基本数据结构的编写和日志库的认识和封装
1.准备工作:
上面的都是在进行测试和普及 现在就要开始编写基本的数据结构了
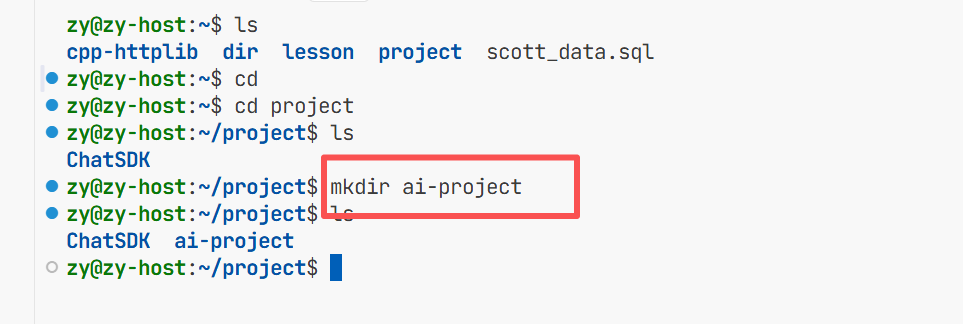
首先在项目路径下创建一个ai-project的目录用来存储这个项目
然后进入到这个目录 再从远端创建一个这个项目的仓库 然后git clone本地相当于在这个仓库里面存放我们编写的代码
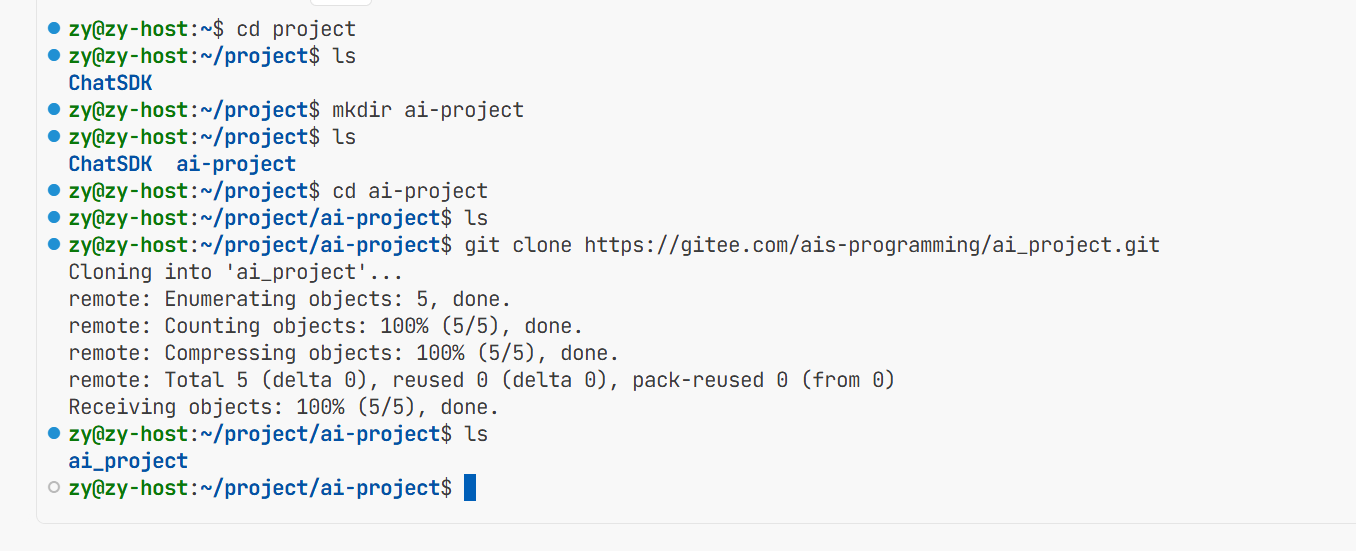
此时就从远端仓库拉取下来了 然后我们之后就在ai_project这个目录下编写我们的代码 注意我在创建的时候犯了小失误 两个名字是差不多的只是-和_的区别 所以要注意一下
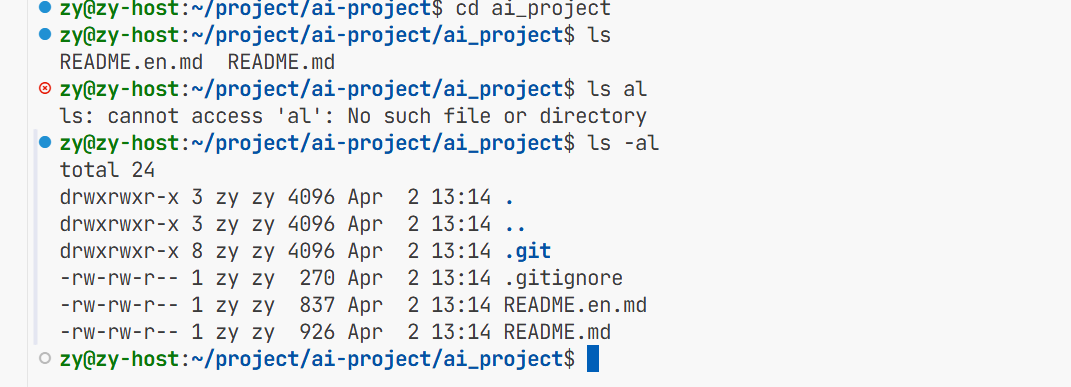
此时我们再进入这个远程仓库这个目录 可以发现 有git这个目录 但是我们不想让他在trae出现 所以我们再创建一个目录
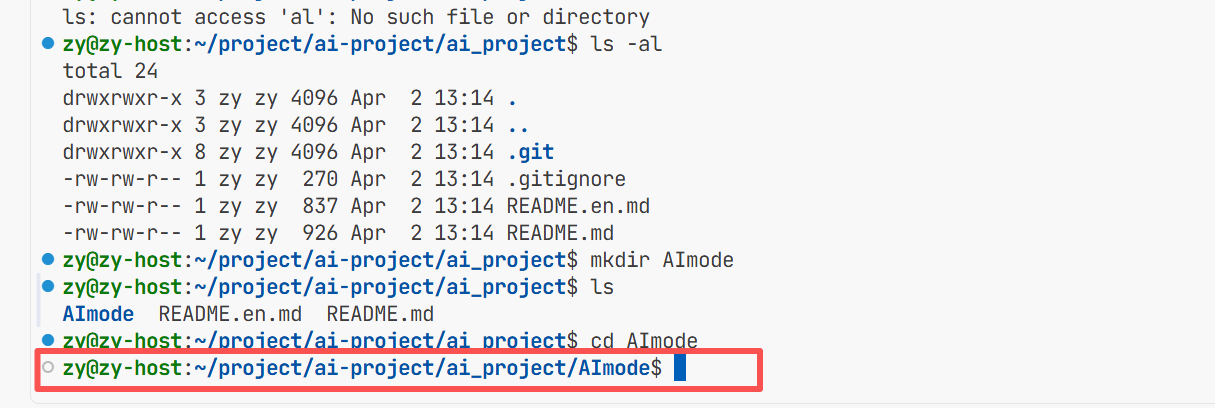
注意以后我们就在此目录下写我们接入模型的代码了

2.基本数据结构的编写
在这个目录下创建一个sdk文件夹用来放置我们的源文件和头文件 我们做到头文件与源文件的分离
方便我们开发完编译成静态库 当我们运行安装时只需要拷贝我们的静态的头文件和源文件即可
1.在include下创建一个common.h的头文件用来放我们所需要的数据库
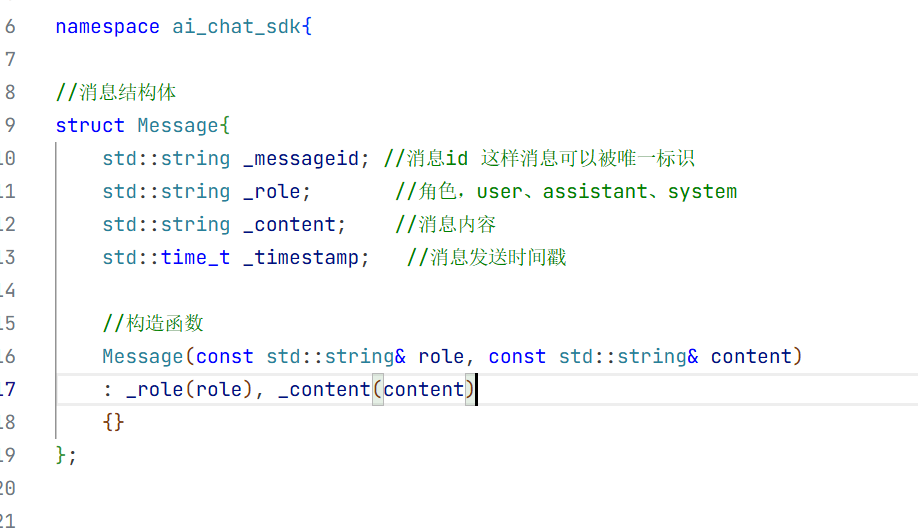
