从零实现 AI 聊天助手:可直接复用的前端核心方案
从零实现 AI 聊天助手:可直接复用的前端核心方案
引言
项目目标:使用 Vue2 + TypeScript 构建 AI 聊天助手核心功能,实现「用户发送→AI逐字流输出」(类似 ChatGPT 的流式返回)效果,提供可落地的实现方案。
核心要求:
- 视觉一致(左对齐、黑色、不斜体)
- 输入锁定(避免并发推送)
- 自动滚到底部
- 支持请求真实API(SSE/ReadableStream)
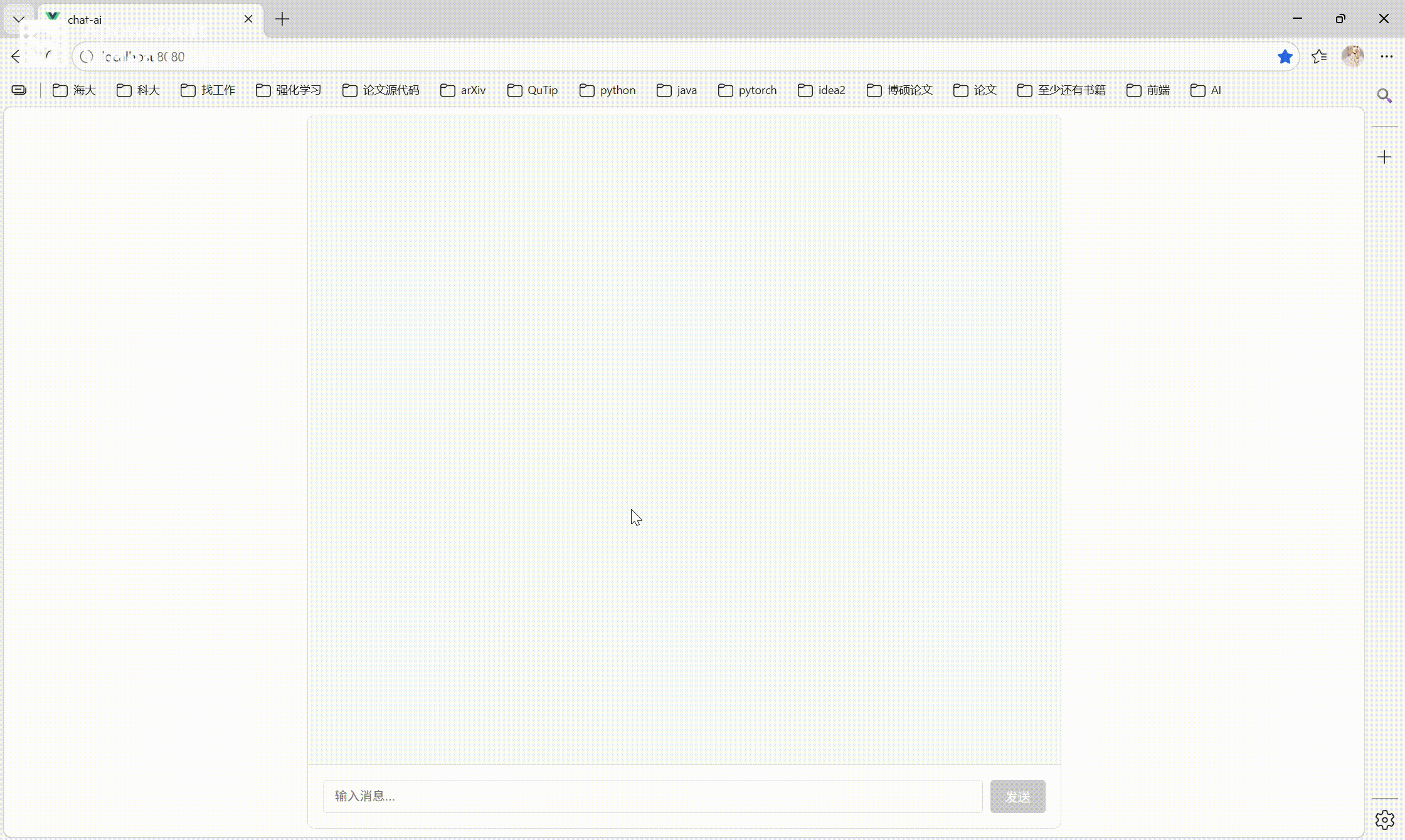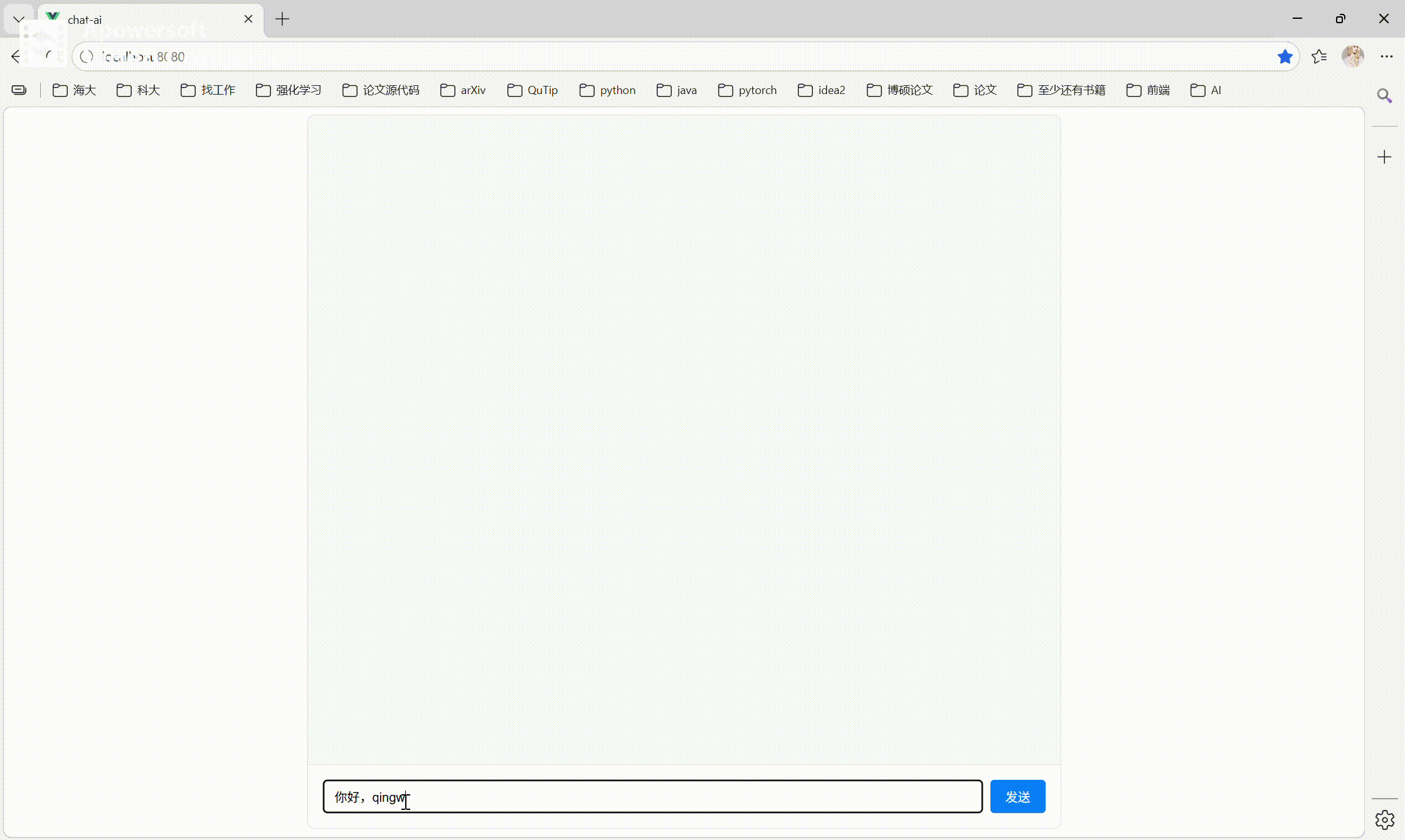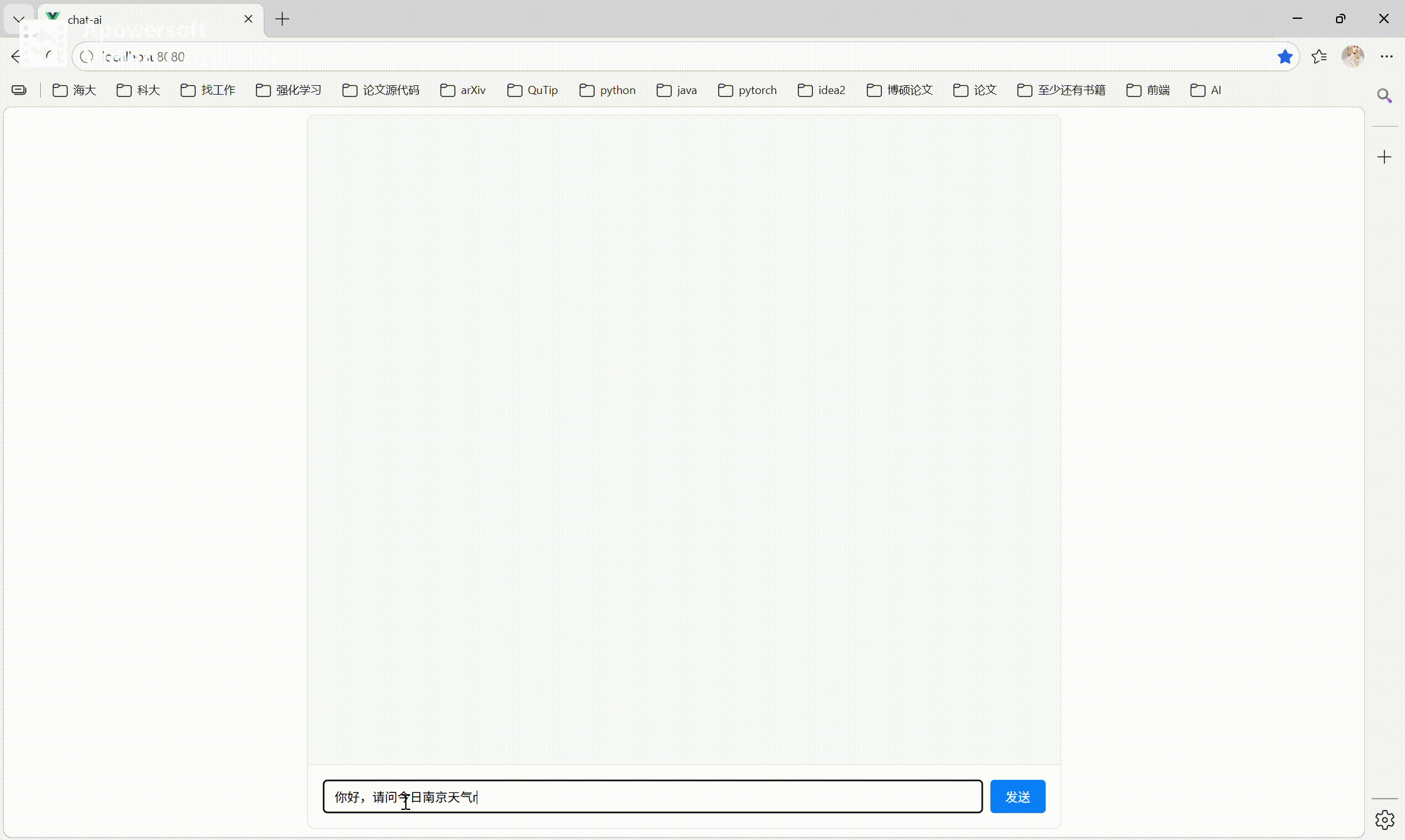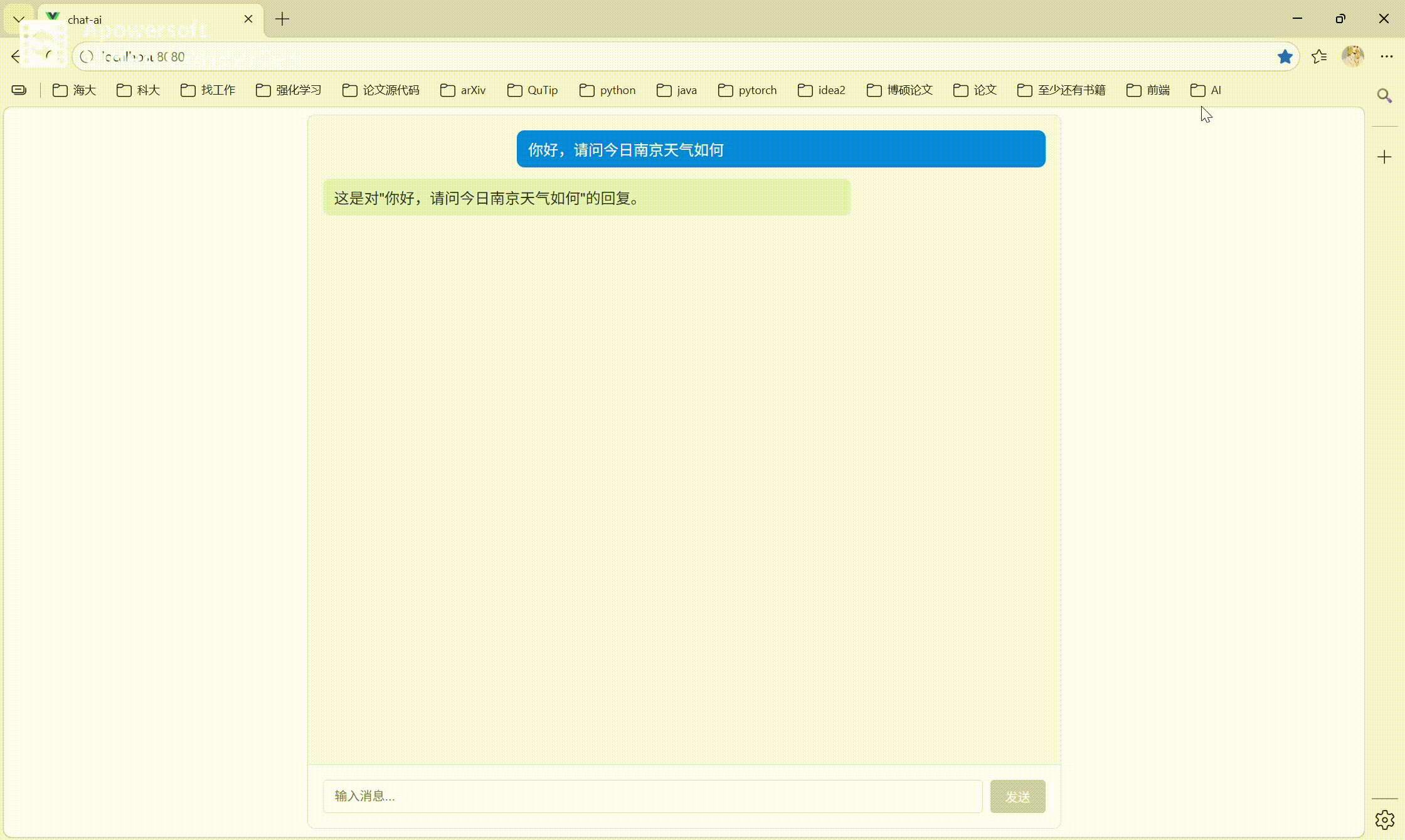
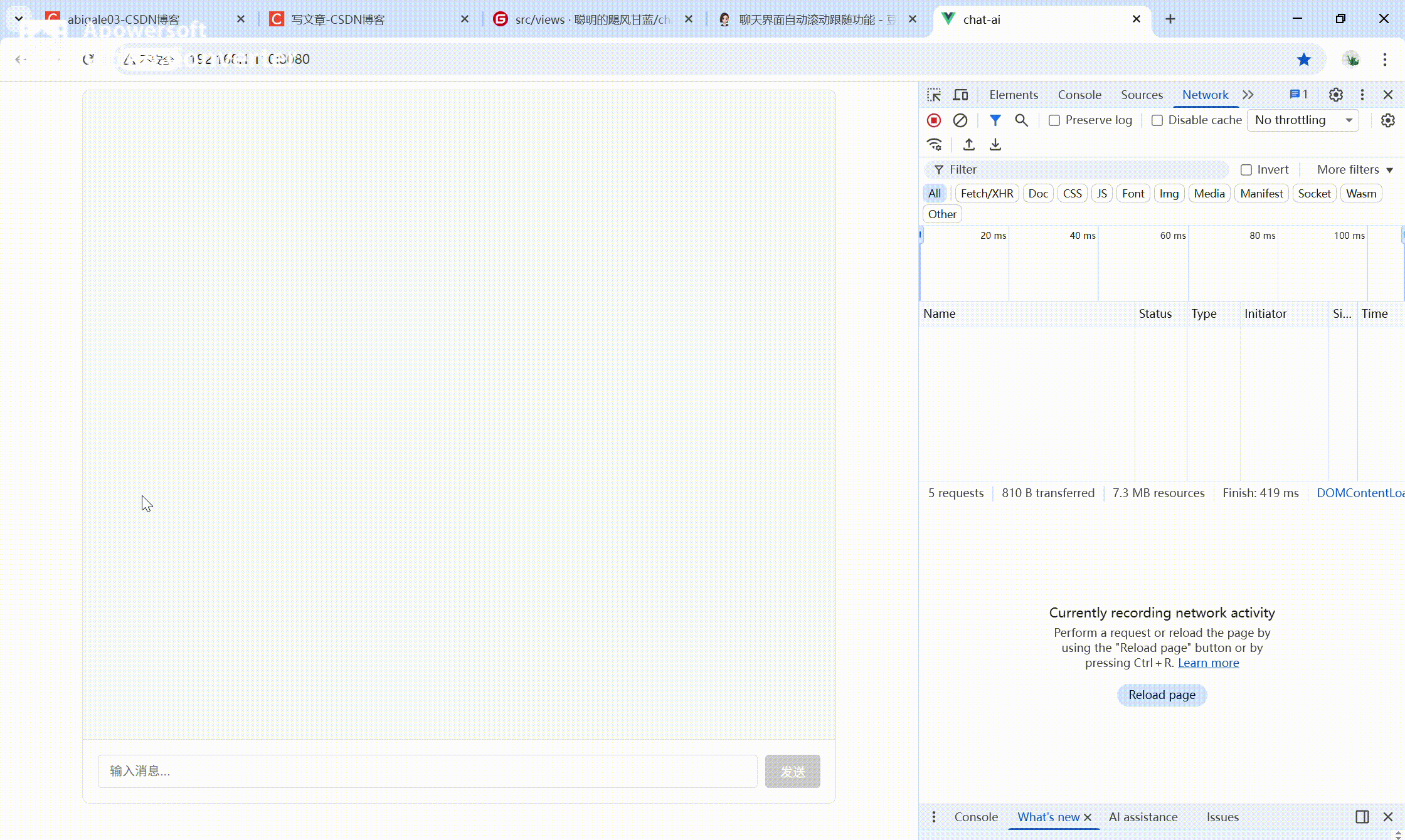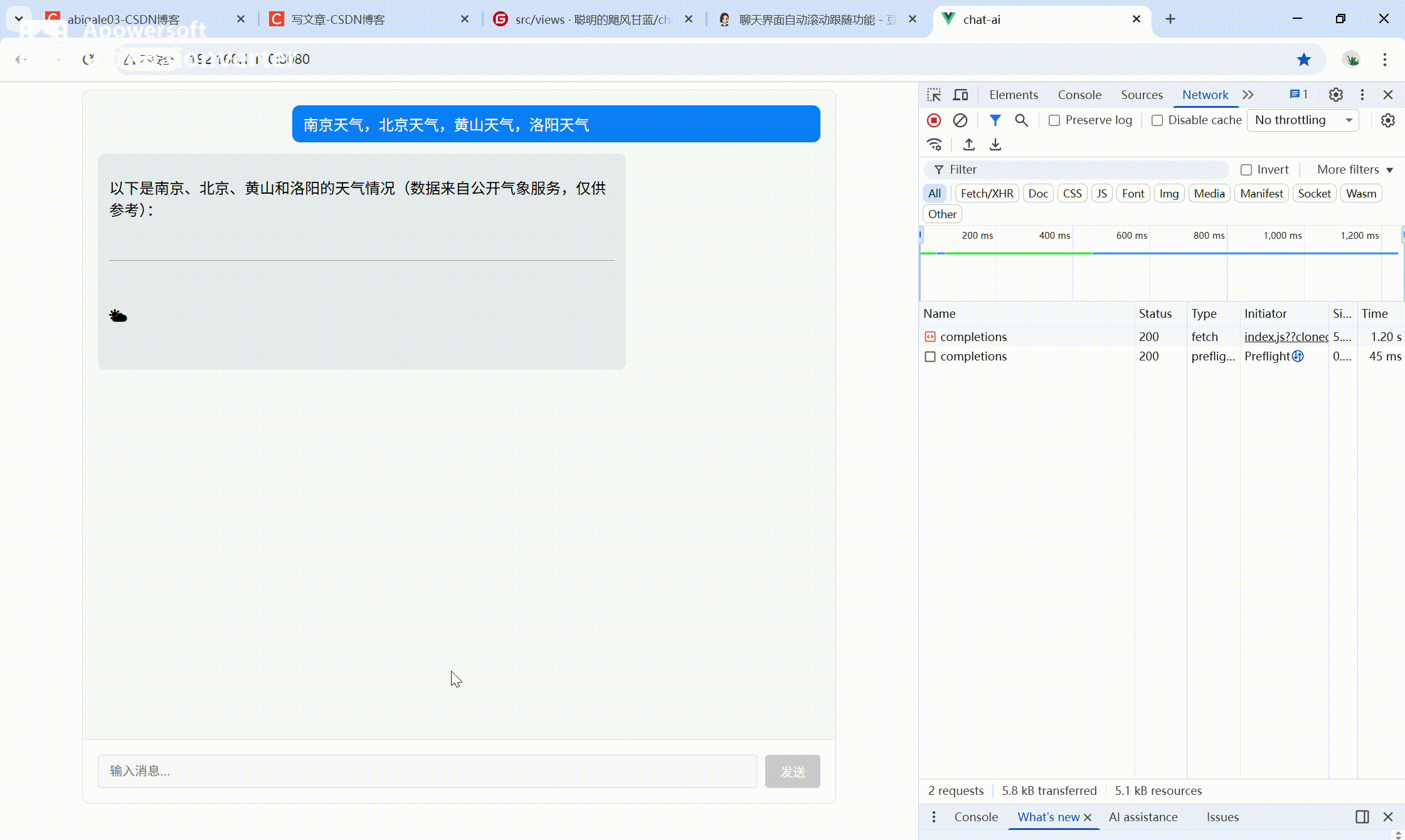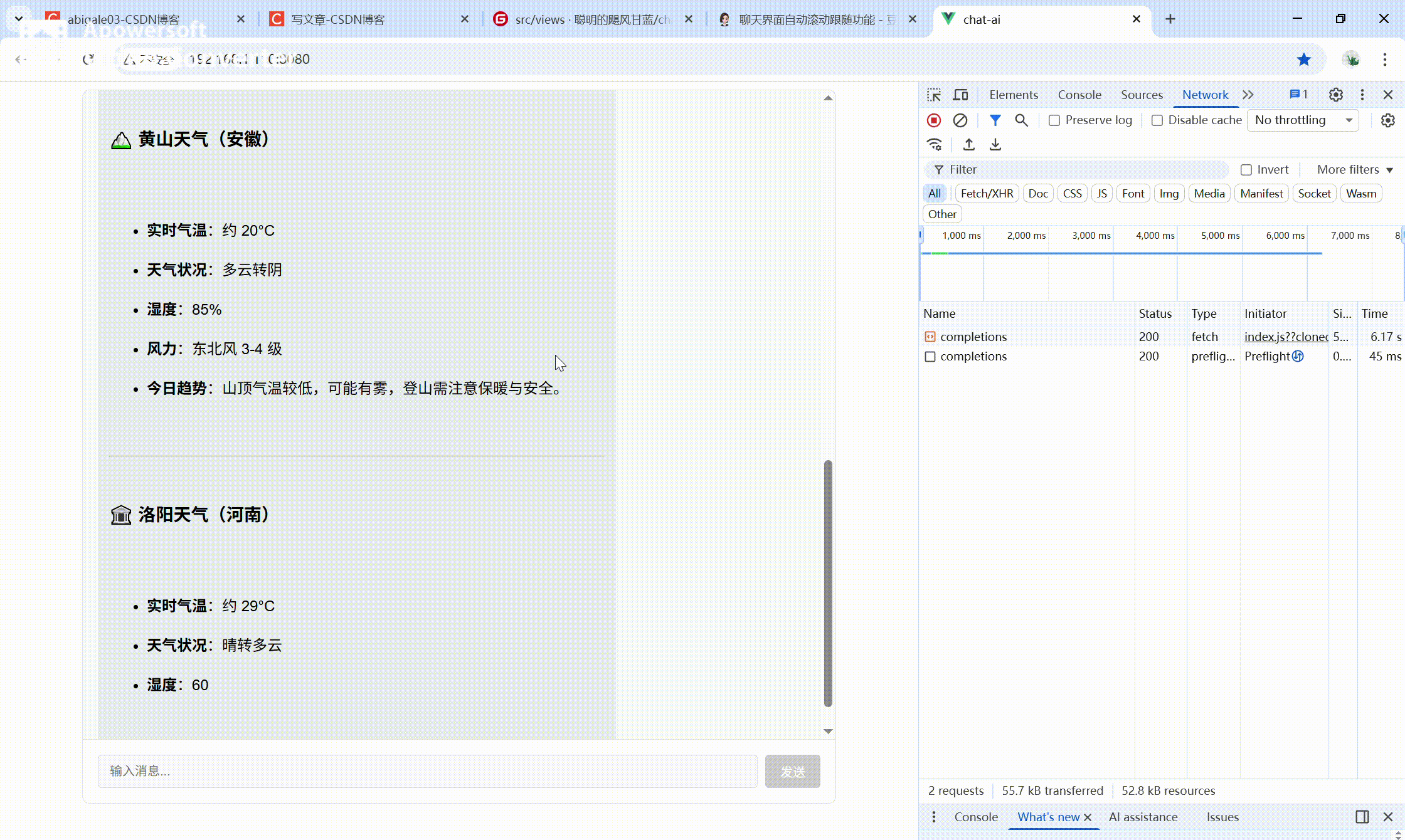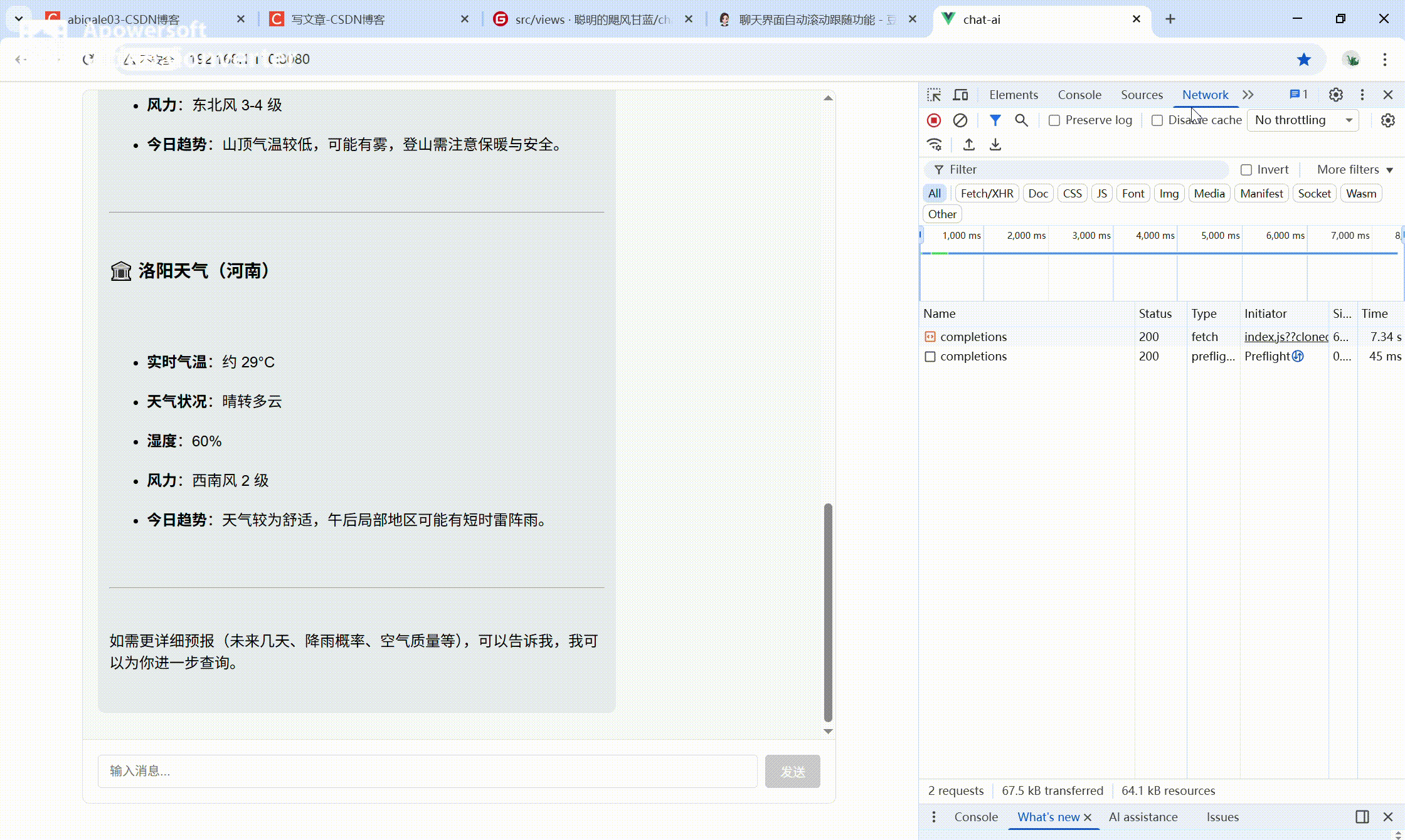
1. 效果展示
本组件实现类 ChatGPT 的流式聊天体验。
核心效果
- 用户消息实时展示
- AI 回复逐字流式输出(打字机效果)
交互体验
- 聊天区域自动滚动到底部
- 流式过程中禁用输入,防止重复发送
UI规范
- 统一干净的 UI 样式(左对齐、黑色常规字体)
完整流程
- 输入消息 → 发送 → 顶部展示用户消息
- 底部立即出现 AI 占位消息 → 逐字输出回复内容
- 输出完成后恢复输入框,可继续对话
效果动图
2. 项目文件结构
核心文件说明,明确各文件作用与修改注意事项
-
chat.vue:聊天组件核心文件(重点开发文件)
-
chat-vue-technical-doc.md:技术说明文档(自动生成,无需手动修改)
-
main.ts / App.vue:全局路由与入口文件(无需改动,仅作为项目入口)
3. Chat 组件(核心功能组件)
3.1 基础配置与核心定义
3.1.1 数据结构定义
-
定义Message接口,明确角色、内容、流式状态等核心字段。
-
接口详情:role(区分user/assistant)、content(消息完整内容)、streaming(流式状态标识)、displayedContent(流式增量展示内容)。
-
字段作用说明:用户消息直接渲染,AI消息先占位(“空内容
content=''+ 流状态streaming=true+displayedContent=''”)再在循环里逐字补充内容
interface Message {
role: "user" | "assistant";
content: string;
streaming?: boolean;
displayedContent?: string;
}
3.1.2 关键状态变量
