常见面试题目集合
栈和队列、列表、链表区别是什么
栈和队列是操作受限的线性表。
列表和链表是存储方式。
栈(Stack):先进后出(LIFO),只能在一端插入删除。
队列(Queue):先进先出(FIFO),一端进队,另一端出队。
数组/顺序表(List/Array):内存连续存放,支持随机访问(通过下标查找O(1)),插入删除要移动元素,慢O(n),大小固定(或动态扩容,但仍然连续)。
链表(Linked List):内存不连续,靠指针连接,不支持随机访问(查找需要遍历O(n)),插入删除只用改指针,快O(1)。
Mysql的底层是用的什么数据结构
用的B+树。
B+树的优点:
- 多路平衡、高扇出,树高通常3-4层,磁盘I/O少。
- 非叶子节点仅存索引键与指针,叶子节点存数据或主键,空间利用率高。
- 叶子节点双向链表串联,范围查询、排序高效。
B树与B+树
普通二叉树:每个分叉只存一个值,数据多,树就很高,磁盘读取次数多,速度就慢。
B树:一个节点中存多个值。所有节点都存数据,树很矮,磁盘I/O少;但是查询不方便,需要遍历树。
比如:3阶B树,每个节点最多3个关键字。
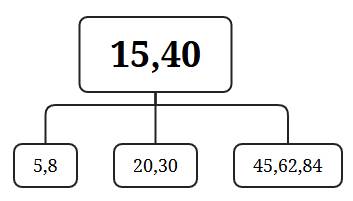
B+树:在B树的基础上,每个节点是双向链表。
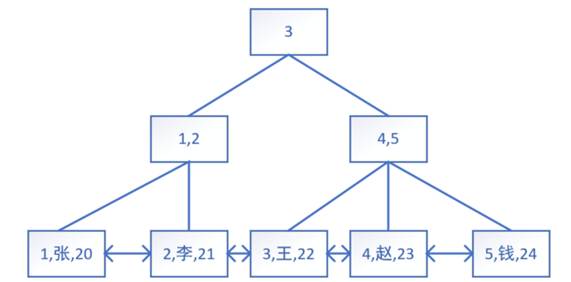
B+树特点:
- 非叶子节点只存索引(主键id),不存真实数据,树更矮
- 只有叶子节点存真实数据
- 所有叶子节点用链表串起来,查询更快,顺着扫就可。
*注意:B+树使用自增BigInt的ID查询最快,最稳的方法是UUID单独字段+binInt唯一索引,BigInt主键可以使用自己写的雪花ID(符号位+时间戳+机器ID+序列号),可以实现有序递增、分布式和性能高的特点。
数据库分库和分区
分区:MySQL自带的功能,把单表根据时间、id等条件进行内部分区,查询更快,SQL不用改,但是数据量大或者并发高会导致卡死。适合数据量大但并发不高的表,如日志、历史记录。
分库:把数据分成不同类型,存在不同数据库,简单的分库是物理在一起,逻辑分开,分布式分库是把不同的数据放不同的机器上。
分库的话,C++使用MyCat(国产最流行)、ShardingSphere-Proxy(Apache顶级项目),Java使用ShardingSphere-JDBC,在代码里面只用连接中间件的IP,正常写sql语句即可。
MySQL 索引的最左原则
最左原则:联合索引(a,b,c),必须从左边开始连续使用,中间不能跳过否则会索引失效。
如以下才可以匹配成功:
select * from table where a = '1';
select * from table where a = '1' and b = '2';
select * from table where a = '1' and b = '2' and c='3';*注意:
(1)查询条件顺序不影响,比如a=’1’ and b=’2’和b=’2’ and a=’1’ 效果一致。
(2)范围查询和运算、函数等会中断后面的索引,比如where a= ? and b > 18 and c = ?,c的索引被中断了。
InnoDB 和 MyIsam 引擎的区别?
