Segment Any Motion in Videos论文模型
目录
1.2D Tracks and Depths(2D轨迹与深度图)
8.Predicted Fine-grained Masks(预测的细粒度掩码)
原论文于CVPR收录,链接:CVPR Poster Segment Any Motion in Videos
abstract:运动目标分割是视觉场景理解与下游应用的核心任务。以往基于光流的方法受部分运动、复杂形变、运动模糊、背景干扰等问题影响,预测效果不佳。我们提出一种新方法:结合长程轨迹运动线索与 DINO 语义特征,并通过迭代提示策略利用 SAM2 实现像素级掩码细化。模型采用时空轨迹注意力与运动 - 语义解耦嵌入,在整合语义信息的同时优先考虑运动特征。在多数据集上的实验验证了其当前最优性能,尤其在复杂场景与多目标细粒度分割场景中表现优异。
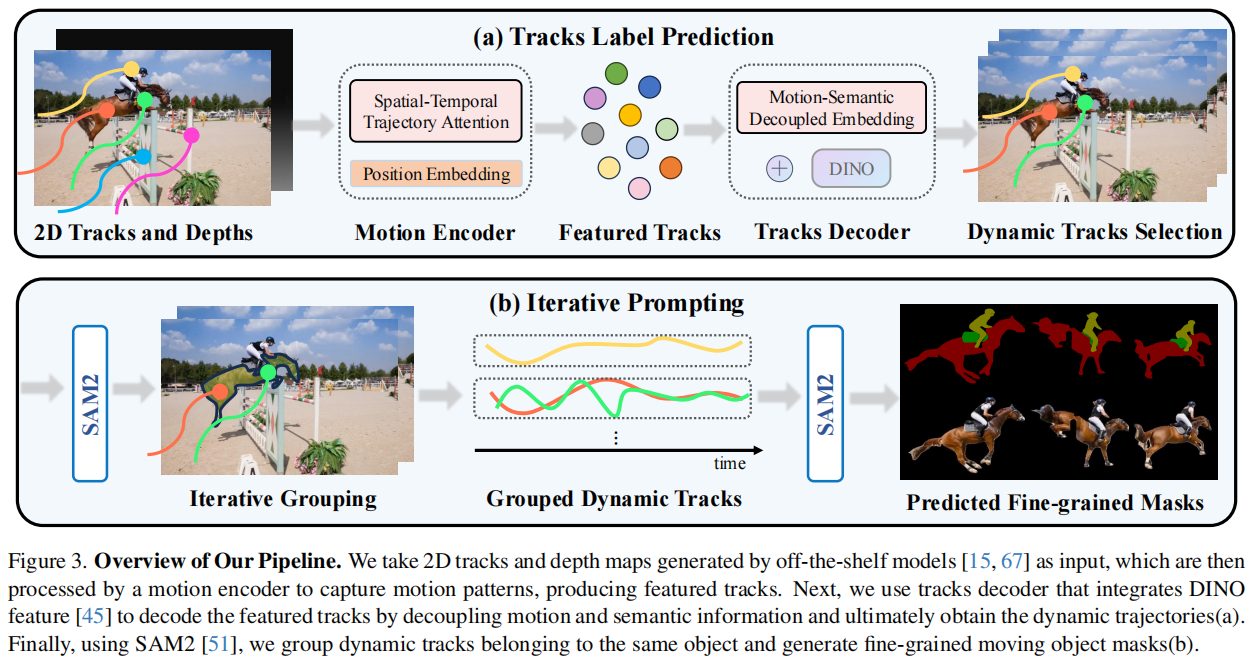
1.2D Tracks and Depths(2D轨迹与深度图)
BootsTAP方法用于生成2D轨迹,Depth-Anything算法生成深度图提供了点在三维空间中的深度信息(BootsTAP方法可以在视频中跟踪任意像素点的 2D 轨迹,同时输出每个轨迹点的置信度评分。)(深度图(Depth Map) 是一种图像或数据结构,其中每个像素的值表示对应场景点(或图像点)到相机(或其他传感器)的距离或深度。换句话说,深度图为图像中的每个像素提供了一个数值,表示该点在三维空间中离观察者有多远。)
我们的输入数据包含各种长距离运动轨迹,每条轨迹都由标准化后的像素坐标(ui, vi)、可见性指标pi以及置信度得分ci组成,其中i属于(O,时间)区间。
2.Motion Encoder(运动编码器)
位置编码 → MLP投影(多层感知机) → 时空注意力编码 → 时间池化。
(1)位置编码
将经过位置编码的坐标、深度值、差分值、可见性和置信度等信息拼接起来。在经过一层多层感知机降维和特征融合。
(2)时空注意力编码
轨迹维度注意力:在某一个特定的时间步(比如第t帧),计算该帧内所有轨迹点之间的注意力。
时间维度注意力:针对某一条特定的轨迹(比如对应风筝的那个点),计算该轨迹在所有时间步(从第1帧到第T帧)的特征之间的注意力。
时间维度注意力是把同一轨迹的不同帧的轨迹点的向量输入Transformer进行自注意力计算,轨迹维度注意力就是把同一帧下的所有轨迹点的向量输入Transformer进行自注意力计算
(3)时间池化
对时间维度进行最大值池化。
3.Featured Tracks(特征化轨迹)
特征化轨迹是论文方法中一个核心的中间表示。它指的是经过运动编码器处理后的、每条长程点轨迹的高维特征向量。