messages: Message[]存储所有聊天消息,管理消息状态inputMessage: string绑定输入框,存储用户待发送消息isStreaming: boolean控制UI输入锁定,保证一次仅一个流式输出
3.2 聊天流程:逐字打字机模拟
3.2.1 sendMessage 逻辑
-
输入校验:检查空输入,流式过程中禁用发送功能
-
消息处理:推送用户消息到messages数组,同时推送AI空占位消息
-
流式调用:调用simulateStreaming方法,传入AI模拟响应和消息索引
-
状态重置:模拟流式输出完成后,将isStreaming设为false,恢复输入功能
3.2.2 simulateStreaming 动画机制
-
核心逻辑:循环遍历AI响应字符串,每50ms追加一个字符到displayedContent
-
交互优化:每次追加字符后调用scrollToBottom(),保证消息实时可见
-
状态更新:流式输出结束后,切换streaming为false,将完整响应内容写入content字段
-
可扩展性说明:该逻辑支持后续替换为真实SSE/fetch stream/websocket,无需修改前端核心结构
3.3 模板与样式:可控 UI
3.3.1 模板渲染逻辑
-
角色区分渲染:根据message.role判断渲染用户/AI消息
-
流式状态渲染:AI消息流式输出时,渲染displayedContent;非流式状态渲染content
-
核心模板代码示例:区分用户、AI流式、AI非流式三种场景的渲染逻辑
<span v-if="message.role === 'user'">{{ message.content }}</span>
<span v-else-if="message.streaming" class="streaming-text">{{ message.displayedContent }}</span>
<span v-else>{{ message.content }}</span>
3.3.2 样式调整
-
基础样式:.message类设置text-align:left,保证所有消息左对齐
-
流式文本样式:.streaming-text设置color:#000、font-style:normal、white-space:pre-wrap,保证视觉一致
-
样式效果:避免流式文本灰色、斜体,提升阅读体验
4. 大模型 API 集成
以智谱 AI为例,前端用 fetch + ReadableStream 实现流式。
需要前往 智谱开放平台 注册并创建应用,获取 API Key.
4.1 实现目标
- 调用智谱 GLM 大模型接口
- 开启流式输出(stream: true)
- 实时接收 AI 逐字返回的内容
- 动态更新到页面上,实现打字机效果
4.2 实现细节
4.2.1 方法定义与基础配置
async fetchAIStream(aiMsgIdx: number) {
const apiKey = "62e6df10d65d43b09c97bb4d3c340bce.xxxxxxxxxxxx";// 替换为你的 API Key
