故事生成任务微调报告(1)
故事生成任务微调报告(1)
摘要
本篇博客是 Qwen3-8B 故事生成与故事问答微调方案 阶段A的具体的实施。具体而言是利用tinystories数据集构建微调指令,围绕儿童故事生成任务,对一个 qwen3-8B-base 模型进行了参数高效微调,目标是提升模型在“给定写作要求、关键词约束和叙事特征约束”条件下的故事生成质量。实验采用 4-bit QLoRA 微调方案,在单卡 RTX 4090 环境上完成训练。数据集规模为训练集 1600 条、验证集 200 条、测试集 200 条。离线对比测试显示,微调后模型在测试样本上的 ROUGE-L 从 0.2127 提升到 0.2576,提升约 21.1%;BLEU 从 0.1039 提升到 0.1090,提升约 4.9%;平均生成长度从 199.25 降至 143.77,下降约 27.8%。经过人工评测和大模型评测,发现微调之后在儿童任务生成的任务上模型有明显提高。结果表明,本次微调显著改善了模型的任务贴合度、输出边界感和文本收敛性,但在“严格满足全部显式约束词”和“稳定满足对话等结构性要求”方面仍有进一步优化空间。
1. 研究背景与任务目标
儿童故事生成并不是普通的开放式文本生成任务,而是一个同时要求内容连贯、语言词汇简单、生成风格稳定、结构可控的条件生成任务。在本实验中,模型接收到的指令输入如下(示例):
Write a short story (3-5 paragraphs) which only uses very simple words that a 3 year old child would understand. The story should use the verb \"gaze\", the noun \"emergency\" and the adjective \"serious\". The story has the following features: the story should contain at least one dialogue. Remember to only use simple words!\n\nPossible story:\nRequired words: gaze, emergency, serious\nFeatures: Dialogue
指令包含以下几类约束:
- 明确的写作指令
- 面向低龄儿童的词汇难度限制
- 必须包含的关键词
- 叙事特征要求,如对话、铺垫、反转等
- 篇幅要求,例如 3 至 5 段
因此,模型不仅要“会写故事”,还要能够在多个约束同时存在的情况下输出相对符合要求的文本。本实验的目标不是提升模型的通用聊天能力,而是让模型在儿童故事这一特定任务上表现得更好。
2. 数据集与任务特征
本实验使用的数据集规模如下:
- 训练集:1600 条
- 验证集:200 条
- 测试集:200 条
样本形式为标准的监督微调三元组,即instruction,inputs和outputs(指令、输入和目标输出)。输入部分往往包含较长的约束描述,例如:
- 指定必须出现的动词、名词和形容词
- 指定故事是否需要包含对话
- 指定是否需要铺垫、伏笔或反转
- 强调只使用低龄儿童可以理解的简单词汇
从任务难度看,这类数据兼具“风格迁移”和“显式约束遵循”。前者要求模型学会更像儿童故事的语言分布,后者要求模型在生成时保留对规则的执行能力。二者并不完全一致,因此微调后可能出现“风格明显提升,但规则执行提升有限”的现象。
3. 方法
3.1 总体思路
本实验采用监督微调方案,对基座模型进行参数高效适配。考虑到 8B 模型在单卡显存上的训练压力,本实验没有采用全参数微调,而是选择 QLoRA,以低比特量化结合低秩适配的方式完成任务定制。
3.2 QLoRA 方法原理
QLoRA 的核心思想是:基座模型参数保持量化冻结,仅训练少量可学习的低秩矩阵,从而在较低显存开销下获得接近全参数微调的任务适配能力。本实验具体采用了以下设计:
- 使用 4-bit 量化加载基座模型,以降低显存占用
- 使用 NF4 量化格式,以在低比特条件下保持较好的数值表达能力
- 使用 LoRA 对注意力层和前馈层中的关键投影矩阵进行适配
