机器学习 —— 逻辑回归(浅析与实例)
目录
一、概念
解决的是分类问题
应用场景:预测疾病(阴性、阳性)、银行信任贷款(放贷、不放贷)、预测广告点击率(点击、不点击)等等。
逻辑回归核心思想(解决二分类的利器)
比如:
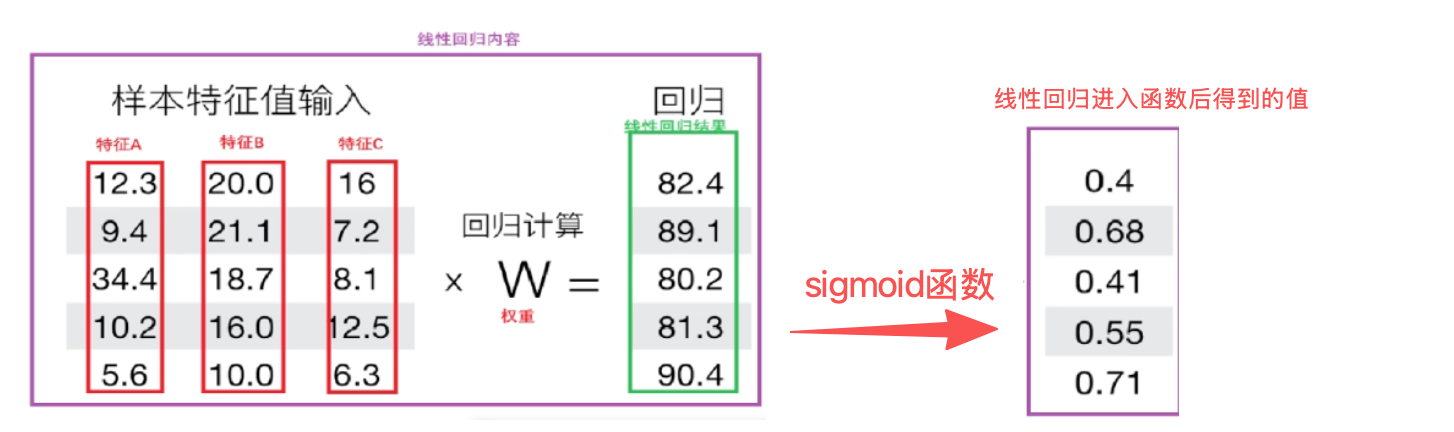
学生成绩(输入成绩、考试分数) => 线性函数 ![]()
=> 把线性回归的输出作为sigmoid函数的输入
=> P 设置概率,比如P > 0.5 通过, P <= 0.5 不通过
将线性回归的输出映射到(0,1)区间,不一定是0.5
把线性回归的输出,当做逻辑回归的输入,然后讲数据映射到区间上,做分类操作
二、数学知识
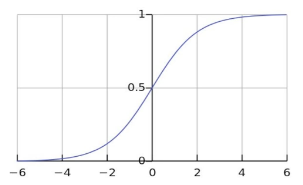
1.sigmoid 函数
![]()
作用
![]()
数学性质
单调递增函数
拐点在x=0 时 y = 0.5,斜率最大
当 f(x) > 0.5 时,预测结果维1
当f(x) < 0.5 时,预测结果为0
导函数
![]()
f(x). 概率值
![]() 线性回归的输出
线性回归的输出
逻辑回归的假设函数

例子:逻辑回归预测过程(阈值为0.6)
阈值0.6
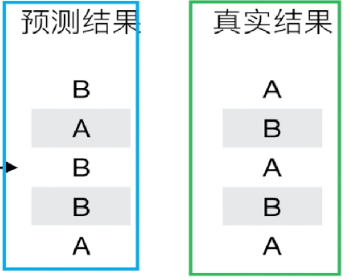 预测结果不好,调整特征。
预测结果不好,调整特征。
2.概率
<1> 边际概率 ——
描述的是单一事件发生的可能性:
记作P(A) 或者 P(B)
事件A事件B发生的概率
<2> 联合概率 ——
描述的是两个或多个独立事件同时发生的概率:
记作P(A∩B)或者P(A,B)
A交B的概率 A和B的联合概率
<3> 条件概率 ——
描述的是在事件A已发生的条件下,事件B发生的概率:
记作P(B | A)
在事件A发生的情况下,事件B发生概率
场景1:联合概率
事件A:周一早上堵车,P(A) = 0.7
事件B:周二早上堵车,P(B) = 0.7
P(A∩B) = 0.7 * 0.7 = 0.49 概率
场景2:条件概率
事件A:周一早上堵车,P(A) = 0.7
事件B:周一中午堵车,切已知P(B | A)= 0.3 (即早上堵车时,中午堵车概率0.3)
联合概率 => P(A∩B)= P(A) * P(B | A)= 0.7 * 0.3 = 0.21
公式:P (B | A)= P (A∩B)/ P(A)
———————————————————————————————————————————
3、逻辑回归原理 —— 交叉熵损失函数
(二分类 (0,1))
损失函数:Loss(L)所有的样本的损失值越小越好
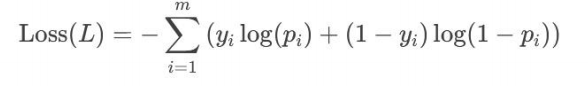
yi : 第i个真实值标签
m:样本总数
pi:第i个样本的预测值
yi: 第i个真实标签 = 1时
如果预测概率(pi)接近于1 log(1)=0 损失接近于0 很好,
如果预测概率(pi)接近于0 log(0)=趋近于负无穷,损失非常大
yi: 第i个真实标签 = 0时
如果预测概率(pi)接近于0 log(1)=0 损失接近于0 很好,
如果预测概率(pi)接近于1 log(0)=趋近于负无穷,损失非常大
例子: 损失函数手工计算

