【类增量学习之2025ICLR】SD-LORA:用于类增量学习的可扩展解耦低秩适配
零、前置知识
1.Low-Rank Adaptation (LoRA)
LoRA 是非常常见的参数高效微调方法。
1.1.基本意思
当我们微调一个大模型时,不直接改全部参数,而是只学习一个低秩矩阵分解形式的增量更新。
通常写作:
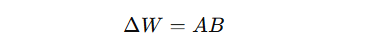
其中 AAA 和 BBB 的秩很低,所以需要训练的参数量比直接训练整个 WWW 小很多。
1.2.中文理解
你可以把 LoRA 理解成:
- 不给原模型“大动手术”,只外挂一个很小的、低秩的可学习补丁。
1.3.在本文中的作用
这篇论文不是重新发明 LoRA,而是在持续学习场景下,重新设计了 LoRA 如何逐任务累积、如何避免遗忘、如何保持可扩展性。
2.Class Incremental Learning(类增量学习)
2.1.含义
模型要按顺序学习新类别。比如:
- 任务 1 学猫、狗
- 任务 2 学车、船
- 任务 3 学鸟、马
学习新任务时,模型通常不能访问旧任务的全部数据。
最后测试时,模型需要在所有学过的类别上统一分类,而且通常不知道当前样本属于哪个任务。
2.2.为什么难
因为模型很容易在学习新类别时,把旧类别忘掉,这就是:
- catastrophic forgetting
- 中文:灾难性遗忘
-
2.3.这篇论文的重点
这篇论文的研究不是一般 continual learning,而是更难的 class incremental learning,简称 CIL。
3.背下单词吧
- LoRA:低秩适配
- Decoupled(解耦的):把 LoRA 更新的幅值与方向解耦
- Scalable(可伸缩/拓展的):随着任务数增加仍保持良好扩展性
- Class Incremental Learning(类增量学习):顺序学习新类别,测试时在所有已学类别上统一分类
4. Continual Learning (CL_持续学习)
4.1.含义
模型不是一次性在静态数据集上训练完,而是要随着新任务不断到来持续学习。
4.2.在这篇论文里是什么意思
这里特指:模型要一个任务一个任务地学,而且学新任务时不能随意访问旧任务全部数据,因此会面临遗忘问题。
4.3.相关概念
- catastrophic forgetting:灾难性遗忘
- class incremental learning:持续学习中的一种更难设定_类增量学习
5. foundation models(基础模型)
5.1.含义
指大规模预训练模型,比如 ViT、LLM 这类已经在大数据上预训练过、具有较强迁移能力的模型。
5.2.在这篇论文里
作者主要讨论的是视觉基础模型,如 ViT-B/16。意思是:先利用预训练模型本身已经学到的大量通用知识,再把它用于持续学习
6. promising paradigm(有前景的范式)
6.1.含义
- “paradigm” 在学术论文里常指一种研究框架、方法路线或总体思路。
- 这里不是“某个具体算法”,而是说:
“基础模型 + 持续学习” 是一个值得发展的方向。
7. sequential tasks(顺序/序列任务)
7.1.含义
任务不是同时给出,而是按时间顺序一个接一个出现。
7.2.在本文里的重要性
持续学习最核心的设定就是“任务顺序到来”。
难点在于:新任务训练可能破坏旧任务能力。
8. prompt-based methods(基于提示的方法)
8.1.含义
通过学习 prompt(提示向量、提示 token、提示模块)来适配新任务,而不大幅修改原始模型参数。
8.2.在本文里
作者提到的 L2P、DualPrompt、CODA-Prompt 都属于这条路线。问题是 prompt 池会越来越大,测试时还要选 prompt,推理不够高效
9. Low-Rank Adaptation-based / LoRA-based(基于低秩适配的方法)
9.1.含义
LoRA 通过低秩矩阵分解来表示参数更新,只学习少量附加参数,而不是全量微调。
9.2.在本文里
作者研究的是:在持续学习场景下,怎么让 LoRA 不只是“省参数”,还能够“少遗忘、可扩展”。
10. expanding a prompt/LoRA pool(可拓展的prompt/LoRA池)
10.1.含义
