【腾讯位置服务开发者征文大赛】 AI 帮你选对址:WorkBuddy + 腾讯位置服务,把选址报告变成可交互的智能助手
【腾讯位置服务开发者征文大赛】 AI 帮你选对址:WorkBuddy + 腾讯位置服务,把选址报告变成可交互的智能助手
前言
你有没有试过让 AI 帮你选址?输入一句话,它给你生成一个页面——看起来挺酷,但每次生成的结构都不一样,数据也没法复用,demo 感很强,离真正能用还差得远。
这次参加腾讯位置服务的 AI+地图征文,我最开始其实想做得更"炸"一点。
比如 3D 园区、地图大屏、建筑模型叠加、热力图动画,甚至把地图和三维城市一起拉起来,做成一个一眼就炫酷的 Demo。但真正开始推进后,我还是把方案收回来了。
原因很简单,比赛时间有限,主线越清楚,作品越容易做成;主线一旦散掉,最后就很容易变成"功能不少,但每个都只做了一半"。所以我最后定下来的方向是:
把选址分析过程封装成一个 Skill / 工作流,让 WorkBuddy 负责任务编排和本地 JSON 写入,前端只负责读取这份 JSON 并渲染成分析报告。
下面我搭配了视频解说,演示了完整的用户流程:
用户提需求 -> WorkBuddy 编排选址流程 -> 腾讯地图 Skills 提供能力 -> 生成结构化 JSON -> 前端自动渲染成报告。
腾讯地图AI选址助手
这篇文章就围绕这个演示视频展开。
一、AI 生成地图卡片的痛点与场景化选择
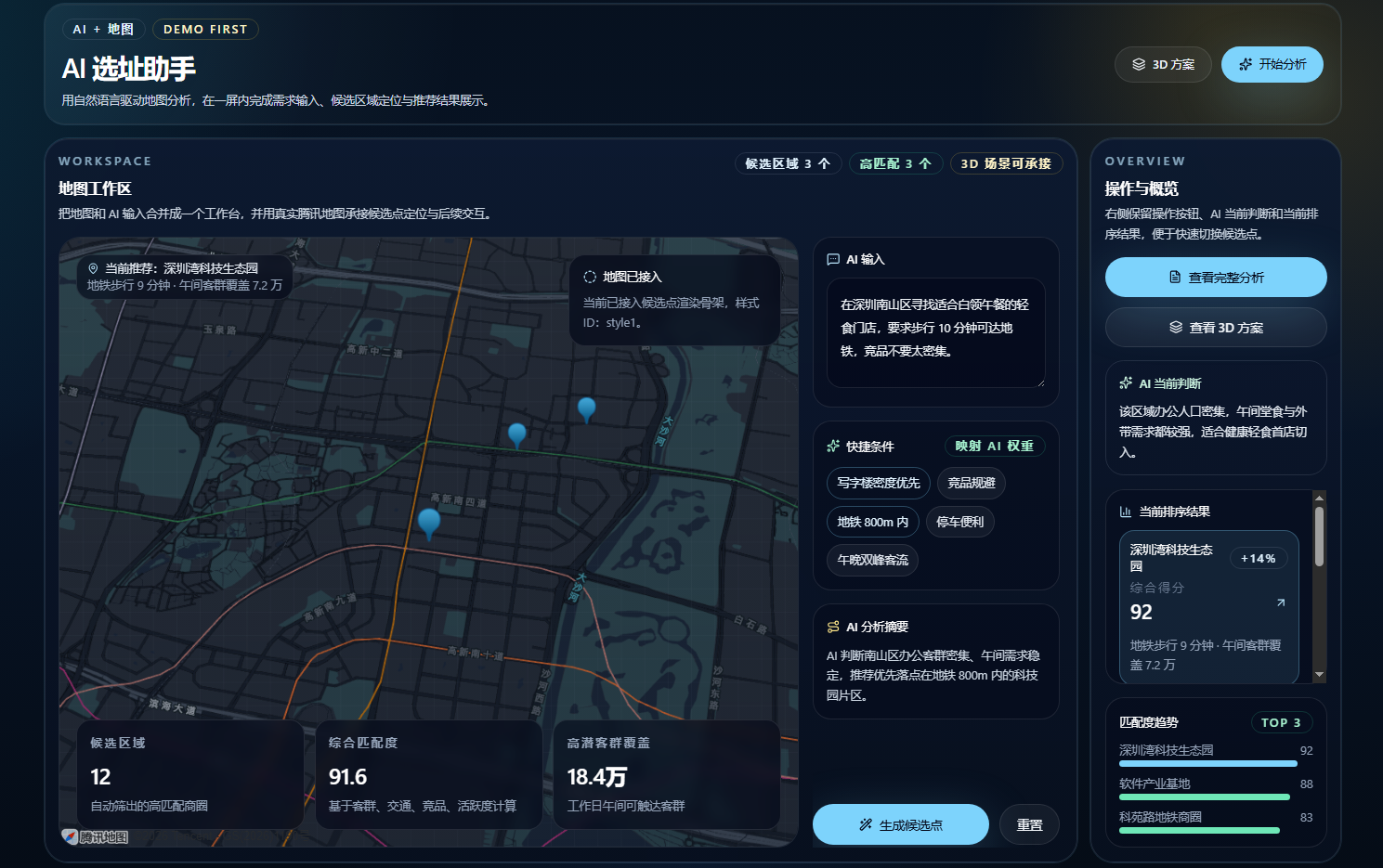
因为选址这件事,特别适合把自然语言、地图能力和业务分析放在一起看。
现实里的需求通常长这样:
在深圳南山区找一个适合轻食首店的位置,优先办公人群,离地铁近一点,竞品不要太密集。
这句话里其实已经包含了很多可执行条件:
- 城市和区域
- 业态类型
- 目标客群
- 交通偏好
- 竞品约束
- 输出形式
如果完全靠人工分析,流程一般会变得很碎:
- 打开地图
- 搜附近 POI
- 看写字楼、地铁、商场、社区
- 对比竞品密度
- 估算客群覆盖
- 最后自己写一段结论
这套流程不是不能做,而是太依赖经验,且很难复用。换一个城市、换一个业态、换一组条件,分析逻辑就要重新来一遍。AI 时代的到来,让很多智能体、龙虾调用大模型已经能实现选址了,但是问题也很明显,每次生成的内容结构都不太一样,demo 感很强但不适合商业化展示。
