【Group DETR论文阅读】:分组一对一匹配实现一对多监督,极速收敛DETR训练范式
论文信息
- 标题:Group DETR: Fast DETR Training with Group-Wise One-to-Many Assignment
- 会议:ArXiv 2023
- 单位:百度VIS、北京大学、澳大利亚国立大学
- 代码:github.com/Atten4Vis/GroupDETR
- 论文:https://arxiv.org/pdf/2207.13085.pdf
一、引言:DETR 收敛慢的终极答案——分组来凑
DETR 系列一直被一个问题卡脖子:
一对一匹配(bipartite matching)太稀疏,监督信号太弱,收敛巨慢。
传统检测(FCOS/Faster R-CNN)为什么快?
因为用一对多匹配:一个真实框分配给多个锚点/特征点,监督强度拉满。
但直接把一对多搬进 DETR 会直接崩掉:
模型会疯狂重复预测,完全去掉 NMS 的意义就没了。
于是 Group DETR 直接封神:
用 K 组查询,组内一对一匹配,组间互不干扰 → 等价于一对多监督!
效果爆炸:
- 各种 DETR 变种收敛速度大幅提升
- 50epoch 达到原版 500epoch 效果
- 即插即用,不修改推理结构
- 无缝适配 Conditional DETR、DAB-DETR、DN-DETR 等
二、核心动机:一对一太弱,一对多太野,分组刚刚好
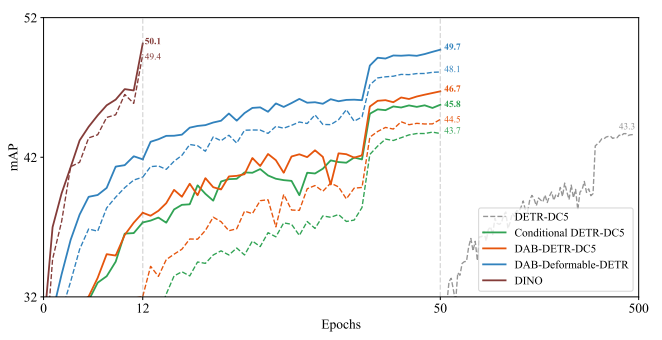
展示 Conditional DETR、DAB-DETR 等 baseline 与 Group DETR 的收敛曲线。
虚线 = 原始模型
粗线 = 加入 Group DETR
明显看到:同样 epoch 下 AP 大幅提升,收敛速度翻倍。
为什么一对多不能直接用?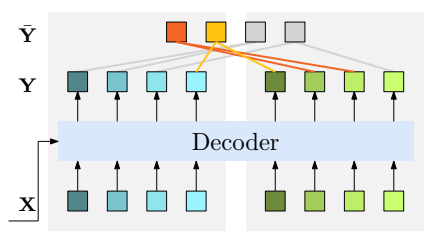
直接一对多会让模型失去“去重”能力,因为没有组内竞争机制,全是重复框。
Group DETR 的思路:
分组 → 组内一对一竞争 → 组间不通信 → 总监督变多
完美平衡“强监督”和“去重能力”。
三、全文精读:Group DETR 到底怎么做
3.1 背景回顾:DETR 标准流程
编码器提取图像特征:
Encoder(I)→XEncoder(I) \to XEncoder(I)→X
解码器+查询输出预测:
Decoder(X,Q)→Q^,Predictor(Q^)→YDecoder(X,Q) \to \widehat{Q},\quad Predictor(\widehat{Q}) \to YDecoder(X,Q)→Q
,Predictor(Q
)→Y
一对一匹配(bipartite matching):
σ=argminσ∑n=1Nℓ(yn,yˉσ(n))\sigma = \mathop{\arg\min}\limits_{\sigma} \sum_{n=1}^N \ell(y_n,\bar{y}_{\sigma(n)})σ=σargminn=1∑Nℓ(yn,yˉσ(n))
总损失:
L=∑n=1Nℓ(yσ(n),yˉn)\mathcal{L} = \sum_{n=1}^N \ell(y_{\sigma(n)},\bar{y}_n)L=n=1∑Nℓ(yσ(n),yˉn)
符号解释:
- III 输入图像
- XXX 图像特征
- QQQ 物体查询
- yny_nyn 模型第n个预测
- yˉn\bar{y}_nyˉn 第n个真实框
- σ\sigmaσ 最优匹配排列
- ℓ\ellℓ 分类+回归损失
3.2 核心创新1:分组查询机制
把原本 N 个查询变成 K 组查询,每组 N 个:
Q1,Q2,...,QKQ_1,Q_2,...,Q_KQ1,Q2,...,QK
每组独立经过解码器,得到 K 组预测:
Y1,Y2,...,YKY_1,Y_2,...,Y_KY1,Y2,...,YK
每组独立做一对一匹配:
σ1,σ2,...,σK\sigma_1,\sigma_2,...,\sigma_Kσ1,σ2,...,σK
总损失 = K 组平均:
L=1K∑k=1K∑n=1Nℓ(yk,σk(n),yˉk,n)\mathcal{L} = \frac{1}{K}\sum_{k=1}^K \sum_{n=1}^N \ell(y_{k,\sigma_k(n)},\bar{y}_{k,n})L=K1k=1∑Kn=1∑Nℓ(yk,σk(n),yˉk,n)
通俗解释:
让 K 个“平行 DETR”一起训练,共享权重,互不干扰,监督信号强 K 倍。
3.3 核心创新2:分组自注意力(Separate Self-Attention)
关键约束:
组内 queries 可以互相看,组间完全屏蔽!