4.Tracks Decoder(轨迹编码器)
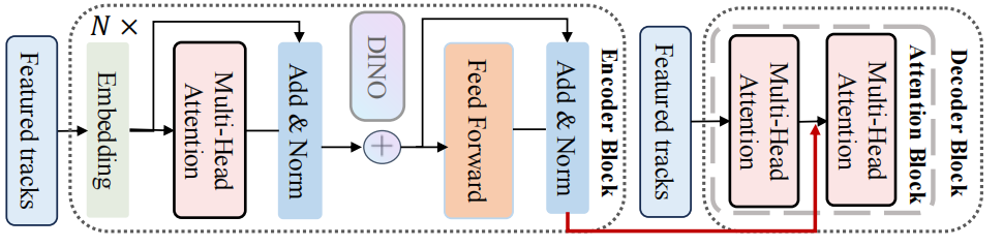
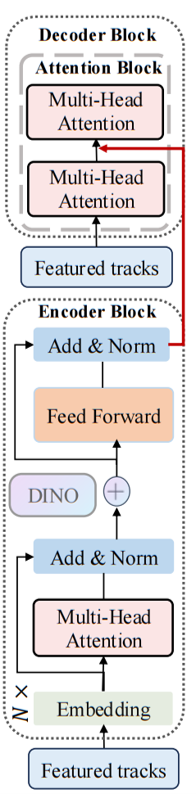 与transformer模型基本一致,先输入特征化轨迹(一个高维向量),编码器部分:
与transformer模型基本一致,先输入特征化轨迹(一个高维向量),编码器部分:
Embedding(嵌入层):将输入的轨迹特征转换为适合后续处理的向量表示(可能是维度调整或语义嵌入)。
Multi-Head Attention(多头注意力):通过多头自注意力机制,让轨迹特征在不同“头”中关注自身或其他轨迹的关系,捕捉全局依赖。
Add & Norm(残差连接+层归一化):残差连接(Add)缓解梯度消失,层归一化(Norm)稳定训练。
DINO(可选模块):图中包含一个DINO模块(可能是借鉴DINO自监督学习的思想,用于增强特征区分度或鲁棒性)。DINO特征是通过“拼接”的方式,在注意力层之前就与运动特征融合的。(DINO是DIstillation with NO labels无标签蒸馏,一种自监督学习方法,本质上是使用一个经过特殊训练的(Vision Transformer)ViT模型所提取的特征,DINO特征是一个提供外观与语义先验的辅助信息源)
Feed Forward(前馈网络):对注意力输出进行非线性变换,进一步提取特征。(一个前馈网络通常由两个线性层和一个激活函数组成,这里用的是S型激活函数)
重复的编码器块(N ×):图中显示有N个这样的编码器块(N是超参数,文档未明确,但通常为多层堆叠),以逐步细化特征。
解码器部分:
Encoder tracks(编码器轨迹特征):解码器接收编码器输出的轨迹特征作为输入(通过红色箭头的反馈或连接)。
Multi-Head Attention(多头注意力):解码器中的多头注意力机制,可能用于关注编码器特征的不同部分,或解码过程中的自注意力。
另一个Multi-Head Attention(可能是交叉注意力):图中第二个多头注意力模块,可能是交叉注意力(关注编码器和解码器之间的交互,或不同轨迹之间的关系)。
Add & Norm(残差连接+层归一化):同样用于稳定训练和缓解梯度消失。
5.Dynamic Tracks Selection
最终输出筛选后的动态轨迹
6.Iterative Grouping
我们利用这些动态轨迹作为输入,通过迭代式的两阶段提示策略来驱动SAM2[51]工作。第一阶段的任务是将属于同一物体的所有轨迹归类,并将每个物体的轨迹存储在内存中。第二阶段则利用这些存储在内存中的轨迹作为提示,让SAM2[51]生成相应的动态掩膜。
