面试题:PEFT-LoRA 及变种详解——LoRA 原理、矩阵初始化、作用矩阵、Rank/Alpha 选择、过拟合治理、rsLoRA/AdaLoRA/DoRA/LoRA-GA/QLoRA 全解析
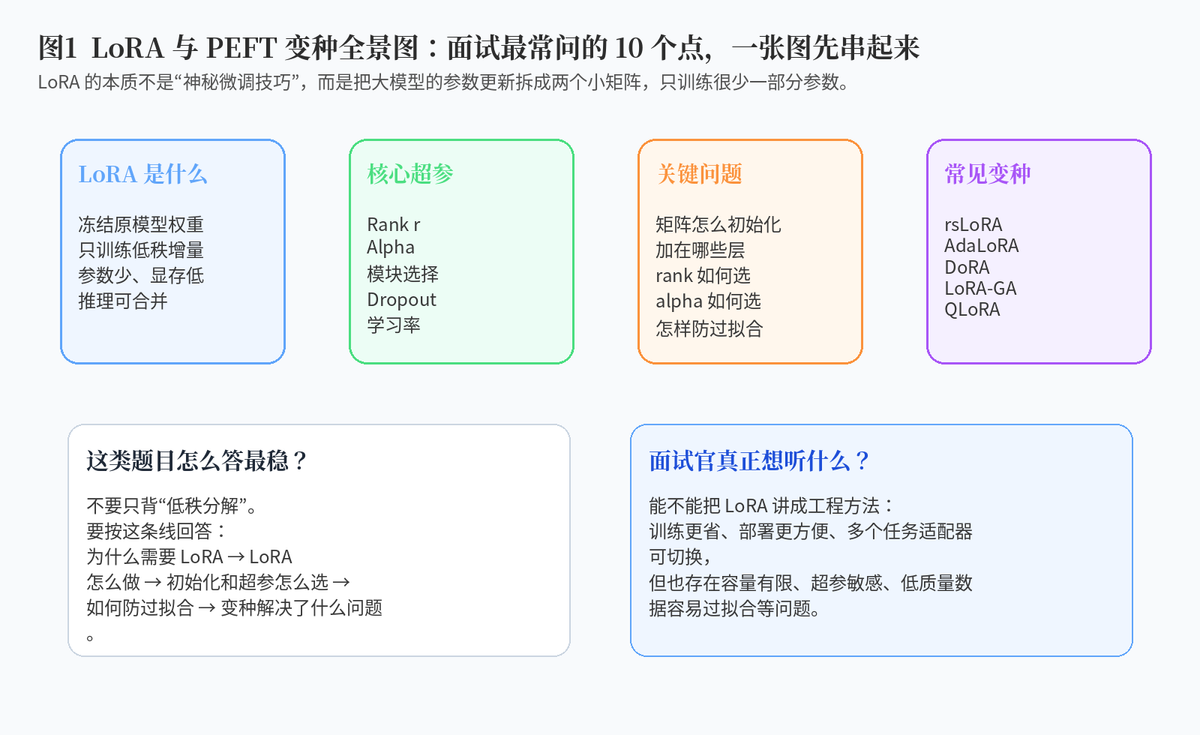
1. 先介绍一下 LoRA
1.1 LoRA 到底是什么?
LoRA,全称 Low-Rank Adaptation,可以翻译成“低秩适配”。它是一种非常经典的 PEFT 方法,也就是参数高效微调方法。它的核心思想是:不要直接更新大模型原始权重,而是在原始权重旁边加一个很小的低秩增量分支,只训练这个小分支。
用一句人话解释:大模型原来的参数太大了,全部微调成本高、显存压力大、部署不方便。LoRA 的做法是把大模型冻结住,只给它贴一个很轻的小补丁。训练时只改这个小补丁,原模型本体不动。
1.2 为什么 LoRA 能省参数?
在大模型里,很多权重矩阵都非常大。如果直接微调,就要更新完整矩阵。LoRA 认为,针对某个具体任务,模型真正需要学习的变化往往没那么复杂,可以用一个低秩更新来近似。于是,它把原本很大的更新矩阵拆成两个小矩阵。这样训练参数数量会大幅下降。