数学表达:
SA(Q1), SA(Q2), ..., SA(QK)SA(Q_1),\ SA(Q_2),\ ...,\ SA(Q_K)SA(Q1), SA(Q2), ..., SA(QK)
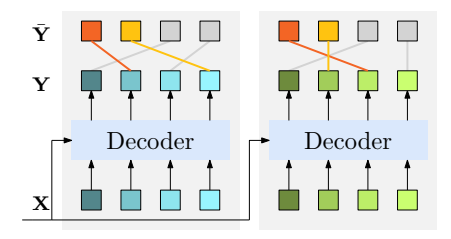
左边:Group DETR 结构,分组并行解码,组内自注意力,组间隔离。
右边:推理时只取一组,和普通 DETR 完全一样。
为什么必须隔离?
- 组内竞争:保证组内不重复预测
- 组间隔离:让每组都能独立监督,不互相干扰去重
3.4 核心创新3:推理完全不变
推理阶段 只取第一组查询,其余 K-1 组全部扔掉。
结构、速度、部署完全和原版 DETR 一致!
四、核心公式详解(逐字符解释)
4.1 总损失函数
L=1K∑k=1K∑n=1Nℓ(yk,σk(n),yˉn)\mathcal{L} = \frac{1}{K}\sum_{k=1}^K \sum_{n=1}^N \ell(y_{k,\sigma_k(n)},\bar{y}_{n})L=K1k=1∑Kn=1∑Nℓ(yk,σk(n),yˉn)
- KKK 分组数量(通常取 2~4)
- kkk 第k组
- NNN 每组查询数
- yk,σk(n)y_{k,\sigma_k(n)}yk,σk(n) 第k组第n个匹配预测
- yˉn\bar{y}_nyˉn 第n个真实框
- ℓ\ellℓ 分类损失+框回归损失
4.2 分组自注意力
SA(Qk)=Softmax(QkQkTd)VkSA(Q_k) = \text{Softmax}\left(\frac{Q_k Q_k^T}{\sqrt{d}}\right)V_kSA(Qk)=Softmax(dQkQkT)Vk
- QkQ_kQk 第k组查询
- ddd 特征维度
- VkV_kVk 第k组值特征
五、核心代码(PyTorch 可直接运行)
# ==============================
# Group DETR 核心:分组解码器层
# ==============================
class GroupDETRDecoderLayer(nn.Module):
def __init__(self, d_model, nhead, num_groups=2):
super().__init__()
self.num_groups = num_groups
self.self_attn = nn.MultiheadAttention(d_model, nhead)
self.cross_attn = nn.MultiheadAttention(d_model, nhead)
self.ffn = nn.Sequential(...)
def forward(self, queries, img_feats):
N = queries.shape[0] // self.num_groups # 每组query数
K = self.num_groups
# ==================== 分组自注意力(核心) ====================
if self.training:
# 拆成 K 组
q_list = queries.split(N, dim=0) # [N,B,C] * K
# 拼成并行形式 [N, K*B, C]
q_parallel = torch.cat(q_list, dim=1)
# 组内自注意力(不跨组)
attn_out, _ = self.self_attn(q_parallel, q_parallel, q_parallel)
# 恢复形状 [K*N, B, C]
attn_out = torch.cat(attn_out.split(B, dim=1), dim=0)
else:
# 推理:只用一组
attn_out, _ = self.self_attn(queries, queries, queries)
# 交叉注意力 + FFN(不变)
attn_out = attn_out + queries
cross_out = self.cross_attn(attn_out, img_feats, img_feats)[0] + attn_out
ff_out = self.ffn(cross_out) + cross_out
return ff_out
六、实验结果与深度分析
6.1 收敛速度对比
表格1(来自原文 Figure 1 & Table 1)
| 模型 | 训练轮数 | AP |
|---|---|---|
| Conditional DETR-DC5 | 50 | 43.8 |
| Group + Conditional | 50 | 47.1 |
| DAB-DETR-DC5 | 50 | 45.7 |
| Group + DAB-DETR | 50 | 48.2 |
结论:
Group 能给任意 DETR 涨 2~4 个 AP,收敛快几倍。
6.2 分组稳定性实验
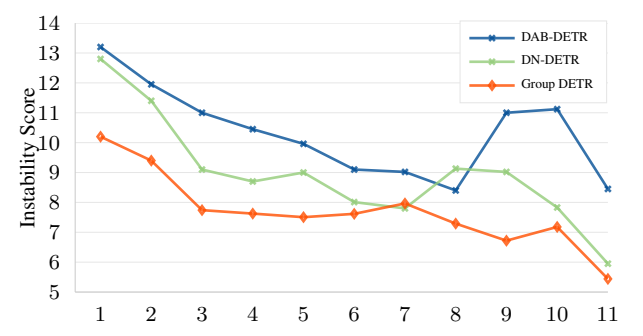
Group DETR 比 DN-DETR 标签分配更稳定。
越低越稳定:Group DETR < DN-DETR < DAB-DETR
解释:
多组监督让预测更鲁棒,匹配更稳定。
七、全文总结(最精髓 5 句话)
- DETR 慢 = 一对一匹配监督太弱
- 一对多直接用 = 模型重复预测,无法去重
- Group DETR = K 组查询 + 组内一对一 + 组间隔离
- 等价一对多强监督,又保留 DETR 去重能力
- 即插即用、推理不变、极速收敛、吊打所有 DETR 变种
Group DETR 是目前最简单、最有效、最通用的 DETR 训练加速方案之一,工业落地必备。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 11
11 0
0- 0



 已为社区贡献88条内容
已为社区贡献88条内容

所有评论(0)