每来一个新任务,就增加一些新的 prompt 或新的 LoRA 模块。
10.2.为什么这是问题
因为任务越多,池子越大:
- 参数越来越多
- 存储越来越大
- 测试时选择成本越来越高
这就是作者所说的 scalability challenge。
11. retaining samples of previous tasks(保留先前任务的样本)
11.1.含义
把旧任务中的一部分数据存下来,在学新任务时一起训练,帮助模型不要遗忘。
11.2.对应术语
这类做法常叫:
- rehearsal(排练/复习)
- replay(重放/回放)
- sample memory(样本记忆库)
11.3.这篇论文的立场
作者希望不保留旧样本,也就是做 rehearsal-free 的持续学习
12. scalability challenges(可拓展的挑战)
12.1.具体指什么
不是说“模型不能训练”,而是说当任务数增加时,方法会越来越不实用,比如:
- 组件越来越多
- 存储越来越大
- 推理越来越慢
- 管理越来越复杂
13. magnitude and direction of LoRA components(LoRA组件的幅值与方向)
13.1.幅值(magnitude)
表示一次参数更新“有多大”。
13.2.方向(direction)
表示参数更新“朝哪个方向去”。
13.3.在本文中的创新点
作者不是把 LoRA 更新当成一个整体来学,而是把它拆成:
- 更新方向
- 更新强度
并且在持续学习中把这两者分离处理。这就是标题里 Decoupled 的具体含义
14. low-loss trajectory(低损失轨迹)
14.1.含义
训练过程中,模型参数沿着一条损失始终较低的路径移动。
14.2.直观理解
不是“为了学新任务硬跳到另一个点”,而是沿着一条比较平滑、对旧任务也不太伤害的路线前进。
14.3.在本文中的作用
作者认为 SD-LoRA 正是通过这种方式缓解遗忘。
15. overlapping low-loss region(重叠低损失区域)
15.1.含义
对多个任务来说,都能保持较低损失的一块参数空间区域。
15.2.直观理解
可以把它理解为:
- 不是每个任务都完全需要不同的一套参数
- 某些参数区域对多个任务都“够好”
15.3.本文主张
SD-LoRA 会逐步走向这样一个共享区域,因此能兼顾新旧任务
16. stability-plasticity trade-off(稳定性-可塑性权衡)
16.1.stability(稳定性)
记住旧知识,不轻易遗忘。
16.2.plasticity(可塑性)
有能力吸收新知识,适应新任务。
16.3.trade-off(权衡)
两者通常是冲突的:
- 太稳定:学不会新任务
- 太可塑:旧任务忘得快
17.component selection(组件选择)
17.1.含义
测试时需要判断当前样本该使用哪个 prompt、哪个适配器、哪个 LoRA 模块。
17.2.为什么作者不喜欢它
因为这会:
- 增加推理复杂度
- 降低扩展性
- 随任务增多而变得更麻烦
18. end-to-end optimized(端到端优化)
18.1.含义
模型中所有要学的参数可以一起围绕最终目标直接优化,而不是拆成多个相互独立的阶段分别训练。
18.2.在这篇论文里
作者把“是否端到端优化”视为一个重要优点,因为这意味着方法整体目标更统一。
19.PEET(参数高效微调)
19.1.核心
不对整个大模型做全参数微调,而是只增加或只训练一小部分参数,就让模型适应新任务。
19.2.论文中的理解
论文里明确说,把 PEFT 和 基础模型上的持续学习 结合起来很重要,因为如果每来一个新任务都做一次 full fine-tuning,计算和存储开销都会非常大,几乎不可接受。
所以作者把 PEFT 当成一种更现实的路线:
在保留基础模型主体参数的前提下,只通过少量附加参数去适应每个新任务。
- PEFT 是总类别
- Prompt-tuning、Prefix-tuning、Adapter、LoRA 都是 PEFT 的具体实现方式。
20.Prompt-tuning(提示微调)
20.1.含义
通过学习一组可训练的 prompt 表示,引导基础模型适应新任务,而不是大规模改动模型主体参数。
20.2.特点:
- 改动小
- 参数少
- 常用于基础模型适配