InnoDB(默认):索引与数据物理聚簇,主键索引(聚簇索引)的叶子节点存整行数据;二级索引叶子节点存主键。均为B+树,空间索引用R树。InnoDB的普通索引是非聚簇索引,要查主键再索引,又叫做回表。
MyISAM(legacy):索引与数据分离,所有索引(含主键)均为非聚簇,叶子节点存数据物理地址,统一用B+树。查数据,不管是主键还是普通索引,至少查两次才能拿到数据。
Legacy:老旧的,冷古董,仅兼容旧系统。
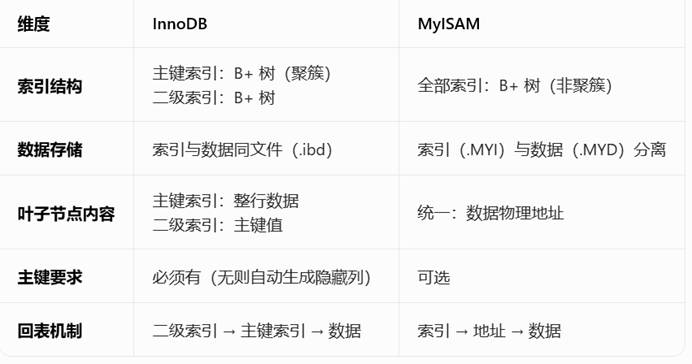
聚簇索引:目录和内容在同一页。
非聚簇索引:目录只告诉页码,内容在其他页码。
适合的场景:
InnoDB:需要增删改多,并发高,要安全、要事务的业务系统。
MyISAM:几乎不修改、大量查询、追求静态数据。
|
数据库引擎 |
适合场景 |
适合原因 |
|
InnoDB |
电商订单、支付 |
|
|
用户系统、后台管理 |
||
|
论坛、社交、内容平台 |
||
|
MyISAM |
系统日志(只插入不更新) |
|
|
文章、新闻、商品详细 |
||
|
统计报表、历史数据 |
有哪些优化数据库性能的方法?
- sql语句优化
- 避免select *
- 避免隐式类型转换
- 避免在索引列使用函数和运算
- 避免深分页(limit 10000,10)
- 减少join,特别是跨库join
- 避免子查询(select套select)
- 避免not in/!=/is not null(容易造成索引失效)
- 避免使用filesort,使用group by/order by排序
- 索引优化
- 给高频查询键建立联合索引
- 等值字段放前面,范围字段放后面
- 使用覆盖索引(在联合索引基础上,用explain查select语句,Extra字段出现Using index就是覆盖了)
- 删除重复、冗余、未使用的索引
- 区分度低的字段不建索引(性别,状态,数据多直接全表更快)
- 禁止左模糊(like ‘%abc’)
- 单表索引控制在3-5个
- 表结构优化
- 尽量使用Not Null,设置默认值
- 大字段拆分(text/blob单独建子表存,使用时用join)
- 冷热数据分离(不常用的字段放子表)
- 单表数据控制在2000w内,超过就分表
- 数据库配置优化
- 调整连接数(max_connections),最佳数量=cpu核心数*2*磁盘类型系数,如8核cpu推荐32~64连接
- 调整缓冲池(innodb_buffer_pool_size)到物理内存的50%~70%
- 调整日志策略,减少磁盘I/O
- 开启查询缓存
- 调整日志大小(innodb_log_file_size)
- 关闭不必要的二进制日志
- 引擎事务优化
- 业务表最好使用InnoDB
- 事务尽可能小
- 避免锁等待、死锁
- 降低事务隔离级别
- 数据库架构优化
- 读写分离(主库写,从库读)
- 多级缓存
- 分库分表
- 冷热分离
- 异步化
- 禁止高频实时统计
- 索引和慢查询治理
- 开启慢查询日志
- 使用explain分析执行计划
- 定期优化表、分析碎片
- 硬件与部署优化
- 使用SSD
- 提高内存
- 分盘存放(系统、数据、日志分开)
如何定位慢查询?
查看是否打开慢查询日志:
show variables like 'slow_query_log'; --on=打开
show variables like 'long_query_time'; --long_query_time=1 超过1秒就算慢查询
show variables like 'slow_query_log_file'; --日志存储位置没有开的话,打开:
set global slow_query_log = 1;
set global long_query_time = 1; -- 超过1秒记录
set global log_queries_not_using_indexes = 1; -- 没走索引也记录log里面的信息:慢查询语句、执行时间、哪个库、哪个用户执行的。
使用mysqldumpslow分析,结果按照时间排序,最慢的排前面:
mysqldumpslow -s t /var/lib/mysql/slow.log查出来后,使用explain看优化方向:
explain select * from user where name='张三';
- type=ALL:全表扫描,需要加索引
- extra=using filesort:排序太慢,使用group by/order by并使用联合索引
- extra=using temporary:用了临时表,性能差
临时表MySQL自动创建:union/union all一定会有临时表;group by自动没有索引;order by+group by字段不一致;distinct+order by不同字段。
临时表:mysql算不出来,把数据放到临时的表里面进行分组排序操作。
MySQL 支持行锁还是表锁?分别有哪些优缺点?