此时我们构造函数只需要初始化角色和用户输入内容即可。
2.大模型的公共配置参数的结构体


3.通过API方式接入的云端大模型

4.最后完成页面中大模型的基本信息介绍
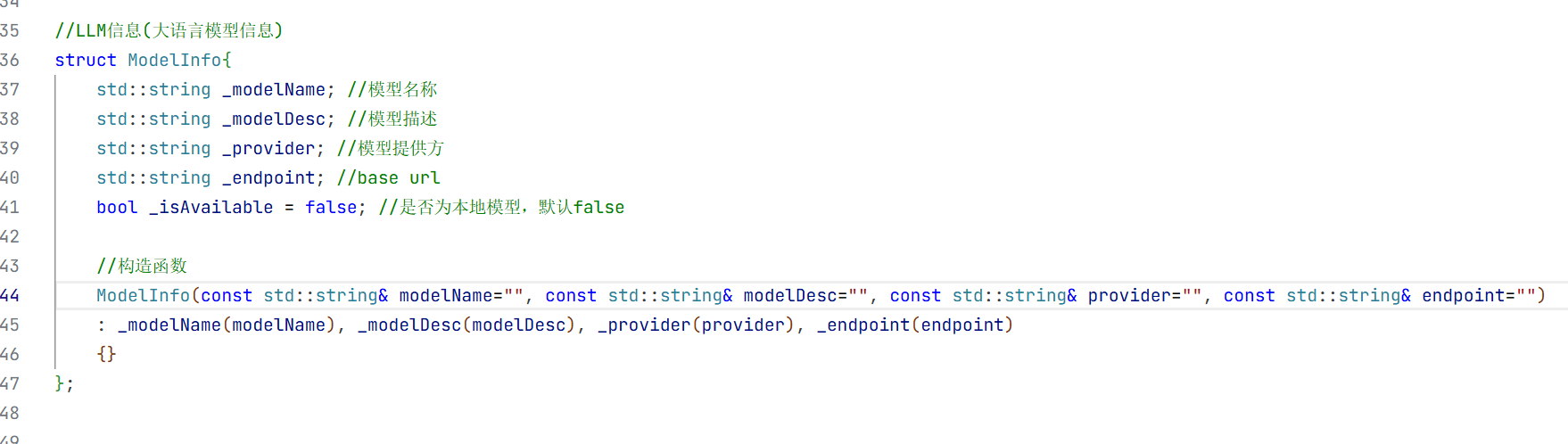
5.会话消息结构体
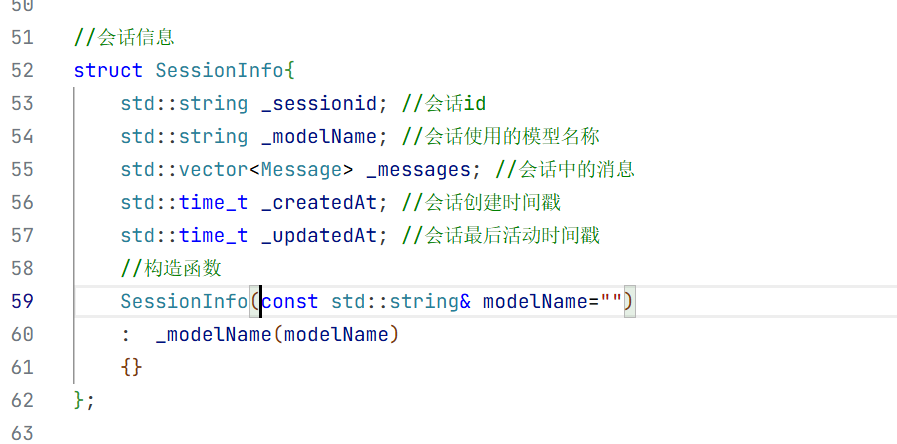
在构造方法中我们只需要初始化大模型名称即可 因为其他的只有这个对话开始的时候你才知道是什么时候开始的
#pragma once
#include <string>
#include <ctime>
#include <vector>
namespace ai_chat_sdk{
//消息结构体
struct Message{
std::string _messageid; //消息id 这样消息可以被唯一标识
std::string _role; //角色,user、assistant、system
std::string _content; //消息内容
std::time_t _timestamp; //消息发送时间戳
//构造函数
Message(const std::string& role, const std::string& content)
: _role(role), _content(content)
{}
};
//大模型公共配置参数
struct Config{
