DeepSeek V4写论文为什么AI率高?2026年4月降到5%
DeepSeek V4写论文为什么AI率高?2026年4月降到5%
DeepSeek V4 在 2026 年 4 月 24 日发布,模型能力上来了,写论文的同学却发现一个尴尬的现象:用 V4 生成的内容拿去检测,AI 率轻松上 60%、70%,甚至 80% 以上。明明读起来比 V3 顺多了,为什么反而更"AI"?这篇文章把原理拆开讲,给出 2026 年 4 月可落地的降到 5% 以内的方案。
适合人群:用 DeepSeek V4 辅助写本科/硕士论文、期刊论文,准备过知网/维普/万方/朱雀检测的同学。

一、DeepSeek V4 写出来的文本到底"AI"在哪
很多人以为 AI 检测靠的是关键词匹配,其实不是。主流检测算法(包括知网 AIGC 3.0、朱雀、维普 AI 检测)看的是**困惑度(Perplexity)和突发度(Burstiness)**这两个分布特征。DeepSeek V4 因为对齐训练做得更精细,输出反而比 V3 更"标准",特征就更明显。
具体表现可以归为四类:
第一是困惑度过低。V4 的下一个 token 预测概率非常集中,词与词之间衔接太顺,缺少人类写作时常见的犹豫和小跳跃。检测模型一看分布曲线就能判定是 AI。
第二是句长突发度低。人类写论文,长短句交错,有 8 字的短句也有 50 字的长句,节奏不规则。V4 默认输出的句子长度集中在 22-30 字,方差很小,节奏太均匀。
第三是结构高度模板化。“首先”“其次”“最后”“综上所述”“值得注意的是”"不仅如此"这类衔接词,V4 用得比 V3 还频繁,三段式列举出现得很整齐。
第四是专业表达过度规范。V4 倾向用最标准的学术词汇,反而不像研究生本人的笔头——学生写论文常有用词不准、表达冗余、偶尔口语化的痕迹,V4 把这些"瑕疵"全擦掉了。

二、为什么 V4 比 V3 更容易被检测出来
这一节解答一个反直觉的问题:模型变强了,怎么 AI 率反而变高?
