私有化部署PaddleOCR-VL-1.5
1、PaddleOCR-VL-1.5是什么?
PaddleOCR-VL是一款文档解析模型,专为文档中的元素识别设计。以其初代版本(PaddleOCR-VL v1)为例,其核心组件为 PaddleOCR-VL-0.9B,这是一种紧凑而强大的视觉语言模型(VLM),它由 NaViT 风格的动态分辨率视觉编码器与 ERNIE-4.5-0.3B 语言模型组成,能够实现精准的元素识别。该系列模型支持 109 种语言,并在识别复杂元素(如文本、表格、公式和图表)方面表现出色,同时保持极低的资源消耗。
2026年1月29日,发布了PaddleOCR-VL-1.5。PaddleOCR-VL-1.5不仅以94.5%精度大幅刷新了评测集OmniDocBench v1.5,更创新性地支持了异形框定位,使得PaddleOCR-VL-1.5 在扫描、倾斜、弯折、屏幕拍摄及复杂光照等真实场景中均表现优异。
好,以上内容来自官方文档。总结下就是,PaddleOCR-VL-1.5是一个视觉语言模型并应用在文档解析场景。
2、它与PP-OCRv5到底什么关系?
PP-OCRv5 和 PaddleOCR-VL-1.5 都是 PaddleOCR 3.x 生态中的模型,但它们的设计目标和适用场景差异很大。
PP-OCRv5 采用传统检测+识别串联架构,沿用了"检测-方向分类-识别"三阶段流水线设计。它属于通用场景的文字识别,比如在工业上的字符识别场景,比如我之前的文章提到的车牌识别,又比如在游戏外挂中的文字识别等等。
而PaddleOCR-VL-1.5 则采用端到端多模态 VLM 架构,本质是一个 0.9B 参数的视觉语言大模型。它集成了 NaViT 风格的动态分辨率视觉编码器和 ERNIE-4.5-0.3B 语言模型,实现视觉与语义的联合理解。它的战场在复杂文档解析和结构化输出。比如合同、财报、论文的识别,又比如有表格、公式的卷纸的识别等。
这就是两者的区别与联系。
3、PaddleOCR-VL的工作流程
现在来浅浅的了解下它的工作流程:由版面分析与 VLM 识别两个核心阶段组成,见下图: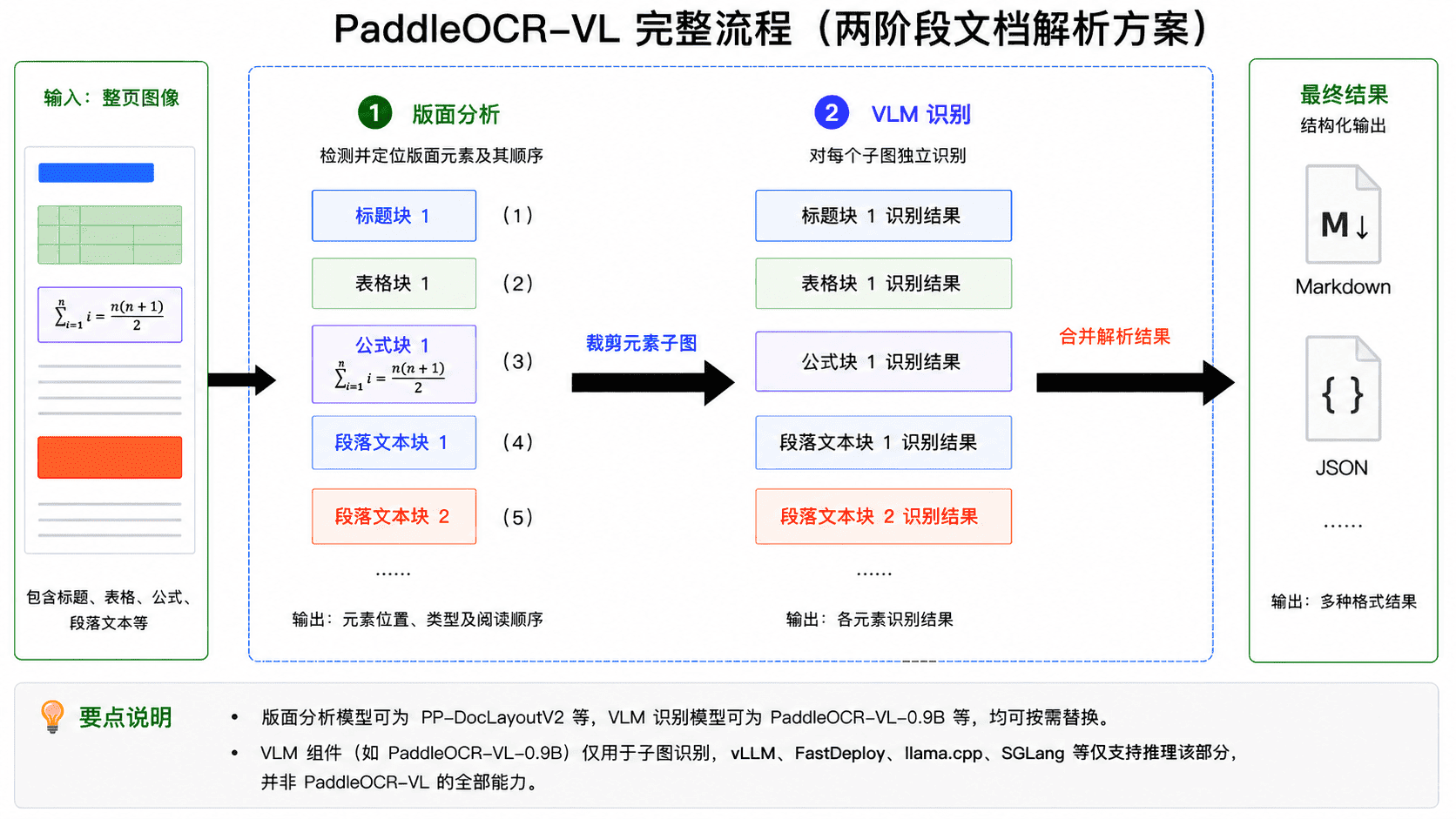
第一阶段中模型以整图作为输入,检测并定位图像中的各类版面元素(例如表格、公式等),同时确定其阅读顺序,并根据检测结果裁剪出对应的元素子图。
第二阶段为 VLM 识别:将每个子图独立输入 VLM,生成对应的识别结果(例如 Markdown 文本),随后再按照版面分析阶段给出的顺序对各元素结果进行合并,得到整幅图像的完整解析结果。
4、如何私有化部署?
PaddleOCR-VL支持的硬件还是挺多的,尤其是国产硬件。这一点让其在政府等场景更有竞争力。
我为了验证功能,使用最容易的方式,那就是docker部署。也建议小伙伴第一步也是使用docker,因为手动安全会遇到千奇百怪的问题,简直在浪费生命。下面展示了paddleocr-vl docker的运行,拉取镜像,启动并进入容器。