const url = "https://open.bigmodel.cn/api/paas/v4/chat/completions";
- async:标记这是异步函数,内部可以用 await 等待接口响应
- aiMsgIdx: number:接收一个消息索引,用来定位要更新的 AI 消息
- apiKey:智谱大模型的身份密钥(你自己的密钥)
- url:智谱官方的对话接口地址
sendMessage()调用fetchAIStream()时需要await,等待全部
4.2.2 发送 POST 请求给大模型
const response = await fetch(url, {
method: "POST",
headers: {
"Content-Type": "application/json",
Authorization: `Bearer ${apiKey}`, // 身份验证
},
body: JSON.stringify({
model: "glm-4.5-flash", // 使用的模型版本
stream: true, // ✅ 核心:开启流式输出
messages: this.messages
.map((msg) => ({
role: msg.role,
content: msg.content || msg.displayedContent,
}))
.filter((m) => m.role === "user" || m.role === "assistant"),
}),
});
这部分是请求核心:
- fetch:浏览器原生 API,发送网络请求
- headers:请求头,携带身份凭证和数据格式
- stream: true:最重要的参数!告诉大模型不要一次性返回全部答案,而是逐字流式返回
- messages:对话上下文
- 只保留 user(用户)和 assistant(AI)的消息
- 取完整内容 content 或正在显示的内容 displayedContent
为什么用fetch而不是其他请求
一句话结论:可以用 axios,但不推荐!流式输出必须用 fetch.
因为 AI 流式输出(SSE / ReadableStream) 依赖一个核心能力:
读取原生数据流(stream / ReadableStream)。fetch 天生支持response.body.getReader()(可以逐块读取数据)。axios 目前完全不支持:axios 会等整个请求全部结束才把结果一次性给你,不能实时拿到每一段文字。也就是说:fetch = 边煮边喝汤(流式);axios = 煮完才能喝(一次性)。
Axios 官方文档写得很清楚:Axios does not support streaming responses. Axios 不支持流式响应。它会把整个返回缓存起来,直到结束才返回,无法实现打字机效果。
那能不能强行让 axios 支持?能,但非常麻烦:要装额外插件 axios-observable. 要配置复杂;兼容性差;不如 fetch 原生稳定、简洁。
一句话总结:AI 流式聊天 = 必须用 fetch, 普通接口(增删改查)= 随便用 axios /fetch.
