以AI量化为生:23.打造AI全驱动量化策略引擎
本文是《以AI量化为生》系列的第23篇,我们将从传统量化策略的局限性出发,设计并实现一个AI全驱动的策略引擎,让AI从数据理解、市场分析到交易决策实现全自动化,彻底替代人工编写固定规则的旧模式。

写在前面
上一篇讲了指标计算引擎的重构,让策略能直接复用图表指标的计算逻辑。有读者问了个很关键的问题:复用指标计算确实方便了,但策略的逻辑还是得自己写——金叉买、死叉卖,或者RSI超买做空、超跌做多。这些规则写死了,市场一变,策略就不管用了。
这个问题困扰了我很久。说实话,刚开始做量化的时候,我觉得只要找到"对的指标参数",就能稳定盈利。于是花大量时间调参,MACD的(12,26,9)换成(5,13,5),RSI的14换成7,来回折腾。结果呢?趋势市参数A好用,震荡市参数B好用,市场在这两种状态之间反复切换,你根本来不及换。
后来我意识到,问题的本质不是参数不对,而是策略逻辑本身是死的。不管你怎么调参,规则都是固定的:“满足条件A就买,满足条件B就卖”。市场是活的,规则是死的,这个矛盾没法靠调参解决。
所以我就想,能不能让AI来做决策?不是让AI帮我选参数,而是让AI理解当前市场状态,然后自己决定该做什么。这就是AI策略引擎的出发点。
AI策略引擎是什么?
简单说,AI策略引擎就是一个让AI替代固定规则做交易决策的系统。
传统策略的工作方式是:K线数据进来 → 用if-else判断条件 → 执行买卖。AI策略引擎的工作方式是:K线数据进来 → 组装成AI能理解的上下文 → AI分析并返回决策 → 验证风控 → 执行。
核心区别在于:传统策略的判断逻辑是你预先写死的,AI策略的判断逻辑是AI根据当前市场状态动态生成的。
不过话说回来,让AI做交易决策,不是说随便扔个prompt给GPT就行。期货市场有它的特殊性——杠杆、保证金、涨跌停、夜盘,这些跟股票完全不一样。如果AI不理解这些概念,给出的建议可能完全不靠谱。
