Windows 安装 Ollama 全教程:本地部署大模型并跑通第一个 AI 对话

现在在 Windows 上跑本地大模型,已经没有以前那么“重工业”了。
如果你的目标不是自己编译推理框架,而是先把模型跑起来、先能本地对话、先能调接口,那 Ollama 是一条很适合入门的路线。
这篇文章就按最常见的 Windows 场景来,带你把安装、模型下载、命令行验证和 API 调用完整走一遍,先把第一个闭环跑通。
一、项目背景
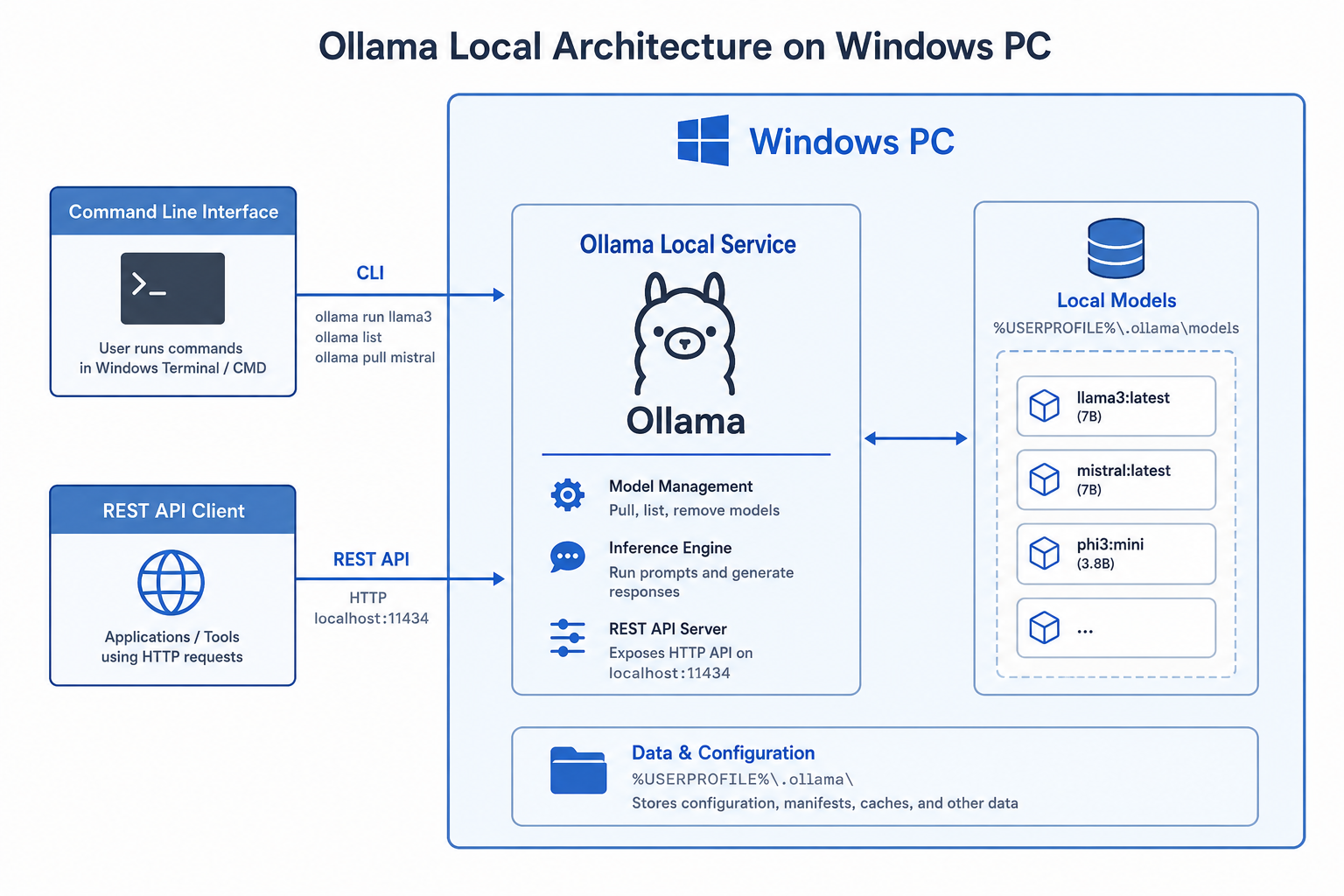
Ollama 是一个用于本地运行和管理大语言模型的开源工具。它的定位很清楚:尽量降低本地 LLM 的使用门槛,让开发者能用更简单的方式完成模型下载、启动、对话和接口调用。
对于普通开发者来说,Ollama 的价值主要体现在这几个方面:
- 可以在本机直接运行常见大模型
- 提供统一的命令行体验
- 内置本地 HTTP API,便于程序接入
- 适合和 Open WebUI、AnythingLLM 等工具联动
- 适合作为本地 AI 工具链的入口
很多人第一次接触本地大模型,容易把精力都花在环境复杂度上,比如显卡驱动、推理框架、依赖版本、模型格式兼容。但如果你的目标只是先跑通一个可用的本地模型服务,Ollama 明显更省心一些。
官方GitHub的项目地址:
https://github.com/ollama/ollama
如果你只是想快速体验本地大模型,或者准备把模型接进自己的应用、脚本、知识库系统里,那 Ollama 很适合作为第一站。
二、本文环境说明
本文采用的是Windows 本地安装方案,以“先跑通”为核心目标,不追求一步到位搞生产环境。
运行环境
- 操作系统:Windows 10 / Windows 11
- 部署方式:官方安装包本地安装
- 终端工具:PowerShell
