CVPR 2026 | 哈工大(深圳)&清华等提出 DreamPRVR:引入扩散模型“先想https://mmbiz.qpic.cn/sz_mmbiz_png/P9M象后检索”,刷新长视频检索三项榜单

-
论文地址: https://arxiv.org/abs/2604.03653
-
代码仓库: https://github.com/lijun2005/CVPR26-DreamPRVR (已开源)
在海量的未剪辑长视频中,通过一句话精准找到那个“高光时刻”,是视频检索领域的一大难点。不同于短视频检索,长视频中往往充满了大量无关的背景信息,类似的检索常常被称为“大海捞针”。最近,来自哈尔滨工业大学(深圳)、清华大学深圳国际研究生院以及深圳鹏城实验室的研究团队提出了一种极具灵感的新方案。
该模型被命名为 DreamPRVR,其中“Dream”代表了模型在正式进行细粒度匹配之前,会先通过扩散模型“想象”出视频的全局背景特征;而“PRVR”则代表了它所针对的核心任务——部分相关视频检索(Partially Relevant Video Retrieval, PRVR)。这种“先想象全局,再聚焦局部”的思路,为解决长视频检索中的歧义问题提供了全新的视角。
局部噪声:长视频检索的“隐形杀手”
在部分相关视频检索(PRVR)任务中,用户给出的查询语句通常只对应长视频中的一小段。这就带来了一个棘手的问题:查询歧义(Query Ambiguity)。
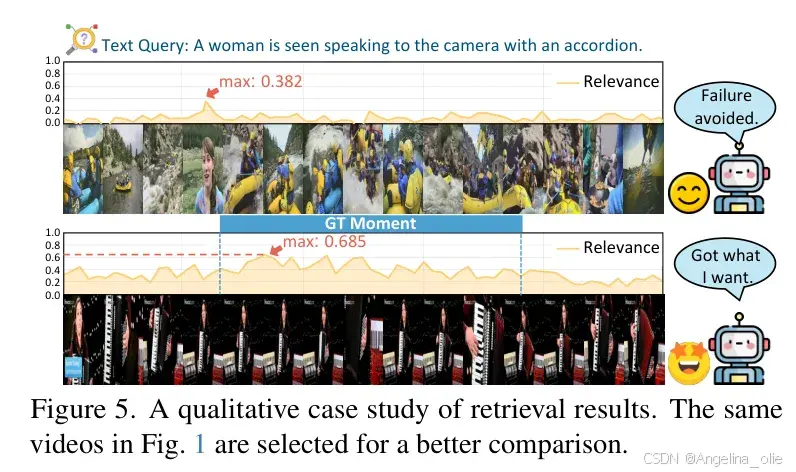
想象一下,搜索“一个女人拿着手风琴对着镜头说话”时,如果模型只关注局部相似度,它可能会被另一个视频中“人们在河上划船”的某个瞬间误导,仅仅因为那个瞬间的光影或动作在特征空间上产生了伪响应。这种现象在论文中被生动地称为“局部尖峰(Local Spikes)”。
