上下文窗口的秘密:从 4K 到 1M 的技术演进
上下文窗口的秘密:从 4K 到 1M 的技术演进
《大模型知识与部署》系列 · No.05 / 35(入门认知篇收官)
适合人群:AI 工程师、后端开发
阅读时间:约 25 分钟
写在前面
我们已经走完了入门认知篇的前 4 篇:
- 第 1 篇 看清生态全景
- 第 2 篇 拆解 Transformer 架构
- 第 3 篇 算清参数账
- 第 4 篇 理解 Token 账
这一篇是入门认知篇的收官,我们要谈一个所有大模型厂商都在卷、所有工程师都被它折磨的东西——
上下文窗口(Context Window)。
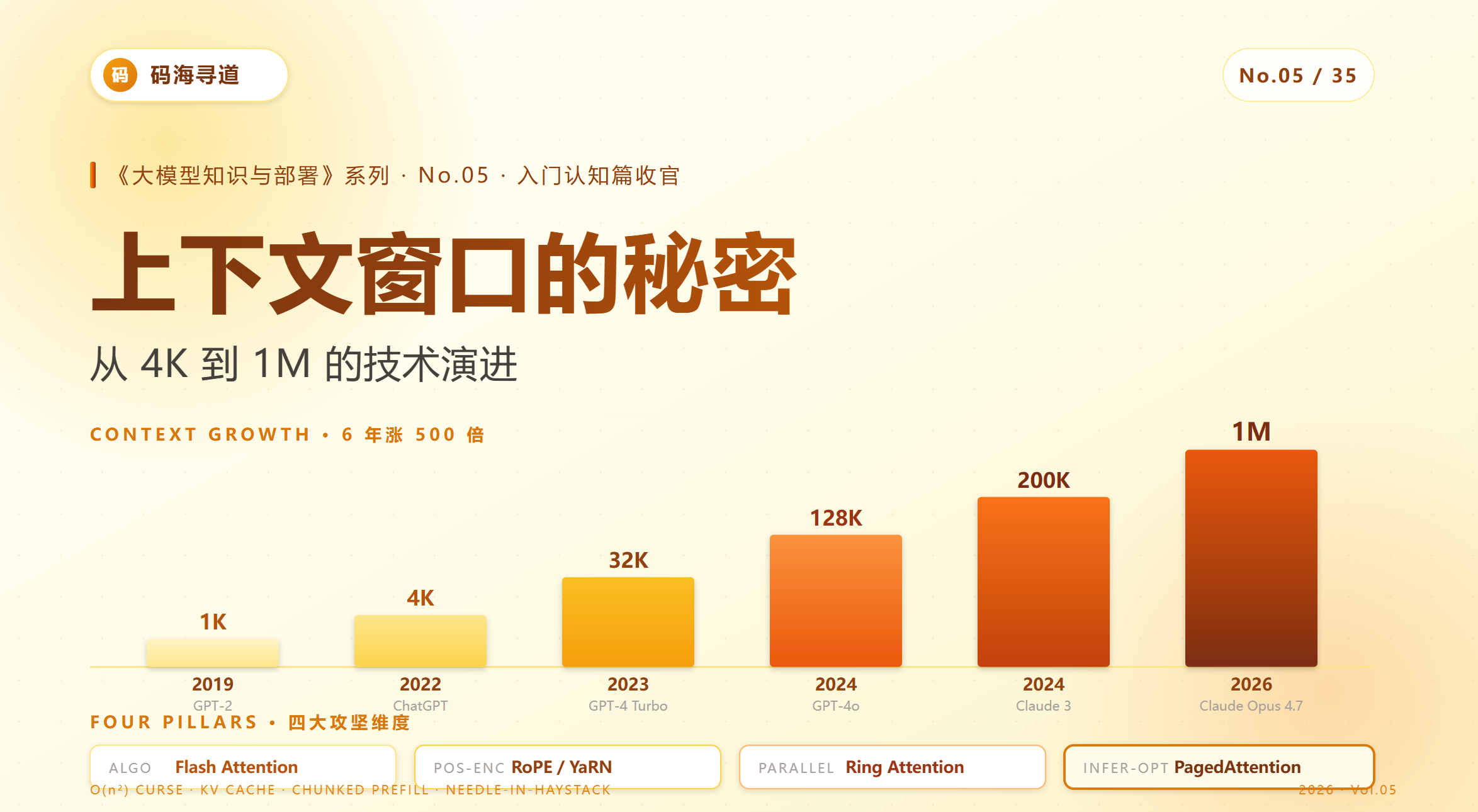
2020 年 GPT-3 上下文是 2K,到了 2026 年 Claude Opus 4.7 和 Gemini 2.5 Pro 都已经支持 1M——6 年涨了 500 倍。
这个数字看起来像是简单的"扩参数",但工程上每一个数量级的扩展都是一场硬仗。
如果你做过相关工作,下面这些经历应该不陌生:
- 模型号称支持 128K,实测放进去 80K 之后就开始"失忆"
- 同样 32K 上下文,对话越长延迟越糟糕——而且不是线性变糟
- 长上下文模式打开后,显存吃掉一半,并发掉到原来的 1/10
- 同样的"大海捞针"任务,开源模型崩溃,闭源模型稳定
- 老板说"我们也搞个 1M 上下文的应用",你想:用得起吗?