- 验证方式:
- 命令行对话
- 本地 REST API 调用
- 默认服务地址:
http://localhost:11434
模型建议
为了提高首次安装成功率,本文建议优先使用小模型,比如:
gemma3:1bllama3.2:1b
原因很简单:
- 下载更快
- 占用更低
- 更容易验证
- 对内存和磁盘更友好
硬件建议
结合官方 README 的说明,可大致参考:
- 7B 模型:建议至少 8GB 内存
- 13B 模型:建议至少 16GB 内存
- 33B 模型:建议至少 32GB 内存
如果你只是跟着教程做验证,建议不要一开始就上大模型。
先把小模型跑通,这一步远比“模型参数大不大”更重要。
说明
本文属于便于快速上手的简化路径。
如果你后续需要:
- 更强 GPU 性能
- 多模型管理
- 生产环境部署
- 与 Web UI 深度集成
建议再结合官方文档做扩展配置。
三、安装前准备
正式安装前,先做几项基础检查,避免后面遇到问题时一头雾水。
1. 检查系统版本
按下 Win + R,输入:
winver
确认系统是较新的 Windows 10 或 Windows 11。
如果系统版本过老,很多桌面工具的兼容性都会变差,别把时间浪费在不必要的系统坑里。
2. 检查磁盘空间
Ollama 本体不算大,但模型文件会占用比较明显的空间。
建议至少预留几 GB 以上磁盘空间,尤其是你准备拉多个模型时。
如果只是做首次验证,用 1B 小模型压力不大,但也不要让系统盘只剩几百 MB 再来装本地 AI 工具。
你可以在“此电脑”里直接查看各盘剩余空间。
3. 检查内存是否足够
虽然 Ollama 支持本地运行模型,但运行体验很大程度上取决于机器资源。
如果你的机器本身只有较低内存,又开着一堆浏览器和 IDE,大模型跑起来慢是很正常的,不是项目跟你过不去。
首次验证建议:
- 尽量关闭高占用后台程序
- 选择 1B 小模型
- 不要同时开太多重型软件
4. 准备 PowerShell
本文演示命令默认使用 PowerShell。
打开方式:
- 开始菜单搜索
PowerShell - 建议右键选择“以管理员身份运行”
严格来说,不是每一步都必须管理员权限,但在安装阶段这样做通常更稳。
四、安装与部署
这一部分是全文核心:在 Windows 上安装 Ollama,并确认服务可正常运行。
1. 下载 Windows 安装包
Windows 下推荐直接使用官方安装入口。
可参考以下地址:
- GitHub 仓库:
https://github.com/ollama/ollama - 官方网站:
https://ollama.com
进入官网后,下载 Windows 版安装包并执行安装。
2. 执行安装
双击安装包,按提示完成安装即可。
Windows 下这一步通常比较直接,属于标准桌面软件安装流程。
安装完成后,Ollama 一般会完成这些动作:
- 安装本地程序
- 注册可执行命令
- 启动本地服务
- 默认开放本地 API:
localhost:11434
3. 检查命令是否生效
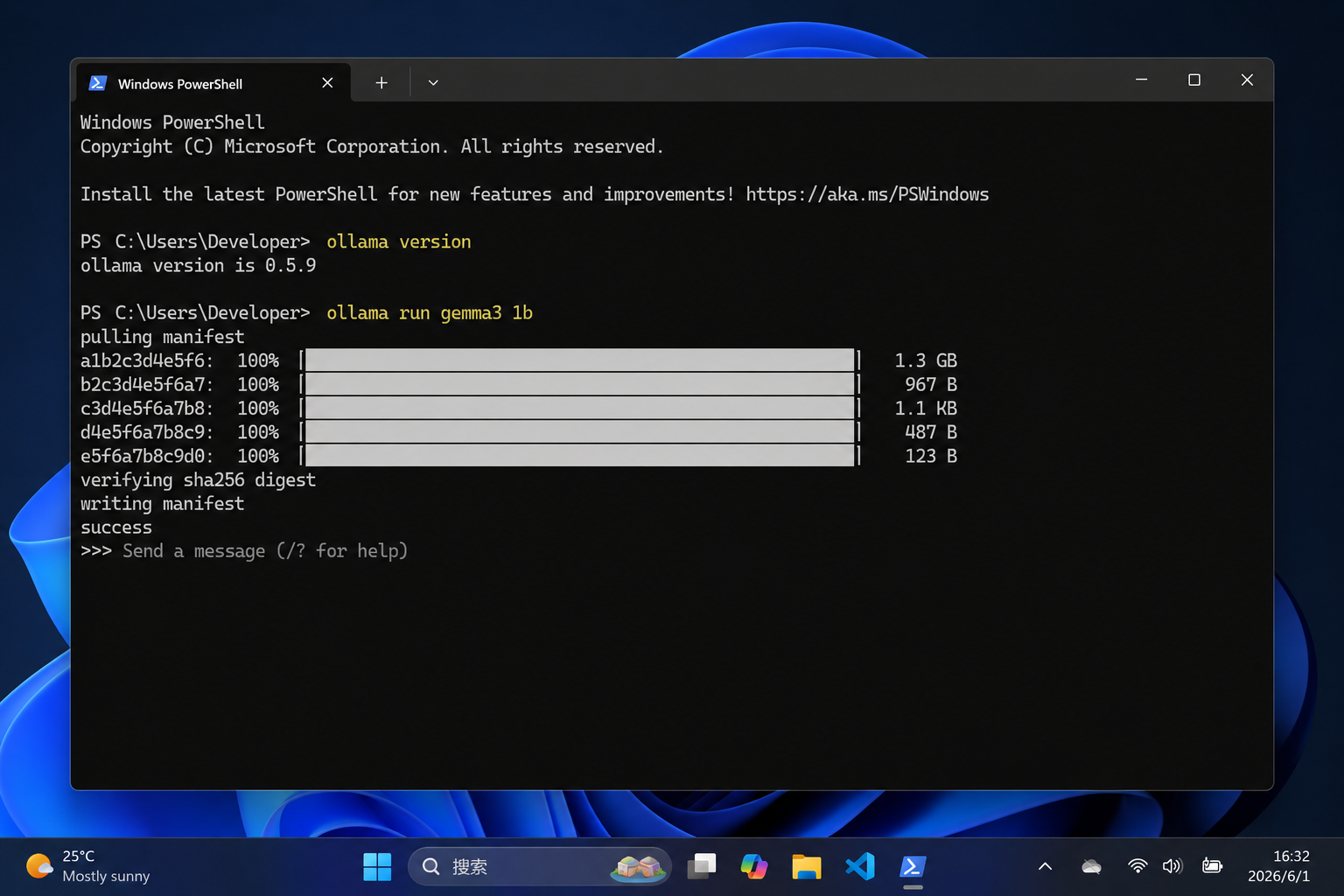
安装完成后,重新打开一个新的 PowerShell 窗口,执行:
ollama --version
如果能输出版本信息,说明 Ollama 已经安装成功。
如果这里提示找不到命令,先别急,后面的“常见报错与解决方案”里会专门处理。
4. 检查 Ollama 是否可正常响应
执行:
ollama list
如果命令能正常执行,说明基本环境已经打通。
此时如果你本地还没有模型,列表可能为空,这是正常的。
因为安装 Ollama 不等于自动安装模型,模型需要单独拉取。
5. 第一次拉取模型
为了降低第一次失败的概率,建议先拉小模型。
