Var-JEPA:联合嵌入预测架构的变分形式 —— 连接预测式与生成式自监督学习 ----论文翻译
Var-JEPA: A Variational Formulation of the Joint-Embedding Predictive Architecture — Bridging Predictive and Generative Self-Supervised Learning
原文地址:https://arxiv.org/pdf/2603.20111
关于变分推断的内容之前也讲过:VAE学习笔记
摘要
联合嵌入预测架构(JEPA)常被视为基于似然的自监督学习的非生成式替代方法,其核心是在表示空间中进行预测,而非在观测空间中做重构。本文提出,这种与概率生成建模的割裂大多是表述层面的,而非结构层面的:标准 JEPA 的设计 —— 耦合编码器与上下文到目标的预测器 —— 与对一类耦合隐变量模型做变分推断得到的变分后验、学习到的条件先验高度吻合;标准 JEPA 可被看作一种确定性特例,其正则化依赖架构与训练启发式规则,而非显式似然。
基于这一视角,本文推导变分 JEPA(Var-JEPA):通过优化单一证据下界(ELBO)显式建模隐生成结构,无需特设的防坍缩正则器即可学到有效表示,并支持对隐空间进行严格的不确定性量化。本文将该框架用于表格数据(Var-TJEPA),在表示学习与下游任务上取得强劲效果,持续优于 T-JEPA,且与强原始特征基线相比具备竞争力。
1 引言
机器学习的核心目标之一是从数据中构建能真正理解并预测世界的模型。自监督学习通过训练模型 “用输入的一部分预测另一部分”,无需人工标注即可学到丰富表示。在此背景下,LeCun(2022)提出联合嵌入预测架构(JEPA),旨在构建 “世界模型”,为智能决策学习世界的抽象表示。
与常规生成模型(直接预测像素等原始输入)不同,JEPA 完全在隐空间工作:用上下文信号 x 的嵌入,去预测相关目标视图 y 的嵌入。其实现包含上下文编码器、目标编码器
与预测器 g,从上下文表示 sx 与可选辅助变量 z 生成目标表示 s^y。训练目标最小化预测与真实目标表示的距离,并对目标编码器做 ** 停止梯度(stop-gradient)** 操作,避免模型学到无意义的预测特征。
尽管效果强大,该设计存在两个关键问题:
- 易发生表示坍缩:编码器易输出恒定向量,需依赖特设方案(如辅助损失、指数移动平均 EMA)保证表示多样性。
- 被定性为非生成方法:与基于似然的自监督学习、概率隐变量建模割裂。
本文对这一割裂提出全新视角:这一区分主要是表述上的,而非结构上的。JEPA 的耦合编码器 + 上下文到目标预测器结构,与耦合变分自编码器(VAE)的变分后验、学习到的条件先验高度一致。具体来说,本文反向构建一个概率模型,其 ELBO 恰好将 JEPA 预测器转化为隐空间条件先验;标准 JEPA 可自然解释为该模型的确定性特例。
这一视角不仅打通预测式与生成式自监督学习,还提供了天然防坍缩路径,并支持隐空间不确定性量化。
本文核心贡献:
- 建立 JEPA 与变分推断的全新形式化联系,将其重解释为确定性隐变量模型。
- 提出Var-JEPA:基于该联系推导的生成式 JEPA,配套 ELBO 目标。
