KNN 算法知识点全面解析
KNN 算法知识点全面解析
KNN 算法知识点
知识导图
KNN算法
├─ 核心:K近邻 → 多数表决/平均值
├─ 流程:距离计算 → 排序 → 取K邻 → 决策
├─ 距离:欧氏、曼哈顿、切比雪夫、闵可夫斯基
├─ K值:小→过拟合;大→欠拟合;调优=网格搜索+交叉验证
├─ 预处理:归一化(鲁棒差)、标准化(推荐)
├─ API:KNeighborsClassifier/Regressor
└─ 案例:电影分类、鸢尾花、手写数字识别
1 KNN 算法简介
名词解释
KNN(K-Nearest Neighbor)K 近邻算法
根据样本在特征空间中K 个最相似邻居的类别,通过多数表决判断自身类别;回归任务取 K 个邻居目标值的平均值。
核心思想
样本距离越近 → 相似度越高 → 类别 / 属性越接近。
2 KNN 执行流程
2.1 分类流程(5 步)
-
计算未知样本到所有训练样本的距离
-
按距离升序排序
-
选取最近的 K 个样本
-
统计 K 个样本的类别频次
-
多数表决 → 确定类别
2.2 回归流程(5 步)
-
计算未知样本到所有训练样本的距离
-
按距离升序排序
-
选取最近的 K 个样本
-
计算 K 个样本目标值的平均值
-
平均值作为预测结果
3 距离度量方法
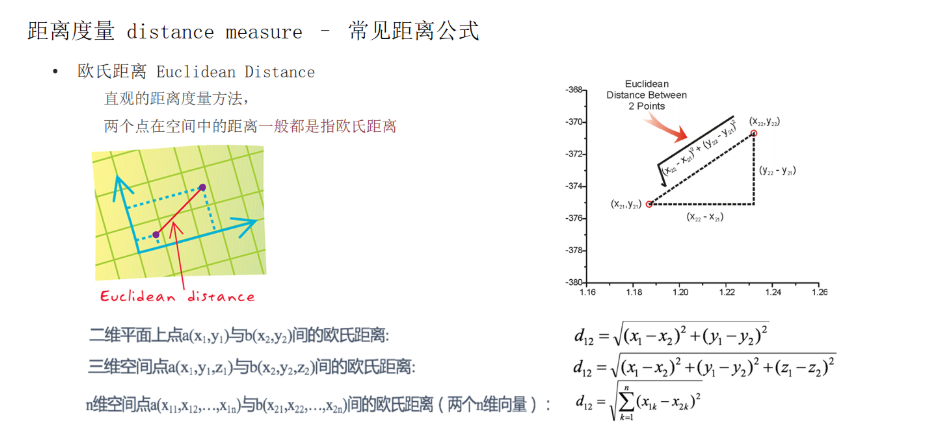
3.1 欧氏距离
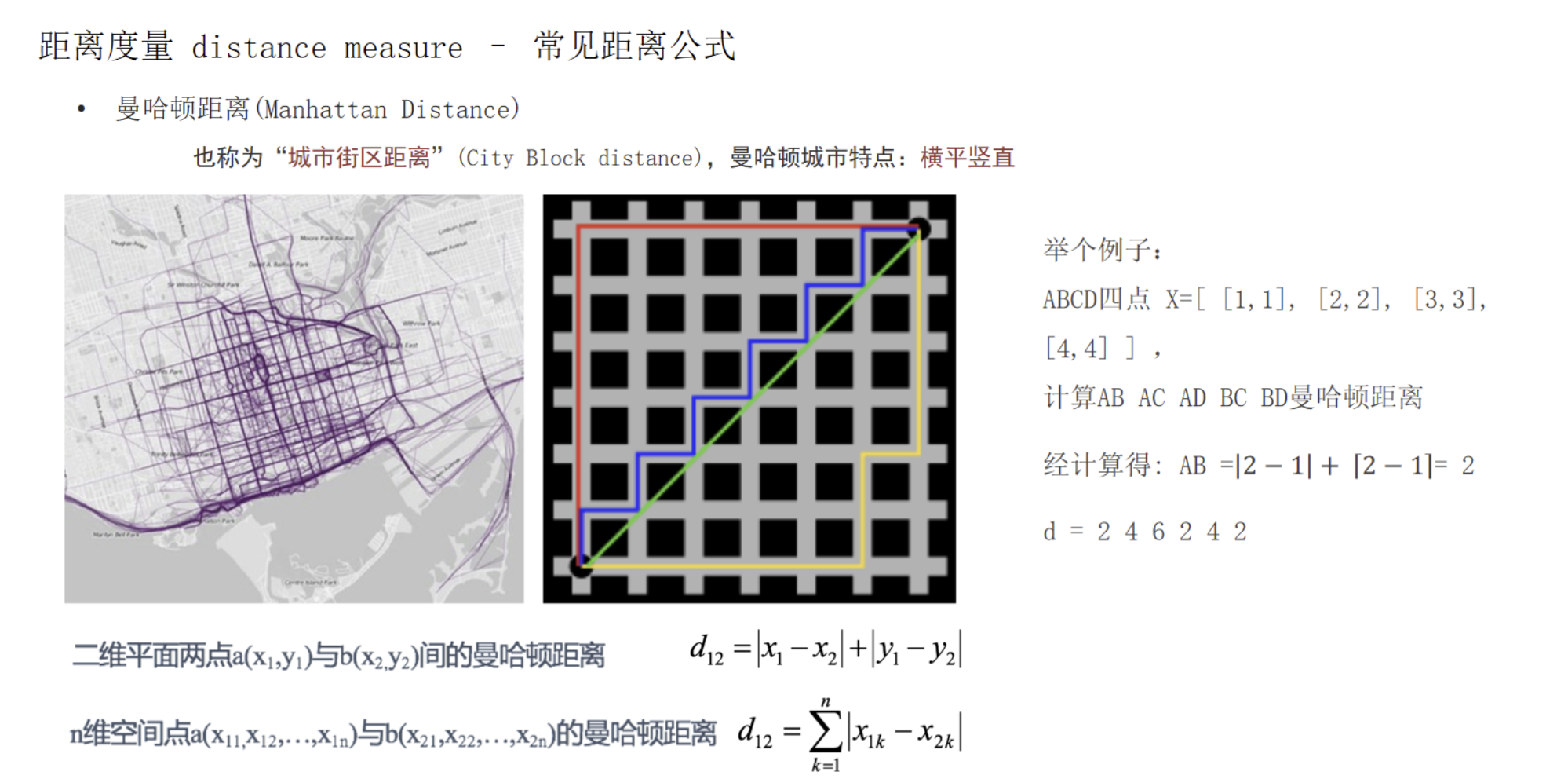
3.2 曼哈顿距离
3.3 切比雪夫距离

3.4闵可夫斯基距离

3.5.1 三种常见距离汇总
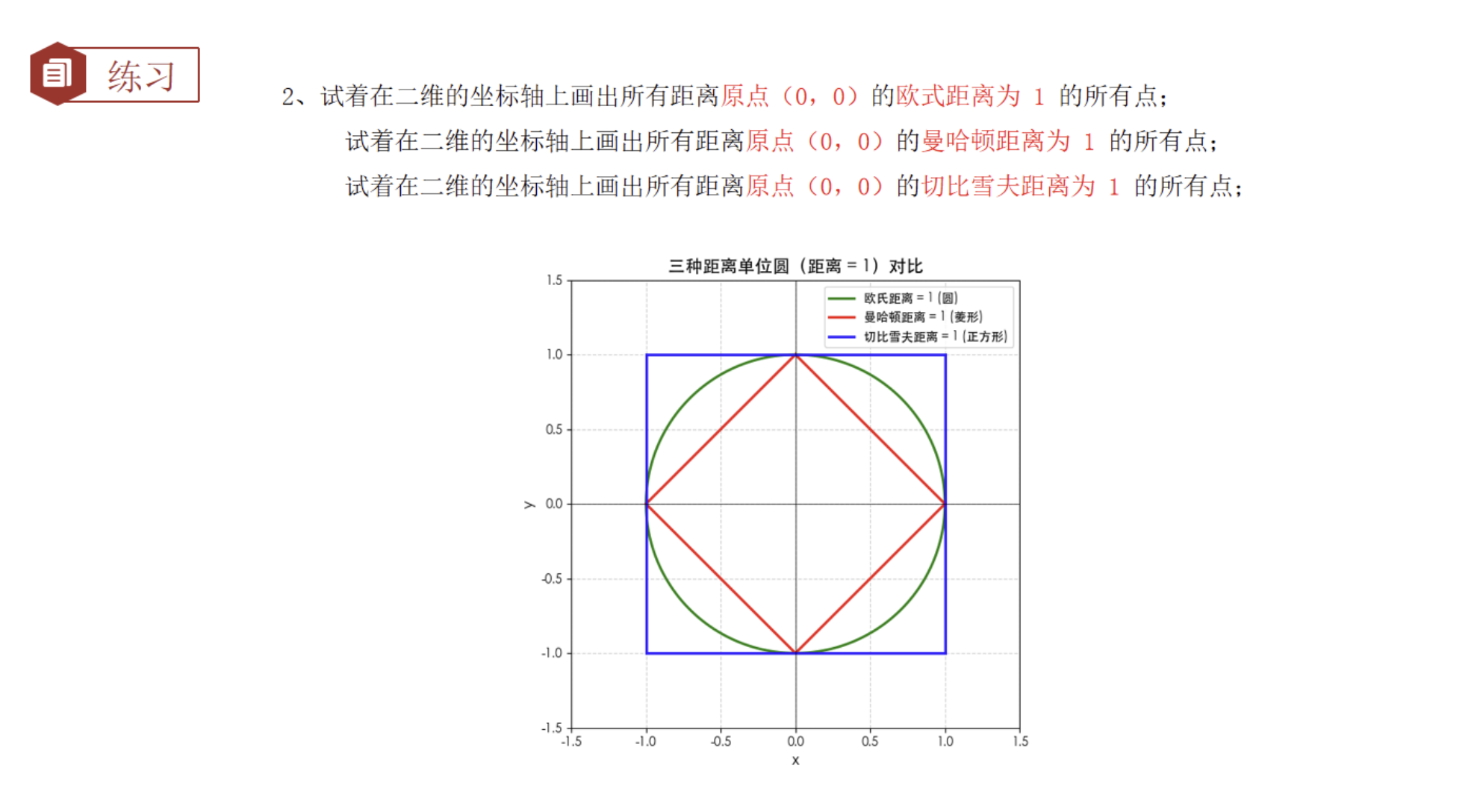
