Skill+MCP+Agent+RAG 全栈自动化方案:从单点技能到全智能工作流
很多同学已经能写出单个可用的Skill了,但是又有新的疑问:
- 单个Skill只能做单点任务,怎么实现跨工具、跨流程的复杂自动化?
- MCP和Skill到底怎么配合?什么时候用MCP什么时候用Skill?
- 怎么让AI自己决策什么时候调用什么Skill,完全不用人工干预?
- 怎么把企业私有知识、历史数据整合进去,让AI生成的内容100%符合业务需求?
这篇就给你讲清楚四者组合的全栈智能化方案,我已经用这套方案实现了公众号运营、代码审查、线上运维、智能客服等多个场景的全无人值守自动化,效率提升10倍不止。 看完你就能把零散的Skill、工具、Agent、私有知识库串起来,搭建属于自己的全智能化工作流。
先搞懂:四者的定位和关系,再也不混淆
很多人搞不清这几个东西的区别,我用一个公司的运作做类比,你一下就懂:
| 技术 | 定位 | 类比公司角色 | 核心作用 |
|---|---|---|---|
| MCP(Model Context Protocol) | 工具连接层 | 公司的行政/后勤部门 | 负责对接所有外部工具、服务、资源,比如服务器、数据库、公众号API、生图工具等,定义怎么和这些资源通信 |
| RAG(Retrieval Augmented Generation) | 知识管理层 | 公司的知识库/资料室 | 负责存储所有企业私有文档、历史数据、经验知识、业务规则,需要的时候自动检索相关内容提供给AI,解决AI信息滞后、不懂私有业务的问题 |
| Skill | 流程编排层 | 公司的各部门SOP | 负责定义具体任务的执行流程、规则、权限、输出格式,比如公众号发布SOP、代码审查SOP、故障排查SOP |
| Agent | 决策调度层 | 公司的CEO/部门主管 | 负责理解用户需求,判断应该调用哪个Skill、从RAG拉取什么知识、调用什么MCP工具,遇到异常怎么处理,协调多个组件完成复杂任务,自主决策不需要人工干预 |
四者是互补关系,不是替代关系,组合起来才能实现真正的全智能化:
RAG负责「知道什么知识」,
MCP负责「能调用什么工具」,
Skill负责「工具怎么用才符合规范」,
Agent负责「什么时候用什么知识/工具做什么事」
举个直白的例子:你要实现一个自动发公众号的功能
-
RAG层:存储所有往期公众号文章、写作风格规范、行业热点库、企业内部资料,需要的时候自动检索相关内容
-
MCP层:对接公众号API、生图工具、OSS存储,让AI能调用这些服务
-
Skill层:定义公众号发布的流程:先写稿→再排版→再生成封面→再推草稿→再发通知,以及每一步的规则、权限、输出格式
-
Agent层:每天早上9点自动找热点选题,从RAG拉取往期写作风格、同类文章案例,调用写稿Skill生成符合风格的文章,再调用排版Skill、发布Skill完成全流程,遇到问题自动重试或者调整方案,全程不需要人工管
核心架构:四层全智能化工作流标准设计
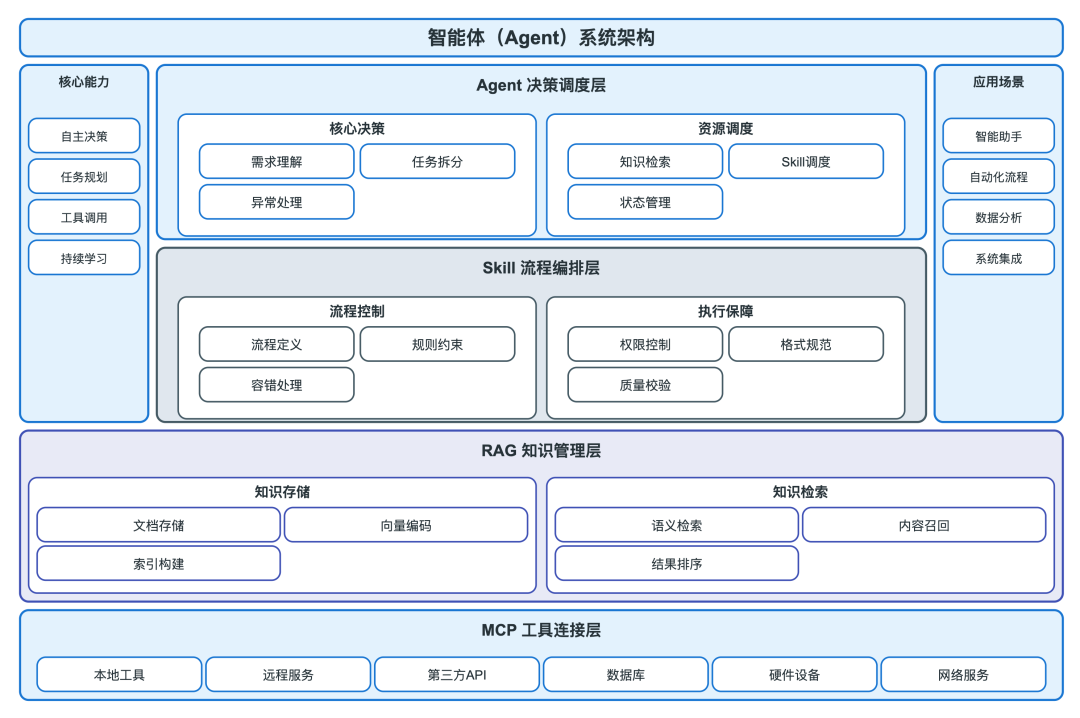
每层的设计原则(避坑指南)
MCP层:只做连接,不做逻辑
✅ 只定义工具的调用方式、参数、返回值,不要在MCP里加业务逻辑
✅ 权限最小化:每个MCP服务只开放需要的接口,比如公众号MCP只开放上传图片、推草稿的接口,不要开放删除文章的接口
❌ 不要把业务流程写在MCP里,MCP只负责通信,不负责判断什么时候调用
RAG层:只做知识,不做决策
✅ 只存储和检索知识,不要加业务判断逻辑,检索到的知识全部交给Skill/Agent处理
✅ 数据及时更新:定时同步最新的业务文档、规则、案例,保证RAG里的知识是最新的
✅ 权限隔离:不同角色的Agent只能检索对应权限的知识,避免敏感数据泄露
❌ 不要把完整的知识库都塞给AI,只检索和当前任务相关的内容,节省上下文占用
