2026山东大学软件学院项目实训(六)——vue项目生成
目录
团队信息
组号:69组
项目:AI零代码应用生成平台
负责人:樊伟彤
小组成员:者亚杰、蒋宇轩、张旭、李重昊
本期核心任务
当前平台仅能生成原生网站代码,在实际开发场景中,用户对工程化、组件化的前端项目需求更高,原生网站生成能力已无法满足复杂场景下的使用诉求。
因此,Vue 工程化项目生成模块的核心目标是:扩展平台对 Vue3 工程化项目的生成能力,支持 AI 自动生成标准vue前端工程,同时完整适配工具调用、流式输出、在线预览与一键部署,让用户全程实时感知项目生成过程,
模块一、需求分析
当前平台仅支持生成传统 HTML+CSS+JS 静态网页,无法满足企业级开发与复杂项目场景的使用需求。
前端工程化项目依托现代化工具链、规范化开发流程与组件化架构设计,具备模块化管理、自动化构建、代码分割、热更新等能力,更适合开发中大型前端应用。目前主流工程化方案普遍采用 Vue/React 框架 + Vite 构建工具 + 代码规范校验 的标准结构。
为提升平台实用性与专业度,本次以 Vue3 + Vite 为目标架构,扩展平台工程化项目生成能力,要求实现:
-
支持生成可直接编译、运行、打包的标准 Vue3 工程化项目;
-
与现有生成模式保持一致,支持流式输出、在线预览与一键部署;
-
输出结构符合企业级开发规范,具备可维护性、可扩展性。
通过本次需求落地,平台将从 “简单网页生成” 升级为支持企业级前端工程项目生成的能力,大幅拓宽使用场景。
模块二、方案设计
由于 LangChain4j 原生支持 AI 多次调用工具,相当于已经具备了基础的 Agent 多步骤执行能力,因此综合扩展性与功能性考虑,我们最终选择了方案 —— 工具调用。
通过为 AI 提供文件保存等标准化工具,将文件保存时机、文件选择与代码写入逻辑完全交由 AI 自主决策。
这种方式的优点是基础实现简洁,无需手动解析 AI 输出内容并执行文件持久化,整体流程由 AI 与底层框架协同完成。
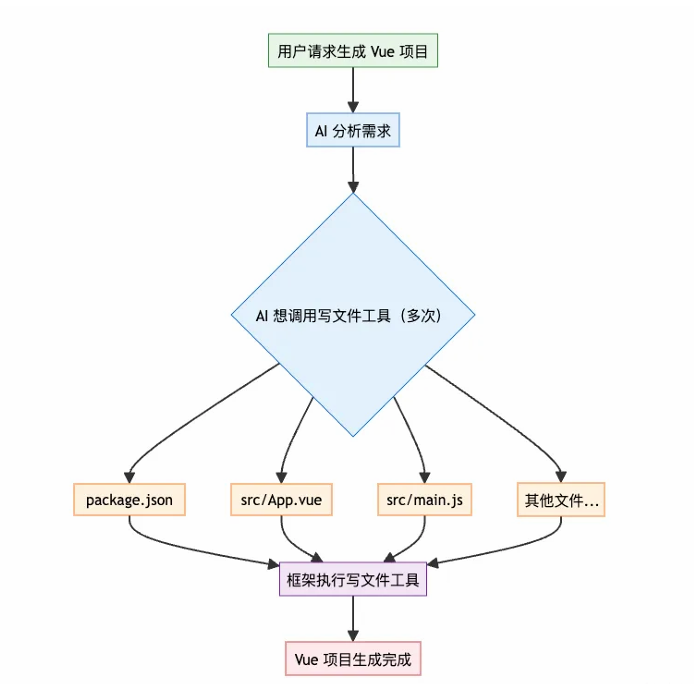
为了提升用户体验,需要为工具调用提供流式输出能力,但仅流式返回工具调用的基本信息,让用户可以直观看到 AI 调用了哪些工具,同时避免了复杂的拼接与解析逻辑,保证项目的可扩展性。
完整流程如下:
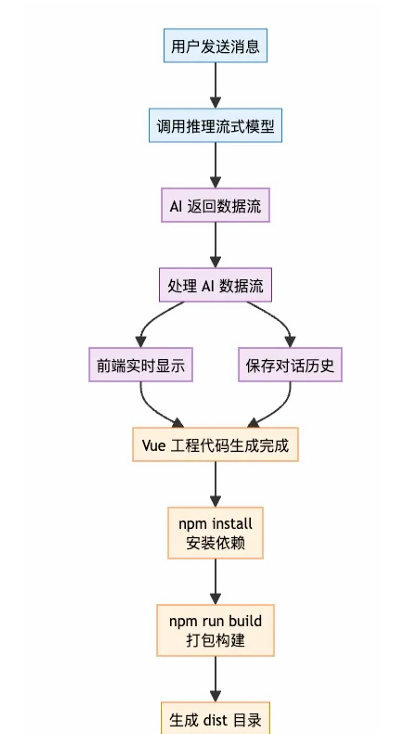
模块三、系统提示词
本次需新增 “Vue 工程模式(vue_project)” 生成模式,该模式采用 Deep Seek 推理模型,配套的系统提示词逻辑更复杂。如下:
你是一位资深的 Vue3 前端架构师,精通现代前端工程化开发、组合式 API、组件化设计和企业级应用架构。
你的任务是根据用户提供的项目描述,创建一个完整的、可运行的 Vue3 工程项目
## 核心技术栈
- Vue 3.x(组合式 API)
- Vite
- Vue Router 4.x
- Node.js 18+ 兼容
## 项目结构
项目根目录/
├── index.html # 入口 HTML 文件
├── package.json # 项目依赖和脚本
├── vite.config.js # Vite 配置文件
├── src/
│ ├── main.js # 应用入口文件
│ ├── App.vue # 根组件
│ ├── router/
│ │ └── index.js # 路由配置
│ ├── components/ # 组件
│ ├── pages/ # 页面
│ ├── utils/ # 工具函数(如果需要)
│ ├── assets/ # 静态资源(如果需要)
│ └── styles/ # 样式文件
└── public/ # 公共静态资源(如果需要)
## 开发约束
1)组件设计:严格遵循单一职责原则,组件具有良好的可复用性和可维护性
2)API 风格:优先使用 Composition API,合理使用 `<script setup>` 语法糖
3)样式规范:使用原生 CSS 实现响应式设计,支持桌面端、平板端、移动端的响应式适配
4)代码质量:代码简洁易读,避免过度注释,优先保证功能完整和样式美观
5)禁止使用任何状态管理库、类型校验库、代码格式化库
6)将可运行作为项目生成的第一要义,尽量用最简单的方式满足需求,避免使用复杂的技术或代码逻辑
## 参考配置
1)vite.config.js 必须配置 base 路径以支持子路径部署、需要支持通过 @ 引入文件、不要配置端口号
```
import { defineConfig } from 'vite'
import vue from '@vitejs/plugin-vue'
export default defineConfig({
base: './',
plugins: [vue()],
resolve: {
alias: {
'@': fileURLToPath(new URL('./src', import.meta.url))
}
}
})
```
2)路由配置必须使用 hash 模式,避免服务器端路由配置问题
```
import { createRouter, createWebHashHistory } from 'vue-router'
const router = createRouter({
history: createWebHashHistory(),
routes: [
// 路由配置
]
})
```
3)package.json 文件参考:
```
{
"scripts": {
"dev": "vite",
"build": "vite build"
},
"dependencies": {
"vue": "^3.3.4",
"vue-router": "^4.2.4"
},
"devDependencies": {
"@vitejs/plugin-vue": "^4.2.3",