Mysql支持行锁和表锁,以行锁为主,因为现在基本使用InnoDB,InnoDB支持行锁+表锁,默认是行锁,MyISAM引擎只支持表锁,但是现在业务不怎么用,太老了。
表锁(table Lock):锁整张表,开销小,加锁快,不会出现死锁,并发能力极差。没命中索引,全表扫描时会自动升级成表锁。
行锁(Row Lock):只锁某一行数据,加锁慢,开销大,可能出现死锁,并发能力强。必须命中索引,否则会退化成表锁。
多表查询
- inner join

- left join: 以左表为主,全部显示;右表匹配不到就显示 NULL

- group by:一对多关系联表会出现数据重复,使用
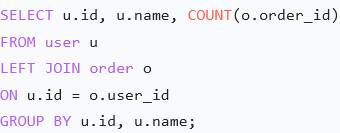
- full join:左右表全部保留,匹配不上的一边填 NULL
- 子查询
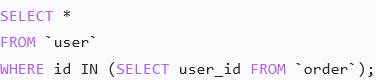
- Union/union all: 把两条独立查询的结果上下拼在一起
*UNION:自动去重,慢一点
*UNION ALL:不去重,更快,推荐用
SQL常见问题:
- 查询去重distinct
select distinct name from user_table- 分页limit n offset m
select * from user_table limit 10 offset 20- 联表查询user_table u join order_table o on u.id=o.id
select u.*, o.order_no from user u left join orders o on u.id = o.user_id;- 内联 inner join
像交集,只筛选交集部分。
- 排序 order by DESC(降序)/ASC(升序)
SELECT * FROM user ORDER BY create_time DESC;- 查重复数据 group by having
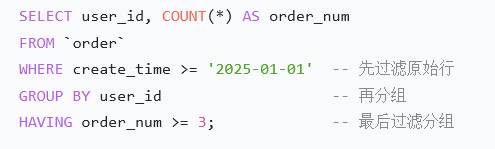
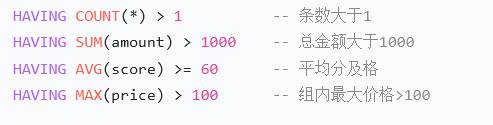
select phone, count(*) from user group by phone having count(*) > 1;having:必须在group by后面,对group by结果过滤。
事务的四大特点:
原子性、一致性、隔离性、持久性
事务隔离级别:
读未提交、读已提交、可重复读、串行化。
Mysql默认可重复读
数据库三大范式:
1NF(列不可再分,一个格子里面只能放一个值)
2NF(非主键字段完全依赖主键,一张表只讲一件事)
3NF(不传递依赖)
作用:减少冗余,避免数据不一致
其他范式:
BCNF(所有决定因素都是码)
4NF(消除多值依赖,一张表一个一对多)
5NF(拆到不能再拆)
3NF理解:如图,班级依赖班级Id,不应该在学生表中
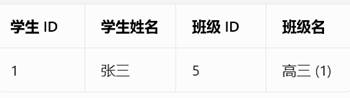
BCNF理解:谁说的算,谁就是主键。
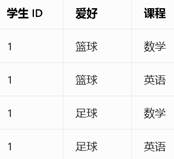
4NF理解:不允许有多个1对多的关系,需要变成[学生 ID, 爱好],和[学生 ID, 课程]
几个读:
- 脏读:读到未提交的数据。
- 不可重复度:同一事务两次查询不一致。
- 幻读:范围查询突然多了/少了数据。
锁:
- 共享锁(读)
- 排它锁(写)
读写互斥,写写互斥,保证并发安全
索引是什么,作用是什么
索引就是给数据库加目录(B+树目录,sorted排序的树形结构),方便查找。
但是写入慢(insert、update、delete要维护索引树),索引多了会导致优化器选择混乱。
作用:
- 加速查询
- 减少I/O次数
- 通过唯一索引(unique)保证数据唯一性
全文索引(FullText):做关键词搜索的索引,为了解决like “%abc%”模糊查询的,使用match against实现。但是只支持文本类型(char/vervhar/text),只对英文分词友好,中文需要ngram插件配置,数据量大了以后性能一般。
SELECT * FROM article WHERE MATCH(content) AGAINST('手机 电脑');MySQL的drop、delete与truncate的区别
Delete:删除表中的数据,可以删除一行或多行,表结构还在,可以回滚。
Truncate:清空整张表的所有数据,表结构还在,不可回滚,速度极快。
Drop:删除整张表(数据+结构),直接把表从数据库中移除,不可回滚。
计算机网络各层有哪些协议?