这一篇我们就来彻底搞清这套账。读完它你会知道:
- 上下文窗口扩展的物理瓶颈是什么?
- 业界用什么算法、什么并行、什么工程手段一路推到 1M 的?
- 自己部署长上下文服务时,最容易踩的几个坑在哪里?
- 什么时候该用 1M 上下文,什么时候应该用 RAG?
我们开始。
一、上下文窗口为什么是头等大事
1.1 一条 6 年涨 500 倍的曲线
简单回顾上下文长度的演进史:
| 年份 | 代表模型 | 上下文 | 工程意义 |
|---|---|---|---|
| 2019 | GPT-2 | 1K | 段落级 |
| 2020 | GPT-3 | 2K | 短文章 |
| 2022 | ChatGPT | 4K | 多轮对话 |
| 2023.3 | GPT-4 / Claude 1 | 8K / 100K | 文档级 |
| 2023.7 | Llama 2 | 4K | 开源仍落后 |
| 2024.3 | Claude 3 | 200K | 长文档 SOTA |
| 2024.5 | GPT-4o | 128K | 全面跟进 |
| 2024.12 | Gemini 1.5 Pro | 2M | 首破 1M |
| 2025 | Claude 4 / DeepSeek V3 | 200K / 128K | 主流标配 |
| 2026 | Claude Opus 4.7 / Qwen 3 | 1M / 1M | 1M 成主流 |
这条曲线背后是巨大的技术鸿沟——4K 到 32K 是工程优化,32K 到 128K 是位置编码革新,128K 到 1M 是分布式架构创新。
1.2 为什么所有人都在卷上下文
工程视角下,长上下文价值有三层:
第 1 层:直接消除"切分"的痛苦
短上下文时代,所有 LLM 应用都被一个动作折磨:chunking(切片)。
- 处理一份 50 页 PDF?切成 100 个 chunk,每个塞一点
- 分析 10 万行代码?切成 500 个文件块
- 总结一本书?分章节循环 prompt
切片的代价:信息丢失、上下文断裂、结果难拼接。
128K 上下文意味着 100 页 PDF 一次性丢进去;1M 上下文意味着整本《三体三部曲》一次进,整个代码仓库一次进。这是产品形态的根本性升级。
第 2 层:让 Agent 真正可用
第 1 篇我们提到 Agent 是 2026 年大模型的主战场。Agent 的本质特征是多步推理 + 工具调用 + 记忆——每一步都会往上下文里塞新信息:
- 系统提示 + 工具定义:~5K tokens
- 用户原始请求:~1K
- 第 1 步:检索结果 ~3K + 思考 ~1K
- 第 2 步:调用 API + 返回 ~5K + 思考 ~1K
- 第 N 步:…
一个跑了 20 步的 Agent,上下文很容易突破 100K。短上下文时代 Agent 跑几轮就崩溃,1M 上下文是 Agent 走向生产的前提。
第 3 层:把"知识库"变成"记忆"
短上下文 + 向量库 = RAG。
长上下文 + 全量灌入 = “直接记忆”。
很多场景下,长上下文比 RAG 更准——因为没有 chunk 切分、没有检索召回率问题。
1.3 工程师面对的真实账本
理想很丰满,但每多扩 10 倍上下文,工程师就要为这个数字埋单:
| 上下文 | 单请求 KV Cache (Llama-3-70B, FP16) | 单卡 H100 能并发请求数 |
|---|---|---|
| 4K | 1.3 GB | ~30 |
| 32K | 10.7 GB | ~5 |
| 128K | 43 GB | ~1 |
| 1M | 335 GB | 跨多卡 |
并发能力骤降是显而易见的,但还有更隐蔽的代价:
- 第 100 万个 token 处的"理解质量"远不如第 1000 个
- prompt 越长,首 token 延迟(TTFT)越大——1M 上下文的 TTFT 可达几十秒
- 跨多卡的长上下文调度难度指数上升
下面我们就从这些工程账本背后,拆解长上下文到底是怎么"卷"起来的。
二、O(n²) 的诅咒:物理上的硬墙
2.1 attention 的复杂度公式
回忆第 2 篇我们讲过的核心公式:
Attention(Q, K, V) = softmax(QK^T / √d_k) · V
注意 QK^T 这一步:
Q维度:[n, d](n 是序列长度,d 是隐藏维度)K^T维度:[d, n]- 结果:
[n, n]
这是一个 n × n 的矩阵。意味着:
- 计算复杂度:
O(n² · d) - 显存复杂度:
O(n²)(要存这个矩阵做 softmax)
直观影响——上下文每翻倍,attention 部分的算力和显存就涨 4 倍。
2.2 实际数字感受
我们用 Llama-3-70B 实测(FP16,单 layer attention 计算量):
| 序列长度 n | attention 矩阵显存 | 单 layer 计算量 (TFLOPS) |
|---|---|---|
| 4K | 32 MB | 0.5 |
| 32K | 2 GB | 32 |
| 128K | 32 GB | 512 |
| 1M | 2 TB | 32,000 |
注意 1M 那一行:单 layer 的 attention 矩阵就需要 2 TB 显存——光这一项就远超任何单卡甚至单机的极限。这就是为什么"原始 attention"根本撑不到 1M。
2.3 KV Cache 的指数膨胀
除了 attention 矩阵,KV Cache 也是大头。第 2 篇推导过的公式:
KV_cache = 2 × batch × seq_len × num_layers × num_kv_heads × head_dim × dtype_size
按 Llama-3-70B(80 layers, 8 KV heads with GQA, head_dim=128, FP16):
| 上下文 | 单请求 KV Cache | 占用估算 |
|---|---|---|
| 4K | 1.3 GB | 单卡毛毛雨 |
| 32K | 10.7 GB | 单卡可以容纳 |
| 128K | 43 GB | 占满半张 H100 |
| 1M | 335 GB | 超过 4 张 H100 |
这意味着什么?
在 1M 上下文下,光放一个请求的 KV Cache 就要 4 张 H100。你不可能用单卡跑 1M 上下文 + 并发。
2.4 三大瓶颈合一
汇总到一张图:
传统 attention 在长上下文下的"三座大山"
┌─────────────────────────────────┐
│ ① Attention 矩阵 O(n²) │ → 显存爆炸
├─────────────────────────────────┤
│ ② KV Cache O(n) │ → 单请求吃满显卡
├─────────────────────────────────┤
│ ③ Prefill 计算量 O(n²·d) │ → 首 token 延迟飙升
└─────────────────────────────────┘
工业界为了攻破这三座山,从四个维度同时发力,下面挨个看。
三、技术演进:四个维度的攻坚
3.1 算法维度:让 attention 本身变便宜
Flash Attention(2022):IO 优化的奇迹
关键洞察:传统 attention 慢,不是因为计算量,而是因为 IO 太多。
GPU 的 HBM 显存带宽是 3 TB/s,看似很快,但 attention 中间结果 n × n 矩阵的读写需要反复访问 HBM——成了真正的瓶颈。
Flash Attention 的做法:
- 把 Q、K、V 分块(block-wise)加载到 SRAM(片上高速缓存,比 HBM 快 100 倍)
- 在 SRAM 中融合计算 softmax 和加权求和
- 用一种巧妙的"在线 softmax"算法避免中间矩阵物化
效果:
| 指标 | 传统 Attention | Flash Attention |
|---|---|---|
| 显存 (n²) | 32 GB (128K) | 0.1 GB |
| 速度 | 1× | 2-4× |
| 数值精度 | 基线 | 完全一致 |
Flash Attention 现在是所有主流推理框架的默认实现——vLLM、SGLang、TGI 全都基于它。
👉 详见 系列第 13 篇:Flash Attention 原理与实践。
Sliding Window Attention:放弃全局视野
思路:让每个 token 只看附近 w 个 token,不再做全局 attention。复杂度从 O(n²) 降到 O(n·w)。
代表模型:Mistral 系列(w=4096)、Llama 4 部分层。
问题:长距离信息丢失。所以现代模型常用"局部 + 全局"混合,比如每 4 层用一次全局 attention。
Sparse Attention:选择性看
