Qwen3-8B 故事生成与故事问答微调方案
Qwen3-8B 故事生成与故事问答微调方案
目标是把 TinyStories 的叙事流畅性,WritingPrompts的长故事生成与 FairytaleQA 的阅读理解能力融合在一个模型里,让 Qwen3-7B 学会“会讲故事”和“能回答故事问题”。实际硬件是单张 RTX 3090/4090,训练策略需要优先保证可落地。
考虑实际硬件情况,采用 LoRA而不是全参数微调。这样可以把显存压力降到可控范围,同时保留较好的任务能力。训练框架采用LLamaFactory,操作系统与驱动环境保持在 Ubuntu 22.04 与 CUDA 12.1 及以上。对于单卡场景,最重要的不是把单步 batch 设得很大,而是保证有效 batch 和序列长度匹配任务特征,并让训练稳定收敛。
数据分析结论与任务定位
TinyStories 是由微软研究院推出的一个合成数据集(GPT4.0和GPT3.5合成),专门用于研究和训练极小规模语言模型,其特点是仅使用 3 到 4 岁儿童能理解的基础词汇(约 1500 个单词),十分适合项目中面向幼儿及小学生的故事生成任务。
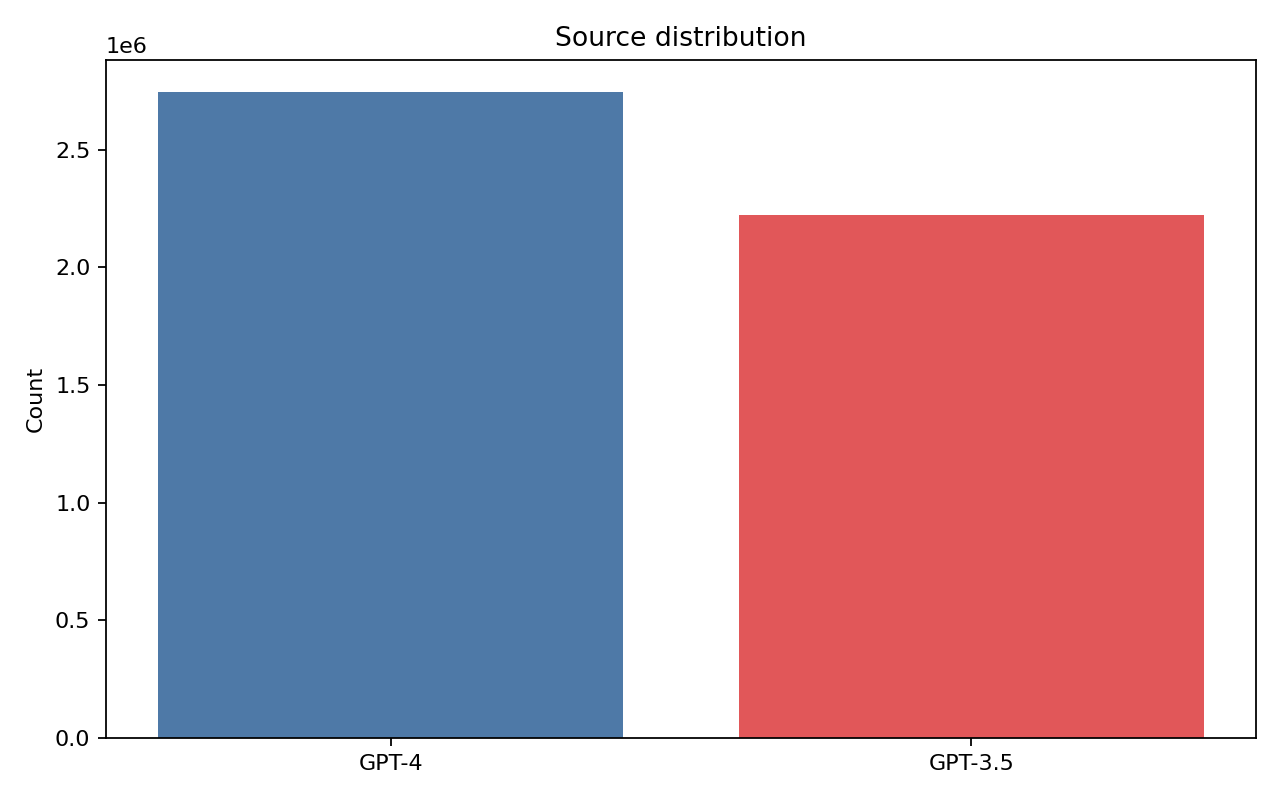