欧氏距离:d = √[(x1-x2)² + (y1-y2)²]
曼哈顿距离:d = |x1-x2| + |y1-y2|
切比雪夫距离:d = max(|x1-x2|, |y1-y2|)
闵可夫斯基距离:d = (Σ|xi-yi|^p)^(1/p)
3.5.2 三种距离单位圆画图
4 特征预处理
4.1 为什么预处理
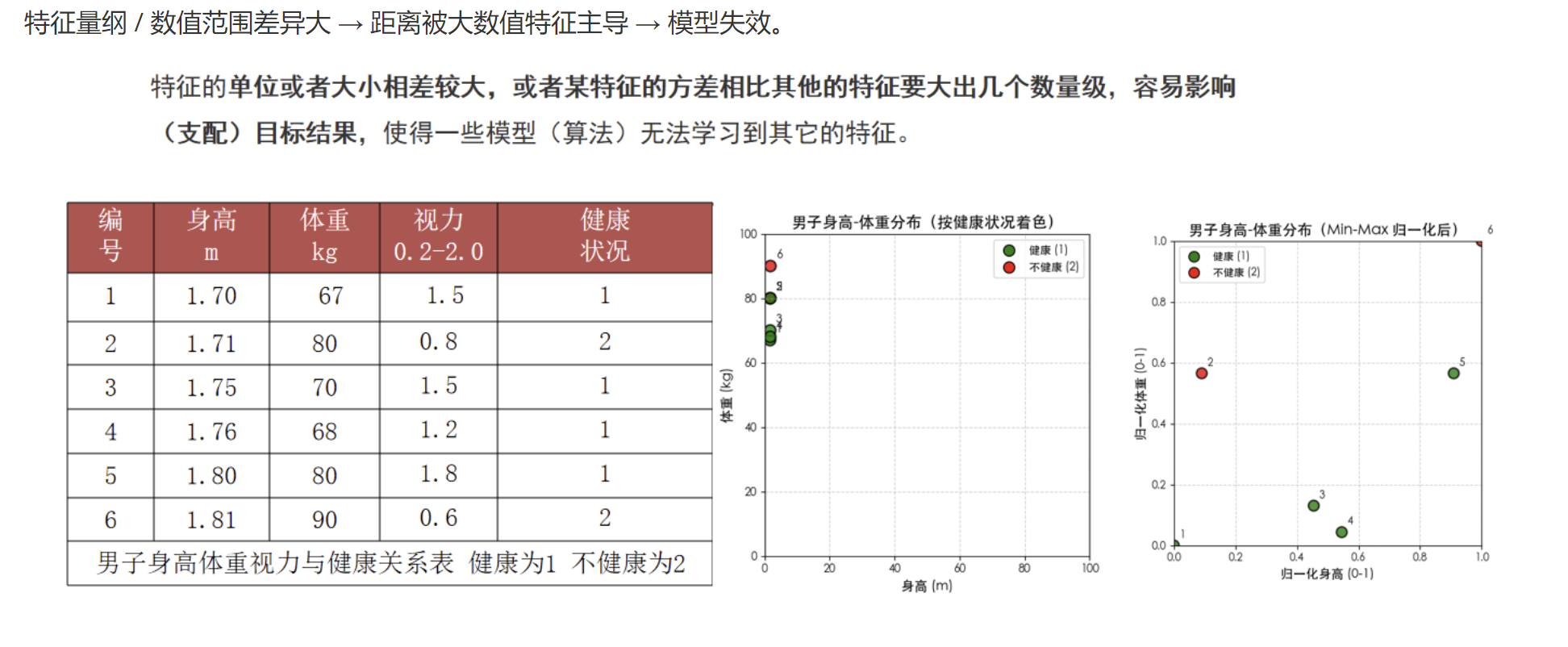
特征量纲 / 数值范围差异大 → 距离被大数值特征主导 → 模型失效。
4.2 归一化后分布

4.3 归一化代码
from sklearn.preprocessing import MinMaxScaler
data = [[90, 2, 10], [60, 4, 15], [75, 3, 13]]
trans = MinMaxScaler()
print(trans.fit_transform(data))
4.4 标准化分布
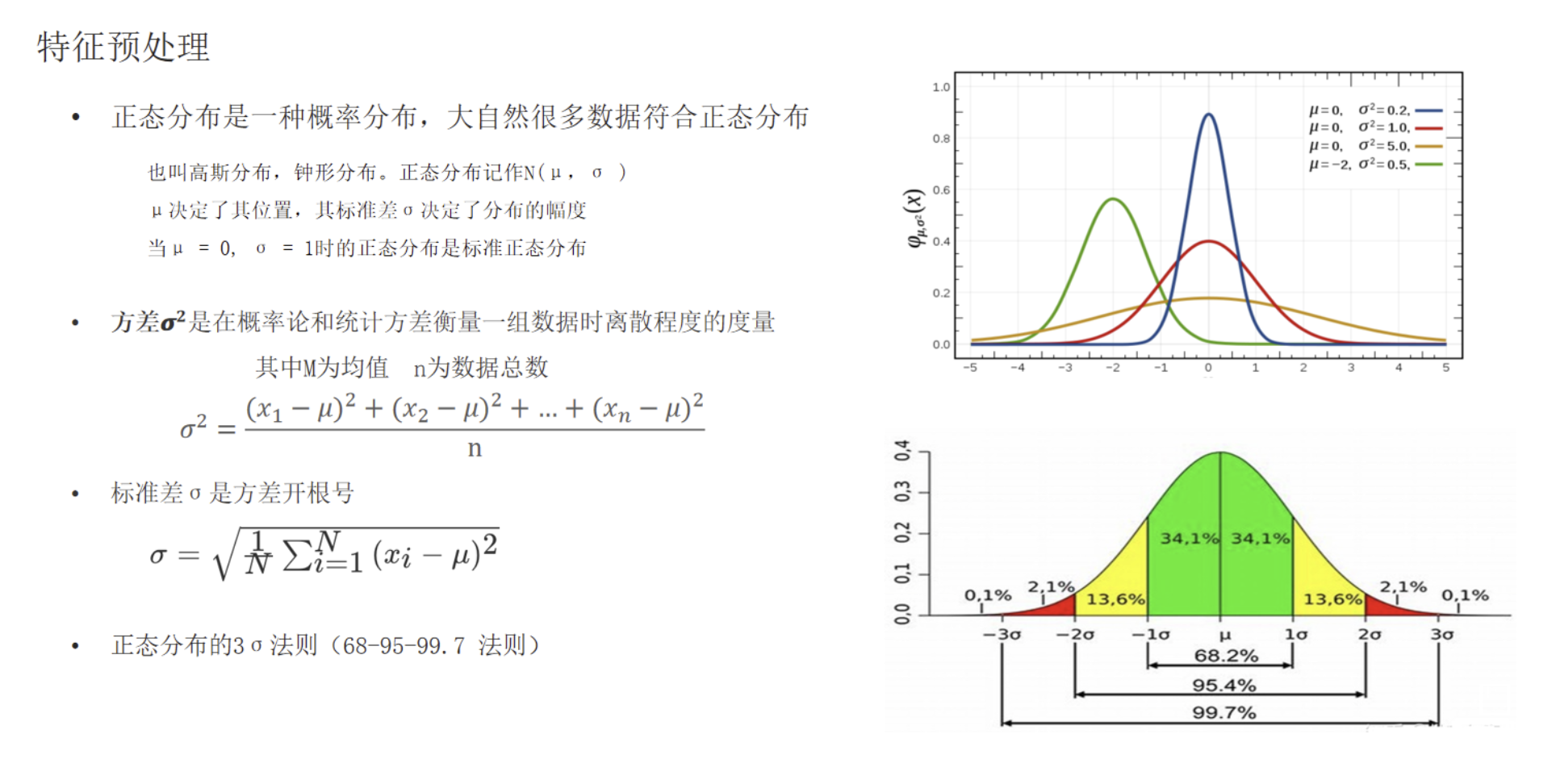

4.5 标准化代码
from sklearn.preprocessing import StandardScaler
data = [[90, 2, 10], [60, 4, 15], [75, 3, 13]]
trans = StandardScaler()
print(trans.fit_transform(data))
4.6 归一化 vs 标准化(对比辨析)
| 方法 | 抗异常值 | 适用场景 | 推荐度 |
|---|---|---|---|
| 归一化 | 差 | 小数据、干净数据 | 低 |
| 标准化 | 好 | 大数据、嘈杂数据 | 高 |
5 K 值选择与超参数调优
