ICLR2026:时序Transformer本质低秩坍缩,算力浪费65%+,别硬套LLM架构
别再拿套壳LLM的思路做时间序列了:深挖Transformer的低秩坍缩与本质算力
目前行业的绝对误区是:只要把时间序列做个Token化(无论是量化还是连续Patch),然后原封不动地扔进类似LLaMA或T5的Transformer架构里暴力预训练,大力就能出奇迹。大家在狂抄文本大模型的前馈层宽度、注意力头数和网络深度,将这视为Time Series Foundation Models (TSFM) 的标准范式。
但真实问题在于,时间序列数据的内在数学几何结构与自然语言存在本质裂痕。语言拥有极高复杂度的离散词表,而时序信号本质是低维连续流形。把文本模型的超参硬套给时间序列,换来的是架构级、灾难性的算力冗余。这篇偏向数学基础的论文不仅扒开了时序Embedding的空间底裤,更向整个学术界证明了一点:你根本不需要那么宽的注意力网络去拟合时间序列。

另外我整理了《Understanding Transformers》核心代码包,感兴趣的可以dd,希望能帮到你!
2. 核心结论
这篇论文,本质上做了:证明了时间序列数据在Transformer中天然具有极低的“秩(Rank)”,并以此为依据提出了一种随网络层数动态变化的算力分配法则,在零掉点的前提下,直接把大规模时序模型的推理耗时砍掉65%,显存直降81%。
3. 方法拆解
不要沉迷于工程层面的SVD截断,整个方法必须抽象为对数据流经网络时的“降维与重构”。
Stage 1:揭示维度表象下的秩坍缩(解决数据表征的本源问题)
文本数据映射到高维空间后,依然能撑起庞大的表达维度。但时间序列不论如何切Patch做Embedding,其在隐藏层空间中都会迅速向低秩子流形坍缩。这直接说明,时序模型在输入阶段就面临着严重的无效参数空转。
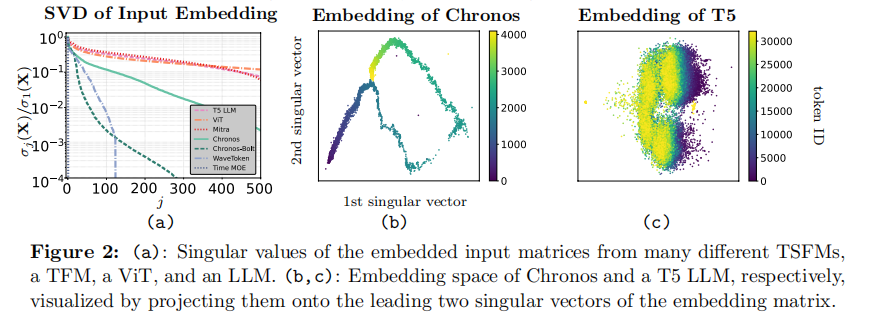
说明:各大基础模型Input Embedding的奇异值衰减对比,时序模型(蓝线)呈现出极其陡峭的暴跌,证明其极度的低秩特性。
Stage 2:注意力矩阵的降维等效(解决计算繁冗的本源问题)
既然输入进来的东西本质上只有几根骨架是硬的(低秩),全尺寸的Q、K、V线性投影层就成为了一种无意义的过度参数化。通过坚实的定理证明,只需极低秩的近似矩阵,就能在时序低秩输入上重现完整Attention矩阵的表达能力。
说明:时序大模型参数流转的核心逻辑图,揭示从Low-rank输入到Low-rank注意力的传导关系。
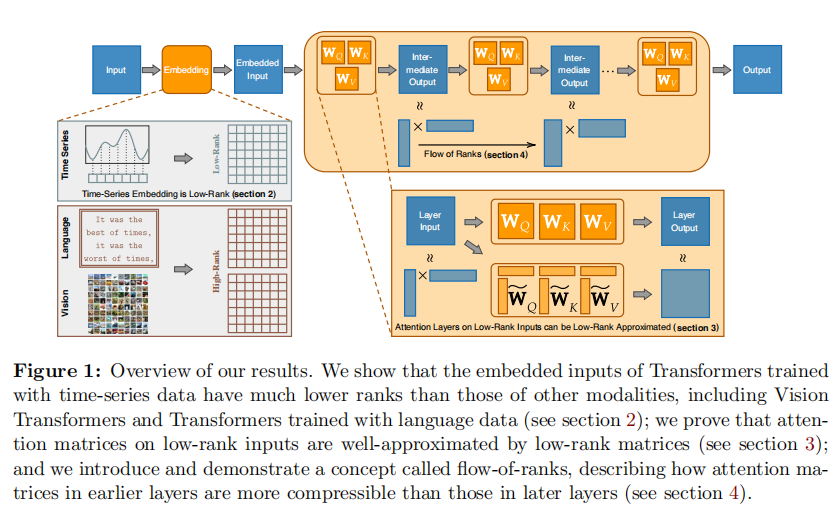
Stage 3:基于“秩流”的动态算力分配(解决网络架构深度的本源问题)
秩不是一成不变的。随着网络加深,非线性激活和残差连接会不可避免地导致信号维度的膨胀。这就形成了文章核心的范式:浅层网络极度过度参数化,必须重度压缩;深层网络维数回升,压缩率应逐渐放宽。这一随层数改变的结构被称为 Flow-of-ranks。
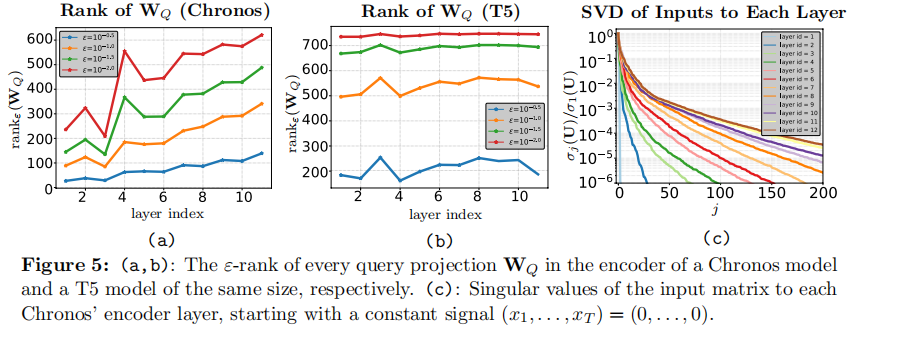
说明:Chronos(左)与T5(右)每一层注意力矩阵的有效秩变化对比。时序模型明显展示出随深度增加而秩升高的Flow-of-ranks现象。
4. 关键技术翻译
-
Time-Series Embedding (时序嵌入的低秩性):把低维连续信号硬塞进Transformer的高维空间里时,有效信息其实只占据了几根极瘦的“骨架”(奇异值急剧衰减),其余大部分高维空间全是废维度。
-
Low-rank Approximation of Attention (注意力矩阵瘦身):在输入信息只有几根核心骨架的情况下,强行用全尺寸、满级的QKV矩阵去相乘,在数学上等价于高射炮打蚊子;低秩截断不仅完全够用,而且输出误差在理论上受严格约束。
-
Flow-of-ranks (秩流演化):随着网络层级变深,Transformer内的残差连接和激活函数会不可逆地把原本干净的低维信号“揉散”,导致表达维度(秩)由浅入深逐步膨胀。