4.2.3 初始化流式读取器
const reader = response.body?.getReader();
const decoder = new TextDecoder("utf-8");
- response.body?.getReader():获取流式响应读取器,用来一点点接收数据
- response.body → 是一个 ReadableStream 对象(浏览器自带)
- .getReader() → 获取这个流的读取器(ReadableStreamDefaultReader)
const reader = response.body?.getReader();是浏览器原生 Fetch API + 流式响应 (ReadableStream) 标准用法
- TextDecoder(“utf-8”):把二进制流解码成我们能看懂的文字
4.2.4 循环读取流式数据
while (true) {
const { done, value } = await reader!.read();
if (done) break; // 数据接收完毕,退出循环
- while(true):无限循环,持续读取流数据
- reader.read():读取一段数据,返回两个值
- done:是否读取完成
- value:本次读取到的二进制数据
- 读完就 break 跳出循环
- 为什么你看不到 done?done: true 是 浏览器流 ReadableStream API 内部返回的状态,不是后端返回的文本,不会出现在 data: xxxx 里,只有流彻底关闭时,才会返回 { done: true }。所以你抓包看不到,但代码里能读到。
- 整体代码流程
1. 发送请求
2. 拿到 ReadableStream(response.body)
3. 拿读取器 reader
4. while 循环 reader.read()
→ 读一段数据
→ 解析显示
5. 后端最后发 data: [DONE]
6. 后端关闭连接
7. 浏览器自动返回 { done: true }
8. 循环 break,结束
- 观察接口返参
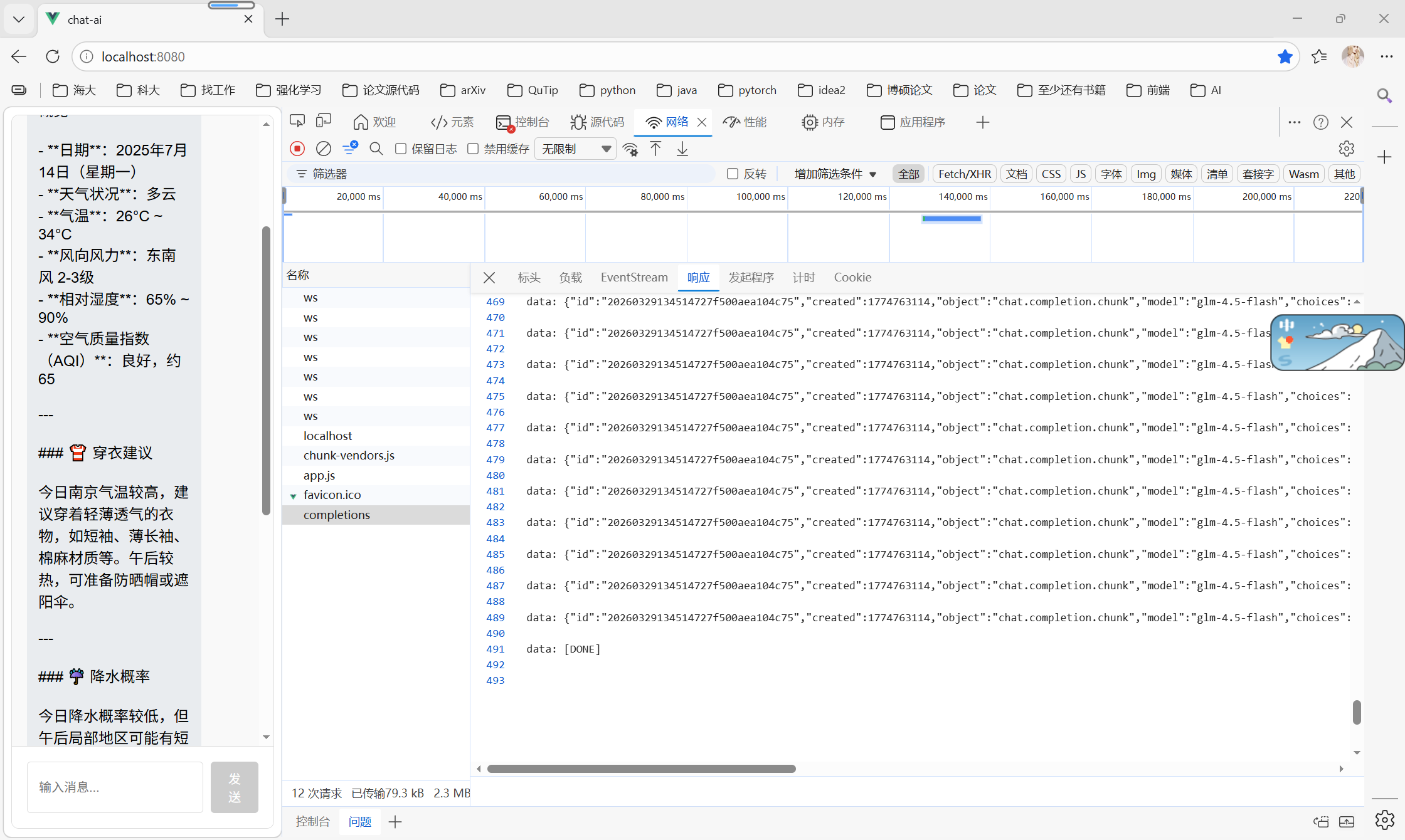
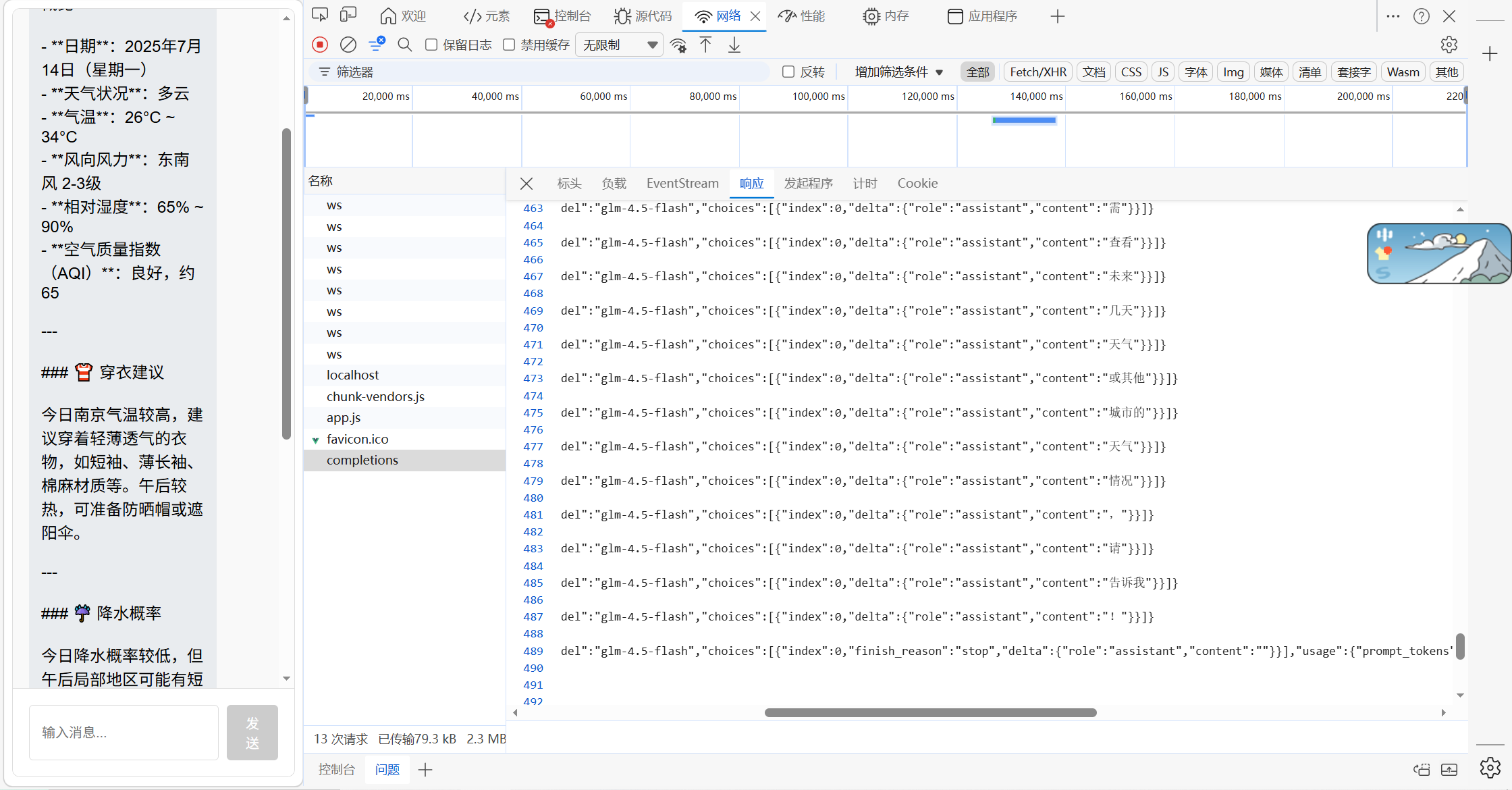
4.2.5 解析每一段流式数据
const chunk = decoder.decode(value); // 二进制转文字
const lines = chunk.split("\n").filter((line) => line.trim());
- 解码二进制数据为文本
- 按换行符拆分(大模型流式返回的格式要求)
- 过滤空行,避免无效数据
4.2.6 处理标准 SSE 格式数据
for (const line of lines) {
if (!line.startsWith("data: ")) continue; // 只处理以 data: 开头的行
const data = line.slice(6).trim();
if (data === "[DONE]") continue; // 结束标记,跳过
这是大模型流式返回的固定格式(SSE):
- 每一段数据都以 data: 开头
- 最后会返回 data: [DONE] 表示传输结束
- 这里做格式过滤,只保留有效内容
4.2.7 解析 JSON 并实时更新页面
try {
const json = JSON.parse(data);
const content = json.choices[0]?.delta?.content || "";
this.messages[aiMsgIdx].displayedContent += content;
