二层,费曼验证。 任务执行完之后,执行Agent必须用"给完全不懂的人讲清楚"的方式复述自己做了什么。然后另一个Reviewer Agent专门负责找茬——你的复述和实际执行日志对不上,回去重跑。
这套东西很烧token。但它解决了一个核心问题:LLM的"自信幻觉"。尤其是Minimax,它经常对错误答案非常自信。费曼验证用"输出一致性"来约束"执行正确性"——你说你做对了,那你证明给我看。
用Kimi Code CLI做Orchestrator
既然Hermes-agent的自主性不够稳,我引入了一个外部监督层:Kimi Code CLI。
架构很简单:
用户意图
→ Kimi Code CLI(拆解任务、定策略、设约束)
→ Hermes-agent(执行脏活累活)
→ Kimi Code CLI(评估结果,决定继续/重试/终止)
→ 输出
Kimi Code CLI不写业务代码,它做元工作:拆任务、定策略、设约束、评结果。Hermes-agent负责读文件、写代码、跑测试、查日志。
这个分工不是拍脑袋想的,是基于LLM能力边界的判断:Orchestrator需要系统思维和长程规划能力,LLM相对擅长;Executor需要细节精确性和工具调用稳定性,LLM相对短腿。让外部系统补Executor的短板,比让Executor自己进化更现实。
冗余设计和不改源代码
这里我要强调一个原则,是我用30亿token买来的——
任何外部增强方案都做冗余措施,绝不嵌入源代码。
Ralph Loop、费曼验证、Kimi Code CLI的监督逻辑,全部是独立脚本和配置文件,通过标准接口(文件、数据库、API)与Hermes-agent交互。Hermes-agent本身不需要知道这些外部系统的存在。
这样做有三个好处:
- 官方版本更新了,我直接替换,外部系统不受影响。
- 某个补丁出问题,关掉对应的脚本就行,不用翻源码找耦合点。
- 哪天Hermes-agent我也弃了,这些外部系统可以平滑迁移到下一个框架。
各位师傅如果也在做智能体增强,千万不要图省事直接改源码。那是条不归路。你改得越多,维护负担越重,最后这软件就成了你一个人的私生子,官方动一下你疼一下。
三、Minimax就是个捣蛋鬼,所以我引入了QMD
半个月踩坑的完美知识库选型
说Minimax之前,先说说QMD。
QMD(Queryable Markdown Database),底层是BM25 + sqlite-vec + reranker,跑在我那台老破旧电脑上。半个月踩坑,最终选型落定。它的价值不是替代搜索引擎,而是给LLM的认知提供一个锚点。
为什么要做这个?只有一个原因:Minimax实在太操蛋了。
10秒一个答案,然后一本正经胡说八道
Minimax-M2.7-highspeed的速度是真的快。你问一个问题,10秒钟之内必定有回复。在需要长时间自治的任务里,低延迟意味着整体执行时间可以被压到合理范围。
但内容质量呢?