更进一步:让 attention 只在某些"重要位置"激活。代表:Longformer、BigBird。
现状:在 LLM 时代不算主流,更多用于特殊任务。
3.2 位置编码维度:让模型"外推"到训练长度之外
这一维度是过去 3 年长上下文最大的突破之一。
问题:训练 4K,推理 32K 会怎样
如果直接用训练长度之外的位置——模型行为崩溃。原因:
- 绝对位置编码:训练时没见过位置 5000,embedding 是随机的
- 相对位置编码:位置插值方式没学过
ALiBi(2021):用偏置代替位置
思路:不用位置编码,直接在 attention 分数上加一个"距离惩罚"——位置越远,惩罚越大。
优点:天然支持外推(距离越远惩罚就越大,新位置也能算)。
缺点:远距离信息衰减太快,不利于真正长上下文理解。现已被 RoPE 路线超越。
RoPE(2021):当下主流
思路:用旋转矩阵编码相对位置。每个位置 m,把 Q/K 的每对维度旋转角度 m·θ。
q'_m = q_m · R(m·θ)
k'_n = k_n · R(n·θ)
q'_m · k'_n = q_m · R((m-n)·θ) · k_n
↑
天然包含相对位置 m-n
优点:相对位置 + 计算高效。
缺点:直接外推到训练长度之外,效果会崩溃(高频维度旋转太快)。
NTK-aware / YaRN:RoPE 的外推神器
这是让短训练模型用上长上下文的关键。
核心思路:
- RoPE 的不同维度对应不同频率
- 长上下文外推时,对高频维度做"减缓"处理(外推),对低频维度做"拉伸"处理(插值)
- 通过混合策略,平衡新位置的稳定性和已有学习的保留
实际效果:Llama-3-8B 原训练 8K,用 YaRN 可以外推到 32K-128K,效果损失极小。
主流玩家:
- YaRN:开源主流,配合 fine-tuning 可推到 1M
- LongRoPE:微软方案,无需训练直接推到 2M
- NTK-aware Scaling:训练时启用,效果稳定
👉 详见 系列第 15 篇:长上下文优化 - YaRN/Ring Attention 详解。
3.3 并行维度:把上下文拆到多卡
当单卡装不下整个 KV Cache 时,必须把上下文切分到多张卡上。
Ring Attention(2023):上下文级的分布式 attention
思路:
- 把序列均匀切分到 N 张 GPU
- 每张 GPU 持有局部 Q、K、V
- K/V 在卡之间环形传递,每张卡轮流和其他卡的 K/V 做 attention
- 通信和计算 overlap
效果:理论上 N 张卡可以处理 N 倍长的上下文。Google 用 Ring Attention 训练了 Gemini 1.5 Pro 的 2M 上下文。
代价:通信开销随上下文长度线性增长,需要高速互联(NVLink / IB)。
Sequence Parallelism / Context Parallelism
Sequence Parallelism:训练时把激活值按序列维度切分到多卡(节省激活显存)。
Context Parallelism:推理时把 KV Cache 按序列维度切分到多卡。
这些技术 2024 年开始进入主流推理框架——vLLM、SGLang、TensorRT-LLM 都已支持。
👉 详见 系列第 20 篇:分布式推理 TP/PP/EP/CP。
3.4 推理优化维度:把每一比特榨干
PagedAttention(vLLM 核心)
问题:传统 KV Cache 是连续分配的——为了支持最长序列,要预先分配最大显存。结果:
- 短请求大量浪费
- 显存碎片化严重
- 并发能力骤降
PagedAttention 思路:借鉴操作系统的虚拟内存分页——把 KV Cache 按 16 token 一页管理,按需分配,可以共享。
效果:
- 吞吐量提升 2-4×
- 显存利用率提升 60%+
- 同时支持长短上下文混合并发
👉 详见 系列第 11 篇:推理加速三板斧。
KV Cache 量化
把 KV Cache 从 FP16 量化到 INT8 / FP8 / INT4,显存直接砍半甚至砍 1/4。
实际生产参数:
| 量化级别 | 显存 | 精度损失 | 适用场景 |
|---|---|---|---|
| FP16 (baseline) | 1× | 0% | 默认 |
| FP8 | 0.5× | < 1% | H100+ 推荐 |
| INT8 | 0.5× | 1-2% | 生产主流 |
| INT4 | 0.25× | 3-5% | 极限优化 |
