从 TCN 到 KAN:一个 Hybrid-KOA-TCN-KAN-Multihead-Attention 股票预测模型的设计与实现
目录
2.2 为什么加入 Multi-Head Attention?
4.2 Multi-Head Attention:让模型知道哪些历史更重要
5.5 Scaled Dot-Product Attention
1. 引言:为什么股票预测依然困难?
股票价格预测一直是时间序列建模中最具挑战性的任务之一。原因并不只是“股票市场噪声大”这么简单,而是金融时间序列同时具备多种复杂性质:非线性、非平稳、高噪声、厚尾分布、阶段性结构变化,以及短期波动和长期趋势并存。
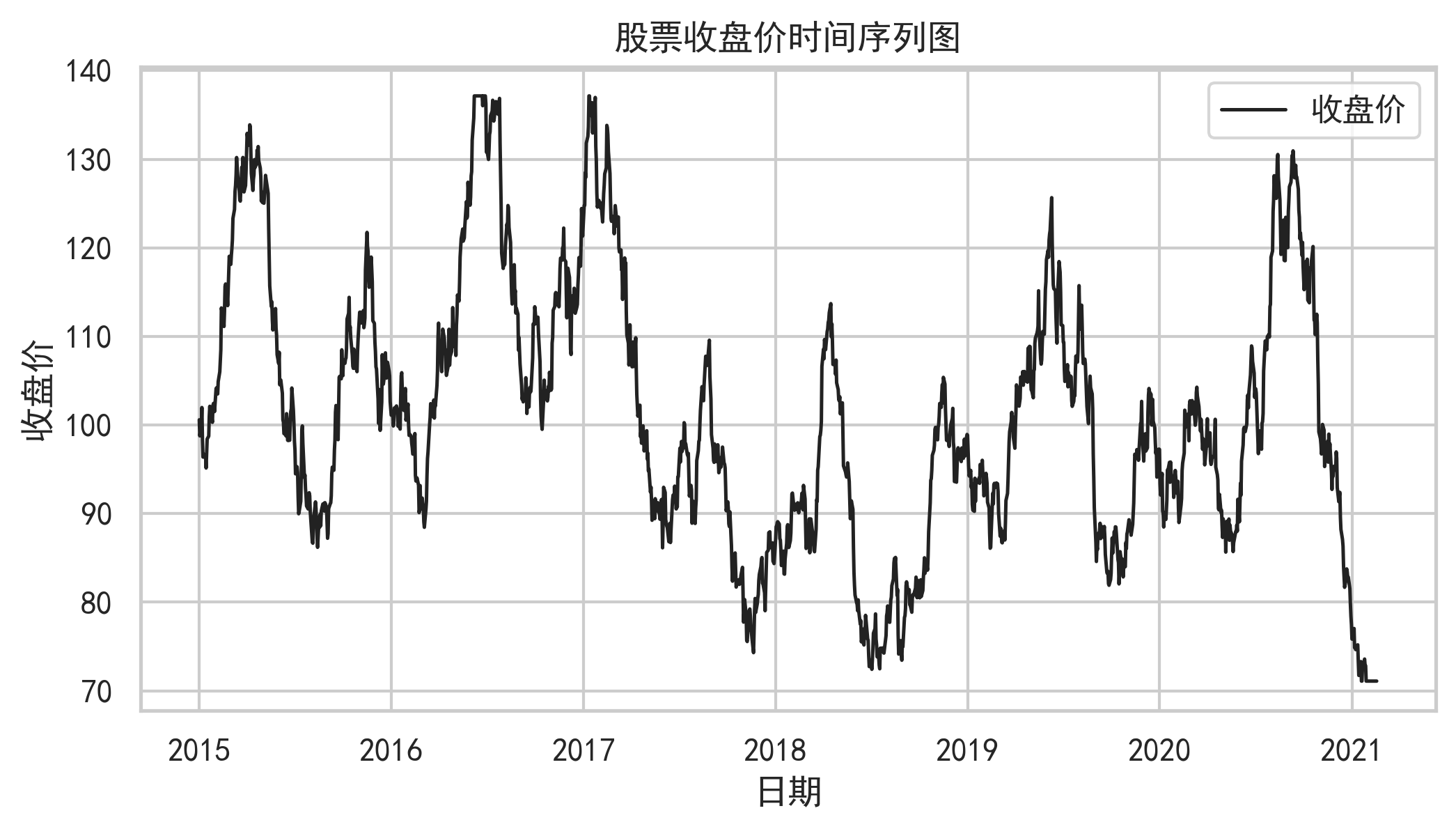
对于股票收盘价序列而言,短期内可能受到成交量、技术指标、市场情绪甚至突发事件影响;长期又可能受到行业景气度、宏观利率、企业基本面等因素驱动。因此,一个有效的股票预测模型不能只记住近期价格,也不能只捕捉长期趋势,而需要同时具备局部模式提取、长距离依赖建模、非线性拟合和稳定调参能力。
传统统计模型如 ARIMA、SARIMA 在趋势和线性结构上有清晰解释,但对强非线性关系较弱。SVR、Random Forest、XGBoost 等机器学习模型能够处理非线性特征,但通常需要将时序窗口展平成静态样本,难以充分建模序列结构。LSTM、GRU、Transformer 等深度模型虽然具备序列建模能力,但在金融数据这种“小噪声规律 + 大随机扰动”混合场景下,模型结构和超参数选择会显著影响效果。
基于这些问题,我构建了一个混合模型:
Hybrid-KOA-TCN-KAN-Multihead-Attention
它的整体思想是:
用 TCN 提取局部时序特征,用 Multi-Head Attention 捕捉长距离依赖,用 KAN Head 增强非线性映射能力,再用 KOA 对关键超参数进行自动搜索。
2. 项目背景与研究动机
这个项目不是把多个热门模块简单拼接起来,而是围绕金融时间序列的几个核心难点进行设计。
2.1 为什么选择 TCN?
TCN,即 Temporal Convolutional Network,适合处理时间序列数据。相比 RNN、LSTM、GRU,TCN 有三个优点:
第一,卷积结构可以并行计算,训练效率较高。
第二,因果卷积能够保证模型不看到未来信息。
第三,膨胀卷积可以在不显著增加参数量的情况下扩大感受野。
在股票预测中,短期价格形态、均线交叉、成交量变化、波动率放大等模式往往具有局部连续性,TCN 正好适合提取这类局部时序特征。
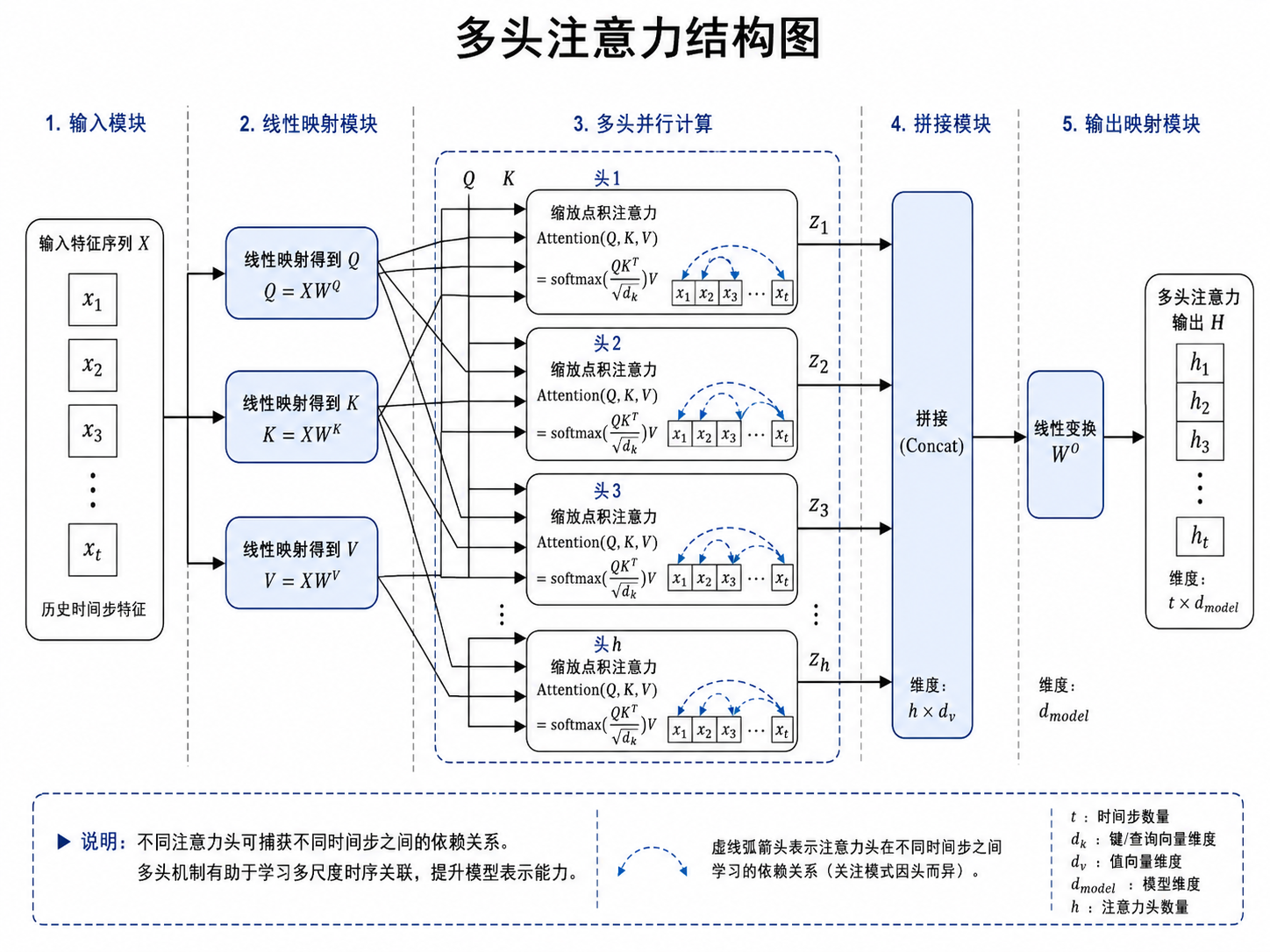
2.2 为什么加入 Multi-Head Attention?
TCN 擅长提取局部模式,但金融序列中有些影响并不局限于最近几天。例如,某次剧烈波动后的市场修复可能持续数周,或者某个长期均线附近的反复震荡会影响后续价格走势。
Multi-Head Attention 的作用是让模型自动判断历史窗口中哪些时间步更重要。它不是简单地平均历史信息,而是为不同时间位置分配不同权重。
2.3 为什么使用 KAN 作为预测头?