std::string _modelid; //模型id
double _temperature = 0.7; //温度参数
int _max_tokens = 2048; //最大token数
};
//通过API方式调用云端大模型
struct APIConfig: public Config{
std::string _apikey; //api key
};
//通过ollama方式调用本地大模型
//LLM信息(大语言模型信息)
struct ModelInfo{
std::string _modelName; //模型名称
std::string _modelDesc; //模型描述
std::string _provider; //模型提供方
std::string _endpoint; //base url
bool _isAvailable = false; //是否为本地模型,默认false
//构造函数
ModelInfo(const std::string& modelName="", const std::string& modelDesc="", const std::string& provider="", const std::string& endpoint="")
: _modelName(modelName), _modelDesc(modelDesc), _provider(provider), _endpoint(endpoint)
{}
};
//会话信息
struct SessionInfo{
std::string _sessionid; //会话id
std::string _modelName; //会话使用的模型名称
std::vector<Message> _messages; //会话中的消息
std::time_t _createdAt; //会话创建时间戳
std::time_t _updatedAt; //会话最后活动时间戳
//构造函数
SessionInfo(const std::string& modelName="")
: _modelName(modelName)
{}
};
}//end namespace ai_chat_sdk这就是我们接入大模型所需要的最基本的结构体 这样就创建好了。
3.日志
1.日志的概念:
当我们运行执行的时候 不管是报错还是成功运行 都将这些信息存储在日志中 不管是后续的调试还是测试 这样都可以了解程序运行时发生了什么 ,通常将日志信息写入控制台或者文件中或者远程服务器中。
2.日志的级别:
1.TRACE:
日志的级别分为TRACE:最详细的跟踪信息 用于追踪程序的执行的流程 比如函数的进入和退出。
2.DEBUG:
调试信息 ,帮助开发人员理解程序运行的状态比如监控执行的关键节点,重要的变量状态。
3 .INFO:
重要的运行信息 反映程序的正常状态比如系统启动成功,配置文件加载成功
4.WARN:
潜在的问题信息 但是不影响程序的执行 比如非关键性错误