5.1 K 值影响
-
K 过小:模型复杂 → 过拟合
-
K 过大:模型简单 → 欠拟合
-
K=N:永远预测多数类
5.2 交叉验证及网格搜索原理


5.3 网格搜索实例

这段代码是K 近邻(KNN)分类器的网格搜索调参代码,功能是自动遍历所有参数组合,找出 5 折交叉验证下效果最好的超参数。
# 1. 导入依赖库
from sklearn.model_selection import GridSearchCV
from sklearn.neighbors import KNeighborsClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
# 2. 加载示例数据(鸢尾花数据集)
data = load_iris()
X = data.data # 特征
y = data.target # 标签
# 3. 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# 4. 定义参数网格
param_grid = {
'n_neighbors': [1, 3, 5, 7],
'weights': ['uniform', 'distance'],
'p': [1, 2]
}
# 5. 网格搜索(5折交叉验证)
grid = GridSearchCV(KNeighborsClassifier(), param_grid, cv=5)
grid.fit(X_train, y_train)
# 6. 输出结果
print("最优超参数:", grid.best_params_)
print("最优交叉验证准确率:", round(grid.best_score_, 4))
6 sklearn KNN API
6.1 分类 API
from sklearn.neighbors import KNeighborsClassifier
X = [[0],[1],[2],[3]]
y = [0,0,1,1]
knn = KNeighborsClassifier(3)
knn.fit(X, y)
print(knn.predict([[4]]))
6.2 回归 API
from sklearn.neighbors import KNeighborsRegressor
X = [[0,0,1],[1,1,0],[3,10,10]]
y = [0.1,0.2,0.3]
knn = KNeighborsRegressor(2)
knn.fit(X, y)
print(knn.predict([[3,11,10]]))
7 实战案例
7.1 鸢尾花分类(完整代码)

from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
iris = load_iris()
X_train, X_test, y_train, y_test = train_test_split(
iris.data, iris.target, test_size=0.2, random_state=22
)
trans = StandardScaler()
X_train = trans.fit_transform(X_train)
X_test = trans.transform(X_test)
knn = KNeighborsClassifier(3)
knn.fit(X_train, y_train)