KV Cache 卸载(Offloading)
新趋势:把不常用的 KV Cache 部分卸载到 CPU 内存 / SSD,按需读回 GPU。代表方案:vLLM 的 Prefix Caching、SGLang 的 RadixAttention。
典型应用:长对话中复用历史 KV Cache,避免重复 prefill。
四、实战:部署一个长上下文服务
4.1 模型选型:不要被「支持 N」骗了
模型宣传支持的上下文长度,和实际能用好的上下文长度经常不是一回事。判断方法:看 “大海捞针”(Needle in a Haystack)测试——在长文本中藏一句话,让模型回答关于这句话的问题。
| 模型 | 标称上下文 | 大海捞针有效范围(参考) |
|---|---|---|
| Claude Opus 4.7 | 1M | 全程稳定 |
| Gemini 2.5 Pro | 1M / 2M | 全程稳定 |
| GPT-5 | 400K | 全程稳定 |
| Qwen 3-Max | 1M | 800K 以内稳定 |
| Llama 3-8B (YaRN 扩) | 128K | 64K 以内稳定 |
| DeepSeek-V3 | 128K | 100K 以内稳定 |
经验法则:宣传值打 0.5-0.7 折,是更保险的"可用上下文"。
4.2 vLLM 配置长上下文示例
# 部署 Qwen3-32B 支持 128K 上下文
python -m vllm.entrypoints.openai.api_server \
--model Qwen/Qwen3-32B-Instruct \
--max-model-len 131072 \
--tensor-parallel-size 2 \
--kv-cache-dtype fp8 \
--enable-prefix-caching \
--gpu-memory-utilization 0.9 \
--max-num-seqs 32
几个关键参数解释:
--max-model-len 131072:声明支持 128K--tensor-parallel-size 2:双卡张量并行(系列第 20 篇详解)--kv-cache-dtype fp8:KV Cache 量化到 FP8,显存砍半--enable-prefix-caching:复用历史 prefix 的 KV Cache,加速多轮对话--gpu-memory-utilization 0.9:留 10% 显存给临时 buffer--max-num-seqs 32:最大并发数(长上下文下应该降低)
4.3 长上下文部署的 5 个真实坑
坑 1:首 token 延迟(TTFT)爆炸
prompt 越长,prefill 阶段越慢。1M 上下文的 prefill 可能要 30 秒+。
对策:
- 流式输出 + 用户侧 loading 动画
- Prefix Caching(多轮对话场景显著改善)
- Chunked Prefill(vLLM 高版本支持)
坑 2:并发掉到地板
128K 上下文 + Llama-3-70B + H100 80G,最多只能并发 1-2 个请求。
对策:
- 长短请求分流到不同实例
- 引入 priority queue,长请求降级处理
- 短请求走 7B 模型,长请求走 70B 模型
坑 3:质量随长度衰减
模型在第 1000K 位置的"理解"远不如第 1K。常见症状:
- 忘记早期指令(“忽略系统提示”)
- 中间内容"被压缩"
- 对长文档某段内容的回答精度下降
对策:
- 关键指令放在 prompt 开头 + 结尾(两端效应)
- 测试你的模型在不同长度的真实表现,划定安全区
- 考虑 RAG + 短上下文的混合策略
坑 4:成本曲线非线性
API 计费按 token,但 prefill 的算力成本随长度平方增长。所以 OpenAI、Anthropic 都对长 prompt 收 prefix caching 折扣——用上 caching 能省 50-90%。
自部署时同样要在监控里加 TTFT、吞吐、显存利用率三项关键指标。
坑 5:上下文超长 → KV Cache 溢出
如果用户输入超过 --max-model-len,vLLM 会直接拒绝。要在网关层做硬截断 + 友好提示。
五、长上下文 vs RAG:永恒的争论
随着 1M 上下文普及,一个老问题再次浮上水面:
既然我能把 100 万 token 都丢给模型,是不是 RAG 就过时了?