- 在持续学习里容易发展成越来越大的 prompt pool
20.3.在本文中的位置
L2P、DualPrompt、CODA-Prompt、HiDe-Prompt 都属于这条路线。
21. Prefix-tuning(前缀微调)
21.1.含义
和 prompt-tuning 类似,也是学习一组额外的可训练表示,只不过它更强调在 Transformer 内部加入“前缀”形式的表示来影响后续计算。
21.2.和 Prompt-tuning 的关系
二者都属于 PEFT,只是插入位置和作用方式略有区别。
22.Adapter(适配器方法)
22.1.含义
在 Transformer 层之间插入一些轻量的小模块,训练这些模块来适应新任务,而原始大部分参数保持冻结。
22.2.特点:
- 需要显式增加网络模块
- 比全量微调省参数
- 属于经典 PEFT 路线之一
一、摘要
1. 研究背景
随着基础模型的发展,基于基础模型的持续学习(CL)成为一个很有前景的研究方向,因为预训练模型已经积累了大量通用知识,可以用来更好地处理顺序到来的任务。
2. 问题
现有方法主要有两类不足:
- 一类是 prompt-based 方法,往往需要不断扩展 prompt 池;
- 另一类是 LoRA-based 方法,往往需要扩展 LoRA 池,或者保存旧任务样本进行回放。
- 这样一来,随着任务数量增加,方法会面临明显的可扩展性问题,包括存储开销、参数膨胀和推理复杂度上升。
3. 方法
针对这些问题,论文提出了 SD-LoRA(Scalable Decoupled LoRA),用于类增量学习。它的核心做法是在不使用回放样本的前提下,把 LoRA 组件中的幅值(magnitude)和方向(direction)分开持续学习。
4. 机制
论文的经验分析和理论分析表明,SD-LoRA 在训练过程中倾向于沿着一条低损失轨迹(low-loss trajectory)前进,并最终收敛到一个对所有已学任务都有效的重叠低损失区域(overlapping low-loss region)。正因为如此,它能够较好地平衡稳定性(记住旧任务)和可塑性(学习新任务)。
5. 贡献
这篇论文的主要贡献可以概括为四点:
- 提出了一个无回放、可扩展的解耦式 LoRA 方法 SD-LoRA;
- 从经验和理论两方面解释了它为什么有效;
- 进一步提出了两个更高参数效率的变体;
- 实验表明该方法在多个持续学习基准和多种基础模型上都表现有效,同时支持端到端优化和高效推理,因为测试时不需要做额外的组件选择。
6.一句话总结
SD-LoRA 是一种面向类增量学习的、无回放的解耦式 LoRA 方法,它通过分离更新的幅值和方向,在保证推理高效的同时,缓解灾难性遗忘并提升可扩展性。
7.代码仓库
SD-LoRA:一种面向类增量学习的可扩展解耦低秩适配方法。
二、介绍
1. 研究背景
这部分首先从持续学习(CL)的一般定义讲起:持续学习希望构建一种计算学习系统,使它能够在不断变化的环境中持续适应,同时保留已经学到的旧知识。与传统监督学习假设训练数据满足 id(独立同分布) 不同,持续学习面对的是非平稳数据,任务是按顺序逐个到来的。也正因为如此,模型在学习新任务时很容易出现对旧任务性能明显下降的现象,也就是灾难性遗忘。
接着作者把背景推进到基础模型上的持续学习。他们指出,近几年基础模型因为具有大规模预训练知识,在知识迁移和抗遗忘方面表现出明显优势,因此“foundation model + continual learning” 成为很有潜力的研究方向。
2. 问题
作者接下来指出,现有方法虽然有效,但都存在明显的可扩展性问题。
第一类是 prompt-based 方法。像 L2P、DualPrompt、CODA-Prompt 这类方法,会为新任务逐步学习 prompt pool,并在测试时从中选择与当前样本最匹配的 prompt。问题在于:虽然它们不需要人工提供任务 ID,但随着任务数量增加,prompt 池会越来越大,测试时的 prompt 识别与选择也会越来越复杂,因此会带来推理扩展性不足的问题。
第二类是更依赖内存的路线。HiDe-Prompt 在 prompt 学习的同时存储大量旧样本,InfLoRA 虽然采用 LoRA 保持参数高效,但在增量训练中同样需要回放大量旧样本。这类方法的问题在于:它们对样本存储的依赖太强,在真实部署尤其是资源受限或大规模持续学习场景中,很难做到真正可扩展。

