一套企业级 RAG 问答系统的实现记录(Spring AI Alibaba ReactAgent + Qdrant)
这段时间,我基于知识库做了一套问答系统。
一开始的想法其实很简单:
👉 把已有的文档,用“问答”的方式更方便地用起来。
做的过程中也踩了一些坑。
有些地方效果还可以,有些地方也还有不少可以继续优化。
这篇文章主要是把这次实现过程中的一些做法整理一下。
如果你刚好也在做 RAG,或许能有一点参考价值。
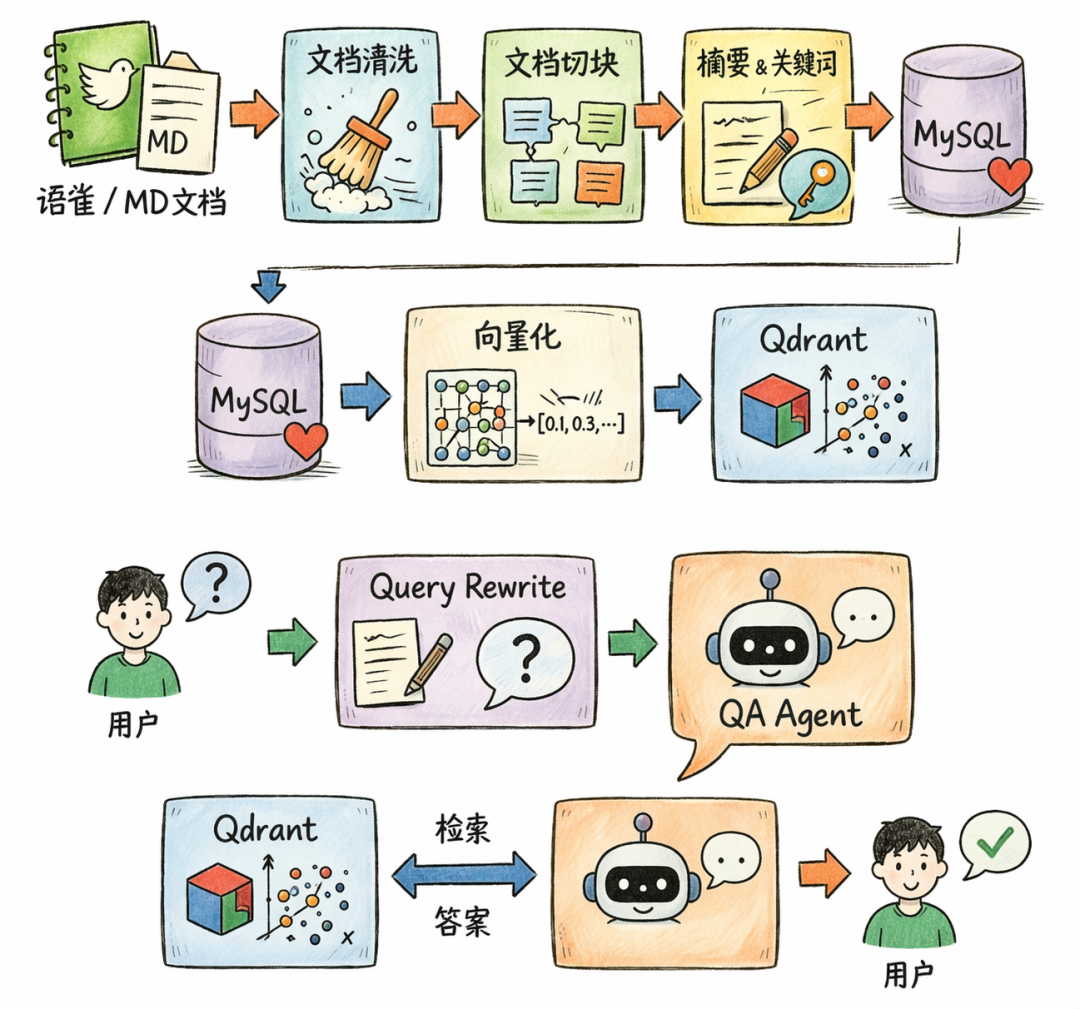
🧩 整体思路:一个简单的 RAG 流程拆解
这套实现主要是基于 Spring AI Alibaba ReactAgent 来做 Agent 编排, 向量检索使用的是 Qdrant。
如果从流程上看,可以拆成四个阶段:
👉 文档处理 → 索引增强 → 检索 → 问答生成
对应到实现大概是:
- 文档处理:语雀 / Markdown → 清洗 → 切块
- 索引增强:提取标题、关键词、摘要
- 检索:向量检索 + BM25 + 融合排序
- 问答:Query Rewrite + Agent 多次检索 + 生成答案
这几部分拼在一起,就是一条比较完整的 RAG 链路。
📌 第一步:先解决“文档从哪里来”
知识源我这边主要用了两类:
- 语雀知识库
- 本地 Markdown 文档
这里有一个小处理:
👉 不只是拿正文
👉 会把目录结构一起保留下来
因为在后面切块的时候,目录其实就是天然的上下文信息。
⚙️ 第二步:文档清洗(这一层比较基础,但有必要)
文档拿到之后,我没有直接做 embedding。
而是先做了一轮清洗:
- 去掉无关图片
- 去掉注释和杂质
- 保留代码块
- 统一成 Markdown 文本
这一层不复杂,但如果不做,后面的问题会被放大。
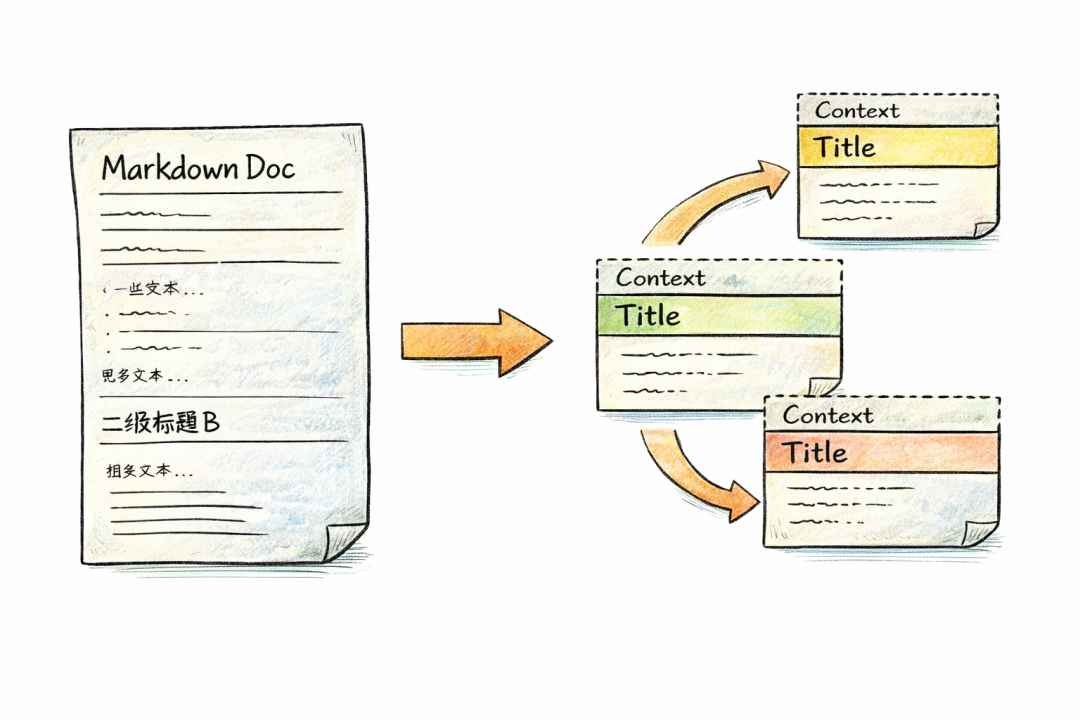
✂️ 第三步:切块(Chunking 比想象中更重要)
RAG 里一个很容易被忽略的点是:
👉 文档怎么切
很多实现是:
- 固定 token 切分
- 或者简单按段落切
但这样容易有一个问题:
👉 上下文被切断
我这边采用的是:
👉 目录结构 + 字数控制
大致规则:
- 内容不长 → 一个块
- 太长 → 按一级标题切
- 还长 → 按二级标题
- 再长 → 按段落
核心逻辑类似这样:
List<MarkdownUtils.ChunkResult> chunks = MarkdownUtils.splitWithContext(content, docContext);for (MarkdownUtils.ChunkResult chunk : chunks) { FeaturePoint point = extractFromChunk(chunk);}
