Java开发者AI转型第二十一课!吃透Spring AI MCP底层源码,彻底告别黑盒调用
大家好,我是直奔標杆!专注Java开发者AI转型实战分享,和大家一起从零基础吃透Spring AI,拒绝浅尝辄止,共同成长进阶~
欢迎来到《Spring AI 零基础到实战》系列的第二十一课!上两节课我们手把手完成了MCP实战,通过@McpTool、@McpSampling等注解,轻松实现了大模型与Spring Boot应用的跨网络双向通信,很多小伙伴留言说“配置即用”太便捷,但也有不少追求进阶的同学问:底层到底是怎么流转的?
作为Java后端开发者,咱们不能只做“框架搬运工”——会配YAML、会写注解只是入门,真实生产环境里,网络波动导致MCP连接异常、异构Server返回非标准JSON-RPC数据包引发反序列化报错,这些问题都需要我们能直击底层排查根源。如果对源码流转一无所知,乱改配置试错,无异于给生产环境埋雷⚠️
今天,直奔標杆就和大家一起深扒Spring AI MCP的源码脉络,从源码层面拆解:一个普通的Java方法调用,如何被包装成标准JSON-RPC协议,跨网络精准触发对端逻辑,彻底打破“黑盒调用”的壁垒!
温馨提示:本节课的源码剖析,基于上一节课我们配置的streamable模式。Spring AI还支持SSE以及微服务架构下的Stateless(无状态)模式,它们的底层调度器与责任链设计高度一致,吃透streamable,其他模式就能触类旁通,大家可以重点掌握~
本节学习目标(一起打卡进阶)
-
源码透视:深入剖析Server端响应式路由机制,搞懂WebFlux如何充当流量分发中枢,理解响应式编程在MCP中的核心作用;
-
握手解密:穿透Client启动源码,拆解大模型与外部系统“交换外交国书”(Initialize)的底层细节,搞懂连接建立的完整流程;
-
闭环追踪:从客户端一行callTool代码出发,完整追踪JSON-RPC数据包在服务端的逆向拆解与反射调用,摸清Tool调用的全链路。
MCP源码流转全景图(先有全局认知)
在深入代码之前,咱们先看一张全景图(建议收藏),快速了解Spring AI底层源码如何接管并流转MCP数据包,后续拆解源码时,大家可以对照这张图理解,会更清晰:
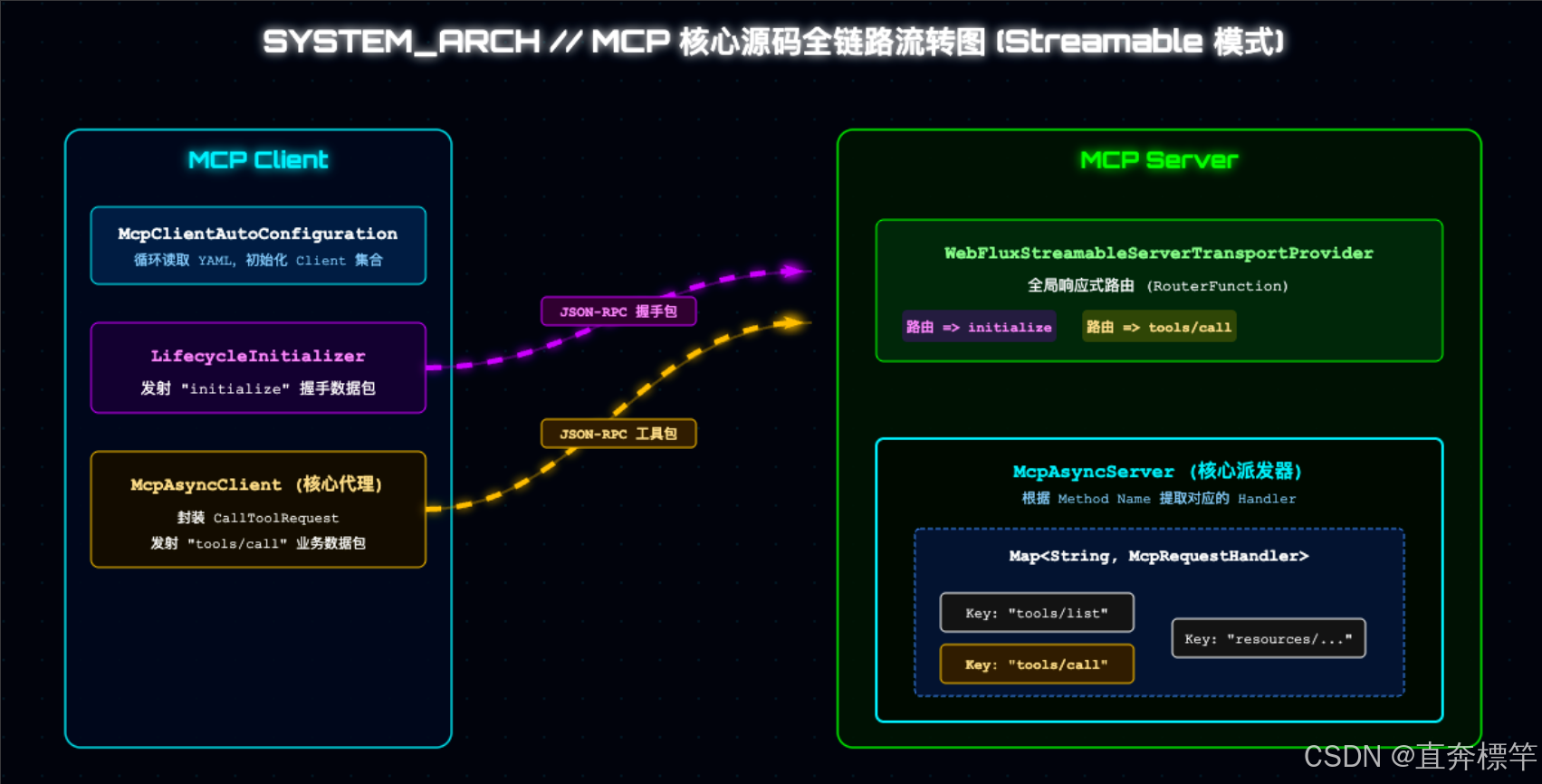
接下来,我们分三个阶段,一步步拆解源码,一起领略顶级框架的设计之美,建议大家跟着源码路径实操一遍,印象更深刻~
阶段一:Server端源码解析——响应式分配中枢的诞生
做过传统Web开发的同学都知道,处理不同请求往往要写大量@RequestMappping注解的Controller,还要堆砌冗长的if-else分支,代码臃肿且难维护。但深入MCP Server底层源码会发现,它借助WebFlux响应式编程,打造了一个极其简洁、高效的流量分发中枢,这也是Spring AI高性能的核心原因之一。
第一步:初始化底层传输通道(Streamable模式核心)
当我们在YAML配置文件中声明protocol: streamable时,Spring Boot的自动装配机制会自动构建一个基于响应式长连接的传输提供者,这是整个Server端的基础,也是Streamable模式区别于SSE、stdio模式的关键所在,Streamable HTTP协议能更好地兼容代理、网关和负载均衡器,适合生产环境使用。
// 源码位置:org.springframework.ai.mcp.server.autoconfigure.McpServerStreamableHttpWebFluxAutoConfiguration
@Bean
public WebFluxStreamableServerTransportProvider webFluxStreamableServerTransportProvider(...) {
// 核心作用:构建WebFlux Streamable服务端传输的底层Bean,奠定长连接通信基础
return WebFluxStreamableServerTransportProvider.builder()...build();