this.$nextTick(() => this.scrollToBottom());
} catch (e) {}
这是页面实时显示的核心:
- 解析 JSON 数据
- 取出流式增量内容:choices[0].delta.content
- 追加到对应 AI 消息的 displayedContent 上(不是覆盖!)
- $nextTick:Vue 异步更新 DOM 后,自动滚动到页面底部
- try/catch:捕获解析异常,避免页面报错
4.3 注意事项
- API Key 直接写在代码里不安全(生产环境要放后端)
- 依赖浏览器原生 fetch,不支持非常老的浏览器
- 必须开启 stream: true,否则无法流式接收
4.4 调用方式
这个方法一般在发送消息后调用。
// 示例:发送用户消息 → 添加一条空的AI消息 → 调用流式方法填充内容
this.messages.push({ role: "user", content: "你好" });
const aiMsgIdx = this.messages.length;
this.messages.push({ role: "assistant", displayedContent: "" });
// 开始流式输出
try {
await this.fetchAIStream(aiMsgIdx);
} catch (error) {
console.error("请求出错", error);
this.messages[aiMsgIdx].content = "请求失败,请稍后重试";
} finally {
this.messages[aiMsgIdx].streaming = false;
this.messages[aiMsgIdx].content =
this.messages[aiMsgIdx].displayedContent || "没有回复内容";
this.isStreaming = false;
}
4.5 实现效果
lz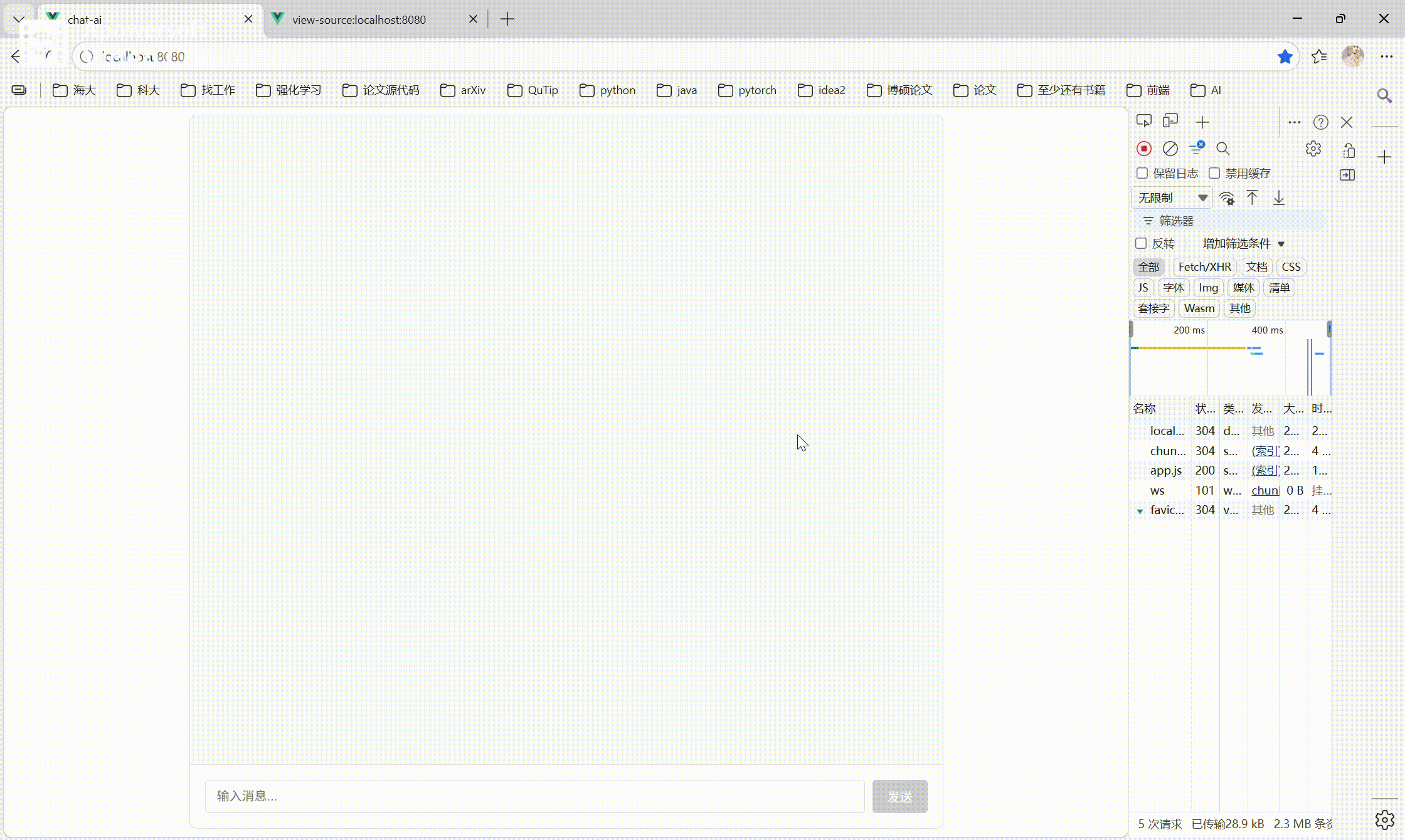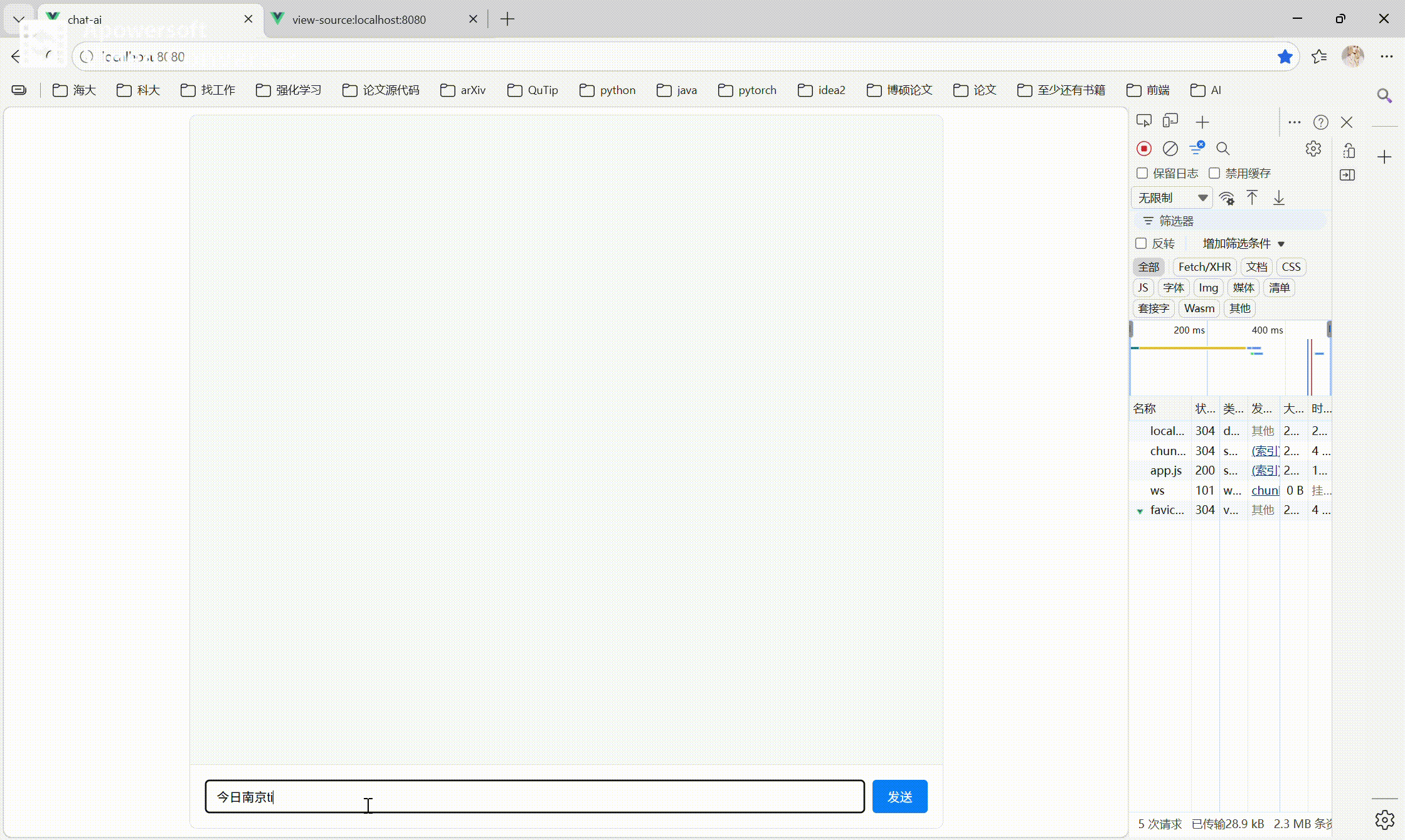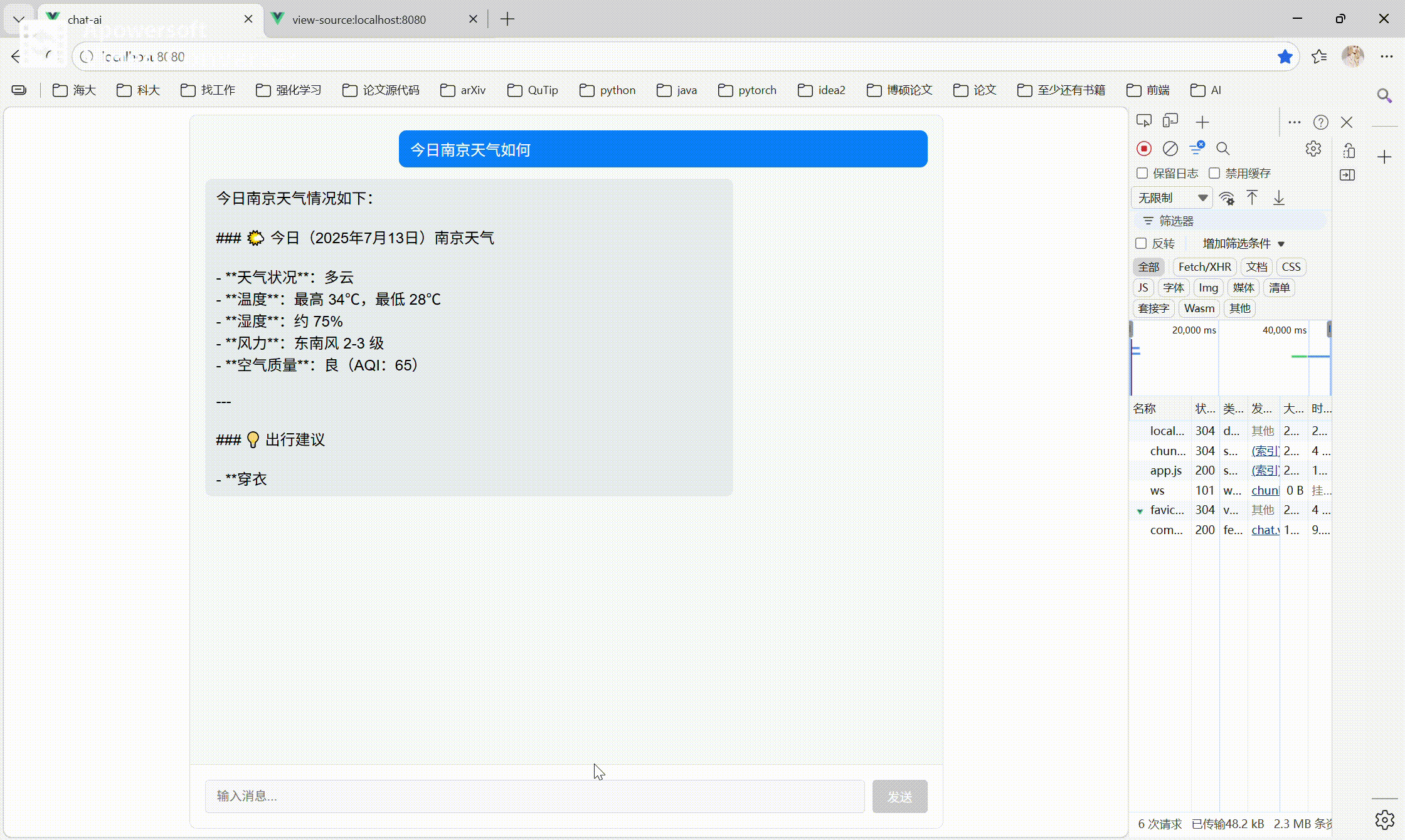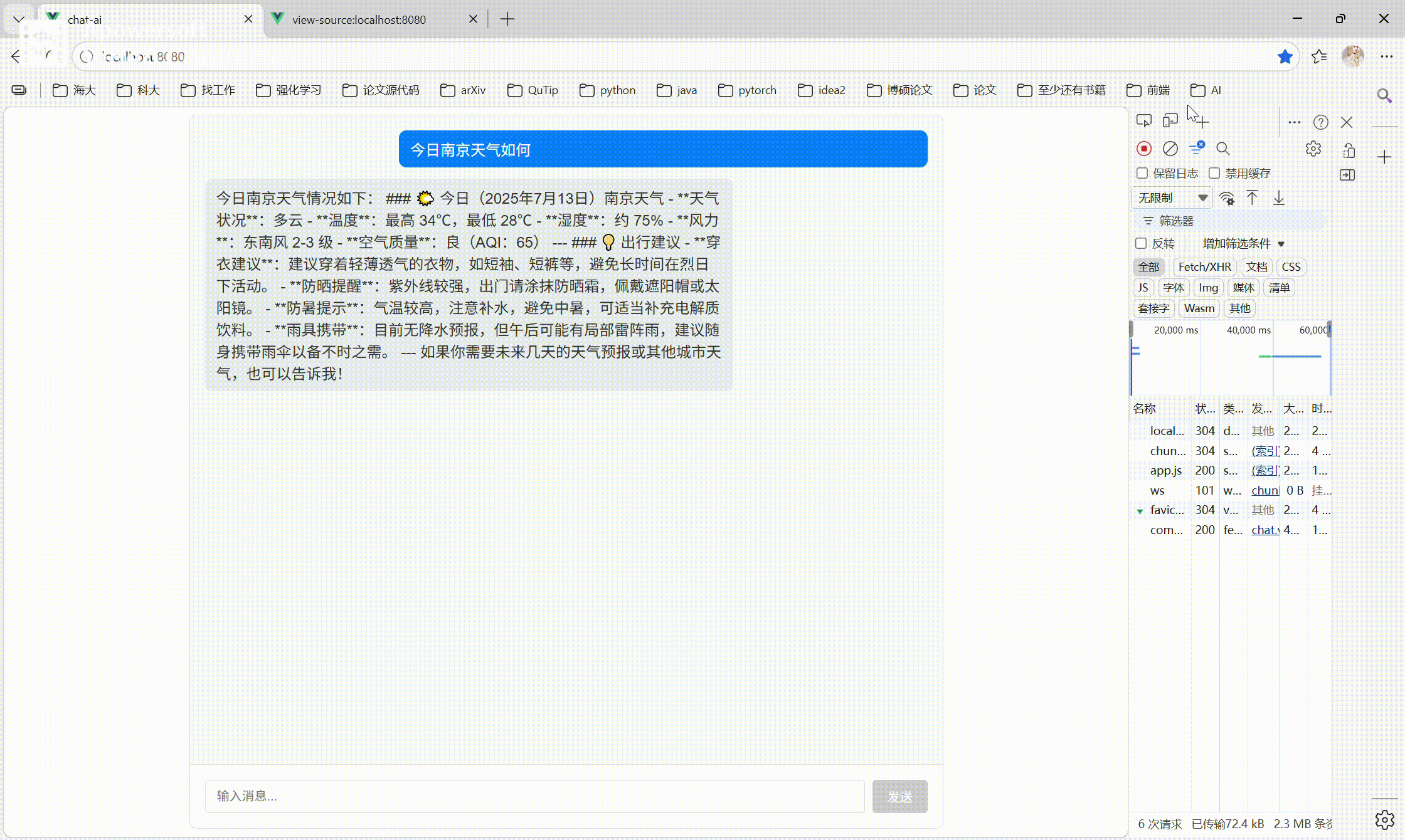
5 Markdown 格式适配
实现目标
将消息内容中的 Markdown 语法(标题、列表、代码块、引用、表格、链接、加粗斜体等) 渲染为美观的富文本样式,并支持代码高亮。
技术选型
技术选型
- marked:Markdown 解析渲染
- highlight.js:代码块语法高亮
安装依赖
marked 依赖支持所有 Markdown 语法:标题、粗体、斜体、列表、表格、引用、链接、图片;代码块高亮(几十种语言);代码高亮主题可换; Vue2 样式穿透:用 ::v-deep 让样式作用于 v-html 渲染的内容。
npm install marked@4.3.0 highlight.js
Vue2 用 marked 4.x 最稳定,不会报错。
Markown渲染
<script lang="ts">
/* eslint-disable */
import { Component, Vue } from "vue-property-decorator";
import { marked } from "marked";
import hljs from "highlight.js";
// 代码高亮主题(可替换)
import "highlight.js/styles/github-dark.css";
....