- 证明 ELBO 可自然避免表示坍缩,无需 JEPA 常用的替代损失,并与 LeJEPA 的 SIGReg 正则建立关联。
- 针对异构表格数据提出实用实现 Var-T-JEPA。
- 通过控制变量模拟研究与多数据集下游实验验证方法,效果持续优于标准 JEPA 与强基线。
2 相关工作
2.1 JEPA 类预测表示学习
JEPA 由 LeCun(2022)提出,通过匹配表示学习预测式世界模型。典型实现包括:
- I-JEPA:无需手工数据增强,从上下文区域预测掩码区域的嵌入,学到强图像表示。
- V-JEPA:扩展到视频,学习时空表示。
- T-JEPA:适配异构表格数据,采用特征级掩码与 Transformer 分词,无需 heavy 数据增强仍具备竞争力。
2.2 基于分布正则避免坍缩
主流 JEPA 用 EMA 缓慢更新目标编码器以稳定训练,但这种启发式无法直接控制嵌入分布。后续工作:
- Drozdov 等(2024):通过方差–协方差惩罚显式正则嵌入分布,鼓励维度方差、抑制相关性。
- LeJEPA(Balestriero & LeCun,2025):提出各向同性高斯嵌入分布对下游探针是 minimax 最优的,并设计 SIGReg:通过随机一维投影让聚合嵌入分布匹配标准正态 N(0,I)。
本文中,ELBO 对 、z 做逐样本向固定先验的正则,同时在模拟研究中将 SIGReg 作为显式聚合分布正则器进行对比。
2.3 生成式世界模型与隐空间建模
世界模型研究侧重学习用于预测与规划的隐态动力学。与生成式隐模型、VAE 相比,JEPA 更强调隐空间预测,通常避开显式似然建模。
本文核心贡献是:JEPA 类架构可自然来自带学习条件先验的变分隐变量模型。同期工作(Huang,2026)也探索了 JEPA 的概率形式用于隐预测不确定性,但 Var-JEPA 更进一步:将 JEPA 建模为耦合隐变量生成模型,用统一 ELBO 桥接预测式联合嵌入学习与生成式建模,说明它不是对 JEPA 的增量正则,而是暴露其隐式生成结构的严格变分形式。
3. JEPA 的变分视角
3.1. 问题形式化
我们首先提出一个简单的结构问题:如果将 JEPA 中的预测嵌入步骤解释为耦合 VAE 的变分后验,那么会产生怎样的生成模型?
这种观点自然引导我们对 JEPA 进行一种新颖的概率潜在变量框架下的重新解释。具体而言,我们将 JEPA 的确定性编码器和预测器替换为条件分布,并将预测路径解释为学到的潜在空间条件先验。这建立了一个清晰的关于上下文、目标和辅助潜在变量的生成过程,并从中推导出一个单一的变分目标(ELBO)。我们的形式化将 JEPA 风格的预测学习与重建和条件生成统一起来,同时通过潜在正则化提供了一种严格的避免坍缩机制。
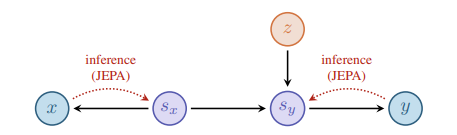
结构。 与 JEPA 类似,我们的模型处理上下文观测 和目标观测
,学习潜在表示
(上下文)、
(目标)以及
(辅助预测变量,用于捕捉
无法解释的 sy s_y sy 中的变异性)。有向无环图(DAG)遵循基础生成过程:
(图示:x → (JEPA 推断),y →
(JEPA 推断),z 连接到
,
→
)
标准 JEPA 主要采用从观测到表示的单向映射(,
),而我们的变分框架要求双向关系,以同时建模生成过程和推断过程。对于上下文和目标,我们分别学习两个方向:编码(从观测到潜在)和重建(从潜在回观测)。单一 ELBO 目标将这些方向绑定在一起,并联合训练编码器和解码器。