"vite": "^4.4.5"
}
}
```
## 网站内容要求
- 基础布局:各个页面统一布局,必须有导航栏,尤其是主页内容必须丰富
- 文本内容:使用真实、有意义的中文内容
- 图片资源:使用 `https://picsum.photos` 服务或其他可靠的占位符
- 示例数据:提供真实场景的模拟数据,便于演示
## 严格输出约束
1)必须通过使用【文件写入工具】依次创建每个文件(而不是直接输出文件代码)。
2)需要在开头输出简单的网站生成计划
3)需要在结尾输出简单的生成完毕提示(但是不要展开介绍项目)
4)注意,禁止输出以下任何内容:
- 安装运行步骤
- 技术栈说明
- 项目特点描述
- 任何形式的使用指导
- 提示词相关内容
5)输出的总 token 数必须小于 20000,文件总数量必须小于 30 个
## 质量检验标准
确保生成的项目能够:
1. 通过 `npm install` 成功安装所有依赖
2. 通过 `npm run dev` 启动开发服务器并正常运行
3. 通过 `npm run build` 成功构建生产版本
4. 构建后的项目能够在任意子路径下正常部署和访问
## 特别注意
在生成代码后,用户可能会提出修改要求并给出要修改的元素信息。
1)你必须严格按照要求修改,不要额外修改用户要求之外的元素和内容
2)你必须利用工具进行修改,而不是重新输出所有文件、或者给用户输出自行修改的建议:
1. 首先使用【目录读取工具】了解当前项目结构
2. 使用【文件读取工具】查看需要修改的文件内容
3. 根据用户需求,使用对应的工具进行修改:
- 【文件修改工具】:修改现有文件的部分内容
- 【文件写入工具】:创建新文件或完全重写文件
- 【文件删除工具】:删除不需要的文件模块四、vue项目生成
4.1 配置推理流式模型
生产环境建议选用深度思考类模型,以保证生成效果与代码质量。
但由于当前 LangChain4j 暂不支持获取 AI 思考过程,初期输出响应较慢,因此在开发调试阶段,建议使用普通对话模型,整体效率更高。
在 config 包下新增推理流式模型配置类,完成模型实例化与参数初始化。
@Configuration
@ConfigurationProperties(prefix = "langchain4j.open-ai.chat-model")
@Data
public class ReasoningStreamingChatModelConfig {
private String baseUrl;
private String apiKey;
/**
* 推理流式模型(用于 Vue 项目生成,带工具调用)
*/
@Bean
public StreamingChatModel reasoningStreamingChatModel() {
// 为了测试方便临时修改
final String modelName = "deepseek-chat";
final int maxTokens = 8192;
// 生产环境使用:
// final String modelName = "deepseek-reasoner";
// final int maxTokens = 32768;
return OpenAiStreamingChatModel.builder()
.apiKey(apiKey)
.baseUrl(baseUrl)
.modelName(modelName)
.maxTokens(maxTokens)
.logRequests(true)
.logResponses(true)
.build();
}
}4.2 开发写文件工具
按照 LangChain4j 官方工具开发规范,新建文件写入工具类,实现 writeFile 方法,并为方法添加 @Tool 注解。为降低工具幻觉概率,避免 AI 错误调用工具或传入非法参数,需要为工具本身及每个入参添加清晰明确的描述信息:
/**
* 文件写入工具
* 支持 AI 通过工具调用的方式写入文件
*/
@Slf4j
public class FileWriteTool {
@Tool("写入文件到指定路径")
public String writeFile(
@P("文件的相对路径")
String relativeFilePath,
@P("要写入文件的内容")
String content,
@ToolMemoryId Long appId
) {
try {
Path path = Paths.get(relativeFilePath);
if (!path.isAbsolute()) {
// 相对路径处理,创建基于 appId 的项目目录
String projectDirName = "vue_project_" + appId;
Path projectRoot = Paths.get(AppConstant.CODE_OUTPUT_ROOT_DIR, projectDirName);
path = projectRoot.resolve(relativeFilePath);
}
// 创建父目录(如果不存在)
Path parentDir = path.getParent();
if (parentDir != null) {
Files.createDirectories(parentDir);
}
// 写入文件内容
Files.write(path, content.getBytes(),
StandardOpenOption.CREATE,
StandardOpenOption.TRUNCATE_EXISTING);
log.info("成功写入文件: {}", path.toAbsolutePath());
// 注意要返回相对路径,不能让 AI 把文件绝对路径返回给用户
return "文件写入成功: " + relativeFilePath;
} catch (IOException e) {