PS D:\workspace\paddleocr> docker run -it --gpus all --network host --shm-size 32g --ipc=host ccr-2vdh3abv-pub.cnc.bj.baidubce.com/paddlepaddle/paddleocr-vl:latest-nvidia-gpu-sm120 /bin/bash
Unable to find image 'ccr-2vdh3abv-pub.cnc.bj.baidubce.com/paddlepaddle/paddleocr-vl:latest-nvidia-gpu-sm120' locally
latest-nvidia-gpu-sm120: Pulling from paddlepaddle/paddleocr-vl
1257a55b8f69: Pull complete
...
Digest: sha256:b43e3a1d8e29561270d3eb21a344ee473b01c446d4d768620421100f917f6750
Status: Downloaded newer image for ccr-2vdh3abv-pub.cnc.bj.baidubce.com/paddlepaddle/paddleocr-vl:latest-nvidia-gpu-sm120
镜像中仅预装飞桨框架,它可以完整的运行整个流程:版面分析模型 + VLM识别模型 + 所有后处理逻辑。
5、它的效果如何?
我用两个命令行的例子来展示下它的效果。
5.1 发票识别
我在网上找到了一张发票测试图片,没有信息安全问题。图片如下:
上面的启动容器命令中,并没有挂载主机目录,所以我需要将图片复制到容器内。新启动一个命令行,执行如下命令:
docker ps -a
CONTAINER ID IMAGE COMMAND CREATED NAMES
04939001bde5 paddlepaddle/paddleocr-vl:latest-nvidia-gpu-sm120 "/bin/bash" 4 weeks ago pedantic_varahamihira
docker cp D:\Pictures\fp.png pedantic_varahamihira:/home/paddleocr/
Successfully copied 390kB to pedantic_varahamihira:/home/paddleocr/
好了,接下来在容器内一行命令跑识别流程:
paddleocr@docker-desktop:~$ paddleocr doc_parser -i ./fp.png --save_path ./output
文档解析fp.png并将结果保存到output路径。
日志如下:
Creating model: ('PP-DocLayoutV3', None, None)
Model files already exist. Using cached files. To redownload, please delete the directory manually: `/home/paddleocr/.paddlex/official_models/PP-DocLayoutV3`.