逻辑函数原理 —— 似然函数
1.伯努利分布
描述单次二分类实验结果的离散概率分布,其随机变量X只有两种取值:
X = 1(表示“成功”,概率为p)
X = 0 (表示“失败”,概率为1-p)
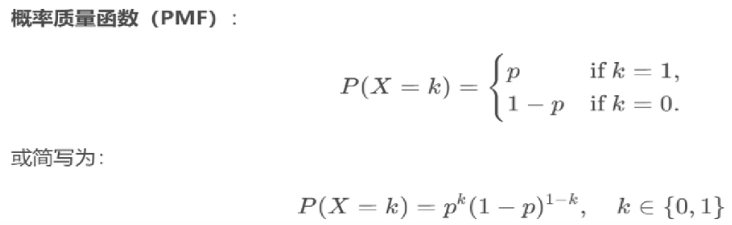
2.伯努利分布函数
假设:有样本[(x1,y1),(x2,y2)....,(xn,yn)],n个样本都预测正确的概率就是伯努利分布的似然函数
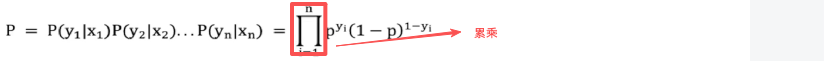
1.pi 表示每个样本被分类正确时候的概率
2. yi 表示每个样本的真实类别(0 或 1)
总体是联合概率,每一项是条件概率。
问题转化为:让联合概率事件最大时,估计w、b的权重参数,这就是极大似然估计(Maximum Likelihood Estimation)
核心思想:在已知观测数据的情况下,选择使用这些数据出现概率最大的参数值。
3.交叉熵和似然函数关系
伯努利分布的似然函数是逻辑回归交叉熵损失的来源,对其取负对数,直接得到交叉熵损失!
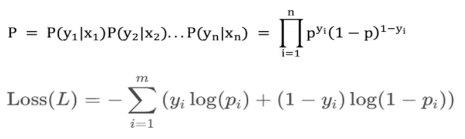
1.把最大化问题将其变为最小化问题(最大化似然函数 -> 最小化交叉熵损失)
2.把连乘问题变为连加问题
举例:
假设数据y = [1,0],模型预测p = [0.8,0.3]
1.伯努利似然:
![]()
2.交叉熵损失:
![]()
总结:
逻辑回归解决分类问题,把线性回归输出作为逻辑回归的输入
逻辑回归的优化操作
1.极大化似然函数
2.最小化交叉熵损失
三、逻辑回归模型实例
需求
癌症分类预测,对699条样本,共11列数据
(1)第一列用于检索的id,后9列 肿瘤医学特征,最后一列肿瘤类型的数值
(2)包含16个缺失值,用“?”标出
(3)2表示良型,4表示恶性
from sklearn.linear_model import LogisticRegression #逻辑回归模型
from sklearn.model_selection import train_test_split #数据集切分
from sklearn.preprocessing import StandardScaler #标准化
from sklearn.metrics import accuracy_score #模型评估
import pandas as pd
import numpy as np
1.获取数据
data = pd.read_csv("../机器学习/breast-cancer-wisconsin.csv")
2.数据处理 缺失值
# 2.1用np.NaN
data = data.replace("?",np.nan)
# data.info()
# 2.2删缺失值
# 参1: axis=0 (按行删) 参2:是否影响原数据
data.dropna(axis=0,inplace=True)3.特征工程
# 3.特征工程
# 3.1 获取特征列 和 目标值
# iloc [行,列] 切片
# 第一列 到 倒数第二列
x_data = data.iloc[:,1:-1] #所有行,第1 ~ -1列
# 3.2取标签
y_target = data.iloc[:,-1] #获取最后一列
# 3.3 已有 x 特征集,y 标签级
# 随机种子 18 优于其他
x_train, x_test, y_train, y_test = train_test_split(
x_data,
y_target,
test_size = 0.2,
random_state = 18
)
# 3.4 数据集相差不大,可以不用做标准化,但为了让步骤完整。坐一下
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)4.模型训练
# 4 模型训练
model = LogisticRegression()
model.fit(x_train, y_train)5.模型预测
# 5.模型预测 x_test 预测集特征
y_predict = model.predict(x_test)
print(f'预测值{y_predict}')6.模型评估
# 6.模型评估
# model.score 模型自带
print(f'准确率:{model.score(x_test, y_test)}')
print(f'准确率:{accuracy_score(y_test, y_predict)}')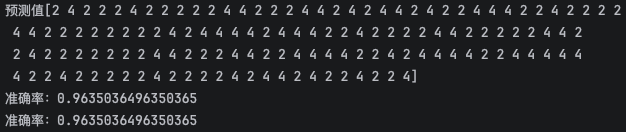

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 5
5 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)