// 渲染方法
renderMarkdown(text: string): string {
marked.setOptions({
gfm: true,
breaks: true,
highlight: function (code: string, lang?: string) {
try {
if (lang && hljs.getLanguage(lang)) {
return hljs.highlight(code, { language: lang }).value;
}
return hljs.highlightAuto(code).value;
} catch (e) {
return code;
}
},
});
return marked.parse(text) as string;
}
}
</script>
实现效果
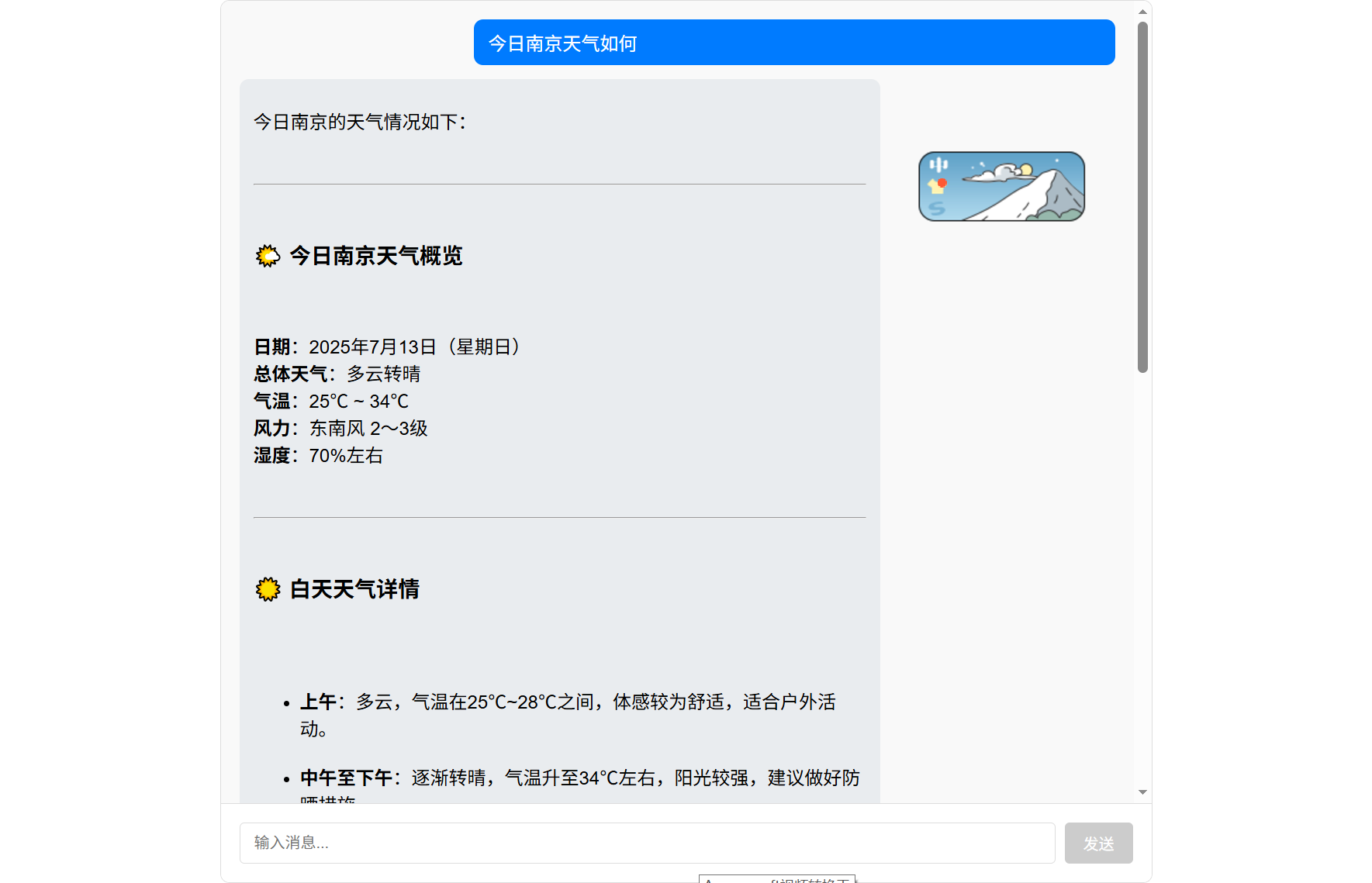
优化建议
- 标题上下间距有点大,建议通过样式穿透重新调整间距大小。
- 渲染方法封装
6 流式输出优化
6.1 Chunk Buffer 机制
在大模型接口开发中,流式输出(Stream)是提升用户体验的核心特性——无需等待完整响应,AI回复可实时逐字呈现,避免长时间加载导致的用户流失。但在实际开发中,很多开发者会遇到这样的问题:流式输出偶尔出现乱码、文字截断、JSON解析失败,甚至部分内容丢失,尤其在切换不同大模型接口时,该问题会更加突出。
此前笔者在基于智谱GLM模型开发聊天助手时,发现智谱接口的流式输出相对规范,此类问题出现概率极低,便忽略了分片处理的细节。但当扩展至DeepSeek、Ollama本地模型、通义千问等其他大模型时,上述问题频繁爆发,最终定位到核心原因:流式响应的分片传输特性,导致单条有效数据被拆分到多个TCP包中,直接解析会出现数据不完整。而解决这一问题的关键,就是引入Chunk Buffer(分片缓存)机制。
1 什么是Chunk Buffer?核心作用是什么?
Chunk Buffer,即分片缓存区,是流式数据处理中用于临时存储、拼接分片数据的核心机制。其本质是一个字符串缓存容器,专门应对HTTP Chunked Transfer Encoding(分块传输编码)的特性——大模型的流式响应会被拆分为多个小分片(Chunk),通过TCP协议逐包传输,单个分片可能无法构成完整的可解析数据(如JSON对象、完整句子)。
Chunk Buffer的核心作用的是“补全不完整分片”,具体可概括为3点:
- 缓存分片:将每次接收到的不完整分片数据,追加到缓存容器中,避免数据丢失;
- 拆分完整数据:按大模型流式响应的格式(通常是换行符\n分隔),拆分缓存中的完整数据行,只处理可解析的完整内容;
- 保留不完整分片:将拆分后剩余的不完整分片,重新放回缓存,等待下一个分片到来后拼接,确保数据完整性。
简单来说,Chunk Buffer就像一个“数据拼图盒”,每次收到的分片是零散的拼图块,先放进盒子里,拼出完整的图案(可解析数据)后再取出使用,未拼完的碎片则留在盒子里,等待下一批碎片补充。
2 为什么需要Chunk Buffer?不同大模型的表现差异
很多开发者会有疑问:“我用的智谱GLM模型,从来没出现过分片问题,为什么还要加Chunk Buffer?” 这其实是不同大模型的接口规范和优化策略不同,导致分片问题的出现概率有差异,但不存在完全不会分片的大模型——因为HTTP分块传输的底层特性,决定了分片是必然存在的,只是是否会影响业务解析。
智谱GLM:低概率分片,仍需兜底。智谱GLM的流式接口做了严格的规范优化,主要体现在两点:一是按“词/短句”拆分分片,单分片基本能构成完整的JSON行(如data: { … }\n);二是国内线路+官方网关优化,减少了TCP粘包、乱序的概率,因此分片导致的解析问题极少出现。
但这并不意味着绝对安全,在以下场景中,智谱也会出现分片截断:
- 长文本输出(超过500字):模型会拆分更多分片,难免出现单个JSON被切分的情况;
- 网络波动或高并发:TCP包传输延迟、丢包重传,可能导致分片乱序、粘包;
- 使用代理/CDN:第三方代理或CDN会对传输数据二次切割,破坏原有分片完整性。
- DeepSeek(R1/V3系列):大量使用超长分片,且强制携带think标签,经常将一个JSON对象拆分为2~3个分片,直接解析会导致JSON.parse报错;
- Ollama本地模型(Llama 3、Qwen、DeepSeek-R1本地版):无官方网关优化,分片粒度混乱,常出现多个data行合并为一个TCP包,拆分后无法直接解析;
- 通义千问、讯飞星火、腾讯混元等国内其他大模型:长文本输出时100%会拆分分片,且部分模型的分片格式不规范,易出现粘包;
- 自建大模型服务(vLLM、Text Generation Inference):底层按token流输出,完全不保证行边界,分片截断是常态。
3 Chunk Buffer实践(基于Vue+TypeScript)
结合大模型流式请求场景(以智谱GLM接口为例),以下是Chunk Buffer的实战代码实现,核心是在流式读取逻辑中加入缓存、拆分、拼接的逻辑,兼容所有大模型接口,且不影响原有业务逻辑。
实现
// 流式请求大模型接口(带Chunk Buffer防截断优化)
async fetchAIStream(aiMsgIdx: number) {
const apiKey = "62e6df10d65d43b09c97bb4d3c340bce.GbVVrNkX2tuuCMn3";
const url = "https://open.bigmodel.cn/api/paas/v4/chat/completions";
try {
// response:接口握手成功的响应头,没有任何完整返回结果。
const response = await fetch(url, {
method: "POST",
headers: {
"Content-Type": "application/json",
Authorization: `Bearer ${apiKey}`,
},
body: JSON.stringify({
model: "glm-4.5-flash",
stream: true,
messages: this.messages
.map((msg) => ({
role: msg.role,
content: msg.content || msg.displayedContent,
}))
.filter((m) => m.role === "user" || m.role === "assistant"),
}),
});
if (!response.ok) {
throw new Error(`HTTP 错误:${response.status} ${response.statusText}`);
}
// reader 是一个 ReadableStreamDefaultReader 类型的对象
// 作用:通过 调用它的 read() 方法 来获取流数据
const reader = response.body?.getReader();
const decoder = new TextDecoder("utf-8");
// 核心:声明Chunk Buffer缓存容器
let buffer = "";
while (true) {
// value 是一段 Uint8Array 二进制数组,元素是UTF-8 字节码
const { done, value } = await reader!.read();
if (done) break;
// 1. 将新接收的分片追加到缓存中(stream: true确保解码不丢失数据)
buffer += decoder.decode(value, { stream: true }); // decoder.decode:Uint8Array 二进制 → 转成字符串
// 2. 按换行符拆分数据,只处理完整行
// lines 数组里的每一项=== 服务端返回的 data: {...} 每一行原始字符串,
// 即 data: {"id":"123","choices":[]}
// data: {"id":"456","choices":[]}
// data: [DONE]
const lines = buffer.split("\n");
// 3. 最后一行可能不完整,放回buffer,等待下一个分片
buffer = lines.pop() || "";
// 处理每一行完整数据
for (const line of lines) {
const trimmed = line.trim();
// 过滤空行和非标准格式行
if (!trimmed || !trimmed.startsWith("data: ")) continue;
// 提取 data: 后面的 JSON 字符串
const data = trimmed.slice(6).trim();
// 处理流式结束标志
if (data === "[DONE]") {
buffer = ""; // 清空缓存,避免残留数据
return;
}
try {
const json = JSON.parse(data);
const content = json.choices[0]?.delta?.content || "";
// 追加AI回复内容,实现流式输出
this.messages[aiMsgIdx].displayedContent += content;
this.$nextTick(() => this.scrollToBottom());
} catch (e) {
console.warn("JSON解析失败(已忽略):", line);
}
}
}
} catch (error) {
console.error("流式请求异常:", error);
this.messages[aiMsgIdx].displayedContent += "\n\n❌ 连接异常,请重试";
}
}
关键实现与细节
// 1. 新二进制片段 → 转字符串 → 拼进缓存
// 拼:把刚收到的一小段文字,接到缓存后面
buffer += decoder.decode(value, { stream: true });
// 2. 按换行切分行 → 得到所有【完整的 data: 行】
// 切:按换行切开,只拿已经完整的行(就是 data: {...})
const lines = buffer.split("\n");
// 3. 最后一行可能不完整 → 塞回缓存等下一段
// 留:最后半截没写完的,留在缓存里不处理,等下一段数据来了继续拼
buffer = lines.pop() || "";
实现细节:
- 缓存初始化:在循环读取分片前,声明空字符串buffer作为缓存容器,确保每次请求的缓存独立,避免交叉污染;
- 分片解码:使用decoder.decode(value, { stream: true }),确保流式解码时不丢失数据,适配不同编码格式;
- 完整行拆分:按换行符\n拆分缓存,将最后一行不完整数据放回buffer,确保每次处理的都是可解析的完整行;
- 异常处理:解析失败时仅警告,不中断整体流式请求,同时清空缓存,避免残留数据影响下一次请求。
4 总结
Chunk Buffer看似是一个简单的缓存逻辑,却是大模型流式开发中“稳定性兜底”的关键,其核心价值在于:屏蔽不同大模型的分片差异,解决流式输出的乱码、截断、解析失败问题,提升接口兼容性和用户体验。
结合实战经验,给出以下最佳实践建议:
- 无论使用哪种大模型,都建议加入Chunk Buffer:即使是分片概率极低的智谱GLM,也能应对网络波动、长文本等极端场景,做到“有备无患”;
- 缓存独立化:每个流式请求单独声明buffer,避免多请求并发时缓存交叉污染;
- 兼容扩展:该实现可直接适配所有遵循SSE(Server-Sent Events)规范的大模型接口,未来切换模型时无需修改核心逻辑;
- 异常兜底:在解析失败、请求中断时,及时清空缓存,避免残留数据导致后续请求异常。
引入Chunk Buffer后,流式输出的稳定性会得到显著提升,无论是单一模型还是多模型兼容场景,都能实现流畅、无异常的实时响应,为用户提供更优质的聊天体验。
6.2 自动滚动跟随
流式输出是提升用户体验的关键特性——它能模拟人类对话的“逐字打字”效果,让AI回复不再是“一次性加载”,而是循序渐进地呈现,降低用户等待焦虑。
但流式输出也会带来一个细节问题:新内容不断刷新时,如何让滚动条既自动跟随最新消息,又不干扰用户查看历史记录?