1.3 LoRA 的最大价值是什么?
第一,训练成本低;第二,显存占用小;第三,同一个基础模型可以挂多个不同 LoRA 适配器;第四,部署时可以选择动态加载,也可以把 LoRA 合并回原权重。
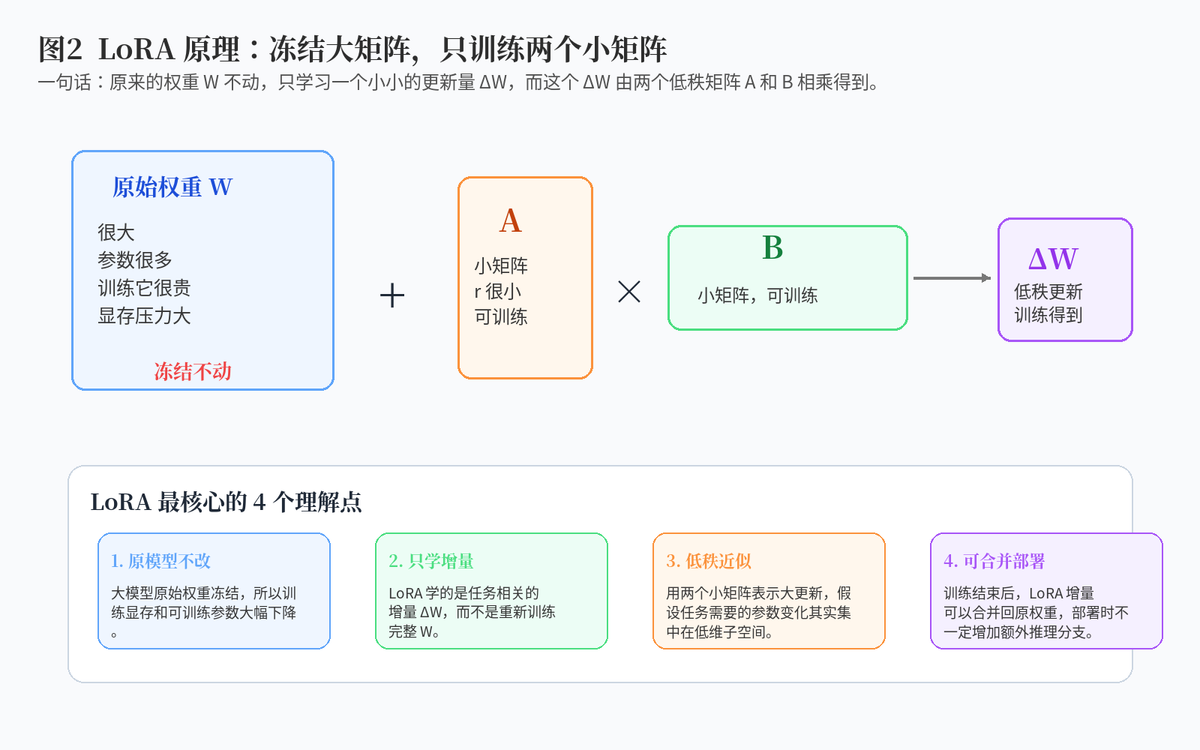
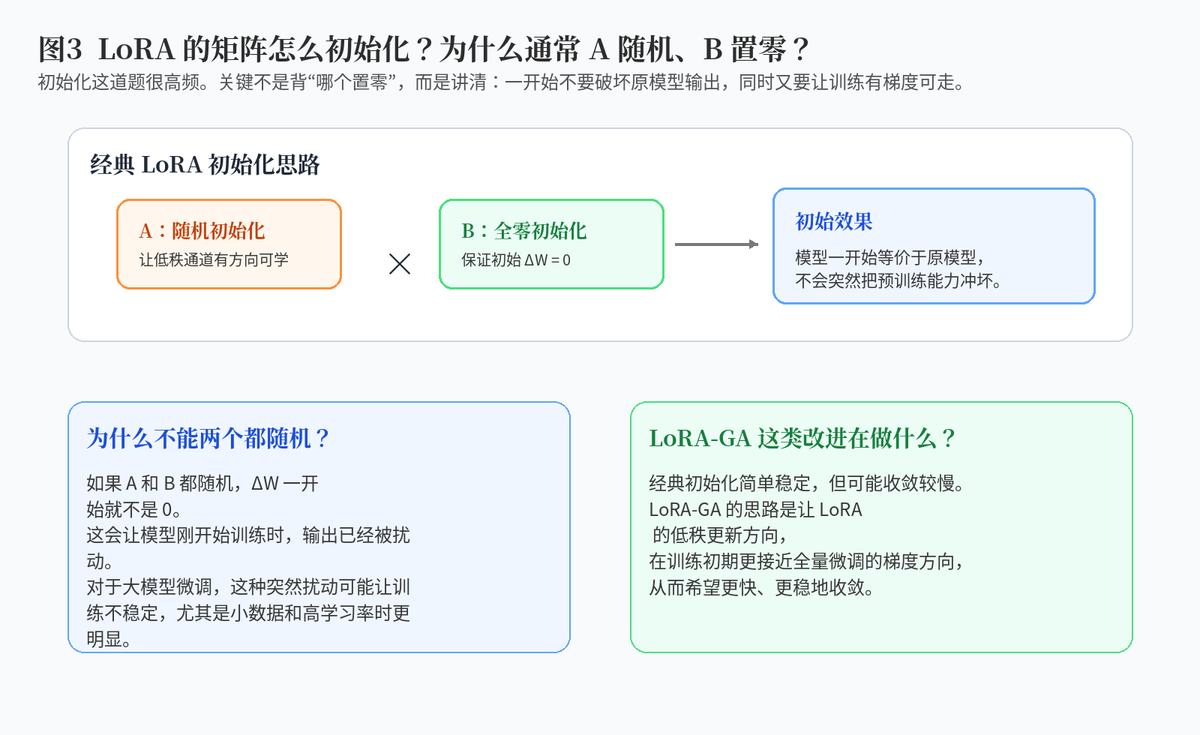
2. LoRA 的矩阵怎么初始化?为什么?
2.1 经典初始化:A 随机,B 置零
经典 LoRA 里,常见做法是让其中一个小矩阵随机初始化,另一个小矩阵初始化为 0。很多实现里会让 A 随机,B 为 0。这样两个矩阵相乘得到的 LoRA 增量一开始就是 0。
这件事非常关键:因为 LoRA 是加在原模型旁边的增量分支,如果一开始增量不是 0,就相当于刚开始训练时已经改变了原模型输出,可能破坏预训练模型已有能力。
2.2 为什么不能两个矩阵都随机?