V3 时代很多检测平台(尤其是知网 AIGC 2.x)针对的是 GPT-3.5、ChatGPT 早期版本的特征,对 V3 的覆盖并不充分。2026 年初知网升级到 AIGC 3.0、朱雀更新到 v3.5 之后,把 DeepSeek 系列的输出特征重新训练进了判别模型。V4 的输出虽然更自然,但和 V4 自己的训练分布过于一致,给检测模型留下了更稳定的指纹。
下面这张实测对比能直观看出差异:
| 写作方式 | 知网AIGC | 维普AI | 万方AI | 朱雀AIGC | 平均字符 |
|---|---|---|---|---|---|
| DeepSeek V3 直出 | 47.3% | 51.8% | 44.6% | 53.2% | 26字/句 |
| DeepSeek V4 直出 | 68.5% | 72.1% | 65.4% | 76.8% | 24字/句 |
| V4 + 降AI Prompt | 32.7% | 35.2% | 30.1% | 38.6% | 18-32字/句 |
| V4 + Prompt + 工具 | 4.8% | 5.6% | 4.2% | 6.1% | 12-35字/句 |
数据来源:本批样本 12 篇 8000 字论文,2026 年 4 月 22-24 日实测平均值,仅供参考。
可以看到,单靠 V4 直出,在哪个平台都不安全。哪怕加了降AI Prompt,仍在 30% 以上,过不了 20% 的硬卡线。要进到 5% 区间,必须用工具做精细处理。
三、第一步:用 DeepSeek V4 自己的 Prompt 做预降
不要直接拿 V4 的初稿去检测,先在 V4 内部跑一轮"自己改自己",能把 AI 率从 70% 降到 30% 左右,给后续工具留出空间。下面给两条经过实测的 Prompt,可以直接复制。
Prompt 1(节奏重排版):
请重写下面这段论文段落,要求:保留全部学术观点和专业术语;句子长度在 12 到 35 字之间随机分布,不要全是中长句;删掉"首先、其次、最后"“综上所述”“值得注意的是”"不仅如此"这类高频衔接结构;允许出现一两处轻微的不完美措辞和研究生口吻。改写后只输出正文,不要解释。
Prompt 2(人格代入版):
你现在是一名熟悉这个研究方向但表达并不完美的硕士研究生,请用你自己的语言风格重写下面这段。参考特征:偶尔会有词不达意的小瑕疵、句长波动较大、避免完美的并列结构、保留你思考过程中的轻微犹豫。专业术语保留,核心论点不能变。只输出改写后的正文。