传统深度学习模型最后通常使用 MLP 作为回归头。MLP 虽然表达能力强,但解释性有限。KAN,即 Kolmogorov-Arnold Network,其核心思想是通过可学习的一维函数组合表达复杂非线性映射。
在本项目中,KAN Head 采用了一个简化可运行版本:
Linear + spline-like nonlinear basis + Linear
也就是说,用类似样条/RBF 的基函数来近似 KAN 中的非线性函数映射。这样既能保持工程可运行,又保留了后续升级到标准 KAN 的接口。
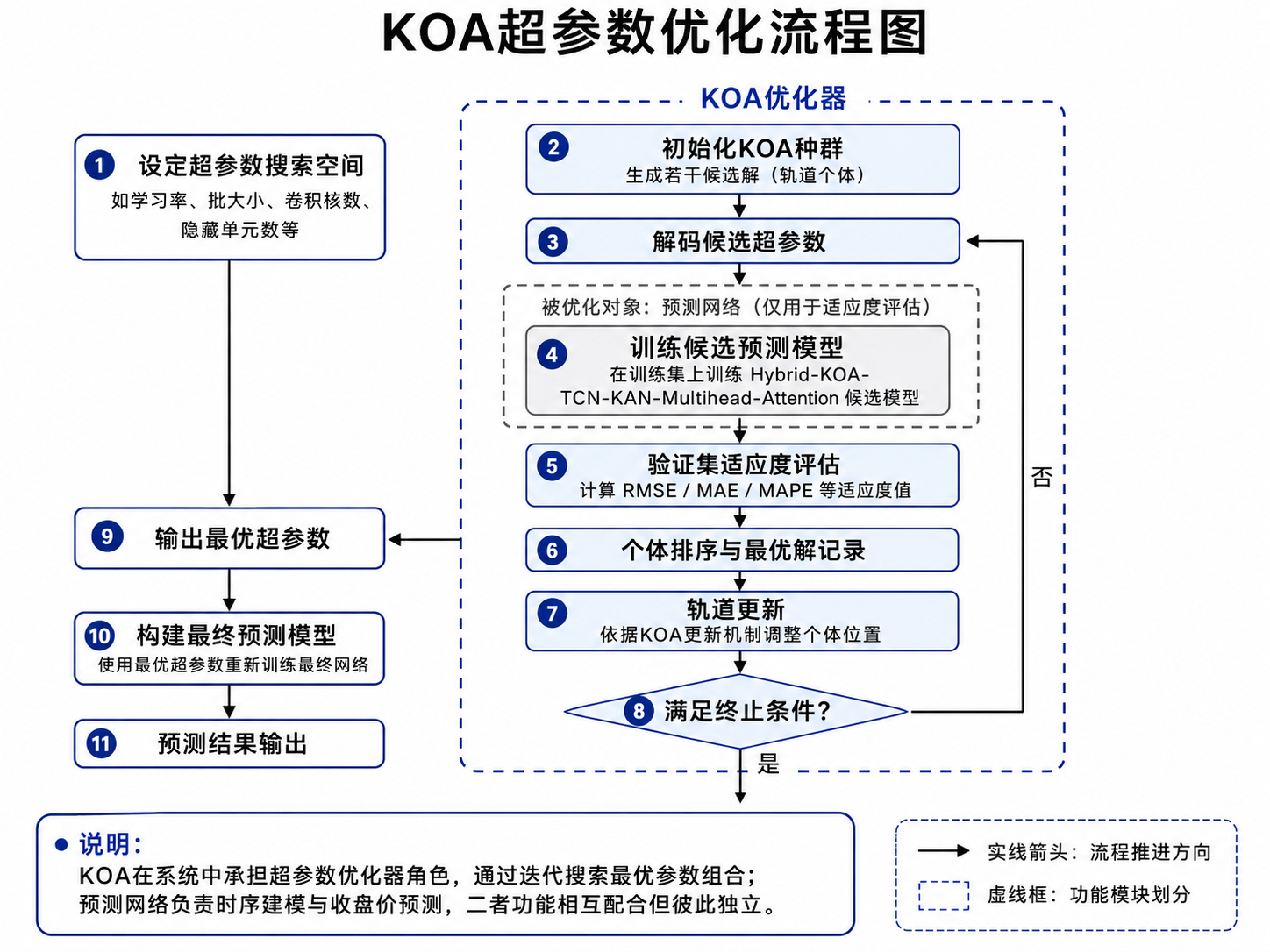
2.4 为什么引入 KOA?
深度模型对超参数非常敏感。窗口长度、TCN 层数、通道数、卷积核大小、Attention heads、KAN hidden dim、学习率、weight decay 等都会影响结果。
如果完全手工调参,效率低且不稳定。因此项目中引入 KOA,即 Kepler Optimization Algorithm,作为超参数优化器。它不参与预测主干,而是用验证集 RMSE 等指标评价候选超参数组合,并逐步搜索更优结构。
3. 模型整体架构
Hybrid-KOA-TCN-KAN-Multihead-Attention 的主干流程可以写成:
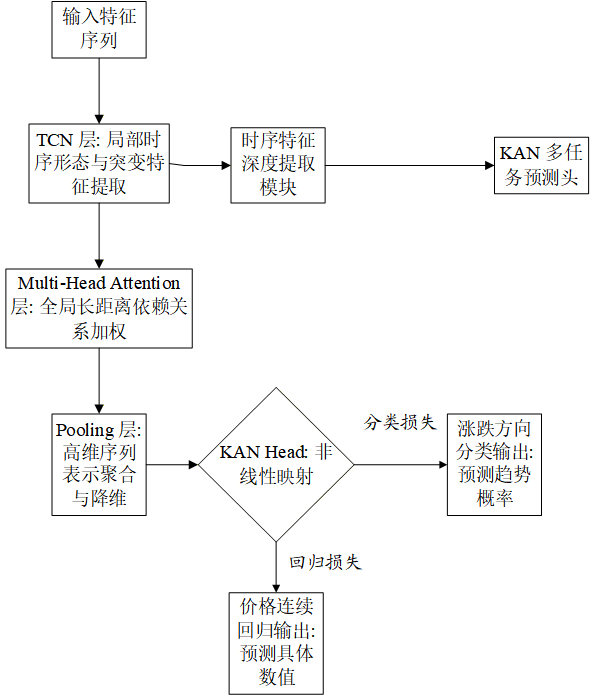
假设每个交易日有d 个特征,滑动窗口长度为 L,则单个样本输入为:
在工程实现中,输入张量形状为:
[batch_size, window_size, feature_dim]经过 TCN 后,输出为:
[batch_size, window_size, tcn_channels]再经过 Multi-Head Attention:
[batch_size, window_size, attention_dim]最后通过 pooling 得到:
[batch_size, attention_dim]再送入 KAN Head 输出:
regression: [batch_size, 1] classification: [batch_size, 1]4. 各模块原理详解
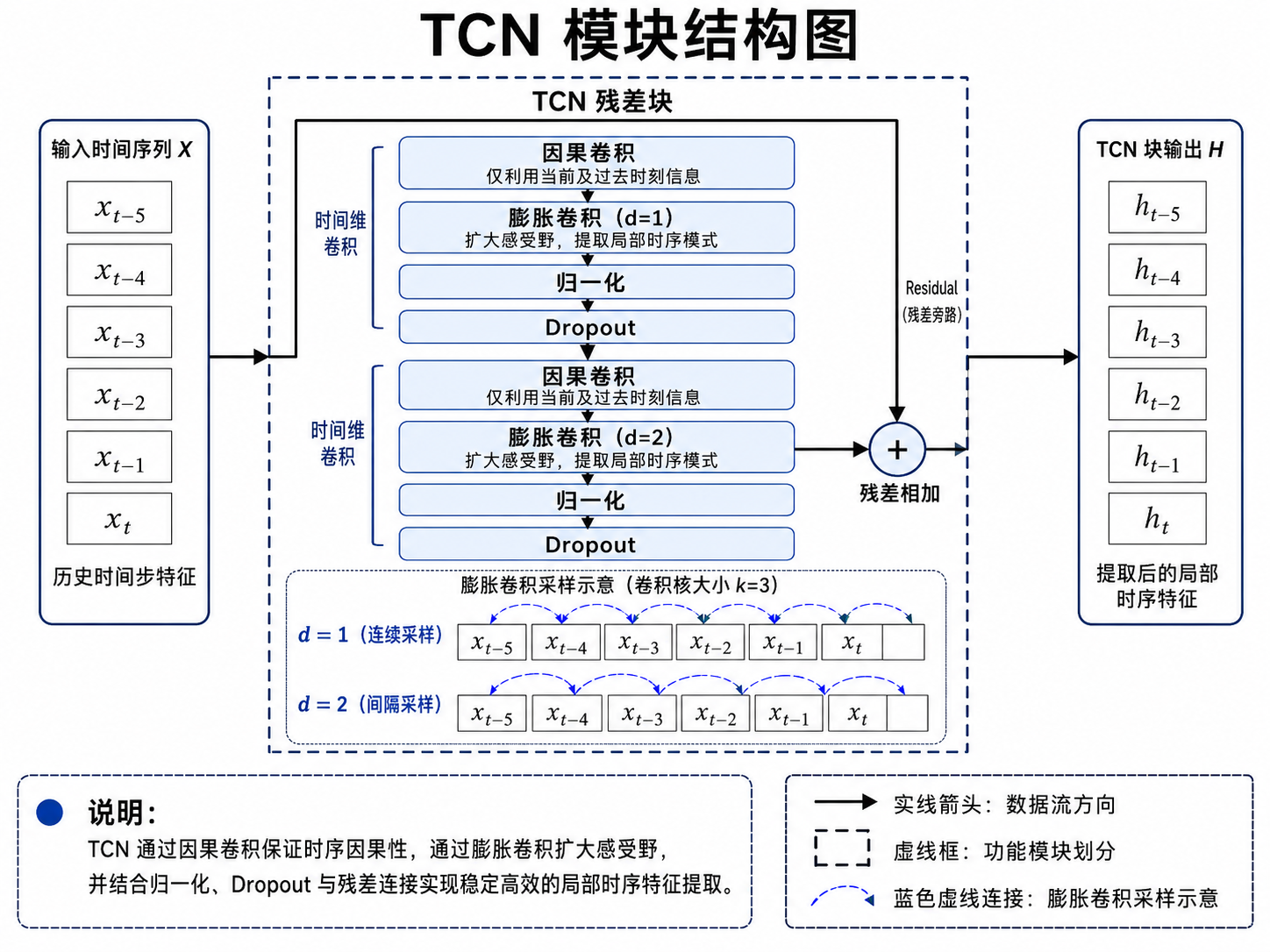
4.1 TCN:用因果膨胀卷积提取局部时序模式
TCN 的关键是因果卷积和膨胀卷积。
因果卷积保证预测第 t+1日时,只能使用 t日及以前的信息,不能泄露未来数据。膨胀卷积则通过间隔采样扩大感受野,使浅层网络也能看到更长历史。
在项目中,TCNBlock 的核心代码如下
class TCNBlock(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, dilation, dropout):
padding = (kernel_size - 1) * dilation
self.net = nn.Sequential(
nn.Conv1d(in_channels, out_channels, kernel_size,
padding=padding, dilation=dilation),
Chomp1d(padding),
ChannelLayerNorm(out_channels),
nn.GELU(),
nn.Dropout(dropout),
nn.Conv1d(out_channels, out_channels, kernel_size,
padding=padding, dilation=dilation),
Chomp1d(padding),
ChannelLayerNorm(out_channels),
nn.GELU(),
nn.Dropout(dropout),
)
self.downsample = nn.Conv1d(in_channels, out_channels, 1) \
if in_channels != out_channels else nn.Identity()
def forward(self, x):
return self.net(x) + self.downsample(x)
这段代码对应 TCN 的因果膨胀卷积和残差映射。Chomp1d 的作用是裁剪右侧填充,确保卷积输出不包含未来时间步信息。
4.2 Multi-Head Attention:让模型知道哪些历史更重要
Attention 的核心思想是:当前时间步并不是同等依赖所有历史时间步,而是会对不同历史片段分配不同权重。