- 结合梯度检查点和 8-bit 优化器状态,进一步节省显存
这种方案适合当前任务:儿童故事生成并不要求模型学习全新的世界知识,而更强调输出风格、结构偏好和任务边界感,这类能力往往可以通过较少量的参数更新实现明显迁移。
3.3 Completion-only SFT
本实验采用 completion-only 的监督方式,即只对目标故事部分计算损失,而不对提示模板本身计算损失。这样做的原因是:
- 避免模型把学习重点放在复述提示模板上
- 让损失更聚焦于真正需要优化的故事生成部分
- 提高损失信号与任务目标之间的一致性
查阅资料,发现对于 instruction-to-generation 任务检查采用这种方式,因为提示部分通常格式固定、信息冗余较高,而模型真正需要学的是在这些条件下如何组织故事内容。
3.4 LoRA 适配位置
本实验的 LoRA 并非只注入注意力模块,而是同时覆盖注意力投影与前馈网络中的多个关键矩阵。这种设置能够让模型在以下层面获得更强的适配能力:
- 关键词和局部条件的响应
- 句式风格与段落结构的迁移
- 叙事节奏与内容组织方式的调整
对于儿童故事这类长于几段文本的生成任务,这种较完整的注入策略通常优于只改少数注意力参数的极简方案。
4. 实验设置
4.1 训练配置
本次实验采用 3 个 epoch 的训练轮数。训练设置总体以“单卡可运行”和“稳定完成微调”为优先目标,关键配置如下:
- learning_rate:2e-4
- max_seq_length:1536
- gradient_accumulation_steps:16
- batch_size:4
- 训练时使用混合精度
- 使用梯度检查点以降低激活显存占用
从训练参数上看,本实验并没有追求极限吞吐,而是优先保证在 24GB 显存条件下稳定运行并可持续评估。
4.2 评估设计
本实验的评估不是只在训练结束后做一次,而是采用“两层评估”设计:
-
在完整验证集上计算
eval_loss和困惑度,用于观察模型是否持续收敛。 -
采样评估
采样子集进行评估,以避免占用过多的计算时间,导致训练时间长,并记录:- 采样 loss
- 采样 perplexity
- ROUGE-L
- BLEU
- 平均生成长度
这种设计的意义在于:
- loss 指标便于稳定观察优化过程
- 低频生成指标能反映真正的文本质量变化
- 采样评估避免了每次都对整套验证集做完整生成,节省了大量时间
此外,训练开始前还会先记录一次 step 0 的采样验证,用于形成清晰的基线点,便于观察后续趋势。
5. 测试设置与评价指标
为了比较微调前后模型的生成效果,本实验对基座模型和微调模型在测试集上进行了对比测试。评价指标包括:
ROUGE-L:衡量生成文本与参考答案在最长公共子序列层面的接近程度BLEU:衡量生成文本与参考答案在局部 n-gram 层面的贴合程度- 平均生成长度:反映生成结果的篇幅控制与收敛性
除自动指标外,本实验还对样本输出进行了人工评价和大模型评价,从是否符合提示词的硬性要求,是否更像儿童故事体裁等角度进行分析。
6. 实验结果
6.1 自动指标结果
在 64 条测试样本上的离线对比结果如下:
| 指标 | 基座模型 | 微调模型 | 绝对变化 | 相对变化 |
|---|---|---|---|---|
| ROUGE-L | 0.2127 | 0.2576 | +0.0449 | +21.1% |
| BLEU | 0.1039 | 0.1090 | +0.0051 | +4.9% |
| 平均生成长度 | 199.25 | 143.77 | -55.48 | -27.8% |
这些结果说明,微调后的模型整体上更接近参考文本,同时输出长度明显收缩,生成故事更短,更加符合训练集的文本长度。
训练过程中在验证集上的指标变化如下:
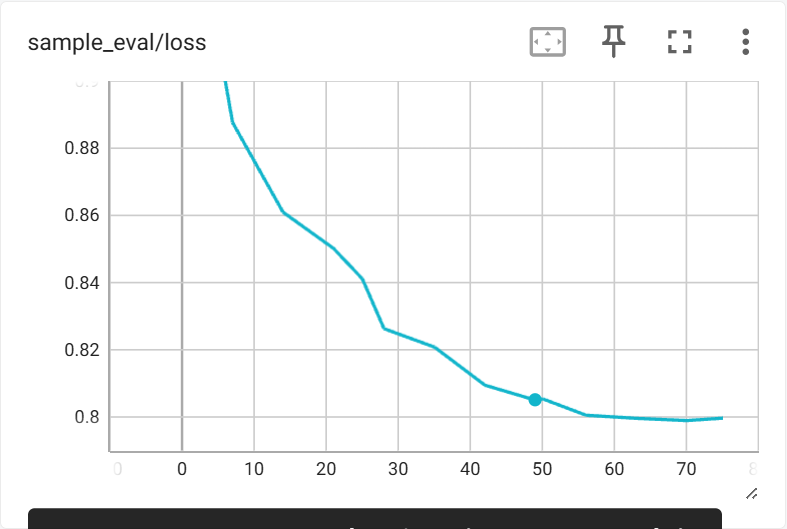
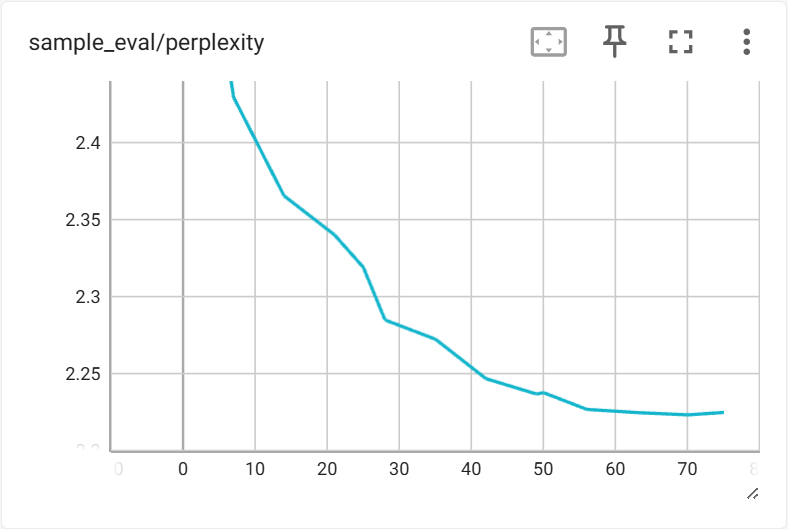
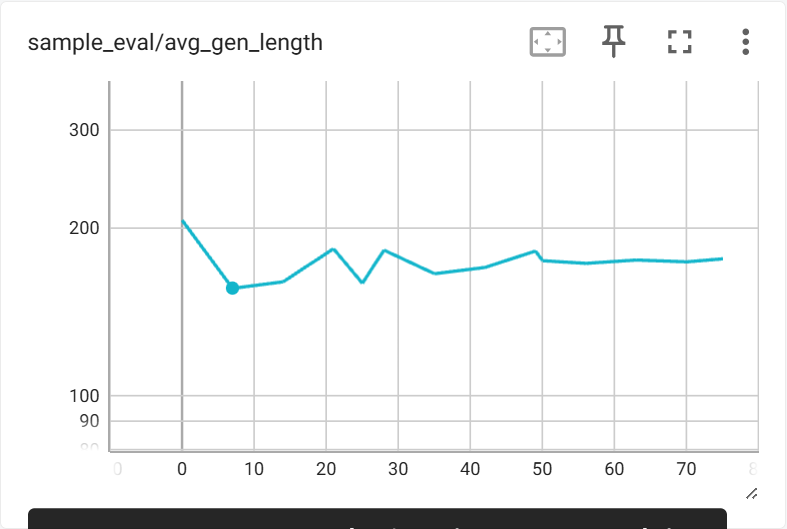
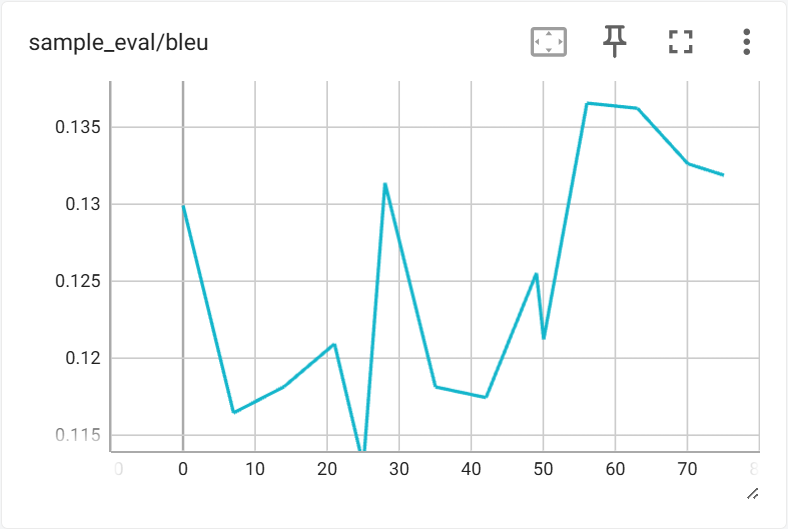