目标与因子分解。 我们的主要目标是学习一个生成模型,以最大化观测数据对 (x,y) 的边际对数似然:
对数似然衡量参数化模型(参数为 θ )对观测数据的解释程度。按照 DAG,联合分布
的因子分解为:
生成模型参数化。 我们将生成模型中的分布实现为高斯分布。潜在变量的先验为标准高斯,而条件分布由神经网络参数化:
解码器网络 和
从潜在表示重构观测,其中
为观测维度。预测网络输出 \mu^s_y_{\theta}(s_x, z) 和 \Sigma^s_y_{\theta}(s_x, z) 由参数为 θ \theta θ 的神经网络计算。重构噪声参数
和
可设为 1 或全局学习,以建模观测不确定性。
3.2. 变分后验
由于给定因子分解和参数化下,式 (4) 中的积分因复杂神经网络函数和高维潜在空间而不可解,我们无法直接优化。因此,我们采用变分推断方法,引入一个易处理的变分后验
作为真实后验
的近似,并由参数为 ϕ 的神经网络参数化。我们将变分后验因子分解为:
我们采用该因子分解的原因如下:
- 上下文潜在
仅依赖于上下文观测 x,确保上下文表示独立于目标信息学习。
- 辅助潜在 z 仅依赖于上下文表示
,防止训练期间目标信息泄漏。
- 目标后验
同时依赖
的学习,使其编码有意义的目標信息,从而确保对上下文的依赖通过正确的预测关系而非平凡捷径学习。
变分后验参数化。 变分后验的每个组成部分均参数化为具有可学习均值和协方差的高斯分布:
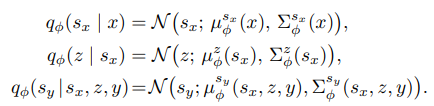
推断网络 ![]() 实现为神经网络,根据各自输入输出分布参数。
实现为神经网络,根据各自输入输出分布参数。
3.3. Var-JEPA:证据下界
建立变分后验后,我们通过 Jensen 不等式推导 ELBO——边际对数似然的易计算变分下界:
![]()
更具体地,我们通过最大化其易处理的变分下界来实现最大化 的目标。代入
和
的因子分解后,我们得到:
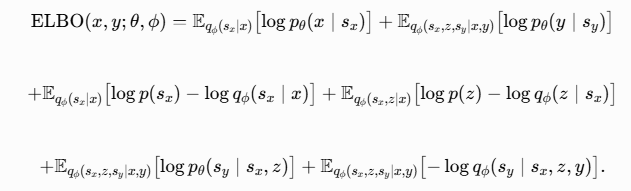


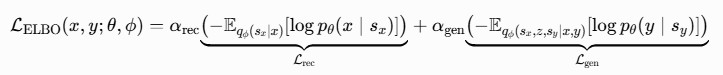
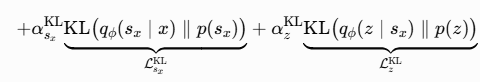
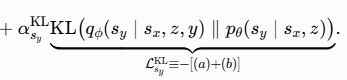

3.4. JEPA 与 Var-JEPA 架构对比
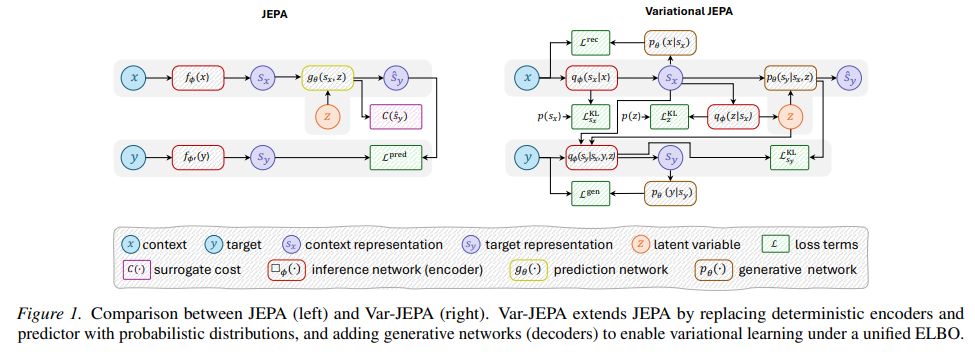
图 1 说明了标准 JEPA 与 Var-JEPA 之间的关系。两种方法共享相同的核心预测结构,包括上下文 (x) 和目标 (y) 观测、它们的潜在表示 、
以及辅助潜在变量 z。JEPA 依赖推断和预测网络,需要代理损失 C(⋅) 来防止表示坍缩。Var-JEPA 通过添加生成网络(即解码器)来扩展 JEPA,从而可以用统一的变分目标训练模型,该目标自然防止坍缩。
3.5. 重参数化技巧与采样实现
为通过随机潜在变量进行反向传播,我们应用重参数化技巧(Kingma & Welling, 2013),将样本表示为噪声的确定性函数,从而使梯度明确定义。潜在变量采样使用以下重参数化形式:
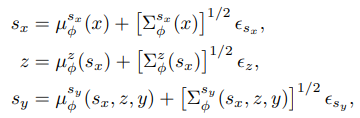
其中![]() 为独立标准高斯噪声向量,
为独立标准高斯噪声向量, 表示协方差的矩阵平方根。实践中,我们在每次前向传递中对每个潜在变量采样一次实现来估计梯度。梯度估计器变为:
其中每次训练步骤使用从重参数化分布抽取的新样本 。
3.6. 理论生成推断
当 Var-JEPA 被解释为真正的生成模型时,它可以通过生成路径从上下文采样生成目标观测。在目标不可用时适用的生成推断过程为:
这与训练不同,训练中 z 通过 推断,且目标后验
可访问真实目标。对于下游表示学习任务(目标为预测而非生成),我们报告后验均值而非采样来使用确定性嵌入(见附录 D.5)。
3.7. 与 LeJEPA 的关系
LeJEPA(Balestriero & LeCun, 2025)将各向同性高斯嵌入动机为在广泛探针家族下对下游预测的最小最大最优。它使用 SIGReg 通过随机一维投影将聚合嵌入分布匹配到各向同性高斯来强制执行此分布结构。
Var-JEPA 通过其变分正则化项与此图景相关。对于具有固定标准正态先验( 和
)的潜在变量,ELBO 包含每个样本的 KL 项
。这些项允许标准“ELBO 手术”分解(Hoffman & Johnson, 2016)为聚合后验失配项和信息瓶颈项:
类似。相比之下,Var-JEPA 中的目标潜在项为
,即正则化到学到的条件先验而非
,因此不会以相同方式分解为聚合 KL 到固定参考分布。这促使我们在模拟研究中将 SIGReg 作为显式聚合分布正则化器(尤其是对
)进行研究,并报告 LeJEPA 链接诊断。
4. 实验
4.1. 模拟研究
我们在受控的合成环境中评估 Var-JEPA,该环境旨在隔离潜在正则化、各向同性以及信息瓶颈的影响,同时保留已知的真实生成过程。这一设置使我们能够分析变分目标如何塑造聚合潜在分布,以及这种分布又如何影响下游探针性能。
数据生成。 我们从具有混合结构上下文潜在变量 、与
相关的目标潜在变量
以及影响
(进而影响
)的辅助因子
的潜在过程生成观测
。观测通过非线性映射
和
以及独立高斯噪声获得:
ELBO 分解与解释。 虽然 Var-JEPA 并未显式优化聚合后验 KL 项,但具有固定先验的潜在变量(此处为 和 z)的期望 KL 项允许式 (11) 中的标准分解。对于目标潜在变量,ELBO 包含条件先验项,该项不会以相同方式分解为聚合 KL 到固定参考分布。这突显了 Var-JEPA 将固定先验的潜在空间分布正则化与惩罚输入与潜在变量之间过度依赖的信息瓶颈相耦合。
实验变体。 为研究 Var-JEPA 与 LeJEPA 的关系,我们进行系统消融研究,比较十个变体(表 1 中标记为 A–J)。除非明确设为零,否则所有损失权重参数使用默认值:ELBO 项的 ,SIGReg 正则化的
。我们比较以下变体:(A) 完整 ELBO 目标(标准 Var-JEPA);(B–D) ELBO 附加 SIGReg,其中 SIGReg 分别应用于
(B,
)、
(C,
)或两者(D)。ELBO+SIGReg 的一般形式为:
![]()
我们还考虑 (E–F) 移除某些 KL 项的 ELBO( 和
);(G) 移除重建和生成项的 ELBO(