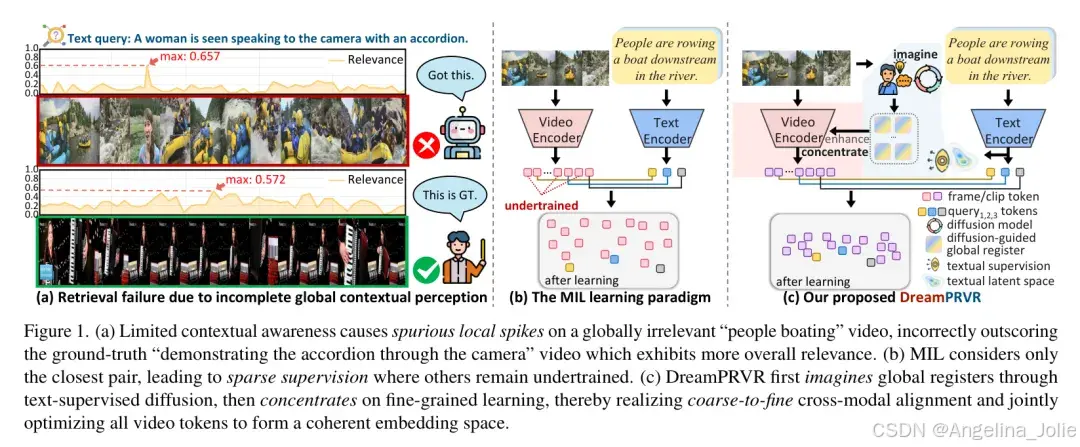
图1展示了PRVR任务中的挑战以及DreamPRVR的解决思路
如上图所示,传统的检索范式(如 MIL 多示例学习)往往只奖励匹配度最高的那一对,导致其他片段训练不足,缺乏全局观。而 DreamPRVR 的核心逻辑是:在匹配之前,先让模型对视频的整体语义有一个“宏观把握”,通过全局背景来过滤掉那些具有迷惑性的局部噪声。
方法详解:从“想象”到“聚焦”的协同进化
DreamPRVR 采用了一种从粗到细的学习范式。为了让读者更清晰地理解其运作方式,我们首先梳理其整体流程:
-
Input(输入):一段未剪辑的长视频 V提取为帧级或片段级特征)和一个文本查询语句 。
-
Output(输出):该文本与视频的跨模态相似度得分S(Q,V) ,用于最终的检索排序。
1. 文本引导的“语义想象”
为了让模型拥有全局观,作者引入了全局寄存器(Global Registers)的概念。这些寄存器就像是视频的“语义摘要本”,专门用来存储整段视频的宏观信息。
但如何生成可靠的寄存器呢?作者借用了扩散模型(Diffusion Model)的力量。
-
文本语义结构学习(Textual Semantic Structure Learning, TSSL):为了给寄存器生成提供高质量的导航,模型首先学习一个结构化的文本空间。作者提出了查询相似度保持损失(Query Similarity Preservation Loss, QSP)。不同于以往盲目拉开所有查询距离的做法,QSP 会让来自同一个视频的多个描述(查询)在空间上相互靠近,而让不同视频的查询相互远离。
-