我想做的,就是把这件事变成一条更顺的链路:
用户只管描述需求,AI 负责理解需求,腾讯位置服务负责补齐数据,前端负责把结果变成可视化报告。
这样一来,地图不再只是"展示工具",而是选址决策的一部分。
二、TencentMap-AI 选址助手工作流设计与实现
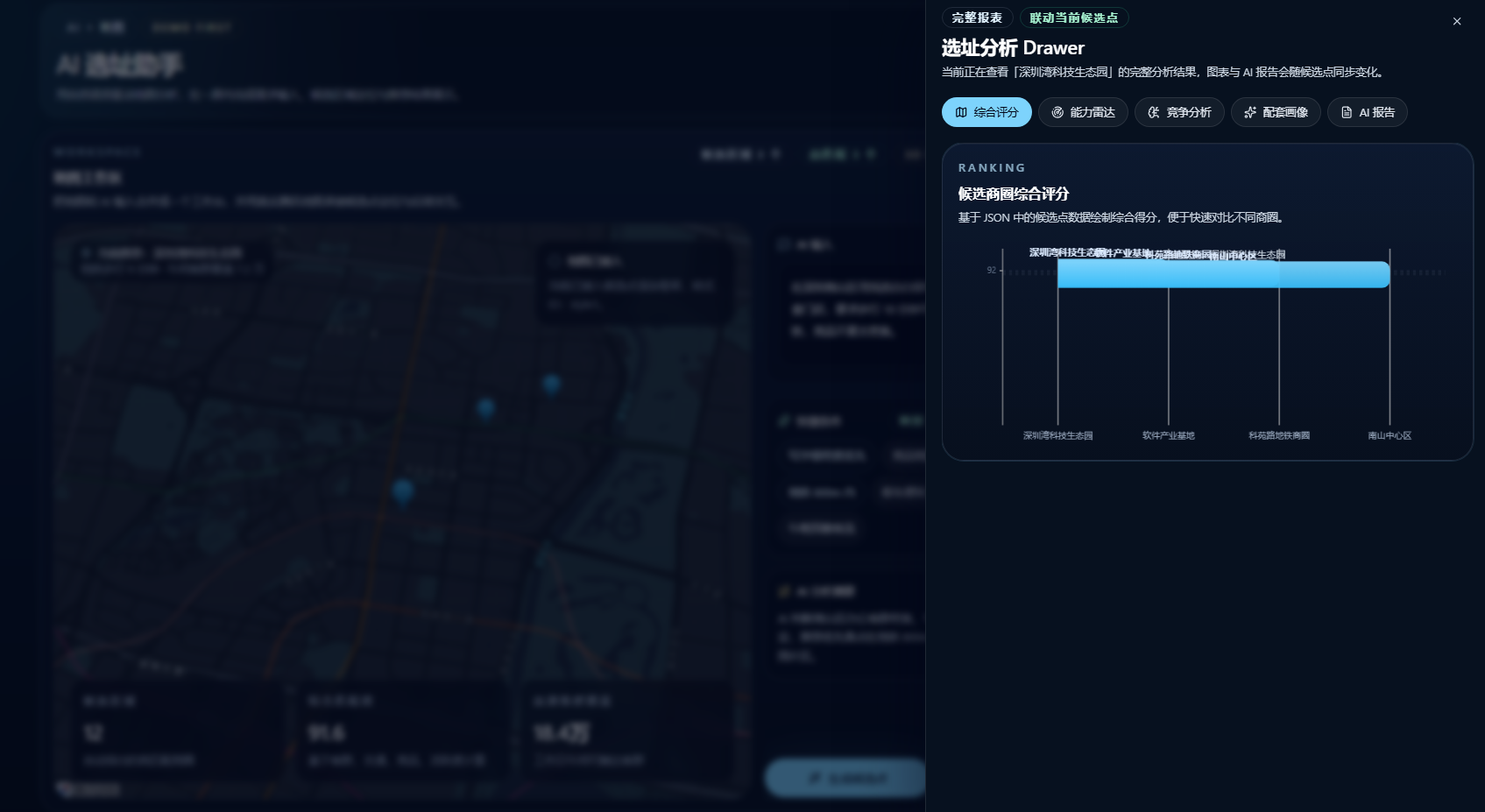
为了解决 AI 生成富媒体内容的质量问题,我利用 BI 时代的可视化经验,把它设计成一个"工程模板"。
整体链路可以概括成四步:
用户输入自然语言
↓
WorkBuddy 调起选址工作流
↓
工作流调用腾讯地图相关 Skills
↓
写入统一 JSON → 前端读取并渲染
这个设计的好处很直接:
- 数据和页面解耦
- 地图、图表、报告可以替换
- 更灵活,AI 驱动数据,不需要重写前端
- 文章里也更容易把"AI + 地图"讲清楚
说白了,这套方案不是在沿用 AI 实时生成静态页面的路线,而是在做一条"问答 -> 本地 JSON -> 可视化报告"的流水线。我希望能把"自然语言输入、地图数据拉取、选址评分、报告生成、页面展示"串成完整闭环,用户使用 WorkBuddy 本地只需要考虑数据分析与 AI 对话即可。
2.1为什么选 WorkBuddy 做编排器
WorkBuddy 是腾讯推出的桌面 Agent 平台,它最大的特点是:能在本地环境中编排多步骤任务,调用外部 Skill,并把结果写入本地文件系统。
在这个项目里,我给它的定位不是 UI 组件,也不是单纯的问答工具,而是一个**“选址分析编排器”**。它负责理解用户的自然语言输入,识别其中的城市、业态、约束条件,然后决定调用哪些腾讯地图 Skill,最后把结果汇总成一份结构统一的 JSON 写到本地。
选 WorkBuddy 而不是其他 AI Agent 平台的原因很简单:它天然支持 Skill 注册和工作流编排,而且结果可以直接写入本地文件,前端通过 fetch 就能读取——整个链路不需要额外的后端服务。
2.2三类 Skill 的分工
我把腾讯地图相关能力拆成了三类:
TencentMap_jsapi_skills负责前端地图展示能力,比如地图初始化、3D 视图、覆盖物绘制、图层管理、事件系统、可视化渲染和三维模型展示TencentMap_lbs_skills负责周边搜索、旅游规划、轨迹图可视化这类 LBS 综合能力TencentMap_webservice_skills负责地址转换、POI 搜索、路线规划、距离矩阵、IP 定位、天气查询、行政区划这些基础服务
这三层能力放到"选址"这个场景里,刚好互相补位:
- JSAPI GL 负责"看得见",
- WebService 负责"查得到"
- LBS 负责"分析得更像业务"
下面以"深圳轻食选址"为例,展示一次完整的 Skill 调用链路:
Step 1: webservice_skills → 行政区划查询(district/v1/getchildren)
→ 获取深圳市南山区边界与商圈划分
Step 2: webservice_skills → POI 搜索(place/v1/search, keyword="科技园")
→ 获取南山区主要办公园区候选区域
Step 3: webservice_skills → POI 搜索(place/v1/search, keyword="轻食")
→ 获取各候选区域的竞品分布与密度
Step 4: webservice_skills → 距离矩阵(distance/v1/matrix)
→ 计算每个候选点到最近地铁站的步行距离
Step 5: lbs_skills → 周边搜索(place/v1/explore, category="写字楼")
→ 估算各候选点 800m 范围内的办公客群覆盖量
Step 6: 汇总五维评分 → 写入 public/reports/latest-report.json
这条链路的好处是:每一步都对应一个真实的腾讯地图 API 调用,数据来源可追溯,结果可验证。
2.3选址这件事,核心到底看什么
我在做这个 Demo 之前,先把"选址"拆成了几个最基本的问题。
选址的本质不是"数据可视化的复杂程度",而是:
这个位置是不是能稳定地接住目标客群的需求。
所以我把分析维度固定成五类:
- 客群密度
- 交通可达性
- 竞品压力
- 配套完整度
- 区域活跃度
这五个维度其实也很适合用腾讯位置服务来承接。
- 客群密度可以看写字楼、住宅区、学校、商圈