OSI七层:
|
层数 |
名称 |
支持协议 |
例子或通俗理解 |
人话翻译 |
|
第七层 |
应用层 |
HTTP、HTTPS、FTP、DNS、DHCP、SMTP、POP3、Telnet、SSH |
浏览器、聊天软件(QQ/微信)、邮箱 |
给人用的协议 |
|
第六层 |
表示层 |
SSL/TLS、JPEG、ASCII、加密格式 |
数据加密、压缩、翻译 |
翻译+加密 |
|
第五层 |
会话层 |
RPC、SQL、NFS |
负责建立连接、保持通话、断开连接 |
建立/管理会话 |
|
第四层 |
传输层 |
TCP、UDP |
负责数据打包 |
发货方式 |
|
第三层 |
网络层 |
IP、ICMP(ping)、ARP、OSPF、RIP |
管ip地址,像地图导航、规划路线 |
Ip地址,找路 |
|
第二层 |
数据链路层 |
以太网、WiFi、MAC 地址、PPP |
管mac地址,像小区快递员,只在小区送货 |
Mac地址,同一局域网传输 |
|
第一层 |
物理层 |
电压、频率、光纤、网线 |
硬件本身,只传0和1的电信号 |
看得见的硬件 |
TCP/IP四层:
|
OSI层数 |
OSI名称 |
TCP/IP层数 |
TCP/IP名称 |
支持的协议 |
|
第七层 |
应用层 |
第四层 |
应用层 |
HTTP、HTTPS、DNS、FTP、SSH |
|
第六层 |
表示层 |
|||
|
第五层 |
会话层 |
|||
|
第四层 |
传输层 |
第三层 |
传输层 |
TCP、UDP |
|
第三层 |
网络层 |
第二层 |
网络层 |
IP、ICMP(ping)、ARP |
|
第二层 |
数据链路层 |
第一层 |
网络接口层 |
以太网、MAC、网线 |
|
第一层 |
物理层 |
TCP 和 UDP 协议的区别?
TCP:可靠,面相连接,慢,有重传/拥塞控制(打电话)。HTTP/HTTPS、文件传输、邮件使用。
UDP:不可靠,无连接,快,不保证到达(发短信、广播)。直播、游戏、DNS查询、视频通话使用。
TCP 为什么需要三次握手和四次挥手?
TCP三次握手:你在,我在,开始
- 客户端问:我能连吗(SYN)
- 服务端答:可以,你能收到吗(SYN+ACK)
- 客户端:收到,开始传(ACK)
TCP四次挥手:我完,等会,我也完,再见
- 客户端:我发完了,要关(FIN)
- 服务端:收到,我还没发完(ACK)
- 服务端:我也发完了(FIN)
- 客户端:收到,断开(ACK)
HTTP 和 HTTPS 协议的区别?
HTTP:明文传输,不安全,默认80端口。
HTTPS:HTTP+TLS/SSL加密,更安全,默认443端口,需要证书,握手耗时长一点,性能略低。
HTTPS握手过程:
- 客户端请求,服务端返回证书(含公钥)
- 客户端验证证书
- 客户端生成随机密钥,用公钥加密发给服务端
- 使用这个密钥对称加密通信
IP与常见协议
IP协议:负责寻找地址和路由,把数据包从一个ip送到另一个ip,只管送到,不管丢不丢。
ARP协议:通过ip找Mac地址,本地有缓存直接用,没有则广播,目标主机单播回复。内网所有设备都可以响应。
RARP协议:Mac地址找IP地址,没有硬盘的机器广播,仅有RARP服务器单播回复,客户端配置IP。必须依赖专用RARP服务器,已淘汰,换成DHCP。
DHCP协议:动态主机配置协议,自动给局域网设备分配地址(ip/子网掩码/网关/DNS)。
工作流程:
Discover(发现)->Offer(提供)->Request(请求)->Ack(确认)。
ICMP协议:网络探测、报错,ping命令使用的协议。
DNS:把域名翻译成ip,网络通讯录。
HTTP方法
GET:查数据
POST:提交/新增
PUT:修改,全量更新
DELETE:删除
PATCH:局部更新
HEAD:只拿响应头,不拿正文,检查接口存活、文件存在(收到200/404)
OPTIONS:查支持的请求方式,跨域预检(收到Allow:get,post,put…)
报代码415什么意思
后端不认识这个数据格式。
原因:
- Content-type没写或者写错了。
- 参数格式不对,比如json写成了key-value形式
Content-type支持格式:
- application/json(最常用)
application/json:传输json,后端现在基本都用这个。
- application/x-www-form-urlencoded
application/x-www-form-urlencoded:表单默认传输格式,参数格式a=1&b=2。
- multipart/form-data
multipart/form-data:上传文件使用,传图片和文件必须使用。
- text/plain
text/plain:纯文本格式。
- application/xml、text/xml
- text/html
- text/css
- application/javascript / text/javascript
- image/jpeg、image/png、image/gif
- application/pdf
- application/octet-stream