如果两个矩阵都随机,增量更新一开始就有随机扰动。对于大模型来说,预训练权重本身已经很敏感,随机扰动可能让训练初期不稳定,尤其在数据少、学习率高、任务偏窄的场景下更明显。
2.3 为什么不能两个都置零?
如果两个都置零,虽然初始输出不会被改变,但训练信号很难有效进入两个矩阵,学习会受到影响。所以通常会让一个矩阵随机,另一个矩阵置零,在“不扰动原模型”和“可训练”之间做平衡。
2.4 LoRA-GA 这类初始化改进做了什么?
经典初始化足够简单稳定,但不一定收敛最快。LoRA-GA 这类方法尝试让 LoRA 的低秩更新在训练初期更接近全量微调的梯度方向,相当于一开始就给 LoRA 找一个更好的起跑姿势,从而提升收敛速度和稳定性。
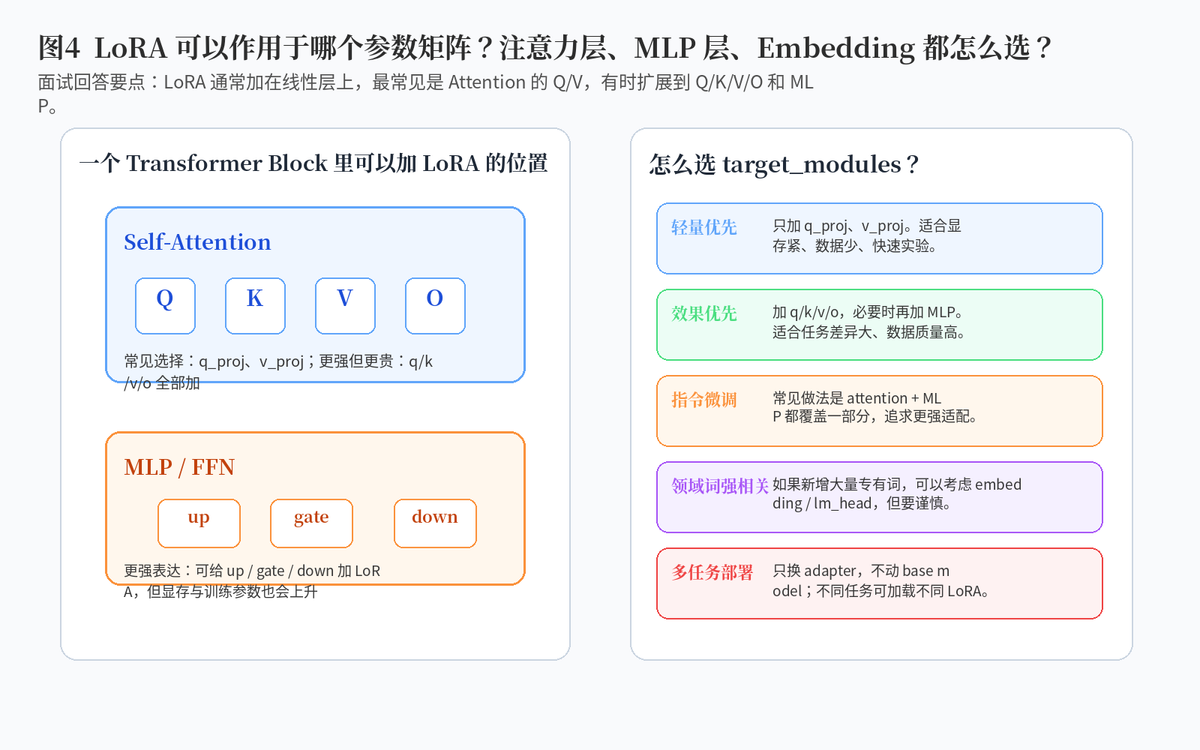
3. LoRA 可以作用于哪个参数矩阵?
3.1 最常见位置:Attention 的 Q、V 投影矩阵
LoRA 通常加在 Transformer 中的线性层上。最经典、最轻量的做法,是只加在注意力层的 query 和 value 投影矩阵上,也就是常说的 q_proj 和 v_proj。
为什么是 Q 和 V?因为 Q 影响“当前 token 想看谁”,V 影响“最终拿到什么信息”。这两个位置对任务适配非常关键,同时参数量和成本相对可控。
3.2 更强做法:Q/K/V/O 全部加
如果任务难度更高、数据量更大、显存也允许,可以把 LoRA 扩展到 Q、K、V、O 全部投影矩阵。这样模型可以在注意力计算的多个环节进行适配,表达能力更强,但训练参数和显存开销也会上升。
3.3 MLP 层也可以加 LoRA
除了注意力层,很多大模型微调也会把 LoRA 加到 MLP / FFN 的 up、gate、down 等线性层上。这样可以进一步增强任务适配能力,尤其是指令微调、复杂推理、领域迁移任务。