- 交通可达性可以看地铁、公交、步行和距离矩阵
- 竞品压力可以看同类 POI 的分布和密度
- 配套完整度可以看餐饮、零售、停车等设施
- 区域活跃度可以结合 POI 数量和区域热度做判断
在我的设计中,这五个维度不是"抽象指标",而是根据抓取的脚本进行实时分析决策,增加角色化体验。
2.4不同行业的权重差异
评分逻辑基于加权公式:总分 = 客群密度×W1 + 交通可达性×W2 + 竞品压力×W3 + 配套完整度×W4 + 区域活跃度×W5。
不同业态会动态调整权重。我在 industry-configs.json 中为 8 个行业预设了不同的权重配置,下面是其中几个典型行业的对比:
| 维度 | 轻食 | 便利店 | 奶茶 | 火锅 |
|---|---|---|---|---|
| 客群密度 | 30% | 25% | 30% | 25% |
| 交通可达性 | 25% | 35% | 20% | 20% |
| 竞品压力 | 20% | 15% | 25% | 20% |
| 配套完整度 | 15% | 15% | 10% | 20% |
| 区域活跃度 | 10% | 10% | 15% | 15% |
| 搜索半径 | 800m | 300m | 500m | 1500m |
可以直观看到:
- 便利店最看重交通可达性(35%),因为它是通勤节点的高频刚需生意,选址精度要求最高,搜索半径只有 300m
- 奶茶的竞品压力权重最高(25%),因为年轻人聚集区竞争激烈,品牌差异化是关键
- 火锅的配套完整度权重最高(20%),因为聚餐场景需要停车位、商业配套支撑,搜索半径拉到 1500m
这种可配置的行业模型,使选址决策更贴近真实业务场景,而非通用评分带来的生硬判断。换一个行业只需要修改配置文件,前端和工作流框架完全不用动。
2.5工程模板拉通 Skill、工作流实现数据闭环
传统业务侧开发是前端对接接口,而 AI 的富媒体生成目前还达不到一次生成即可使用的程度。所以最合适的不是"AI 直接生成网页",而是让 WorkBuddy 把整个流程包起来。
它的任务是:
- 解析用户输入
- 识别城市、业态、约束条件
- 调用腾讯地图相关技能
- 汇总分析结果
- 写入本地 JSON 文件
- 前端读取 JSON 并渲染报告