文本扰动采样器(Textual Perturbation Sampler, TPS):考虑到文本描述本身存在不确定性,TPS 通过在文本特征中加入可控扰动,模拟出一个连续的语义空间,为后续的扩散过程提供更稳健的监督信号。
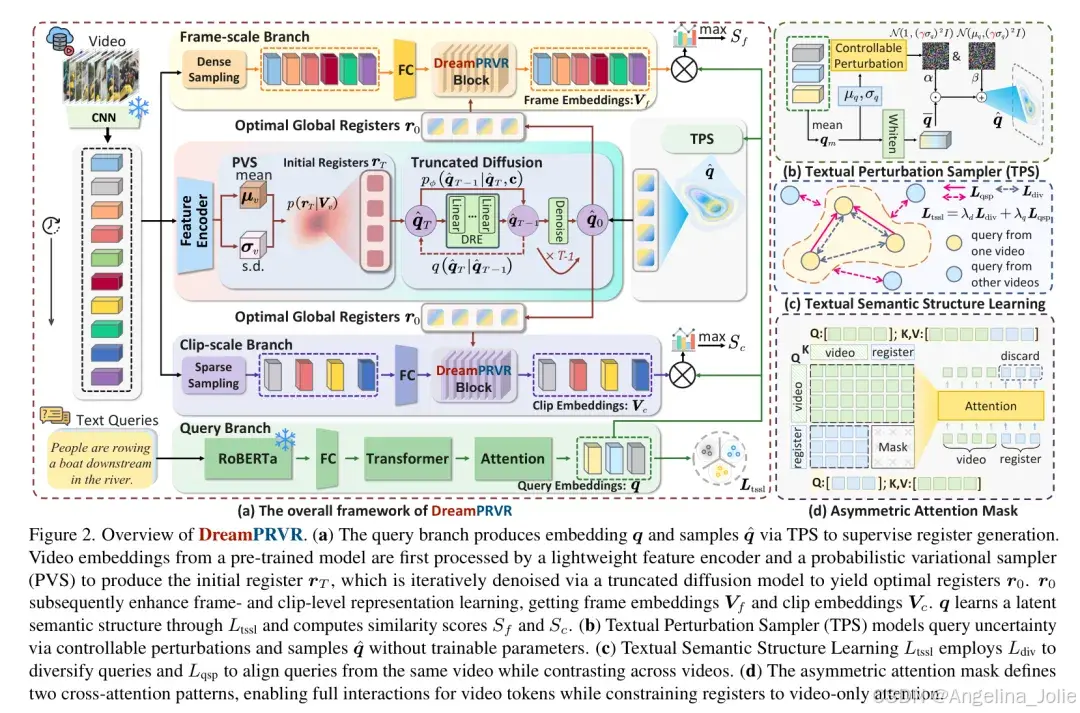
图2展示了DreamPRVR的整体架构,包括扩散引导的寄存器生成流程
2. 截断扩散模型生成寄存器

3. 寄存器增强的特征融合
有了这些“想象”出来的全局寄存器 ,下一步就是将它们注入到视频的局部特征中。作者设计了寄存器增强注意力块(Register-augmented Attention Block, RAB)。这里使用了一种异步注意力掩码(Asymmetric Attention Mask):视频 Token 可以同时看到其他视频 Token 和全局寄存器,从而获得全局上下文;而寄存器则只关注视频 Token,避免了寄存器之间的冗余交互。
这种设计确保了模型在计算相似度时,每一个局部片段都带上了“全局背景”的滤镜,从而有效抑制了那些局部相似但全局不相关的伪响应。
作者对这一过程进行了严谨的理论定义和推导,可参见论文原文3.1节。
实验结果:全面霸榜与高效推理
研究团队在 ActivityNet Captions、Charades-STA 和 TVR 三大主流数据集上进行了严苛的测试。
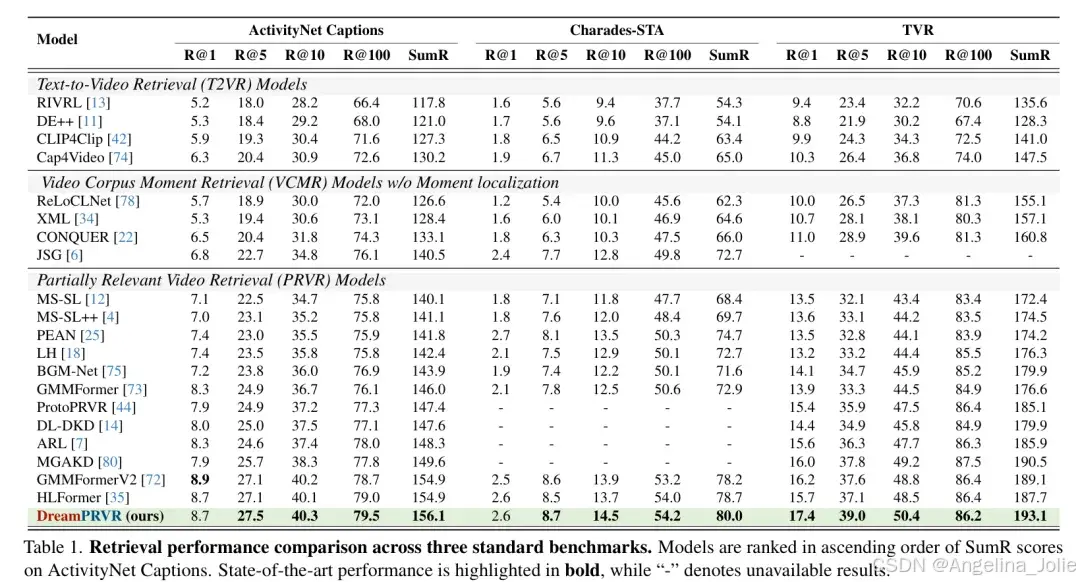
表1展示了DreamPRVR在三大数据集上的性能对比,全面超越了现有SOTA
结果显示,DreamPRVR 在各项指标上均刷新了纪录。例如在 ActivityNet Captions 上,其综合得分 SumR 达到了 156.1,显著优于之前的强力竞争对手 HLFormer 和 GMMFormerV2。