print('准确率:', knn.score(X_test, y_test))
7.2 手写数字识别(完整代码)

import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
data = pd.read_csv('手写数字识别.csv')
X = data.iloc[:,1:] / 255
y = data.iloc[:,0]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
knn = KNeighborsClassifier(3)
knn.fit(X_train, y_train)
print('准确率:', knn.score(X_test, y_test))
8 核心考点总结
8.1 核心考点总结
-
KNN 是惰性学习,无显式训练过程
-
距离度量 + K 值 是两大核心
-
必须做标准化,否则距离计算失真
-
超参数调优 = 网格搜索 + 交叉验证
-
适合低维、小样本、分类 / 回归任务
8.2 核心考点解析
KNN 是惰性学习,无显式训练过程
意思:KNN 不训练模型,fit\(\) 只是把数据存起来,不计算任何参数、不学习任何规则。
关键点:
-
训练极快(只是存数据)
-
预测很慢(现场算所有距离)
-
没有 “学习” 过程,所以叫惰性学习
一句话背:KNN 不训练,只存数据;预测时临时算距离。
距离度量 + K 值 是两大核心
KNN 算法只靠这两个东西决定结果,别的都不重要。
① 距离度量(怎么算 “近不近”)
-
p=1曼哈顿距离(格子走法) -
p=2欧氏距离(直线距离)
② K 值(找几个邻居投票)
-
K 太小 → 过拟合(太敏感,受噪声影响)
-
