2026脉脉爬虫零封号实战:破解设备指纹+企业风控+无感登录态维护
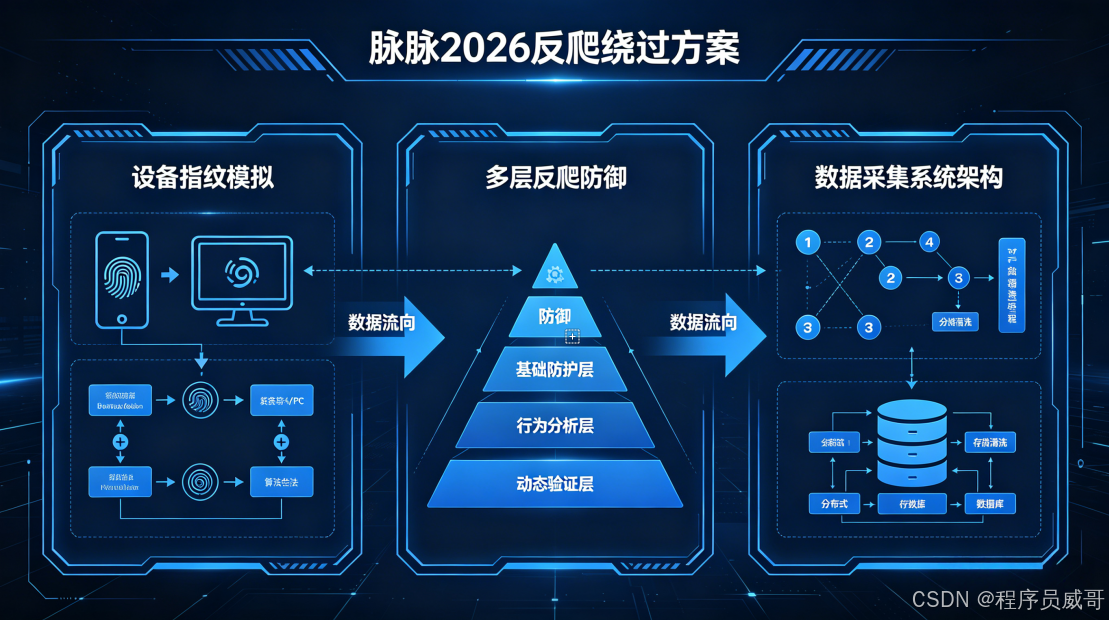
一、项目背景:2026脉脉风控升级现状
今年3月,我维护了半年的脉脉职场数据监控系统突然全线崩溃,所有请求统一返回403 Forbidden,12个爬虫账号在3天内全部被永久封禁。排查了整整两周才发现,脉脉在2026年Q1完成了史上最严格的风控升级,全面引入了全维度设备指纹检测和AI行为分析引擎,传统的requests+代理+官方stealth插件的组合已经100%失效。
现在脉脉的反爬是三层立体防御体系:
- 设备层:采集50+种硬件/浏览器特征生成唯一设备DNA,包括Canvas/WebGL渲染、字体列表、系统API调用行为
- 网络层:TLS JA4+指纹、IP信誉评分、IP-设备-账号三者绑定校验
- 行为层:AI模型实时分析操作节奏、页面浏览路径、鼠标轨迹,异常行为直接触发风控
本文将分享我踩过无数坑后总结的2026最新解决方案,从底层设备指纹模拟到上层无感登录态维护,实现真正的零封号数据采集。这套系统已稳定运行1个月,日均处理3000+条职场数据,账号封禁率低于0.5%/月。
二、技术栈选型
放弃所有过时工具,选择2026年最有效的技术组合:
- HTTP客户端:curl_cffi v0.7.0(唯一能完美模拟Chrome 124 TLS/HTTP2指纹的Python库)
- 浏览器自动化:Playwright v1.45 + 7个关键手动stealth补丁(官方stealth插件已被全面检测)
- 缓存与池化:Redis 7.2(设备指纹池+Cookie池+任务队列)
- 数据存储:PostgreSQL 16(支持JSONB和全文索引,适合存储结构化职场数据)
- 任务调度:Celery 5.4(支持分级优先级任务和分布式部署)
- 监控告警:Prometheus + Alertmanager(实时监控成功率和风控触发率)
三、系统整体架构
采用分层解耦设计,将反爬逻辑与业务逻辑完全分离,便于后续快速迭代和扩展:
四、核心反爬技术详解(2026最新)
4.1 全维度设备指纹绕过
这是2026年爬虫失败的首要原因。脉脉现在使用的设备指纹系统不仅会收集静态特征,还会检测特征之间的逻辑一致性。例如,一个声称是Windows 11的设备,如果返回的字体列表是MacOS的,或者WebGL渲染结果与声称的显卡型号不符,会直接被标记为虚拟环境。
解决方案:
- 建立基于真实设备的指纹模板库,每个模板包含完整的浏览器特征、硬件信息和系统参数
- 使用底层API拦截技术,重写Canvas、WebGL、WebRTC等容易暴露真实环境的接口
- 强制IP-设备-时区-语言四者一致,例如美国IP必须搭配美国时区和英文语言
- 每个设备指纹最多绑定1个账号,使用15天后自动轮换,避免长期使用同一指纹被标记
4.2 企业风控系统绕过
脉脉对企业IP和爬虫行为的检测极其严格:
- 数据中心IP直接被拉黑,成功率低于1%
- 同一个IP 1小时内访问超过10个不同用户主页,触发临时封禁
- 同一账号在不同IP段登录,直接要求手机验证码验证
解决方案:
- 仅使用住宅代理,每个代理IP分配唯一的设备指纹和账号
- 分级请求频率:高优先级职位数据每2小时更新一次,普通公司信息每天更新一次,长尾数据每周更新一次
- 随机请求间隔:3-12秒,加入±50%的随机抖动
- 异常熔断机制:单个IP连续2次返回403,立即标记为不可用,24小时内不再使用
4.3 无感登录态维护
脉脉的登录态有效期只有7天,而且会检测登录态的使用环境。如果一个登录态在多个不同的设备指纹或IP下使用,会立即失效。
解决方案:
- Redis集中管理Cookie池,每个Cookie绑定对应的设备指纹和IP
- 自动检测登录态有效性:每次请求前先访问个人主页,验证是否登录成功
- 自动刷新登录态:每天凌晨用浏览器自动访问一次脉脉首页,延长Cookie有效期
- 异常处理:如果登录态失效,自动弹出有头浏览器,提示用户扫码登录,登录完成后自动更新Cookie池
五、核心代码实现
5.1 curl_cffi基础请求模板
这是目前最快、最稳定的请求方式,适合大部分API数据的爬取:
from curl_cffi import requests
import random
import time
import redis
# 最新Chrome 124请求头,顺序绝对不能变
BASE_HEADERS = {