application/octet-stream:未知二进制流,下载文件时常见。
常见的报错代码
|
1xx信息类 |
2xx成功 |
3XX重定向 |
4xx客户端错误 |
5xx服务端错误 |
|
100 继续 |
200 ok请求成功 |
301 永久重定向 |
400 请求参数错误 |
500 服务器内部错误 |
|
201 create 创建成功 |
302 临时重定向 |
401 未登录 / 鉴权失败 |
502 网关错误 |
|
|
204 not content 成功无返回 |
304 资源未修改(缓存) |
403 禁止访问(权限不够) |
503 服务不可用 / 过载 |
|
|
404 接口不存在 |
504 网关超时 |
|||
|
405 方法不允许 (GET/POST 用错) |
||||
|
415 不支持的媒体类型 (Content-Type 错) |
||||
|
429 请求频率超限 |
cookie和session的区别
|
名称 |
存哪里 |
存什么 |
安全性 |
存储大小 |
生命周期 |
|
Cookie |
浏览器/ 电脑本地 |
少量信息,id/token/记住密码 |
不安全,用户可以随便改、查看、伪造 |
很小,每个大约4KB |
可以设置永久保存,直到过期 |
|
Session |
服务器内存 |
用户完整登录状态、权限、信息 |
安全,用户不能改,只能拿到sessionId |
不限制大小,服务器能存多少就多少 |
默认浏览器关闭或超时就失效 |
Session跨端/域麻烦;服务端压力大,要存所有用户会话。
传统Session只靠SessionId识别,CSRF风险高。
工作流程:(session依赖cookie传递sessionId,但是session本身不在cookie里)
- 用户登录成功
- 服务器创建session,保存用户信息
- 服务器生成sessionId,通过cookie发给浏览器
- 浏览器之后每次请求都自动带上这个cookie
- 服务器根据sessionId找到对应的session
现在主流Session:Redis + HttpOnly Cookie + 安全加固
1.登录
后端生成唯一一个SessionId,把用户信息存Redis,通过set-Cookie把SessionId种到浏览器。Cookie 设置 HttpOnly(js读不到Cookie,防XSS)+Secure(只在HTTPS传输) + SameSite(防CSRF,第三方发起请求不会带Cookie)。
2.后续请求
浏览器自动带上SessionId Cookie,去后段拿SessionId去Redis查用户信息。
3.登出,删除Redis里面的会话即可
Token,JWT是什么?
Token:临时身份证,代表身份的字符串。登录成功后,服务器发一个token,之后每次请求都加到请求中,服务器验证字符串有效否。
Token特点:不依赖Cookie;移动端也可以用;服务端可以不存状态。
JWT:Json Web Token,规范格式的Token,自带用户信息,加密后的字符串。结构是头部(算法)+载荷(用户id/昵称等)+签名(防篡改)。但是签名后难作废,过期控制不好。跨域/端非常友好。
JWT特点:不依赖Cookie;服务端不需要存会话;拿到JWT签名就可以;信息在字符串里面。
*Cookie中可以放Token/JWT(前后端不分离情况,有CSRF风险),但不是必须放,现在主流是放在请求头中。Cookie和JWT不冲突,但是可以完全无关。
CSRF攻击:浏览器自动带上对应域名Cookie,不管请求是哪个页面发起的,攻击者利用登录状态,在第三方网站伪造请求。可以使用Token/JWT预防,请求头里面必须带上Token/JWT才认。
现在前后端分离:只在请求头中带Token/JWT,不带Cookie,并且Cookie中什么身份信息都不带,完全不靠Cookie认证。
现在的Cookie作用:存储语言、主题、灰度识别、谷歌分析、埋点,部分老系统存SessionId,绝对不存敏感身份认证。
主流项目二选一:
- JWT放请求头(无Cookie)
- 使用SessionId放安全Cookie(无Token)。双重验证或老系统改造才两个都带
|
Session |
JWT |
|
|
存储位置 |
服务器 |
客户端 |
|
存储内容 |
用户信息、状态、权限 |
自包含信息:id、角色 |
|
安全性 |
高(SessionId随机,不可猜) |
中高(签名放篡改) |
|
服务端存状态 |
是 |
不存服务器 |
|
Cookie依赖 |
依赖(SessionId放Cookie) |
不依赖(放请求头) |
|
扩展性 |
差(分布式需要共享Session) |
极好(无状态,多节点通用) |
|
退出登录 |
服务端删除Session |
前端丢弃Token,服务端无法主动作废 |
|
性能 |
读取快,写入慢 |
签发快,解析快 |
|
CSRF风险 |
有(必须防御SameSite) |
几乎没有(不依赖Cookie) |
|
真实项目占比 |
后台系统、传统网站 |
现代前后端分离、app、小程序 |
为什么用 JWT 不用 Session?