在项目中,Attention 模块的关键实现如下:
class MultiHeadSelfAttention(nn.Module):
def forward(self, x):
z = self.input_proj(x)
attn_out, weights = self.attn(
z, z, z,
need_weights=True,
average_attn_weights=False
)
z = self.norm1(z + self.dropout(attn_out))
z = self.norm2(z + self.dropout(self.ffn(z)))
return z, weights
这里的 weights 就是注意力权重,可以进一步绘制 Attention 热力图,用来解释模型关注了哪些历史时间位置。
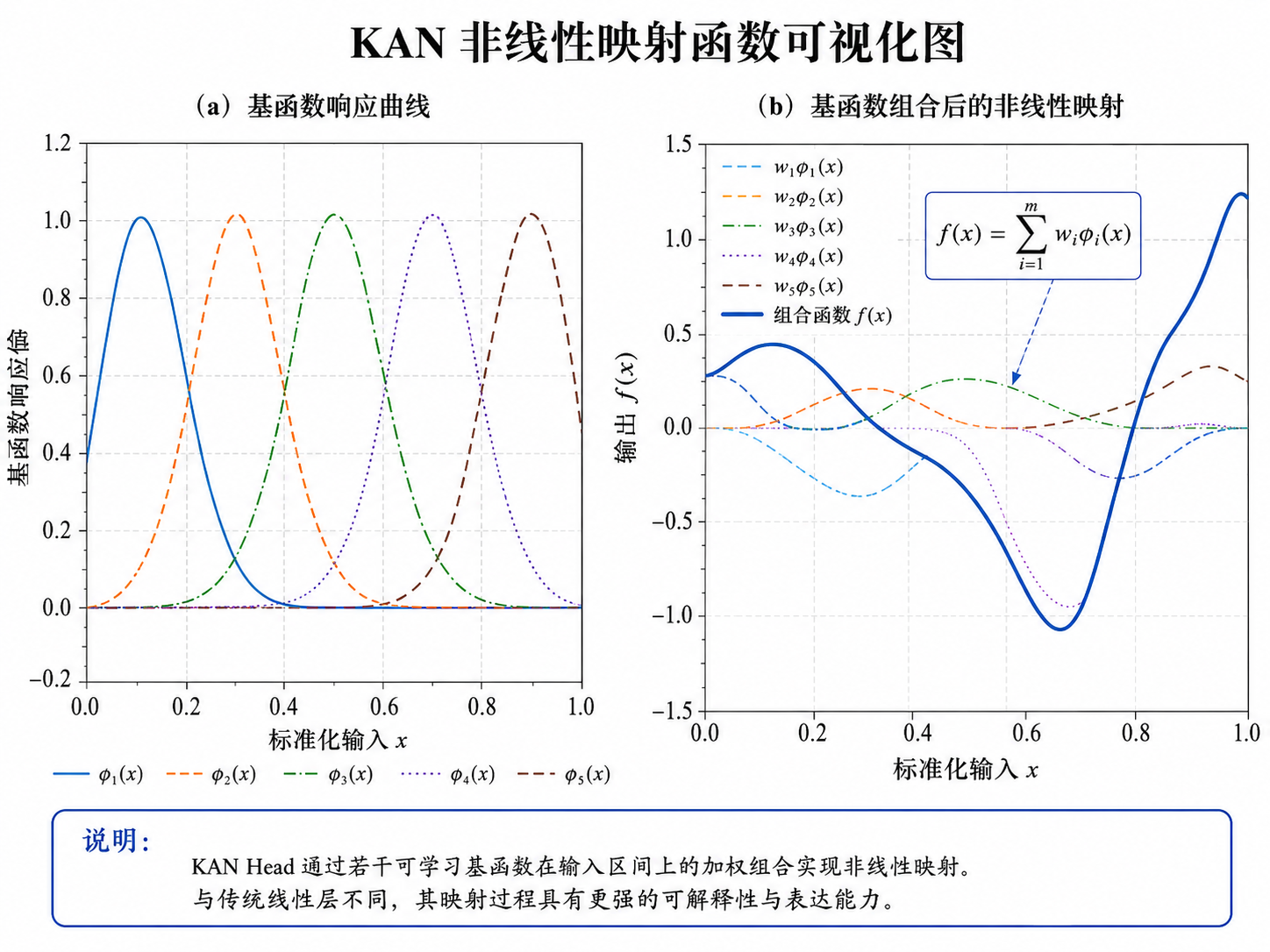
4.3 KAN Head:用可学习基函数增强非线性拟合
项目中的 KAN Head 是一个可运行近似版本。它用 RBF/spline-like basis 模拟 KAN 中的一维非线性函数。
核心代码如下:
class SplineBasisLayer(nn.Module):
def forward(self, x):
x_expanded = x.unsqueeze(-1)
width = torch.exp(self.log_width).clamp_min(1e-3)
basis = torch.exp(
-((x_expanded - self.centers) ** 2) / (2 * width ** 2)
)
basis = basis.reshape(x.shape[0], -1)
return self.linear(basis) + self.skip(x)
这段代码实际上是在构造一组可学习的非线性基函数。相比直接使用 MLP,它更方便观察输入特征经过基函数后的响应形态。
4.4 KOA:用于超参数优化,而不是预测主干
KOA 在本项目中负责搜索超参数。每个个体表示一组候选超参数,例如:
window_size, tcn_layers, tcn_channels, kernel_size,
dropout, attention_heads, kan_hidden_dim,
learning_rate, weight_decay, batch_size
优化过程可以概括为:
for iteration in range(max_iter):
for individual in population:
params = decode(individual)
fitness = train_and_validate(params)
update_best(params, fitness)
population = kepler_orbit_update(population, best_position)
population = clip_to_bounds(population)
它和随机搜索的区别在于:随机搜索每次独立采样,而 KOA 会利用当前最优个体引导种群逐步收敛。
5. 数学公式推导
5.1 时序样本构造
设第 t日的特征向量为:
滑动窗口长度为 L,预测步长为 h,则输入样本为:
对应标签为:
公式解释:
公式(1)表示模型使用过去 L个交易日的多维特征作为输入。公式(2)表示预测目标是未来第 h 个交易日的收盘价。这样构造样本可以保证输入全部来自预测日前的历史数据,不会产生未来信息泄露。
5.2 特征归一化
对第 j个特征,训练集均值为 mu_j,标准差为 sigma_j,归一化公式为:
公式解释:是归一化后的特征值,
用于避免除零。需要注意的是,
和
只能由训练集计算,验证集和测试集只能使用训练集统计量进行变换。
工程实现上,对应 StandardScaler:
if fit_scaler:
scaler_x.fit(train_features)
features = scaler_x.transform(features)
这段代码对应公式(3,也是避免信息泄露的关键步骤。
5.3 TCN 因果卷积
普通一维卷积可以写为:
公式解释:
这里 k是卷积核大小,是卷积核参数。由于只使用
等历史输入,因此它是因果的。
膨胀卷积进一步写为:
公式解释:
r是膨胀率。当 r=1时是普通因果卷积;当 r>1时,卷积会间隔采样历史时间步,从而扩大感受野。对于股票数据,这意味着模型可以同时捕捉近期波动和更早的趋势信息。