且TinyStories “叙事模板丰富、语言风格统一(json格式)、规模大”,非常适合作为故事生成能力的主干数据,经过数据分析统计显示包含 4,967,871 条样本,约 6,650.58 MB,考虑到微调的硬件限制,微调如此大的数据量是不可能的,在微调的时候会进行采样。数据来源由 GPT-4 与 GPT-3.5 混合生成,长度分布呈现典型长尾。这个数据对语言流畅性、段落衔接和基础情节结构特别有帮助,但其监督信号更偏“生成”,对证据对齐与问答可解释性的支持相对有限。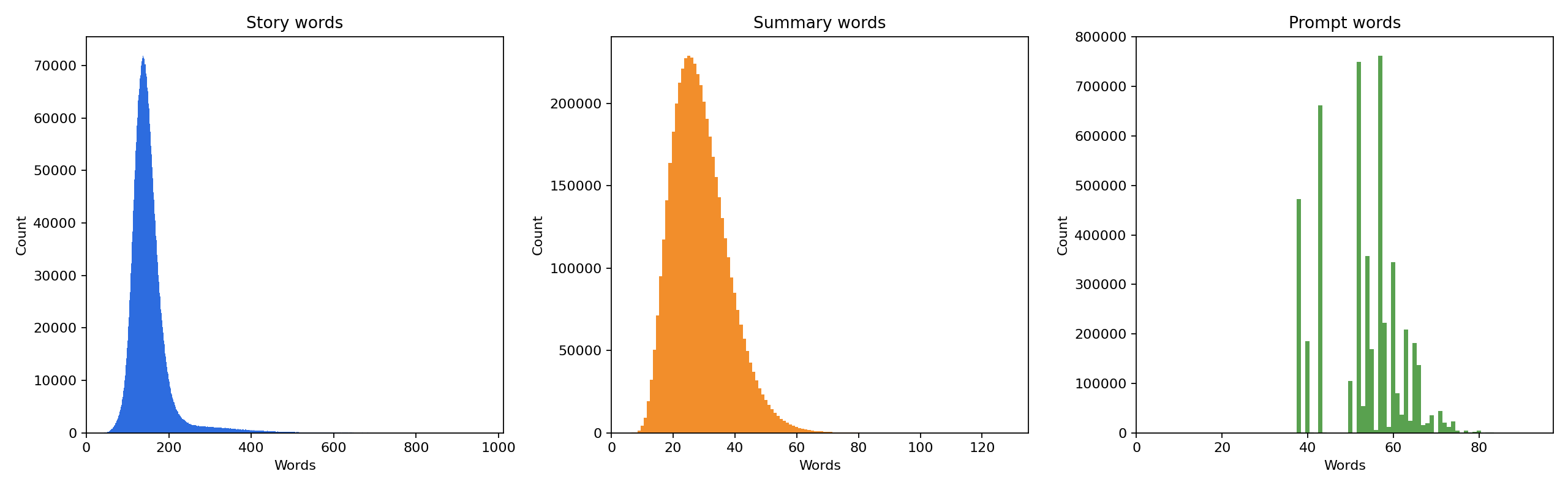
FairytaleQA 是在自然语言处理和人工智能教育领域非常经典的高质量数据集。
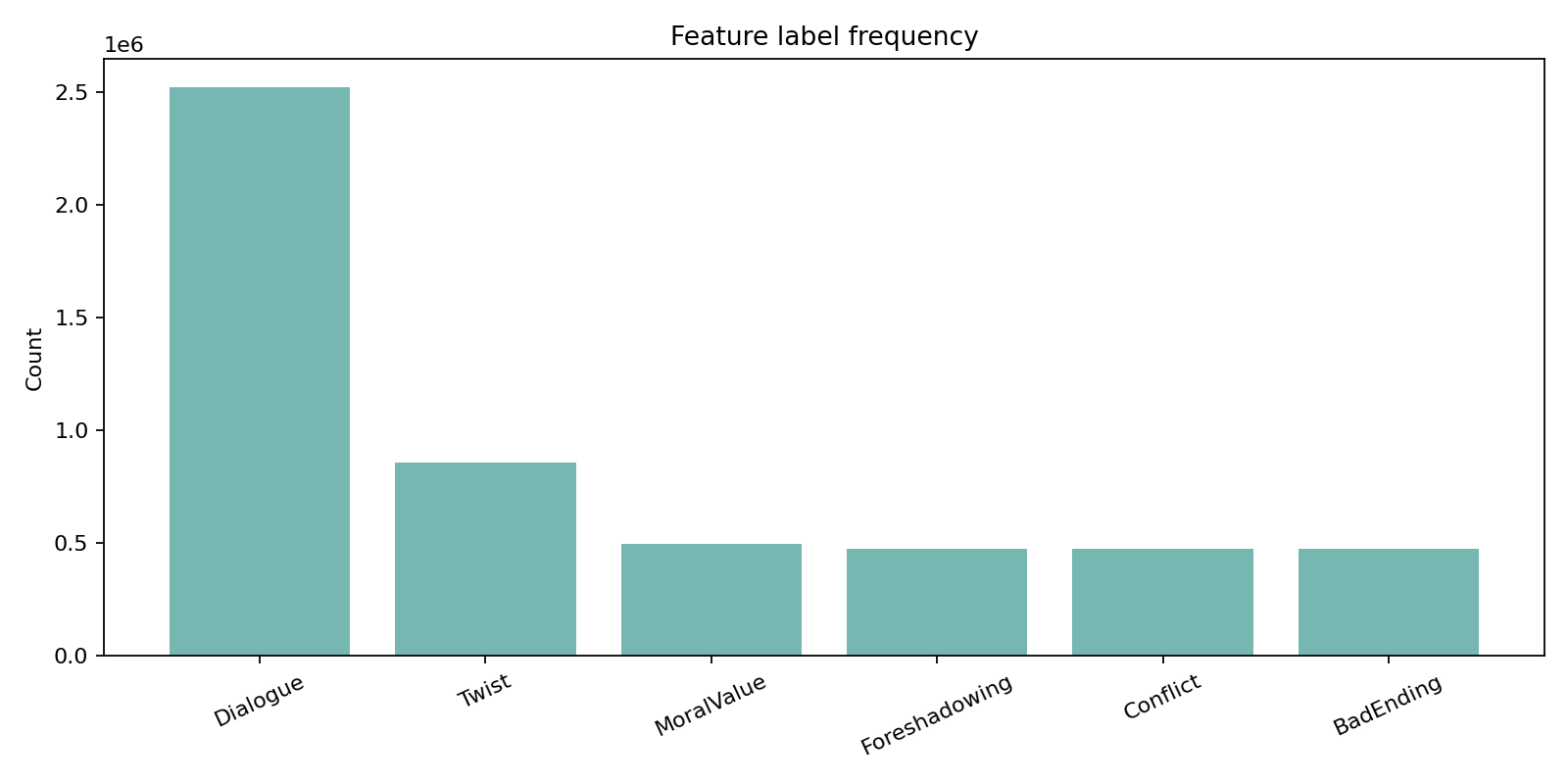
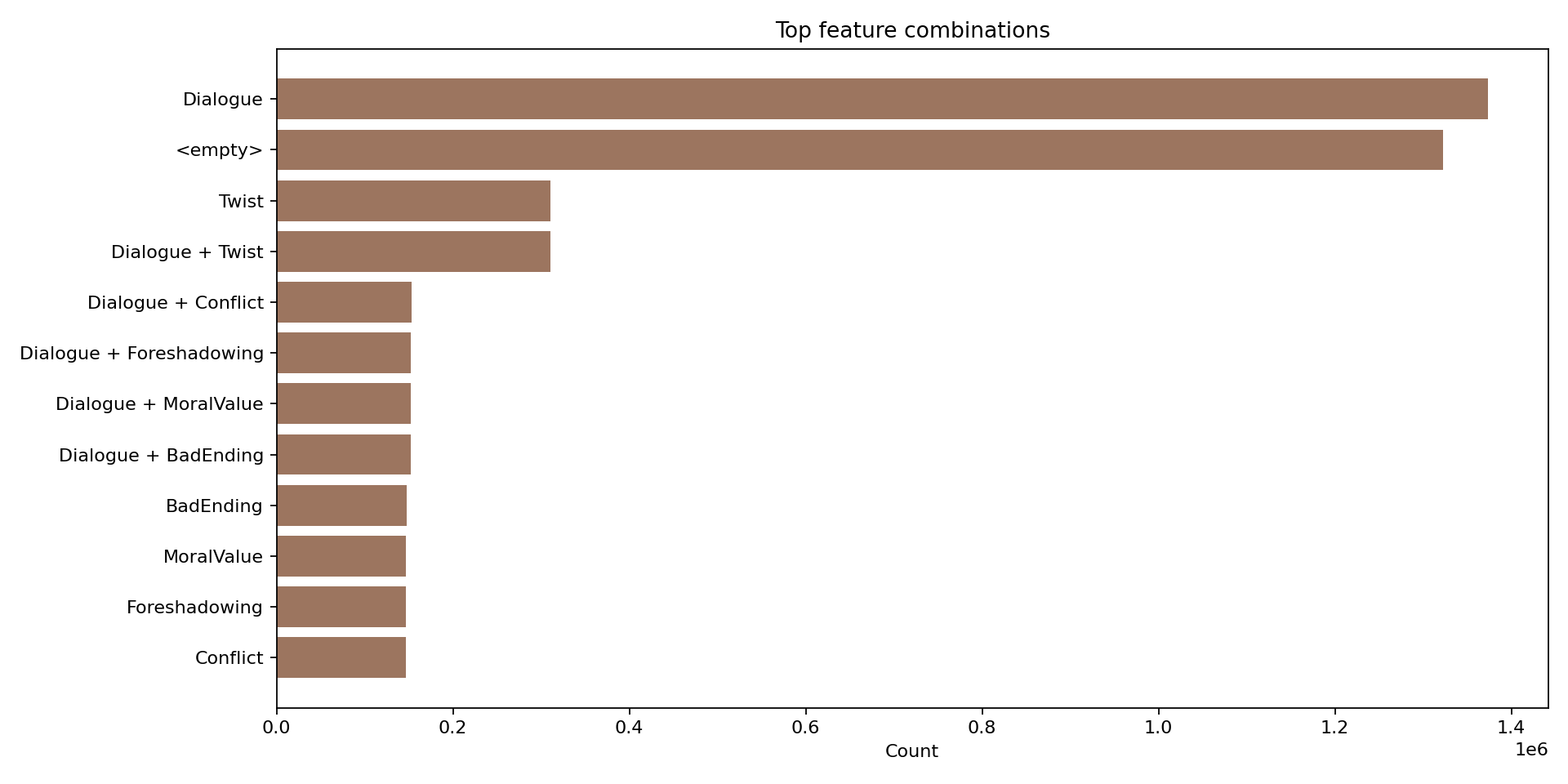
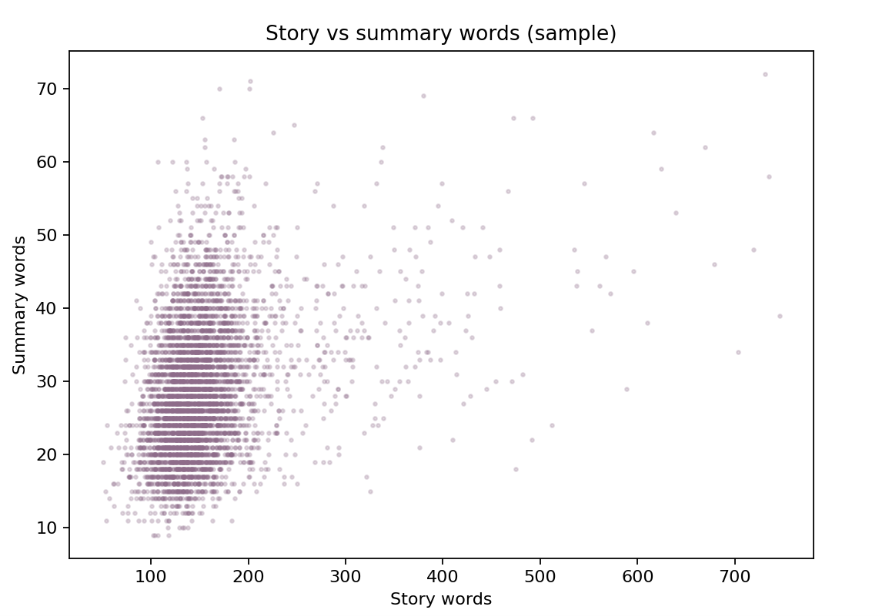
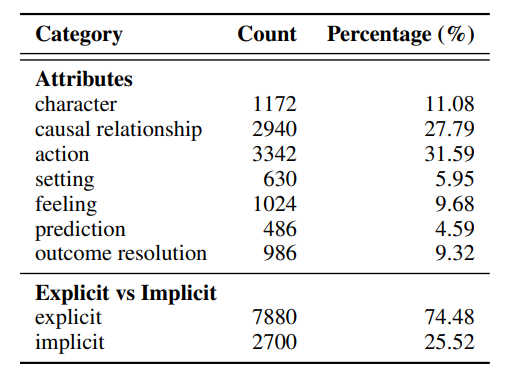
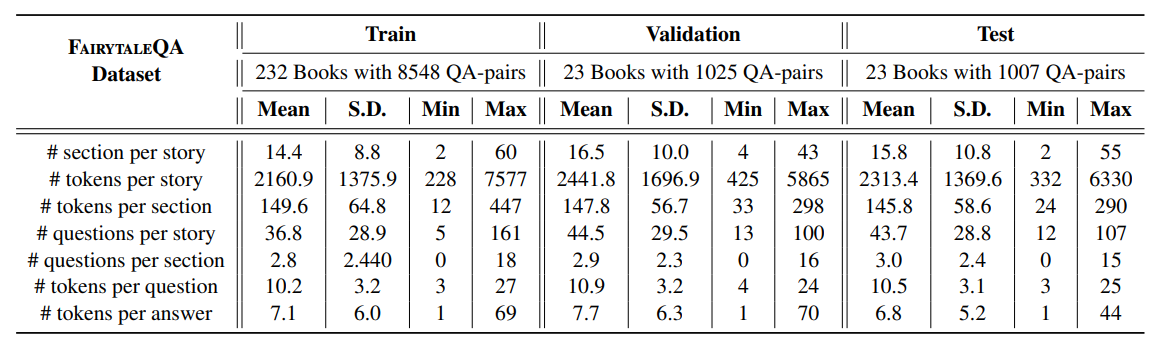