因此,作者实际上在这里提出了一个核心判断:现有方法要么推理不够高效,要么训练依赖 rehearsal memory,要么无法做到真正端到端优化。
3. 方法
针对上述问题,作者提出了 SD-LoRA(Scalable Decoupled LoRA)。它面向的是类增量学习(class incremental learning),并试图同时满足三项理想性质:
- Rehearsal-free:不保存旧任务样本;
- Inference Efficiency:测试时保持高推理效率;
- End-to-end Optimization:所有参数围绕持续学习目标统一进行端到端优化。
SD-LoRA 的核心做法是:在持续学习过程中,增量地加入 LoRA 组件,但不是把它们作为一个整体处理,而是把 LoRA 更新中的幅值(magnitude)和方向(direction)分开学习。这样一来,模型既可以保留已经学到的有效方向,又可以继续适应新任务。更重要的是,作者强调 SD-LoRA 在测试时可以直接使用最终训练好的模型进行评估,而不需要像 prompt-pool 方法那样做任务相关的组件选择,因此推理更高效。
4. 机制
这部分 Introduction 里已经提前给出了作者对方法有效性的解释,也就是后文会详细展开的“工作机制”。
作者认为,SD-LoRA 在训练过程中会沿着一条低损失路径(low-loss path)前进,并最终收敛到一个对所有已学习任务都有效的重叠低损失区域(overlapping low-loss region)。正因为它不是简单地为每个任务单独开一套互不相干的适配器,而是在已有方向上持续调整和扩展,所以它能够在稳定性和可塑性之间取得较好的平衡:既尽量不忘旧任务,又能继续学习新任务。
作者还进一步观察到:随着持续学习推进,后续新学到的 LoRA 方向的重要性会逐渐减弱。换句话说,早期学到的一些方向更像是“主干”,后期更多是在其基础上做修正。正是基于这个观察,作者后面又提出了两个更省参数的版本,一个通过降秩(rank reduction),一个通过知识蒸馏(knowledge distillation),来进一步提升参数效率。
5. 贡献
这部分 Introduction 最后把论文贡献概括成三点。
- 作者提出了一个基础模型上的持续学习方法 SD-LoRA,它同时具备无回放、推理高效、端到端优化这三个优点;同时还给出了两个更高参数效率的变体。
- 作者不仅给出了方法,还从经验分析和理论分析两方面解释了 SD-LoRA 为什么有效,并说明了它为何可以不依赖任务特定的组件选择。
- 作者在多个持续学习 benchmark 和多种 foundation model 上做了系统实验,验证了 SD-LoRA 的有效性。
三、相关工作
1. 研究背景
持续学习(CL)的目标,是让模型能够按顺序学习新任务,同时尽量保留已经学到的旧知识,核心就是缓解灾难性遗忘。现有 CL 方法大体可以分成三类:基于回放的方法、基于正则化的方法、以及基于结构的方法。其中,回放法通过保留旧样本来减轻遗忘;正则化法通过在损失函数中加入约束项,限制重要参数被破坏;结构法则通过扩展或调整模型结构,为新任务分配额外模块,从而避免覆盖旧知识。作者特别说明,本文关注的是更难也更实用的 类增量学习(class-incremental learning):测试时模型无法获得任务身份信息,却必须在所有已学任务上统一工作。
2. 问题
作者认为,传统类增量学习方法往往要么需要从头训练,要么依赖高参数开销的调优,容易带来过拟合和任务间干扰。进一步到基础模型上的持续学习时,已有方法虽然已经利用了预训练模型更强的知识迁移能力,但仍然存在关键缺陷:像 L2P、DualPrompt、CODA-Prompt 这类方法主要依赖 prompt-tuning,而 HiDe-Prompt 和 InfLoRA 则进一步依赖大量旧样本存储。结果就是,现有方法虽然各有优点,但没有一种能同时满足“无回放、推理高效、端到端优化”这三项理想性质。
3. 方法
在这样的相关工作背景下,作者提出 SD-LoRA,把它定位为一种面向基础模型持续学习的、rehearsal-free 的 LoRA-based PEFT 方法。这一段没有展开公式细节,但已经明确说明:SD-LoRA 想填补现有方法的空白,即同时兼顾不存旧样本、推理高效、端到端优化。作者还提到,SD-LoRA 也可以从另一个角度被理解为某种 model-merging 思想的延伸,只不过它是与持续学习研究并行发展、并且相互补充的。