3.4 Embedding 和 lm_head 要不要加?
如果任务涉及大量新增专有词、特殊 token 或领域词表变化,可以考虑对 embedding 或 lm_head 做适配。但这类位置更敏感,容易影响基础语言能力,通常要谨慎评估。
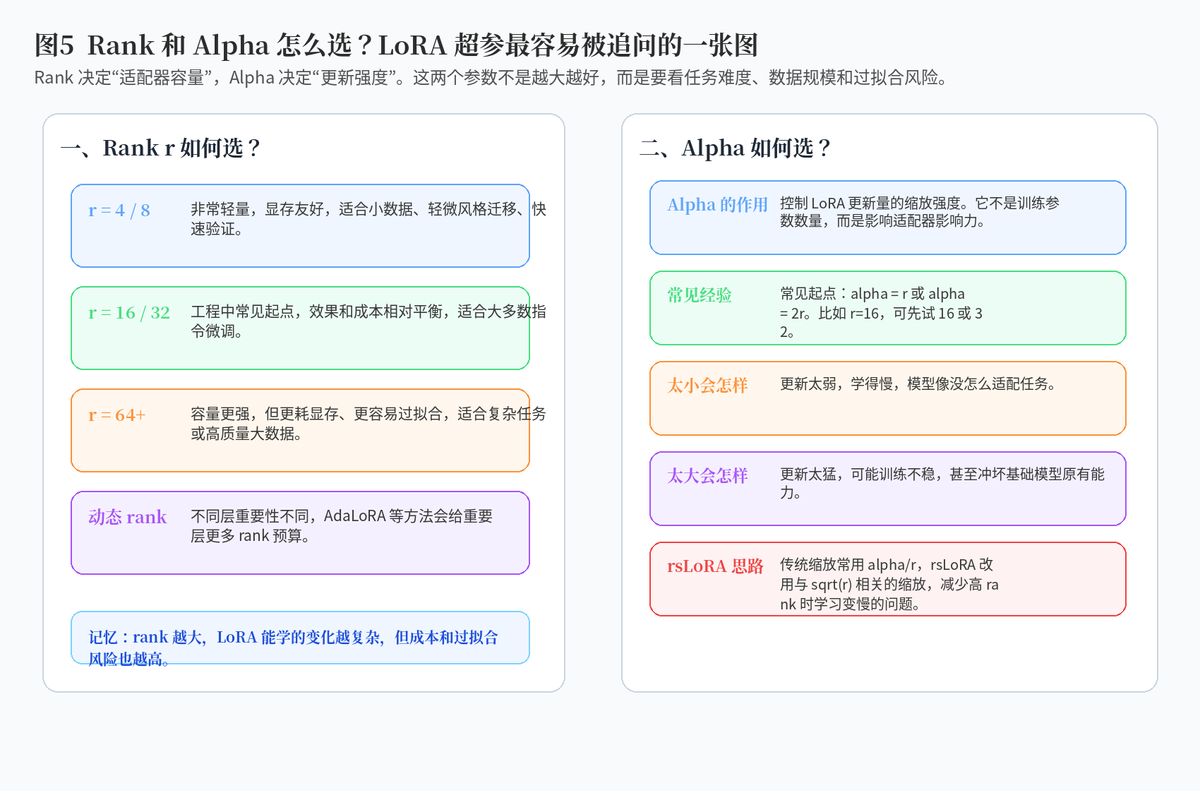
4. Rank 如何选取?
4.1 Rank 的本质:LoRA 适配器的容量
Rank 可以理解为 LoRA 这个小补丁的容量。rank 越小,参数越少,显存越省,但能表达的任务变化也有限。rank 越大,模型可学习的更新越复杂,但成本更高,也更容易过拟合。
4.2 常见经验值怎么选?
如果只是轻量任务、数据不多、想快速验证,可以从 r=4 或 r=8 开始。如果是常规指令微调,r=16 或 r=32 经常是比较均衡的起点。如果是复杂领域迁移、大数据、高质量训练,可以尝试 r=64 或更高,但要更重视验证集和过拟合风险。
4.3 Rank 越大越好吗?
不是。rank 越大,训练参数越多,也越可能记住训练集中的模板和噪声。尤其当数据质量一般或规模很小时,高 rank 反而可能让泛化变差。
5. Alpha 参数如何选取?
5.1 Alpha 的作用:控制 LoRA 更新强度
Alpha 可以理解成 LoRA 增量的放大器。rank 决定 LoRA 有多大容量,alpha 决定这个增量最终对原模型输出的影响有多强。
5.2 常见经验:alpha = r 或 2r
工程上,常见起点是 alpha 等于 rank,或者 alpha 等于 2 倍 rank。例如 r=16 时,可以先试 alpha=16 或 alpha=32。实际还要结合学习率、数据规模、任务难度一起调。