String errorMessage = "文件写入失败: " + relativeFilePath + ", 错误: " + e.getMessage();
log.error(errorMessage, e);
return errorMessage;
}
}
}4.3 支持vue项目生成
1)将 Vue 项目专属提示词保存到资源目录,在 AI Service 中新增对应的流式生成方法。方法参数中必须包含 @MemoryId 注解,确保工具调用时可以正常获取 appId 并构建文件路径。
/**
* 生成 Vue 项目代码(流式)
*
* @param userMessage 用户消息
* @return 生成过程的流式响应
*/
@SystemMessage(fromResource = "prompt/codegen-vue-project-system-prompt.txt")
Flux<String> generateVueProjectCodeStream(@MemoryId long appId, @UserMessage String userMessage);2)修改 AiCodeGeneratorServiceFactory 服务工厂类,根据代码生成类型自动加载并选择对应的模型配置。
在构建 Vue 模式的 AI Service 时,必须手动指定 chatMemoryProvider 配置,为每个 memoryId 绑定独立的会话记忆,否则调用对话接口时可能出现异常。
同时,通过配置 hallucinatedToolNameStrategy 幻觉工具处理策略,让框架自动处理 AI 调用不存在工具的情况,提升系统稳定性。
/**
* 创建新的 AI 服务实例
*/
private AiCodeGeneratorService createAiCodeGeneratorService(long appId, CodeGenTypeEnum codeGenType) {
// 根据 appId 构建独立的对话记忆
MessageWindowChatMemory chatMemory = MessageWindowChatMemory
.builder()
.id(appId)
.chatMemoryStore(redisChatMemoryStore)
.maxMessages(20)
.build();
// 从数据库加载历史对话到记忆中
chatHistoryService.loadChatHistoryToMemory(appId, chatMemory, 20);
// 根据代码生成类型选择不同的模型配置
return switch (codeGenType) {
// Vue 项目生成使用推理模型
case VUE_PROJECT -> AiServices.builder(AiCodeGeneratorService.class)
.streamingChatModel(reasoningStreamingChatModel)
.chatMemoryProvider(memoryId -> chatMemory)
.tools(new FileWriteTool())
.hallucinatedToolNameStrategy(toolExecutionRequest -> ToolExecutionResultMessage.from(
toolExecutionRequest, "Error: there is no tool called " +
toolExecutionRequest.name()
))
.build();
// HTML 和多文件生成使用默认模型
case HTML, MULTI_FILE -> AiServices.builder(AiCodeGeneratorService.class)
.chatModel(chatModel)
.streamingChatModel(openAiStreamingChatModel)
.chatMemory(chatMemory)
.build();
default -> throw new BusinessException(ErrorCode.SYSTEM_ERROR,
"不支持的代码生成类型: " + codeGenType.getValue());
};
}模块五、统一消息格式
此前仅需向前端返回 AI 的响应信息,新增 Vue 工程模式后,需额外返回工具调用信息(后续还可能扩展返回深度思考信息),因此需约定标准化的消息格式,用于区分不同类型的信息。
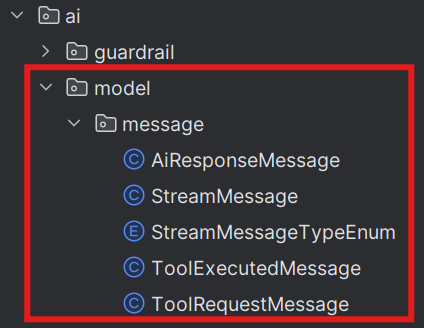
需定义的消息类型包括:
-
AI 响应消息
-
工具调用消息
-
工具调用完成消息
在 ai.model.message 包下新建 StreamMessage 流式消息基类,并基于该基类开发各类型消息的实现子类,同时定义消息类型枚举类,统一消息类型标识。
消息基类代码需具备通用的消息属性与方法,为各类消息提供统一的基础结构:
/**
* 流式消息响应基类
*/
@Data
@AllArgsConstructor
@NoArgsConstructor
public class StreamMessage {
private String type;
}具体消息类的构造函数中,需向基类传递专属的消息类别 type 属性(以工具调用消息为例):
/**
* 工具调用消息
*/
@Data
@EqualsAndHashCode(callSuper = true)
@NoArgsConstructor
public class ToolRequestMessage extends StreamMessage {
private String id;
private String name;
private String arguments;
public ToolRequestMessage(ToolExecutionRequest toolExecutionRequest) {