Creating model: ('PaddleOCR-VL-1.5-0.9B', None, None)
Model files already exist. Using cached files. To redownload, please delete the directory manually: `/home/paddleocr/.paddlex/official_models/PaddleOCR-VL-1.5`.
Bucketed engine_config has no entry for resolved engine 'paddle_dynamic'; using an empty config for that engine.
Loading configuration file /home/paddleocr/.paddlex/official_models/PaddleOCR-VL-1.5/config.json
Loading weights file /home/paddleocr/.paddlex/official_models/PaddleOCR-VL-1.5/model.safetensors
use GQA - num_heads: 16- num_key_value_heads: 2
...
Loaded weights file from disk, setting weights to model.
All model checkpoint weights were used when initializing PaddleOCRVLForConditionalGeneration.
All the weights of PaddleOCRVLForConditionalGeneration were initialized from the model checkpoint at /home/paddleocr/.paddlex/official_models/PaddleOCR-VL-1.5.
If your task is similar to the task the model of the checkpoint was trained on, you can already use PaddleOCRVLForConditionalGeneration for predictions without further training.
Loading configuration file /home/paddleocr/.paddlex/official_models/PaddleOCR-VL-1.5/generation_config.json
[2026/05/24 03:57:49] paddleocr INFO: Processed item 0 in 11492.055177688599 ms
从上述日志可以看出:整个过程耗时约 11.5 秒,模型成功识别了这张发票。版面分析模型使用PP-DocLayoutV3来识别发票上的各个区域,VLM识别模型使用PaddleOCR-VL-1.5-0.9B,用来识别文字内容。
两个模型都使用了缓存,无需重新下载。
识别的结果如下:
{'res': {'input_path': './fp.png', 'page_index': None, 'page_count': None, 'width': 779, 'height': 453, 'model_settings': {'use_doc_preprocessor': False, 'use_layout_detection': True, 'use_chart_recognition': False, 'use_seal_recognition': False, 'use_ocr_for_image_block': False, 'format_block_content': False, 'merge_layout_blocks': True, 'markdown_ignore_labels': ['number', 'footnote', 'header', 'header_image', 'footer', 'footer_image', 'aside_text'], 'return_layout_polygon_points': True}, 'layout_det_res': {'input_path': None, 'page_index': None, 'boxes': [{'cls_id': 22, 'label': 'text', 'score': 0.8300427794456482, 'coordinate': [106, 25, 244, 51], 'order': 1, 'polygon_points': array([[106., 25.],
[244., 25.],
[244., 51.],
[106., 51.]], dtype=float32)}, {'cls_id': 6, 'label': 'doc_title', 'score': 0.8609796166419983, 'coordinate': [266, 4, 486, 29], 'order': 2, 'polygon_points': array([[266., 4.],
[486., 4.],
[486., 29.],
[266., 29.]], dtype=float32)}, {'cls_id': 22, 'label': 'text', 'score': 0.8420836329460144, 'coordinate': [0, 70, 229, 91], 'order': 3, 'polygon_points': array([[-6.123234e-16, 7.000000e+01],
[ 2.280000e+02, 7.000000e+01],
[ 2.280000e+02, 9.000000e+01],
[ 0.000000e+00, 9.000000e+01]], dtype=float32)}, {'cls_id': 20, 'label': 'seal', 'score': 0.9233654737472534, 'coordinate': [320, 5, 435, 81], 'order': 4, 'polygon_points': array([[320., 5.],
[435., 5.],
[435., 81.],
[320., 81.]], dtype=float32)}, {'cls_id': 22, 'label': 'text', 'score': 0.8362825512886047, 'coordinate': [545, 14, 696, 42], 'order': 5, 'polygon_points': array([[545., 14.],
[696., 14.],
[696., 42.],
[545., 42.]], dtype=float32)}, {'cls_id': 22, 'label': 'text', 'score': 0.8474958539009094, 'coordinate': [530, 63, 730, 83], 'order': 6, 'polygon_points': array([[530., 63.],
[729., 63.],
[729., 82.],
[530., 82.]], dtype=float32)}, {'cls_id': 21, 'label': 'table', 'score': 0.9652956128120422, 'coordinate': [3, 94, 755, 449], 'order': None, 'polygon_points': array([[ 3., 94.],