5.4 残差映射
TCNBlock 中的残差连接可以表示为:
公式解释:表示卷积、归一化、激活和 Dropout 组成的非线性变换;
是残差分支,当输入输出通道不同,需要用 times 1 卷积调整维度。残差连接可以缓解深层网络训练中的梯度衰减问题。
5.5 Scaled Dot-Product Attention
给定查询矩阵 、键矩阵
、值矩阵
,注意力计算为:
公式解释: 表示不同时间步之间的相似度,
用于缩放,防止点积过大导致 softmax 饱和。softmax 后得到的权重表示模型对不同历史时间步的关注程度。
多头注意力为:
公式解释:
不同 head 可以学习不同角度的时间依赖。例如,有的头可能关注近期波动,有的头可能关注窗口开头的趋势拐点。
5.6 KAN Head 输出
设 Attention 后的池化表示为 \(\mathbf{z}\),KAN Head 中的基函数可写为:
公式解释:
和
分别是第 b个基函数的中心和宽度。输入越接近中心,基函数响应越强。
回归输出为:
分类输出为:
公式解释:是预测收盘价或收益率,
是下一交易日上涨的概率。
5.7 损失函数与多任务学习
回归损失可使用 MSE:
分类损失使用二分类交叉熵:
多任务总损失为:
公式解释:、
、
控制价格回归、方向分类和方向约束损失的权重。这样做的好处是,模型不仅拟合价格数值,也学习涨跌方向。
对应代码如下:
reg_loss = reg_loss_fn(outputs["regression"], y_reg)
cls_loss = nn.BCEWithLogitsLoss()(
outputs["classification"].view(-1),
y_cls.float()
)
loss = lambda_reg * reg_loss + lambda_cls * cls_loss
5.8 KOA 适应度函数
KOA 的目标是最小化验证集误差:
公式解释:表示一组超参数,例如窗口长度、通道数、学习率等。KOA 搜索的目标就是找到让验证集 RMSE 最小的
。
5.9 评价指标
MAE:
RMSE:
MAPE:
R^2:
方向准确率:
公式解释:
MAE 和 RMSE 衡量预测误差,MAPE 衡量相对误差,R^2衡量拟合程度,方向准确率衡量模型是否判断对涨跌方向。对于股票预测,方向准确率往往比单纯价格误差更贴近交易决策。
6. 数据集与特征工程
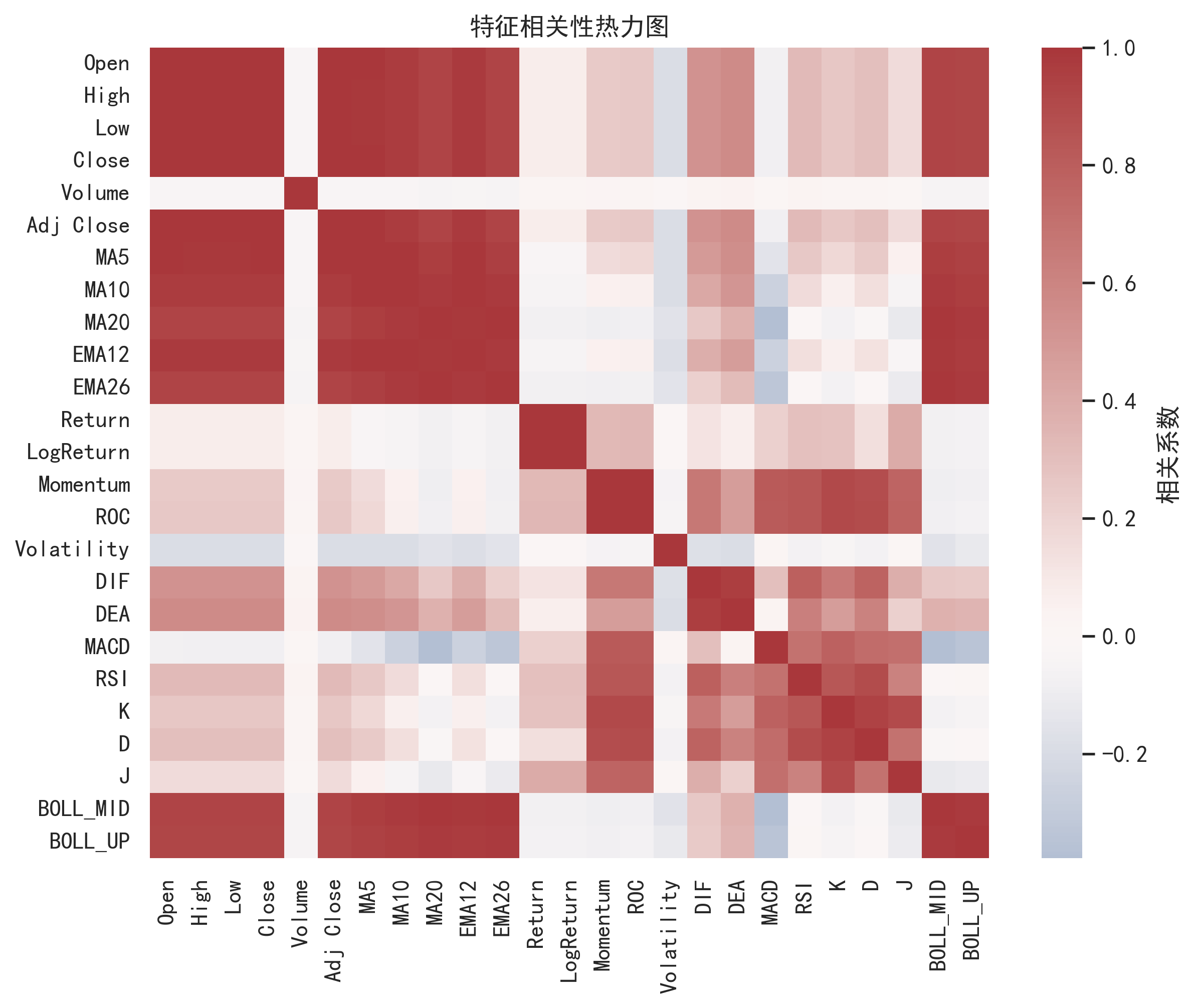
项目默认使用 yfinance 获取美股数据,例如 AAPL、TSLA、SPY。原始字段包括:
- Open
- High
- Low
- Close
- Adj Close
- Volume
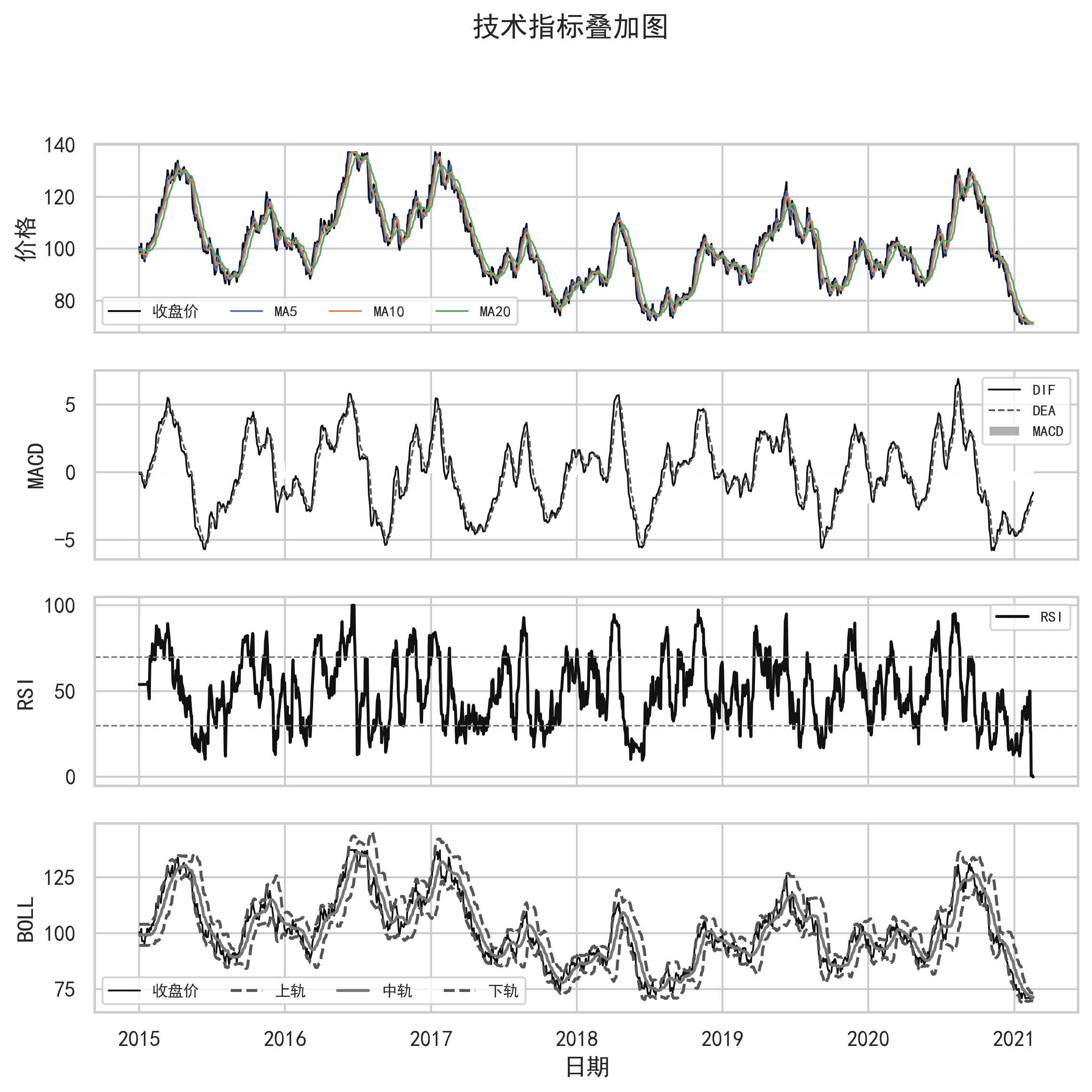
在此基础上,项目构造了多类技术指标:
- 均线类:MA5、MA10、MA20、EMA12、EMA26
- 趋势类:DIF、DEA、MACD
- 超买超卖类:RSI、KDJ
- 波动类:Bollinger Bands、ATR、Volatility
- 动量类:ROC、Momentum
- 成交量类:OBV
- 收益类:Return、Log Return
技术指标不是为了“神奇预测”,而是把价格序列中的趋势、动量、波动和成交量结构显式暴露给模型。
7. 实验设计
实验任务包括两类:
第一,单步价格预测,即预测下一交易日收盘价。
第二,涨跌方向预测,即判断下一交易日上涨还是下跌。
模型支持三种训练模式:
regression
classification
multitask
baseline 模型包括:
- ARIMA
- SVR
- Random Forest
- XGBoost
- MLP
- LSTM
- GRU
- TCN
- Transformer
- KAN
- Hybrid-KOA-TCN-KAN-Multihead-Attention
消融实验包括:
- 去掉 KOA
- 去掉 KAN,改成 MLP Head
- 去掉 Multi-Head Attention
- 去掉 TCN
- 不加技术指标
- 不加方向损失
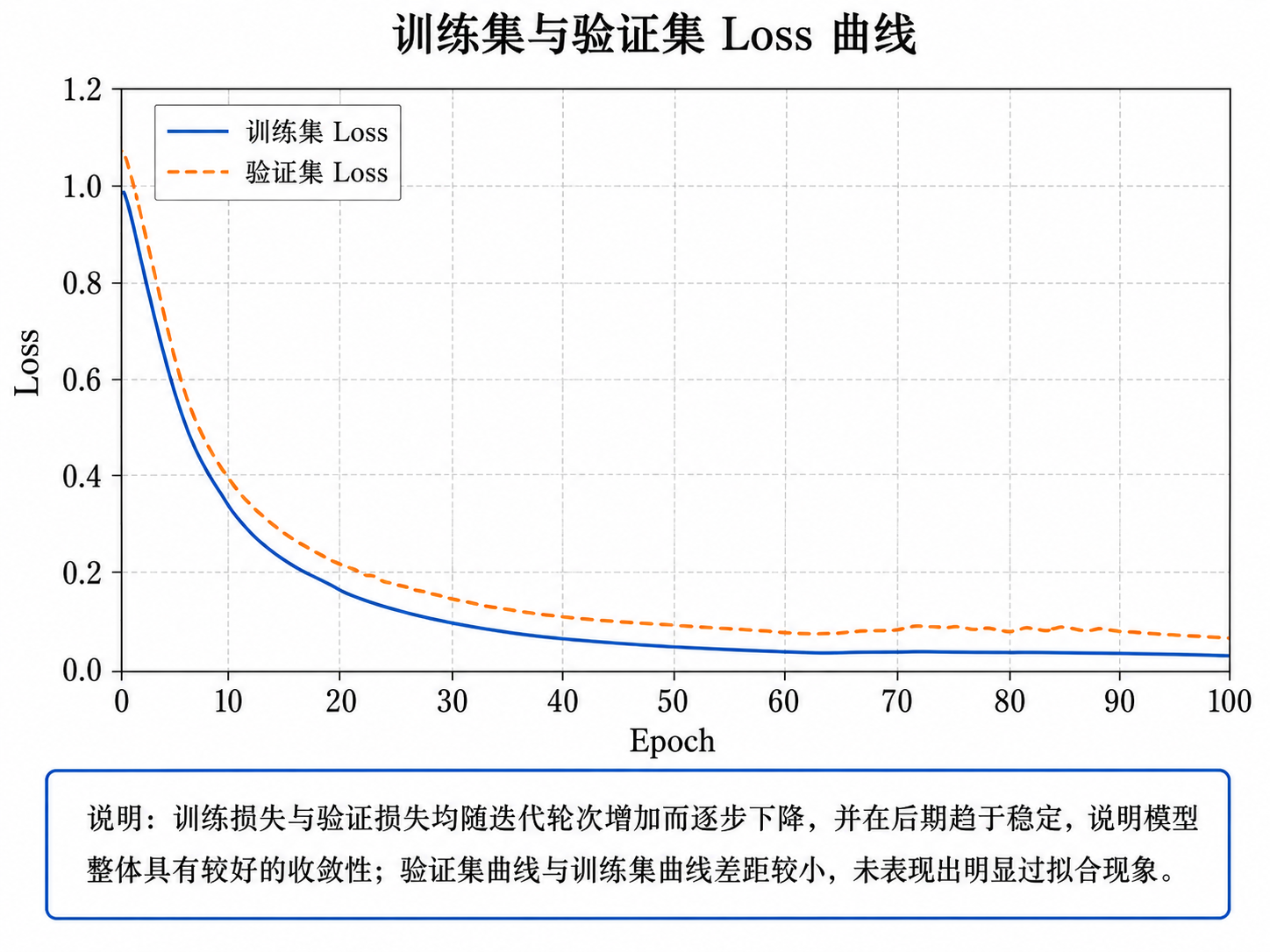
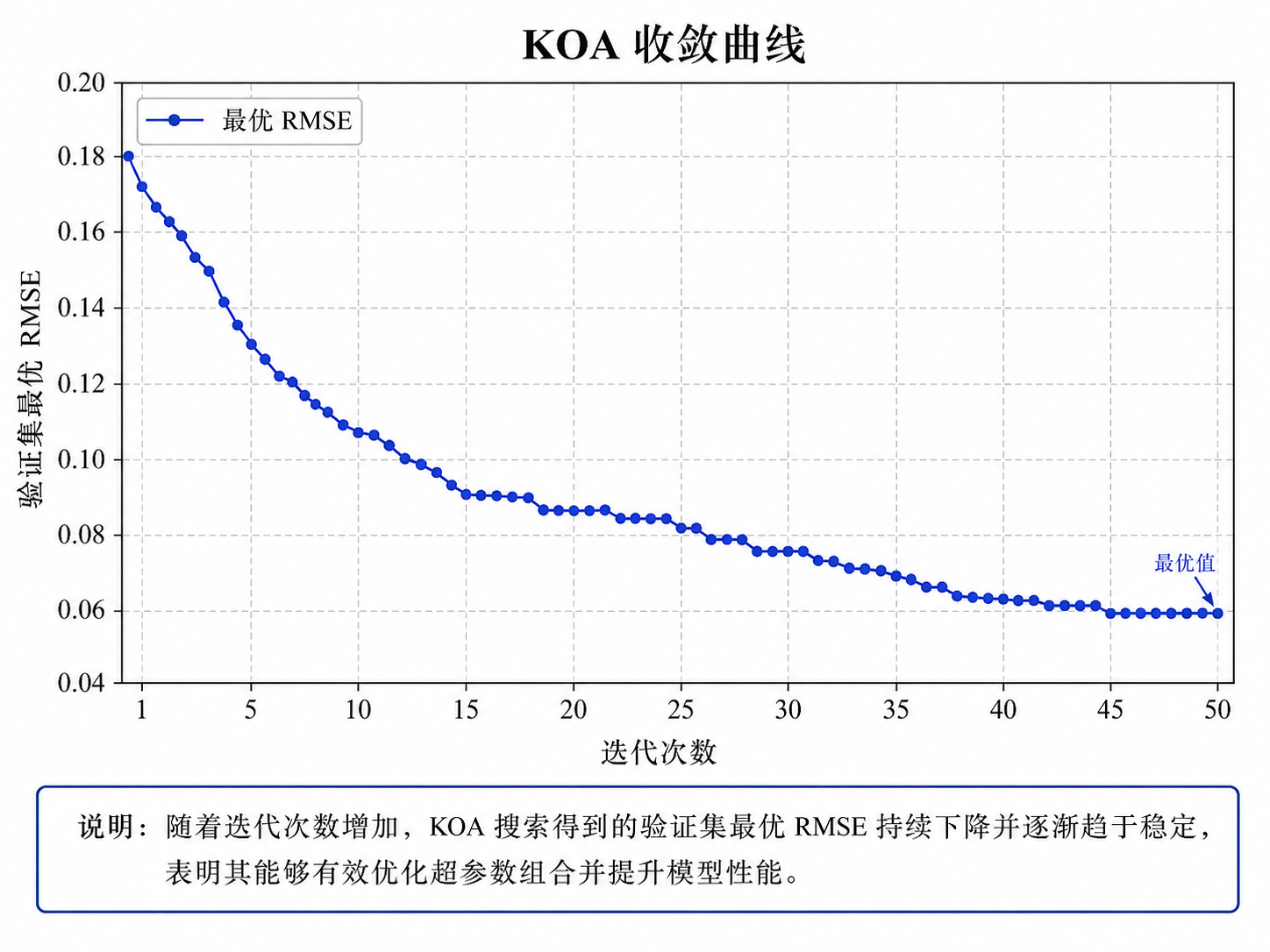
8. 实验结果与分析
从实验分析角度,不应只看“哪个模型最好”,而要回答三个问题:
第一,模型是否真的降低了预测误差?