- JWT是无状态的,服务端不存储,扩展强
- 支持多端统一,不依赖Cookie,天然放CSRF
- 分布式中Session麻烦,JWT不用共享
- 前端可以自主解析用户信息,减少一次接口调用
XSS攻击是什么?和CSRF区别是什么?
XSS攻击:跨站脚本攻击,攻击者往网页中注入恶意JS代码,让浏览器执行,偷数据、Cookie、账号密码、token、模拟操作界面、篡改页面内容。
|
XSS跨站脚本 |
CSRF跨站请求伪造 |
|
|
原理 |
注入恶意js执行 |
利用浏览器自带Cookie伪造请求 |
|
是否需要代码注入 |
需要 |
不需要 |
|
能不能拿到Cookie |
能,直接偷 |
不能,只是借用 |
|
攻击目标 |
用户浏览器 |
用户身份(会话) |
|
危害 |
偷信息、控制页面、盗取账号 |
转账、删帖、改资料 |
|
防御重点 |
过滤、转义(把<>变成无害字符)、HttpOnly |
Token、SameSite、验证来源 |
常见网络攻击
CSRF攻击:借身份伪造请求
XSS攻击:偷数据
SQL注入:用户输入中写SQL语句,骗过后端直接执行
文件上传漏洞:上传图片时,偷偷上传asp/php/jsp木马,服务器拿到直接执行,拿到服务器权限
命令注入:用户输入夹带系统命令,后端直接执行,比如删库跑路
文件包含漏洞:通过路径穿越,让服务器包含恶意文件
越权访问:水平越权(让A用户看B用户的数据),垂直越权(普通用户可以用管理员接口)
点击劫持:做一个透明网页盖在正常页面上面,诱导点击,不知不觉点到恶意按钮
目录遍历/路径穿越:读取服务器任意文件
弱密码+爆破:暴力猜测账号密码
中间人攻击(MITM):窃听HTTP明文,篡改内容、窃取信息
重放攻击:截取合法请求,反复发送,重复扣款
从浏览器输入url发生了什么
- 输入网址、回车
- 浏览器解析URL
根据协议(HTTPS)+域名(www.baidu.com)+路径(/index),分析用什么协议,访问谁。
- 浏览器查看缓存,看有没有用过的ip
查浏览器DNS缓存,系统host文件,路由器缓存,有的话就直接用ip,没有就进行下一步。
- DNS解析,把域名转成ip
- 封装TCP/IP数据包,发起三次握手,连接成功后开始传输数据
- 如果是HTTPS,进行TLS握手
- 浏览器发送HTTP/HTTPS请求
- 服务器处理请求,返回响应
- 浏览器接受响应,解析html(从上到下解析,生成DOM树)
遇到<link css>:下载并解析,生成CSSOM
遇到<script js>:默认阻塞解析,下载并执行
遇到图片/视频:异步下载,不阻塞
- DOM+CSSOM合成渲染树(Render Tree)
- 布局(Layout/Reflow)
- 绘制(Paint)
- 合成(Composite)
- TCP四次挥手,断开连接
Linux如何查看某个进程的运行状态
查看是否在运行
ps -ef | grep 进程名或
ps aus | grep 进程名动态实时查看进程(类似任务管理器)
top 按 M 按内存排序
按 P 按 CPU 排序
按 q 退出
杀死进程
kill -9 [pid]查看pid状态
ps -ef | grep 进程名 #拿到PID
ps -p pid号 -o pid,ppid,pcpu,cmd,state查看进程详细状态(最完整)
cat /proc/[pid]/status查看:进程状态(运行 / 睡眠 / 僵尸);内存、线程数、FD 数;启动时间、所有者
查看进程是否存活或查看pid
(有数字输出表示在运行,没有输出表示没有运行)
pidof 进程名或
Pgrep 进程名查看进程打开的文件、端口
lsof -p [pid] 看占用端口:
netstat -antp | grep [pid]
ss -antp | grep [pid]进程状态码意义
|
R |
Running 正在运行 |
正在跑cpu,或排队等cpu |
|
S |
Sleeping 可中断睡眠(绝大多数进程) |
等待资源、锁、信号,可被信号唤醒 |
|
D |
不可中断睡眠(I/O阻塞) |
等待I/O,不能被打断,极少出现 |
|
Z |
Zombie僵尸进程(需要父进程回收) |
线程结束但是还没有被回收资源 |
|
T |
Stopped停止 |
被调试、被信号暂停 |
|
S |