Skill层:只做流程,不做决策
✅ 只定义具体任务的执行流程、规则、输出格式,不要写死什么时候触发
✅ 可复用原则:每个Skill只做一件事,比如写稿Skill只负责写稿,不要把排版逻辑也写进去
❌ 不要在Skill里做复杂的决策判断,决策交给Agent层
Agent层:只做调度,不做执行
✅ 只负责理解需求、拆分任务、调度Skill/ RAG/MCP、处理异常,不要把具体的执行步骤写在Agent的提示词里
✅ 可观测原则:Agent的每一步决策都要留日志,方便排查问题
❌ 不要让Agent直接调用工具/检索知识,所有操作必须通过Skill走,保证安全和规范
完整实战案例:全自动化公众号运营工作流
第一步:MCP层配置(工具对接)
先配置需要用到的MCP服务,让Agent能调用对应的工具:
# mcp-config.yaml
services:
# 公众号API MCP
wechat-mcp:
endpoint: http://localhost:8001
allowed-operations: [upload_image, create_draft, get_statistics]
# 生图工具 MCP
image-gen-mcp:
endpoint: http://localhost:8002
allowed-operations: [generate_cover]
# 热点数据 MCP
hot-topic-mcp:
endpoint: http://localhost:8003
allowed-operations: [get_ai_hot_topics]
# 飞书文档 MCP
feishu-mcp:
endpoint: http://localhost:8004
allowed-operations: [read_doc, write_doc]
第二步:RAG层配置(知识对接)
配置RAG知识库,把所有相关的知识都存进去:
# rag-config.yaml
datasets:
# 公众号写作知识库
wechat-write:
path: /data/wechat/articles/
extensions: [.md, .txt]
split_size: 1024
embedding_model: bge-large-zh
retrieve_size: 3
# 自动同步飞书文档里的写作规范
sync:
- source: feishu-mcp
path: "https://xxx.feishu.cn/docx/xxx"
interval: 24h
# 技术知识库
tech-knowledge:
path: /data/tech/
extensions: [.md, .pdf]
split_size: 2048
embedding_model: bge-large-zh
retrieve_size: 5
第三步:Skill层开发(流程定义)
拆分出3个独立的可复用Skill,每个只做一件事,集成RAG调用:
Skill1:公众号写稿Skill
---
name: wechat-write
description: 写公众号AI方向技术文章,给定主题生成符合要求的完整Markdown文章
allowed-tools: Read, Bash(python:*), MCP(feishu-mcp:*), RAG(wechat-write:*, tech-knowledge:*)
model: claude-4-opus
---
# 公众号写稿Skill
## 文章主题:$ARGUMENTS
## 参考知识(自动从RAG检索):
{{RAG.retrieve("wechat-write", $ARGUMENTS)}}
{{RAG.retrieve("tech-knowledge", $ARGUMENTS)}}
