智能体 Agent 完全拆解:架构、组件与实战指南
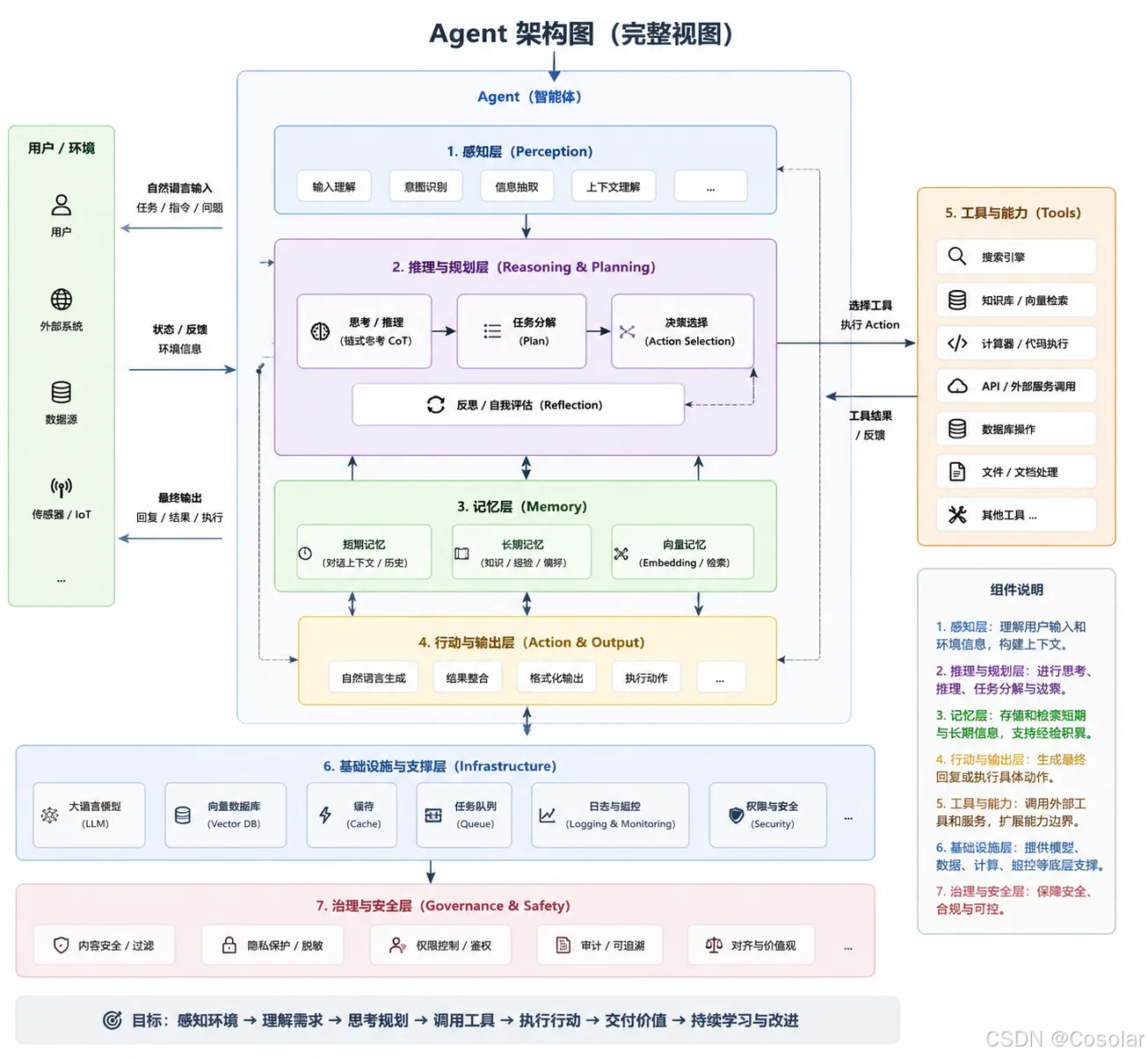
🗺️ Agent 核心架构总览
智能体(Agent)是一种能够自主感知环境、制定计划、调用工具并执行行动的 AI 系统。其核心思想源于经典的 Sense-Plan-Act 循环,但在大语言模型(LLM)的加持下,规划与推理能力得到了质的飞跃。
一个完整的 Agent 系统通常包含以下层次:
- 感知层(Perception):接收并理解用户输入,包括文本、图片、语音等多模态信息。
- 推理层(Reasoning):由 LLM 驱动,对任务进行拆解、推理与决策。
- 行动层(Action):调用外部工具(API、数据库、代码执行器等)执行具体操作。
- 记忆层(Memory):维护短期上下文与长期知识,支持多轮交互与经验积累。
技术要点:当前主流 Agent 框架(如 LangChain、AutoGPT、MetaGPT)均基于此分层设计,区别在于各层的实现粒度与编排方式。
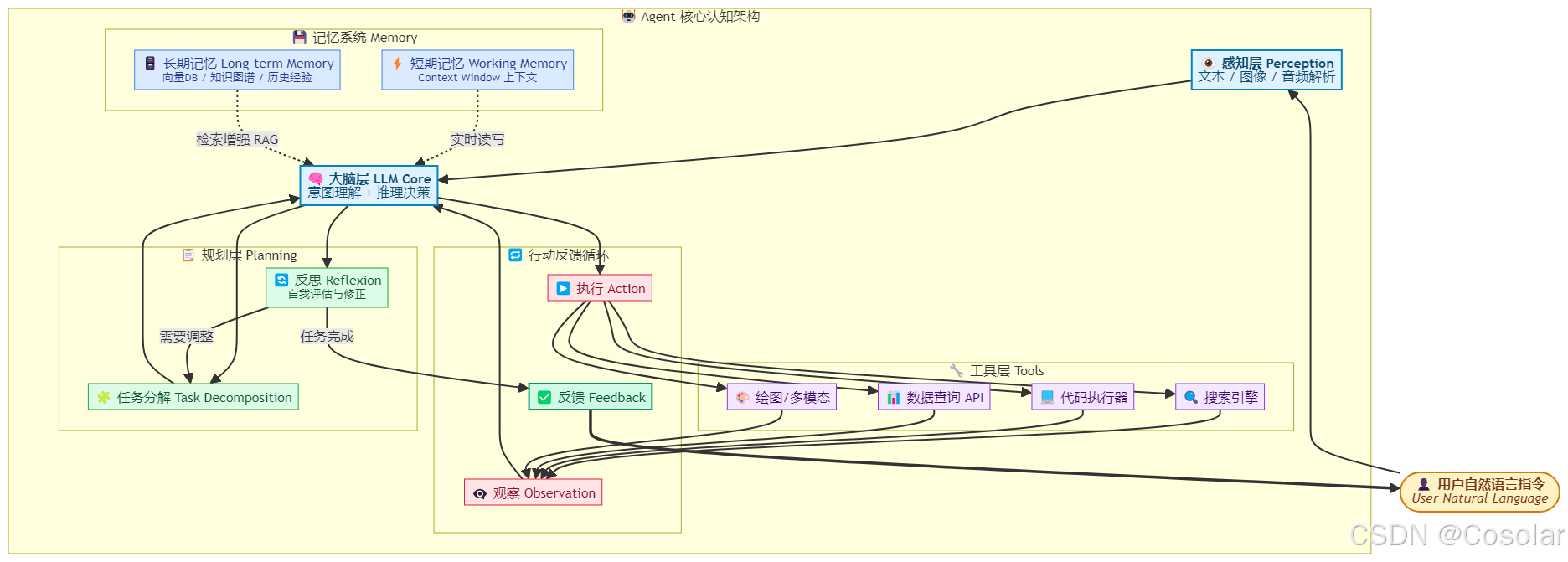
🧩 六大核心组件详解
1. 🧠 大脑 LLM — 理解与推理的核心
LLM(Large Language Model)是 Agent 的"大脑",负责自然语言理解、逻辑推理与决策生成。以 Transformer 架构为基础,通过海量文本预训练获得通用知识,再通过指令微调(Instruction Tuning)和人类反馈强化学习(RLHF)对齐人类偏好。
关键技术点:
- 上下文窗口:决定了 Agent 能"记住"多长的对话历史,当前主流模型已从 4K 扩展到 128K~1M tokens。
- 思维链(Chain-of-Thought, CoT):引导模型逐步推理,显著提升复杂任务的准确率。
- 函数调用(Function Calling):LLM 输出结构化 JSON 来触发外部工具,是 Agent 行动的关键接口。
# 示例:使用 OpenAI Function Calling 定义工具
import json
def get_weather(location: str) -> str:
return f"{location} 今日天气:晴,25°C"
tools = [
{
"type": "function",
"function": {
"name": "get_weather",
"description": "获取指定城市的天气信息",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "城市名称,如北京、上海"
}
},
"required": ["location"]
}
}
}
]
2. 📋 规划 Planning — 任务拆解的艺术
规划模块将复杂任务分解为可执行的子步骤。常见的规划策略包括:
- 任务分解(Task Decomposition):将"写一篇技术博客"拆解为"确定主题 → 收集资料 → 撰写大纲 → 逐章写作 → 校对发布"。
- 思维树(Tree-of-Thoughts, ToT):同时探索多条推理路径,通过评估选择最优分支。
- 计划-执行(Plan & Execute):先生成完整计划,再按顺序执行,适合步骤明确的场景。
from typing import List
def decompose_task(task: str) -> List[str]:
subtasks = [
"1. 分析任务需求与约束",
"2. 检索相关知识库",
"3. 制定执行计划",
"4. 逐步执行并验证结果",
"5. 汇总输出最终答案"
]
return subtasks
3. 🔧 工具 Tools — Agent 的"双手"
工具是 Agent 与外部世界交互的桥梁。常见的工具类型包括:
| 工具类型 | 示例 | 用途 |