性能提升但效率并未牺牲。虽然引入了扩散模型,但由于采用了“截断”策略(仅 10 个步长)和极少量的寄存器(4-8个),其推理延迟非常低。
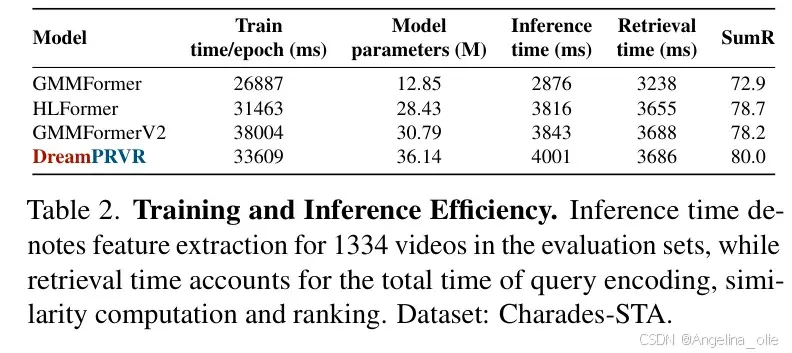
表2展示了模型的训练与推理效率,可以看到DreamPRVR在保持高性能的同时,计算开销非常克制
在 Charades-STA 数据集上,DreamPRVR 的推理时间约为 4001ms(针对 1334 个视频),与主流模型处于同一量级,能够满足实际应用的需求。
深度分析:寄存器到底学到了什么?
为了直观展示扩散过程的作用,作者利用 t-SNE 对寄存器的生成过程进行了可视化:
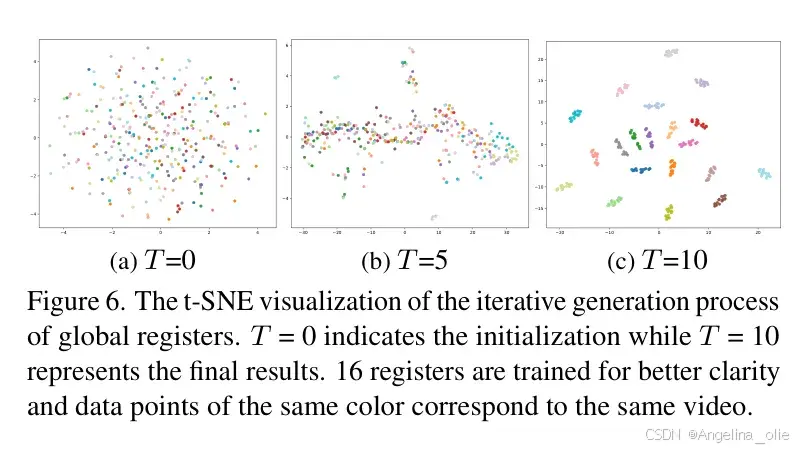
图6展示了寄存器从初始化到最终生成的演变过程
从上图可以看到,在 T=0 时,不同视频的寄存器混杂在一起,毫无语义可言;随着去噪步数增加,到 T=10 时,同属一个视频的寄存器紧密聚类,且不同视频之间界限分明。同时,文本空间的学习也变得更加有序:

图4展示了引入QSP损失后,文本空间变得更加紧凑且具有区分度
在实际案例中,引入全局寄存器后,模型对无关视频的响应显著降低,而对目标片段的定位更加精准。
写在最后
DreamPRVR 可看作是生成式模型(扩散模型)与判别式任务(检索)的一次成功联姻。它告诉我们,在做检索之前,先做一点语义想象,能够极大地提升模型处理复杂背景的能力。
目前代码已经开源,对于正在从事多模态检索、视频理解的同学来说,这套“寄存器 + 轻量扩散”的组合拳值得借鉴。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 3
3 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)