FairytaleQA 的价值在于“结构化监督强、问题类型清晰”。它不是单 JSON,而是多表 CSV 关系结构,问题通过 cor_section 映射到故事 section,并附带 local-or-sum、attribute、explicit/implicit 等教育学标签。全量统计为 278 篇故事、10,580 QA、4,095 sections、25,382 sentences,特别适合增强模型的因果理解、跨段信息提取与问答可解释性。
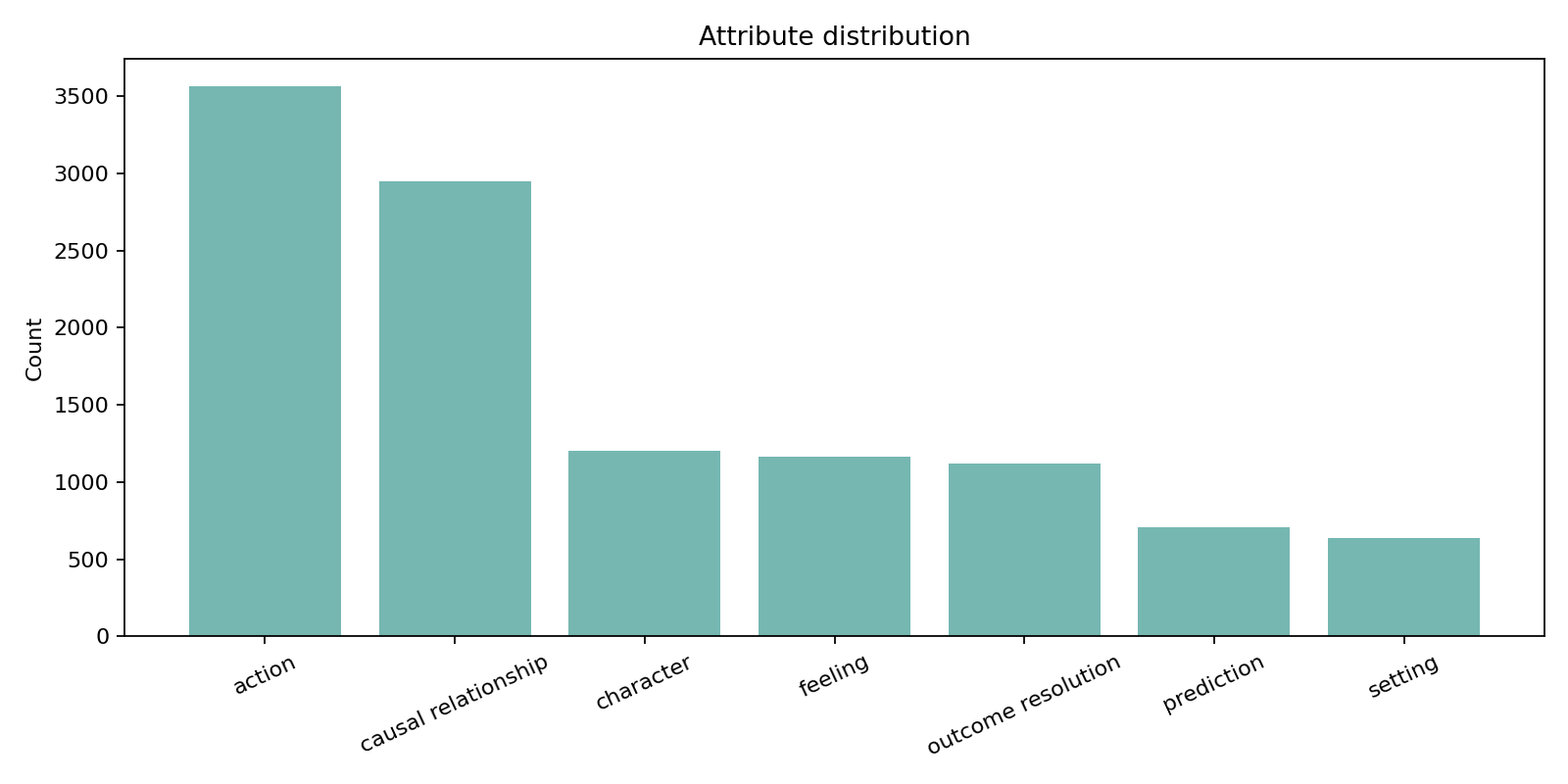
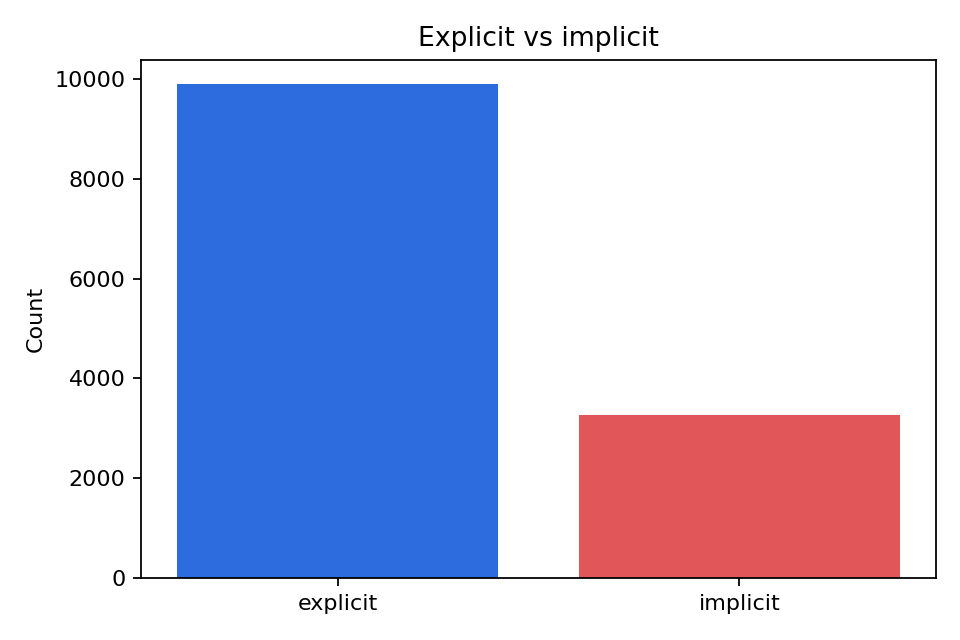
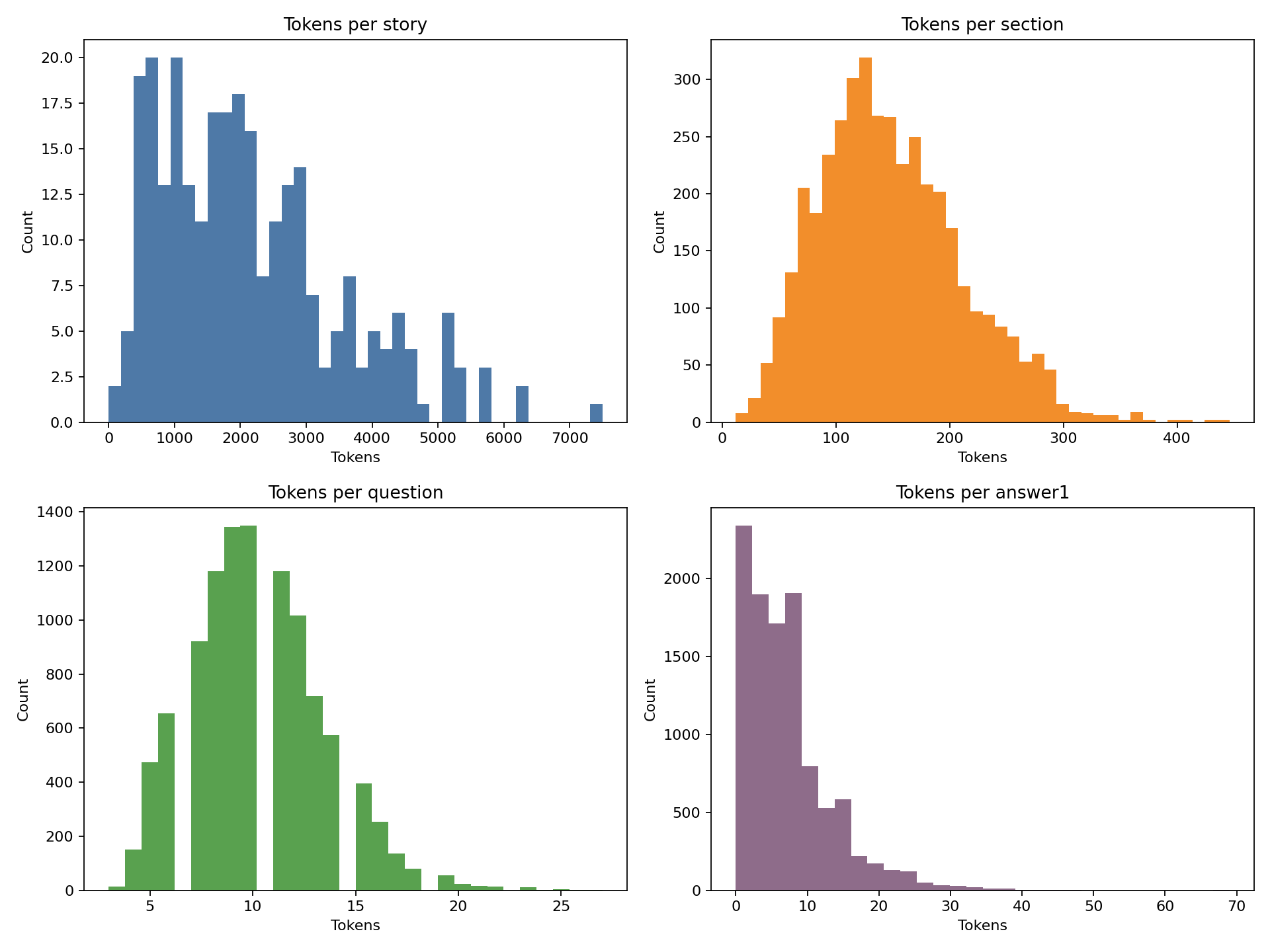
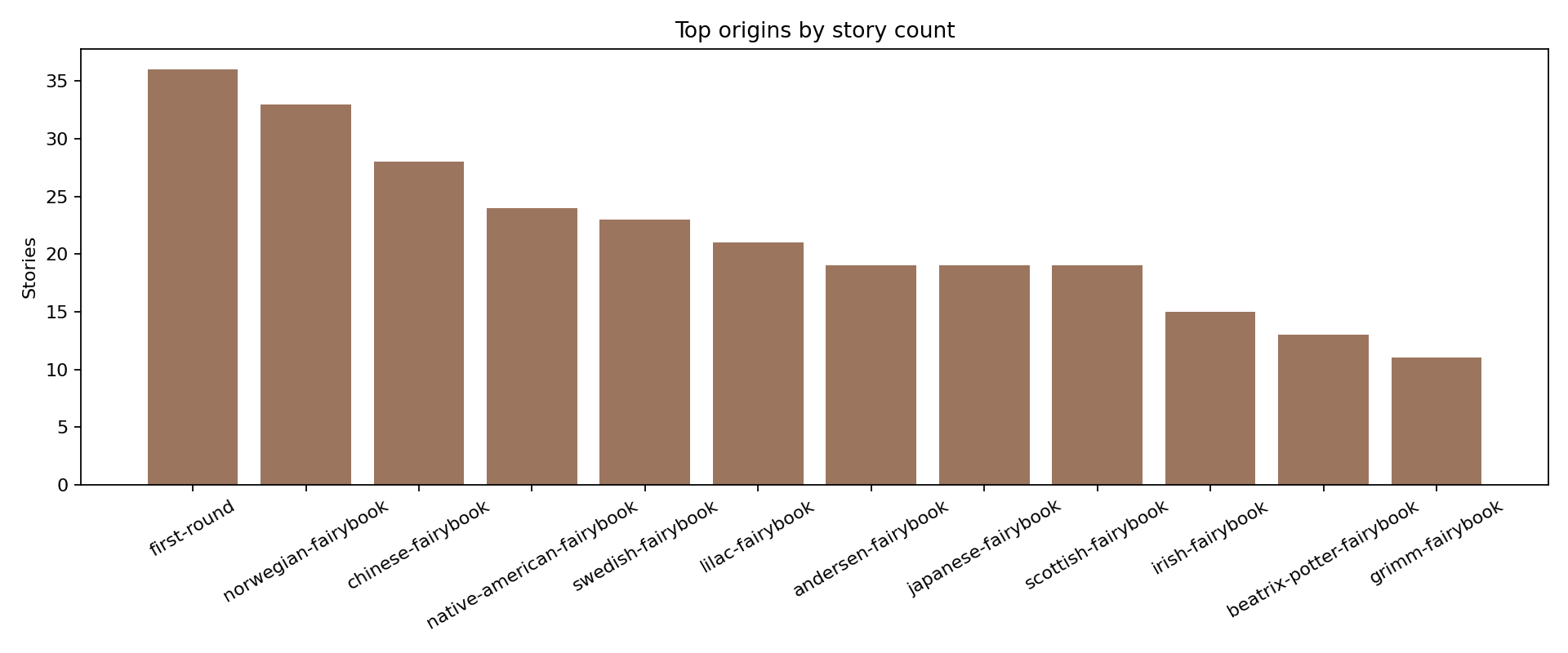
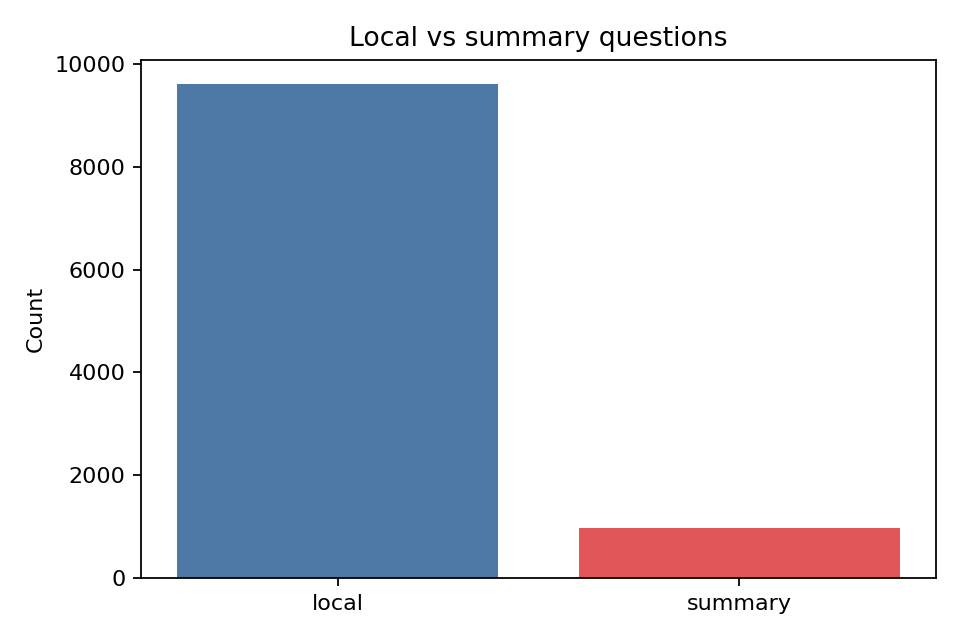
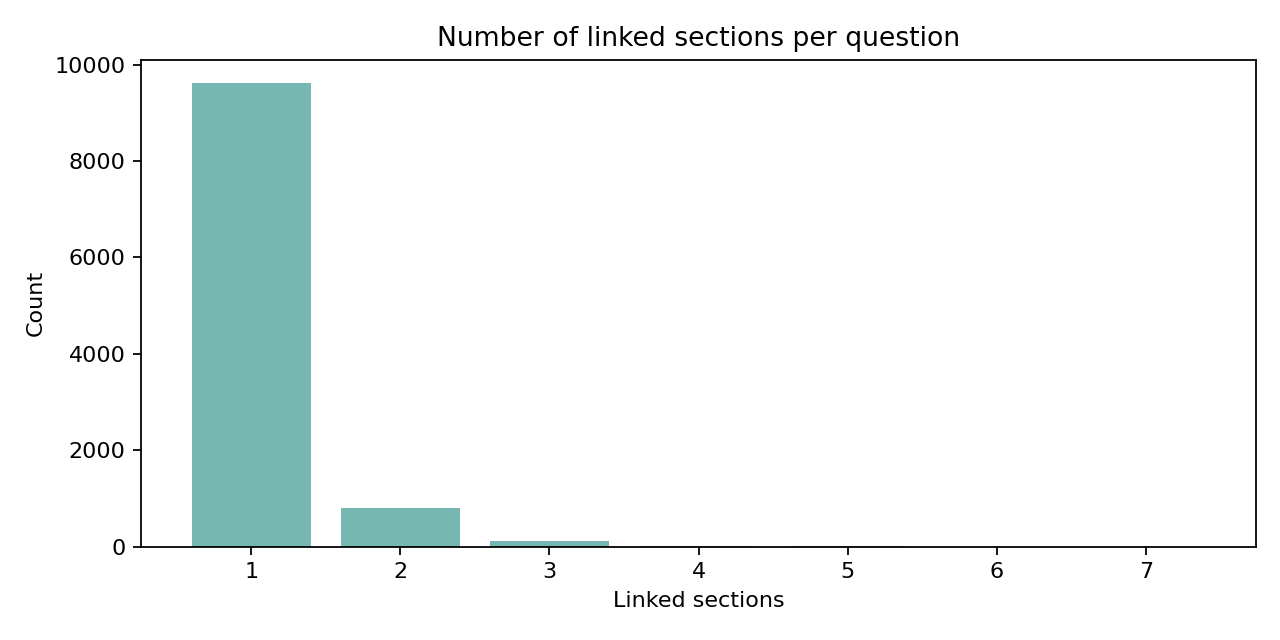
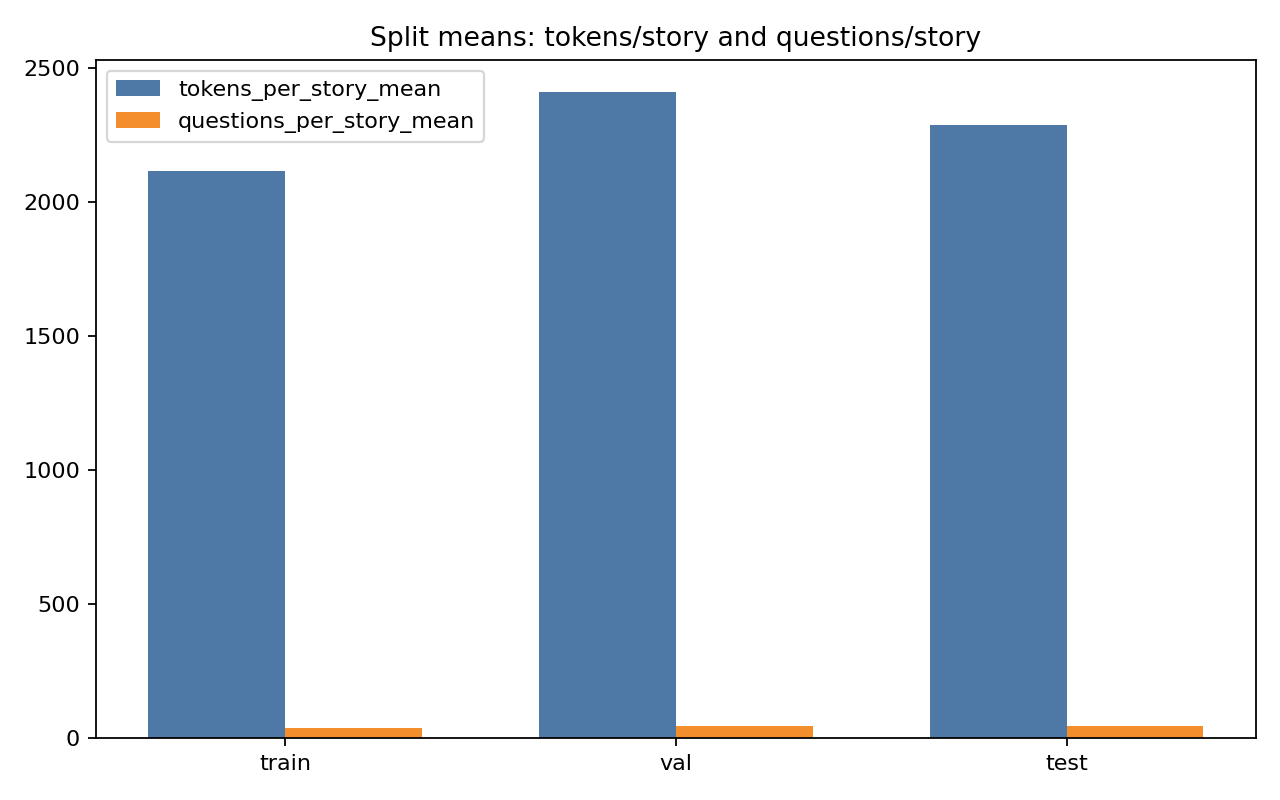