|---|---|---|
| 搜索引擎 | Google Search API | 获取实时信息 |
| 代码执行器 | Python REPL | 运行代码并获取结果 |
| 数据库查询 | SQL Connector | 访问结构化数据 |
| 文件操作 | 读写文件 | 处理文档与数据 |
| API 调用 | RESTful API | 对接第三方服务 |
from langchain.tools import Tool
from langchain.utilities import SerpAPIWrapper
search = SerpAPIWrapper()
tools = [
Tool(
name="Search",
func=search.run,
description="搜索互联网获取最新信息,输入应为搜索关键词"
),
Tool(
name="Calculator",
func=lambda x: eval(x),
description="执行数学计算,输入应为数学表达式"
)
]
4. 🧠 记忆 Memory — 让 Agent 拥有"记忆力"
记忆系统是 Agent 实现持续交互的关键,分为两个层次:
- 短期记忆(Short-term Memory):利用 LLM 的上下文窗口,存储当前对话的完整历史。
- 长期记忆(Long-term Memory):通过向量数据库(如 Chroma、FAISS、Pinecone)存储历史知识,支持语义检索。
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Chroma
embeddings = OpenAIEmbeddings()
vectorstore = Chroma(
collection_name="agent_memory",
embedding_function=embeddings,
persist_directory="./memory_db"
)
vectorstore.add_texts([
"用户偏好:喜欢简洁的技术文章",
"上次讨论主题:Agent 架构设计"
])
results = vectorstore.similarity_search("用户偏好", k=2)
for doc in results:
print(doc.page_content)
5. 👁️ 感知 Perception — 多模态输入处理
感知模块让 Agent 能够理解多种输入形式:
- 文本感知:基础能力,解析用户指令与文档。
- 图像感知:通过多模态模型(如 GPT-4V、CLIP)理解图片内容。
- 音频感知:语音识别(ASR)与语音合成(TTS)。
- 结构化数据感知:解析 JSON、CSV、数据库表等。
6. 🔄 行动循环 Action Loop — ReAct 模式的核心
行动循环是 Agent 运行的核心机制,遵循 观察 → 思考 → 行动 → 观察 的迭代过程:
class ReActAgent:
def __init__(self, llm, tools):
self.llm = llm
self.tools = {t.name: t for t in tools}
self.history = []
def run(self, task: str, max_steps: int = 5):
thought = f"任务:{task}"
for step in range(max_steps):
action = self.llm.generate_action(thought, self.history)
if action["type"] == "finish":
return action["result"]
tool = self.tools.get(action["tool_name"])