),仅保留 KL 正则化;(H) 与 (G) 相同但附加 SIGReg;(I) 移除所有 KL 项的 ELBO(
),仅保留重建和生成;(J) 与 (I) 相同但附加 SIGReg。这些变体使我们能够区分每个样本变分正则化与直接控制聚合潜在分布的效果。
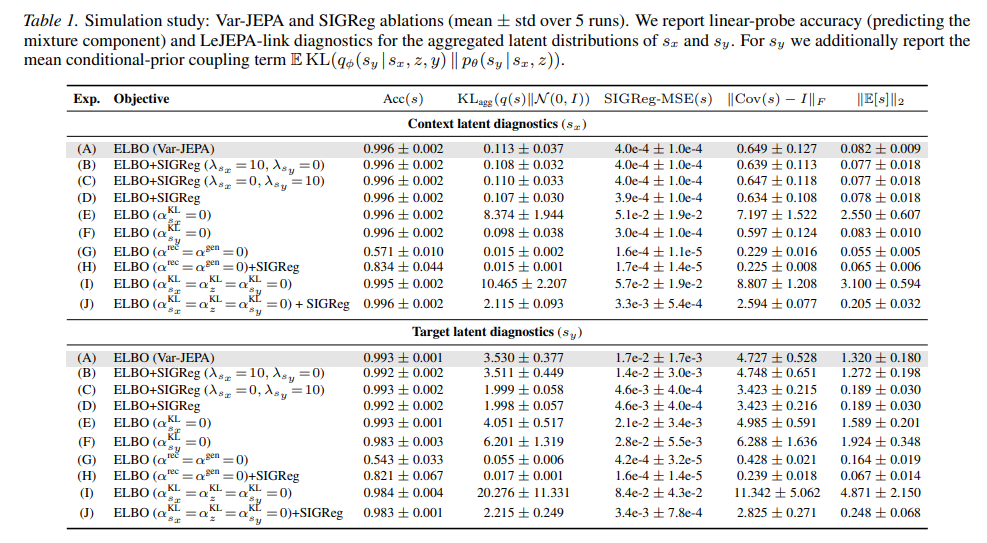
模拟研究结果。 我们在相同架构和训练计划下进行受控比较,仅改变 SIGReg 的存在/范围以及是否包含 KL 项。结果如表 1 所示,报告分布诊断:聚合 KL 散度到、SIGReg-MSE(通过 SIGReg 的偏差)、协方差与单位矩阵偏差的 Frobenius 范数
以及均值范数
。图 2 显示了选定消融在训练期间这些诊断的变化。
关键发现是 ELBO 中的 KL 散度项为 实现了与显式聚合分布正则化(SIGReg)相当的分布性质。这表明每个样本 KL 正则化到固定先验自然强制聚合分布各向同性,而无需额外正则化机制。对于
,ELBO 正则化到学到的条件先验而非
,这是目标潜在变量理论上正确的目标;因此,聚合分布偏离各向同性高斯,这符合预期。
移除重建项(变体 G)导致表示坍缩,探针准确率降至接近随机水平。移除 上的 KL 项(变体 E)导致严重分布坍缩,聚合 KL 散度和 SIGReg-MSE 值显著增加。移除所有 KL 项(变体 I)导致所有分布指标的更严重坍缩,表明 KL 正则化对于维持良好潜在分布至关重要。当 SIGReg 添加到无 KL 变体(变体 J)时,它部分补偿了缺失的 KL 项,但完整 ELBO 仍是最佳。图 2 中的训练动态显示这些分布性质在训练期间逐渐出现,KL 项在整个过程中提供稳定正则化。
4.2. 表格数据的下游评估
4.2.1. 实验细节
Var-T-JEPA。 我们评估了我们的表格实现 Var-T-JEPA,它将特征级掩码与式 (10) 的统一变分目标相结合。该模型受确定性 T-JEPA(Thimonier et al., 2025)的启发,但为异构表格数据实例化了 Var-JEPA 框架,通过学习高斯潜在嵌入并在 ELBO 下联合训练预测和重建路径。Var-T-JEPA 将异构数值和类别特征标记化为 transformer 序列,推断高斯潜在嵌入 sx s_x sx 和 sy s_y sy,并通过耦合重建–预测目标训练潜在空间预测器,该目标直接实例化了针对异构表格数据的 Var-JEPA 框架。这同时产生确定性嵌入(通过后验均值)和来自学到潜在分布的每个样本不确定性估计。我们将完整概念描述推迟到附录 A。
数据集。 我们在五个真实世界表格数据集上评估学到的表示:Adult (AD)、Covertype (CO)、Electricity (EL)、Credit Card (CC) 和 Bank Marketing (BM),以及 MNIST(视为具有可控输入损坏的表格特征)和完全合成的模拟数据集 (SIM);更多细节见附录 C.1.1。
下游和基线预测器。 对于每个数据集,我们将强原始特征基线与在 Var-T-JEPA 和 T-JEPA 产生的嵌入上训练的相同预测器架构进行比较(附录 D.5 中的细节)。遵循 Thimonier et al. (2025),我们考虑一系列强大且广泛使用的表格预测器:MLP、DCNv2(Wang et al., 2021)、ResNet(He et al., 2016)、AutoInt(Song et al., 2019)、FT-Transformer(Gorishniy et al., 2021)和 XGBoost(Chen & Guestrin, 2016)。