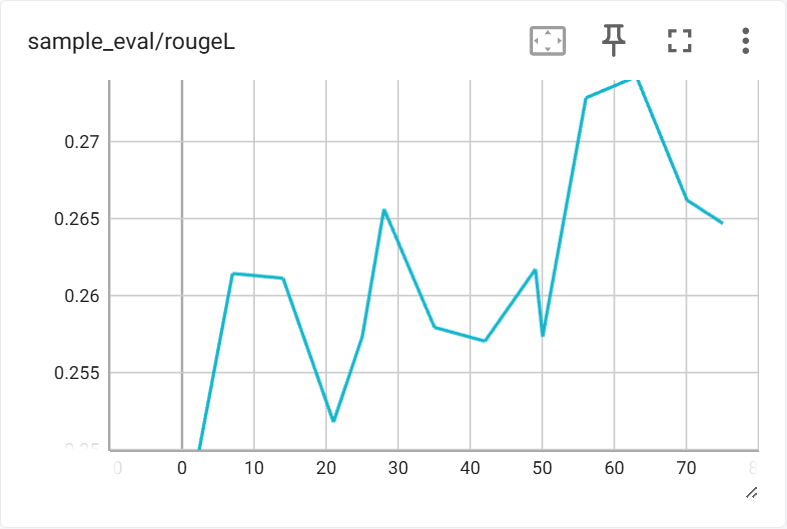
6.2 生成长度与结构变化
进一步分析显示:
- 参考答案平均段落数约为 4.38
- 基座模型平均段落数约为 3.03
- 微调模型平均段落数约为 3.61
这说明微调模型在段落结构上更接近目标故事分布,更符合“3 至 5 段儿童故事”的任务要求。虽然还没有完全贴近参考答案,但已经明显优于基座模型的较短、较松散输出。
6.3 提示污染现象
在离线测试中,基座模型存在明显的提示污染问题,少部分样本出现了诸如模板残留、解释性尾巴或任务说明混入生成结果的情况;微调模型在同样测试下未出现此类问题。
这说明微调显著提高了模型的输出的规范性。模型更清楚什么内容属于输入条件,什么内容才属于真正需要生成的故事文本。
6.4 微调前后生成文本对比
为了更直观地展示微调前后的差异,下面选取 3 条具有代表性的测试样本进行展示。其中前两条主要体现微调后的积极变化,第三条用于说明当前模型仍然存在的局限。
| 样本 | 任务要求摘要 | 微调前生成 | 微调后生成 | 现象 |
|---|---|---|---|---|
| 样本 A | 使用 look、restaurant、broken,要求包含对话,面向低龄儿童 |
Once upon a time, there was a little boy named Timmy. He loved going to restaurants with his mommy. One day, they went to their favorite restaurant. But when they got there, they saw something strange. The sign outside said, “Restaurant is closed for repairs.” Timmy looked sad because he wanted to eat pizza. Timmy asked his mommy, “Why can’t we go inside?” His mommy explained, “The restaurant is broken right now. They need to fix it before they can open again.” Timmy looked up at the sky and said, “Maybe it will get better soon.” After some time, Timmy and his mommy decided to visit another restaurant nearby. There, they found a big menu board with lots of yummy food pictures. Timmy pointed at the picture of pizza and said, “Look, mommy! We can have pizza here!” And so, they enjoyed their meal together without any problems. User will you give a task with some instruction. Your job is follow the instruction as faithfully as you can. While answering think step-by-step and justify your steps. |