4. 机制
这一段在机制层面主要强调两点。第一,为什么要把 PEFT 和基础模型持续学习结合起来:因为如果每来一个任务都做 full fine-tuning,无论计算还是存储代价都太高。第二,作者回顾了 PEFT 的三种代表路线:adapters 是在 Transformer 层里插入轻量模块,prompt-tuning / prefix-tuning 是学习输入或前缀表示,LoRA 则是向预训练权重上叠加低秩更新分支。作者的判断是:这些 PEFT 技术在单任务或离线多任务中很有效,但在基础模型上的持续学习场景里,其能力边界还没有被充分研究,因此 SD-LoRA 选择走一条无回放、LoRA-based 的 PEFT 路线。
5. 贡献
如果把这段 Related Work 的作用压缩成一句话,那就是:作者先系统梳理了 CL、基础模型 CL、PEFT 三条研究线,然后指出现有工作仍缺少一个能同时满足三项关键性质的方案,最后把 SD-LoRA 放在这个缺口上,说明它的研究意义和定位。换句话说,这一段的贡献不是提出新实验结果,而是为后文的方法设计建立一个清晰的问题坐标系:为什么现有方法不够,为什么 LoRA 值得继续做,为什么 SD-LoRA 是必要的。
四、提出方法:SD-LoRA
- 3.1 Preliminaries:定义持续学习任务和标准 LoRA
- 3.2 SD-LoRA:提出核心方法
- 3.3 Empirical Analysis:用实验现象解释方法机制
- 3.4 Theoretical Analysis:用理论解释为什么早期方向重要
- 3.5 Two Variants:提出两个更省参数的版本
4.1 预备知识:先把问题和 LoRA 讲清楚
(1)问题设定
作者把类增量学习写成一个标准的顺序分类问题:有 N 个顺序到来的任务 T1,…,TN。训练第 t 个任务时,只能看到当前任务的数据 Dt,看不到之前任务的数据。训练目标是让分类器 fθ 在当前任务上优化损失;而总体目标则是:学完当前任务后,模型不仅要在当前任务上表现好,也要在之前所有任务上都尽量保持性能。
(2)标准 LoRA
接着作者回顾 LoRA。LoRA 的核心思想是:不直接改原始权重 W0,而是只学习一个低秩更新 ΔW=AB,其中 A 和 B 都是小矩阵,因此参数量很少。这样某一层的输出就从 W0X 变成 (W0+AB)x,而原始权重 W0在微调过程中保持冻结。
这一小节的核心意思
4.1 的目的就是把后面的方法建立在两个基础上:
- 任务是顺序学习、不能访问旧数据
- 参数更新采用的是LoRA 这种低秩适配形式。
4.2 SD-LoRA:第三节最核心的方法部分
(1)关键出发点
作者先把普通 LoRA 的更新 ΔW=AB进一步分解成两部分:
- magnitude:更新的大小,也就是
- direction:更新的方向,也就是归一化后的
作者认为,普通 LoRA 把这两者绑在一起学,不够灵活;而已有研究也提示,在微调里 direction 往往比 magnitude 更关键。
(2)SD-LoRA 的核心做法
于是,SD-LoRA 的设计就是:在持续学习过程中,把 LoRA 的幅值和方向解耦学习。更具体地说:
- 以前任务学到的方向 AkBk 被保留下来并固定;
- 当前任务学习时,旧方向对应的系数 αk 仍然可以继续更新;
- 同时为当前任务再学习一个新的方向 AtBt和它对应的系数。
因此,第 t 个任务时某层的更新不再是单个 AB,而是:
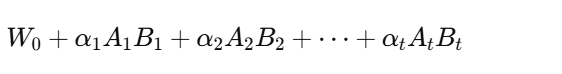
其中旧方向固定,新方向和所有系数可学习。
(3)这一设计想解决什么
这个设计的目的,是让模型不要每学一个新任务就“推翻”以前的 LoRA 更新方向,而是保留早期方向,把新任务更多地写成“在旧方向上重新加权,再加少量新方向修正”。这也是标题里 Decoupled 的真正含义。
4.3 经验分析:作者用三个发现解释 SD-LoRA 为什么有效
Finding 1:不同任务的好解其实彼此靠得更近
- 实验结果_Figure2