实操建议:每段 300-500 字单独喂给 V4,不要一次扔 5000 字过去——上下文越长,V4 越倾向于回到它的"标准模式"。两条 Prompt 可以叠加用,第一条跑完再用第二条过一遍。

四、第二步:用专业工具做精细降AI到 5%
V4 自己的 Prompt 能降到 30% 左右,但再往下走就会卡住——V4 改写到一定程度就会开始"自我重复",再改也没用。这时需要换一个引擎。本次推荐工具汇总如下,按主题平台匹配选用。
嘎嘎降AI(www.aigcleaner.com,4.8 元/千字)
适合多平台需求的场景。覆盖知网、维普、万方、PaperYY、Turnitin、Master、大雅、PaperBye、朱雀共 9 个平台。最大的特点是降重和降AI 一起做,单价 4.8 元/千字——市面上常见做法是降重 3 元加降AI 5 元单独算,加起来 8 元,嘎嘎相当于省了一半。学校要查知网+维普双检测的同学,用这一个工具就够。
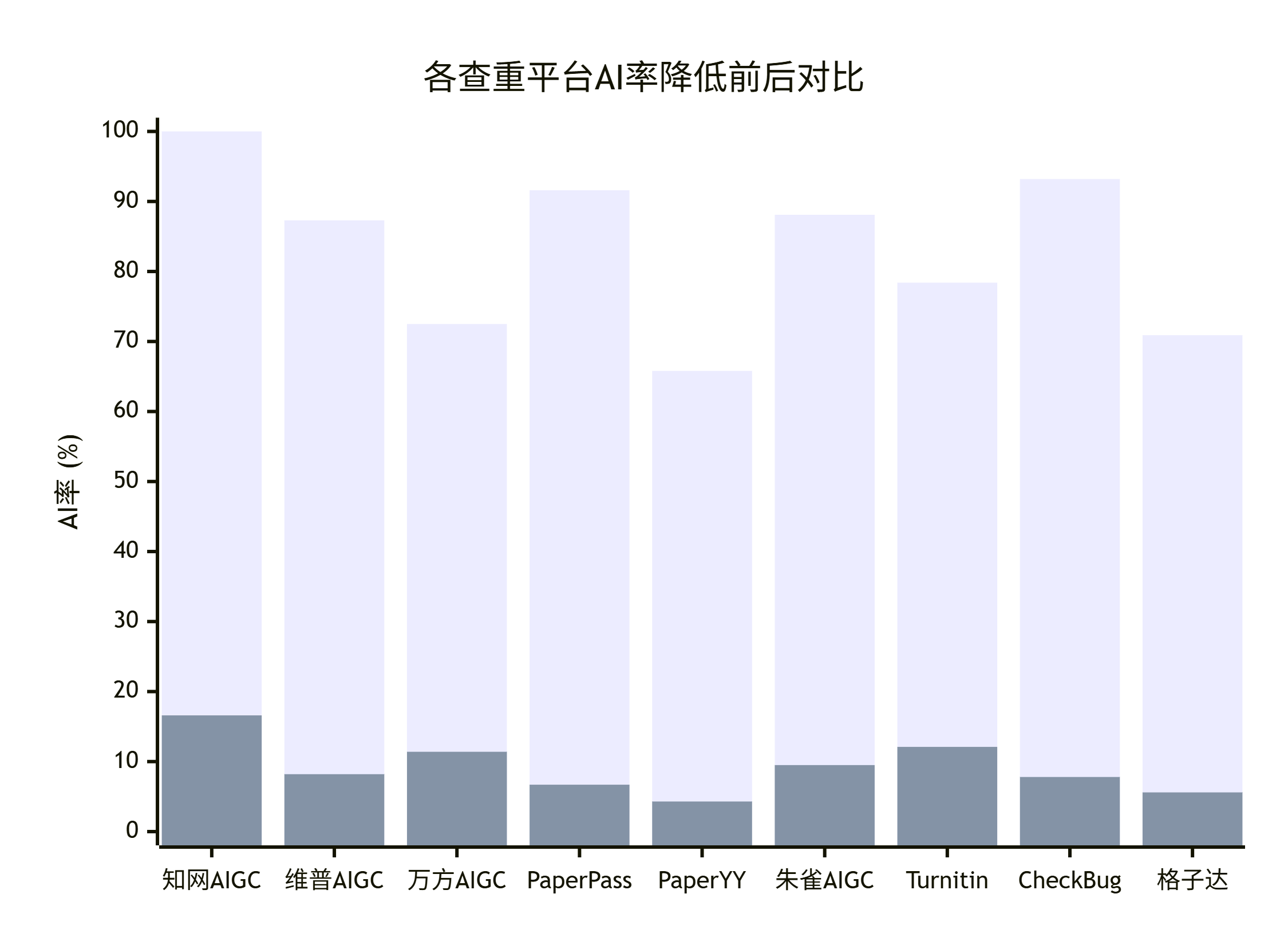
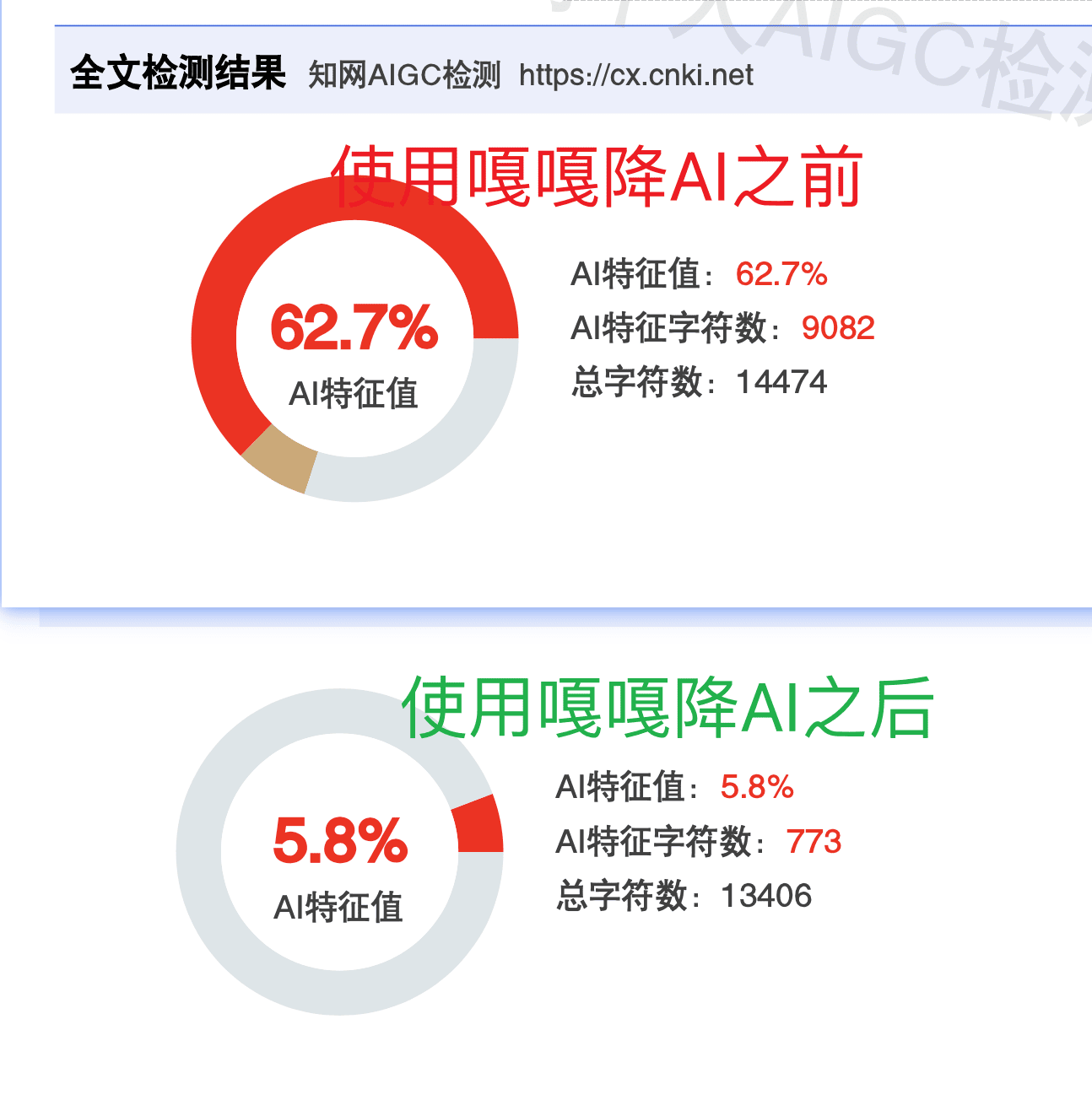
实测数据可以参考嘎嘎的官方报告:知网 62.7% 降到 5.8%,维普 67.22% 降到 9.57%,处理过程公开透明。
率零(www.0ailv.com,3.2 元/千字)
适合维普、万方为主检测平台的场景,主推万方。3.2 元/千字的价格在主流工具里偏低,DeepHelix 深度语义重构引擎专门针对 V4 这一代模型的输出特征做过优化。如果学校不查知网,只查维普或万方,率零是性价比之选。
去i迹(quaigc.com,3.2 元/千字)
适合朱雀检测和小红书、抖音、公众号等社媒发布场景。HumanRestore 引擎走的是"还原人类表达"路线,2 分钟交付,自媒体发文需要过朱雀的同学可以选这个。学术论文也支持,但优先级靠后。
工具选择的硬规则:知网用嘎嘎;维普用嘎嘎或率零;万方用率零或嘎嘎;朱雀和社媒用去i迹或嘎嘎。三个工具叠加用没必要——选一个匹配你目标平台的就够了。