}💡 直奔標杆小贴士:这里的自动装配,完美体现了Spring Boot“约定优于配置”的哲学,无需我们手动创建Bean,框架自动完成底层基建,这也是Spring AI上手便捷的核心原因。
第二步:RouterFunction——统一的流量入口(替代传统Controller)
在WebFluxStreamableServerTransportProvider的内部构造中,框架放弃了传统的Controller映射,转而使用函数式路由(RouterFunction)接管特定端点,所有请求统一入口,避免了Controller冗余,这也是响应式编程的典型应用。
// 源码位置:io.modelcontextprotocol.server.transport.WebFluxStreamableServerTransportProvider
private WebFluxStreamableServerTransportProvider(....) {
// 链式路由注册,统一接管配置的MCP Endpoint所有流量
// 无论GET、POST还是DELETE请求,只要命中MCP Endpoint,都由对应的handle方法拦截处理
this.routerFunction = RouterFunctions.route()
.GET(this.mcpEndpoint, this::handleGet)
.POST(this.mcpEndpoint, this::handlePost)
.DELETE(this.mcpEndpoint, this::handleDelete)
.build();
}【底层细节剖析】:这里的this::handleGet、this::handlePost等方法,就是整个MCP协议处理的“咽喉要道”!客户端发来的所有JSON-RPC请求体,都会先进入这些方法,完成基础的反序列化和请求类型鉴别,相当于流量的“第一道筛选关卡”,大家可以重点关注这些handle方法的实现逻辑。
第三步:门面模式+策略分发(解耦的核心设计)
底层传输通道和流量入口搭建完成后,核心业务逻辑就交给服务层处理。Spring AI在这里用到了经典的门面模式(Facade Pattern),对外暴露简洁的McpSyncServer(同步外壳),内部则封装了高并发的McpAsyncServer(异步核心),既保证了调用便捷性,又兼顾了高性能。
而对于繁杂的协议命令,框架采用策略模式实现解耦,拒绝面条式逻辑判断,咱们直接看源码:
// 源码位置:io.modelcontextprotocol.server.McpAsyncServer#prepareRequestHandlers
private Map<String, McpRequestHandler<?>> prepareRequestHandlers() {
// 1. 初始化注册表,装载所有协议定义的处理能力(Tools、Resources、Prompts等)
Map<String, McpRequestHandler<?>> requestHandlers = new HashMap<>();
// 2. 如果服务端声明支持Tools能力(我们实战中常用的@McpTool就属于这类)
if (this.serverCapabilities.tools() != null) {
// 3. 将JSON-RPC的method字段与具体处理器绑定,实现精准调度
requestHandlers.put("tools/list", this.toolsListRequestHandler());
requestHandlers.put("tools/call", this.toolsCallRequestHandler());
}
// ...同样处理Resources、Prompts等其他协议能力
return requestHandlers;
}【底层细节剖析】:这是Spring AI MCP解耦的核心设计!框架没有用臃肿的if-else判断请求类型,而是将JSON-RPC的method字段(比如tools/call、tools/list)作为Key,直接映射到对应的处理器,后续新增协议能力时,只需新增处理器并注册,无需修改核心调度逻辑,完全符合“开闭原则”。这种设计也让MCP协议具备了良好的横向扩展能力,适配不同场景的需求。