通过不确定性的选择性评估。 Var-T-JEPA 提供每个样本的不确定性估计;我们报告选择性评估,其中丢弃不确定性最高的 10%、20% 或 50% 的样本后再计算准确率(“Var-T-JEPA (10%)” 等),说明放弃低置信度样本时的覆盖–准确率权衡。
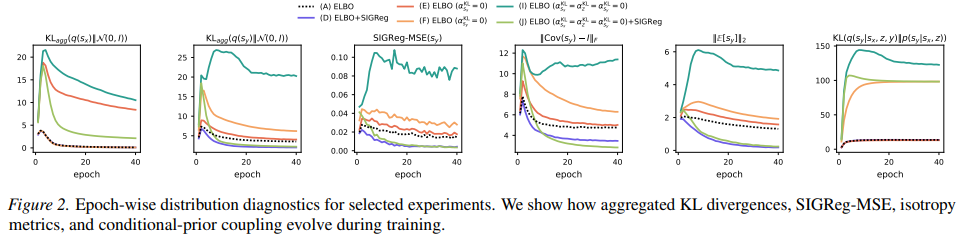
4.2.2. 结果
表 2 总结了跨数据集和预测器家族的下游测试准确率。在真实世界表格数据集(AD、CO、EL、CC、BM)上,Var-T-JEPA 为下游分类器产生了具有竞争力的嵌入,选择性评估显示出清晰的覆盖–准确率权衡:在保留子集上丢弃最不确定的测试样本可提升所有模型家族的性能。相比之下,确定性 T-JEPA 基线在某些数据集上可能遭受表示坍缩,导致下游性能较差且鲁棒性降低。
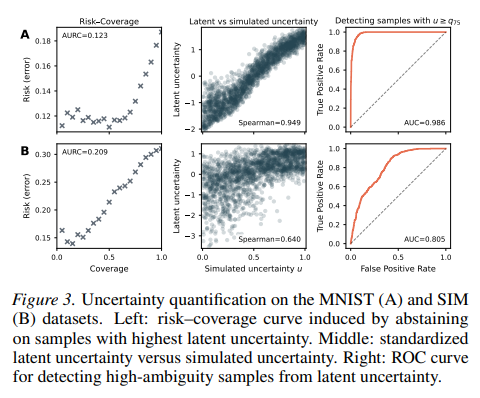
对于(半)合成 MNIST 和 SIM 数据集,Var-T-JEPA 还产生与底层模拟损坏/歧义结构一致的不确定性信号:图 3 可视化了(左)由在最高潜在不确定性样本上放弃诱导的风险–覆盖曲线,(中)标准化潜在不确定性与模拟不确定性分数之间的正相关,以及(右)显示潜在不确定性可识别高歧义样本(由模拟不确定性分数的高分位阈值定义)的 ROC 曲线。这些诊断通过显示学到的潜在不确定性不仅对放弃有用,而且与受控设置中已知的不确定性信号对齐,从而补充了表 2 中的选择性评估结果。更多实验结果,包括敏感性分析,见附录 B。
5. 讨论
我们对 JEPA 设计模式提供了一种新颖的重新解释,将其视为耦合潜在变量模型中的变分推断:预测器是学到的条件先验 pθ(sy∣sx,z) p_{\theta}(s_y \mid s_x, z) pθ(sy∣sx,z),而临时成本是 ELBO 正则化的间接形式。这澄清了常见的“JEPA vs. 生成建模”二分法在很大程度上是表述问题:JEPA 在潜在变量生成模型的设计空间中占据一个特定(隐式、通常是确定性)的点。通过使这种潜在生成结构显式化,我们在单一原则框架内统一了预测性和生成性自监督学习。
从经验上看,ELBO 训练在无需启发式防坍缩目标(例如 EMA 或分布匹配惩罚等辅助正则化器)的情况下产生了可用的表示,并从后验协方差中实现了严格的不确定性估计。我们将 Var-T-JEPA 作为表格数据的具体实现引入,在下游表格评估中,它在各种数据集上产生了具有竞争力的嵌入,并基于估计的潜在不确定性支持选择性预测。更广泛地,我们观察到每个样本 KL 项到固定先验驱动了与显式分布正则化器(如 SIGReg)相当的聚合分布行为,同时将目标潜在变量留给其学到的条件先验。未来工作包括扩展到视觉和视频,以及扩展到测试时目标观测缺失的设置,此时条件生成成为核心。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 5
5 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)