时序数据库选型指南(实战版):做一轮可落地评估
很多团队做时序数据库选型时,先看的是峰值写入和宣传参数,但项目上线 3-6 个月后,真正影响体验的往往是另外几件事:查询是否稳定、存储成本是否可控、模型是否容易维护、运维是否能标准化。本文不做“参数秀”,而是按一个真实项目的路径,给出一套更实战的选型思路,并用 IoTDB SQL 示例串起来。
下载链接:https://iotdb.apache.org/zh/Download/
企业版官网:https://timecho.com
一、先定选型标准:不要只看写入 QPS
如果你的场景是工业设备、能源计量、车联网遥测、机房监控,建议把评估拆成 4 组问题:
- 写入侧:高并发持续写入下,延迟是否稳定,有没有明显抖动。
- 查询侧:最近值、区间明细、窗口聚合、异常筛选是否都能直接表达。
- 成本侧:压缩率、磁盘增长曲线、历史数据保留策略是否清晰。
- 治理侧:Schema 管理、权限、生命周期、备份恢复是否可标准化。
这 4 组问题里,只有第一组是“纯性能问题”,后面三组都和长期运维成本直接相关。也就是说,选型不是一次压测,而是一次长期可运维性评估。
二、从大数据视角看时序库:关键是“数据链路完整度”
在企业架构里,时序数据库通常不是孤立系统,而是这条链路的一部分:
数据采集 -> 时序存储 -> 实时计算/离线分析 -> 可视化/告警 -> 数据归档
所以选型时建议重点看两件事:
- 能否和现有数据平台顺畅衔接(消息队列、批流计算、BI)。
- 能否在不频繁改模型的前提下持续扩点(设备数、测点数、保留时长增长)。
很多国外产品在监控类场景表现不错,但工业类项目通常结构更复杂,设备层级深、测点类型多、历史保留时间长。IoTDB 的树形路径模型和时序查询语义,在这类场景里更容易做到“模型和业务结构一致”,这会明显减少后期 schema 调整频率。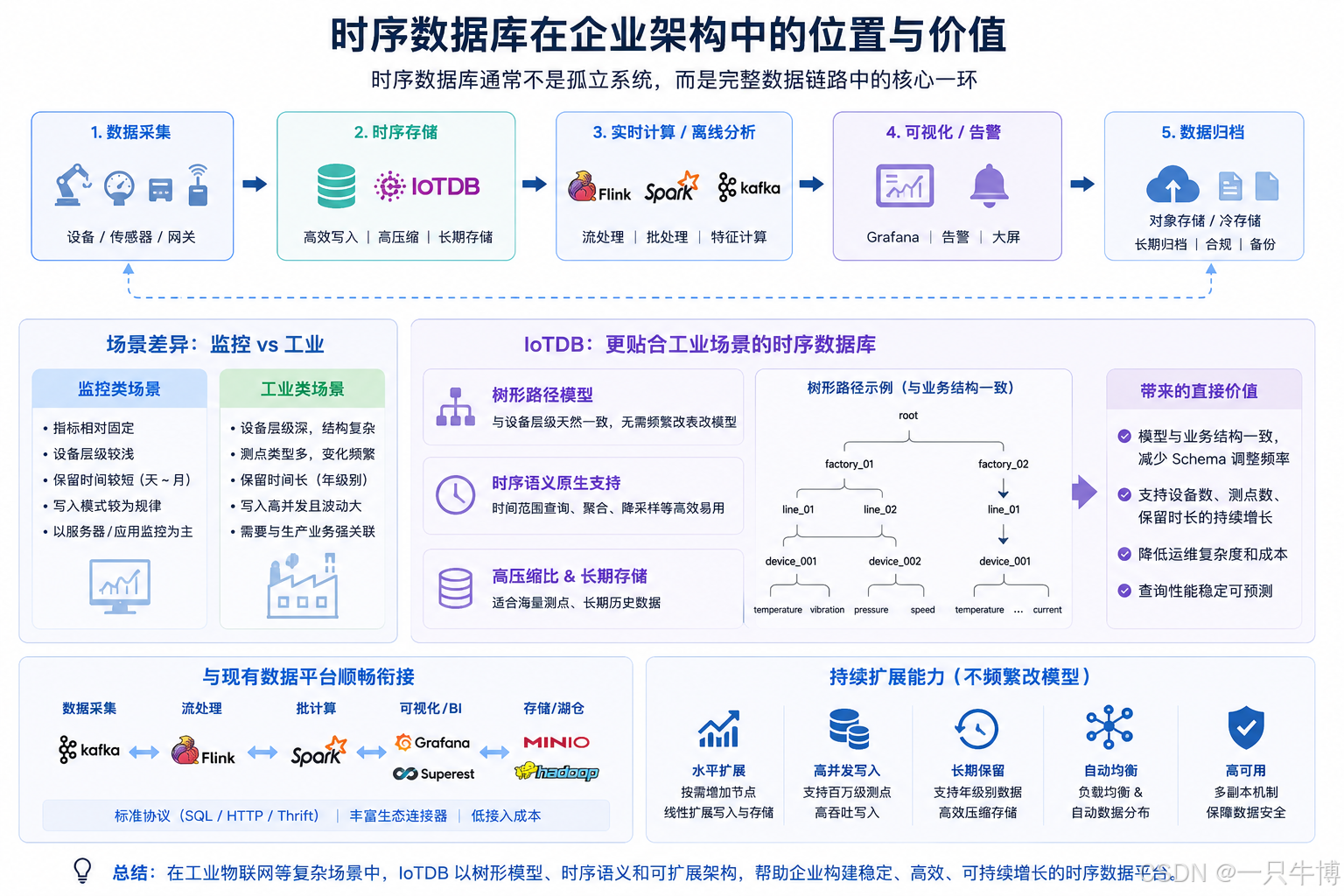
三、用一套 SQL 走完核心场景(可直接改成你的 PoC 脚本)
下面以“工厂设备监测”为例,路径约定为:root.factory.区域.产线.设备.测点。
1)建库与建模
-- 创建数据库(存储组)
CREATE DATABASE root.factory;
-- 非对齐时序:适合测点更新频率不一致的设备
CREATE TIMESERIES root.factory.bj.line1.d01.temperature WITH DATATYPE=FLOAT, ENCODING=RLE, COMPRESSOR=SNAPPY;
CREATE TIMESERIES root.factory.bj.line1.d01.pressure WITH DATATYPE=FLOAT, ENCODING=RLE, COMPRESSOR=SNAPPY;
CREATE TIMESERIES root.factory.bj.line1.d01.status WITH DATATYPE=BOOLEAN, ENCODING=PLAIN, COMPRESSOR=SNAPPY;
如果同一设备的多个测点通常同时间戳写入,可以改用对齐时序:
-- 对齐时序:同设备多测点同采样时刻,通常更利于批量写入和压缩
CREATE ALIGNED TIMESERIES root.factory.bj.line1.d02 (
temperature FLOAT ENCODING=RLE COMPRESSOR=SNAPPY,
pressure FLOAT ENCODING=RLE COMPRESSOR=SNAPPY,