这一层的核心价值不在于"它有多智能",而在于它把原来人工做的事情拆成了可执行步骤。
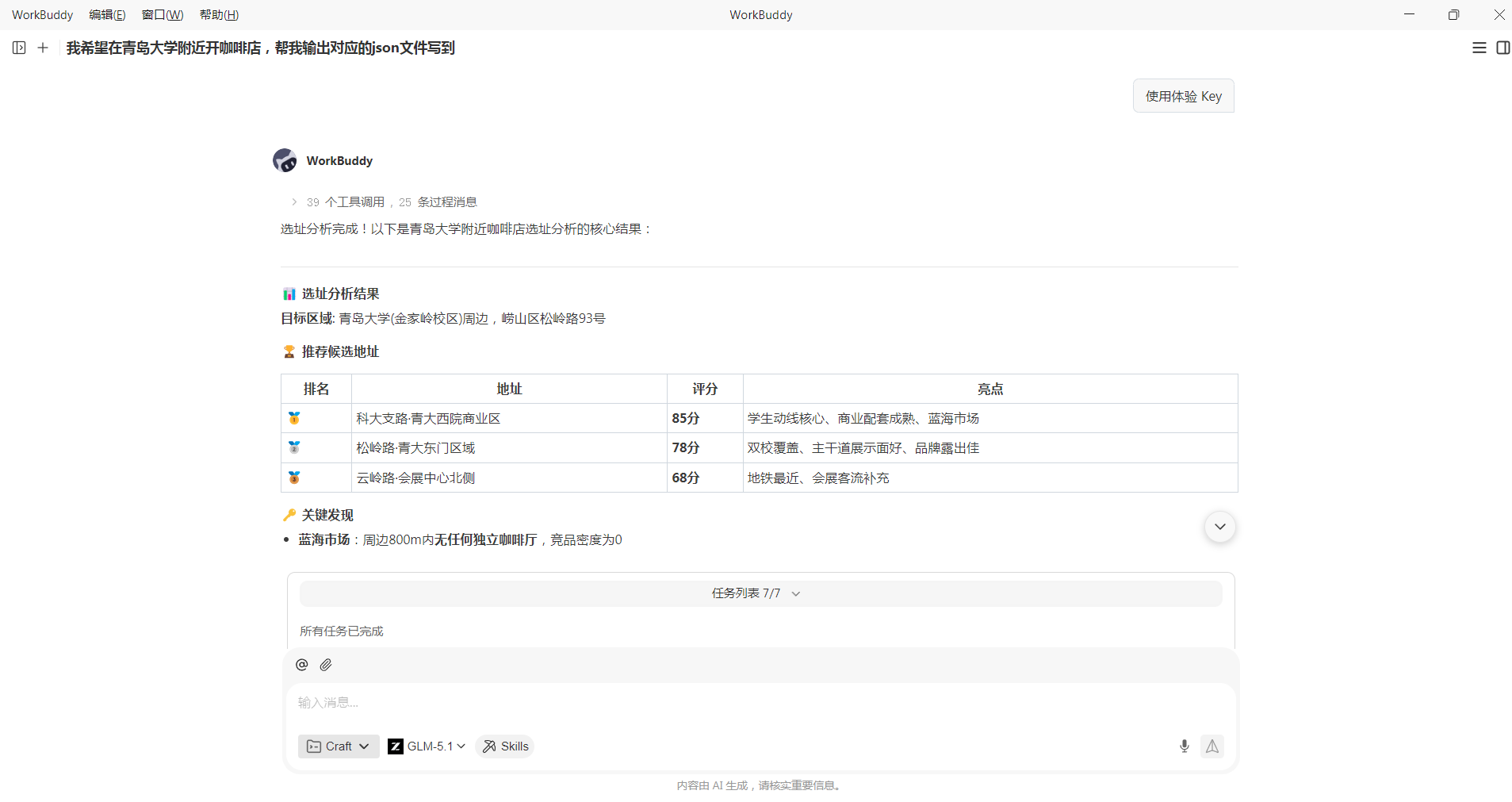
首先,系统会解析用户自然语言中的核心需求(如城市、行业、客群偏好),并自动补齐行业默认参数(如轻食业态看重写字楼密度与午间客流)。随后调用地图与 POI 数据接口,完成区域划分、周边检索、路线规划等数据采集,再通过固定评分模型对候选点进行量化打分。最终生成结构统一的 JSON 报告,由前端直接渲染为地图、图表与可视化报告。
在这个方案里,我把这个思想进一步收敛成了一个统一的输出协议。
2.6 输出协议为什么要固定
我这次把输出协议固定成了一个很简单的结构,因为用户感知上最怕"每次返回结构都不一样"。
展示侧需要的,不是一个巨大的、不可预测的对象,而是一份稳定的报告协议。
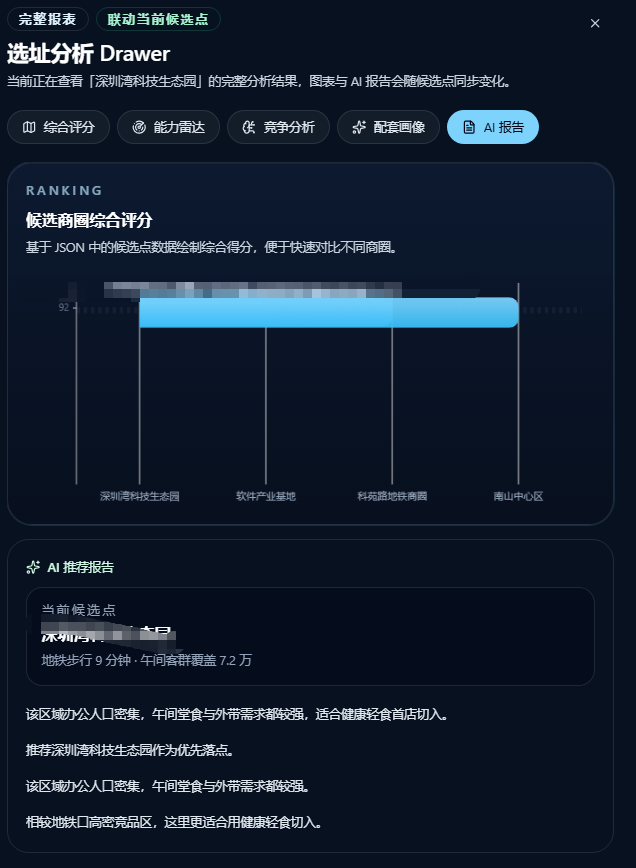
工作流最终输出的内容格式如下:
{
"projectName": "AI选址助手",
"city": "深圳",
"industry": "轻食",
"summary": "AI 判断南山区办公客群密集、午间需求稳定,推荐优先落点在地铁 800m 内的科技园片区。",
"map": {
"center": [113.94695, 22.53332],
"zoom": 13,
"styleId": "style1"
},
"sites": [
{
"id": "site-a",
"name": "深圳湾科技生态园",
"score": 92,
"lat": 22.53332,
"lng": 113.94695,
"summary": "办公密度高、午间消费稳定、步行可达地铁。",
"aiReason": "该区域办公人群密集,适合健康轻食切入。",
"radiusText": "地铁步行 9 分钟 · 午间客群覆盖 7.2 万",
"tags": ["办公客群", "地铁可达", "竞品可控"]
}
],
"metrics": [
{
"label": "候选区域",
"value": "12",
"detail": "自动筛出的高匹配商圈",
"tone": "primary"
}
],
"barData": [