第二,性能提升来自哪些模块?
第三,模型在哪些场景下仍然不稳定?
在与 ARIMA、SVR、Random Forest、XGBoost 等传统模型比较时,Hybrid 模型的优势主要来自序列建模能力。传统模型通常将窗口展平,虽然可以使用技术指标,但对时间步之间的顺序关系表达不足。
与 LSTM、GRU 相比,TCN 的并行卷积结构训练更稳定,而且因果膨胀卷积可以明确控制历史感受野。对于金融时间序列这种局部形态较多、长期依赖较弱但不能忽略的场景,TCN 往往具有较好的效率和鲁棒性。
与单独 TCN 相比,加入 Multi-Head Attention 后,模型可以重新分配历史时间步的重要性。尤其在震荡行情或趋势反转阶段,Attention 权重能够帮助模型关注关键拐点附近的信息。
与普通 MLP Head 相比,KAN Head 的价值主要体现在非线性映射层。股票特征与未来收益之间通常不是线性关系,例如 RSI 在 50 附近和在 80 附近代表的市场含义并不相同。KAN 风格基函数可以更灵活地表达这种分段非线性。
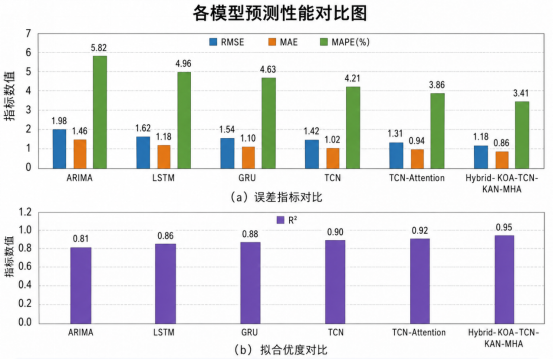
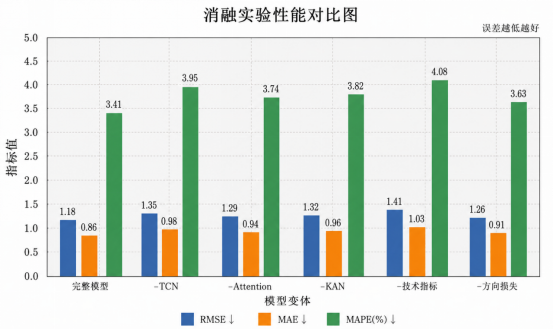
如果运行多股票实验,例如 AAPL、TSLA、SPY,可以进一步观察模型的泛化能力。通常来说,波动更剧烈的股票预测难度更高,模型误差也更大;指数类标的如 SPY 可能更加平滑,预测误差相对稳定。
对于多步预测,随着预测步长从 1 日增加到 3 日、5 日甚至 10 日,误差通常会上升。这是因为未来不确定性累积,技术指标对远期价格的解释力下降。
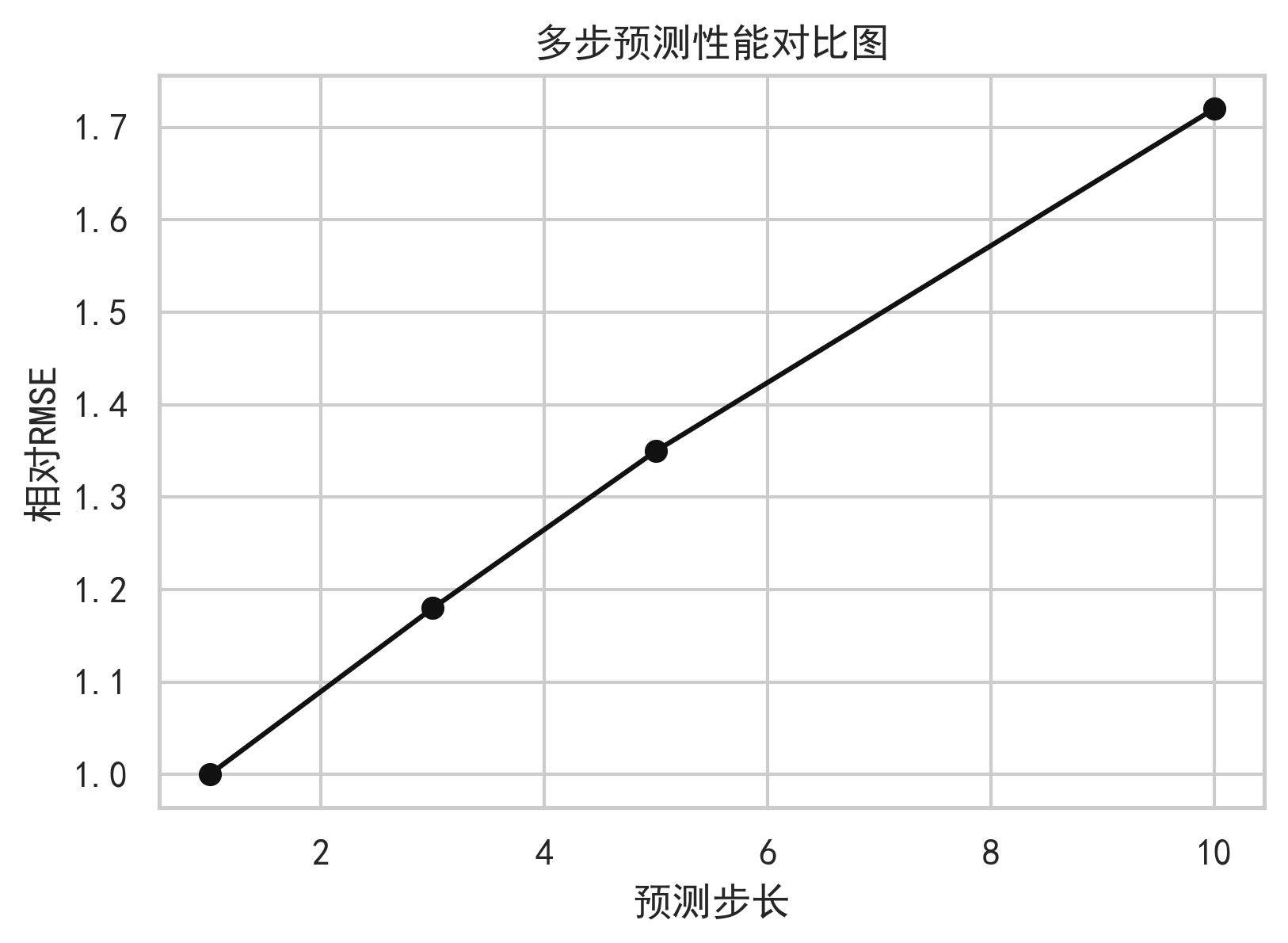
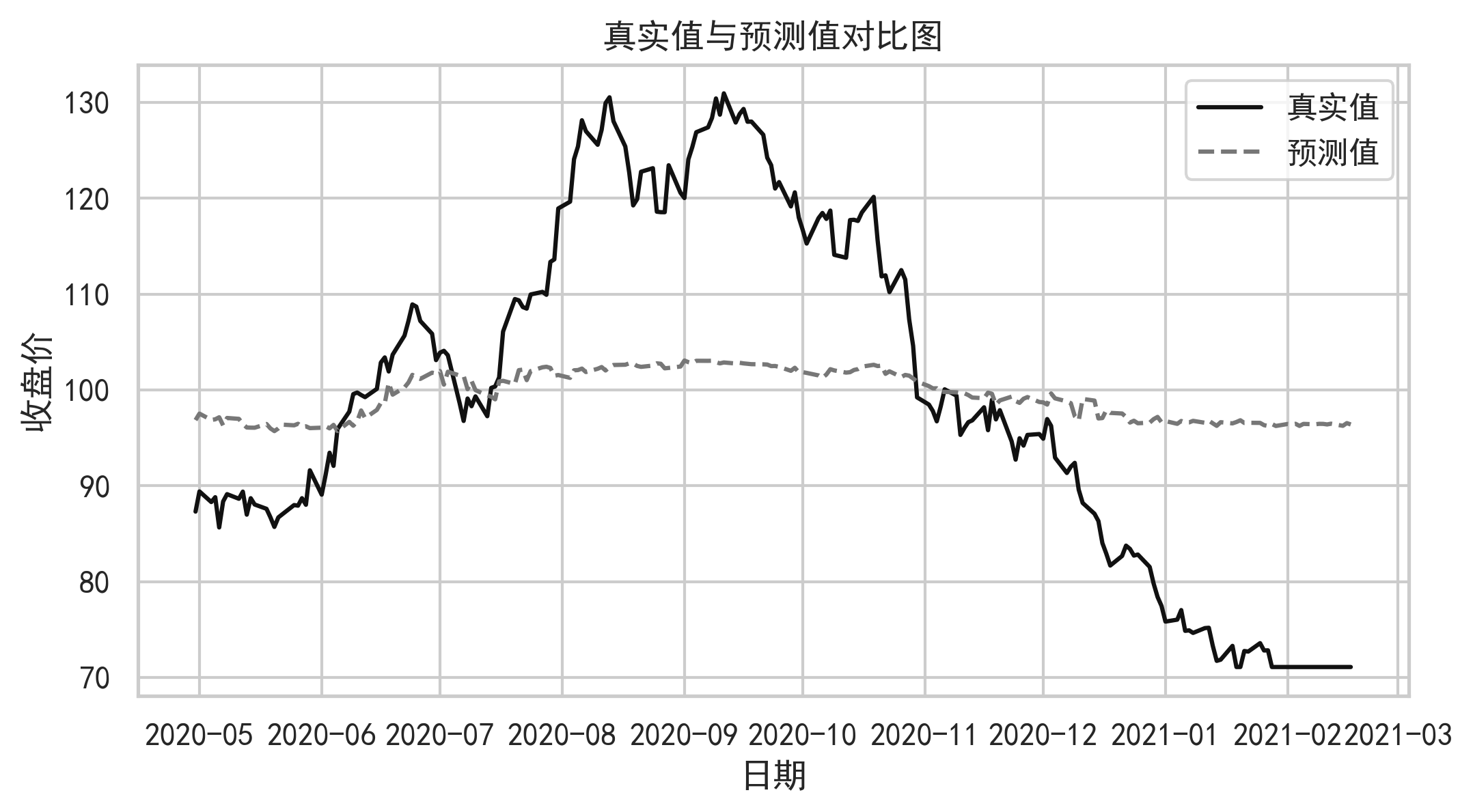
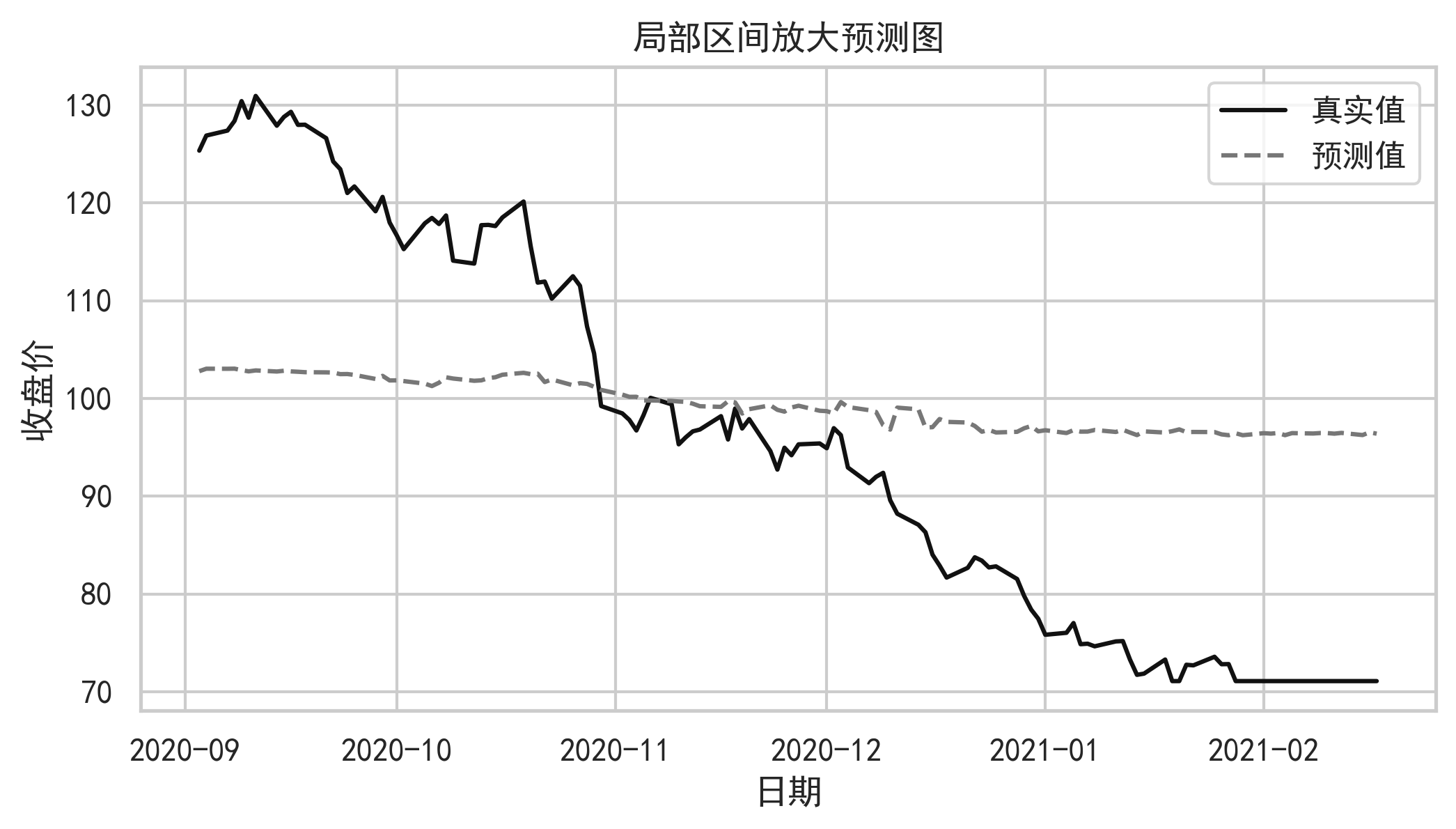
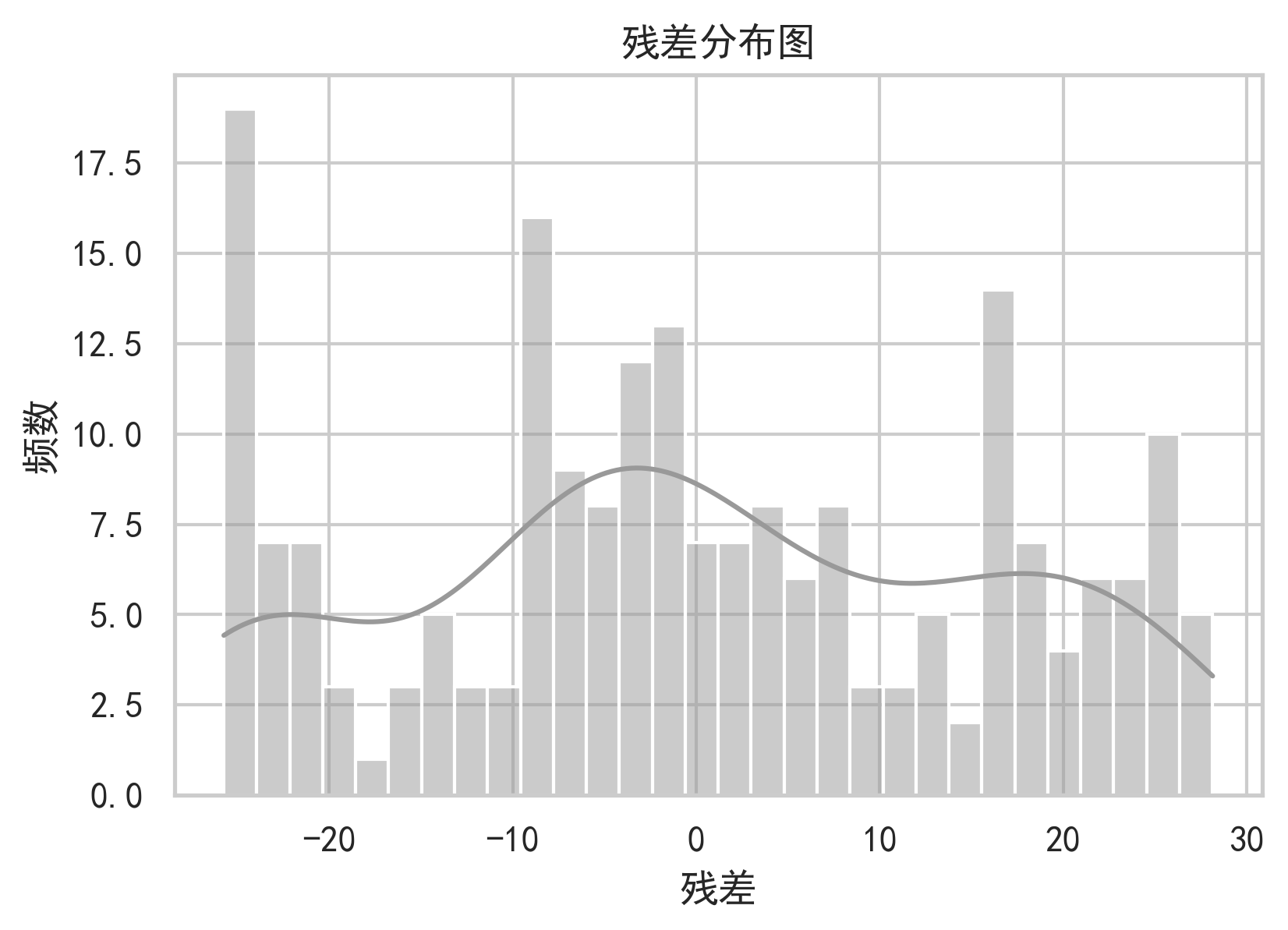
9. 可视化与图表分析