vibration DOUBLE ENCODING=GORILLA COMPRESSOR=SNAPPY
);
2)写入样例
-- 单条写入
INSERT INTO root.factory.bj.line1.d01(timestamp, temperature, pressure, status)
VALUES (1717200000000, 26.5, 101.3, true);
-- 多条写入(示意)
INSERT INTO root.factory.bj.line1.d01(timestamp, temperature, pressure, status)
VALUES (1717200060000, 26.7, 101.2, true);
INSERT INTO root.factory.bj.line1.d01(timestamp, temperature, pressure, status)
VALUES (1717200120000, 27.1, 101.6, true);
-- 对齐设备写入
INSERT INTO root.factory.bj.line1.d02(timestamp, temperature, pressure, vibration)
VALUES (1717200000000, 26.1, 100.9, 0.017);
3)日常查询:最近值、区间明细、排序分页
-- 最近值查询(看实时状态常用)
SELECT LAST temperature, pressure, status FROM root.factory.bj.line1.d01;
-- 时间区间明细
SELECT temperature, pressure
FROM root.factory.bj.line1.d01
WHERE time >= 1717200000000 AND time < 1717203600000;
-- 倒序看最近 10 条
SELECT temperature, pressure, status
FROM root.factory.bj.line1.d01
ORDER BY time DESC
LIMIT 10;
4)统计聚合:班次报表和日汇总常用
-- 区间统计
SELECT COUNT(temperature), AVG(temperature), MAX_VALUE(temperature), MIN_VALUE(temperature)
FROM root.factory.bj.line1.d01
WHERE time >= 1717200000000 AND time < 1717286400000;
-- 按 1 小时窗口聚合(降采样的常见做法)
SELECT AVG(temperature), MAX_VALUE(temperature), MIN_VALUE(temperature)
FROM root.factory.bj.line1.d01
GROUP BY ([1717200000000, 1717286400000), 1h);
5)多设备查询:同产线横向对比
-- 通配查询同产线设备温度
SELECT temperature
FROM root.factory.bj.line1.*
WHERE time >= 1717200000000 AND time < 1717203600000;
-- 按设备对齐展示(便于报表侧消费)
SELECT temperature
FROM root.factory.bj.line1.*