下列三张图是论文中的统计结果,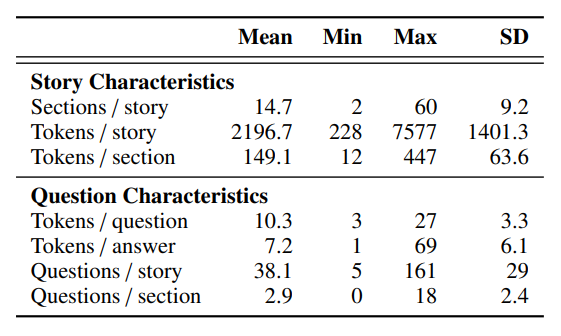
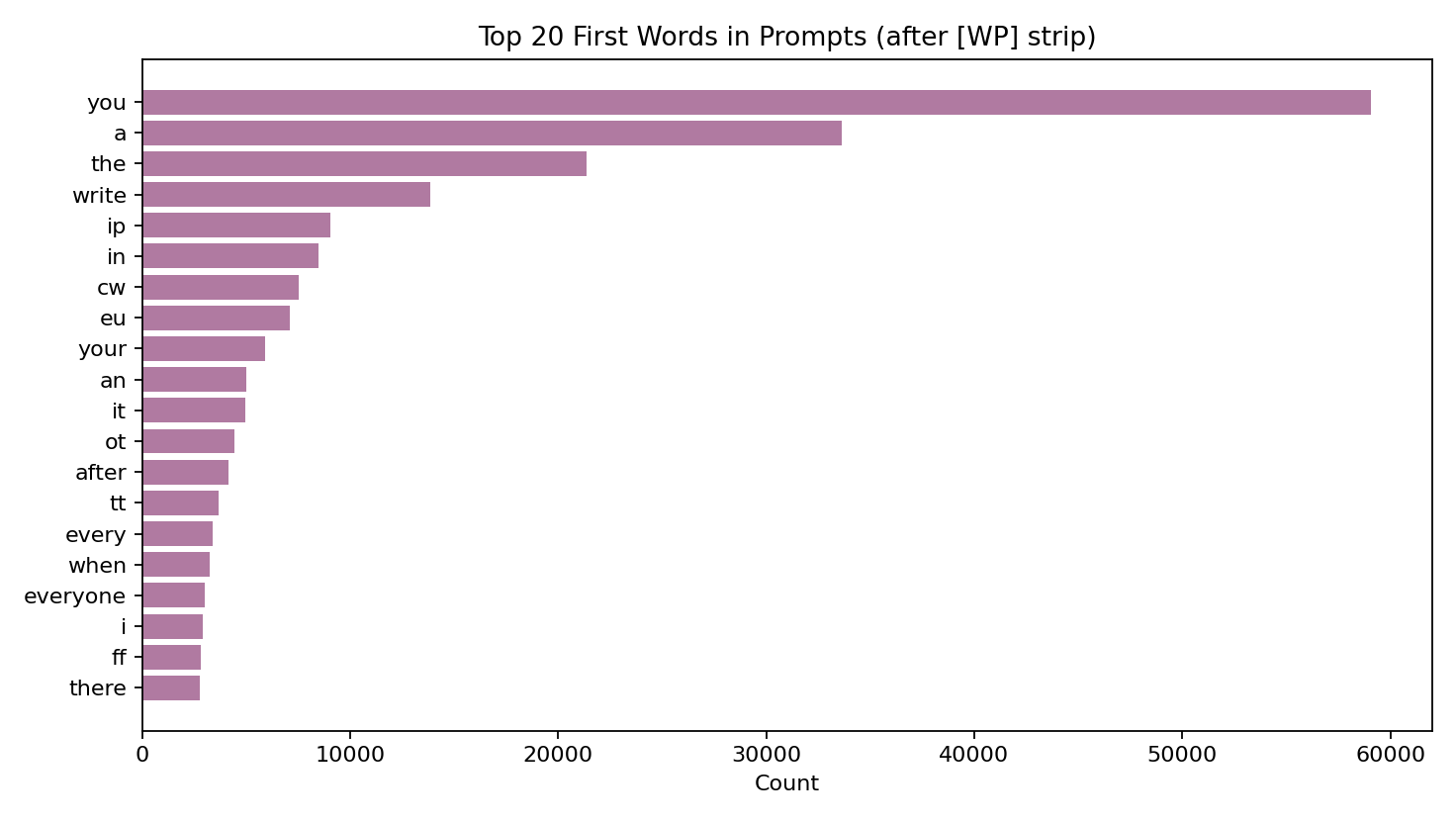
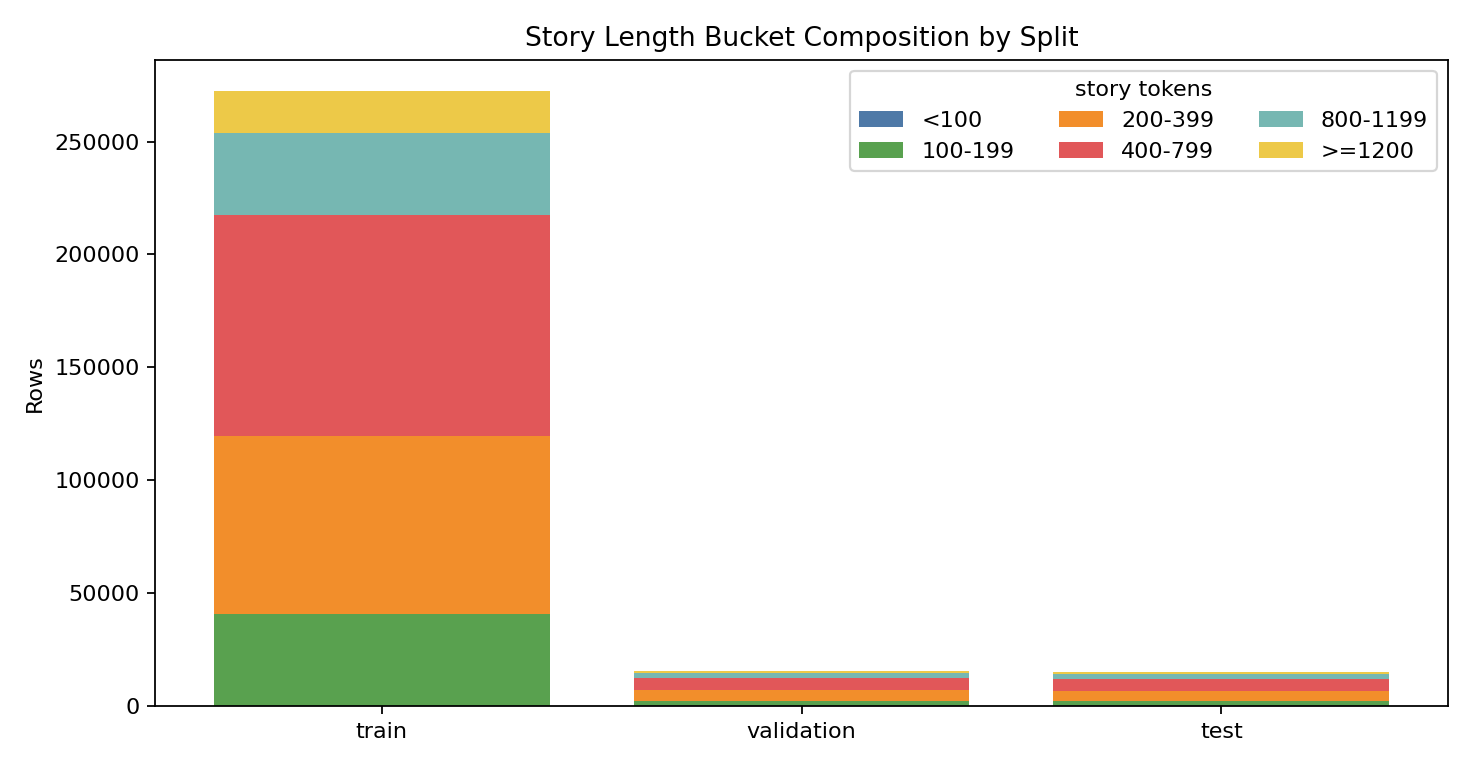
WritingPrompts 是故事生成领域最经典的大规模数据集之一,特别适合补足 TinyStories 在复杂叙事上的短板。它的核心特点是“短提示词驱动长故事生成”,能够显著提升模型在长程情节展开、角色一致性和段落级推进上的能力。本地全量统计显示该数据集共 303,358 条样本(train 272,600 / validation 15,620 / test 15,138),考虑到硬件条件,利用如此大的数据量进行微调也是不现实的,会进行采样,且 split 间长度分布稳定。
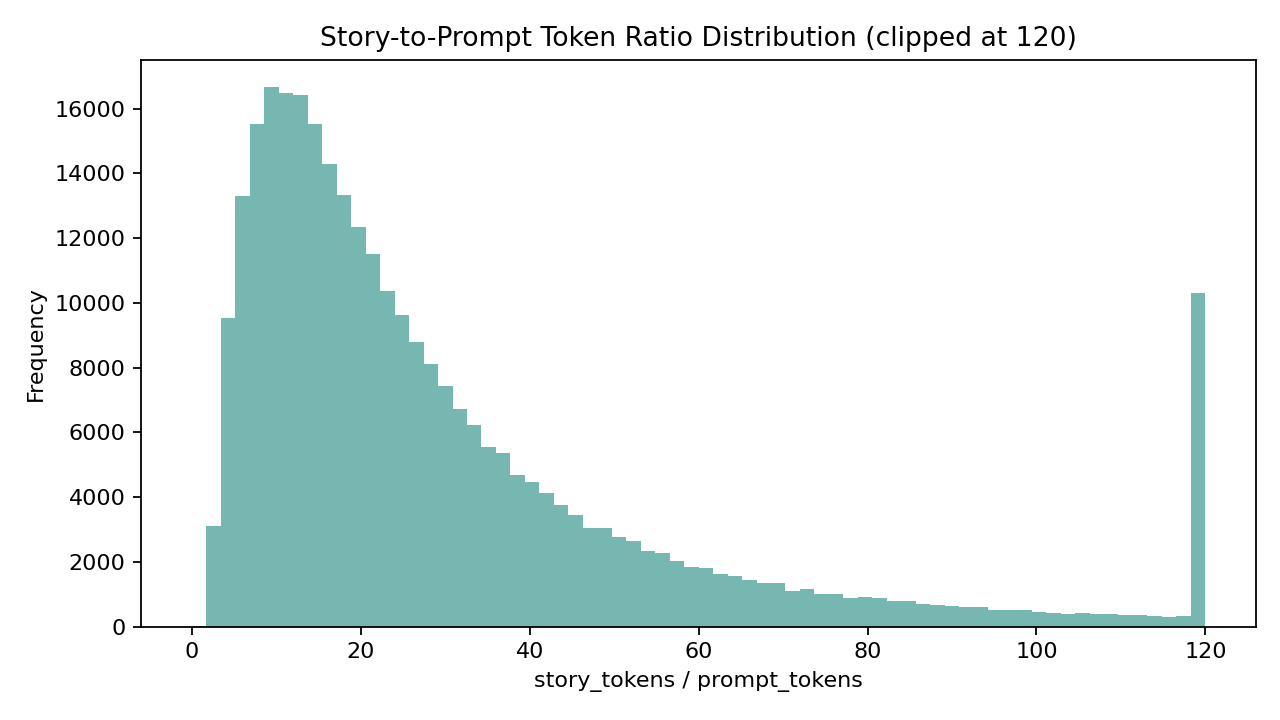
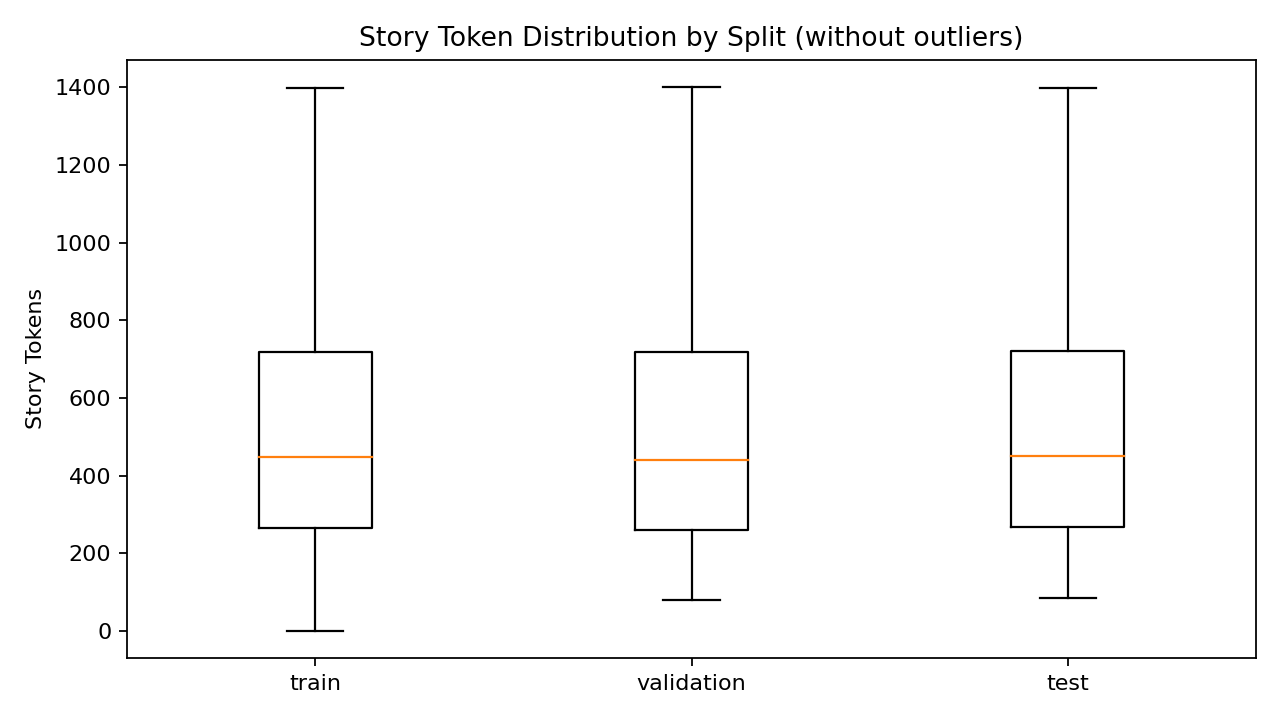