会话首进程 |
|
|
+ |
前台进程 |
|
|
N |
低优先级 |
-
Linux常用命令
查看端口
-
查看所有端口
netstat -tuln
或
ss -tuln-
查看某个端口是否被占用
netstat -tulpn | grep 8080
ss -tulpn | grep 8080-
查看端口被哪个进程占用
lsof -I :8080-
查看所有连接
netstat -ant查看日志
-
实时刷新看日志
tail -f xxx.log-
看最后一百行
tail -100 xxx.log-
从头看
cat xxx.log-
分页查看
less xxx.log上下箭头翻页,/关键字搜索,q退出
查看系统资源
-
实时看CPU/内存
topM 按内存排序
P 按 CPU 排序
q 退出
-
看内存使用
free -h-
看磁盘空间
df -h-
看文件夹大小
du -sh 文件夹名文件操作
-
编辑文件
vi 文件名
vim 文件名-
复制文件
cp a.txt b.txt-
移动/重命名
mv a.txt /file123
mv a.txt b.txt-
删除
rm -rf 文件夹/文件-
创建文件
touch 1.txt-
创建文件夹
mkdir file123网络命令
-
网络连通性
ping www.baidu.com-
查看域名ip
nslookup www.baidu.com-
抓包
tcpdump -I any prot 8080Linux如何查看文件内容
只想要看文件内容:
cat/less/tail想要编辑文件:
vim/vilinux内存占用过高,该怎么看是哪个进程在哪出了问题
- 看整体内存情况
free -h 看used是不是要满了,看available(真正能分配的内存)
- 按内存使用率排序
top ->按M,根据使用率排序,看VIRT(虚拟内存)和RES(实际物理内存,重点关注)
或
ps aux –sort=-%mem | head -10按照内存降序,显示前十个进程
如何在 Linux 上查找 1 G以上 的大文件,以及查看大文件内容
查找文件(按照类型和大小):
- 全局查找
find / -type f -size +1G- 某个目录下
find /home -type f -size +1G- 显示详细信息
find / -type f -size +1G -exec ls -ln {} \;{}:占位符,表示find找到的每一个文件
\;:表示-exec命令结束
使用less分页查看大文件内容。
|
上下箭头 |
翻页 |
|
PageUp/PageDown |
翻页 |
|
/关键字 |
搜索,比如/abc |
|
n |
下一个匹配 |
|
N |
上一个匹配 |
|
G |
跳到文件末尾 |
|
gg |
跳到文件开头 |
|
Q |
退出 |
Linux管道是什么?用法
管道(|):把前一个命令的输出当做后一个命令的输入,串起来用。不生产临时文件,把多个命令串起来处理数据。
注意:可以无限叠加使用。
ps -ef | grep java | grep -v grep | wc -l (列出所有进程;找出 java;排除 grep 自身;统计有多少个)
用法:
- 查找进程
ps -ef | grep 进程名- 查看日志并过滤
cat xxx.log | grep “error”- 排序
ps aux | sort -k 6- 统计行数
cat xxx.log | wc -l查看linux 进程数,内存占用情况
ps -ef | wc -l #查看进程数量
ps aux –sort=-%mem | head -5什么是死锁?死锁产生的4个条件?
死锁(DeadLock):两个或多个进程/线程在执行过程中,互相持有对方所需要的资源,并且都不释放自己占有的资源,导致彼此无限等待、无法继续执行的僵局。
死锁的四个条件:
- 互斥;
- 请求与保持;
- 不可剥夺;
- 循环等待
四个条件缺一不可。
死锁预防(DeadLock Prevention):从根源杜绝死锁发生可能性,保守但安全,效率低。破坏四个必要条件之一,宁可浪费资源也不允许死锁出现。
死锁避免(DeadLock Avoidance):动态判断系统是否安全,允许进入不安全的状态,但决不允许进入死锁状态,灵活效率高。银行家算法,边走边看。
线程有哪几种状态?