WHERE time >= 1717200000000 AND time < 1717203600000
ALIGN BY DEVICE;
6)缺失值处理与工程化查询
-- 先按窗口聚合,再用前值填充,减少图表断点
SELECT AVG(temperature)
FROM root.factory.bj.line1.d01
WHERE time >= 1717200000000 AND time < 1717203600000
GROUP BY ([1717200000000, 1717203600000), 5m)
FILL(PREVIOUS, 10m);
7)元数据与治理 SQL
-- 查看时序定义
SHOW TIMESERIES root.factory.bj.line1.**;
-- 查看设备
SHOW DEVICES root.factory.bj.line1.*;
-- 设置 TTL:仅保留最近 180 天数据(毫秒)
SET TTL TO root.factory 15552000000;
-- 取消 TTL
UNSET TTL TO root.factory;
8)数据清理与纠错
-- 删除错误时间段数据(示例)
DELETE FROM root.factory.bj.line1.d01.temperature
WHERE time >= 1717200000000 AND time < 1717200600000;
-- 删除错误建模时序(谨慎)
DELETE TIMESERIES root.factory.bj.line1.d01.bad_metric;
上面这套 SQL 覆盖了 PoC 阶段 80% 以上的验证动作。建议直接落成脚本,在同一套真实数据上重复执行,观察写入稳定性、查询时延和磁盘增长。
四、怎么把“选型”变成“可复用的评估流程”
建议用两周做一次小型 PoC,流程如下:
- 第 1-2 天:梳理真实查询清单(至少 20 条 SQL),覆盖实时看板、日报、告警回放。
- 第 3-5 天:导入真实样本数据,按 1 倍和 3 倍流量分别压测。
- 第 6-8 天:执行治理动作(TTL、删除、重建部分时序),验证可维护性。
- 第 9-10 天:评估成本曲线(磁盘增长、压缩效果、查询抖动)。
- 第 11-14 天:做一次故障演练(节点重启、写入恢复、查询回归)。
这套流程的目标不是跑出“最好看”的数值,而是回答三个问题:
- 业务查询能否长期稳定地跑。
- 运维动作是否能标准化,不依赖个人经验。
- 未来设备规模扩大后,是否还在可控成本区间内。
五、IoTDB 在选型中的定位(克制结论)
如果你的场景是典型时序数据(设备监测、工业采集、运维指标),IoTDB 值得优先进入候选名单,原因主要是:
- 建模方式和设备层级天然贴近,前期 schema 设计更直接。
- SQL 语义覆盖常见时序分析任务,上手成本相对可控。
- 在开源方案里,兼顾了工程化能力与后续扩展空间。
但是否最终选 IoTDB,仍建议基于你的真实 SQL 清单和真实流量做结论,而不是只看公开 benchmark。把 PoC 做扎实,结论通常会更客观,也更容易和研发、运维、业务三方达成一致。
六、建议
- 先用开源版做 2 周 PoC,验证模型和查询。
- 再评估生产期 SLA、运维工具链和支持响应需求。
- 最后决定是否采用企业版支持方案。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 11
11 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)