K 太大 → 欠拟合(太笼统,失去局部特征)
一句话背:距离算相似度,K 值定模型复杂度。
必须做标准化,否则距离计算失真
这是 KNN 最容易丢分、最容易错的考点!
为什么必须标准化?
因为 KNN 完全依赖距离。如果特征量纲不一样(比如一个 0~1,一个 0~10000),数值大的特征会直接 “吃掉” 距离!
例子:
-
身高:170cm
-
收入:10000 元
不标准化 → 收入主导距离 → 模型完全失效。
标准化方法:StandardScaler 或 MinMaxScaler
一句话背:KNN 必须标准化,不标准必失真。
超参数调优 = 网格搜索 + 交叉验证
KNN 没有要学习的参数,只能手动调超参数。
要调的参数:
-
n\_neighbors:K 值 -
weights:uniform / distance -
p:距离公式
调参方法固定搭配:
GridSearchCV + 5 折交叉验证
作用:
-
遍历所有参数组合
-
自动选出最优的一组
-
防止过拟合,保证泛化能力
一句话背:KNN 调参 = 网格搜索 + 交叉验证。
适合低维、小样本、分类 / 回归任务
KNN 优点缺点都很明显,所以使用场景非常固定。
✅ 适合
-
数据维度不高(低维数据)
-
数据量不大(小样本)
-
分类任务、回归任务都能做
❌ 不适合
-
高维数据(维度灾难,距离失效)
-
大数据量(预测太慢)
-
实时性要求高的场景
一句话背:KNN 适合低维小样本,大数据高维别用它。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 9
9 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)