五种 IO 模型
1. IO
1.1 认识 IO
什么是IO?IO是input和output的简称,是外设(键盘、网卡、磁盘等)和内存之间的数据交互。网络通信就属于IO范畴。
IO的本质 = 等 + 拷贝。
当我们调用read函数,其实是在检测TCP接收缓冲区中是否存在数据。如果没有数据,就会阻塞等待。我们常说read函数的本质就是一种拷贝——从内核缓冲区拷贝到用户空间。但read不只是做拷贝,它需要等待数据就绪。因此:读IO = 等数据就绪 + 拷贝数据。
当我们调用write函数,其实是将数据写到发送缓冲区中。若发送缓冲区写满了,write会阻塞等待,等到缓冲区有空间了再写入。因此:写IO = 等空间就绪 + 拷贝数据。
为什么IO慢?我们觉得IO慢,是因为等的时间太长。拷贝的时间差不多是固定的,由硬件(内存、总线)决定。理解了IO的本质是"等 + 拷贝",就能明白:单位时间内IO中等待的比重越低,IO效率越高。要设计高效的IO,就需要减少单位时间内IO中"等"的比重。
1.2 五种 IO 模型
IO总共分成五种IO模型,分别是:阻塞IO,非阻塞IO,信号驱动IO,多路转接IO,异步IO。
阻塞IO:在内核将数据准备好之前,系统调用会一直等待。所有的套接字(socket),默认都是阻塞方式。
示意流程如下图所示:
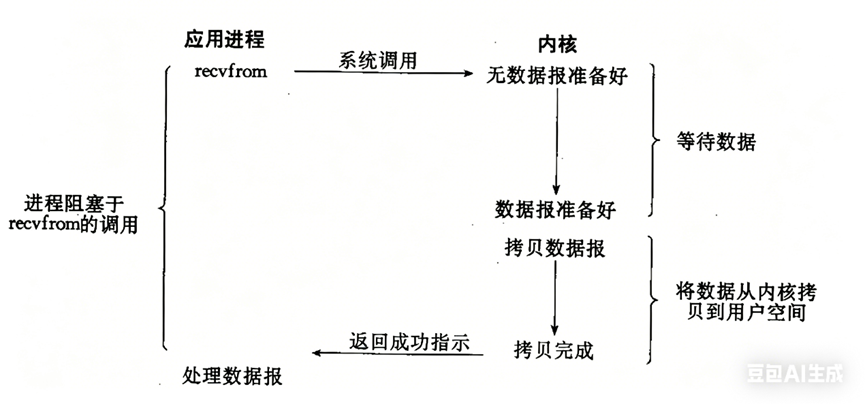
流程:进程调用recvfrom;内核发现没有数据准备好,进程阻塞;内核准备好数据;内核将数据从内核拷贝到用户空间;返回成功指示。
非阻塞IO:如果内核还未将数据准备好,系统调用仍然会直接返回,并且返回EWOULDBLOCK错误码。
非阻塞IO往往需要程序员以循环的方式反复尝试读写文件描述符,这个过程称为轮询。这对CPU来说是较大的浪费,一般只有特定场景下才使用。
示意流程如下图所示:
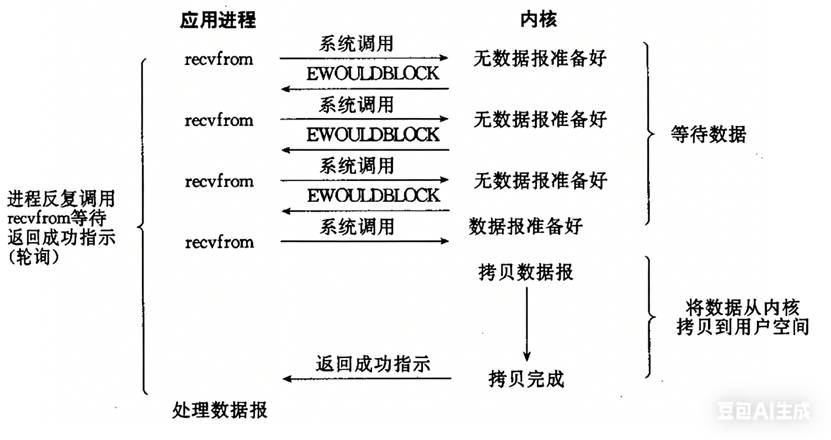
流程:进程调用recvfrom;内核发现没有数据准备好,立即返回EWOULDBLOCK;进程反复调用recvfrom(轮询);内核准备好数据;调用recvfrom,拷贝数据到用户空间,返回成功。
信号驱动IO:内核将数据准备好的时候,使用SIGIO信号(29号信号)通知应用程序进行IO操作。
示意流程如下图所示:
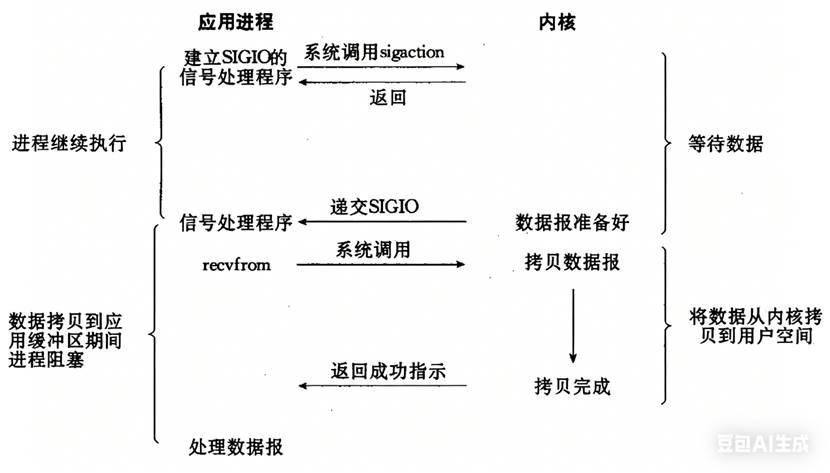
流程:进程建立SIGIO信号处理函数;进程继续执行(不阻塞);内核准备好数据;内核递交SIGIO信号给进程;进程在信号处理函数中调用recvfrom拷贝数据。
在高IO并发场景下,会产生多个SIGIO信号,可能丢失部分信号,这是一个巨大的缺陷。因此信号驱动IO在实际中很少使用。
IO多路转接:虽然从流程图上看起来和阻塞IO类似(都有阻塞),但最核心的区别在于:IO多路转接能够同时等待多个文件描述符的就绪状态。
示意流程如下图所示:
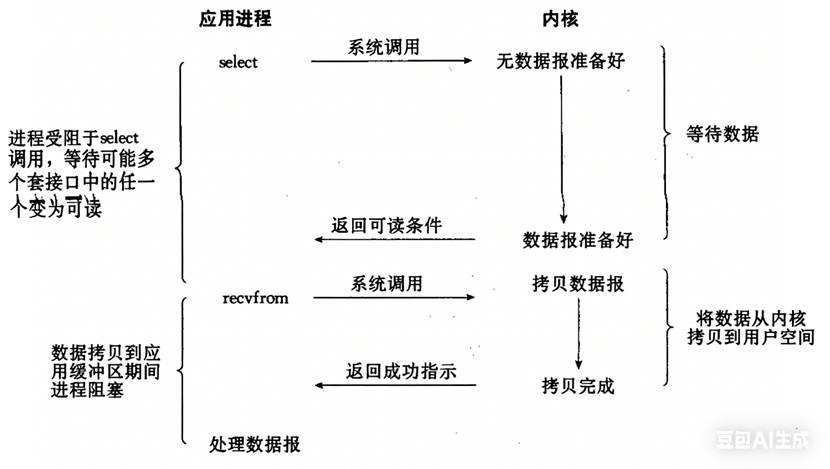
流程:进程调用select(或poll/epoll),可以同时传入多个文件描述符;进程阻塞在select调用上,等待多个文件描述符中的任意一个就绪;内核准备好数据,select返回可读条件;进程调用recvfrom拷贝数据。
select 只负责"等",recvfrom 只负责"拷贝",分工更精细。
