微调 Qwen3-8B-Think 踩坑记录
微调 Qwen3-8B-Think 踩坑记录:我只用 Alpaca 格式,结果把模型的 CoT 能力训没了
这篇博客记录一次真实的项目失误。
我用 LLaMA-Factory 微调 Qwen3-8B-Think,本来目标是让模型在故事生成上表现更好,同时保留它原本很强的推理能力。结果我只准备了 Alpaca 格式数据(instruction/input/output),没有设计和保留 Think 模型特有的思考过程信号。微调后,模型即使开启think模式,也不会进行深入的思考,出现“答得快但不思考”的现象。
总结一下,这不是偶然,而是一个典型的训练目标错配问题。
一、问题现场:我到底做错了什么
1. 我的初始假设(错误)
我当时的想法是:
- Alpaca 格式足够通用,很多模型都能直接训。
- 只要 output 里是正确答案,模型就会自己学会怎么推理。
- Think 不是训练必须项。
这三个判断都不完整,尤其是第 2 点和第 3 点。
微调时的样例如下:
{"instruction": "Write a coherent children's story based on the prompt and requested features.",
"input": "Prompt: Write a short story (3-5 paragraphs) which only uses very simple words......",
"output": "Lily and Tom are friends. They like ......"}
2. 实际操作中的关键遗漏
我做的是标准 SFT 流程:
- 数据统一转成 instruction/input/output。
- output 主要放最终答案,几乎不包含结构化推理轨迹。
- 没有为 think 模型设计专门模板或字段来承载“思考态”。
- 训练目标等价于“最大化最终答案 token 的似然”。
起初训练的时候loss平稳下降,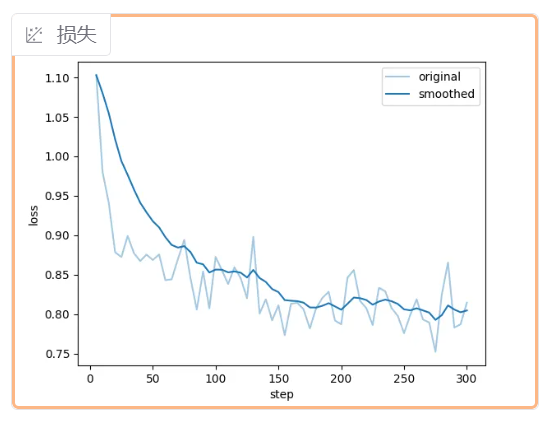
但是我在最终测试微调之后模型的性能的时候,发现模型的思考过程没有了,且通过让
gemini对生成的故事打分的方式评价模型生成故事的优劣,发现微调之后性能降低了。
问答过程如图所示:




这意味着模型被持续强化成:
- 直接给结果。
- 用最短路径结束回答。
- 减少中间推理展开。
对普通 instruct 模型,这可能还能接受;但对 Think 模型,这相当于在微调阶段持续弱化它最宝贵的推理能力。
二、为什么会这样:从训练目标看根因
SFT 的本质是让模型拟合给出的目标分布。
如果数据只奖励“最终答案”,那模型会把概率质量向“快速产出答案”收缩。
可以简单理解为:
L=−∑tlogPθ(yt∣y<t,x) \mathcal{L} = -\sum_t \log P_\theta(y_t \mid y_{<t}, x) L=−t∑logPθ(yt∣y<t,x)
当yty_tyt 主要是“结论 token”,而不是“推理 token + 结论 token”,模型自然不会优先保留长链路推理习惯。它不是“忘了推理”,而是你在新任务上告诉它:不用花那么多 token 去想,直接给我结论就好。
这就是我这次踩坑的核心:
- 基座能力没有凭空消失。
- 但在新分布上被重新对齐到了“短答优先”。
- 结果表现为 CoT 深度下降、鲁棒性下降。
三、Think 模型为什么要单独对待
Think 类模型的设计目标通常不是“更会聊天”,而是“更会推理”。
它们在训练和对齐阶段,往往更依赖以下信号:
- 多步分解能力:把问题拆成子问题。
- 中间状态一致性:前后逻辑不自相矛盾。
- 反思与修正模式:遇到冲突时进行自检。
- 推理-结论耦合:结论来自可追踪的推理轨迹。
当用纯 Alpaca 且只保留短答案时,相当于把任务改写成了“只评估最后一句”。这会导致:
- 模型推理过程被隐式压缩。