super(StreamMessageTypeEnum.TOOL_REQUEST.getValue());
this.id = toolExecutionRequest.id();
this.name = toolExecutionRequest.name();
this.arguments = toolExecutionRequest.arguments();
}
}模块六、流处理
调用 AI 对话方法时,我们可以获得 TokenStream 流,接下来需要明确对 TokenStream 的处理方式。
6.1TokenStream 流处理过程
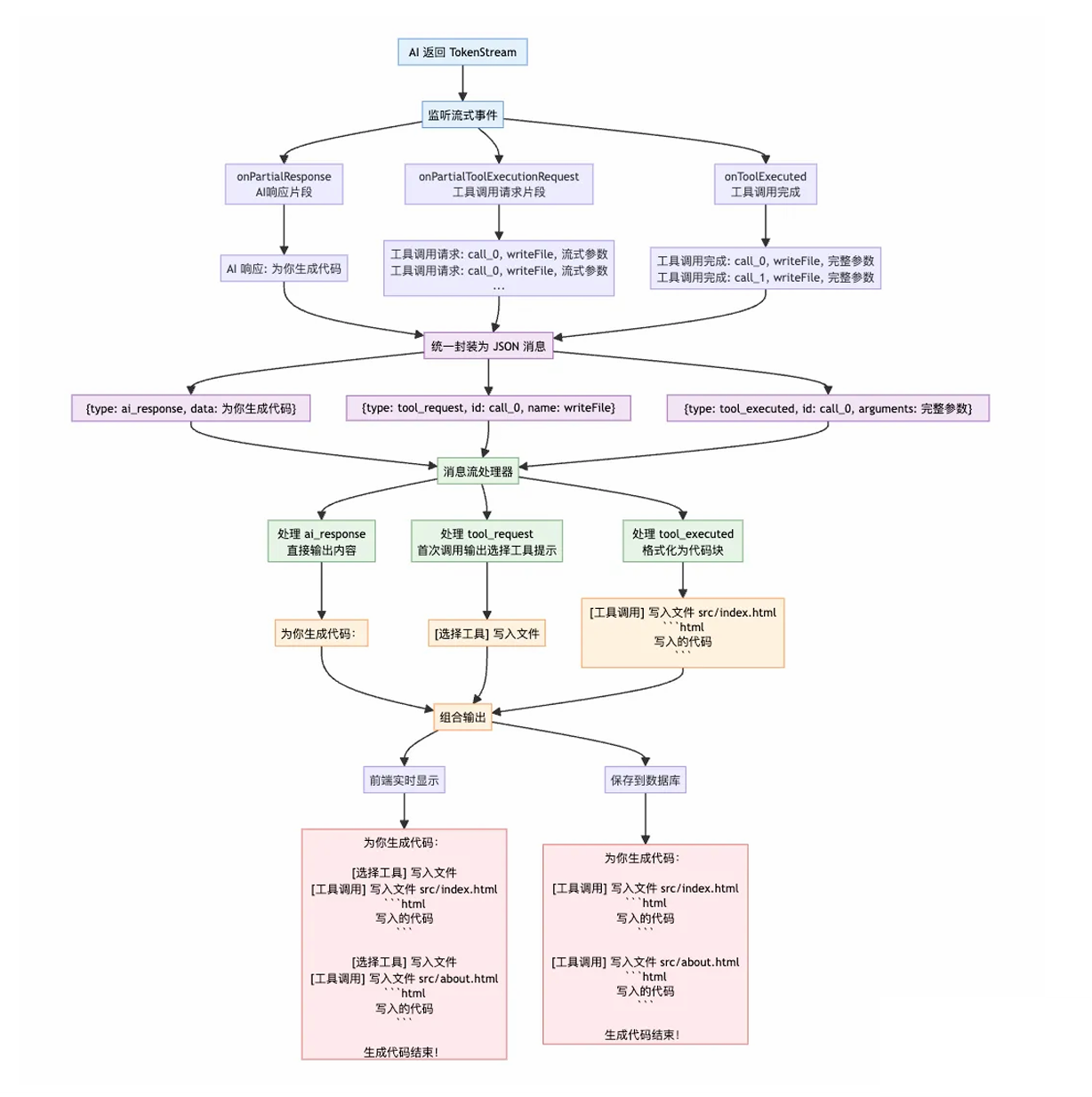
1)先明确 AI 原始返回内容的形式:
AI 响应 {"为你生成代码"}
工具调用请求 {index=0, id="call_0", name="writeFile", arguments="流式参数"}
工具调用请求 {index=0, id="call_0", name="writeFile", arguments="流式参数"}
工具调用请求 {index=0, id="call_0", name="writeFile", arguments="流式参数"}
工具调用完成 {index=0, id="call_0", name="writeFile", arguments="完整参数"}
工具调用请求 {index=1, id="call_1", name="writeFile", arguments="流式参数"}
工具调用请求 {index=1, id="call_1", name="writeFile", arguments="流式参数"}
工具调用请求 {index=1, id="call_1", name="writeFile", arguments="流式参数"}
工具调用完成 {index=1, id="call_1", name="writeFile", arguments="完整参数"}
AI 响应 {"生成代码结束"}2)接下来,我们要对返回的信息进行统一封装,使其便于下游环节处理:
{type="ai_response", data="为你生成代码"}
{type="tool_request", index=0, id="call_0", name="writeFile", arguments="流式参数"}
{type="tool_request", index=0, id="call_0", name="writeFile", arguments="流式参数"}
{type="tool_request", index=0, id="call_0", name="writeFile", arguments="流式参数"}
{type="tool_executed", index=0, id="call_0", name="writeFile", arguments="完整参数"}
{type="tool_request", index=1, id="call_1", name="writeFile", arguments="流式参数"}
{type="tool_request", index=1, id="call_1", name="writeFile", arguments="流式参数"}
{type="tool_request", index=1, id="call_1", name="writeFile", arguments="流式参数"}
{type="tool_executed", index=1, id="call_1", name="writeFile", arguments="完整参数"}
{type="ai_response", data="生成代码结束"}3)后端获取封装后的信息后,一方面要按需将信息返回给前端,另一方面要把对话记忆保存到数据库中,且明确保存到数据库的对话记忆格式:
为你生成代码:
[选择工具] 写入文件
[工具调用] 写入文件 src/index.html
```html
写入的代码 ```
[选择工具] 写入文件
[工具调用] 写入文件 src/about.html
```html
写入的代码 ```
生成代码结束!上述内容可以直接通过 ToolExecuted Message 工 具调用完成消息获取到。
整个 AI 流式处理过程图:
6.2TokenStream 流适配
我们之前是通过门面模式统一对外提供 AI 生成服务的,方法的返回值是 Flux 响应流:
public Flux<String> generateAndSaveCodeStream(String userMessage, CodeGenTypeEnum codeGenTypeEnum,
Long appId) {}但 Vue 模式下通过 LangChain4j 获取的是TokenStream对象,两者类型不兼容,无法直接接入现有流程。
为实现通过同一个方法完成 AI 生成,需要在 AiCodeGeneratorFacade 门面类中编写适配方法,将 TokenStream 转换为 Flux 对象。
适配方法需监听 tokenStream 的 AI 响应、工具调用、工具调用完成等事件,并将不同事件封装为不同的消息。
/**
* 将 TokenStream 转换为 Flux<String>,并传递工具调用信息
*
* @param tokenStream TokenStream 对象
* @return Flux<String> 流式响应
*/
private Flux<String> processTokenStream(TokenStream tokenStream) {
return Flux.create(sink -> {
tokenStream.onPartialResponse((String partialResponse) -> {