举个例子。我让Hermes-agent写一个腾讯云函数的定时触发器配置,Minimax给出的代码里用了五字段cron表达式,解释里说"这是腾讯云官方推荐配置"。
实际上腾讯云函数用的是六字段格式(带秒)。Minimax把AWS Lambda的cron格式和腾讯云的混在一起了,还自己脑补了一个"官方推荐"。
最可怕的是,这段代码看起来完全正确——格式规范、注释完整、解释逻辑通顺。如果不是我把它的答案放到kimi code cli进行评估,这个bug就会直接进生产环境。(你试试,你试试就知道了,试试就逝世)
提示词软限制根本没用
发现问题之后,我的第一反应是加强prompt约束。
我在system prompt里加了:"你必须基于腾讯云官方文档给出配置","如果你不确定某个细节,你必须回答'我不确定'而不是猜测"。
Minimax每次都答应得好好的:"好的,我会严格遵守。"
然后继续胡说八道。
我试过few-shot示例、试过贴官方文档原文让它严格按此执行、试过加各种硬核约束。全部无效。它记住了约束的表面措辞,但没记住约束的实质含义——它确实说了"基于官方文档",但文档内容是自己编的。
外部脚本限制的副作用
提示词管不住,我就上了外部硬限制(harness全局约束层)——在Hermes-agent执行write_file之前,先检查内容是否包含已知错误模式。
这个方案确实拦截了一部分错误。但副作用也很明显:
误杀率太高。Minimax的写法经常有"模糊正确"的边界情况——API存在但版本号写错。精确匹配会漏掉,模糊匹配会把正确的也拦下来。
更麻烦的是,外部脚本的校验逻辑增加了write_file的延迟,在长时间自治任务里累积下来效率下降明显。而且Minimax有时候会因为"被拦截次数太多"进入一种奇怪的摆烂模式——不再尝试写文件,而是把所有内容塞到一个巨大的返回消息里,让你自己手动复制粘贴。
额~。~。
把QMD索引知识库作为行动第一要求
被Minimax折磨了半个月之后,我想通了一件事:与其试图约束LLM"不要乱说",不如直接给它一个"不会说错"的参考源。
于是我们把小程序开发相关的知识库(也就是另一篇文章里写的那套115篇文档)全部灌进了QMD。然后在Hermes-agent的system prompt里加了一条铁律:
任何技术细节的回答,必须以QMD检索结果为第一信源。如果知识库中没有相关信息,你必须明确声明"此信息未经本地知识库验证",而不是自行推断。
这条规则把Minimax的创作冲动锁死了。它不能再凭感觉编一个cron格式出来——它必须先查知识库。查到了,就对;查不到,就老实承认不知道,然后用mcp搜索资料。
填充小程序开发知识库的真正目的
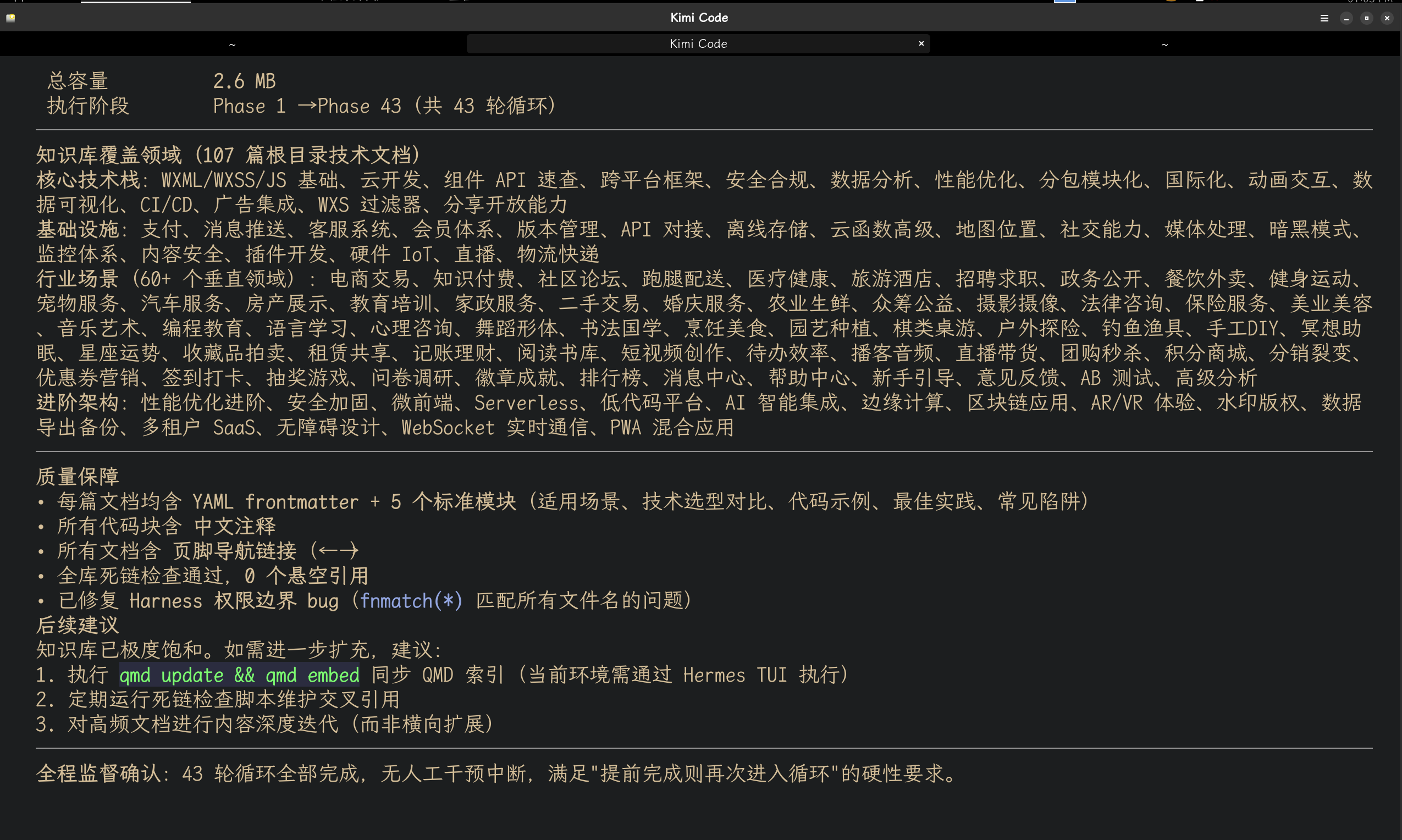
前面做的那个8小时知识库循环填充任务,表面上是在写文档,实际上有三个目标:
第一,建立硬约束。 给Minimax(以及其他可能不靠谱的模型)的回答加一个不可绕过的事实检查层。知识库里的内容经过人工审核,相当于给Agent的认知加了一道防火墙。