异步IO:由内核在数据拷贝完成时通知应用程序。整个过程,应用程序既没有调用recv去等,也没有调用recv去拷贝,没有参与IO的任何过程,这些过程都是操作系统完成的。
示意流程如下图所示:
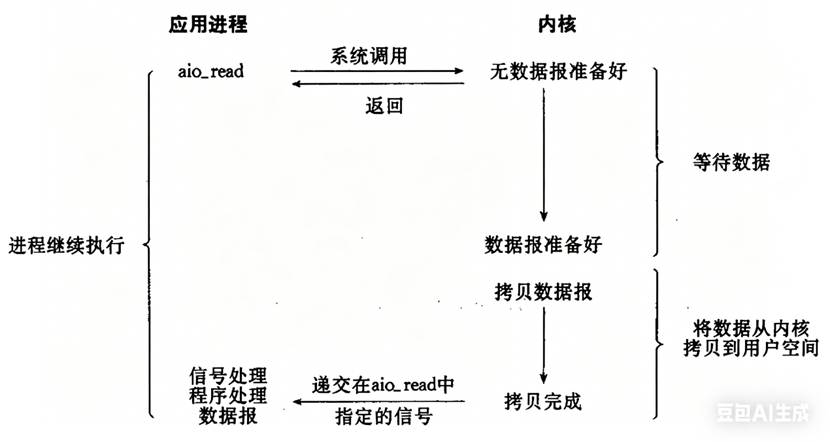
流程:进程调用aio_read,指定缓冲区、回调信号等;aio_read立即返回,进程继续执行;内核等待数据就绪;内核将数据从内核拷贝到用户空间;拷贝完成后,内核递交指定的信号给进程;信号处理程序处理数据。
五种模型对比总结
|
IO模型 |
等待阶段是否阻塞 |
拷贝阶段是否阻塞 |
进程参与程度 |
|
阻塞IO |
阻塞 |
阻塞 |
全程参与 |
|
非阻塞IO |
轮询(不阻塞) |
阻塞 |
全程参与 |
|
信号驱动IO |
不阻塞(信号通知) |
阻塞 |
参与拷贝 |
|
IO多路转接 |
阻塞在select上 |
阻塞 |
参与拷贝 |
|
异步IO |
不阻塞 |
不阻塞 |
完全不参与 |
五种IO模型中,多路转接IO模型的IO效率最高(在并发场景下)。因为它能够同时等待多个文件描述符,将"等"的粒度从单个文件描述符扩大到多个。
当前学习的系统调用:read、recv、recvfrom等函数,每次只能传递1个文件描述符,它们同时完成了"等"和"拷贝"两件事。
select、poll、epoll等接口,只负责IO中的"等",让read、recv函数做另一件事——"拷贝"。这种精细化的拆分,使得:可以用一个系统调用同时等待多个文件描述符,一旦有任何一个就绪,就通知上层调用recv进行拷贝。
同步IO vs 异步IO
- 同步IO:进程参与IO的"拷贝"阶段。阻塞IO、非阻塞IO、信号驱动IO、IO多路转接都是同步IO。
- 异步IO:进程完全不参与IO的等待和拷贝,由内核完成后通知进程。
信号驱动IO是基于信号的,信号的产生是异步的,但信号驱动IO本身参与了IO的拷贝过程(在信号处理函数中调用了recvfrom)。所以它属于同步IO,而不是异步IO。
标准定义(POSIX):
- 同步IO:导致请求进程阻塞直到IO操作完成的IO操作
- 异步IO:不导致请求进程阻塞的IO操作
按此定义,信号驱动IO在等待阶段不阻塞,但在拷贝阶段阻塞,因此属于同步IO。
阻塞IO vs 非阻塞IO:
这两种IO模型的IO效率是一样的。因为IO效率的高低取决于单位时间内"等"的比重,它俩等待事件就绪的方式不同,但拷贝的效率基本一样。区别在于:非阻塞IO可以在"等"的过程中去做其他事情,时间利用率更高,而不是IO效率更高。
2. 非阻塞 IO
2.1 多种方法
让一个文件描述符以非阻塞方式进行IO,存在多种方法:
方法1:使用flags参数
recv函数原型:ssize_t recv(int sockfd, void *buf, size_t len, int flags)
recvfrom函数原型:ssize_t recvfrom(int sockfd, void *buf, size_t len, int flags, ...)
flags有一个标志位:MSG_DONTWAIT,表示开启非阻塞等待
方法2:使用open函数的flags
open函数原型:int open(const char *pathname, int flags, ...)