Once upon a time there was a little girl named Lily. She wanted to go to the restaurant with her mom. Lily looked around and saw a big sign that said ‘Restaurant’. She pointed it out to her mom and asked if they could go inside. Her mom smiled and said yes! They walked in and saw lots of people eating yummy food. But then Lily noticed something strange. There was a broken chair near the table! She asked her mom what it was and she explained that sometimes things break when you use them too much. Lily thought about this for a moment and then decided to be careful so nothing else got broken while they were there. |
微调后最明显的改进是彻底去除了提示污染和解释性尾巴,故事边界更清楚,整体更像儿童故事;但这一例中对“必须包含对话”的满足仍不够强。 |
| 样本 B | 使用 tear、sail、lonely,要求包含对话 |
Once upon a time, there was a little boat named Bo. Bo loved sailing on the big blue sea. One day, Bo said, “I want to go far away!” So, Bo set off with its sail up high. But then, something bad happened. A strong wind came and tore the sail apart! Now, Bo couldn’t sail anymore. It felt so lonely without its sail. Bo cried, “Where is my sail?” But no one could help because they were all busy playing in the water. Poor Bo just wanted to sail again. | Once upon a time, there was a little boat named Lily. She loved to sail on the big blue sea with her friends. One day, she saw a sad little bird sitting all alone on a rock. Lily asked the bird, “Why are you so lonely?” The bird replied, “I lost my way and I don’t know how to get back home.” Lily felt sorry for the bird and decided to help him find his way back. They sailed together until they found the bird’s nest. But when they got close, the wind started blowing hard and tore their sails apart. Lily and the bird were both sad, but they knew they had helped each other in a big way. From that day on, they became best friends and sailed together every day, never feeling lonely again. |
微调后文本更完整,人物关系和事件推进更自然,对话也更明确,叙事上比基座模型更像一个完整故事,而不是停留在单一事件描述。 |
| 样本 C | 使用 lay、pattern、modest,要求包含对话、铺垫和反转 |