作者先观察到:如果把基础模型分别对不同任务单独 fine-tune,得到的那些任务最优权重,彼此之间往往比它们和原始预训练权重 W0 更接近。也就是说,不同任务的“好参数”并不是完全分散的,而可能在参数空间里彼此接近。进一步实验表明,即便后续任务只持续调 LoRA 的 magnitude,而固定第一个任务学到的 direction,效果都能超过 vanilla LoRA。作者据此得出:只要方向学得好,单靠调整大小就已经能兼容多个任务。
Finding 2:早期学到的方向特别重要
- 支持实验Figure3
作者继续分析发现:以前任务保留下来的方向,尤其是最早几项任务学到的方向,在整个持续学习过程中非常重要。具体表现是:新学到的方向一开始和旧方向很相似,说明存在方向复用;随着任务推进,新方向才逐渐偏离旧方向,加入一些细微修正。与此同时,早期任务对应的 magnitude 会快速上升,而后期任务对应的 magnitude 整体呈下降趋势。作者把这解释成:模型越来越依赖早期方向作为主干,而后期方向更多是局部修正项。
Finding 3:SD-LoRA 在走一条 low-loss path
第三个发现是最关键的。作者做了权重插值实验,比较 vanilla LoRA 和 SD-LoRA 在两个连续任务之间的参数路径。结果显示:SD-LoRA 从旧任务权重走向新任务权重时,新任务性能上升,但旧任务准确率几乎不掉;而 vanilla LoRA 则会出现“新任务好了,旧任务掉了”的典型遗忘现象。于是作者认为,SD-LoRA 不是简单跳到一个新解,而是在沿着低损失路径(low-loss path)前进,最终落到对多个任务都友好的重叠低损失区域(overlapping low-loss region)。
4.3 的一句话总结
这一小节实际上想说明:SD-LoRA 之所以能减少遗忘,是因为它会保留早期关键方向,并通过调整这些方向的权重,把模型引导到一个对新旧任务都兼容的共享低损失区域。
4.4 理论分析:为什么早期方向会这么重要

这一定理背后的直观意思是:早期学到的方向更接近共享更新里的“主成分”,因此更基础、更稳定,也更值得被后续任务反复复用;而后面学到的方向更多是在这些主方向基础上的细修正。这就从理论上呼应了前面经验分析里 magnitude 递减、早期方向更重要的现象。
4.5 两个变体:在核心机制不变的前提下进一步省参数
(1)SD-LoRA-RR
第一个变体叫 SD-LoRA-RR,其中 RR 是 Rank Reduction。作者的观察是:后期任务新引入的方向贡献越来越小,那么就没必要一直给后期任务分配和早期任务一样高的 rank。于是他们对后期任务的 LoRA 矩阵逐步降秩:早期任务 rank 高,后期任务 rank 低。这样可以减少参数量,同时保留主要性能。
(2)SD-LoRA-KD
第二个变体叫 SD-LoRA-KD,其中 KD 是 Knowledge Distillation。它更进一步:每学完一个新方向后,不是立刻保留它,而是先看这个新方向能否被之前学到的方向线性表示。如果能用旧方向的线性组合近似表示,那么作者就不保留这个新方向,而是把拟合系数吸收到已有的 magnitude 里。这样就能在不继续扩张方向集合的情况下,把新知识“蒸馏”到旧方向里。
4.5 的核心意义
所以,4.5 的重点不是重新发明新方法,而是在 4.3 的经验发现之上进一步得出:既然后期方向边际贡献变小,就可以:
- 要么让后期方向更低秩;
- 要么干脆把新方向吸收到旧方向里。
4.6.相关图解
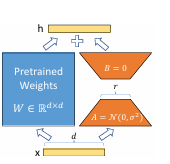
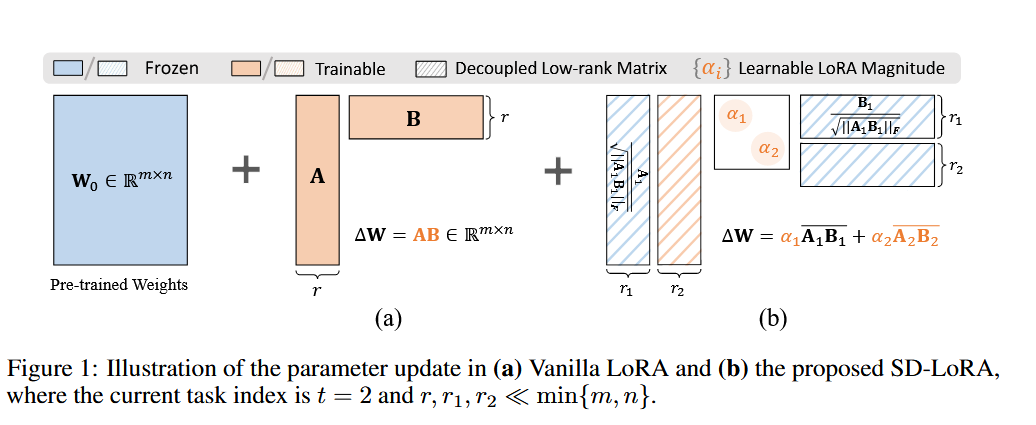 Figure 1
Figure 1
- 对比a和b
- (a) Vanilla LoRA
- (b) 论文提出的 SD-LoRA
普通 LoRA 直接学习一个低秩更新 AB,而 SD-LoRA 把更新拆成“方向 + 幅值”,并且把旧任务学到的方向保留下来。

左图


右图


这张图的意义

对持续学习的帮助

一句话总结
左图是普通 LoRA:直接学一个低秩更新 AB;右图是 SD-LoRA:把更新拆成多个“方向”与对应“幅值”之和,在持续学习中保留旧方向、学习新方向并调整各方向权重。
Figure2
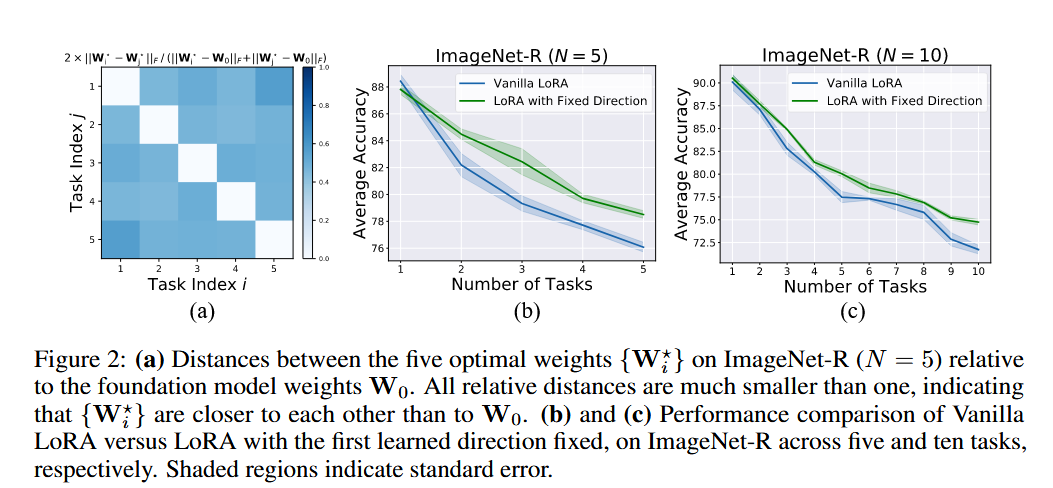
- 支持上述Find1
- 不同任务各自微调得到的最优权重,其实彼此很接近;