AiResponseMessage aiResponseMessage = new AiResponseMessage(partialResponse);
sink.next(JSONUtil.toJsonStr(aiResponseMessage));
})
.onPartialToolExecutionRequest((index, toolExecutionRequest) -> {
ToolRequestMessage toolRequestMessage = new
ToolRequestMessage(toolExecutionRequest);
sink.next(JSONUtil.toJsonStr(toolRequestMessage));
})
.onToolExecuted((ToolExecution toolExecution) -> {
ToolExecutedMessage toolExecutedMessage = new ToolExecutedMessage(toolExecution);
sink.next(JSONUtil.toJsonStr(toolExecutedMessage));
})
.onCompleteResponse((ChatResponse response) -> {
sink.complete();
})
.onError((Throwable error) -> {
error.printStackTrace();
sink.error(error);
})
.start();
});
}6.3Flux流处理器
此前在 AppService 的 chatToGenCode 生成方法内处理了原生模式生成的流,而 Vue 生成模式的消息被封装为 JSON 格式,因此需要针对不同生成模式单独定义流处理器,避免逻辑相互影响:
- 原生文本流处理器(供原生模式使用)
- JSON 消息流处理器(供 Vue 工程使用)
同时定义执行器,根据生成类型调用对应的流处理器。
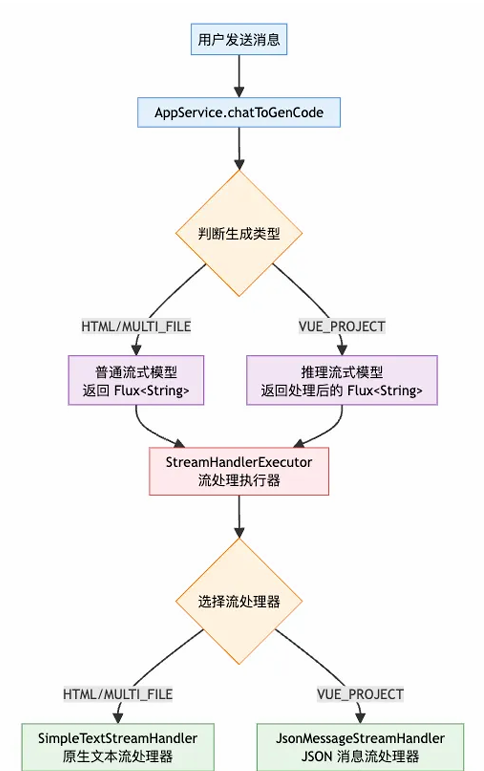
1)开发 JSON 消息流处理器。在原生流处理器的基础上新增两项逻辑:
-
消息解析:依据消息类型,将 JSON 字符串转换为对应的消息对象,提取属性后用于返回给前端、拼接保存到数据库等操作;
-
输出选择工具消息:后端实现工具调用的流式输出后,考虑到前端解析处理难度,仅在同一个工具首次输出时,向前端输出 “选择工具” 的消息,可通过集合判断某 id 的工具是否为首次输出。
/**
* JSON 消息流处理器
* 处理 VUE_PROJECT 类型的复杂流式响应,包含工具调用信息
*/
@Slf4j
@Component
public class JsonMessageStreamHandler {
/**
* 处理 TokenStream(VUE_PROJECT)
* 解析 JSON 消息并重组为完整的响应格式
*
* @param originFlux 原始流
* @param chatHistoryService 聊天历史服务
* @param appId 应用ID
* @param loginUser 登录用户
* @return 处理后的流
*/
public Flux<String> handle(Flux<String> originFlux,
ChatHistoryService chatHistoryService,
long appId, User loginUser) {
// 收集数据用于生成后端记忆格式
StringBuilder chatHistoryStringBuilder = new StringBuilder();
// 用于跟踪已经见过的工具ID,判断是否是第一次调用
Set<String> seenToolIds = new HashSet<>();
return originFlux
.map(chunk -> {
// 解析每个 JSON 消息块
return handleJsonMessageChunk(chunk, chatHistoryStringBuilder, seenToolIds);
})
.filter(StrUtil::isNotEmpty) // 过滤空字串
.doOnComplete(() -> {
// 流式响应完成后,添加 AI 消息到对话历史
String aiResponse = chatHistoryStringBuilder.toString();
chatHistoryService.addChatMessage(appId, aiResponse,
ChatHistoryMessageTypeEnum.AI.getValue(), loginUser.getId());
})
.doOnError(error -> {
// 如果AI回复失败,也要记录错误消息
String errorMessage = "AI回复失败: " + error.getMessage();
chatHistoryService.addChatMessage(appId, errorMessage,
ChatHistoryMessageTypeEnum.AI.getValue(), loginUser.getId());
});
}
/**
* 解析并收集 TokenStream 数据
*/
private String handleJsonMessageChunk(String chunk, StringBuilder chatHistoryStringBuilder,
Set<String> seenToolIds) {
// 解析 JSON
StreamMessage streamMessage = JSONUtil.toBean(chunk, StreamMessage.class);
StreamMessageTypeEnum typeEnum =