Java线程有6个线程状态:New(新建)、Runnable(可运行)、Blocked(阻塞,在等进入synchronized,等锁)、Waiting(无限等待)、Timed_Wating(显示等待)、Terminated(终止)。
C++线程无状态,仅joinable:可joinable(正在运行/就绪/阻塞)、已完成/可等待、已分离/已结束。
Qt线程有5个状态:New(新建)、Running(就绪/运行)、Blocked(阻塞中)、InterruptionRequested(请求中断)、Terminated(已终止)。
Linux中线程有5中状态:R(Runing/Runnable运行/就绪)、S(InterruptionSleep可中断睡眠)、D(UninterruptionSleep不可中断睡眠)、T(Stopped暂停)、Z(Zombie僵尸)。
有哪些进程调度算法?
先来先服务(FCFS):对短作业不好,平均等待时间长。
短作业优先(SJF):预计运行时间最短的先执行,平均等待时间短,长作业可能长期饥饿。
最短剩余时间优先(SRTF):新的短进程来了可以抢占当前长进程,切换开销大。
优先级调度(Priority Schrduling):按优先级运行,低优先级进程可能长期饥饿,可以用等待时间长调整优先级解决。
时间片轮转(RR/Round Robin):分时系统,每个进程分配一个时间片,用完切换,如果时间片太小,切换很频繁,如果时间片太大,退化成FCFS(先来先服务)。
多级反馈队列(MLFQ):Mutilevel Feedback Queue,综合了RR+优先级+动态调整,多个队列优先级从上到下降低,新进程进最高优先级队列,用完时间片还没结束,就降级到下一个队列。Linux早起、Unix常用调度算法。
高响应比优先(HRRN):Highest Ratio Next,响应比=(等待时间+服务时间)/服务时间,照顾短作业同时,防止长作业饥饿,非抢占,综合性能好。
什么是缓冲区溢出?
缓冲区溢出(buffer Overflow):程序向固定大小的内存区域写了超出容量范围的数据,多余数据覆盖了相邻内存空间,破坏乱程序原本执行逻辑。
比如C/C++中不安全的字符串操作,没有检查长度直接拷贝:get()、strcpy()、spintf()、memcpy()
防护缓冲区溢出:
- 使用安全版本函数:fgets()、strncpy()、snprintf()
- 在linux中开启系统保护:ASLR(地址随机化,攻击者找不到跳转位置)、StackCanary(栈金丝雀,检测溢出)、DEP/NX(数据不可执行,让恶意代码无法执行)
- 开启编译器保护:栈保护、边界检查
ASLR、Stack Canary、DEP/NX是什么?它们怎么打开?
|
机制 |
名称 |
作用 |
防护对象 |
|
ASLR |
地址空间布局随机化 |
随机化代码、库、栈、堆的加载地址,让攻击者找不到目标地址 |
ROP、地址预测攻击 |
|
Stack Canary |
栈金丝雀(GS) |
在栈局部变量和返回地址之间插入随机值,返回前校验,被篡改则终止程序 |
栈溢出覆盖返回地址 |
|
DEP/NX |
数据执行保护/不可执行内存 |
标记数据区(栈、堆、全局变量)为不可执行,阻止注入的shellcode运行 |
代码注入、shellcode |
DEP是Windows名字,NX是Linux名字,同一个机制在不同系统的不同叫法,依赖CPU的NX/XD位硬件支持。
在Linux打开:
- 栈金丝雀
编译时加以下命令
-fstack-protector:仅对含 char 数组且长度≥8 字节的函数启用
-fstack-protector-strong:覆盖更多函数(含局部数组引用、alloca ())
-fstack-protector-all:对所有函数启用,安全最强、性能开销最大。
禁用:-fno-stack-protector。
- DEP/NX
GCC默认开启堆、栈不可执行。
禁用:-z execstack
强制开启:-z noexecstack
- ASLR
在root权限下,查看当前是否开启
cat /proc/sys/kernel/randomize_va_space0=关闭
1=仅mmap、栈、vDOS随机化
2=全部随机,默认开启
临时修改:
echo 2 > /proc/sys/kernel/randomize_va_space永久修改:编辑 /etc/sysctl.conf,添加 kernel.randomize_va_space=2,执行sysctl -p生效。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 9
9 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)