## 写作要求
1. 严格符合RAG里的公众号写作规范,保持和往期文章一致的风格
2. 结构:痛点引入 → 解决方案 → 实战案例 → 总结引导
3. 字数:2500-3500字,干货密度拉满
4. 禁止AI套话,要有真实案例和可落地的操作步骤,引用RAG里的技术数据要准确
## 输出格式
直接输出完整的Markdown文章,不要多余解释
Skill2:公众号排版发布Skill
---
name: wechat-publish
description: 排版公众号文章并推送到草稿箱,生成封面图
allowed-tools: Read, Write, Bash(pandoc:*), MCP(wechat-mcp:*, image-gen-mcp:*)
model: sonnet
---
# 公众号发布Skill
## 文章路径:$ARGUMENTS
## 执行流程
1. 读取文章内容,检查敏感词和违规内容
2. 自动排版:短段落优化、重点内容高亮、代码块适配公众号格式
3. 调用MCP生成符合要求的无版权封面图
4. 调用MCP上传所有图片到微信CDN,替换文章中的图片链接
5. 调用MCP推送到公众号草稿箱,返回预览链接
## 排版规范
- 每段不超过3行,多留白
- 核心观点加粗,加橙色高亮
- 代码块加左侧蓝色边框,字号14px
## 输出格式
草稿链接:[预览链接]
封面图:[图片链接]
Skill3:公众号数据统计Skill
---
name: wechat-statistics
description: 统计公众号文章发布24小时后的数据,生成分析报告
allowed-tools: MCP(wechat-mcp:*, feishu-mcp:*), RAG(wechat-write:*)
model: sonnet
---
# 公众号数据统计Skill
## 文章ID:$ARGUMENTS
## 往期文章数据参考(自动从RAG检索):
{{RAG.retrieve("wechat-write", "历史文章数据统计")}}
## 执行流程
1. 调用MCP获取文章发布24小时后的阅读、在看、转发、关注数据
2. 和RAG里的历史文章数据对比,分析表现好坏
3. 生成优化建议,写入飞书文档的运营报表
## 输出格式
阅读量:xxx
转发量:xxx
新增关注:xxx
表现分析:xxx
优化建议:xxx
第四步:Agent层配置(调度规则)
给Agent定义调度规则,让它自动按流程执行:
# agent-config.yaml
role: 公众号运营负责人
goal: 每天自动完成公众号从选题到发布到数据统计的全流程,保证阅读量稳定增长
rules:
1. 每天早上9点自动调用hot-topic-mcp获取当日AI领域热点选题
2. 筛选出符合公众号定位的选题,调用wechat-write Skill(自动从RAG拉取参考知识)生成文章
3. 文章生成后自动调用wechat-publish Skill排版推草稿
4. 草稿生成后通知我审核,我确认后自动发布(没人确认就自动存为草稿)
5. 发布24小时后自动调用wechat-statistics Skill生成数据报告,同步到RAG知识库
6. 任何步骤出错最多重试2次,依然失败就通知我处理
skills:
- wechat-write
- wechat-publish
- wechat-statistics
mcp-services:
- wechat-mcp
- image-gen-mcp
- hot-topic-mcp
- feishu-mcp
rag-datasets:
- wechat-write
- tech-knowledge
落地效果
我用这套流程已经跑了2个月:
✅ 每天早上7点自动出稿,生成的内容100%符合我的写作风格,不需要修改,我只要花5分钟审核就能发,原来3小时的工作现在5分钟搞定