短答案:没有。两者各有适用场景,混合使用是趋势。
5.1 长上下文的优势
- 零信息丢失:不存在 chunk 切分和检索召回率问题
- 跨段推理强:模型能在整个文档范围内做关联
- 实现简单:直接灌入即可,无需 embedding/向量库等基础设施
- 适合一次性任务:长文档总结、代码库分析
5.2 RAG 的优势
- 成本可控:每次只检索几 K,不付百万 token 的算力
- 数据可更新:向量库可增量更新,不需要重新塞 prompt
- 支持海量数据:1M 也只是百 MB 文本,企业知识库经常是 GB-TB 级
- 可追溯:可以告诉用户答案来自哪段
- 延迟低:避免长 prompt 的 prefill
5.3 选型决策表
| 场景 | 推荐方案 | 理由 |
|---|---|---|
| 单份长文档 QA | 长上下文 | 简单且效果好 |
| 企业知识库(GB+) | RAG | 长上下文塞不下 |
| 跨多份文档汇总 | RAG + 长上下文 | 检索召回 → 长上下文整合 |
| 代码库整体重构 | 长上下文 | 跨文件推理 |
| 高频客服 / 商品搜索 | RAG | 成本可控 |
| Agent 多步任务 | 长上下文为主 | 需要保留全程上下文 |
👉 详见 系列第 26 篇:RAG 实战 - 从向量数据库到 GraphRAG。
5.4 混合策略:GraphRAG / Adaptive RAG / Long-Context RAG
2025 年后业界的实际做法越来越混合:
- GraphRAG:先用 RAG 检索相关文档+实体关系图,再用长上下文做推理
- Adaptive RAG:根据 query 难度动态决定检索 + 长上下文比例
- Long-Context RAG:把 RAG 检索结果(通常上百 K)灌入长上下文模型
这是大模型应用层的进化方向——不是"长上下文取代 RAG",而是"两者协同最大化效果"。
结语:上下文是新维度的算力
读完本文你应该明白:
- 上下文窗口从 4K 到 1M,每个数量级都是一场硬仗——攻坚发生在算法、位置编码、并行、推理优化四个维度
- O(n²) 是物理上不可消除的,所有技术都在"绕"它(Flash Attention 绕 IO、Ring Attention 绕单卡、量化绕显存)
- 工程师选型时别看标称,看实测——大海捞针是硬指标
- 1M 上下文不是"免费午餐"——TTFT、并发、成本曲线都会陡变
- 长上下文不是 RAG 的替代品,混合才是未来
至此,入门认知篇(第 1-5 篇)完整收官——你应该已经建立起完整的大模型工程心智模型:生态全景、架构原理、参数账、token 账、上下文账。
接下来我们进入训练与微调篇(第 6-10 篇):
- 第 6 篇:预训练全流程 —— 数据、算力、Scaling Law 实战拆解。我们会看到 DeepSeek V3 用 557 万美元做出顶级模型背后的工程细节。
- 后面陆续是 SFT 微调、RLHF / DPO、垂直领域大模型、训练数据工程。
如果你是做应用为主的工程师,训练篇可以快速浏览,重点放在第 11 篇推理优化 和第 16 篇 vLLM 部署之后的部署模块。
我们下篇见。
📮 关于「码海寻道」
这里是一个聚焦 AI 工程化、大模型部署、后端架构实战的技术专栏。
写最一线的踩坑经验,做最务实的技术拆解。如果这篇文章对你有启发,欢迎点赞、转发、关注。我们下篇见。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 1
1 0
0- 0



 已为社区贡献38条内容
已为社区贡献38条内容

所有评论(0)