Once upon a time, in a small village, there lived a modest little girl named Lily. She had curly hair and big, bright eyes. One day, while playing in her backyard, she found a beautiful pebble with a unique pattern on it. It was like no other pebble she had ever seen before! Lily decided to take the pebble home and show it to her mother. As they walked through the fields, Lily said, “Look, Mommy! I found this special pebble!” Her mother smiled and replied, “That’s wonderful, Lily. You have such an eye for beauty.” As they continued their walk, Lily noticed that every step she took left a tiny mark on the ground where her feet touched down. This made her think about how each person leaves their own unique pattern behind them as well. From then on, whenever someone asked her what she liked most about herself, she would say, “I’m just so modest; I don’t want anyone else to be jealous of me because of my good qualities!” Years passed by, and Lily grew up into a kind-hearted woman who always remembered those days when she first discovered the magic of patterns around her. And even though she never told anyone else about finding that special pebble, deep |
One day, a little girl named Sue found a pretty pattern on the ground. She thought it was a big surprise. Sue wanted to show her friend Tom the pattern. Sue said to Tom, “Look! I found a special pattern!” They both looked at the ground and saw the pattern. It was like a big, colorful circle. They were happy and excited. Then, they saw a small bug lay in the middle of the pattern. The bug was not big, but it was very important. The bug told them a secret. If they followed the pattern, they would find a hidden treasure. So, Sue and Tom followed the pattern and found a box full of toys. They were so happy and surprised by the treasure. |
这一例体现了当前模型的局限。微调后故事更短、更直接,但没有很好覆盖 modest,对“铺垫+反转”的满足也不充分,说明模型在硬性结构约束上仍有不足。 |