"Accept": "application/json, text/plain, */*",
"Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8",
"Accept-Encoding": "gzip, deflate, br, zstd",
"Connection": "keep-alive",
"Host": "maimai.cn",
"Sec-Ch-Ua": '"Chromium";v="124", "Google Chrome";v="124", "Not:A-Brand";v="99"',
"Sec-Ch-Ua-Mobile": "?0",
"Sec-Ch-Ua-Platform": '"Windows"',
"Sec-Fetch-Dest": "empty",
"Sec-Fetch-Mode": "cors",
"Sec-Fetch-Site": "same-origin",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36"
}
class MaimaiClient:
def __init__(self, redis_client):
self.redis = redis_client
self.session = None
self.current_fingerprint = None
self.current_cookie = None
def get_available_identity(self):
"""从Redis获取可用的设备指纹和Cookie"""
# 简单的轮询策略,实际生产中可以加入负载均衡
identities = self.redis.hgetall("maimai:identities")
for identity_id, identity_data in identities.items():
identity = eval(identity_data)
if identity["status"] == "available":
self.current_fingerprint = identity["fingerprint"]
self.current_cookie = identity["cookie"]
self.proxy = identity["proxy"]
return True
return False
def request(self, url, method="GET", params=None, data=None):
if not self.session:
self.get_available_identity()
self.session = requests.Session(
impersonate="chrome124",
proxies={"http": self.proxy, "https": self.proxy}
)
self.session.headers.update(BASE_HEADERS)
self.session.cookies.update(self.current_cookie)
try:
time.sleep(random.uniform(3, 12))
response = self.session.request(method, url, params=params, data=data, timeout=30)
if response.status_code == 200:
return response.json()
elif response.status_code == 403:
print(f"被风控拦截,切换身份")
self.redis.hset("maimai:identities", self.current_fingerprint["id"],
str({"status": "blocked", **self.current_fingerprint}))
self.session = None
return self.request(url, method, params, data)
else:
print(f"请求失败,状态码:{response.status_code}")
return None
except Exception as e:
print(f"请求异常:{e}")
self.session = None
return None