第二,改进Minimax的性格缺陷。 Minimax的问题不是智商不够,是太爱表现自己。它倾向于给出一个"看起来完整"的答案,而不是"确定正确"的答案。强制查知识库,就是把它从创作模式切换到检索-综合模式。
第三,积累可复用的技术资产。 这115篇文档不是一次性消耗品。它们会被持续索引、更新、扩展,成为Hermes-agent乃至未来其他Agent系统的共享知识底座。今天填充的是小程序知识,明天可以是任何需要精确事实的领域。
四、这是我这篇文章最重要的点——AI智能体足够强之后,正确的开发工作流应该是什么样的
先理解传统开发的问题在哪里
一个中等复杂度的软件项目——带后台、用户系统、支付模块的SaaS小程序——传统流程大概是:需求分析、技术选型、数据库设计、API定义、前端开发、后端开发、测试、部署、维护、扩展。
这个流程的瓶颈不在某一步太难,而在步骤之间的协调成本太高。前后端对齐要开会,API改一个字段要同步三个文档,测试发现的问题要跨三个人才能定位根因。
当AI智能体足够强之后,这个协调成本的构成会发生根本性变化。
从一线工程师到团队领袖
我的判断是,未来软件开发会分裂成两层。
下层是AI执行层。 Agent写代码、跑测试、查日志、修bug、部署上线。它们不需要理解业务,只需要精确执行指令。核心指标是准确率和吞吐量。
上层是人类决策层。 人做三件事:定义"做什么"和"不做什么",设计验证规则(什么样的输出算对、什么时候该叫停),仲裁争议(两个Agent结论冲突时给出最终裁决)。
角色变了。你不再写具体代码,而是当乐队指挥——知道每个声部什么时候进、用什么力度、怎么配合。核心能力从"我能写多优雅的代码"变成"我能设计多可靠的执行流程"。
步骤文档化:构思和执行必须解耦
接下来的核心工作是步骤文档化。
什么意思?传统开发里,"构思"和"执行"是交织的。你想到一个方案,马上写代码验证;代码跑不通,回头改方案;方案改了,代码重写……这个循环是创造性的,但也是低效的,因为构思阶段的试错和执行阶段的返工混在一起了。
我的玩法是强制分离:
构思阶段,人主导,AI辅助。 输出一份完整的步骤文档——包含选型清单、技术约束、接口定义、数据模型、测试策略、部署方案、回滚预案。这份文档在构思阶段不经过代码验证。它的正确性由人的经验、领域知识和逻辑推演来保证。AI在这个阶段的角色是智囊团——提供备选方案、对比优劣、模拟风险,但不直接执行。
执行阶段,AI主导,人监督。 Agent按步骤文档逐条执行,每完成一步触发对应的验证规则(比如长达3、6、9轮的辩论环节,取决你能承受的token和时间成本)。验证通过,进下一步;验证失败,触发重试或上报人仲裁。人在这个阶段盯的不是每一行代码,而是流程是否完整走完了。
当AI执行能力足够强之后,流程完整性比代码正确性更重要。因为代码正确性可以通过自动化验证来保证,但流程完整性——是不是漏了某个步骤——是更高阶的风险。
设置各类论证环节
步骤文档化之后,下一步是怎么保证步骤文档本身的正确性。
我的方案是引入多Agent论证环节。不是让一个Agent拍脑袋写方案,而是让多个Agent站在不同立场上辩论。