flags有一个标志位:O_NONBLOCK
方法3:使用fcntl(最常用)
通过修改文件描述符的打开标志位,将其设置为非阻塞。之后,再调用recv/recvfrom/read等函数,都是非阻塞行为。
fcntl函数原型:
#include <fcntl.h> #include<unistd.h> int fcntl(int fd, int op, ... /* arg */ )
传入的cmd值不同,后面追加的参数也不同。常用的功能:获得/设置文件状态标记(cmd = F_GETFL 或 F_SETFL)。
基于fcntl实现SetNonBlock函数:将文件描述符设置成非阻塞。
void SetNonBlock(int fd)
{
int fl = fcntl(fd, F_GETFL);
if (fl < 0)
{
perror("fcntl");
return;
}
fcntl(fd, F_SETFL, fl | O_NONBLOCK);
}
使用F_GETFL将当前文件描述符的属性取出来(这是一个位图),使用F_SETFL将文件描述符设置回去,同时加上O_NONBLOCK标志。
2.2 编写代码
编写代码,将文件描述符设置成非阻塞等待方式。
代码如下所示:
// 将标准输入 0 设置成非阻塞 —— 调用 fcntl 函数
void set_nonblocking(int fd)
{
// 调用 fcntl 函数,函数原型: int fcntl(int fd, int op, ... /* arg */ )
int flags = fcntl(fd, F_GETFL, 0); // 获取文件描述符的当前状态标志
if(flags < 0)
{
std::cerr << "Error getting file flags." << std::endl;
return; // 获取文件标志失败,退出函数
}
fcntl(fd, F_SETFL, flags | O_NONBLOCK); // 将文件描述符设置为非阻塞模式
}
int main()
{
char inbuffer[1024];
// 将标准输入 0 设置为非阻塞模式
set_nonblocking(0);
while(true)
{
ssize_t n = read(0, inbuffer, sizeof(inbuffer)); // 调用 read 函数,从标准输入读
if(n > 0)
{
inbuffer[n] = '\0'; // 将读取到的数据转换为字符串
std::cout << "read: " << inbuffer << std::endl;
}
else if(n == 0)
{
std::cout << "End of file reached." << std::endl;
// break; // 读取到文件末尾,退出循环
}
else
{
std::cerr << "Error reading from standard input." << std::endl;
// break; // 读取发生错误,退出循环
}
sleep(1);
}
return 0;
}程序运行起来后,会循环打印“Error reading from standard input.”,若你输入数据,不按回车键,OS不会接收到数据。