5.3 Alpha 太大或太小会怎样?
alpha 太小,LoRA 更新影响弱,模型像没学到任务;alpha 太大,LoRA 更新过猛,可能冲击基础模型能力,导致训练不稳或泛化变差。
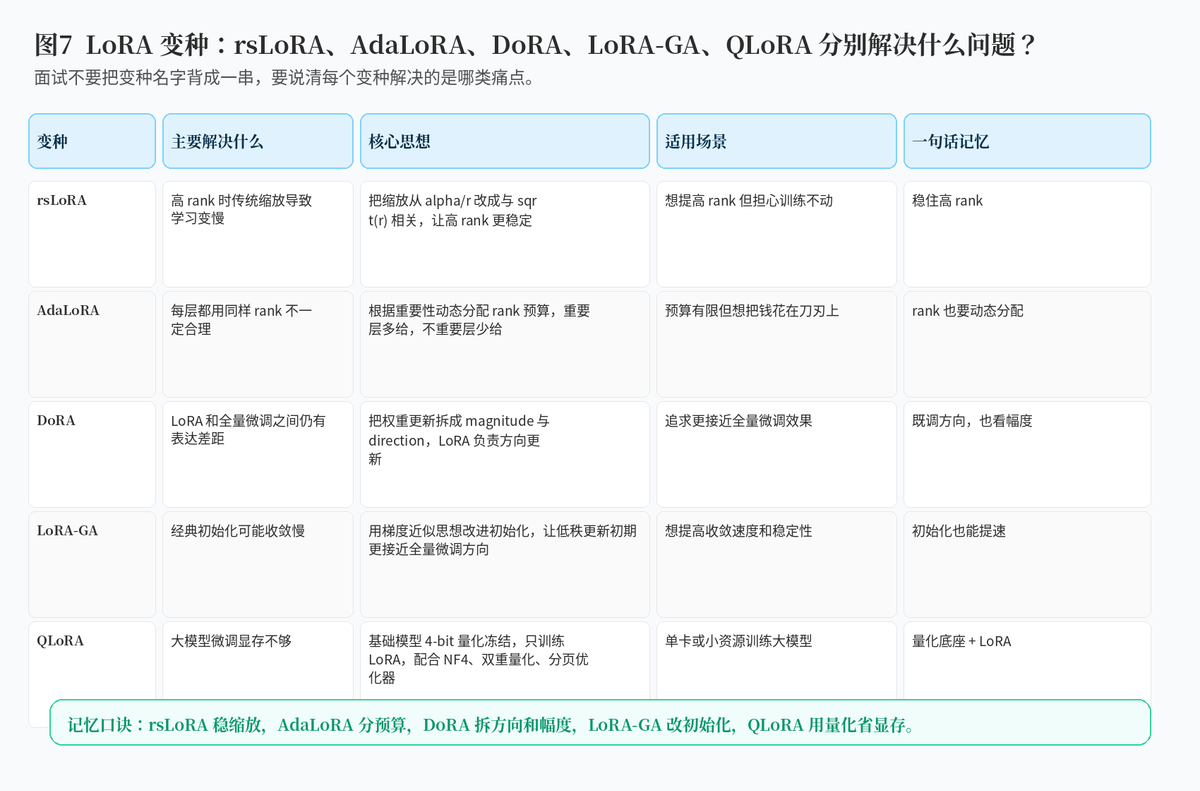
5.4 rsLoRA 为什么能改善高 rank 情况?
传统 LoRA 常用 alpha/r 这样的缩放方式。rsLoRA 的一个核心观察是,当 rank 变大时,这种缩放可能让学习变慢,因此它提出与 sqrt(r) 相关的缩放方式,让高 rank 训练更稳定。
6. LoRA 高效微调如何避免过拟合?
6.1 先认识一个误区:参数少不等于不会过拟合
LoRA 的可训练参数比全量微调少很多,但如果训练数据太少、太脏、太重复,或者 rank 和 alpha 选得太激进,仍然会过拟合。
6.2 数据层治理:质量比数量更重要
首先要去重、去噪、去低质量样本,控制模板化数据比例。其次要让样本覆盖不同问题形式、不同难度、不同边界场景。对于指令数据,还要避免所有答案长得一模一样,否则模型会学到固定话术。
6.3 超参数层治理:rank、alpha、target_modules 都要控制
如果数据不多,不建议一上来就用很大的 rank,也不建议覆盖太多 target_modules。可以先从轻量配置开始,再逐步扩大。alpha 也不宜过猛,否则适配器影响过强,容易破坏原模型泛化。
6.4 训练层治理:早停、验证集、LoRA dropout
训练过程中要用验证集监控,不要只看训练 loss。可以使用早停、保存多个 checkpoint、LoRA dropout、较小学习率等手段,避免模型过度贴合训练集。

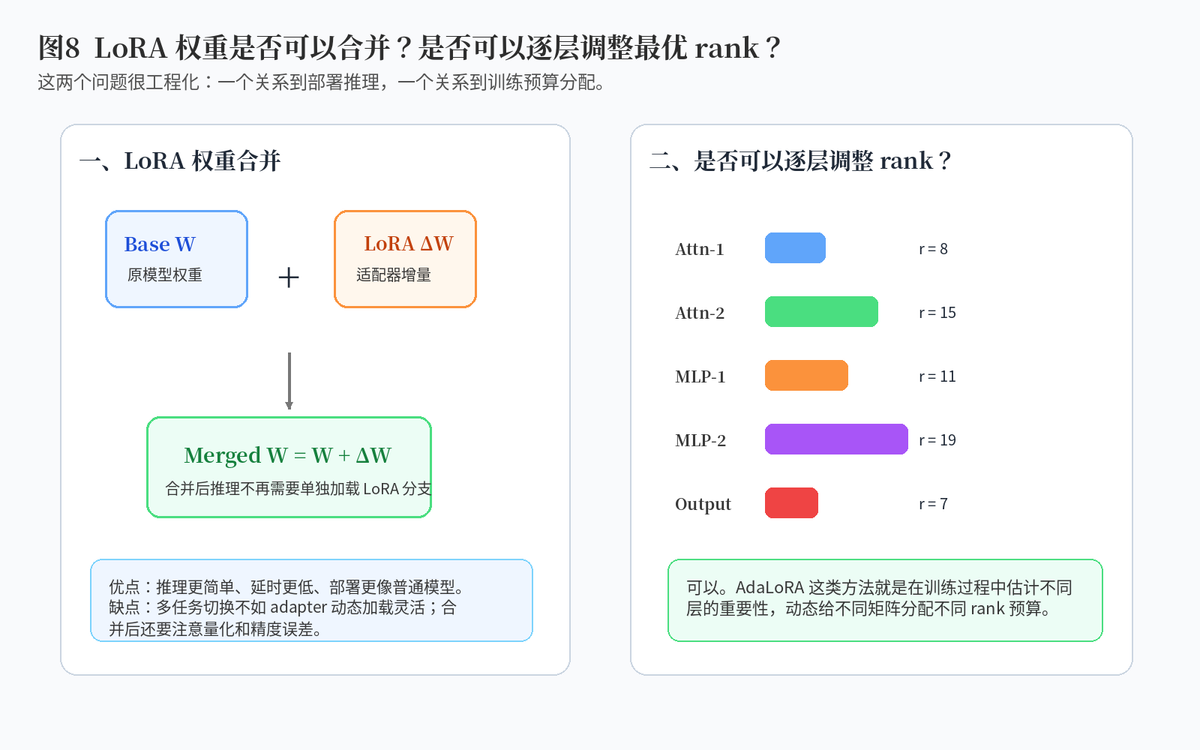
7. LoRA 权重是否可以合并?优缺点是什么?
7.1 可以合并,本质是把增量加回原权重
LoRA 训练完成后,可以把 LoRA 学到的增量更新合并回原始权重。合并后,推理时就不需要再单独走 LoRA 分支,模型看起来就像一个普通微调后的模型。
7.2 合并的优点
合并后部署更简单,推理路径更短,延时更低,也更方便导出和服务化。对于单任务固定模型,这通常很合适。
7.3 合并的缺点