这里我比较在意一点:
👉 每个 chunk 都必须有“能承接上下文的标题”
不是为了好看,而是为了表达:
- 来自哪篇文档
- 属于哪个目录
- 当前在讲什么
可以理解为:
👉 每个 chunk 是一个“最小语义单元”,而不是一段随机文本
🧠 第四步:索引增强(不是只存正文)
切块之后,我没有直接入向量库。
而是做了一步“信息补充”:
👉 提取关键词 + 摘要
这里其实有一个小调整过程:
一开始我是用 Agent 来做关键词提取的。
但后面用下来,做了一次改动:
👉 关键词提取改成了代码实现
原因比较实际:
- 关键词提取更偏规则型任务
- 用代码更稳定、可控
- 调整成本也更低
摘要这块,如果有需要,仍然可以用模型辅助。
最终会把这些信息一起存下来:
QaPair pair = QaPair.builder() .featureTitle(point.title()) .featureKeyword(point.keywords()) .featureSummary(point.summary()) .featureContent(point.content()) .build();
这里一个比较直观的体会是:
👉 不是所有环节都适合用 Agent
规则明确的地方,用工程逻辑反而更合适。
🚀 第五步:向量化(拼的不只是内容)
在向量化时,我没有只用正文。
而是把这些信息拼在一起:
👉 标题 + 关键词 + 摘要 + 正文
再写入 Qdrant。
原因是:
👉 在企业场景里,很多关键信息其实在标题和关键词里
比如:
- 菜单名
- 字段名
- 功能名
如果只 embedding 正文,反而容易丢信息。
可以简单理解为:
👉 我不是在存“内容”,而是在存“更容易被检索到的内容”
🔍 第六步:检索(向量 + BM25 的混合检索)
检索这一层,我没有只用向量检索。
因为在实际场景里,纯向量检索会有一些问题:
- 对精确词不敏感
- 有时候语义相关但不准确
所以这里做了一层混合检索:
- 向量检索:负责语义召回
- BM25:负责关键词命中
- RRF:对多路结果做融合排序
核心逻辑类似这样:
List<Document> vectorResults = performVectorSearch(query, vectorTopK, similarityThreshold);List<Document> keywordResults = performKeywordSearch(query, bm25TopK);List<Document> mergedResults = mergeWithRRF(vectorResults, keywordResults, finalTopK);