if tool:
observation = tool.run(action["arguments"])
else:
observation = f"错误:未找到工具 {action['tool_name']}"
self.history.append((thought, action, observation))
thought = f"观察结果:{observation}"
return "达到最大步数,任务未完成"
| # | 组件 | 一句话 | 我(文心一言)的类比 |
|---|---|---|---|
| 1 | 🧠 大脑 LLM | 理解 + 推理 + 决策的核心 | 这就是 我本身 — 基于 Transformer、飞桨 PaddlePaddle 研发 |
| 2 | 📋 规划 Planning | 把大任务拆成小步骤 | 比如你让我写一篇小说,我会先列大纲再逐章写 |
| 3 | 🔧 工具 Tools | 让 Agent 能"动手"干活 | 我能调用搜索、代码执行、翻译、作画等能力 |
| 4 | 🧠 记忆 Memory | 记住上下文和过往经验 | 短期靠上下文窗口,长期靠向量数据库 |
| 5 | 👁️ 感知 Perception | 接收多模态输入 | 我能理解文本、图片,也在学习更多模态 |
| 6 | 🔄 行动循环 Action Loop | 执行 → 观察 → 调整 | 这就是 ReAct 模式 的核心 |
🧩 六大核心组件详解
| # | 组件 | 一句话 | 我(文心一言)的类比 |
|---|---|---|---|
| 1 | 🧠 大脑 LLM | 理解 + 推理 + 决策的核心 | 这就是 我本身 — 基于 Transformer、飞桨 PaddlePaddle 研发 |
| 2 | 📋 规划 Planning | 把大任务拆成小步骤 | 比如你让我写一篇小说,我会先列大纲再逐章写 |
| 3 | 🔧 工具 Tools | 让 Agent 能"动手"干活 | 我能调用搜索、代码执行、翻译、作画等能力 |
| 4 | 🧠 记忆 Memory | 记住上下文和过往经验 | 短期靠上下文窗口,长期靠向量数据库 |
| 5 | 👁️ 感知 Perception | 接收多模态输入 | 我能理解文本、图片,也在学习更多模态 |
| 6 | 🔄 行动循环 Action Loop | 执行 → 观察 → 调整 | 这就是 ReAct 模式## 🔄 ReAct 行动循环(最主流的运行方式) |
ReAct(Reasoning + Acting)是当前最主流的 Agent 运行范式,由 Shunyu Yao 等人在 2022 年提出。其核心思想是将推理轨迹(Reasoning Traces)与行动步骤(Actions)交替进行,让 Agent 在思考中行动,在行动中反思。
工作流程详解
- 输入解析:接收用户任务,提取关键信息。
- 推理思考:LLM 分析当前状态,生成下一步行动计划。
- 行动执行:调用工具或执行代码,获取外部反馈。
- 观察整合:将工具返回的结果融入上下文。
- 循环迭代:重复 2-4 步,直到任务完成或达到最大步数。
完整代码示例
from langchain.agents import create_react_agent
from langchain.agents import AgentExecutor
from langchain.tools import Tool
from langchain_openai import ChatOpenAI
from langchain.prompts import PromptTemplate
search_tool = Tool(
name="WebSearch",
func=lambda q: f"搜索 '{q}' 的结果:...",
description="搜索互联网获取实时信息"