{ "name": "深圳湾科技生态园", "value": 92 }
],
"reportParagraphs": [
"推荐深圳湾科技生态园作为优先落点。",
"该区域办公人口密集,午间堂食与外带需求都较强。",
"相较地铁口高密竞品区,这里更适合用健康轻食切入。"
]
}
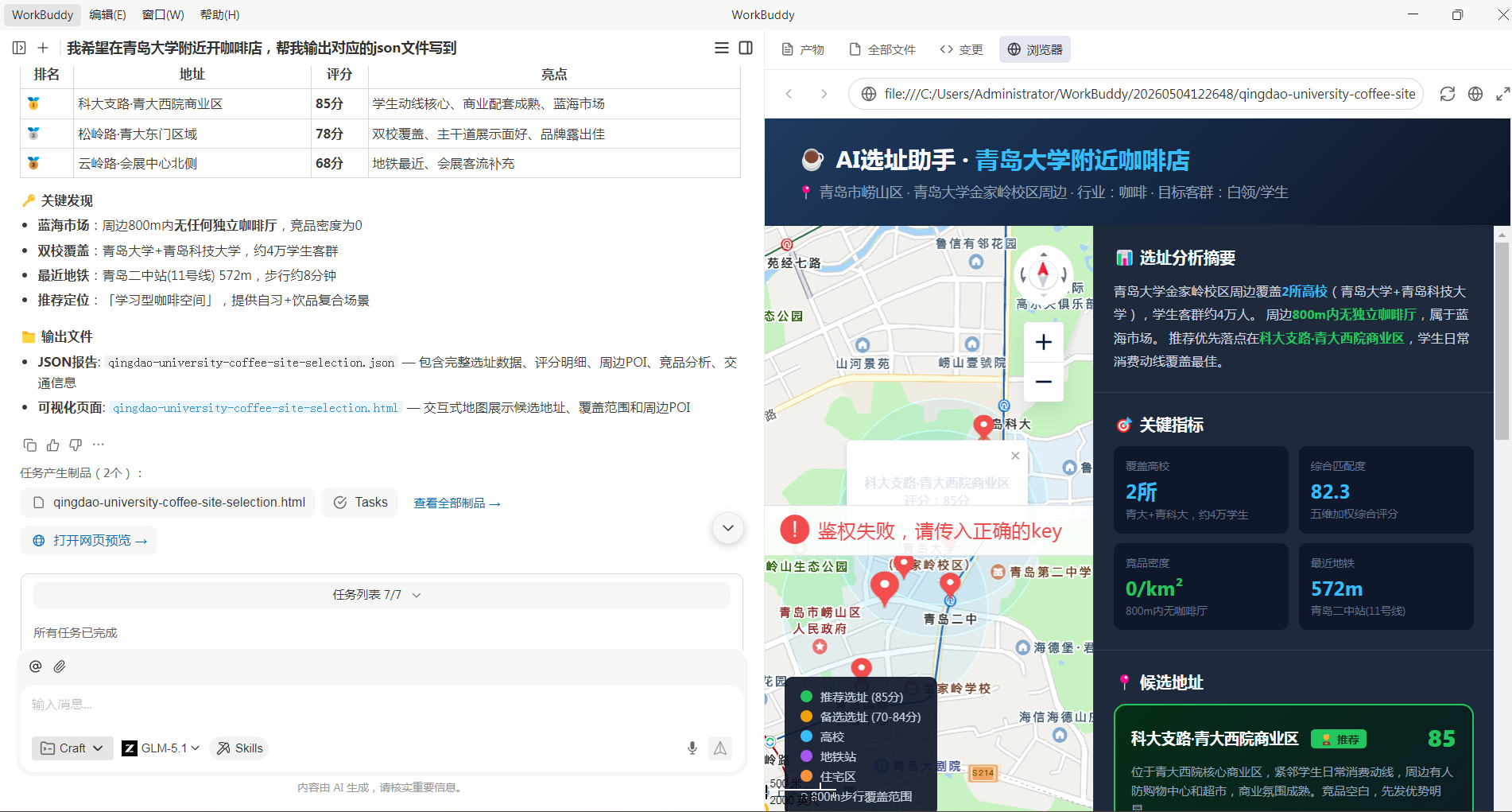
这个 JSON 结构是固定的,不管用户输入什么行业、什么城市,输出格式都一样。前端只需要认这一种结构,就能自动渲染出地图、图表和报告。WorkBuddy 写一份 JSON,页面就自动长出一份报告。
三、UX 设计巧思,人机交互如何设计
不是为做地图壳子,而是真正把 AI 和地图串成链路。JSON 驱动报告的方式,换城市、换行业、换点位都很方便,比传统大屏更适合小场景选址。
前端用 Vue + AntV + 腾讯地图 JS API GL,首屏采用一屏布局:左侧地图 + AI 输入,右侧分析概览 + 候选点切换,详细报告放在 Drawer 里。目的很直接——首屏先让人看到地图和结果,而不是先看到一堆文字。
地图初始化时通过环境变量接入 Key,带上样式 ID:
mapInstance = new TMapNS.Map(mapContainer.value, {
center: new TMapNS.LatLng(props.selectedSite.lat, props.selectedSite.lng),
zoom: 14.8,
pitch: 32,
rotation: 10,
showControl: false,
baseMap: { type: 'vector', features: ['base', 'building3d', 'label'] },
})
最关键的是联动状态:选中的候选点、地图中心、覆盖物全部绑定,地图不是静态背景,而是选址流程的一部分。没有配置 Key 时会明确提示,避免"页面空白但不知道为什么"。
数据驱动的渲染与状态管理
候选点完全由数据驱动,不写死:
function buildGeometries(TMapNS: TMapNamespace) {
return props.sites.map((site) => ({
id: site.id,