所以我们需要做两件事:一是让AI理解期货市场的规则,二是让AI的分析结果能被代码执行。这两件事合在一起,就是整个AI策略引擎要解决的核心问题。
三层架构设计
在讲具体模块之前,先说说整体架构。AI策略引擎采用了三层设计:
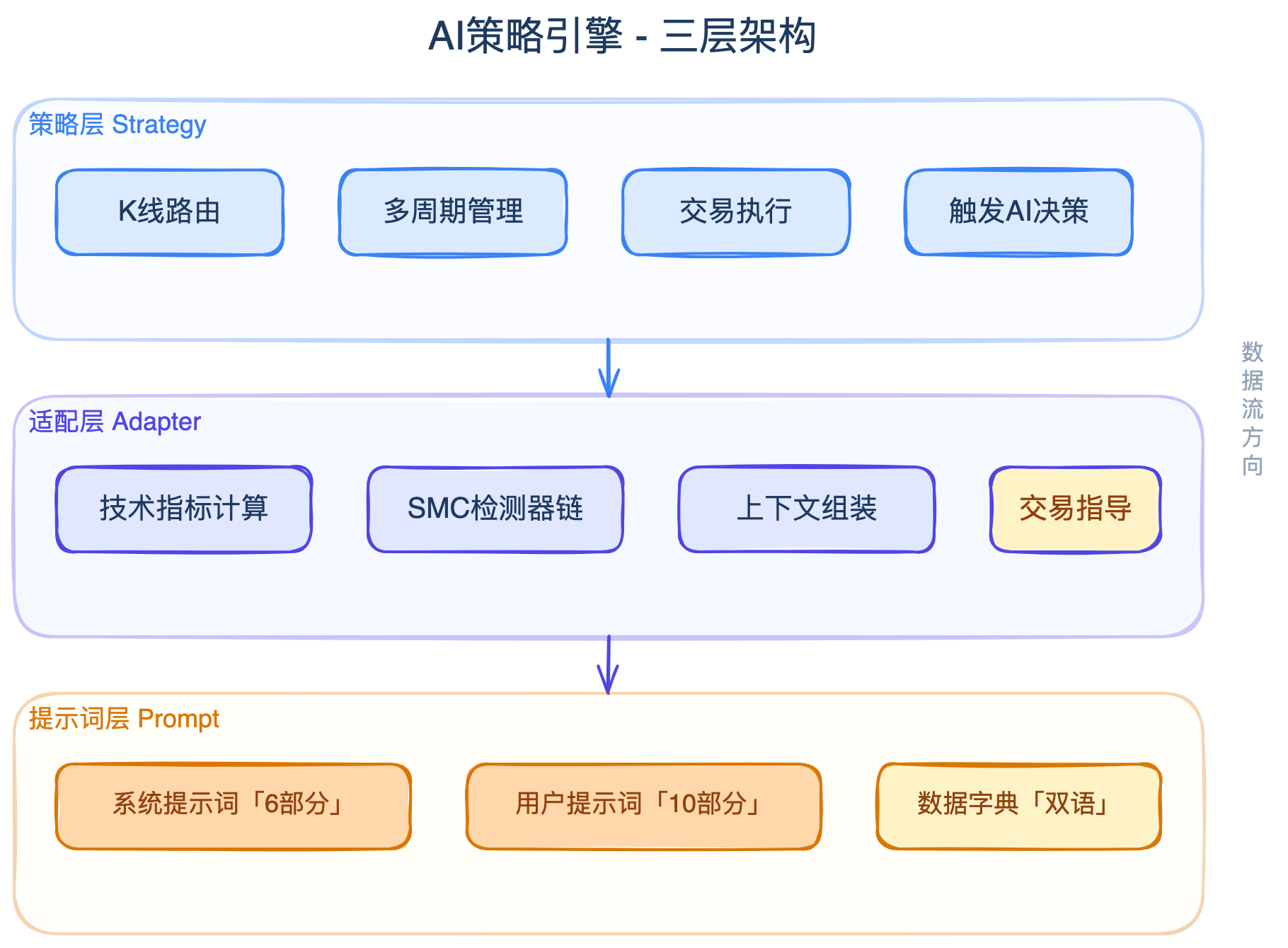
策略层:这是最外层,负责跟vnpy框架对接。它接收行情数据(tick和K线),管理多周期的BarGenerator和ArrayManager,在合适的时机触发AI决策。这一层不关心AI怎么分析,也不关心指标怎么算,只负责"什么时候该让AI想一想"。
适配层:这一层负责把原始的行情数据翻译成AI能理解的格式。包括计算技术指标(EMA、MACD、RSI等)、运行SMC检测器(订单块、FVG、支撑阻力)、生成自然语言的交易指导。简单说,就是把冷冰冰的数字变成有意义的分析结果。
提示词层:这一层负责构建发送给AI的完整提示词。包括系统提示词(角色定义、交易模式、数据字典、风险规则)和用户提示词(当前市场数据、持仓状态、技术分析、K线表格)。
数据从策略层流入,经过适配层加工,最后通过提示词层交给AI,AI返回的决策再回到策略层执行。整个流程是单向的,每层各司其职。
对了,为什么要分三层?刚开始写的时候,策略里面混着指标计算、提示词拼接、AI调用,一个文件上千行,改一个地方动全身。后来重构了好几次,才发现这个分层是最自然的——策略层管"什么时候做",适配层管"准备什么数据",提示词层管"怎么跟AI沟通"。
让AI看懂市场:数据字典与提示词工程
AI要做出好的交易决策,首先得理解我们给它看的数据。这听起来简单,实际上是最花精力的部分。
数据字典
期货交易涉及的数据种类不少:价格数据(开高低收、成交量、持仓量)、技术指标(EMA、MACD、RSI、布林带、ATR、DMI)、账户数据(余额、可用资金、保证金、浮动盈亏)、持仓数据(方向、数量、入场价、强平价)。
如果只是把这些数据扔给AI,它可能搞不清楚每个字段的含义和单位。比如"margin"是指保证金还是保证金率?"volume"是手数还是金额?