执行:
ollama run gemma3:1b
或者:
ollama run llama3.2:1b
首次运行时,Ollama 会自动:
- 检查本地是否已有该模型
- 如果没有,则开始下载
- 下载完成后启动模型
- 进入交互式对话界面
这一步其实就是 Ollama 最核心的体验:
一个命令,把模型下载和运行串起来。
五、配置说明
Ollama 的优点之一就是快速上手不需要复杂配置。
不过有几个点,建议你在开始前理解清楚。
1. 默认 API 地址
Ollama 默认提供本地接口地址:
http://localhost:11434
后面无论你是用 PowerShell 测试,还是用 Python、Node.js 接入,本质上都是调这个服务。
2. 模型和程序是分开的
这是新手最容易误解的一点:
- 安装的是 Ollama 工具
- 下载的是 具体模型
- 运行时调用的是 本地 Ollama 服务
也就是说,你看到 ollama --version 能执行,不代表模型已经准备好了。
例如:
ollama run gemma3:1b
第一次执行时,才会真正开始拉取模型。
3. 常用命令
查看本地已有模型:
ollama list
查看正在运行的模型:
ollama ps
查看模型详情:
ollama show gemma3:1b
停止模型:
ollama stop gemma3:1b
删除模型:
ollama rm gemma3:1b
如果你打算后续长期使用 Ollama,这几个命令基本都绕不开。
4. 自定义模型能力
根据官方 README,Ollama 支持通过 Modelfile 对模型进行轻量封装。
例如:
FROM llama3.2
PARAMETER temperature 1
SYSTEM """
You are a helpful assistant.