styleId: site.id === props.selectedSite.id ? 'active' : 'default',
position: new TMapNS.LatLng(site.lat, site.lng),
properties: { title: site.name, score: site.score },
}))
}
JSON 变了,点位就跟着变,不需要重写地图逻辑。同时支持点击点位切换选中项。
前端数据入口收敛为读取本地文件,但做了两层保护:读取失败时回退到 fallback 数据,字段缺失时自动用默认值补齐。这样 WorkBuddy 还没完全接入,页面也能先跑起来。
状态管理围绕同一份 JSON 展开:selectedSiteId 控制选中点、rankedSites 控制排序、analysisMetrics 控制顶部指标、reportParagraphs 控制详细报告。右侧操作区同时提供快速提问、标签式约束、AI 摘要、重新分析按钮,以及推荐点位和候选点排行——用户的感知不是"我输入了一段话",而是"AI 已经开始帮我筛选"。
抽屉里的分析层与落地闭环
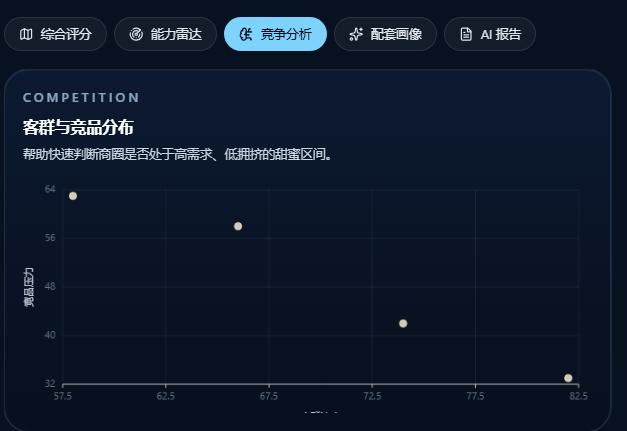
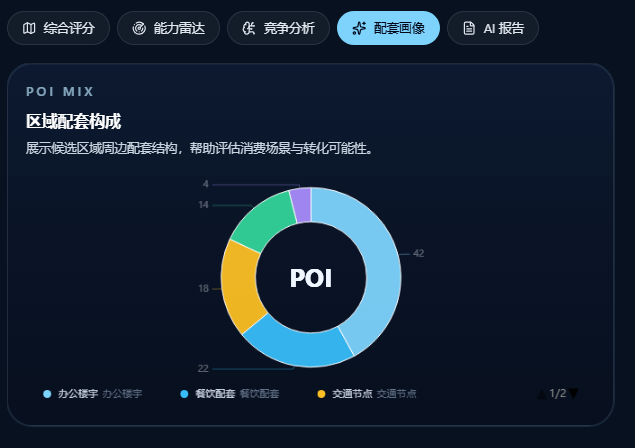
详细分析放在 Drawer 里,用多个 tab 把"为什么推荐这个点"讲透:
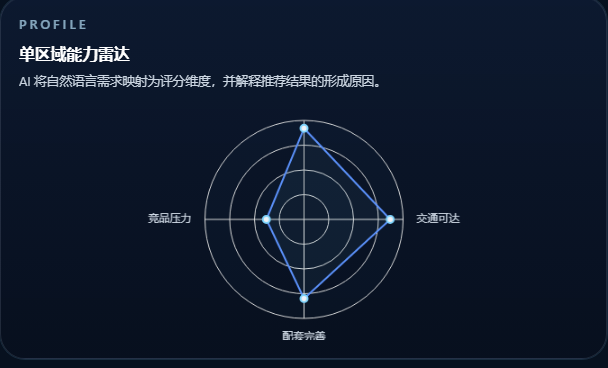
- 综合评分柱状图:一眼看出谁排前面、差距多大
- 能力雷达图:客群密度、交通可达、配套完整、竞品压力四个方向,不只看到分数,更看到"为什么高"
- 竞争分布散点图:客群密度 vs 竞品压力,好位置往往是几个维度的平衡点,不是单维度极端
- 配套画像饼图:办公楼宇、餐饮配套、交通节点、商业综合体、社区服务的结构
- AI 报告:把判断文字串成可直接发布的结论,保留"更像文章"的表达——很多业务方不先看算法公式,但一定想看"最后你到底建议什么"
闭环极简但完整:Skill 生成 JSON → 写入 public/reports/ → 页面自动读取 → 地图、图表、报告同时刷新。换场景(咖啡首店、便利店筛选、社区烘焙、健身房落点、医美评估)只用改行业权重、输入提示词、候选点来源、报告文本,框架不动。