[755., 94.],
[755., 449.],
[ 3., 449.]], dtype=float32)}, {'cls_id': 20, 'label': 'seal', 'score': 0.9313402771949768, 'coordinate': [512, 328, 663, 432], 'order': 7, 'polygon_points': array([[512., 328.],
[663., 328.],
[663., 432.],
[512., 432.]], dtype=float32)}, {'cls_id': 2, 'label': 'aside_text', 'score': 0.8114798665046692, 'coordinate': [758, 166, 773, 330], 'order': None, 'polygon_points': array([[758., 169.],
[772., 169.],
[772., 329.],
[758., 329.]], dtype=float32)}]}, 'parsing_res_list': [{'block_label': 'text', 'block_content': '3300083620', 'block_bbox': [106, 25, 244, 51]}, {'block_label': 'doc_title', 'block_content': '某某增值税普通发票', 'block_bbox': [266, 4, 486, 29]}, {'block_label': 'text', 'block_content': '校验码 93484 56892 10548 44080', 'block_bbox': [0, 70, 229, 91]}, {'block_label': 'seal', 'block_content': '', 'block_bbox': [320, 5, 435, 81]}, {'block_label': 'text', 'block_content': 'No 0123456789', 'block_bbox': [545, 14, 696, 42]}, {'block_label': 'text', 'block_content': '开票日期:2016年03月15日', 'block_bbox': [530, 63, 730, 83]}, {'block_label': 'table', 'block_content': '<table><tr><td rowspan="3">购货单位</td><td colspan="4">名称:个人</td><td rowspan="2">密码</td><td>033+*7-*73*>2170608870>2/>09-7/3/+/86<9><>990498/72132*7+</td><td></td><td></td></tr><tr><td colspan="4">纳税人识别号:地址、电话:开户行及账号:</td><td colspan="3"><>931329*894++897/8>+570*5->6<589/47*019>/306>26+006<89</td></tr><tr><td>货物或应税劳务名称</td><td>规格型号</td><td>单位</td><td>数量</td><td>单价</td><td>金额</td><td>税率</td><td>税额</td></tr><tr><td>公司代用名</td><td></td><td>888888KD</td><td>套</td><td>1</td><td>120.00</td><td>120.00</td><td>25%</td><td>30.00</td></tr><tr><td>合 计</td><td></td><td></td><td></td><td></td><td></td><td>¥120.00</td><td>25%</td><td>¥30.00</td></tr><tr><td>价税合计(大写)</td><td colspan="7">ⓧ叁拾圆整</td><td></td></tr><tr><td>销货单位</td><td colspan="8">名称:某某某某某某有限公司纳税人识别号:10024580015571515地址、电话:某某市某某区某某路某某号 12458788开户行及账号:某某市某某银行某某支 行 888888888888888</td></tr></table>', 'block_bbox': [3, 94, 755, 449]}, {'block_label': 'aside_text', 'block_content': '第二联:发票联购贷方记账凭证', 'block_bbox': [758, 166, 773, 330]}]}}
结果保存在了output目录下,有fp.docx、fp.md和fp_res.json,我将docx文件截图如下:
5.2 新闻识别
这是官方提供的一个例子,图片如下:
识别及结果如下:
paddleocr@docker-desktop:~$ paddleocr doc_parser -i ./paddleocr_vl_demo.png --save_path ./output
[2026/05/24 04:30:25] paddleocr INFO: Processed item 0 in 34695.223569869995 ms
我将docx文件截图如下:
6、最后
本次只是将PaddleOCR-VL-1.5在docker环境中全流程跑通,而且还仅仅使用的CLI命令行方式。
识别速度也看到了,RTX5060Ti的硬件配置如下:
nvidia-smi
Wed Apr 22 14:16:40 2026
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 576.88 Driver Version: 576.88 CUDA Version: 12.9 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Driver-Model | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA GeForce RTX 5060 Ti WDDM | 00000000:01:00.0 On | N/A |
| 0% 41C P5 12W / 180W | 1830MiB / 16311MiB | 10% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
发票识别耗时11.5秒,新闻耗时34.7秒。还是有优化的空间。
为了优化性能,paddlepaddle又推出了VML推理服务镜像(paddleocr-genai-server),它引入专门为大模型推理设计的加速框架,如 vLLM、FastDeploy、SGLang。这些框架使用了诸如 PagedAttention、连续批处理等高级技术,能将VLM的推理速度提升数倍。生产环境部署,需要使用这个镜像提供API服务。后续我们找时间来搭建一套。
我们下期再见。
参考
https://www.paddleocr.ai/latest/version3.x/pipeline_usage/PaddleOCR-VL.html

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 1
1 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)