"""
然后执行:
ollama create mymodel -f .\Modelfile
ollama run mymodel
这类能力更适合后续做:
- 固定系统提示词
- 企业内部助手
- 角色型问答助手
- 特定场景模型封装
本文先不深入展开,知道这个入口就够了。
六、跑通第一个 Demo
接下来开始做最关键的事情:把第一个可用闭环跑通。
Demo 1:命令行对话
执行:
ollama run gemma3:1b
如果你使用的是另一个小模型,也可以替换模型名。
首次运行时,你应该会看到:
- 模型下载进度
- 下载完成后的启动过程
- 进入交互式终端界面
然后输入一句测试内容,例如:
你好,请用一句话介绍你自己
成功现象
如果这一步成功,你应该能看到模型返回文本回复。
这说明下面几件事都已经成立:
- Ollama 程序安装成功
- 模型下载成功
- 模型可正常运行
- 本地推理链路已打通
这一步是整个教程里最重要的验证点。
Demo 2:查看模型是否已经落地
打开另一个 PowerShell 窗口,执行:
ollama list
如果你能看到类似 gemma3:1b 的模型名称、大小和更新时间,说明模型已经成功保存到本机。
Demo 3:测试 /api/generate 接口
根据官方 README,Ollama 提供本地生成接口。
在 PowerShell 中可以这样测试:
curl http://localhost:11434/api/generate -Method Post -Body '{
"model": "gemma3:1b",
"prompt": "请用中文解释一下 Ollama 是什么"
}' -ContentType "application/json"
如果你本地实际运行的是 llama3.2:1b,把模型名换成对应值即可。
Demo 4:测试 /api/chat 接口
继续测试聊天接口:
curl http://localhost:11434/api/chat -Method Post -Body '{
"model": "gemma3:1b",
"messages": [
{ "role": "user", "content": "你好,请简要介绍一下 Windows 上的 Ollama" }
]
}' -ContentType "application/json"
这个接口更适合后续做聊天机器人、桌面助手或者接 Web 前端。
七、效果验证

部署成功不能只看“好像装上了”,最好从几个角度都确认一下。
1. 命令行验证
执行:
ollama --version
ollama list
如果命令可正常输出,说明 CLI 工具已经安装到位。
2. 模型运行验证
执行:
ollama run gemma3:1b
输入问题并拿到回复,说明本地推理能力可用。
3. API 服务验证
执行:
curl http://localhost:11434/api/generate -Method Post -Body '{
"model": "gemma3:1b",
"prompt": "请返回一句:接口调用成功"
}' -ContentType "application/json"
如果接口返回生成内容,说明本地服务已经可以被程序调用。
4. 什么现象说明部署成功?
满足下面几点,基本就可以认为 Ollama 已成功部署:
ollama --version正常输出ollama list可执行- 至少一个模型已成功下载
ollama run 模型名能正常对话- 本地 API 能返回结果
如果这些都通过了,后续你接 Python、Node.js、RAG 工具,思路就很清晰了。
八、常见报错与解决方案
这一节建议认真看。
Windows 下很多问题,并不是 Ollama 本身坏了,而是路径、网络、权限、终端行为或者机器资源在捣乱。
1. 报错:ollama 不是内部或外部命令
原因
最常见的原因有:
- 安装后当前终端没有刷新
- PATH 尚未生效
- 安装过程异常中断
解决方案
按下面顺序处理:
- 关闭当前 PowerShell / CMD
- 重新打开终端
- 再执行:
ollama --version
如果还是不行,可以:
- 重启电脑
- 重新安装 Ollama
- 检查安装目录是否存在
Windows 下这类问题,很多时候不是技术难题,就是终端环境没刷新,别一上来就怀疑自己系统崩了。
2. 模型下载失败或速度很慢
原因
通常是:
- 网络不稳定
- 模型体积较大
- 磁盘空间不足
- 本地安全软件拦截下载过程
解决方案
优先做这几件事:
- 换成小模型先验证
- 检查磁盘空间
- 确认网络可正常访问
- 关闭可能拦截下载的安全软件或代理干扰
建议先执行:
ollama run gemma3:1b
把链路先跑通,比执着某个大模型更重要。
3. 模型运行很慢、响应卡顿
原因