所以我们设计了一个数据字典,把每个字段都定义清楚:
# 数据字典里的每个字段都有完整描述
PRICE_FIELDS = {
"open": FieldDefinition(
name="open", name_cn="开盘价",
description="当前K线的第一笔成交价",
unit="元/吨",
),
# ... 类似的定义覆盖所有字段
}
每个字段都有中英文名称、详细描述、单位和示例值。这些定义最终会被拼接到系统提示词里,让AI在读数据之前先"学习"一遍字典。
你可能会想,中英文双语有必要吗?实际测试下来,纯英文的字典AI理解得不够准确,尤其是中文市场特有概念(比如"保证金率"、“强平价”)。加上中文注释后,AI对数据的理解明显更准。
提示词构建
提示词分为系统提示词和用户提示词两部分。
系统提示词告诉AI"你是谁、你要做什么、有哪些规则"。它由六个部分拼接而成:角色定义、交易模式指引、数据字典、SMC分析指南、风险规则、输出格式。每部分都有明确的作用,比如角色定义告诉AI"你是一个专业的期货交易决策助手",风险规则告诉AI"单品种最大仓位不超过30%"。
用户提示词是每次决策时动态生成的,包含当前市场的完整快照。十个部分:时间品种、账户状态、仓位建议、当前持仓、市场数据、技术指标、近期K线表、交易指导、SMC结构、多周期共振。
其中"交易指导"这个部分比较有意思。它不是原始数据,而是系统根据指标值自动生成的自然语言建议。比如EMA三线排列完美多头,就会生成"EMA:完美多头排列,趋势强劲,回调到均线附近可做多"。这些指导性文字能帮AI更快地理解市场状态。
说白了,提示词工程的核心就是:把AI当成一个刚入行的交易员,它需要清晰的市场数据、明确的交易规则、以及有用的参考意见。数据字典是它的教材,系统提示词是它的操作手册,用户提示词是它每天看到的行情板。
多维度市场分析:多周期与SMC
光有好的提示词还不够,数据本身的质量才是关键。如果AI看到的市场数据不够全面,再好的提示词也没用。
多周期分析
不同时间尺度看同一个市场,结论可能完全不同。15分钟K线在上涨趋势中,1小时K线可能在下跌趋势中。如果只看一个周期,很容易被短期波动误导。
