概念:模型训练,加载与运行
模型概述:
模型由深度学习框架通过训练过程生成,其实际价值与功能则在部署阶段体现。因此,模型生命周期核心分为两大阶段:训练阶段与部署阶段。
什么是模型:
模型是经过数据学习后得到的数学结构与参数集合,本质是一套可复用的计算规则。它能够对输入数据(如图像、文本、传感器信号)进行特征提取、推理判断,最终输出预测结果(如检测框、分类标签、控制指令等)。
模型的运行流程:
输入预处理:对图像、信号等原始数据进行归一化、缩放、格式转换等操作。
前向推理:将预处理后的数据送入模型,通过网络层逐层计算。
后处理:对模型输出结果进行解析,如过滤低置信度目标、NMS 去重、坐标还原等。
结果输出:输出最终可用的识别、检测或决策信息,供业务系统使用。
模型的三个部分:
1. 网络结构
模型的骨架,由卷积、全连接、注意力等计算层按特定逻辑组成,决定模型的能力与性能。
2. 权重参数
训练过程中学习到的关键数值,是模型 “经验” 的载体,直接决定推理精度。
3. 推理逻辑
包含前处理、后处理、解码规则等配套逻辑,是让模型输出能被实际使用的必要部分。
大白话描述:
模型分为两个部分,训练和部署:
训练:
现在的训练底座都是PyTorch,yolo啥的都是基于PyTorch上层封装的工具,这也说明了为啥yolo训练的生成物时best.pt,因为这个pt就是PyTorch的训练生成物。
训练是训练啥了呢?其实就是神经网络,当前最主流/最先进的架构之一是 Transformer 。
神经网络(BP 神经网络、CNN 卷积神经网络、RNN、LSTM等)
整理的资料:PyTorch 神经网络
PyTorch是干啥的呢?就相当于一个算法库的SDK,PyTorch 不直接‘内置’具体算法(如 YOLO、ResNet),而是提供构建块(building blocks),让用户自己搭建任意网络。你用PyTorch就不用自己写算法了,他的就就是好用的,稳定的。
使用PyTorch训练好的模型后缀就叫.pt,我们后续就需要拿这个.pt干活了。
部署:
我们使用yolo的时候,运行指令是这样的:
python detect.py --weights yolov5l.pt --source data/images/zidane.jpg
这个就是PyTorch的模型,yolo直接运行了PyTorch的模型?是不是觉得很奇怪?这也就反向说yolo基于PyTorch。
但是我不能什么地方都安装一个PyTorch啊?比如嵌入式开发板,没有gpu的电脑,没有网络的电脑,资源紧张的设备。我就需要安装其他的模型解释器,也就是部署环境。
opencv:
opencv4.8版本以上的就有这个部署环境:opencv DNN。
OpenCV DNN 模块:OpenCV 内置的轻量级推理引擎(只做前向、不训练),C++ 实现、跨平台、适合边缘 / 嵌入式。
opencv这个环境兼容性比较好,但是把在嵌入式环境中会非常慢,
而且默认opencv这个跑的是cpu,这就是说在x86平台也快不到那里去。
gpu cuda加速:
// 加载 ONNX 模型
cv::dnn::Net net = cv::dnn::readNet("your_model.onnx");
// ========== 开启 CUDA 加速(C++ 必须写)==========
net.setPreferableBackend(cv::dnn::DNN_BACKEND_CUDA);
net.setPreferableTarget(cv::dnn::DNN_TARGET_CUDA);TensonRT:
英伟达GPU加速,Orin加速,速度比opencv快很多。
ONNX Runtime:
兼容性强:速度比opencv快很多。
嵌入式环境加速:
之前几个环境不是cpu,就是英伟达GPU加速,但是嵌入式环境里不能给你塞进去一块英伟达GPU啊,大家还想再几十块的芯片上运行AI加速,这个咋搞呢?每家芯片公司就开发了自己专有的NPU加速器,瑞芯微的RKNN,算能的TPU,地平线的BPU,等等。每家的加速器和英伟达都不兼容,每家也不兼容,这个咋搞呢?