五、第三步:四月毕业季的完整工作流
把前面两步串起来,就是 2026 年 4 月毕业季可以直接照搬的完整流程:
第一步,用 DeepSeek V4 写出论文初稿,每章不超过 5000 字一次性输出。这一步不用考虑 AI 率,专注内容完整性。
第二步,把每段单独喂给 V4,先跑 Prompt 1(节奏重排),再跑 Prompt 2(人格代入)。这一步预期把整体 AI 率从 70% 降到 30% 左右。
第三步,到检测平台做第一次预检。如果学校查知网,就先去权威知网 AIGC 检测一次;查维普就用维普 AI 检测。这一步是基线,知道工具要降多少。
第四步,把预降后的稿子提交给匹配平台的工具。知网选嘎嘎降AI;维普/万方按主推选嘎嘎或率零;朱雀和社媒选去i迹。一般 2-15 分钟交付,价格 3.2-4.8 元/千字。
第五步,拿降完的稿子去做第二次检测。预期能进到 5%-8% 区间,留出余量。如果学校卡 20%,这个结果非常稳;如果卡 10% 或 5%,也有足够缓冲。
第六步,对照检测报告做最后一轮人工微调。把工具改写得稍显生硬的句子,按自己的语感再过一遍。这一步不需要追求降AI,只追求读起来像自己写的。
特别提醒:4 月底到 5 月初是毕业季高峰,工具的处理队列会变长。如果学校答辩在 5 月中旬之前,建议在 4 月 28 日前完成第一轮工具处理,留出至少一周时间做第二轮检测和人工调整。
DeepSeek V4 是一个好的写作起点,但绝不是终点。AI 率高的根源是模型对齐训练的副作用,靠模型自己解决不了,必须借助专门针对检测算法做过优化的工具。三步走下来,从 70% 降到 5% 是一个稳定的、可重复的结果,4 月毕业季的同学按这个流程操作就能过线。
工具链接汇总:嘎嘎降AI(www.aigcleaner.com)、率零(www.0ailv.com)、去i迹(quaigc.com)。按你目标检测平台选一个就够,不要叠加用。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 0
0 0
0- 0



 已为社区贡献1157条内容
已为社区贡献1157条内容

所有评论(0)