本节将聚焦流式输出优化中的「智能自动滚动跟随」,结合实际开发场景,拆解实现逻辑、避坑要点,尤其解决大家容易忽略的scrollTop赋值严谨性问题,让你的AI聊天界面更丝滑、更人性化。
1 流式输出的核心痛点:滚动跟随的“两难”
在未做优化的流式输出中,我们通常会在每次获取到AI的分片内容后,强制将滚动条滚到底部,核心代码如下:
// 简单但不严谨的滚动到底部
scrollToBottom() {
const container = this.$refs.messagesContainer as HTMLElement;
if (container) {
container.scrollTop = container.scrollHeight;
}
}
这种写法能实现“自动跟随最新消息”,但存在一个明显的用户体验问题:
- 当用户主动向上滚动查看历史消息时,流式输出的新内容会强制将滚动条拉回底部,打断用户操作,体验极差;
- 只有当用户停留在聊天底部、关注最新消息时,自动滚动才是合理的。
因此,我们需要实现「智能滚动跟随」:用户在底部时,自动跟随最新消息;用户查看历史时,停止自动滚动;用户滚回底部后,恢复跟随。
2 优化实现:智能自动滚动跟随
结合前端开发实践,我们分3步实现优化,同时解决scrollTop赋值不严谨的问题。
1 新增状态变量:判断用户是否在聊天底部
首先,在组件中新增一个状态变量isAtBottom,用于标记用户当前是否停留在聊天容器的底部,默认值为true(初始状态下,用户默认查看最新消息)。
2 监听滚动事件:动态更新底部状态
给聊天消息容器(chat-messages)添加scroll事件监听,通过计算容器滚动距离,判断用户是否在底部。这里的核心逻辑是:当容器底部剩余滚动距离小于30px(可自定义阈值)时,判定用户在底部。
先修改模板中的容器标签,添加scroll监听:
<!-- 聊天消息容器:添加@scroll监听滚动事件 -->
<div class="chat-messages" ref="messagesContainer" @scroll="watchScroll">
<!-- 消息列表 -->
</div>
再实现watchScroll方法,动态更新isAtBottom状态:
// 监听滚动,判断用户是否在底部
watchScroll() {
const container = this.$refs.messagesContainer as HTMLElement;
if (!container) return;
// 关键计算:容器总高度 - 已滚动高度 - 可视高度 = 底部剩余距离
const bottomRemaining = container.scrollHeight - container.scrollTop - container.clientHeight;
// 阈值30px:距离底部小于30px,视为在底部(可根据需求调整)
this.isAtBottom = bottomRemaining < 30;
}
3 优化滚动方法:严谨且智能的滚动逻辑
这一步是核心,我们既要实现“只有在底部才自动滚动”,也要修正scrollTop赋值不严谨的问题——很多开发者会直接写container.scrollTop = container.scrollHeight,但这其实多算了一个可视窗口的高度。
先明确三个核心属性的关系(避免踩坑):
- scrollHeight:聊天容器内所有内容的总高度(含可视和隐藏部分);
- clientHeight:聊天容器的可视高度(用户能直接看到的区域高度);
- scrollTop:容器向上滚动的距离(卷去的高度)。
滚动到底部的严谨公式是:scrollTop = scrollHeight - clientHeight。直接赋值scrollHeight虽然浏览器会自动兜底(类似max-height的限制,自动截断到最大值),但作为严谨的开发,我们更推荐标准写法。
优化后的scrollToBottom方法如下:
// 智能滚动:只有用户在底部时,才自动滚到底部(严谨版)
scrollToBottom() {
const container = this.$refs.messagesContainer as HTMLElement;
if (!container) return;
// 严谨写法:滚动到底部 = 总高度 - 可视高度
const scrollToBottom = container.scrollHeight - container.clientHeight;
// 只有用户在底部(isAtBottom为true),才执行滚动
if (this.isAtBottom) {
container.scrollTop = scrollToBottom;
}
}
#
4 触发滚动:在流式输出关键节点调用
最后,在流式输出的关键节点调用scrollToBottom,确保滚动跟随生效:
- 用户发送消息后,等待DOM更新,滚动到底部;
- AI消息占位添加后,等待DOM更新,滚动到底部;
- AI每输出一段分片内容(流式打字时),等待DOM更新,滚动到底部。
3 优化效果与避坑总结
1 最终优化效果
- 用户停留在聊天底部时,AI流式输出的新内容会自动滚动跟随,始终显示最新消息;
- 用户主动向上滚动查看历史消息时,自动滚动停止,不打断用户操作;
- 用户滚回底部后,自动恢复滚动跟随,无需手动操作。
2 常见避坑点
- scrollTop赋值不严谨:避免直接写container.scrollTop = container.scrollHeight,推荐用scrollHeight - clientHeight,虽然浏览器会兜底,但标准写法更易维护;
- 滚动监听遗漏:必须给chat-messages容器添加@scroll事件,否则无法动态判断用户是否在底部;
- DOM更新时机:滚动操作必须在this.$nextTick中执行,避免DOM未更新导致滚动失效(尤其是流式输出时,分片内容更新后需要等待DOM渲染);
- 阈值设置合理:底部剩余距离的阈值(如30px)可根据实际界面调整,避免阈值过大导致“用户接近底部但未到,却触发自动滚动”。
6.3 think标签适配
项目原本计划通过解析模型返回文本中的 think 特殊标记,拆分标签内思考内容与标签外正式回复内容,以此实现思考区块和正文内容的分离渲染。
随着大模型接口逐步标准化,DeepSeek 等主流模型已摒弃文本内嵌特殊标签包裹思考过程的旧式设计。行业现已统一采用结构化数据分片规范,将思考过程、正式回答、工具调用等信息拆分为独立字段与片段类型,通过专属标识做语义区分,不再把控制逻辑混入普通文本流中。
结合项目实际开发诉求综合评估:模型思考过程本身实现成本低、无实际业务价值,也无前端展示的必要,因此项目决定直接放弃对思考过程的解析与渲染。同时顺势摒弃传统正则匹配标签的老旧解析思路,仅专注识别并渲染业务正文片段。
该调整规避了文本截取、标签容错、流式断片兼容等冗余解析逻辑,大幅简化前端数据处理链路,减少无效代码维护成本;同时贴合当下大模型接口标准化演进趋势,为后续快速兼容接入各类主流大模型预留扩展空间。
6.4 stop机制
1 现状分析
实际使用中经常需要手动终止大模型回复,避免无效等待、节省接口调用,本文基于原组件改造,接入 AbortController 实现一键停止生成,同时保留原有所有能力,适配智谱 GLM 流式接口。
2 核心实现思路
- 借助浏览器原生 AbortController 中断 Fetch 流式请求;
- 模板做发送 / 停止按钮动态切换,流式中禁用输入框;
- 停止后自动保留已输出内容,标记状态为「已停止输出」;
- 区分用户主动停止和接口异常报错,错误提示互不干扰;
- 完全兼容原有 Chunk Buffer 分片解析、Markdown 高亮、智能滚动逻辑。
3 关键改造点解析
- 新增中断控制器实例
abortController: AbortController | null = null;
全局保存控制器实例,用于随时中断当前 fetch 请求。
- 绑定中断信号到 Fetch
this.abortController = new AbortController();
const signal = this.abortController.signal;
// fetch 配置中加入
signal,
浏览器会监听 signal 状态,调用 abort() 后立刻终止网络请求。
- 停止生成方法
stopStreaming() {
if (this.abortController) {
this.abortController.abort();
this.isStreaming = false;
}
}
点击停止按钮触发,直接中断请求、关闭流式状态。
- 异常区分处理
整个逻辑通过错误类型判断 + try/catch/finally 分层处理,把「用户手动停止」和「真实网络/接口报错」完全分开,互不干扰。
在 sendMessage 中捕获流式请求异常:
try {
await this.fetchAIStream(aiMsgIdx);
} catch (error: any) {
// 区分主动停止和业务异常
if (error.name === "AbortError") {
console.log("用户主动停止流式输出");
} else {
console.error("请求出错", error);
this.messages[aiMsgIdx].content = "请求失败,请稍后重试";
}
} finally {
// 无论成功、停止、报错,都会执行收尾
this.messages[aiMsgIdx].streaming = false;
this.messages[aiMsgIdx].content =
this.messages[aiMsgIdx].displayedContent || "已停止输出";
this.isStreaming = false;
this.abortController = null;
}
逻辑说明
-
error.name === "AbortError"
点击停止按钮调用abortController.abort()后,fetch 会抛出该固定类型错误。识别到该错误时,仅打印日志,不弹出错误提示,保留已流式输出的内容。 -
其他类型错误
网络中断、接口 404/500、鉴权失败等非主动中断的异常,统一判定为接口请求异常,给消息赋值错误文案提示用户。 -
finally 统一兜底收尾
无论请求正常结束、用户手动停止、还是接口报错,都会进入finally:关闭流式标记、把临时流式内容固化为最终消息内容、重置流式状态和中断控制器,避免页面按钮卡死、状态错乱。
同时在 fetchAIStream 内部捕获异常时,只对非 AbortError 追加网络异常文案,并且把错误向上抛出,交由外层统一做状态收尾,保证逻辑分层清晰。
- 视图层交互优化
- 流式中输入框禁用,防止重复发送;
- 按钮动态切换:普通状态显示「发送」,流式中显示蓝色「停止」;
- 停止后保留已输出的 Markdown 内容,不清空。
通过原生 AbortController 极低侵入式改造,给 Vue2 + TS 流式聊天组件补上停止生成能力,交互更贴合主流 AI 聊天产品体验。代码完全可直接复用,只需替换自己的 APIKey 和接口地址,即可接入任意兼容 SSE 流式格式的大模型接口。
4 总结
修改前
AI 输出过程中,发送按钮与输入框保持禁用状态,必须等待 AI 输出完成或异常终止后,才能发起新对话;
AI 出现异常时,发送按钮与输入框仍处于禁用状态,仅在 AI 输出异常提示后,输入框才解除禁用。
优化后效果
AI 输出过程中,发送按钮隐藏、输入框禁用,停止按钮正常可点击;
用户主动停止生成时,输入框立即解除禁用,发送按钮恢复显示、停止按钮隐藏;
AI 出现异常时,发送按钮与输入框保持禁用,输出异常提示后,输入框自动解除禁用。
7 自动重登
7.1 前提
自动重登机制,前提一定是「有账号体系、有登录态」的平台。
为什么只有带账号的 AI 聊天助手才需要
- 游客模式 / 匿名聊天没有账号、没登录态、没 token,根本不存在 “登录过期”,自然不需要自动重登。
- 有账号登录的场景
- 登录靠:登录 Token / RefreshToken / Session
- Token 会过期、异地踢下线、缓存失效、App 重启、进程被杀
- 这时候就需要:检测登录态失效 → 自动用刷新令牌 / 静默登录 → 重新拿到有效会话,就是自动重登机制
一句话总结
- 无账号 = 无登录态 = 不用自动重登;
- 有账号 + 登录态会过期 = 才要做自动重登、静默续登机制。
7.2 说明
自动重登 ≠ 自己做一套账号注册/登录页面
而是: AI 聊天组件 嵌入在「已有完整账号登录体系」的主系统里
比如:
- 后台管理系统
- 官网会员系统
- App 内嵌 H5
- 企业内部系统
这些主系统本身就有:登录、注册、记住登录态、Token 过期。
1 AI 聊天助手的定位
它只是一个纯业务子组件:
- 不做登录页面
- 不做注册
- 不存用户账号密码
- 只管复用主系统的登录态 / Token
2 自动重登的真实含义
不是 AI 自己登录,而是:
- AI 发请求 → 后端返回 401 Token 过期
- AI 组件调用主系统提供的静默登录/刷新 Token 方法
- 拿到新 Token → 重新发起聊天请求
- 用户全程无感知
本质:复用宿主系统的登录能力,AI 只做被动跟随。
3 对比
- 如果是独立版 AI 网页:必须自己做登录、注册、页面、表单、存账号
- 现在这种内嵌版 AI 聊天:完全不需要登录界面,只做静默重登、续Token
4 总结
现在做的这套自动重登,就是给「嵌入在已有登录系统里的AI聊天组件」用的,它本身不负责账号登录注册,只跟着宿主系统的登录态走,过期了就静默刷新。
7.3 自动重登
1 场景说明
本 AI 聊天助手嵌入在外部宿主系统中,自身无登录 / 注册页面,仅通过 ApiKey 进行接口鉴权。
当接口返回 401 授权失效时,需实现:
- 全局静默自动重登(刷新 ApiKey)
- 请求队列缓存,避免并发请求重复触发重登
- 重登成功后自动补发所有失效请求,用户无感知
- 业务层(聊天组件)无感知,不侵入原有逻辑
2 架构设计
- 公共请求层统一封装:所有流式请求走统一入口
- 重登锁:保证全局同一时间只执行一次重登
- 请求队列:登录失效期间的请求全部入队等待
- 补发机制:重登成功后批量执行队列请求
- 业务解耦:聊天组件只负责发送消息,不关心重登逻辑
3 核心代码实现
- 公共请求层:utils/request.ts
统一处理流式请求、401 拦截、自动重登、请求队列。
/**
* 公共流式请求 + 自动重登 + 请求队列
*/
let isRelogin = false; // 重登锁:防止并发重登
const waitRequestQueue: (() => Promise<any>)[] = []; // 失效请求队列
// 获取 AI 接口 ApiKey
export function getApiKey() {
return "你的api key";
}
// 静默重登:对接宿主系统刷新 ApiKey
export async function autoReLogin(): Promise<boolean> {
try {
// 实际业务:调用宿主系统方法获取最新 ApiKey
await new Promise((resolve) => setTimeout(resolve, 600));
console.log("✅ 自动重登(刷新ApiKey)成功");
return true;
} catch (err) {
console.error("❌ 自动重登失败");
return false;
}
}
// 执行队列:重登成功后补发所有请求
async function runWaitQueue() {
while (waitRequestQueue.length) {
const task = waitRequestQueue.shift();
if (task) await task();
}
}
// 流式请求封装