每家芯片公司就对自己的AI加速器API接口进行一个封装,分装成一个模型解释器,模型部署环境。
因为解释器变了,所以他指定不识别PyTorch的pt文件,也不识别onnx文件!它只能识别适配它自己加速的的,模型部署环境的格式。
onnx是通用的格式,所以格式的转化一般就是这样的。
pt文件转化为onnx,onnx转化为芯片公司的私有格式。
这里其实还有一个隐藏的层,就是模型量化。
PyTorch训练好的(FP32/FP16)
训练好的模型(PyTorch 导出 ONNX)默认是:
FP32:单精度浮点数,每个数 32bit
数值范围:很小的小数~很大的小数
优点:准
缺点:大、慢、占显存、嵌入式 NPU 基本跑不动
量化干了啥?(INT8 最常见)
把所有权重、特征值,从 32 位小数 → 压缩成 8 位整数
做两件事:
缩放(scale):把小数范围映射到 [-128, 127]
取整(round):变成整数
结果:
体积 ↓ 4 倍
显存占用 ↓ 4 倍
速度 ↑ 2~4 倍
精度几乎没掉(1% 以内)
这就叫 INT8 量化。
所以它的流程是这样的:
.pt --> .onnx --> 量化 --> 私有模型
训练与部署图
*ONNX是全行业支持的格式。
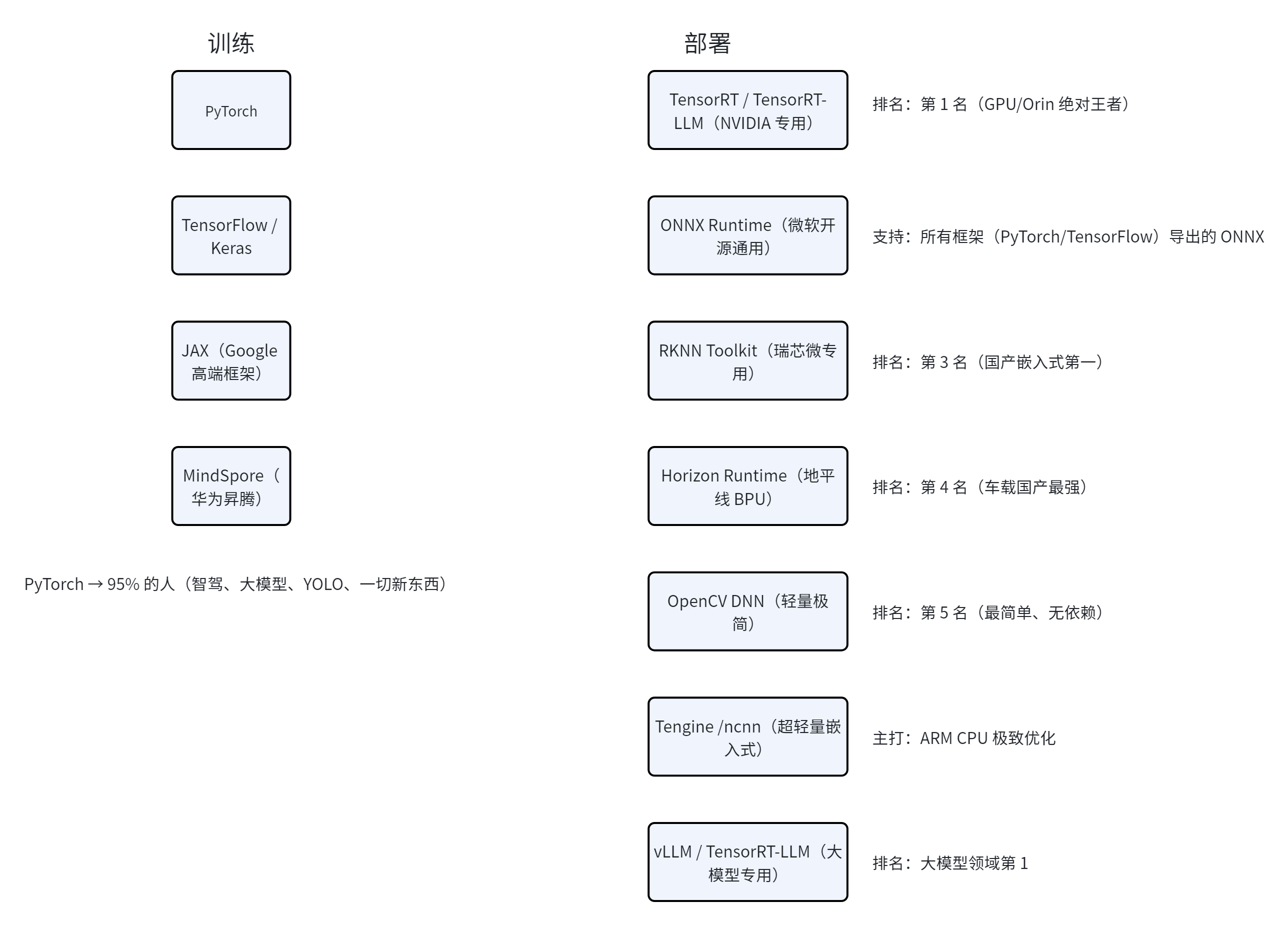
训练:PyTorch > JAX > DeepSpeed >>> 其他全部靠边站
软件推理排名:TensorRT > ONNX Runtime > RKNN > Horizon > OpenCV DNN
硬件部署排名(车载 / 嵌入式):NVIDIA Orin > 地平线 > 瑞芯微 > 高通 > 华为
瑞芯微: .pt → ONNX → RKNN Toolkit 转 .rknn
地平线: .pt → ONNX → Horizon 工具链 转 .bin
高通: .pt → ONNX → SNPE 转 DLC
华为昇腾 CANN
.pt → ONNX → 昇腾工具 转 .om
嵌入式cpu也可以跑 onnx 只不过效率很低
部署器排名:
-
工业视觉 / 服务器端(Linux 服务器、X86)
绝对主流:TensorRT(NVIDIA 显卡)
大厂标配:海康、大华、商汤、旷视、云从、华为云、百度智能云
速度最快:比 OpenCV DNN 快 5~15 倍
必须有 NVIDIA GPU
岗位:算法部署工程师、C++ 算法工程师
格式:ONNX → TensorRT engine
第二名:ONNXRuntime(ORT)
CPU/GPU 通用
微软维护,生态极强
C++/Python 都好用
很多公司内部平台用它
速度中等偏上,兼容性无敌
第三名:OpenVINO
Intel CPU/NPU 专用
工控机、无 GPU 场景主流
你这种纯 CPU 机器,用 OpenVINO 会比 OpenCV 快 2~4 倍
-
嵌入式 / 端侧(Android / 瑞芯微 / 地平线 / 寒武纪 / 大疆)
主流:
NCNN / MNN(手机、Android)
RKNN(瑞芯微 RV1106 / RK3568 / RK3588)
SNPE(高通)
BPU SDK(地平线 X3/X5)
TPU SDK(寒武纪、算能)
全部都是:PyTorch → ONNX → 各家工具链转换 → 板端推理
-
车载行业(自动驾驶、辅助驾驶、行车记录仪)
TensorRT
TensorRT-LLM
OpenPilot 生态(YOLO + 跟踪)
自定义 BSP + NPU 驱动

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)