这样处理之后,在我的测试场景里:
👉 命中效果会相对稳定一些
尤其是一些“精确名称类问题”。
🔄 第七步:Query Rewrite(多轮对话的关键)
在多轮对话场景下,我加了一层 Query Rewrite。
用户问题不会直接进入检索,而是先改写:
👉 当前问题 + 最近几轮对话 → 一个完整问题
比如用户说:
- “这个怎么配?”
- “为什么不行?”
如果直接查,基本命不中。
改写之后会变成一个更明确的问题,再进入检索。
本质上,这一步是在做:
👉 Query Reformulation(查询重写)
用来解决对话中的上下文缺失问题。
💬 第八步:让 Agent 参与“检索过程”
最后才进入问答阶段。
这里我没有做成:
👉 检索一次 → 直接生成答案
而是:
👉 让 ReactAgent 可以多次调用检索工具
比如:
- 换关键词再查
- 多轮查
- 再组织答案
核心注册方式类似:
return ReactAgent.builder() .name("QA-Chat-Agent") .model(chatModel) .methodTools(vectorSearchTool) .build();
这种方式更接近:
👉 “在查资料”,而不是“直接生成”
📊 一些实践中的体会(仅供参考)
这部分不算结论,只是这次实现的一些感受:
- 📌 文档质量,会直接影响最终效果
- 📌 切块方式,对检索影响很大
- 📌 标题不是装饰,而是检索的一部分
- 📌 多轮对话里,Query Rewrite 很有必要
- 📌 Agent 不一定越多越好,分工清晰更重要
如果用一句话总结:
👉 RAG 里模型很重要,但数据和检索设计更关键
🌐 开源 & 体验
这套实现我整理了一下,也开源了一版:
👉 GitHub 地址:https://github.com/liochaoo/yuncheng-agent-qa
👉 Gitee 地址:https://gitee.com/liochaoo/yuncheng-agent-qa
README 里包含了完整的流程说明,包括:
- 文档处理与切块策略
- 向量化与 Qdrant 存储
- 混合检索实现
- Query Rewrite 逻辑
- Agent 调用链路
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 10
10 0
0- 0



 已为社区贡献172条内容
已为社区贡献172条内容

所有评论(0)