这不是一个只会回答"我觉得这里不错"的聊天机器人,而是有可视化证据的决策工具。选址最怕只有结论没有依据、只有结果没有过程——地图和图表的价值就是把过程展开。WorkBuddy 负责编排,Map Skills 负责数据和地图能力,前端负责渲染,三者解耦后,换一个城市、换一组候选点,不用重写页面。
前端 fallback 机制的设计
我给前端做了两层保护:JSON 读取失败时回退到内置的 fallback 数据,字段缺失时自动用默认值补齐。这个设计的初衷是:WorkBuddy 工作流还在调试阶段,前端不能因为 JSON 格式不完整就白屏。事实证明这个决策很对,开发过程中两边可以独立推进。
四、总结与展望
这次我最大的感受是:Mvp设计的主链路一定要清楚。
我最后定下来的这条路其实就一句话:
让 WorkBuddy + Map Skills 负责生成并写入结构化 JSON,让前端负责把本地 JSON 渲染成一份可交互、可替换、可复用的选址分析报告。
这套方案的核心优势
| 维度 | 传统 AI 生成页面 | 本方案(JSON 驱动报告) |
|---|---|---|
| 输出稳定性 | 每次结构不同 | 固定 JSON 协议,结构一致 |
| 可复用性 | 换场景需重新生成 | 只改配置文件,框架不动 |
| 数据可追溯 | 黑盒,不知道数据来源 | 每个字段对应具体 API 调用 |
| 前后端耦合 | AI 直接生成 HTML | 数据与页面完全解耦 |
| 商业化潜力 | demo 感强 | 可直接用于业务汇报 |
如果继续完善,我会优先推进这几件事:
- 支持更多行业场景:目前已配置 8 个行业的权重模型(轻食、咖啡、奶茶、火锅、便利店、健身房、鲜花店、药店),后续可以扩展到医美、教培、宠物等更多业态
- 增加知识库联动、历史对比功能:支持多次分析结果的横向对比,帮助用户在多个候选方案中做最终决策。
一旦这条链路打通,这个项目就不只是一个 Demo了,而是一套能持续演进的 AI 选址原型。AI 和地图放在一起,不只是做数据可视化,而是真的能做商业决策。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)