AI策略引擎同时维护两个周期的数据:主周期(比如1小时)和次周期(比如15分钟)。每个周期都有独立的IndicatorManager,计算完整的技术指标套件——EMA(9/20/60)、SMA(25/60/100)、MACD(12,26,9)、RSI(14)、DMI(14,7)、布林带(20,2)。
两个周期的指标都会传给AI,同时还会做一个"多周期共振分析"——检查主周期和次周期的趋势方向是否一致。如果1小时和15分钟都看涨,信号的可信度就高很多。如果方向相反,AI就会更谨慎。
SMC聪明钱概念
除了传统技术指标,我们还集成了SMC(Smart Money Concepts)分析。SMC是一套基于机构资金行为的市场分析方法,核心工具包括:
- 订单块(Order Block):机构建仓的价格区域,往往成为未来的支撑或阻力
- 公允价值缺口(FVG):价格快速波动留下的缺口,市场有回补缺口的倾向
- 市场结构(BoS/ChoCh):趋势延续和反转的结构性信号
- 流动性区域:大量止损单聚集的价格位置
SMC检测器链是一个串联的处理流程:先跑ZigZag识别关键转折点,然后检测市场结构(高点和低点的排列),接着识别结构突破(BoS)和结构转变(ChoCh),最后提取订单块、FVG和流动性区域。
检测到的支撑阻力位会被注入到AI的上下文里。比如系统检测到3500附近有一个强需求订单块,AI在做空的时候就会更谨慎——因为它知道这个位置可能有大量买盘支撑。
说到这里,有个事值得提一下。SMC分析用的是主周期的K线历史数据,不是实时计算的。所以在回测模式下,我们通过BacktestAdapter来桥接——它从策略的htf_bar_history读取历史K线,喂给SMC检测器。实盘模式下则直接从策略的实时数据流获取。两种模式的检测逻辑完全一样,只是数据来源不同,这样保证了回测和实盘的行为一致性。
从数据到交易:决策全流程
前面讲了怎么准备数据和怎么跟AI沟通,现在讲最关键的部分:AI返回的决策怎么变成实际的交易。
一次AI决策的完整旅程
整个流程是这样的:
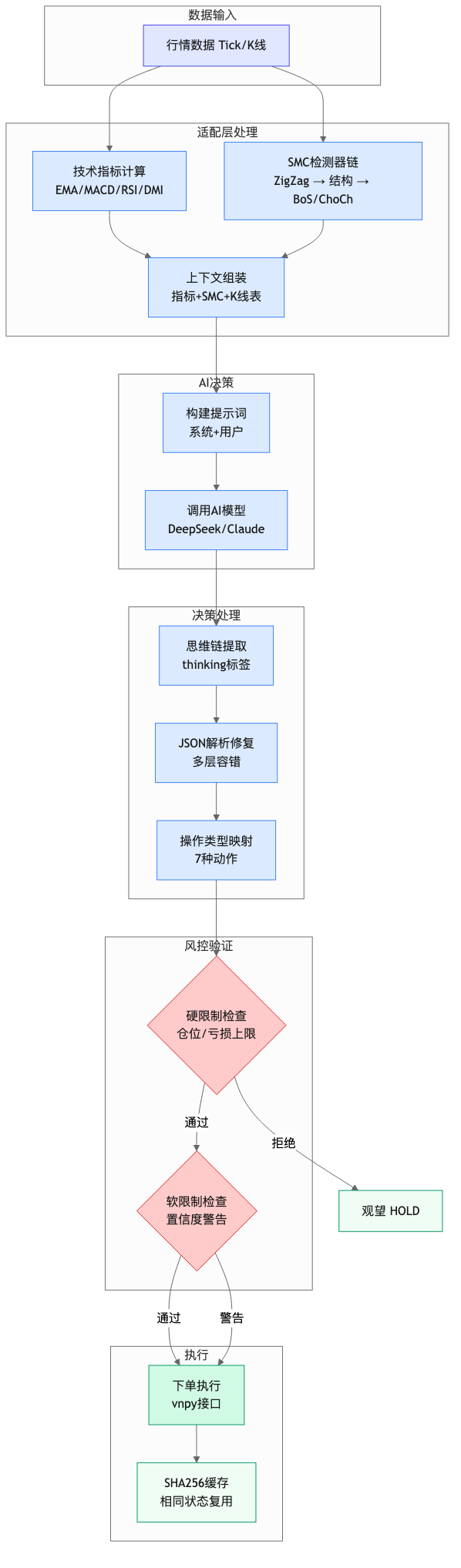