- 长链任务中的错误累积更明显。
- 对复杂指令的稳定性下降。
所以,Think 不是一个可有可无的文案标签,而是一个需要在数据与模板层面被显式维护的能力形态。
四、这次失误的典型症状
微调后我观察到几个非常一致的现象:
- 答案更短了,速度更快了,但思考过程没有了。
- 简单题准确率变化不大,复杂推理题推理能力降低了。
- 遇到需要多步约束的问题时,更容易“第一步就走偏,后面硬凑结论”。
- 同类题重复提问时,输出稳定性不如基座。
这些症状本质上都指向同一件事:模型被重新奖励成“结果导向”,而不是“推理导向”。
五、正确做法
下面是我复盘后总结的一套“至少不要再犯同类错”的做法。
1. 数据上不要只有答案,要有推理结构
至少保证训练样本中存在足够比例的“问题拆解 + 中间推断 + 最终答案”结构,而不是只有一行结论。
如果出于合规或产品策略不直接展示完整 CoT,也要在训练目标中保留可替代的中间推理监督形式,例如步骤摘要、关键判断点、约束检查点。
2. 数据集构建模版上对齐 Think 模型的对话协议
不要机械套用单一 Alpaca 模板。需要根据具体模型的 chat template 或官方建议格式,确保模型能识别“该思考时思考、该输出时输出”的边界。
3. 任务设置上混合样本分布,避免能力塌缩
不要全量替换成垂直短答数据。建议保留一部分通用推理样本做能力锚定,避免模型过度朝单一风格收缩。
六、经验教训
这次最重要的教训不是“Alpaca 不好”,而是“数据格式必须服务模型能力目标”。
我总结为如下方面:
- Think 模型不能按普通指令模型思路粗暴微调。
- 训练数据决定模型会被奖励成什么行为。
- 只监督最终答案,通常会伤害复杂推理表现。
- 模板、数据、评测必须围绕同一个目标闭环。
- 微调不是只追求任务拟合,还要守住基座核心能力。
七、接下来的方案
为了避免继续在同一个方法里消耗算力和时间,我后续会按先稳后难的顺序推进:
方案一:先换用 Qwen3-8B-Base 做微调
目标:先把故事生成任务效果做上去,拿到一个稳定可复现的业务基线模型。
执行步骤:
- 保留当前 Alpaca 风格数据,但重点提升数据质量(去重、纠错、统一风格、控制长度分布)。
- 先做小规模 SFT 试验(例如 1k-5k 样本)验证方向,再扩展到全量训练。
- 固定评测集,持续对比 Base 原始模型与微调模型在故事完整性、语言简单度、主题一致性上的差异。
- 记录训练配置和实验日志,形成可复现 pipeline,避免“这次有效下次复现不出来”。
阶段验收标准:
- 在故事生成任务上,微调模型稳定优于 Base 原始模型。
- 多轮复测波动可控,不出现大幅退化。
- 形成一套可直接复用的数据清洗和训练模板。
方案二:有余力时再尝试 Qwen3-8B-Think 微调
目标:在提升故事生成能力的同时,尽量保留 Think 模型的推理特性。
执行步骤:
- 重新设计微调指令和方法,不再只保留最终答案,加入“任务分解-关键判断-最终输出”的中间监督信号。
- 对齐 Think 模型对应的对话模板和训练格式,避免用纯 Alpaca 生硬套用。
- 采用混合数据策略:业务数据 + 通用推理样本,防止模型只学会短答。
- 单独增加推理评测集,重点监控多步约束任务中的稳定性和一致性。
我会先把方案一做扎实,再决定是否投入资源到方案二。这样既能保证阶段成果,也能降低继续踩坑的风险。
八、结语
这次踩坑的代价不小,但价值很高:我终于真正理解了“能力保持”在微调中的优先级。
以后再做 Think 类模型微调,我会思考:
- 我的数据是否真的在奖励推理,而不只是奖励结论?
- 我的模板是否与模型原生行为兼容?
- 我的评测是否能第一时间发现 CoT 能力退化?
对 Think 模型来说,训得更像你,不代表训得更强。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 9
9 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)