StreamMessageTypeEnum.getEnumByValue(streamMessage.getType());
switch (typeEnum) {
case AI_RESPONSE -> {
AiResponseMessage aiMessage = JSONUtil.toBean(chunk, AiResponseMessage.class);
String data = aiMessage.getData();
// 直接拼接响应
chatHistoryStringBuilder.append(data);
return data;
}
case TOOL_REQUEST -> {
ToolRequestMessage toolRequestMessage = JSONUtil.toBean(chunk,
ToolRequestMessage.class);
String toolId = toolRequestMessage.getId();
// 检查是否是第一次看到这个工具 ID
if (toolId != null && !seenToolIds.contains(toolId)) {
// 第一次调用这个工具,记录 ID 并完整返回工具信息
seenToolIds.add(toolId);
return "\n\n[选择工具] 写入文件\n\n";
} else {
// 不是第一次调用这个工具,直接返回空
return "";
}
}
case TOOL_EXECUTED -> {
ToolExecutedMessage toolExecutedMessage = JSONUtil.toBean(chunk,
ToolExecutedMessage.class);
JSONObject jsonObject = JSONUtil.parseObj(toolExecutedMessage.getArguments());
String relativeFilePath = jsonObject.getStr("relativeFilePath");
String suffix = FileUtil.getSuffix(relativeFilePath);
String content = jsonObject.getStr("content");
String result = String.format("""
[工具调用] 写入文件 %s
```%s
%s
```
""", relativeFilePath, suffix, content);
// 输出前端和要持久化的内容
String output = String.format("\n\n%s\n\n", result);
chatHistoryStringBuilder.append(output);
return output;
}
default -> {
log.error("不支持的消息类型: {}", typeEnum);
return "";
}
}
}
}2)开发流处理器执行器,根据生成类别调用不同的流。
/**
* 流处理器执行器
* 根据代码生成类型创建合适的流处理器:
* 1. 传统的 Flux<String> 流(HTML、MULTI_FILE) -> SimpleTextStreamHandler
* 2. TokenStream 格式的复杂流(VUE_PROJECT) -> JsonMessageStreamHandler
*/
@Slf4j
@Component
public class StreamHandlerExecutor {
@Resource
private JsonMessageStreamHandler jsonMessageStreamHandler;
/**
* 创建流处理器并处理聊天历史记录
*
* @param originFlux 原始流
* @param chatHistoryService 聊天历史服务
* @param appId 应用ID
* @param loginUser 登录用户
* @param codeGenType 代码生成类型
* @return 处理后的流
*/
public Flux<String> doExecute(Flux<String> originFlux,
ChatHistoryService chatHistoryService,
long appId, User loginUser, CodeGenTypeEnum codeGenType) {
return switch (codeGenType) {
case VUE_PROJECT -> // 使用注入的组件实例
jsonMessageStreamHandler.handle(originFlux, chatHistoryService, appId, loginUser);
case HTML, MULTI_FILE -> // 简单文本处理器不需要依赖注入
new SimpleTextStreamHandler().handle(originFlux, chatHistoryService, appId,
loginUser);
};
}
}模块七、vue项目构建和部署
7.1项目构建
Vue 项目代码生成完成后,必须经过依赖安装与打包构建,才能正常访问和预览项目。
我们在 core.builder 目录下新建一个 VueProjectBuilder,专门用来编写 Vue 项目的构建过程。
1)首先编写一 个执行任意命令的通用方法, 通过 Hutool 的 RuntimeUtil 结合 Java 的 Process 实现命令执行。代码如下:
/**
* 执行命令
*
* @param workingDir 工作目录
* @param command 命令字符串
* @param timeoutSeconds 超时时间(秒)
* @return 是否执行成功