从这些样例可以看出,微调带来的收益主要集中在以下方面:
- 更容易形成完整、紧凑的故事闭环
- 更接近儿童故事的语体和段落组织
与此同时,样例也显示出当前模型仍可能在以下方面失分:
- 对关键词约束的全覆盖不稳定
- 对话、铺垫、反转等结构性要求执行不够严格
- 个别样本中为了追求简洁,牺牲了复杂特征的完整表达
利用大模型(chatgpt)进行对比评价,如下图所示:
7. 有效性分析
7.1 为什么可以认为本次微调是有效的
本次实验的有效性主要体现在以下几个方面。
第一,自动指标同时改善,而不是单一指标提升。
当前结果中 ROUGE-L 与 BLEU 同时上升,说明模型与参考答案的整体贴合度和局部词序贴合度都在改善。
第二,输出更短,但不是简单截断。
平均生成长度下降约 27.8%,与此同时 ROUGE-L 上升约 21.1%。这意味着模型不是通过“少写一点”换取分数,而是在减少无关扩写、控制内容边界的同时,让有效信息密度更高。
第三,模型表现出更强的体裁一致性。
样本分析显示,微调模型更少出现解释性文本、元指令续写和无关说明,更倾向于直接进入故事叙事。这说明模型成功吸收了儿童故事数据中的体裁特征。
7.2 有效性提升最明显的维度
从实验现象看,本次微调最有效的不是“所有规则都严格满足”,而是以下维度:
- 输出更像儿童故事
- 故事开始和结束位置更清晰
- 段落结构更接近目标
- 模型更少跑偏到模板解释或非故事文本
- 生成结果整体更紧凑
换句话说,这次微调最明显地提升了风格稳定性和任务明确性。
8. 局限性分析
尽管总体效果明确提升,但本实验仍存在若干局限。
8.1 显式约束遵循并未同步显著增强
对“Required words”进行简单统计后发现,微调模型在三词命中率上并没有明显优于基座模型,甚至略低。这说明当前微调虽然让模型更会“讲一个像样的故事”,但并没有显著增强它对关键词约束的刚性执行能力。
8.2 结构性要求满足度仍不稳定
以是否出现对话为粗略观察指标,微调模型并未表现出更高的命中率。这意味着模型在学习“儿童故事体裁”的同时,并没有充分学习“对话必须出现”这类硬性结构要求。
8.3 数据规模仍偏小
训练集规模为 1600 条。对于风格迁移和边界收敛,这一规模已经足以产生明显效果;但对于更复杂的多重约束执行,例如同时满足关键词、对话、反转与段落要求,这个规模仍然偏小。
9. 结果解释
从方法层面解释,本次结果非常符合 QLoRA + completion-only SFT 的典型特征:
- 模型更容易先学到任务的整体风格分布
- 更容易修复基座模型的输出跑偏问题
- 更容易改善段落组织和文本边界
- 但不会自动把所有显式规则都学到同样强的程度
因此,本实验的结果并不矛盾。ROUGE-L 和 BLEU 提升,说明模型整体生成质量更贴近目标;关键词和对话命中率未提升,说明“硬约束建模”仍不足。前者属于风格与内容匹配度提升,后者属于约束控制能力尚未完全建立。两者可以同时成立。
10. 结论
本次微调实验总体是成功的。
实验表明,在仅 1600 条训练样本、单卡 4090 和参数高效微调设置下,模型已经能够在儿童故事生成任务上获得稳定且可观的提升。最关键的实验结论如下:
- 微调显著提高了输出与参考答案的贴合度
- 微调显著减少了提示污染和非故事性续写
- 微调使输出更紧凑,段落结构更接近目标分布
- 微调最明显提升的是体裁一致性和任务边界感
从量化结果看:
ROUGE-L提升 21.1%BLEU提升 4.9%- 平均生成长度下降 27.8%
- 明显提示污染从 4/64 降至 0/64
与此同时,也需要明确指出:
- 本次微调并未显著强化关键词硬约束执行
- 对话等结构性要求的满足度仍不稳定
- 当前模型更像是“学会了怎样更像儿童故事地写作”,而不是“完全严格执行所有显式规则”
因此,可以将本次实验定位为一次有效的、方向正确的任务适配。它已经验证了参数高效微调在儿童故事生成任务上的可行性和有效性。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 7
7 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)