如果一个基础模型要服务多个任务,不合并、动态加载 adapter 会更灵活。合并后切换任务不方便。此外,如果基座模型本身做了量化,还要注意合并与反量化、再量化过程可能带来的精度误差。
8. 是否可以逐层调整 LoRA 的最优 rank?
8.1 可以,而且很有意义
不同层、不同模块对任务适配的重要性并不一样。有些层对任务非常关键,值得给更高 rank;有些层影响较小,用低 rank 就够。
8.2 AdaLoRA 的思路
AdaLoRA 的核心思想,就是不要把 rank 预算平均分给每一层,而是根据重要性动态分配。重要层多给参数预算,不重要层少给,从而在总参数不变的情况下,提高整体效果。
8.3 工程里怎么理解?
可以把它类比成装修预算:不是每个房间都花一样的钱,而是客厅和厨房更重要,就多投一点,储物间不重要就少投一点。LoRA 的逐层 rank 调整也是这个道理。
LoRA 合并与动态 rank
LoRA 常见变种对比表
9. LoRA 微调有哪些超参数?
9.1 rank
rank 决定 LoRA 适配器容量,是最核心的参数之一。小 rank 省资源,大 rank 表达强,但也更容易过拟合。
9.2 alpha
alpha 控制 LoRA 增量的缩放强度。它和 rank 配合使用,影响模型更新力度。
9.3 target_modules
target_modules 决定 LoRA 加在哪些层,比如 q_proj、v_proj、o_proj、up_proj、gate_proj、down_proj 等。它直接影响训练参数量和适配能力。
9.4 lora_dropout
LoRA dropout 可以缓解过拟合,尤其适合数据量不大或样本重复度较高的场景。
9.5 learning rate、batch size、训练轮数
虽然 LoRA 只训练少量参数,但学习率依然很关键。学习率过大会训练不稳,过小会收敛慢。训练轮数太多也容易让模型记住训练集。
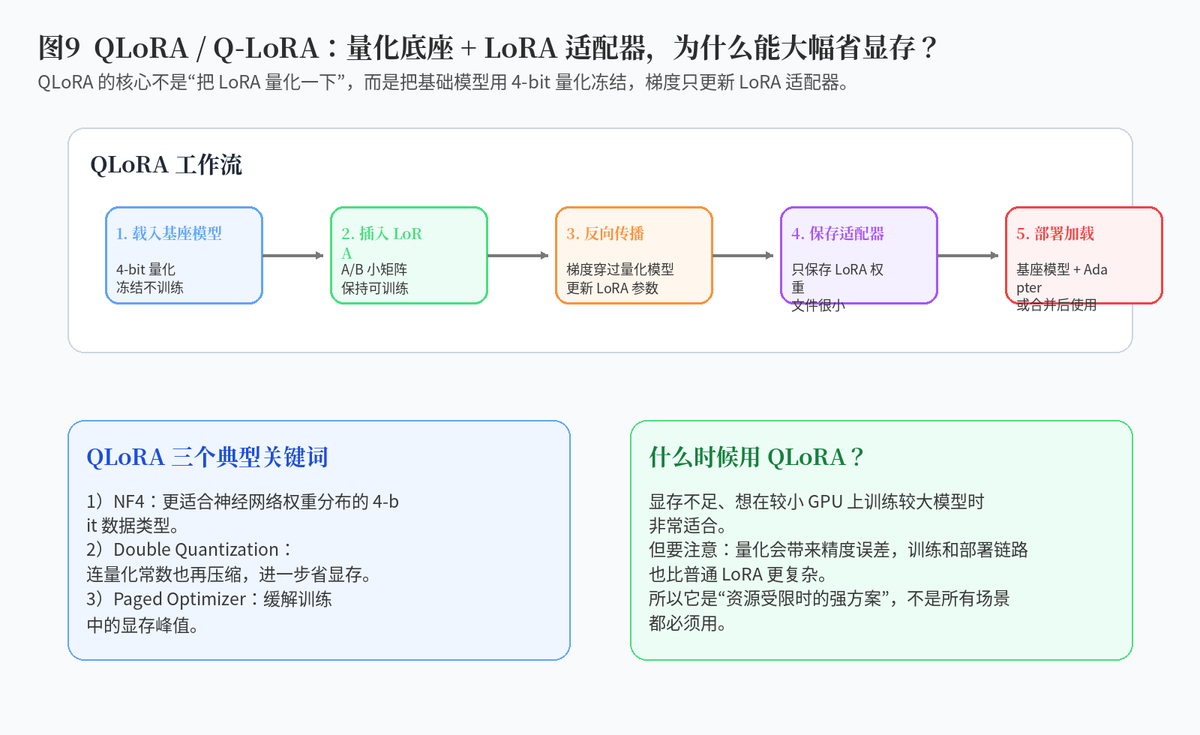
10. 简要介绍 Q-LoRA / QLoRA
10.1 QLoRA 的核心思路
QLoRA 可以理解成“量化底座 + LoRA 训练”。它把预训练大模型以 4-bit 形式加载并冻结,只训练 LoRA 适配器。这样既保留了大模型能力,又显著降低了显存需求。