行情数据进来(tick → 1分钟K线 → 主周期K线)→ 适配层计算指标和SMC → 组装上下文 → 补充20日高低点等额外信息 → 构建系统提示词和用户提示词 → 调用AI模型 → 拿到AI的回复 → 解析决策 → 风控验证 → 执行下单。
每一步都可能出问题,所以每一步都有容错处理。
七种操作类型
AI可以返回七种操作:做多(LONG)、做空(SHORT)、平仓(CLOSE)、观望(HOLD)、加多(ADD_LONG)、加空(ADD_SHORT)、减仓(REDUCE)。
你可能会问,为什么不是简单的买和卖?因为期货交易有方向性——做多和做空是完全独立的操作。而且实战中,加仓和减仓是常见的仓位管理手段。如果只给AI"买"和"卖"两个选项,它的策略空间会受限。
思维链提取与JSON修复
这是整个引擎里最"脏"也最关键的模块。
AI的回复不是总是规规矩矩的JSON。有时候它会先思考一大段再给结论,有时候JSON格式有瑕疵,有时候干脆用中文说"我认为应该做多"。
所以解析器要做三件事:
第一,提取思维链。AI可能会用<thinking>标签包裹它的分析过程,也可能在JSON里有个reasoning字段。解析器支持各种格式,把思考过程提取出来单独保存——这对事后分析很有价值。
第二,修复JSON。这是个大坑。AI经常会写出不标准的JSON:中文引号(“”)代替英文引号、多余的前缀文字、字段名拼写错误。解析器里有个专门的JSON修复模块,处理这些常见问题。
# JSON修复的几种常见情况
def repair_json(text):
# 替换中文引号
text = text.replace('\u201c', '"').replace('\u201d', '"')
# 去掉多余的前缀
if "```json" in text:
text = text.split("```json")[1].split("```")[0]
return text.strip()
第三,兜底处理。如果JSON完全解析失败,解析器会用正则表达式从文本中提取关键信息。比如匹配"做多"、“开空”、"平仓"这些中文关键词,从中推断操作类型。如果连这个也做不到,就默认返回HOLD(观望),保证不会因为解析失败而执行错误操作。
双层风控
AI的决策不能直接执行,必须经过风控验证。我们用了双层风控设计:
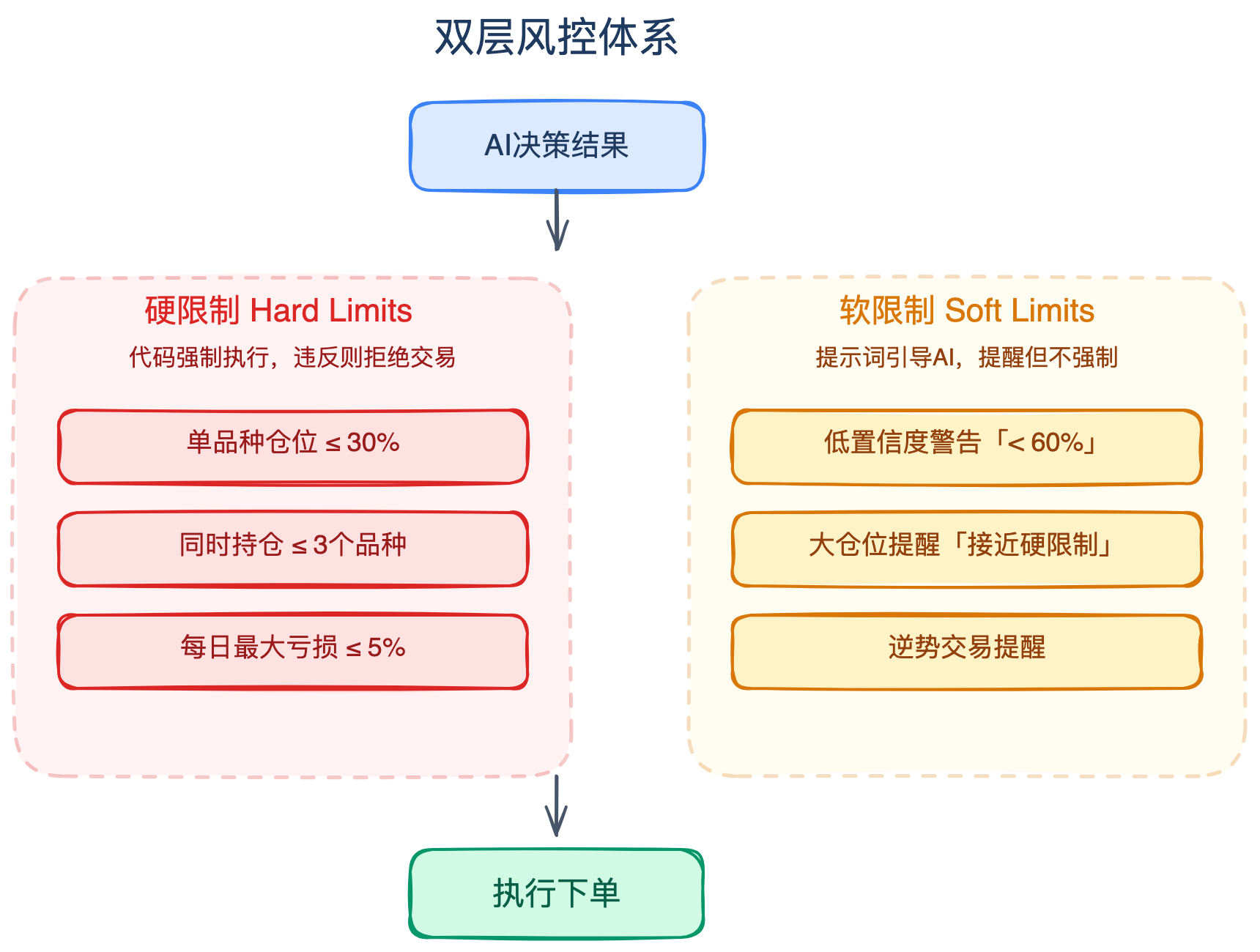
硬限制是代码强制执行的,违反就不执行。比如单品种最大仓位不超过总资金的30%、最多同时持有3个品种、每日最大亏损不超过5%。
软限制是通过提示词引导AI的,不是强制但会提醒。比如低置信度警告(AI说做多但置信度只有60%,提醒它再想想)、大仓位警告(接近硬限制边界时提示)。
为什么要分两层?因为有些规则是绝对不能违反的(比如爆仓风险),有些规则在特定情况下可以灵活处理。全硬限制太死板,全软限制又太危险。双层设计在安全和灵活之间取了个平衡。
写在最后
到这里,AI策略引擎的核心设计基本讲完了。三层架构(策略/适配/提示词)、数据字典、多周期分析、SMC集成、决策解析、双层风控,每个模块各司其职,串起来就是一条从行情到交易的完整流水线。
说到底,这个引擎的核心理念就是:让AI做AI擅长的事(理解和判断),让代码做代码擅长的事(计算和执行)。AI不需要手动计算MACD,也不需要操心K线合成,它只需要"看"已经被加工好的数据和提示词,然后做出决策。反过来,代码不需要理解市场逻辑,只需要忠实执行AI的指令并做好风控。
下一篇准备讲讲AI策略的回测和优化。说实话,AI策略回测跟传统策略回测差别挺大的——传统策略每次运行结果一样,AI策略因为有缓存才有可复现性,而且API调用费用也是个大问题。这些坑值得单独写一篇。
先写到这,有问题欢迎留言交流。
本文是《以AI量化为生》系列文章的第23篇,ATMQuant量化交易系统已开源至GitHub:https://github.com/seasonstar/atmquant
本文内容仅供学习交流,不构成任何投资建议。交易有风险,投资需谨慎。
加入「量策堂·AI算法指标策略」
想系统性掌握策略研发、指标可视化与回测优化?加入我的知识星球,获得持续、体系化的成长支持:

往期文章回顾
《以AI量化为生》系列
《量化指标解码》系列

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 7
7 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)