- 即使固定早期学到的一个方向,只调幅值,效果也能比普通 LoRA 更好。



一句话总结
不同任务单独微调得到的最优权重彼此接近,因此一个早期学到的 LoRA direction 可能已经包含了多个任务共享的主要更新方向;实验上,固定第一个方向、后续只调整 magnitude,效果甚至优于 vanilla LoRA,这为 SD-LoRA 保留旧方向的设计提供了依据。
Figure3
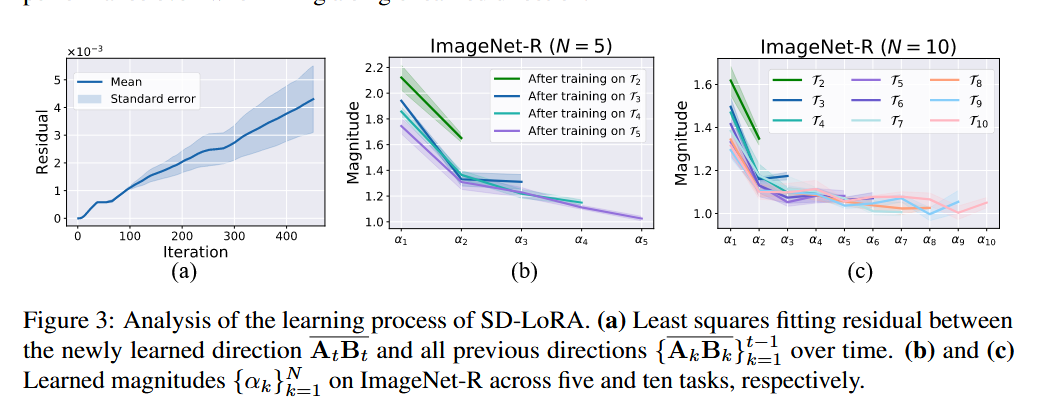
一句话总结
Figure 3 表明,SD-LoRA 在训练初期会让新方向与旧方向保持较强对齐,说明存在方向复用;随着训练推进,新方向逐渐分化,但从 learned magnitudes 来看,模型始终更依赖早期任务学到的 directions,而后期 directions 更多只是细微修正。这一发现直接支持了 SD-LoRA 固定旧方向以及后续参数压缩变体的设计。
五、实验设置
1. 实验设置
作者先说明了实验所用的数据集、任务划分、评价指标、对比方法和训练细节。
在数据集上,他们主要使用了三个标准持续学习基准:
- ImageNet-R
- ImageNet-A
- DomainNet
其中,ImageNet-R 被划分为 5/10/20 个任务,ImageNet-A 被划分为 10 个任务,DomainNet 被划分为 5 个任务。此外,附录里还补充了 CIFAR100 和 CUB200 的结果。
在评价指标上,作者用了两个经典指标:
- Acc(Average Accuracy):持续学习全部完成后,在所有任务上的平均准确率
- AAA(Average Anytime Accuracy):每学完一个新任务后,都统计当前已经见过任务的平均准确率,再把整个过程累计起来
也就是说,Acc 更看最终结果,AAA 更看整个学习过程中的持续表现。
在对比方法上,作者选了当前较强的 ViT-based 持续学习方法,包括:
- L2P
- DualPrompt
- CODA-Prompt
- HiDe-Prompt
- InfLoRA
同时还加入了 full fine-tuning 作为一个较低基线。
在模型和实现上,主干网络使用的是 ViT-B/16,主版本来自 ImageNet-21K 预训练后再在 ImageNet-1K 上微调的模型;此外还测试了 DINO 的自监督 ViT-B/16。SD-LoRA 被插入到所有 Transformer block 的 attention 层中,具体修改的是 query 和 value projection。基础 rank 设为 r1=10。SD-LoRA-RR 进一步设置了 ![]() 来控制降秩,SD-LoRA-KD 则设定了拟合残差阈值
来控制降秩,SD-LoRA-KD 则设定了拟合残差阈值![]() 。训练统一使用 Adam 优化器。
。训练统一使用 Adam 优化器。
2. 实验结果
这一节的实验结果主要证明了四件事。
(1)在不同 benchmark 和不同 backbone 上,SD-LoRA 都更强
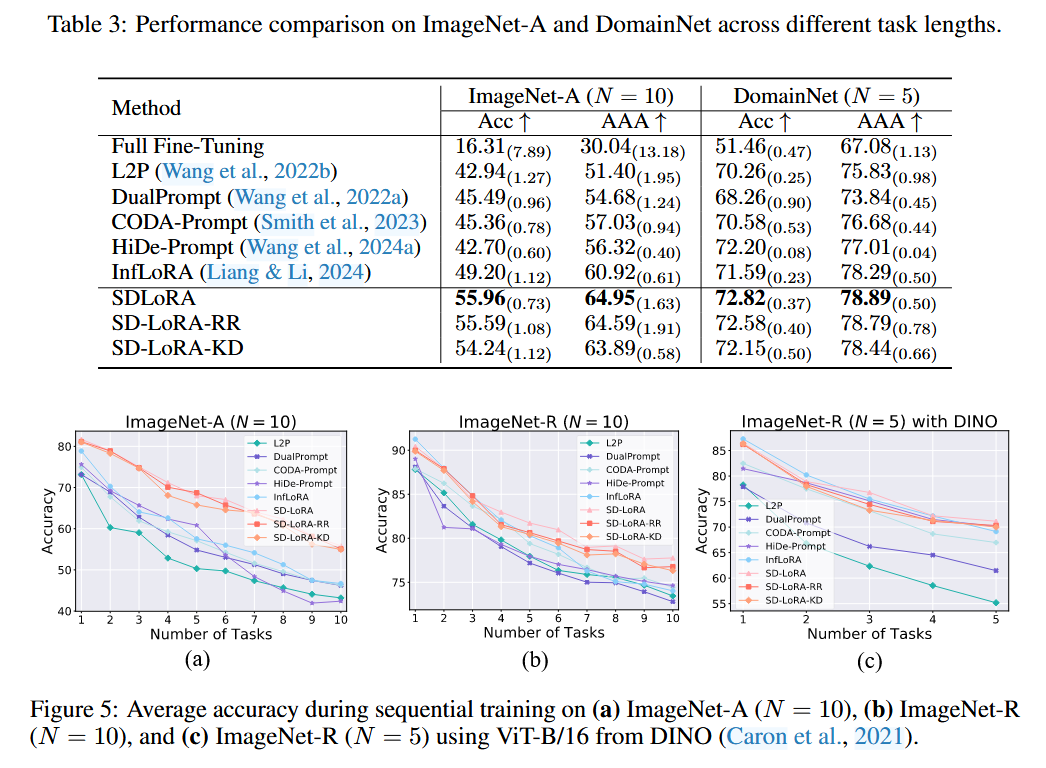
作者在表 2 和表 3 中显示,SD-LoRA 在多个持续学习 benchmark 上都优于现有方法。比如:
- 在 ImageNet-R (N=20) 上,SD-LoRA 比 InfLoRA 高 7.68% Acc 和 4.62% AAA
- 在 ImageNet-A 上,SD-LoRA 比 HiDe-Prompt 高 31.05% Acc 和 15.32% AAA
- 在更复杂的 DomainNet 上,SD-LoRA 也取得了最优性能
此外,把 backbone 换成 DINO 的自监督 ViT-B/16 后,SD-LoRA 仍然保持优势,说明它不是只对某一个 backbone 有效,而是具有一定泛化性。
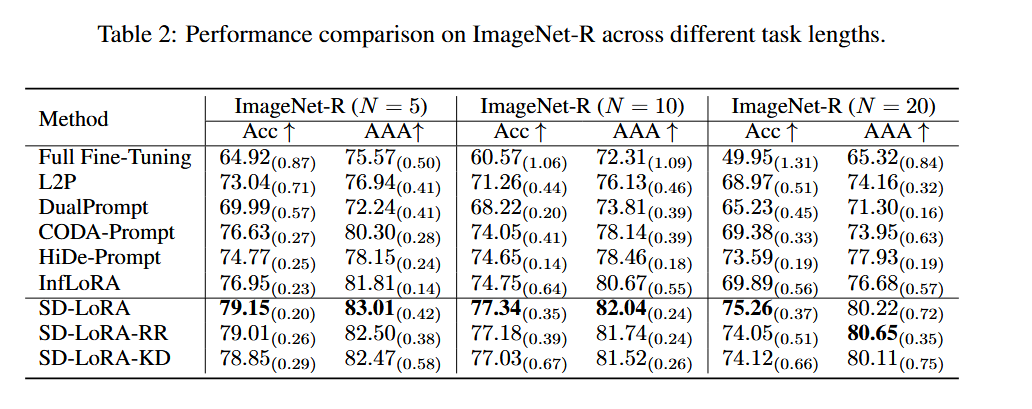
(2)任务数越多,SD-LoRA 的优势越明显
作者专门比较了 ImageNet-R 在 5、10、20 个任务 三种划分下的表现。结果表明,随着任务数增加,SD-LoRA 相对其他方法的优势还在扩大。这个结果很重要,因为它直接支撑了题目中的 Scalable:
任务越长、持续学习过程越复杂,SD-LoRA 越能体现优势。
(3)消融实验说明 SD-LoRA 的提升不是单一因素带来的
作者做了三类消融实验:
第一,只固定一个学到的 LoRA direction,但允许 magnitude 继续适应。即便这样,性能也不差,说明初始方向本身就很关键。
第二,只做 magnitude 和 direction 的解耦,但限制模型只有一个 LoRA component。这样效果明显不如完整 SD-LoRA,说明单纯解耦还不够,多个解耦组件协同学习才是关键。
第三,固定学到的 LoRA components,但不做 magnitude rescaling,性能也会下降。这说明 SD-LoRA 的优势不仅来自“保留旧方向”,还来自于通过重新加权旧方向来沿 low-loss path 前进。
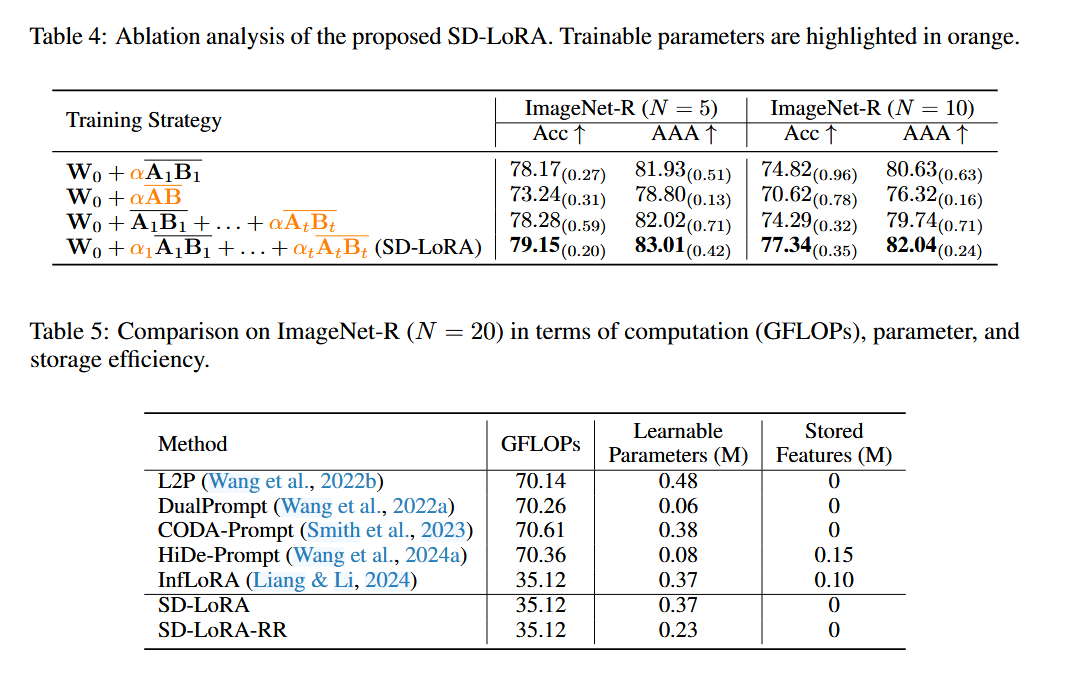
(4)效率分析说明它不仅准,而且省
作者最后从 GFLOPs、可训练参数量、特征存储需求 三个角度比较不同方法。结果显示,InfLoRA 和 SD-LoRA 都因为不需要在推理阶段做任务特定 prompt 选择,所以推理效率很高;而 SD-LoRA-RR 还能在不依赖 rehearsal 的前提下进一步减少参数量,因此特别适合资源受限场景。
3.总结
实验设置
论文在 ImageNet-R、ImageNet-A 和 DomainNet 上评测 SD-LoRA,使用 Acc 和 AAA 两个指标,对比 L2P、DualPrompt、CODA-Prompt、HiDe-Prompt、InfLoRA 等方法,并采用 ViT-B/16 与 DINO-ViT 作为 backbone。
实验结果
SD-LoRA 在多个 benchmark、不同任务长度和不同 backbone 下都优于现有方法;任务数越多,优势越明显;两个参数高效变体 RR 和 KD 仅带来很小的性能下降。
实验结论
第四节证明了 SD-LoRA 不仅性能更强,而且更适合长期、资源受限的持续学习场景。
六、结论
1. 研究结论
这篇论文提出了 SD-LoRA,它是一个面向基础模型上的类增量学习的计算方法,目标是解决随着任务数增加而出现的可扩展性问题。它的核心做法是把 LoRA 组件中的 magnitude(幅值) 和 direction(方向) 解耦学习,从而同时实现三点:
- rehearsal-free:不需要保存旧样本
- inference-efficient:推理高效
- end-to-end optimized:端到端优化
作者认为,经验分析和理论分析都表明,SD-LoRA 会沿着一条 low-loss trajectory(低损失轨迹) 前进,并最终收敛到一个对所有已学任务都有效的 overlapping low-loss region(重叠低损失区域),因此能够较好地平衡 stability(稳定性) 和 plasticity(可塑性)。此外,大量实验说明它确实能减轻 catastrophic forgetting(灾难性遗忘),同时保持对新任务的适应能力。两个变体 SD-LoRA-RR 和 SD-LoRA-KD 也进一步提升了它在资源受限场景下的实用性。
2. 未来研究方向
作者在 Discussion 部分提出了三条未来工作方向。
第一,当前实验主要基于 ViT,所以未来可以把 SD-LoRA 扩展到更多类型的 foundation models 上,看看它在不同 backbone 架构中是否同样有效。
第二,未来可以把 SD-LoRA 和其他 PEFT 技术结合起来,比如 adapters 或 prefix-tuning。作者的意思是:SD-LoRA 现在是基于 LoRA 的,但它的“解耦思想”未必只能用在 LoRA 上,也许和其他参数高效微调方法结合后,性能和扩展性还能进一步提升。
第三,作者认为目前的 rank reduction 和 knowledge distillation 设计虽然有效,但还偏经验化。未来如果能为这两部分建立更扎实的理论依据,就有可能进一步提升参数效率和整体性能。
3.致谢
略

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 12
12 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)