[智能体-299]:文档、文档对象Document、 向量库数据库、Chroma数据库访问对象、文本向量化embedding、检索器retriever他们各自的含义和他们的协作关系,层次关系
·
一、各组件定义
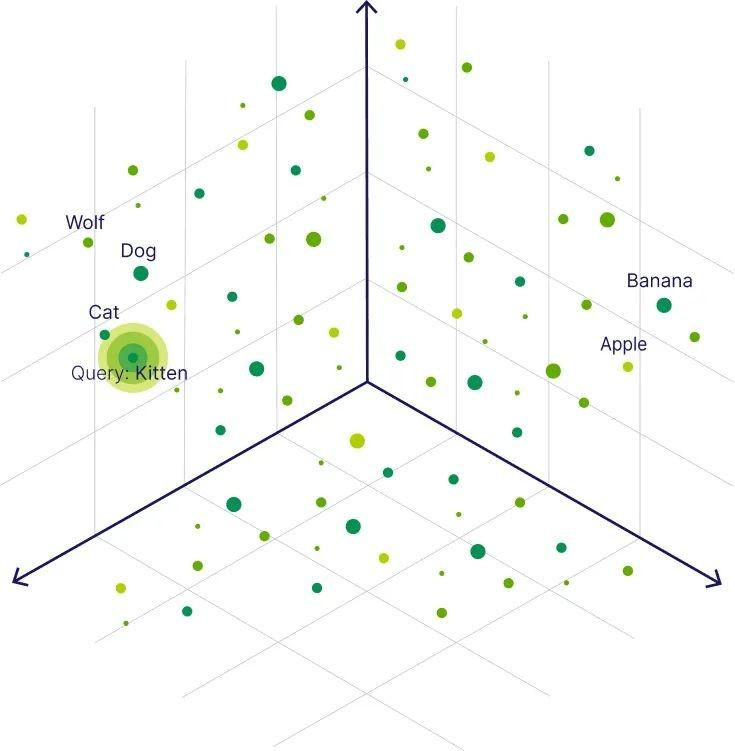
| 组件 | 定义 | 说明 |
|---|---|---|
| 文档(Document) | 原始非结构化文本内容,如一段话、一篇文章、PDF 中的一页等 | 是信息的原始载体,尚未被程序处理 |
| 文档对象(Document Object) | 将原始文档封装为结构化对象,通常包含 page_content(文本)和 metadata(元数据) |
在 LangChain 中是 langchain_core.documents.Document 类的实例 |
| 文本向量化(Embedding) | 使用嵌入模型将文本转换为固定长度的浮点数向量(如 768 维),语义相近的文本向量在空间中距离更近 | 是连接“语言”与“向量计算”的桥梁 |
| 向量数据库(Vector Database) | 专门用于高效存储和检索高维向量的数据库,支持近似最近邻(ANN)搜索 | 如 Chroma、FAISS、Pinecone、Weaviate |
| Chroma 数据库访问对象 | Chroma 提供的客户端对象(如 Chroma 实例),用于管理集合(collection)、插入/查询向量 |
是向量数据库的具体实现接口,在 LangChain 中表现为 VectorStore |
| 检索器(Retriever) | 封装了“接收查询 → 向量化 → 检索 → 返回相关文档”全流程的高层接口 | 通常由 VectorStore.as_retriever() 生成,供 RAG 系统调用 |
二、层次关系(自底向上)
编辑
Level 0: 原始文档(Raw Text)
↓
Level 1: 文档对象(Document Object) ← 结构化表示
↓
Level 2: 文本向量化(Embedding) ← 语义数值化
↓
Level 3: 向量数据库(Vector DB) ← 存储(向量 + 文档)
↓
Level 4: Chroma 数据库访问对象(VectorStore)← 数据库操作接口
↓
Level 5: 检索器(Retriever) ← 应用层统一检索入口✅ 特点:每一层依赖下一层,上层对下层透明。例如 Retriever 不关心底层用的是 Chroma 还是 FAISS。
三、协作流程(数据流)
🔁 两个阶段:
- 索引阶段(离线):文档 → 向量化 → 存入 Chroma。
- 检索阶段(在线):查询 → 向量化 → 在 Chroma 中找相似项 → 返回原文档。
四、完整代码示例(使用本地模型,无需 OpenAI)
✅ 使用
sentence-transformers/all-MiniLM-L6-v2(免费、轻量、768 维)
✅ 全部本地运行,无网络依赖(除首次下载模型)
✅ 展示所有组件创建与协作
安装依赖
pip install langchain langchain-chroma chromadb sentence-transformersPython 代码
Python
# -*- coding: utf-8 -*-
from langchain_core.documents import Document
from langchain_chroma import Chroma
from langchain_community.embeddings import HuggingFaceEmbeddings
# ----------------------------
# 1. 原始文档 → Document 对象
# ----------------------------
raw_texts = [
"机器学习让计算机从数据中自动学习模式,而无需显式编程。",
"深度学习是机器学习的一个分支,使用深层神经网络处理复杂数据。",
"自然语言处理使计算机能够理解、分析、生成人类语言。"
]
documents = [
Document(page_content=text, metadata={"id": i, "topic": "AI"})
for i, text in enumerate(raw_texts)
]
print("✅ 文档对象已创建:")
for doc in documents:
print(f" ID {doc.metadata['id']}: {doc.page_content[:40]}...")