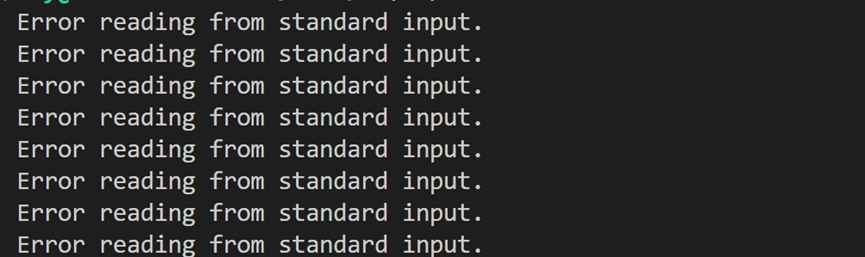
我们可以发现,除了读取文件错误之外,打印“Error reading from standard input”之外,文件描述符未就绪也会打印“Error reading from standard input”。
需要知道的是,文件描述符未就绪不代表读取文件错误,虽然它以读取文件错误的形式打印。怎么区分它是读取错误还是数据未就绪?在C标准库中,存在一个全局变量 —— 错误码errno,它可以告知用户发生错误的原因。在调用read函数失败时,会设置errno。
std::cerr << "Error reading from standard input." << std::endl;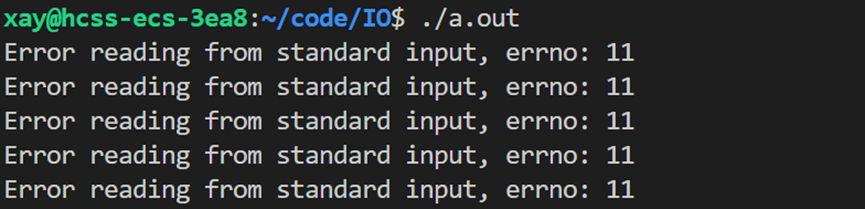
调用 strerror 函数,将错误码转化成错误码信息:
std::cerr << "Error reading from standard input." << std::endl;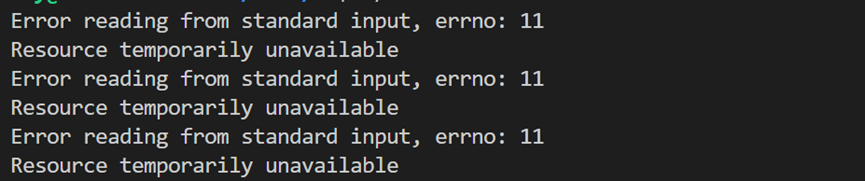
错误码信息为:Resource temporarily unavailable,资源临时不可用,即文件描述符未就绪。
应该区分数据未就绪与读取文件失败两个情况:
if(errno == EAGAIN || errno == EWOULDBLOCK) // 没有数据可读,继续循环
{
// 错误码为 EAGAIN,表示数据未就绪
std::cerr << "No data available to read, errno: " << errno << std::endl;
std::cerr << strerror(errno) << std::endl;
continue; // 没有数据可读,继续循环
}
else // 读取失败
{
std::cerr << "Error reading from standard input, errno: " << errno << std::endl;
std::cerr << strerror(errno) << std::endl;
break; // 读取发生错误,退出循环
}在调用read函数,若不输入数据,进程会阻塞住,输入ctrl + C,就会终止进程。而ctrl + C相当于向进程发送信号,进程接收到了信号,执行相应的动作。这也就说明了阻塞住的进程被唤醒了,这表明了信号可以中断进程的阻塞过程。
若错误码表示 EINTR,表示被信号中断,稳妥起见,还需要加层判断:
else if(errno == EINTR) // 读取被信号中断,继续循环
{
std::cerr << "Read interrupted by signal, errno: " << errno << std::endl;
std::cerr << strerror(errno) << std::endl;
continue; // 读取被信号中断,继续循环
}
AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 7
7 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)