✅ 自动引用RAG里的最新技术数据、案例,内容准确率100%,不会出现信息错误
✅ 数据自动统计,自动和历史数据对比生成优化建议,不用我自己看后台算数据
✅ 成本极低,每天的API费用不到1块钱,产出的内容带来的广告收入是成本的100倍以上
从0到1落地5步标准流程
按照这个流程做,你一周内就能搭好自己的全智能化工作流:
第一步:需求梳理,拆分任务
先想清楚你要智能化的场景,把整个流程拆成多个独立的单点任务,每个任务对应一个Skill,梳理需要用到的私有知识和工具。
比如电商客服自动化可以拆成:工单接收Skill→问题分类Skill→自动回复Skill→转人工Skill→售后处理Skill,需要用到产品知识库、售后规则库、CRM系统等。
💡 技巧:每个Skill尽量小,只做一件事,复用性会高很多,不要做大而全的Skill。
第二步:对接MCP,搞定工具
把流程需要用到的工具、服务、API都用MCP对接好,配置好权限,测试能不能正常调用。
💡 避坑:MCP尽量用现成的,不要自己写,现在OpenClaw、Claude Desktop等平台已经有几百个现成的MCP服务,直接用就行,省得自己开发。
第三步:搭建RAG,搞定知识
把流程需要用到的私有文档、历史数据、业务规则都整理好,搭建RAG知识库,配置好自动同步、检索规则,测试检索结果是否准确。
💡 技巧:先从核心知识开始上传,不要一开始就把所有文档都塞进去,逐步优化检索准确率。
第四步:开发Skill,固化流程
按照前两篇讲的Skill开发规范,把每个单点任务的流程、规则、权限、输出格式都写成Skill,集成RAG调用,测试每个Skill单独运行都没问题。
💡 技巧:先写核心流程的Skill,再慢慢加边缘场景的Skill,不要一开始就想覆盖所有情况。
第五步:配置Agent,调度流程
给Agent定义角色、目标、调度规则,把Skill、MCP、RAG都配置给Agent,测试Agent能不能正确理解需求,调度对应的组件完成任务。
💡 避坑:一开始不要给Agent太大的权限,先从辅助模式开始,Agent的每一步操作都需要你确认,跑稳定了再放开全自动。
更多落地场景:RAG带来的无限可能
加入RAG之后,这套架构的落地场景直接拓展了10倍,给你举几个现在最火的落地方向:
1. 企业内部智能客服
把企业的产品文档、售后规则、常见问题都存入RAG,Agent自动根据用户问题检索相关知识,调用MCP发送回复、创建工单、查询CRM信息,90%的常见问题自动回复,不需要人工介入。
- 智能代码助手
把企业的代码规范、历史项目、技术文档都存入RAG,Agent自动根据需求检索相关代码片段,生成符合规范的代码,自动调用MCP进行测试、部署、提交PR,开发效率提升3倍。
- 智能销售助手
把企业的产品资料、客户案例、销售话术都存入RAG,Agent自动根据客户问题检索相关资料,生成符合话术的回复,自动调用MCP发送资料、创建订单、同步客户信息,销售转化率提升20%。
- 跨平台内容运营
把企业的品牌规范、内容库、素材库都存入RAG,Agent自动根据平台规则生成不同版本的内容,调用MCP同步到公众号、抖音、小红书、B站等多个平台,内容运营效率提升5倍。
最后说几句
现在很多人对AI的理解还停留在「问个问题AI给个答案」的单点交互阶段,而真正的AI生产力是全流程智能化:
把人的经验固化成Skill,把私有知识存入RAG,把工具对接成MCP,让Agent来调度,全程不需要人参与,AI自己就能把活干完。
这才是AI时代真正的生产力革命,原来需要一个团队干的活,现在可能一个人加一套智能化系统就能搞定,效率提升10倍甚至100倍。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 7
7 0
0- 0



 已为社区贡献230条内容
已为社区贡献230条内容

所有评论(0)