最常见的原因就是四个字:资源不够。
具体可能包括:
- 内存不足
- 没有可用 GPU
- 模型选太大
- 后台程序占用过高
解决方案
建议直接从这几点入手:
- 换小模型
- 关闭浏览器、IDE、视频软件等高占用程序
- 不要同时跑多个大任务
- 优先验证可用性,再考虑性能优化
例如:
ollama run llama3.2:1b
如果你的机器本来就偏轻薄本路线,那就别强行拿大模型硬顶。先跑通,是最务实的策略。
4. API 调用失败,提示连接不上
原因
一般集中在以下几个方向:
- Ollama 服务没有启动
- 模型还没下载完成
- 端口未正常响应
- 本地防火墙或安全软件拦截
解决方案
先执行:
ollama list
再尝试直接运行模型:
ollama run gemma3:1b
确保模型可正常进入交互后,再测试 API:
curl http://localhost:11434/api/generate -Method Post -Body '{
"model": "gemma3:1b",
"prompt": "测试接口"
}' -ContentType "application/json"
排查顺序一定要对:
先确认 Ollama 能跑,再确认模型能跑,最后再看 API。
5. PowerShell 里的 curl 用得别扭
原因
Windows PowerShell 里的 curl 和 Linux/macOS 上的体验不完全一致,尤其在 JSON 参数传递上,经常会让人感觉“命令看着没问题,结果就是不顺”。
解决方案
除了继续用 curl,也可以直接用 PowerShell 原生方式:
Invoke-RestMethod -Uri "http://localhost:11434/api/generate" `
-Method Post `
-ContentType "application/json" `
-Body '{
"model": "gemma3:1b",
"prompt": "hello"
}'
如果你长期在 Windows 做接口联调,Invoke-RestMethod 往往更稳。
6. 安装完成后 ollama list 为空
原因
这不是报错,很多时候只是你还没拉模型。
解决方案
执行:
ollama run gemma3:1b
或者:
ollama pull gemma3:1b
然后再次查看:
ollama list
记住一个原则:
装好了 Ollama,不等于模型已经在本机。
7. 怀疑 GPU 没生效
原因
这类问题通常和显卡驱动、系统兼容性、设备状态有关,不完全是 Ollama 一层能解决的。
解决方案
先确认你的系统本身显卡状态正常:
- 驱动已正确安装
- 设备管理器无异常
- 显卡工具可正常识别硬件
如果你只是首次安装,建议先别把精力都耗在 GPU 优化上。
先跑通 CPU 路线,再去研究显卡加速,节奏会更合理。
九、进阶说明
如果你已经顺利完成安装和基础验证,后面可以从下面几个方向继续深入。
1. 联动 Open WebUI
这是很多人后续最常见的选择:
- Ollama 负责本地模型服务
- Open WebUI 负责提供图形化对话界面
适合想搭一个“本地版 ChatGPT”体验的人。
2. 接入自己的应用程序
Ollama 提供本地 HTTP API,你可以直接接入:
- Python 脚本
- Node.js 服务
- Java 后端
- 桌面客户端
- 本地知识库 / RAG 应用
如果你只是想做一个“可调用的本地大模型服务”,这一点已经够用了。
3. 使用 Modelfile 做简单定制
适合做:
- 固定系统提示词
- 专用问答助手
- 角色助手
- 企业内部语料封装
这一步很适合从“能用”走向“更贴业务”。
4. 导入 GGUF 模型
根据官方 README,Ollama 还支持通过 Modelfile 导入本地 GGUF 模型。
如果你后面打算用更灵活的模型来源,这条路线值得研究。
十、总结
Ollama 之所以适合入门,不是因为它把所有复杂问题都消灭了,而是因为它把最关键的第一步尽量做简单了。
这篇文章我们完整做了几件事:
- 在 Windows 上安装 Ollama
- 检查命令行环境是否正常
- 拉取并运行一个小模型
- 跑通第一次命令行对话
- 验证本地 REST API
- 排查常见的命令、网络和资源问题
对于大多数开发者来说,做到这一步已经够用了。
因为本地大模型这件事,真正重要的不是一次性把全家桶装满,而是先确认:你的机器能跑、你的接口能调、你的链路是通的。
一句话总结就是:
先把 Ollama 跑通,本地 AI 工具链才算真正有了起点。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 6
6 0
0- 0



 已为社区贡献36条内容
已为社区贡献36条内容

所有评论(0)