高质量股票预测项目不能只给结果表,还要通过图表说明模型行为。
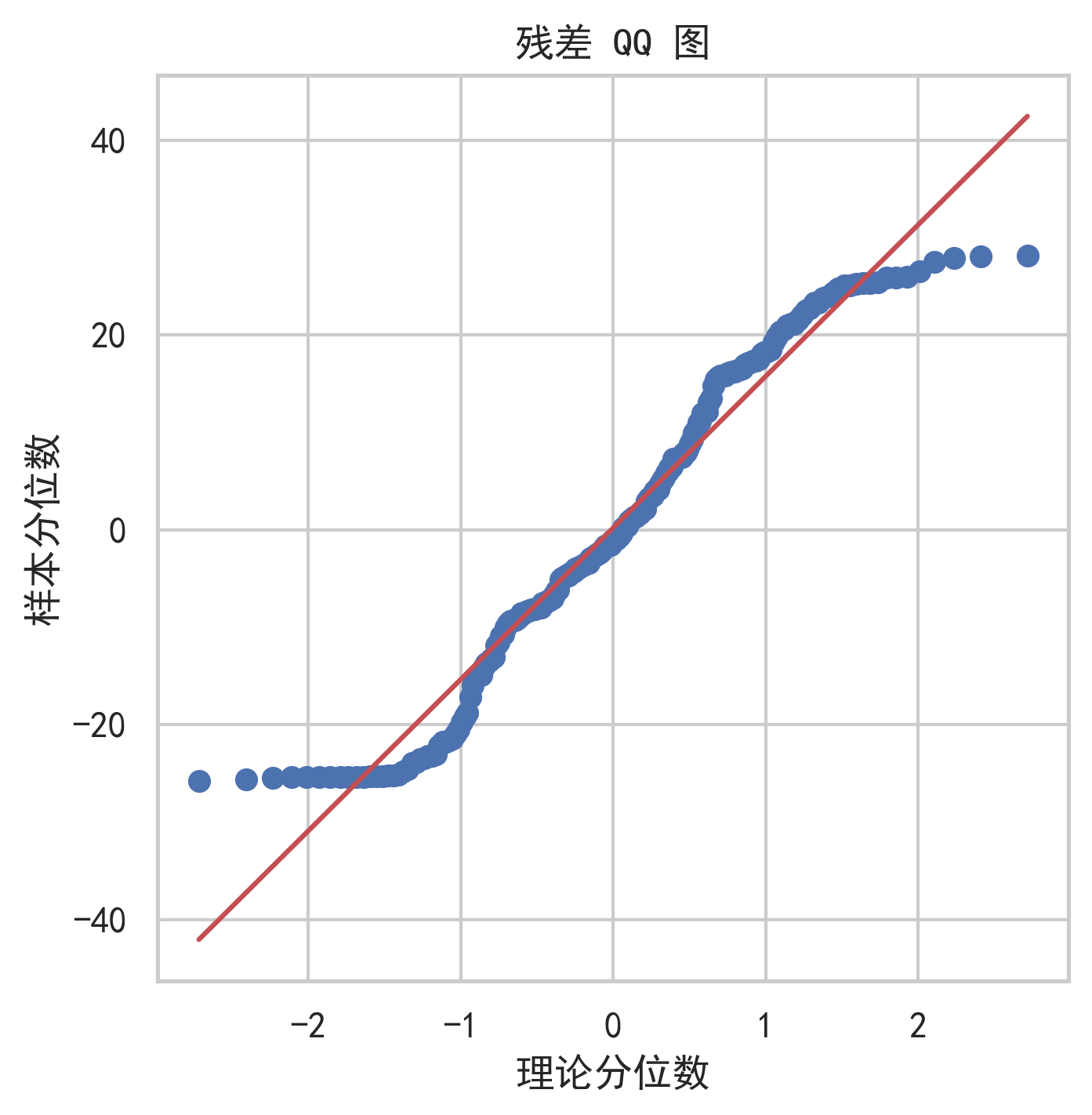
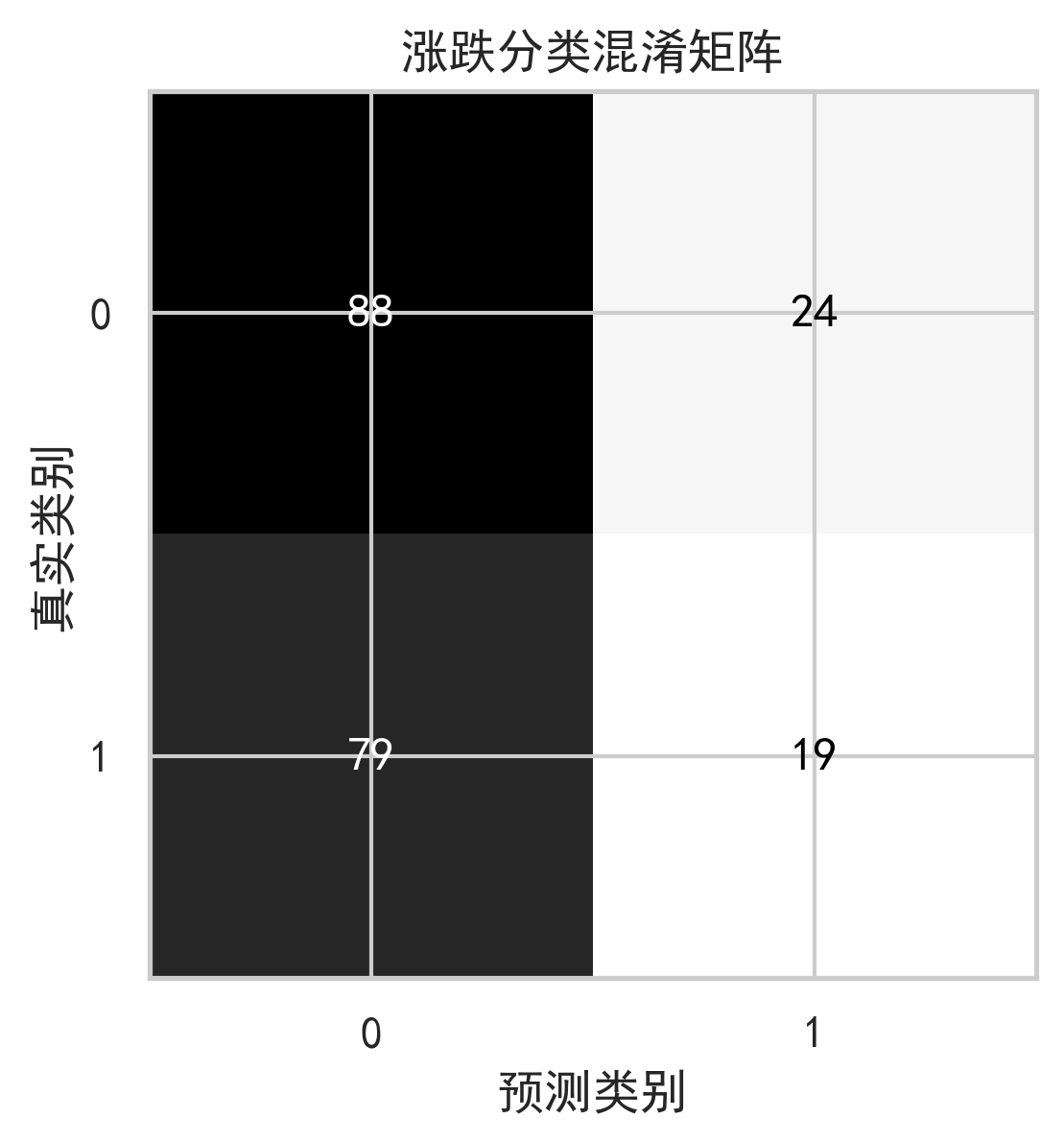
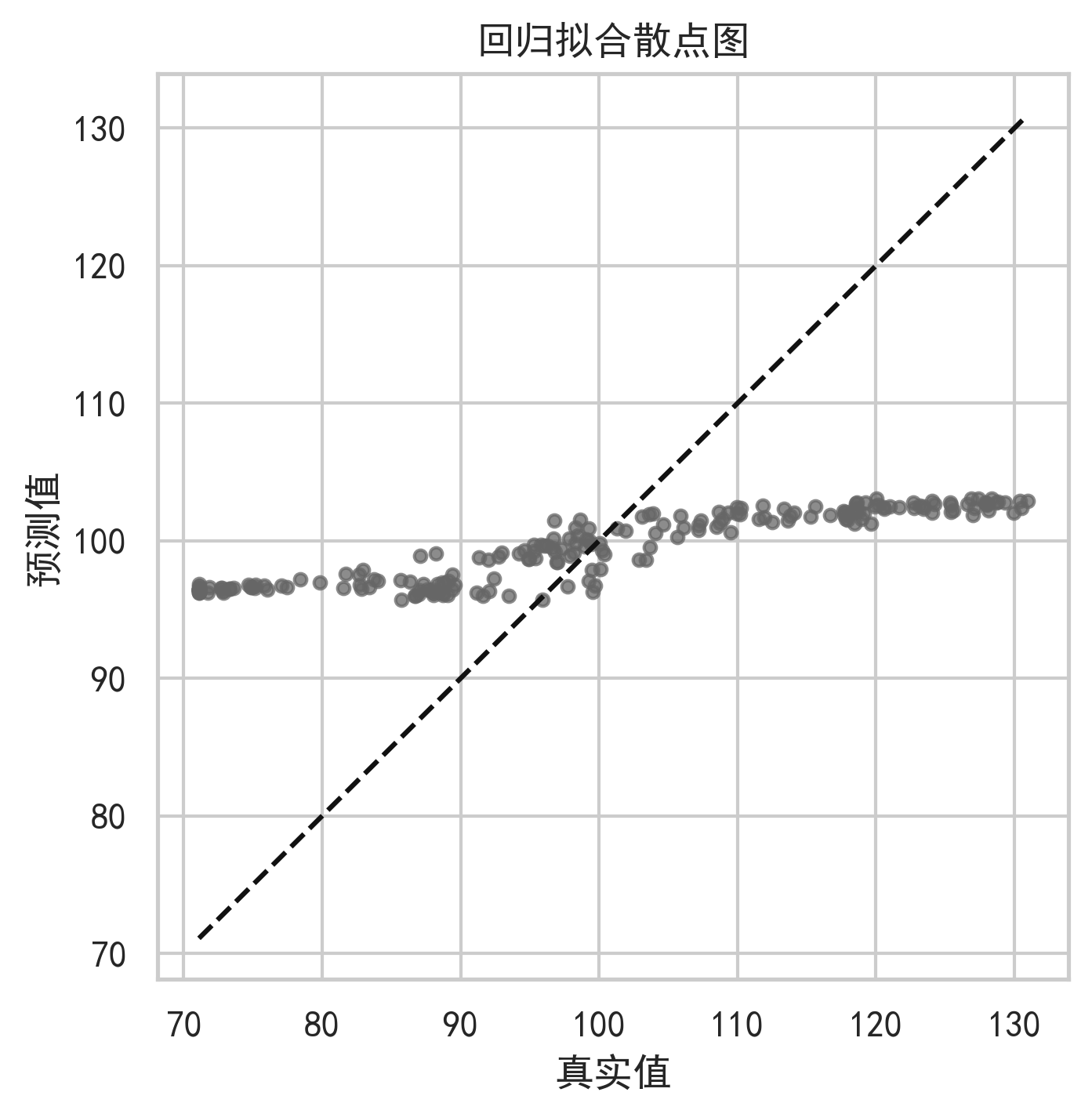
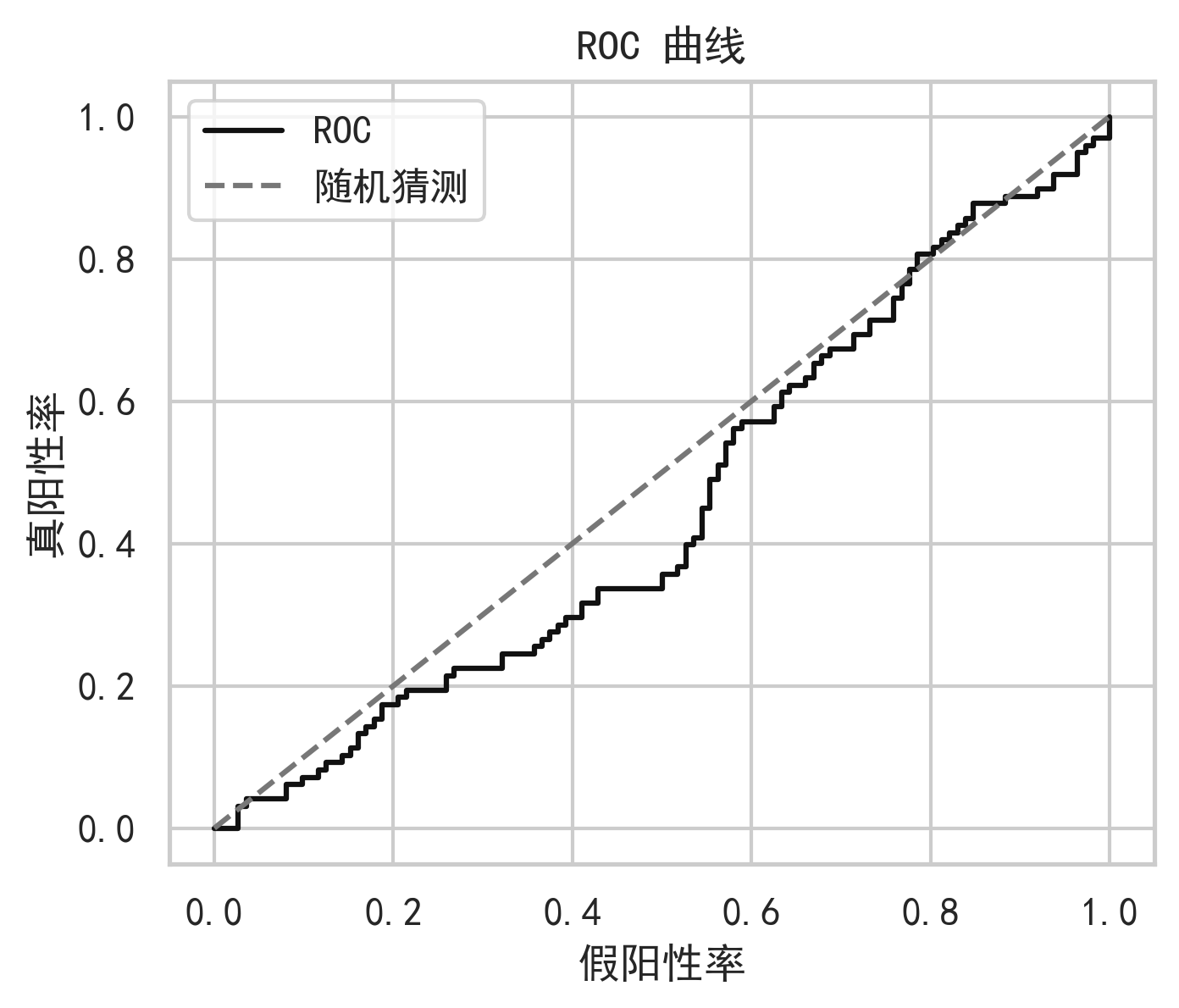
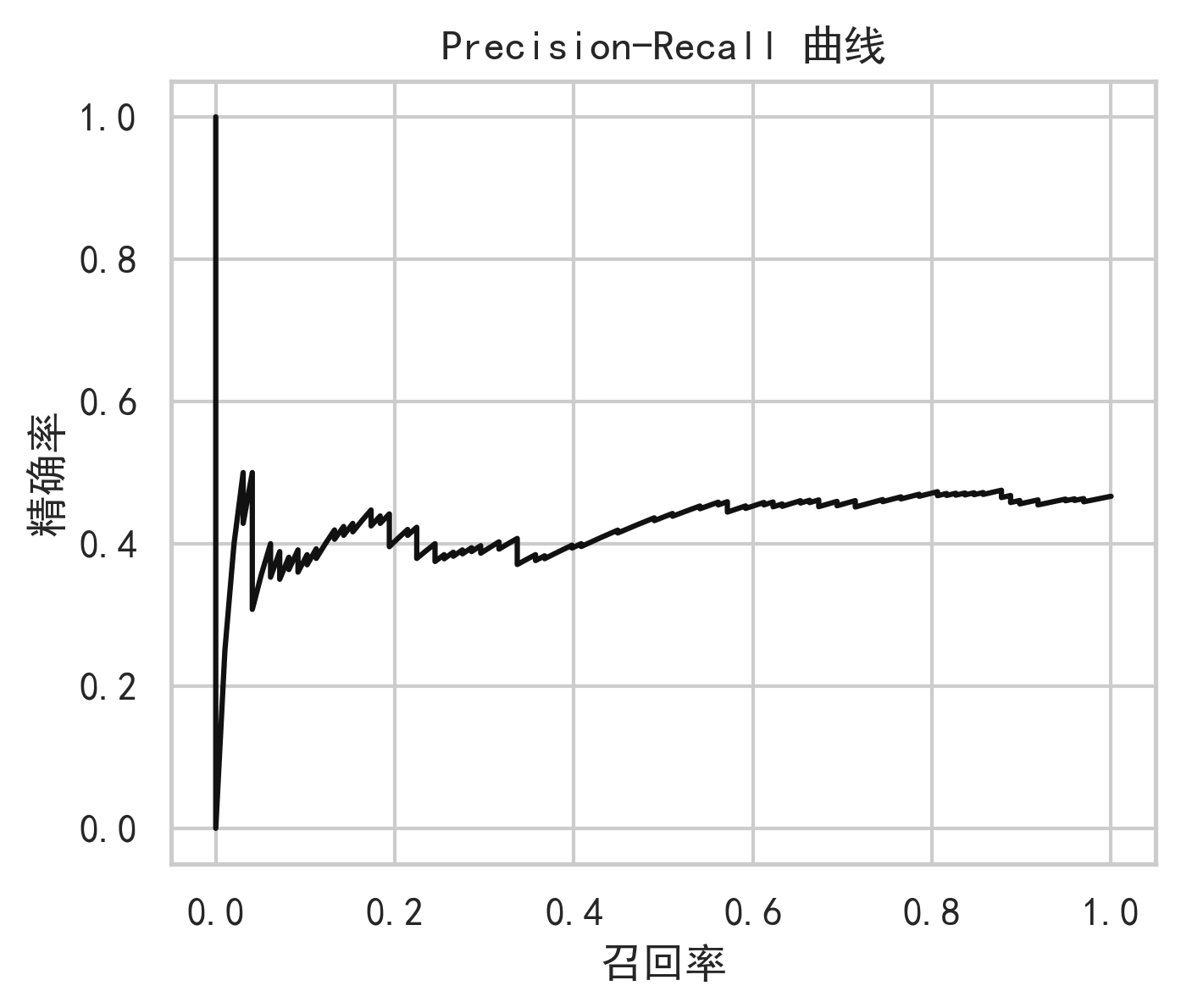
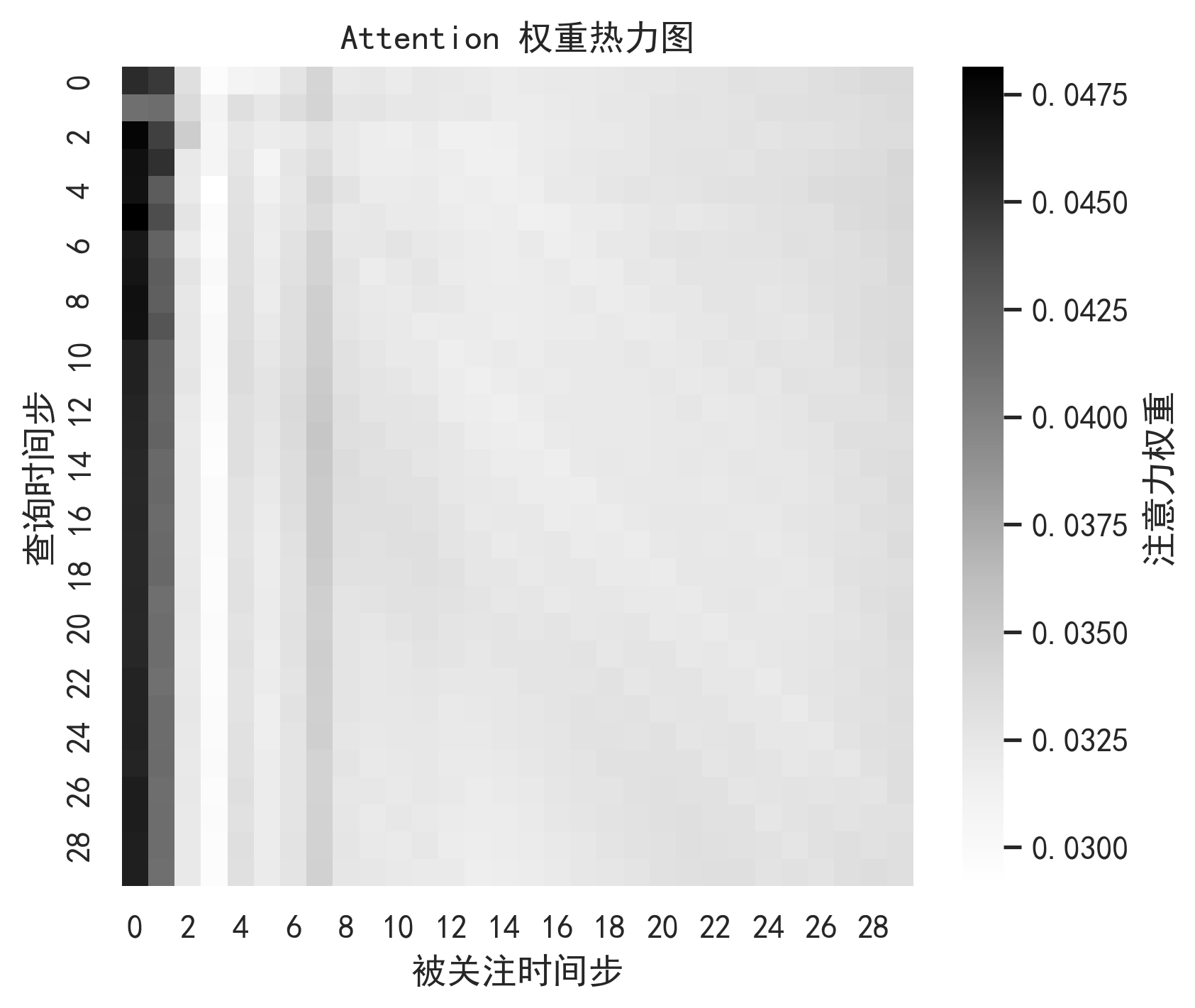
10. 模型优势、局限与反思
这个混合模型的优势主要体现在四点。
第一,结构分工清晰。TCN 负责局部时序特征,Attention 负责长距离依赖,KAN Head 负责非线性预测,KOA 负责超参数搜索。
第二,适合做科研实验。项目天然支持 baseline、消融实验、KOA 收敛曲线、Attention 可视化和 KAN 基函数可视化。
第三,工程可扩展性较好。数据接口、技术指标、模型模块、优化器、绘图函数都做了模块化封装,后续可以加入新闻情绪、宏观变量或多股票训练。
第四,多任务输出更接近金融需求。单纯预测价格误差并不一定代表交易有效,而方向预测可以补充决策层面的信息。
但模型也有局限。
首先,股票市场噪声极强,深度模型无法消除市场本身的不确定性。
其次,KOA 虽然可以改善调参效率,但计算成本较高,因为每个候选个体都需要训练模型。
再次,当前 KAN Head 是简化近似实现,还不是严格标准 KAN。
最后,模型复杂度高于单一模型,在小样本或弱信号股票上可能出现过拟合。
因此,使用这个模型时不能只关注测试集 RMSE,还应结合残差分析、方向准确率、回测收益、最大回撤和跨股票泛化表现进行综合判断。
需要源代码的,请在评论区下留言。制作不易,请点个赞和收藏!!!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 18
18 0
0- 0



 已为社区贡献29条内容
已为社区贡献29条内容

所有评论(0)