【24年新算法】 基于DE-Transformer-BiLSTM多变量时序预测(多输入单输出)附Matlab代码
✅作者简介:热爱科研的Matlab仿真开发者,擅长毕业设计辅导、数学建模、数据处理、建模仿真、程序设计、完整代码获取、论文复现及科研仿真。
🍎 往期回顾关注个人主页:Matlab科研工作室
👇 关注我领取海量matlab电子书和数学建模资料
🍊个人信条:格物致知,完整Matlab代码获取及仿真咨询内容私信。
🔥 内容介绍
在工业过程控制、能源调度、气象预报等众多领域,多变量时序预测至关重要。其旨在通过分析多个相关变量随时间的变化,预测单一目标变量的未来值。但多变量时间序列存在变量间非线性与耦合性、时变特性等复杂关系,传统的线性回归、ARIMA 等模型基于线性和稳态假设,难以捕捉这些特征,且人工特征工程也无法全面反映数据内在规律,导致预测精度较低。
原理
- Transformer 架构
:利用自注意力机制对输入的多维时间序列进行跨时间步、跨变量维度的全局关系建模,能有效捕捉长距离依赖关系,缓解传统 RNN 类模型在长序列中因梯度消失 / 爆炸导致的长程依赖丢失问题。位置编码为模型提供时间步的顺序信息,多头注意力机制可侧重关注特定变量组合间的耦合关系。
- BiLSTM 网络
:BiLSTM 通过前向 LSTM 捕获从过去到当前的时间演化趋势,后向 LSTM 反向挖掘未来信息对当前状态的约束作用,从而在时间轴上形成 “双向语义闭环”,增强对瞬态突变、周期性扰动及非线性滞后效应的建模鲁棒性,有效提取局部时序特征。
- 特征融合
:将 Transformer 输出的全局特征与 BiLSTM 输出的局部特征通过拼接或加权相加等方式进行融合,再经层归一化消除尺度差异,使模型能兼顾局部细节与全局趋势,提升预测精度。
- 差分进化算法优化
:在模型训练过程中,引入 DE 算法对模型参数进行优化。将 Transformer 和 BiLSTM 的参数看作 DE 算法中的个体,通过变异、交叉和选择操作,引导模型参数朝着使预测误差最小化的方向调整,帮助模型跳出局部最优解,收敛到全局最优或近似全局最优的参数配置,提高预测性能。
- 预测输出
:融合后的特征经全连接层整合,实现多输入单输出的回归预测,得到目标变量的预测值。
⛳️ 运行结果
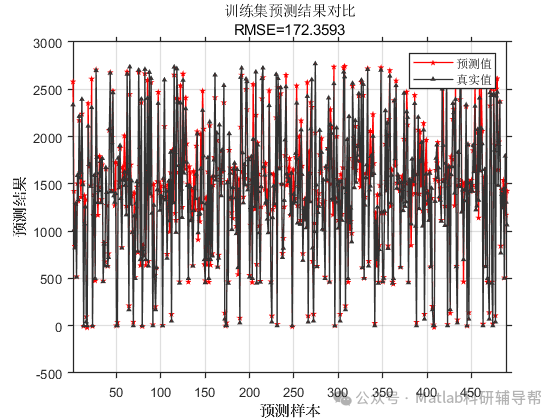
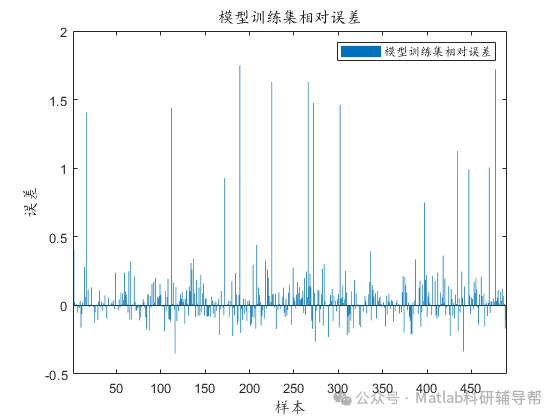
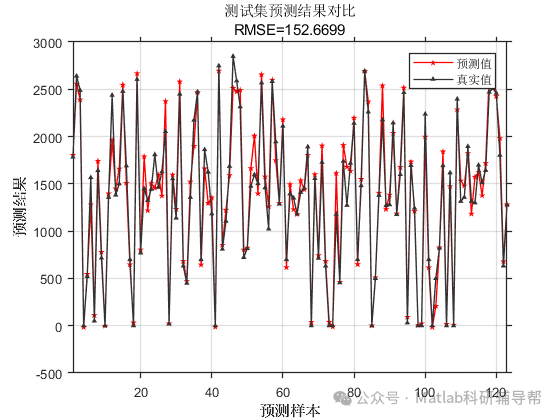
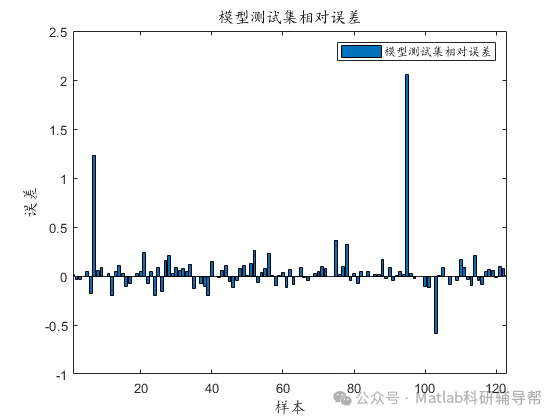
📣 部分代码
function [R,rmse,biaozhuncha,mae,mape]=calc_error(x1,x2)