技术选型团队辩论环节。 Agent A站"性能优先"立场论证选方案X,Agent B站"维护成本优先"论证选方案Y,Agent C站"团队熟悉度优先"论证选方案Z。人听完三方辩论,做最终决策。
代码构建团队论证环节。 Agent D写实现代码,Agent E写测试代码专门找D的茬,Agent F做安全审计检查注入风险和越权风险。三方都通过,才能进合并环节。
代码安全团队论证环节。 专门审查数据流、权限边界、第三方依赖的供应链安全。
部署团队论证环节。 Agent G写部署脚本,Agent H写回滚脚本,Agent I模拟故障注入验证G和H在异常情况下是否有效。
这套机制的本质,是把Code Review、架构评审、安全审计这些人工环节自动化、并行化、常态化。人不需要参与每一次论证,只需要设定论证的规则和通过标准。Agent们自己跟自己打架,打完把结论汇总给人看。
专注于各个环节的工作流程是否完整,但不必专研于具体内容
这句话可能会让一些老工程师不舒服,但我还是要说:
当AI能写90%的代码之后,人的核心竞争力从"知道怎么写"变成了"知道怎么验"。
你不需要知道某个云服务的SDK具体有哪些参数——Agent查文档比人快。你需要知道的是,什么情况下这个调用会失败,失败后怎么处理。
你不需要亲手调优SQL查询——Agent可以生成几十种执行计划跑benchmark。你需要知道的是,业务场景里哪些查询模式是高风险的,该加什么索引、什么缓存策略。
你不需要自己写CI/CD脚本——Agent可以按模板生成。你需要知道的是,部署失败的定义是什么、回滚的触发条件是什么、监控应该看哪些指标。
人的价值从"实现细节"上移到了"元认知"——不是解决具体问题,而是定义问题的边界和验证标准。这就是"从一线工程师转变为团队领袖"的真正含义。你只需要提要求、设约束、设置各类环节,然后让Agent去执行。
下一步:实测
本文是预告,不是总结。下一步我要测的东西已经列好了:
第一,步骤文档的可执行性验证。选一个真实项目,先把完整步骤文档写出来,让Hermes-agent逐条执行。看有多少比例能无人干预跑通,Agent在哪些环节会卡住或跑偏。
第二,多Agent论证环节的有效性验证。技术选型辩论、代码构建论证、部署团队论证分别跑一遍。看不同立场的Agent能不能提出真正有建设性的反对意见,论证结论质量是否显著高于单Agent直接输出。
第三,长时间自治任务的稳定性边界。测复杂依赖关系任务,看执行到第几轮开始出现误差累积,哪些误差能被自动纠正或orchetrator纠正,哪些必须人工介入。
第四,Minimax+QMD组合的量化对比。A组不查QMD直接回答,B组强制先查QMD。统计两组的准确率、幻觉率、响应时间。
结果好坏我都会如实发出来。跑通了,是一个可复用的范式;没跑通,至少知道路在哪个环节断掉了——这比假装能行有价值得多。
欢迎讨论。特别是第四部分的工作流设计,如果你看出我遗漏了什么,直接说。这种层面的问题,越早被挑战,越早能被修正。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 1
1 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)