建议大家实操时,重点看一下toolsCallRequestHandler()的实现,搞懂它如何与我们写的@McpTool注解方法关联。
阶段二:Client端源码解析——跨域通信的“握手”全过程
看完Server端,我们把视线拉回客户端。上一节课我们在YAML中配置了远端Server节点,Spring Boot启动时就自动完成了连接建立,这背后的底层逻辑是什么?今天就和大家拆解Client端的初始化流程,搞懂大模型与外部系统“交换外交国书”的细节。
第一步:按需装配客户端集合(自动识别配置)
Spring Boot启动时,会通过自动装配机制,遍历配置文件中声明的所有远端Server节点,按需构建McpSyncClient实例,并触发初始化,完成连接握手。
// 源码位置:org.springframework.ai.mcp.client.common.autoconfigure.McpClientAutoConfiguration
public List<McpSyncClient> mcpSyncClients(...) {
// 遍历配置文件中所有声明的远端连接
for(NamedClientMcpTransport namedTransport : namedTransports) {
// 基于传输层配置,构建Client规范约束
McpClient.SyncSpec spec = McpClient.sync(namedTransport.transport()).clientInfo(clientInfo);
McpSyncClient client = spec.build();
// 核心操作:触发连接握手初始化,这是建立双向通信的关键一步!
client.initialize();
mcpSyncClients.add(client);
}
return mcpSyncClients;
}💡 直奔標杆小贴士:这里的client.initialize()是核心入口,所有的握手逻辑都从这里触发,大家可以跟着源码断点调试,看看初始化过程中会调用哪些核心类。
第二步:执行Initialize握手协定(“交换外交国书”)
进入client.initialize()的底层链路,会调用到LifecycleInitializer类,它的核心作用是在建立实际业务通信前,完成客户端与Server端的“握手”——相当于“交换外交国书”,告诉对方“我是谁、我支持哪些能力”,确保双方协议兼容。
// 源码位置:io.modelcontextprotocol.client.LifecycleInitializer
private Mono<McpSchema.InitializeResult> doInitialize(...) {
// 1. 构建“外交国书”:告知Server端客户端信息、支持的MCP版本、具备的能力(如支持进度条、回调等)
McpSchema.InitializeRequest initializeRequest =
new McpSchema.InitializeRequest(latestVersion, this.clientCapabilities, this.clientInfo);
// 2. 开启长连接会话,向Server端发送"initialize"请求,完成握手
Mono<McpSchema.InitializeResult> result =
mcpClientSession.sendRequest("initialize", initializeRequest, McpAsyncClient.INITIALIZE_RESULT_TYPE_REF);
}【底层细节剖析】:当initialize请求抵达Server端后,前面提到的handlePost方法会拦截它,并调用this.sessionFactory.startSession(initializeRequest),Server端验证通过后,会将该会话加入活跃会话池(this.sessions.put(...)),至此,客户端与Server端基于MCP标准的双向通信桥梁,正式建立完成!