%此函数用于计算预测值和实际(期望)值的各项误差指标
% 参数说明
%----函数的输入值-------
% x1:真实值
% x2:预测值
%----函数的返回值-------
% mae:平均绝对误差(是绝对误差的平均值,反映预测值误差的实际情况.)
% mse:均方误差(是预测值与实际值偏差的平方和与样本总数的比值)
% rmse:均方误差根(是预测值与实际值偏差的平方和与样本总数的比值的平方根,也就是mse开根号,
% 用来衡量预测值同实际值之间的偏差)
% mape:平均绝对百分比误差(是预测值与实际值偏差绝对值与实际值的比值,取平均值的结果,可以消除量纲的影响,用于客观的评价偏差)
% error:误差
% errorPercent:相对误差
if nargin==2
if size(x1,2)==1
x1=x1'; %将列向量转换为行向量
end
if size(x2,2)==1
x2=x2'; %将列向量转换为行向量
end
num=size(x1,2);%统计样本总数
error=x2-x1; %计算误差
x1(find(x1==0))=inf;
errorPercent=abs(error)./x1; %计算每个样本的绝对百分比误差
mae=sum(abs(error))/num; %计算平均绝对误差
mse=sum(error.*error)/num; %计算均方误差
rmse=sqrt(mse); %计算均方误差根
mape=mean(errorPercent); %计算平均绝对百分比误差
biaozhuncha=std(x2);
%结果输出
for i=1:size(x1,1)
tempdata=(x1(i,:)-x2(i,:)).^2;
tempdata2=(x1(i,:)-mean(x1(i,:))).^2;
R(i)=1 - ( sum(tempdata)/sum(tempdata2) );
% disp(['决定系数R为: ',num2str(R(i))])
end
disp(['标准差为: ',num2str(biaozhuncha)])
disp(['均方误差根rmse为: ',num2str(rmse)])
disp(['平均绝对误差mae为: ',num2str(mae)])
disp(['平均绝对百分比误差mape为: ',num2str(mape*100),' %'])
else
disp('函数调用方法有误,请检查输入参数的个数')
end
end
🔗 参考文献
🍅往期回顾扫扫下方二维码

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 6
6 0
0- 0



 已为社区贡献205条内容
已为社区贡献205条内容

所有评论(0)