从统计结果看,prompt token 均值为 23.53(中位数 22,P95 48),story token 均值为 543.88(中位数 448,P95 1316),story/prompt 长度比均值达到 33.29。这说明数据集天然包含“高压缩提示 -> 高展开叙事”的监督信号,适合训练模型从极短输入生成结构完整的中长篇文本。
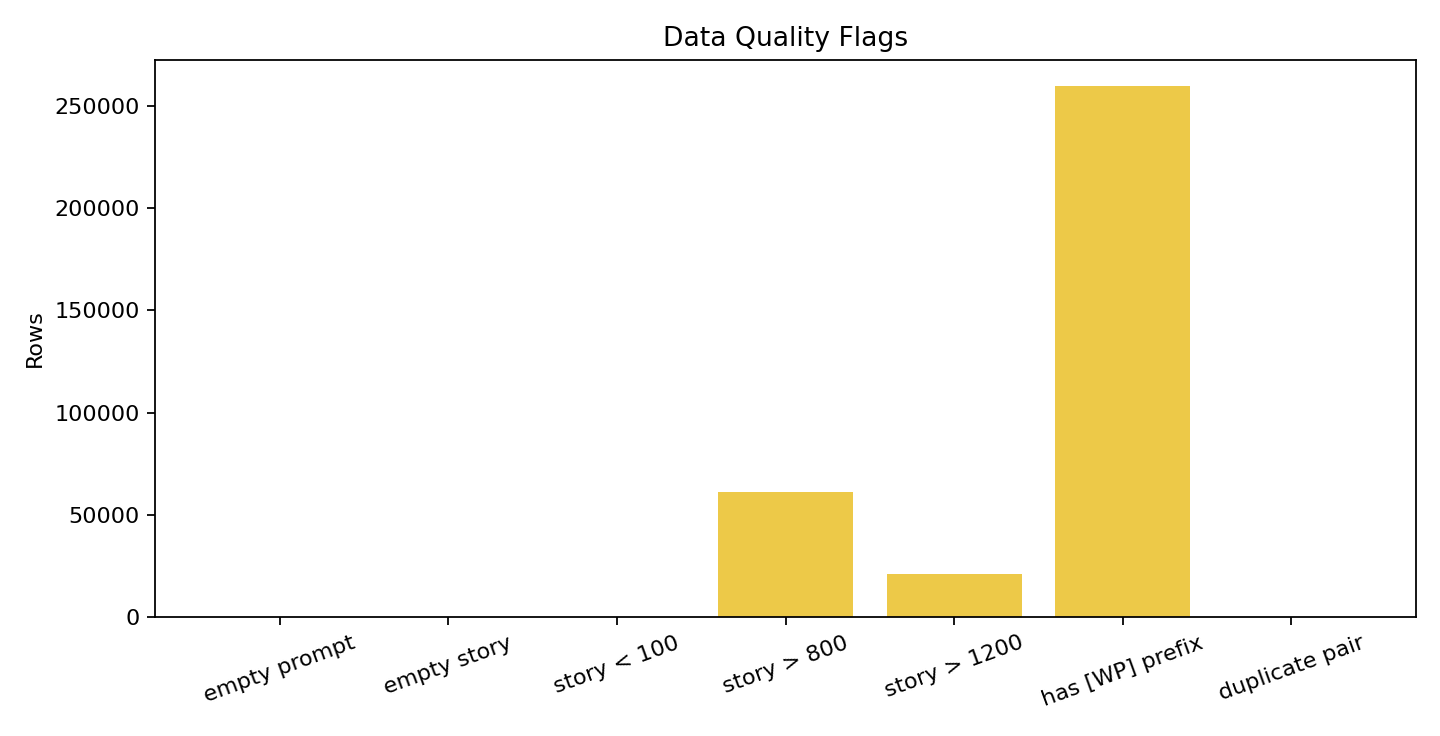
质量层面,空样本几乎为 0(empty prompt/story 都是 0),但长尾明显(story >800 token 共 61,329 条,>1200 token 共 20,969 条),并且 prompt 中 [WP] 前缀占比较高(259,408 条)。因此清洗策略应重点放在前缀归一化、长度分桶训练和去重控制上,而不是激进删除长文本。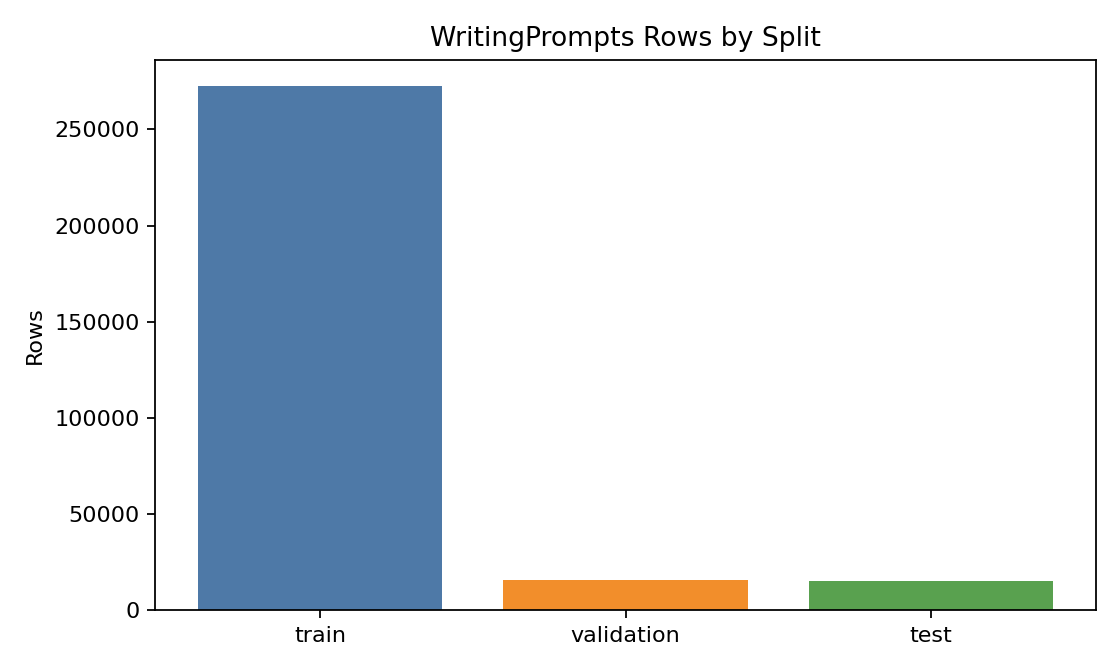
数据构造
数据格式统一成指令微调 JSONL,使用 instruction、input、output 三段。TinyStories 的样本构造:instruction 使用相关的任务描述,input 为具体的要求(即为数据集中的prompt),output 放 story。