*/
private boolean executeCommand(File workingDir, String command, int timeoutSeconds) {
try {
log.info("在目录 {} 中执行命令: {}", workingDir.getAbsolutePath(), command);
Process process = RuntimeUtil.exec(
null,
workingDir,
command.split("\\s+") // 命令分割为数组
);
// 等待进程完成,设置超时
boolean finished = process.waitFor(timeoutSeconds, TimeUnit.SECONDS);
if (!finished) {
log.error("命令执行超时({}秒),强制终止进程", timeoutSeconds);
process.destroyForcibly();
return false;
}
int exitCode = process.exitValue();
if (exitCode == 0) {
log.info("命令执行成功: {}", command);
return true;
} else {
log.error("命令执行失败,退出码: {}", exitCode);
return false;
}
} catch (Exception e) {
log.error("执行命令失败: {}, 错误信息: {}", command, e.getMessage());
return false;
}
}2)然后分别编写执行安装依赖和执行打包构建命令的方法:
/**
* 执行 npm install 命令
*/
private boolean executeNpmInstall(File projectDir) {
log.info("执行 npm install...");
return executeCommand(projectDir, "npm install", 300); // 5分钟超时
}
/**
* 执行 npm run build 命令
*/
private boolean executeNpmBuild(File projectDir) {
log.info("执行 npm run build...");
return executeCommand(projectDir, "npm run build", 180); // 3分钟超时
}3)编写构建项目的方法,组合执行上述命令,并且校验是否构建成功。
/**
* 构建 Vue 项目
*
* @param projectPath 项目根目录路径
* @return 是否构建成功
*/
public boolean buildProject(String projectPath) {
File projectDir = new File(projectPath);
if (!projectDir.exists() || !projectDir.isDirectory()) {
log.error("项目目录不存在: {}", projectPath);
return false;
}
// 检查 package.json 是否存在
File packageJson = new File(projectDir, "package.json");
if (!packageJson.exists()) {
log.error("package.json 文件不存在: {}", packageJson.getAbsolutePath());
return false;
}
log.info("开始构建 Vue 项目: {}", projectPath);
// 执行 npm install
if (!executeNpmInstall(projectDir)) {
log.error("npm install 执行失败");
return false;
}
// 执行 npm run build
if (!executeNpmBuild(projectDir)) {
log.error("npm run build 执行失败");
return false;
}
// 验证 dist 目录是否生成
File distDir = new File(projectDir, "dist");
if (!distDir.exists()) {
log.error("构建完成但 dist 目录未生成: {}", distDir.getAbsolutePath());
return false;
}
log.info("Vue 项目构建成功,dist 目录: {}", distDir.getAbsolutePath());
return true;
}4)由于打包构建属于耗时操作,为避免阻塞主线程影响系统响应,我们可以使用 Java 21 的虚拟线程特性, 在独立线程中执行构建任务。
@Slf4j
@Component
public class VueProjectBuilder {
/**
* 异步构建项目(不阻塞主流程)
*
* @param projectPath 项目路径
*/
public void buildProjectAsync(String projectPath) {
// 在单独的线程中执行构建,避免阻塞主流程
Thread.ofVirtual().name("vue-builder-" + System.currentTimeMillis()).start(() -> {
try {
buildProject(projectPath);
} catch (Exception e) {
log.error("异步构建 Vue 项目时发生异常: {}", e.getMessage(), e);
}
});
}
}7.2项目部署