interface FetchStreamOptions {
url: string;
method?: "GET" | "POST";
body?: any;
signal?: AbortSignal;
}
export async function fetchStream(options: FetchStreamOptions): Promise<Response> {
const { url, method = "POST", body, signal } = options;
const apiKey = getApiKey();
// 封装请求体,支持重试
const doRequest = () =>
fetch(url, {
method,
headers: {
"Content-Type": "application/json",
Authorization: `Bearer ${apiKey}`,
},
body: body ? JSON.stringify(body) : undefined,
signal,
});
// 第一次请求
let response = await doRequest();
if (response.status !== 401) return response;
// ========== 401 登录失效处理 ==========
if (isRelogin) {
// 正在重登 → 当前请求入队等待
return new Promise((resolve) => {
waitRequestQueue.push(async () => {
resolve(await doRequest());
});
});
}
// 未重登 → 加锁并执行重登
isRelogin = true;
try {
const loginSuccess = await autoReLogin();
if (!loginSuccess) {
waitRequestQueue.length = 0;
throw new Error("登录已过期,请重新登录");
}
// 重登成功 → 补发队列 + 重试当前请求
await runWaitQueue();
return await doRequest();
} finally {
isRelogin = false; // 释放锁
}
}
- 业务组件使用(AI 聊天页面)
原有代码完全不动,仅替换请求发起方式(原请求方法替换为公共方法里的请求方法)
4 核心流程说明
- 正常请求:直接发起,返回 200 正常响应
- 401 失效:触发重登机制
- 重登加锁:同一时间只允许一次重登
- 请求入队:其他并发失效请求进入队列等待
- 重登成功:按顺序补发所有队列请求
- 重登失败:清空队列,抛出异常提示用户
5 优势总结
- ✅ 无侵入:不修改原有聊天逻辑、注释、结构
- ✅ 全局唯一重登:避免接口风暴、重复刷新
- ✅ 请求排队补发:用户完全无感知
- ✅ 业务解耦:公共层处理重登,组件只关心业务
- ✅ 适配嵌入场景:无登录页面,支持静默刷新 ApiKey
由于本地开发环境无法真实模拟 Token 登录过期、后端 401 状态码返回等真实业务场景,当前 401 自动重登 + 请求队列防抖逻辑仅为理想化架构实现,仅完成流程框架与并发防锁、请求排队的逻辑封装,暂不具备线上直接可用的真实业务落地能力,需后续对接真实后端刷新 Token 接口、联调过期响应机制后,才可投入实际业务使用。
核心知识点总结:401重登队列中 Promise + 箭头函数 原理复盘
1 整体场景
接口返回401鉴权失效,为避免并发请求重复触发多次重登,做两层控制:
- 重登锁
isRelogin:同一时间只允许执行一次全局重登 - 请求队列
waitRequestQueue:重登进行中时,后续401请求先排队,重登成功后批量补发
2 部分核心代码块
if (isRelogin) {
return new Promise((resolve) => {
waitRequestQueue.push(async () => {
resolve(await doRequest());
});
});
}
3 逐点拆解关键理解
-
为什么要
return new PromisefetchStream是async函数,外部都是通过await fetchStream()调用,必须等待返回响应结果才能继续后续逻辑。- 当前正在重登中,不能立刻发起请求、也不能直接
return结束函数。 new Promise作用:把当前请求挂起、暂停流程,不执行 resolve 就一直卡住外部的await,实现排队等待效果。
-
为什么不能直接
push(doRequest)doRequest只是单纯发起请求的方法,只会发请求,没有能力把结果返回给最外层fetchStream的调用方。- 直接推入队列,请求重试后,没人把响应结果
resolve回去,外部await会一直卡死,程序报错、流式中断。
-
为什么队列里要包一层「箭头函数」
- 需要把逻辑延后执行:不是现在立刻发请求,而是等重登完成、执行队列时再执行。
- 只有封装成函数,才能先存入队列做占位,后续按需调用。
-
resolve(await doRequest())核心作用await doRequest():重登成功后,重新发起接口请求,拿到最新响应。resolve(响应):把重试拿到的结果,返回给最外层fetchStream的 Promise,让外部await fetchStream()正常拿到响应,继续走后续流式解析逻辑。
4 完整执行流程
- 并发请求碰到401,且
isRelogin = true(正在重登); - 返回一个 pending 状态的 Promise,挂起外部 await 流程;
- 往队列存入一个
async 箭头函数(延后执行任务); - 全局重登完成后,执行
runWaitQueue遍历队列; - 执行队列里的箭头函数:重发请求 + resolve 结果;
- 外部 await 拿到响应,继续正常业务逻辑。
5 一句话极简概括
用 new Promise 挂起当前请求,用async箭头函数包装重试逻辑存入队列,既延后执行请求,又能把重试结果通过 resolve 还给最外层调用方,完美实现请求排队+重登补发。
8 统一错误处理
8.1 优化背景与起因
当前 AI 聊天助手项目中同时存在两类请求方式:
- 流式对话接口使用原生 Fetch 实现 SSE 流式通信;
- 项目其他业务接口使用 Axios 发起常规请求。
原生 Fetch 和 Axios 错误触发机制、错误对象结构完全不一致,若不做统一封装,业务层需要维护两套错误判断逻辑,维护成本高、冗余度大、极易出错,核心差异如下:
1 错误触发机制差异
-
Axios
只要接口返回非2xx状态码(401、403、404、500 等)、网络断开、请求取消,都会直接进入 catch 异常捕获。 -
原生 Fetch
只有断网、跨域、请求终止这类网络层面异常才会进入 catch;
接口返回 401/404/500 等 HTTP 业务错误,依然走正常业务流程,不会抛异常,必须手动通过!res.ok判断状态码。
2 错误对象结构差异
-
Axios 错误结构
固定包含response对象,可直接获取状态码、错误信息、后端返回数据:err.response.status // 状态码 err.response.statusText // 错误文案 err.response.data // 后端响应体 -
原生 Fetch 错误结构
无统一response结构,HTTP 错误不会进入异常;请求取消、网络错误的字段标识也和 Axios 完全不同:- 请求取消:
err.name === 'AbortError' - 网络异常:只能原始捕获,无统一状态码字段
- 请求取消:
3 请求取消标识差异
- Axios 取消请求:识别
CanceledError - Fetch 取消请求:识别
AbortError
两套请求、三套异常判断规则,若不统一,业务 catch 中需要大量兼容判断,代码臃肿、难以维护。
8.2 优化目标
- 封装自定义统一错误类,对齐 Axios 错误结构;
- 改造 Fetch 流式请求,手动捕获 HTTP 错误、网络错误、取消请求,统一抛出自定义错误;
- Axios 配置拦截器,将原生错误转为同格式自定义错误;
- 复用已有 401 重登锁、请求队列逻辑,让 Fetch 和 Axios 共用一套重登与排队机制;
- 业务层无需区分请求方式,
catch中一套代码兼容所有错误场景。
8.3 核心代码实现
1 定义统一错误类
class RequestError extends Error {
public response: {
status: number;
statusText: string;
data: any;
};
constructor(message: string, status = 0, data?: any) {
super(message);
this.response = {
status,
statusText: message,
data: data || null,
};
}
}
2 Fetch 层错误统一封装
在原有流式请求 doRequest 内部增加异常捕获与手动状态判断,将 HTTP 非 2xx、网络异常、请求终止全部转为 RequestError:
const doRequest = async (): Promise<Response> => {
try {
const res = await fetch(url, {
method,
headers: {
"Content-Type": "application/json",
Authorization: `Bearer ${apiKey}`,
},
body: body ? JSON.stringify(body) : undefined,
signal,
});
// Fetch 特有:非2xx手动抛错
if (!res.ok) {
throw new RequestError(res.statusText || "请求失败", res.st
atus);
}
return res;
} catch (err: any) {
// 请求取消
if (err.name === "AbortError") {
throw new RequestError("请求已取消", -1);
}
// 已自定义错误直接透出
if (err instanceof RequestError) {
throw err;
}
// 网络异常兜底
throw new RequestError("网络异常,请检查连接", 0);
}
};
3 Axios 拦截器统一适配并复用重登队列
新增 Axios 实例、请求/响应拦截器,统一注入鉴权头、格式化错误、401 复用同一套重登锁与请求队列:
import axios from "axios";
const axiosInstance = axios.create({
timeout: 15000,
});
// 请求拦截器统一携带 ApiKey
axiosInstance.interceptors.request.use((config) => {
const apiKey = getApiKey();
if (apiKey) {
config.headers.Authorization = `Bearer ${apiKey}`;
}
return config;
});
// 响应拦截器:统一错误格式 + 401 共用重登队列
axiosInstance.interceptors.response.use(
(res) => res,
(err) => {
// 网络无响应
if (!err.response) {
return Promise.reject(new RequestError("网络异常,请检查连接", 0));
}
const status = err.response.status;
const msg = err.message || "请求失败";
// 401 复用全局重登锁和队列
if (status === 401) {
if (isRelogin) {
return new Promise((resolve, reject) => {
waitRequestQueue.push(async () => {
try {
resolve(axiosInstance(err.config));
} catch (e) {
reject(e);
}
});
});
}
isRelogin = true;
return autoReLogin().then((success) => {
if (!success) {
waitRequestQueue.length = 0;
return Promise.reject(new RequestError("登录已失效", 401));
}
return runWaitQueue().then(() => axiosInstance(err.config));
}).finally(() => {
isRelogin = false;
});
}
// 其他状态统一转为自定义错误
return Promise.reject(new RequestError(msg, status, err.response?.data));
}
);
export const http = axiosInstance;
8.4 优化效果
- 错误结构统一:无论
Fetch还是Axios,业务捕获后均可通过err.response.status获取状态码; - 异常场景统一:网络异常、请求取消、401/500 等 HTTP 错误,标识规则完全一致;
- 重登逻辑复用:两套请求共用同一把重登锁、同一个请求队列,避免并发重复刷新鉴权;
- 业务层极简:无需区分请求方式,一套错误判断逻辑全覆盖,可维护性大幅提升。
8.5 业务层统一使用示例
统一错误封装后,fetchStream 流式请求与 http(axios)普通请求的错误结构保持一致。
但由于流式读取阶段的取消操作不会经过封装层,仍会抛出浏览器原生 AbortError,因此业务层必须同时判断两种取消方式,才能保证 “停止输出” 功能不被误判为异常。
- 统一错误判断逻辑
const isStopByUser =
err.name === "AbortError" || // 原生错误:流式读取中断(用户停止)
err.response?.status === -1; // 封装错误:普通请求取消(fetch/axios)
- Chat.vue sendMessage 和 fetchAIStream 必须同步修改
9 项目要点总结
-
核心原则:UI与数据分离,messages数组仅存储消息状态,不耦合渲染逻辑
-
流式核心:通过增量更新displayedContent模拟打字机效果,实现优雅的流式体验
-
交互规范:输入锁定、自动滚动、样式统一,保证用户体验一致
-
可扩展性:前端结构与后端解耦,后续替换真实API无需修改前端核心代码
-
适用场景:聊天交互、文案生成、关键进度可视化等需要流式输出的场景
10 迭代优化方向
-
功能拓展
-
新增表情、图片发送功能,丰富消息展示形式
-
拆分核心子组件(ChatMessage、ChatInput),提升组件复用性
-
抽取可复用打字机组件,单独封装为src/components/TypingMessage.vue
-
-
体验优化
-
添加加载动画、错误提示,提升异常场景体验
-
优化打字机效果,采用分块渲染(每句独立显示),搭配动态光标
-
完善异常处理,添加try/catch捕获接口报错,支持重试功能
-
-
性能优化
-
针对大量历史消息渲染优化,避免页面卡顿
-
取消全局isStreaming锁,改为消息级独立状态,支持多消息并行流式输出
-
优化渲染逻辑,减少DOM重绘与回流
-
-
规范优化
-
配合Vite/Vue CLI,统一代码规范,避免语法冲突
-
完善项目注释,提升代码可读性与可维护性
-

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)