)
calc_tool = Tool(
name="Calculator",
func=lambda expr: eval(expr),
description="执行数学计算,输入数学表达式"
)
llm = ChatOpenAI(model="gpt-4", temperature=0)
prompt = PromptTemplate.from_template(
"""你是一个智能助手,请逐步推理并行动来完成任务。
可用工具:{tools}
任务:{input}
{agent_scratchpad}"""
)
agent = create_react_agent(
llm=llm,
tools=[search_tool, calc_tool],
prompt=prompt
)
agent_executor = AgentExecutor(
agent=agent,
tools=[search_tool, calc_tool],
verbose=True,
max_iterations=5
)
result = agent_executor.invoke({
"input": "计算 2024 年全球 GDP 排名前三国家的 GDP 总和"
})
print(result["output"])
ReAct 的优势
- 可解释性强:每一步推理和行动都有记录,便于调试和审计。
- 错误恢复:当工具调用失败时,Agent 可以基于观察结果调整策略。
- 灵活性强:适用于从简单问答到复杂多步推理的各类任务。
 ## 🧠 记忆系统的两层设计
## 🧠 记忆系统的两层设计
记忆是 Agent 实现持续学习和个性化交互的关键。一个完善的记忆系统需要同时兼顾短期响应速度和长期知识积累。
短期记忆(Short-term Memory)
利用 LLM 的上下文窗口(Context Window)存储当前会话的全部信息。
实现要点:
- 使用滑动窗口策略管理 token 数量,超出限制时丢弃最早的历史。
- 对历史消息进行摘要压缩,保留关键信息。
- 支持对话历史的结构化存储(角色、时间戳、元数据)。
class ShortTermMemory:
def __init__(self, max_tokens: int = 4096):
self.messages = []
self.max_tokens = max_tokens
self.token_count = 0
def add_message(self, role: str, content: str):
msg_tokens = len(content) // 4
while self.token_count + msg_tokens > self.max_tokens:
oldest = self.messages.pop(0)
self.token_count -= len(oldest["content"]) // 4
self.messages.append({"role": role, "content": content})
self.token_count += msg_tokens
def get_context(self) -> list:
return self.messages
def summarize(self) -> str:
return f"历史对话摘要:共 {len(self.messages)} 条消息"
长期记忆(Long-term Memory)
通过向量数据库存储和检索历史知识,支持跨会话的记忆访问。
核心技术:
- 嵌入(Embedding):将文本转换为向量表示,常用模型有 text-embedding-ada-002、bge-large 等。
- 向量检索:使用余弦相似度或欧氏距离查找最相关的记忆片段。
- 记忆管理:包括记忆的写入、更新、遗忘和合并策略。
import chromadb
