时序注意力 + 跨帧对齐重磅突破!荣登Nature顶级子刊!
分享一个视频理解领域的核心技术方向:时序注意力 + 跨帧对齐。有人问直接用3D卷积不就行了?注意力机制的优势在于长距离依赖建模和动态权重分配,在长视频场景下优势明显。
现在顶会对时空建模方法审稿更严格,简单的全局注意力因计算复杂度问题直接pass。可以重点关注分解式时空注意力(降低复杂度)、对齐引导注意力(解决帧间运动)、隐式可学习对齐(免显式匹配)这些创新路线。NeurIPS 2022的ATA、ICCV 2023的ILA都是不错的学习案例。
为帮助更高效定位创新点,整理了该方向的创新点挖掘指南 + baseline复现代码(含注释) + 审稿避坑清单,从选题到复现到投稿一条龙,需要可取~~

标题: MULTIMODAL SELF-ATTENTION NETWORK WITH TEMPORAL ALIGNMENT FOR AUDIO-VISUAL EMOTION RECOGNITION
-
关键词: Multimodal emotion recognition, Transformer encoder, temporal alignment, RoPE, cross-temporal matching loss
-
单位: Korea Advanced Institute of Science and Technology (KAIST)
-
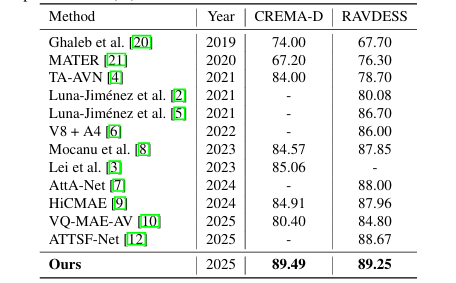
方法: 该论文针对音视频情感识别(AVER)中跨模态帧率不匹配和时间同步不足问题,提出了一个基于Transformer的框架。该框架通过多模态自注意力编码器在共享嵌入空间中同时捕捉模态内和模态间依赖。为解决异构采样率问题,引入了时间对齐旋转位置嵌入(TaRoPE)隐式同步音视频token,并利用跨时间匹配(CTM)损失显式强制时间一致性。
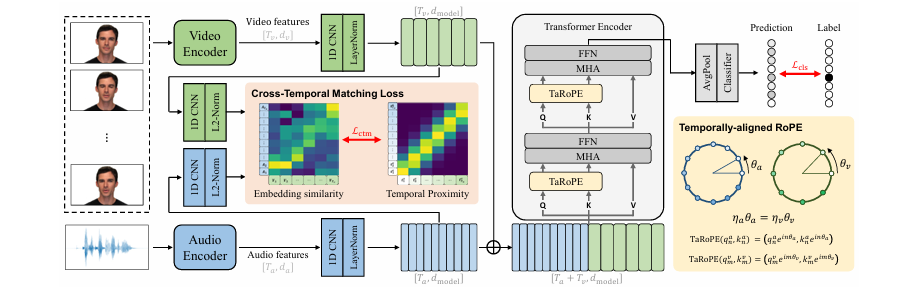
- 创新点:
-
提出/构建了统一的多模态自注意力编码器,实现了在共享特征空间中同时捕捉模态内和模态间依赖。
-
创新地引入/设计了Temporally-aligned Rotary Position Embeddings (TaRoPE),解决了音视频模态间异构采样率的时间对齐问题。
-
通过Cross-Temporal Matching (CTM) 损失,将时间接近的音视频对的嵌入相似度强制统一,解决了跨模态时间不一致性。
-
首次将TaRoPE与CTM损失结合,验证了显式处理帧率不匹配有助于保留时间线索并增强跨模态融合。
-
标题: DashFusion: Dual-stream Alignment with Hierarchical Bottleneck Fusion for Multimodal Sentiment Analysis
-
关键词: multimodal sentiment analysis, multimodal alignment, multimodal fusion, contrastive learning
-
单位: Beijing University of Posts and Telecommunications
-
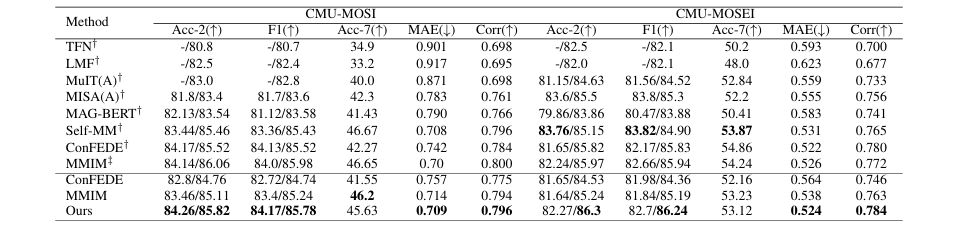
方法: 该论文提出了DashFusion框架,旨在解决多模态情感分析(MSA)中的对齐和融合挑战。其核心是双流对齐模块,通过跨模态注意力实现帧级时间对齐,并利用对比学习进行语义对齐。此外,引入监督对比学习以增强模态特征辨别力,并通过分层瓶颈融合机制,在信息瓶颈概念的启发下,逐步整合多模态信息,同时平衡性能与计算效率。
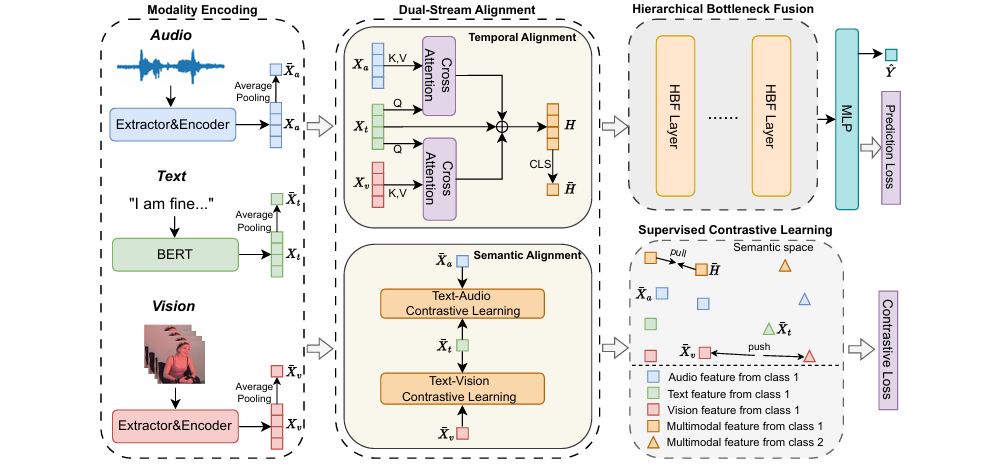
- 创新点:
-
提出/构建了双流对齐策略,实现了多模态数据在时间和语义维度上的全面对齐。
-
创新地引入/设计了分层瓶颈融合(HBF)方法,解决了多模态融合中冗余信息和计算效率的问题。
-
通过监督对比学习,将模态特征与标签信息相结合,增强了特征的判别性和模型的鲁棒性。
-
首次将双流对齐与分层瓶颈融合结合,验证了在多模态情感分析任务上显著优于现有SOTA方法。
-


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 9
9 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)