迭代分组过程内部包含了多次对SAM2的调用。它们是嵌套关系
在第一阶段,先对上个阶段“轨迹标签预测”处理的结果进行选择,我们选择那些可见点数量最多的时间帧,并在该时间帧中找出可见点中最密集的那个点。这个点被用作SAM2算法的初始输入参数,随后SAM2会为该时间帧生成一个初始掩膜。生成掩膜后,我们对掩膜的边界进行扩展处理,将扩展区域内的所有点排除在外,从而去除边缘点;同时假设这些被排除的点属于同一个物体。接着,我们转向下一个可见点数量最多的时间帧,重复上述过程,直到所有时间帧中剩余的可见点数量太少而无法继续处理为止。那些被识别为属于同一物体的点的轨迹会被存储在内存中,每个物体都被赋予唯一的标识符。最后,我们只保存每个物体在未被扩展的掩膜范围内的点。
(为什么选“可见点数量最多”的帧?可见点越多,意味着物体在该时刻被跟踪得最好,特征最明显,以此为起点最可靠。即:保证了物体在该时刻的特征最明显
为什么找“最密集”的点? “最密集”意味着这个点周围有很多同类的轨迹点。这很可能对应着物体的中心区域或一个特征稳定的部分(比如车头、人体躯干),而不是容易漂移或闪烁的边缘。以这个点作为“种子点”,能最大概率地触发SAM2分割出正确的、完整的物体,而不是只分割出一个局部或错误的部分。即:充分触发SAM2的分割能力,让可见点密集区域优先分割)
7.Grouped Dynamic Tracks
- 最上方的黄色线:是一条独立的、运动模式一致的轨迹(对应图 (a) 里骑手 / 马的黄色轨迹)
- 下方红、绿交织的线:是被分组到同一个目标的多条轨迹(对应图 (a) 里马 / 骑手的红、绿轨迹),说明这些轨迹属于同一个运动物体,被算法归为了一组。
SAM2
- 输入:从(a)部分得到动态轨迹(筛选后的动态目标轨迹)。
- 轨迹分析:
- 找到轨迹中密度最高的点(核心点)。
- 找到距离核心点最远的两个点(定义目标范围)。
- 提示SAM2:定期将“核心点+最远点”的信息作为提示,输入给SAM2,让SAM2关注该区域的目标。
- SAM2分割:SAM2根据提示生成初步的物体掩码(可能不完整)。
- 后处理:将多个不完整的掩码合并,得到完整的动态目标分割结果。
8.Predicted Fine-grained Masks(预测的细粒度掩码)
“细粒度掩码”指的是这个流程的最终产物:一个完整、精准、实例级的像素级分割结果。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 12
12 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)