10.2 QLoRA 为什么省显存?
因为基础模型权重被量化成更低比特,并且不参与训练。训练时主要更新 LoRA 小矩阵,而不是整套大模型参数。QLoRA 还引入了 NF4、双重量化、分页优化器等技术进一步降低显存压力。
10.3 QLoRA 的优缺点
优点是显存占用低,能在资源有限的设备上微调更大模型;缺点是训练链路更复杂,量化可能引入精度误差,部署时也要处理好量化和 adapter 的兼容问题。
11. 面试高频追问,建议这样回答
11.1 介绍一下 LoRA
答:LoRA 是一种参数高效微调方法。它冻结原始大模型参数,只训练两个低秩矩阵形成增量更新,从而大幅减少可训练参数和显存开销。
11.2 LoRA 的矩阵怎么初始化?为什么?
答:经典做法是一个矩阵随机初始化,另一个矩阵置零,使 LoRA 增量初始为 0。这样模型一开始等价于原始模型,不会突然破坏预训练能力,同时又能保证后续可以训练。
11.3 LoRA 可以作用于哪个参数矩阵?
答:LoRA 通常作用在线性层上,最常见是 Attention 的 q_proj 和 v_proj,也可以扩展到 q/k/v/o 以及 MLP 的 up、gate、down 等矩阵。
11.4 Rank 如何选取?
答:rank 控制 LoRA 容量。数据少、任务简单时可从 r=4/8 起步;常规指令微调可从 r=16/32 开始;复杂任务可尝试更高 rank,但要注意过拟合和显存。
11.5 Alpha 参数如何选取?
答:alpha 控制 LoRA 更新强度。常见起点是 alpha = rank 或 alpha = 2 × rank。太小学不动,太大可能训练不稳。
11.6 LoRA 高效微调如何避免过拟合?
答:要从数据、超参和训练三层治理。数据要去重去噪,rank 和 alpha 不要盲目加大,target_modules 不要覆盖过宽,并结合 dropout、验证集监控和早停。
11.7 LoRA 权重是否可以合并?优缺点是什么?
答:可以合并,合并后推理更简单、延时更低。但如果一个基础模型需要挂多个任务适配器,动态加载 LoRA 会更灵活。量化模型合并时还要注意精度误差。
11.8 是否可以逐层调整 LoRA 的最优 rank?