WritingPrompts 的样本构造:instruction 固定为“根据提示写连贯故事”的任务描述,input 放清洗后的 prompt,output 放 story。FairytaleQA 的样本构造强调“证据片段 + 问题 + 标准答案”,其中 input 放相关 section 文本,instruction 放问题本身或任务指令,output 放答案。
在训练配比上:
- 阶段A(叙事基底):TinyStories 单独训练,建立简洁稳定的基础叙事风格。
- 阶段B(复杂故事增强):引入 WritingPrompts,与 TinyStories 按 4:6 到 5:5 混合,重点拉升长故事生成能力。
- 阶段C(问答理解对齐):加入 FairytaleQA,推荐
TinyStories:WritingPrompts:FairytaleQA = 3:5:2或4:4:2,提升证据对齐与可解释问答能力。
综合考虑单卡资源与微调的时间成本,TinyStories 进行采样,WritingPrompts 也进行采样,FairytaleQA 使用全部高质量 QA。通过分阶段混训可以避免“只会讲长故事但不擅长回答问题”或“问答变强但故事风格变硬”的互相覆盖问题。
微调配置可行性评估(单卡 3090/4090)
LoRA/QLoRA 路线在单卡上是可行的,把单卡 micro batch 设在 1 到 4,根据 max_length 动态调整,然后通过梯度累积实现目标有效 batch。对于 FairytaleQA 的长上下文问答,max_length 设 2048 ;如果显存紧张,先用 1536 进行主训练,再用少量 2048 样本做续训对齐。
从超参数角度,lora_rank 32 或 64 都可以,先用 r=32 做基线,再看验证集增益决定是否升到 64。lora_alpha 128、learning_rate 1e-4、epochs 3 ,但第二阶段(FairytaleQA 或混合微调)把学习率再降一级,例如 5e-5,防止覆盖第一阶段学到的叙事能力。
损失函数
核心损失仍是自回归交叉熵:
L=−1N∑i=1NlogP(xi∣x<i) L = -\frac{1}{N}\sum_{i=1}^{N}\log P(x_i|x_{<i}) L=−N1i=1∑NlogP(xi∣x<i)
在 SFT 中,label masking 是必要机制。instruction 与 input 不计 loss,只有 output 区间参与损失计算,这样模型学的是“回答能力”和“生成目标风格”,而不是复述提示词。Label smoothing 可以作为可选项保留,但先不开或从较小值开始(如 0.05),先观察是否真的带来多样性收益再启用更强平滑。
对于PPL 目标,做法是看相对趋势:验证集 loss 是否稳定下降、不同子任务(生成与问答)是否同时改善、是否出现明显模式坍缩或答非所问。
评估
评估从两方面看。一方面是自动指标: 故事生成看 PPL、distinct、长度稳定性;问答任务看 ROUGE-L、BLEU-4 以及答案覆盖率。另一方面是人工评估: 重点检查故事是否有完整叙事,问答是否基于给定片段而非幻觉补写,隐式问题是否能给出可追溯理由。
部署与推理
部署阶段先合并 LoRA adapter,再根据场景选择推理后端。考虑到在服务器场景中直接利用 vLLM,本地快速验证可以用 Ollama或者LLamaFactory。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 11
11 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)