这里大家可以思考一个问题:如果握手失败,会抛出什么异常?如何排查?欢迎在评论区留言讨论,一起交流排查思路~
阶段三:Tool调用的闭环追踪——从请求到执行,全程透明
Server端基建就绪、Client端连接建立,接下来就是最核心的Tool调用流程。我们从客户端一行callTool代码出发,完整追踪JSON-RPC数据包的流转,看看@McpTool注解的方法是如何被远程触发执行的。
第一步:客户端的数据封装(JSON-RPC协议格式化)
在业务代码中,我们通过McpSyncClient发起Tool调用,代码很简单,但底层会自动完成JSON-RPC协议的封装,咱们先看业务代码和底层源码:
// 业务代码:客户端发起Tool调用
McpSchema.CallToolRequest toolRequest = McpSchema.CallToolRequest.builder()
.name("tool") // 对应@McpTool注解的方法名
.arguments(Map.of("input", "test input")) // 方法参数
.build();
mcpClient.callTool(toolRequest);
// 底层源码(简化版):io.modelcontextprotocol.client.McpAsyncClient
public Mono<McpSchema.CallToolResult> callTool(McpSchema.CallToolRequest callToolRequest) {
// 核心作用:将CallToolRequest封装为JSON-RPC请求,并打上"tools/call"路由标签
return this.initializer.withInitialization("calling tool",
(init) -> init.mcpSession().sendRequest("tools/call", callToolRequest, CALL_TOOL_RESULT_TYPE_REF));
}这里的关键的是:客户端会自动给请求打上“tools/call”的method标签,这个标签会作为Server端调度的“钥匙”,对应我们前面看到的toolsCallRequestHandler处理器。
第二步:服务端精准提取与反射执行(触发本地方法)
当JSON-RPC数据包抵达Server端后,handlePost方法会将其分拣至responseStream进行业务处理,Server端会根据“tools/call”标签,精准找到对应的处理器,并通过反射机制,触发我们编写的@McpTool注解方法。
// 源码位置:io.modelcontextprotocol.server.McpAsyncServer
public Mono<Void> responseStream(McpSchema.JSONRPCRequest jsonrpcRequest) {
// 1. 核心调度:通过客户端传来的"tools/call"标识,从注册表中提取对应处理器
McpRequestHandler<?> requestHandler = this.requestHandlers.get(jsonrpcRequest.method());
// 2. 执行业务逻辑:通过参数解析+反射,触发@McpTool注解的物理方法
return requestHandler.handle(jsonrpcRequest);
}【流转结果】:requestHandler.handle()执行完毕后,返回值会被重新包装成JSON-RPC的Result结构,沿着原路径返回至客户端,最终在客户端线程上下文中,我们就能拿到结构化的调用结果——整个流程闭环完成,全程透明可追溯!
建议大家实操时,在@McpTool注解的方法上打个断点,看看反射调用的触发时机,更能加深理解。
本节课总结(一起复盘,巩固知识点)
今天这节课,我们跳出“框架使用者”的身份,深入Spring AI MCP的底层源码,拆解了Server端、Client端的核心逻辑,以及Tool调用的全闭环,相信大家对MCP协议的理解又深了一层。
结合源码,我们能感受到Spring AI框架设计的严谨与克制,核心亮点总结3点(建议收藏):
-
高性能:借助WebFlux响应式编程,打造异步调度引擎,从容应对长连接的数据分发,适配高并发场景;
-
高解耦:采用策略模式+HashMap映射,替代臃肿的if-else,让协议扩展更灵活,核心逻辑无需侵入式修改;
-
规范化:通过LifecycleInitializer实现会话生命周期管理,握手流程标准化,确保客户端与Server端兼容。
吃透这些底层逻辑,MCP调用就不再是“黑盒”,未来遇到网络异常、协议不兼容、反序列化报错等问题,我们都能从架构层面快速定位根源,不再依赖“乱改配置试错”。
最后想说:Java开发者AI转型,既要会“用框架”,也要懂“底层逻辑”,这才是我们进阶的核心竞争力。欢迎大家在评论区留言,分享自己的源码阅读心得,或者提出疑问,直奔標杆会一一回复,和大家一起交流学习~
下节预告(实战来袭,敬请期待)
【第二十二课:Spring AI 个人知识库实战(一)】
经过二十一课的技术拆解,Spring AI的核心武器库——ChatClient对话机制、RAG向量检索、Advisors记忆网络、Function Calling以及MCP协议规范,我们已经全部掌握!
但技术不落地,永远只是零散的Demo。下一节课开始,我们正式进入项目实战阶段,整合所有技术碎片,从零开始开发一个“AI个人知识库”,手把手教大家将Spring AI落地到真实业务,敬请期待~
往期内容(连贯学习,不迷路)
-
Java开发者AI转型第十八课!吃透Agent智能体:多工具协同与ReAct动态决策实战
-
Java开发者AI转型第十九课!MCP协议揭秘与无边界插件生态实战
-
Java开发者AI转型第二十课!Spring AI MCP 双向实战:客户端与服务端手把手落地
我是直奔標杆,专注Java开发者AI转型实战分享,每一节课都干货满满,和大家一起从零基础进阶到实战高手。关注我,下节课我们实战见!🚀

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 16
16 0
0- 0



 已为社区贡献39条内容
已为社区贡献39条内容

所有评论(0)