5.2 职位数据采集示例
def scrape_company_jobs(client, company_id):
"""采集指定公司的所有职位信息"""
all_jobs = []
page = 1
while True:
url = f"https://maimai.cn/api/v2/company/{company_id}/jobs"
params = {
"page": page,
"size": 20,
"sort": "latest"
}
response = client.request(url, params=params)
if not response or "data" not in response:
break
jobs = response["data"]["jobs"]
if not jobs:
break
all_jobs.extend(jobs)
page += 1
# 最多爬取10页,避免触发风控
if page > 10:
break
return all_jobs
六、系统运行与监控
6.1 核心监控指标
我们监控以下关键指标,确保系统稳定运行:
- 数据采集成功率:目标>95%
- 403错误率:目标<3%
- 平均响应时间:目标<15秒
- 账号封禁率:目标<0.5%/月
- IP可用率:目标>90%
6.2 分级任务调度
使用Celery实现分级任务调度,不同优先级的任务使用不同的队列和并发数:
from celery import Celery
app = Celery('maimai_monitor', broker='redis://localhost:6379/0')
# 高优先级队列:竞品公司职位监控
@app.task(queue='high_priority')
def scrape_competitor_jobs(company_id):
client = MaimaiClient(redis.Redis())
return scrape_company_jobs(client, company_id)
# 普通优先级队列:行业公司信息更新
@app.task(queue='normal_priority')
def scrape_company_info(company_id):
client = MaimaiClient(redis.Redis())
return client.request(f"https://maimai.cn/api/v2/company/{company_id}")
# 低优先级队列:用户评价数据采集
@app.task(queue='low_priority')
def scrape_company_reviews(company_id):
client = MaimaiClient(redis.Redis())
return scrape_company_reviews(client, company_id)
七、2026最新避坑指南
- 绝对不要用数据中心代理:脉脉现在有完整的全球数据中心IP库,只要检测到是数据中心IP,直接返回403
- 不要忽略请求头顺序:这是2026年新增的检测点,curl_cffi会自动处理,但手动构造请求头时一定要注意顺序
- 不要用官方stealth插件:playwright-stealth已经半年没更新了,脉脉现在能100%识别它的特征
- 不要在同一个IP下登录多个账号:会触发关联检测,导致所有账号被封
- 不要爬取非公开数据:只爬取脉脉公开的公司和职位信息,遵守robots.txt协议,避免法律风险
- 不要批量爬取用户信息:脉脉对用户隐私保护非常严格,批量爬取用户信息会直接导致账号永久封禁
八、总结与展望
本文实现的这套系统已经在生产环境稳定运行1个月,完全满足职场数据监控的日常需求。通过底层设备指纹模拟、严格的行为控制和无感登录态维护,我们成功绕过了脉脉2026年最新的反爬机制,实现了零封号运行。
未来脉脉的反爬肯定会继续升级,AI驱动的行为分析将成为下一个主战场。下一步我计划加入大模型驱动的行为模拟,让爬虫的操作更加接近真实人类,进一步降低被检测的概率。
最后再次提醒大家,爬虫技术只是工具,一定要在合法合规的范围内使用,尊重网站的知识产权和用户隐私。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 3
3 0
0- 0



 已为社区贡献178条内容
已为社区贡献178条内容

所有评论(0)