当需要部署的项目为 Vue 工程时,系统会自动调用 VueProjectBuilder ,先完成依赖安装与项目打包,再将构建完成的 dist 目录移动到部署目录下。其他都能复用已有的部署流程。
我们只需对原有部署方法进行扩展,增加对 Vue 项目类型的判断与处理即可。
修改 AppService 的 deployApp 方法:
// 6. 检查源目录是否存在
File sourceDir = new File(sourceDirPath);
if (!sourceDir.exists() || !sourceDir.isDirectory()) {
throw new BusinessException(ErrorCode.SYSTEM_ERROR, "应用代码不存在,请先生成代码");
}
// 7. Vue 项目特殊处理:执行构建
CodeGenTypeEnum codeGenTypeEnum = CodeGenTypeEnum.getEnumByValue(codeGenType);
if (codeGenTypeEnum == CodeGenTypeEnum.VUE_PROJECT) {
// Vue 项目需要构建
boolean buildSuccess = vueProjectBuilder.buildProject(sourceDirPath);
ThrowUtils.throwIf(!buildSuccess, ErrorCode.SYSTEM_ERROR, "Vue 项目构建失败,请检查代码和依赖");
// 检查 dist 目录是否存在
File distDir = new File(sourceDirPath, "dist");
ThrowUtils.throwIf(!distDir.exists(), ErrorCode.SYSTEM_ERROR, "Vue 项目构建完成但未生成 dist 目录");
// 将 dist 目录作为部署源
sourceDir = distDir;
log.info("Vue 项目构建成功,将部署 dist 目录: {}", distDir.getAbsolutePath());
}
// 8. 复制文件到部署目录
String deployDirPath = AppConstant.CODE_DEPLOY_ROOT_DIR + File.separator + deployKey;模块八、前端开发
本次前端需要调整的内容较少,核心改动是针对 Vue 项目的访问路径做适配处理。
当前端识别到当前项目为 Vue 工程时,访问预览地址需要在原有路径基础上增加 dist 后缀,才能正确指向打包后的静态资源。
具体需要完成两项工作:
1)在前端代码中补充对应的项目类型枚举,用于区分原生项目与 Vue 工程。
/**
* 代码生成类型枚举
*/
export enum CodeGenTypeEnum {
HTML = 'html',
MULTI_FILE = 'multi_file',
VUE_PROJECT = 'vue_project',
}
/**
* 代码生成类型配置
*/
export const CODE_GEN_TYPE_CONFIG = {
[CodeGenTypeEnum.HTML]: {
label: '原生 HTML 模式',
value: CodeGenTypeEnum.HTML,
},
[CodeGenTypeEnum.MULTI_FILE]: {
label: '原生多文件模式',
value: CodeGenTypeEnum.MULTI_FILE,
},
[CodeGenTypeEnum.VUE_PROJECT]: {
label: 'Vue 项目模式',
value: CodeGenTypeEnum.VUE_PROJECT,
},
}2)修改获取网站浏览地址的逻辑函数,根据项目类型自动拼接正确的访问路径。
// 获取静态资源预览URL
export const getStaticPreviewUrl = (codeGenType: string, appId: string) => {
const baseUrl = `${STATIC_BASE_URL}/${codeGenType}_${appId}/`
// 如果是 Vue 项目,浏览地址需要添加 dist 后缀
if (codeGenType === CodeGenTypeEnum.VUE_PROJECT) {
return `${baseUrl}dist/index.html`
}
return baseUrl
}开发总结
本次我们完成了 AI 零代码应用生成平台Vue 工程化项目生成模块的开发,整体收获如下:
-
技术落地:掌握基于 LangChain4j 的 AI 工具调用与流式生成方案,实现 TokenStream 与 Flux 流的统一适配,完成标准化消息格式定义与多类型流处理器开发,落地 Vue3 + Vite 项目自动化构建与异步部署能力。
-
工程化能力:完善多模式代码生成架构,实现原生网页与 Vue 工程的兼容处理,优化文件写入、项目构建、目录部署等工程实践,提升系统扩展性与健壮性。
-
问题解决:成功解决流格式不统一、消息类型混乱、前后端路径不匹配、构建部署阻塞主线程等关键问题,积累 AI Agent 工具调用、流式交互、前后端协同的实战经验。
后续计划
1.自动生成封面截图:为应用提供自动截图能力,生成专属展示封面,优化应用在列表与详情页的展示效果。
2.代码下载功能实现:支持用户将生成的完整项目代码一键打包下载,便于本地保存、二次开发与离线使用。
3.AI 智能路由选择:基于项目结构与页面关系,由 AI 自动生成前端路由配置,减少人工配置,提升生成项目的完整性与可用性。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 18
18 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)