答:可以。不同层重要性不同,AdaLoRA 这类方法会根据重要性动态分配 rank 预算,让关键层获得更大容量。
11.9 LoRA 微调有哪些超参数?
答:主要包括 rank、alpha、target_modules、lora_dropout、learning rate、batch size、训练轮数、是否使用 rsLoRA、是否量化训练等。
11.10 简要介绍 Q-LoRA
答:QLoRA 是在量化大模型上进行 LoRA 微调的方法。它通常把基础模型以 4-bit 量化形式加载并冻结,只训练 LoRA 适配器,从而显著降低显存占用。
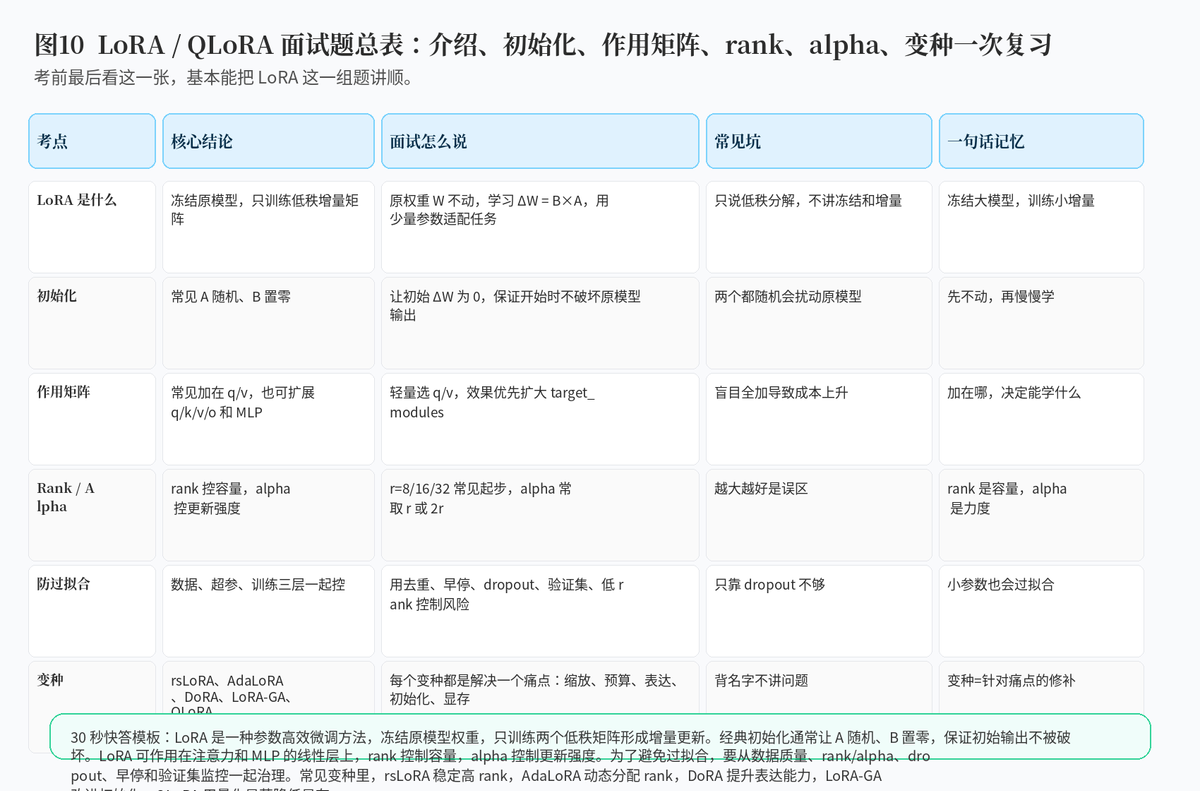
12. 总结:LoRA 的核心不是“低秩”两个字,而是低成本适配大模型的工程思想
如果把 LoRA 这组面试题浓缩成一句话,那就是:LoRA 通过冻结原始大模型、只训练低秩增量矩阵,实现了低成本、低显存、易部署的任务适配。
但真正高质量的回答,不能停留在“低秩分解”上。你还要能讲清:矩阵为什么这么初始化,LoRA 加在哪些参数矩阵上,rank 和 alpha 怎么选,如何防止过拟合,权重能不能合并,动态 rank 怎么做,QLoRA 又如何通过量化进一步降低显存。
面试里最能拉开差距的,不是背出所有变种名字,而是能把每个变种背后的问题讲清楚:rsLoRA 解决高 rank 缩放问题,AdaLoRA 解决 rank 分配问题,DoRA 解决表达能力差距问题,LoRA-GA 改进初始化和收敛,QLoRA 解决显存不足问题。这样回答,才真正像是理解了 LoRA 的工程价值。
附:30 秒面试快答模板
“LoRA 是一种参数高效微调方法,它冻结原始大模型权重,只训练两个低秩矩阵来学习增量更新。经典初始化通常让一个矩阵随机、另一个矩阵置零,使初始增量为 0,避免破坏原模型输出。LoRA 常加在 Attention 的 Q/V 投影上,也可以扩展到 Q/K/V/O 和 MLP。rank 控制容量,alpha 控制更新强度,常见起点是 r=8/16/32,alpha 取 r 或 2r。为了避免过拟合,要从数据质量、rank/alpha、target_modules、dropout、早停和验证集监控一起控制。LoRA 权重可以合并,部署更方便;AdaLoRA 可以逐层动态分配 rank;QLoRA 则通过 4-bit 量化基座模型,只训练 LoRA,进一步降低显存。”

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 2
2 0
0- 0



 已为社区贡献158条内容
已为社区贡献158条内容

所有评论(0)