from chromadb.utils import embedding_functions
class LongTermMemory:
def __init__(self, collection_name: str = "agent_memory"):
self.client = chromadb.Client()
self.collection = self.client.create_collection(
name=collection_name,
embedding_function=embedding_functions.DefaultEmbeddingFunction()
)
def remember(self, key: str, content: str, metadata: dict = None):
self.collection.add(
documents=[content],
metadatas=[metadata or {}],
ids=[key]
)
def recall(self, query: str, k: int = 3) -> list:
results = self.collection.query(
query_texts=[query],
n_results=k
)
return results["documents"][0]
def forget(self, key: str):
self.collection.delete(ids=[key])
混合记忆策略
实际生产环境中,通常将短期记忆与长期记忆结合使用:
- 当前对话使用短期记忆保证响应速度。
- 每轮对话结束后,将关键信息存入长期记忆。
- 新对话开始时,从长期记忆中检索相关历史作为上下文补充。
class HybridMemory:
def __init__(self):
self.short_term = ShortTermMemory()
self.long_term = LongTermMemory()
def process_input(self, user_input: str) -> str:
# 检索长期记忆
relevant_memories = self.long_term.recall(user_input)
# 结合短期记忆处理
context = self.short_term.get_context()
# 返回增强后的上下文
return f"相关记忆:{relevant_memories}\n当前对话:{context}"

🏗️ 四种经典架构对比

| 架构 | 适合场景 | 复杂度 |
|---|---|---|
| ReAct ⭐ | 通用任务、需要多步推理 | ⭐⭐ |
| Plan & Execute | 明确的多步骤任务 | ⭐⭐ |
| Reflexion | 需要自我纠错的场景 | ⭐⭐⭐ |
| Function Calling | 工具调用明确的场景 | ⭐ |
🛠️ 我能帮你做什么?
作为 智能体,我本身就是一个 Agent 的大脑 🧠,我可以:
| 能力 | 说明 |
|---|---|
| ✅ 知识问答 | 学科知识、百科、生活常识 |
| ✅ 文本创作 | 小说、文案、诗歌、作文 |
| ✅ 知识推理 | 逻辑推理、脑筋急转弯 |
| ✅ 代码理解与编写 | Python/JS/C++ 等 |
| ✅ 数学计算 | 算术、代数、统计 |
| ✅ 翻译 | 中英互译为主,多语言学习中 |
| ✅ 作画 | 文生图能力 |
| ✅ 陪伴聊天 | 讲故事、分享笑话 😄 |

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 8
8 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)