# ----------------------------
# 2. 初始化本地 Embedding 模型
# ----------------------------
embedding_model = HuggingFaceEmbeddings(
model_name="sentence-transformers/all-MiniLM-L6-v2"
)
# 测试向量化
vec = embedding_model.embed_query("什么是深度学习?")
print(f"\n✅ Embedding 维度: {len(vec)}") # 应为 384 或 768(此模型为 384)
# ----------------------------
# 3. 创建 Chroma 向量数据库(内存模式)
# ----------------------------
vectorstore = Chroma.from_documents(
documents=documents,
embedding=embedding_model,
collection_name="ai_knowledge"
)
print("\n✅ 向量已存入 Chroma")
# ----------------------------
# 4. 获取 Chroma 访问对象(即 VectorStore)
# ----------------------------
# 此处 vectorstore 就是 Chroma 数据库访问对象
print(f"✅ Chroma 访问对象类型: {type(vectorstore)}")
# ----------------------------
# 5. 创建 Retriever
# ----------------------------
retriever = vectorstore.as_retriever(search_kwargs={"k": 2})
print("\n✅ Retriever 已创建")
# ----------------------------
# 6. 执行检索
# ----------------------------
query = "深度学习和机器学习的关系是什么?"
results = retriever.invoke(query)
print(f"\n🔍 查询: '{query}'")
print("📄 检索结果:")
for i, doc in enumerate(results, 1):
print(f" {i}. {doc.page_content}")
print(f" [元数据: {doc.metadata}]")预期输出(部分)
✅ 文档对象已创建:
ID 0: 机器学习让计算机从数据中自动学习模式...
ID 1: 深度学习是机器学习的一个分支,使用深...
ID 2: 自然语言处理使计算机能够理解、分析...
✅ Embedding 维度: 384
✅ 向量已存入 Chroma
✅ Chroma 访问对象类型: <class 'langchain_chroma.vectorstores.Chroma'>
✅ Retriever 已创建
🔍 查询: '深度学习和机器学习的关系是什么?'
📄 检索结果:
1. 深度学习是机器学习的一个分支,使用深层神经网络处理复杂数据。
[元数据: {'id': 1, 'topic': 'AI'}]
2. 机器学习让计算机从数据中自动学习模式,而无需显式编程。
[元数据: {'id': 0, 'topic': 'AI'}]五、关键总结
| 组件 | 是否必需 | 可替换性 | 示例替代方案 |
|---|---|---|---|
| Document 对象 | 是 | 否(标准接口) | LangChain 标准格式 |
| Embedding 模型 | 是 | 是 | OpenAI / BGE / Cohere |
| 向量数据库 | 是 | 是 | FAISS / Pinecone / Milvus |
| Chroma 访问对象 | 否(若换 DB) | 是 | FAISS 的 FAISS 类 |
| Retriever | 是(在 RAG 中) | 否(抽象层) | 所有 VectorStore 都支持 .as_retriever() |
💡 设计优势:通过分层抽象,你可以:
- 换 Embedding 模型 → 只改一行
- 换向量数据库 → 只改初始化方式
- 上层 Retriever 接口完全不变

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 4
4 0
0- 0



 已为社区贡献234条内容
已为社区贡献234条内容

所有评论(0)