5. 即插即用代码
基于论文中“深层秩变大,浅层秩极小”的推导,我们在搭模型(或魔改开源TSFM架构)时,可以用下面这个针对时序优化过的 DynamicRankLinear 模块,替换掉原来所有层一成不变的 nn.Linear。它可以放在各种时序Transformer的早期Encoder层的 Q/K/V 投影阶段。
import torch
import torch.nn as nn
import math
class DynamicRankLinear(nn.Module):
"""
可放在时序基础模型预训练中的动态秩线性层。
基于层数深度的 Flow-of-ranks 现象动态分配矩阵容量。
"""
def __init__(self, in_dim, out_dim, layer_index, base_rank=3, alpha=0.5):
super().__init__()
# 根据推导公式计算当前层的有效秩: d_i = ceil( d_0 * (1 + i)^alpha )
self.rank = math.ceil(base_rank * (1 + layer_index) ** alpha)
self.rank = min(self.rank, in_dim) # 保证秩不超过原始维度
# 抛弃巨大的满秩权重矩阵,直接参数化为两个小矩阵的乘积
self.U = nn.Parameter(torch.Tensor(out_dim, self.rank))
self.V = nn.Parameter(torch.Tensor(self.rank, in_dim))
self.bias = nn.Parameter(torch.zeros(out_dim))
nn.init.kaiming_uniform_(self.V, a=math.sqrt(5))
nn.init.zeros_(self.U)
def forward(self, x):
# 推理时计算顺序: (x @ V^T) @ U^T,极大缩减MACs
low_dim_proj = torch.matmul(x, self.V.t())
out = torch.matmul(low_dim_proj, self.U.t()) + self.bias
return out
6. 升华一下
这篇论文真正重要的不是教你如何用SVD对开源库里的Chronos模型进行权重截断,而是向整个时间序列社区喊话:不要迷信文本大模型暴力堆算力、堆深度的美学,数据模态的内在几何结构才应该决定架构的最终重参数化形态。
总结为一个“范式”: 模态感知与动态秩分配范式 (Modality-Aware Dynamic Rank Allocation)
7. 可延展方向
基于这篇推翻经验主义的扎实工作,学术界和工程界可以直接切入以下几个方向:
1. 时序特化的多头注意力机制重构 (Research):论文虽然证明了单头下的低秩性,但同时指出多头注意力(MHA)在训练中往往退化为“依赖各个Head做独立降维投射”。未来的新论文完全可以基于此,设计出“强迫多头共享子空间池”的正交注意力机制,继续压榨参数极限。
2. 将动态低秩设计直接融入预训练架构 (Engineering):不再像现在这样“先拿全尺寸预训练,再去SVD压缩”,而是设定包含深度相关Rank参数的轻量级底座直接训练。对工业界来说,花大模型1/10的显存和时间,训出一个零掉点的时间序列大模型,商业价值巨大。
3. FFN(前馈层)维度的时序坍缩验证 (Research):既然Attention矩阵具有如此严重的空转现象,那么占算力大头的MLP层是否对一维时序信号存在同样离谱的空间浪费?这是一个完全可以直接发顶会的验证方向。
8. 小编想说
数据的模态本源,永远是审视Transformer架构合法性的第一性原理。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 6
6 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)