5.ERRO:
表示程序运行出错,影响特定功能,但程序仍正常执行 比如 文件打开失败 比如数据库连接失败
6.CRITICAL:
严重错误导致系统崩溃无法运行 比如内存耗尽,数据损坏,导致一些致命错误。
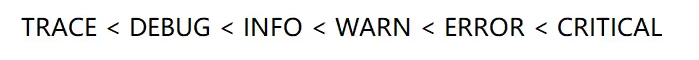
3.日志存储管理:
⽇志库可以将⽇志信息输出到多种⽬标,如控制台、⽂件、远程服务器等。同时,⽇志库通常⽀持
⽇志⽂件的轮转、压缩和归档,⽅便⻓期存储和管理。
⽐如设置⽇志⽂件每天⾃动轮转,并在⽂件⼤⼩超过⼀定阈值时进⾏压缩归档。这有助于避免⽇志
⽂件过⼤导致磁盘空间不⾜。 ⽽ std::cout 只能将信息输出到控制台,⽆法直接⽀持⽇志⽂件的存
储和管理功能。
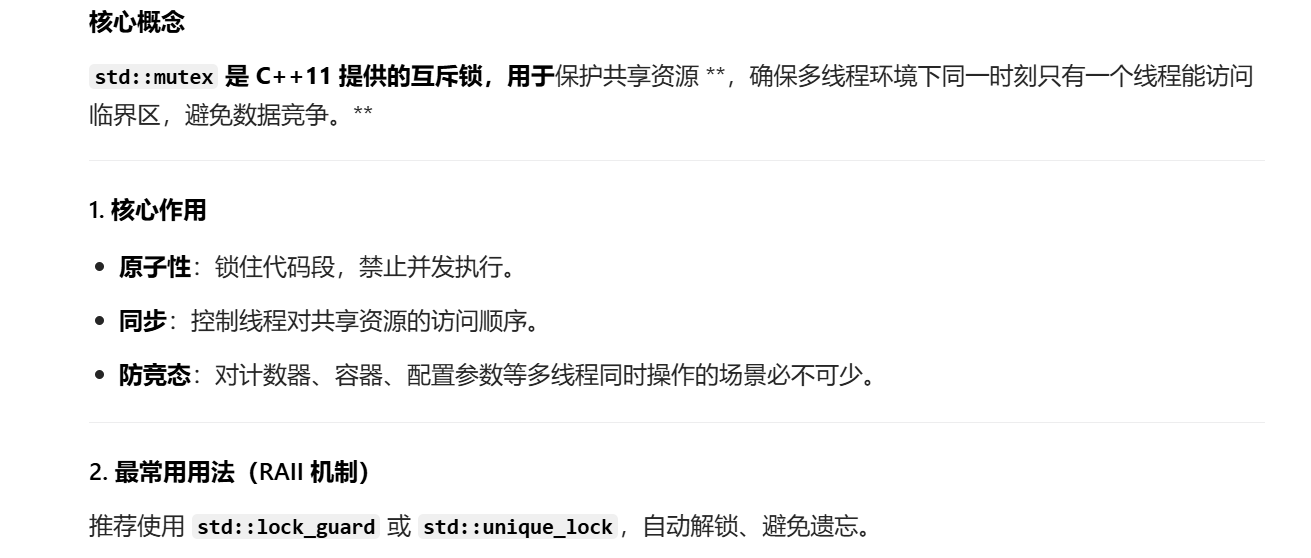
4.线程安全:
在多线程程序中,⽇志库通常提供了线程安全的机制,确保⽇志输出不会出现冲突或数据错乱。在
多线程环境下,多个线程可能同时尝试写⼊⽇志。⽇志库通过锁或其他同步机制确保⽇志输出的线
程安全。 std::cout 在多线程环境下可能会出现⽇志输出混乱的问题,需要开发者⼿动实现线程安全机制。
5.日志库的封装:
本项⽬采⽤google的spdlog⽇志库进⾏⽇志管理,为了使⽤⽅便,对spdlog库采⽤单例模式进
⾏简单封装。
首先在这两个文件下创建两个util的工具使用的文件夹 当后续有什么工具需要封装的时候 往这个文件夹下面放就行了。
1.日志库头文件的封装:
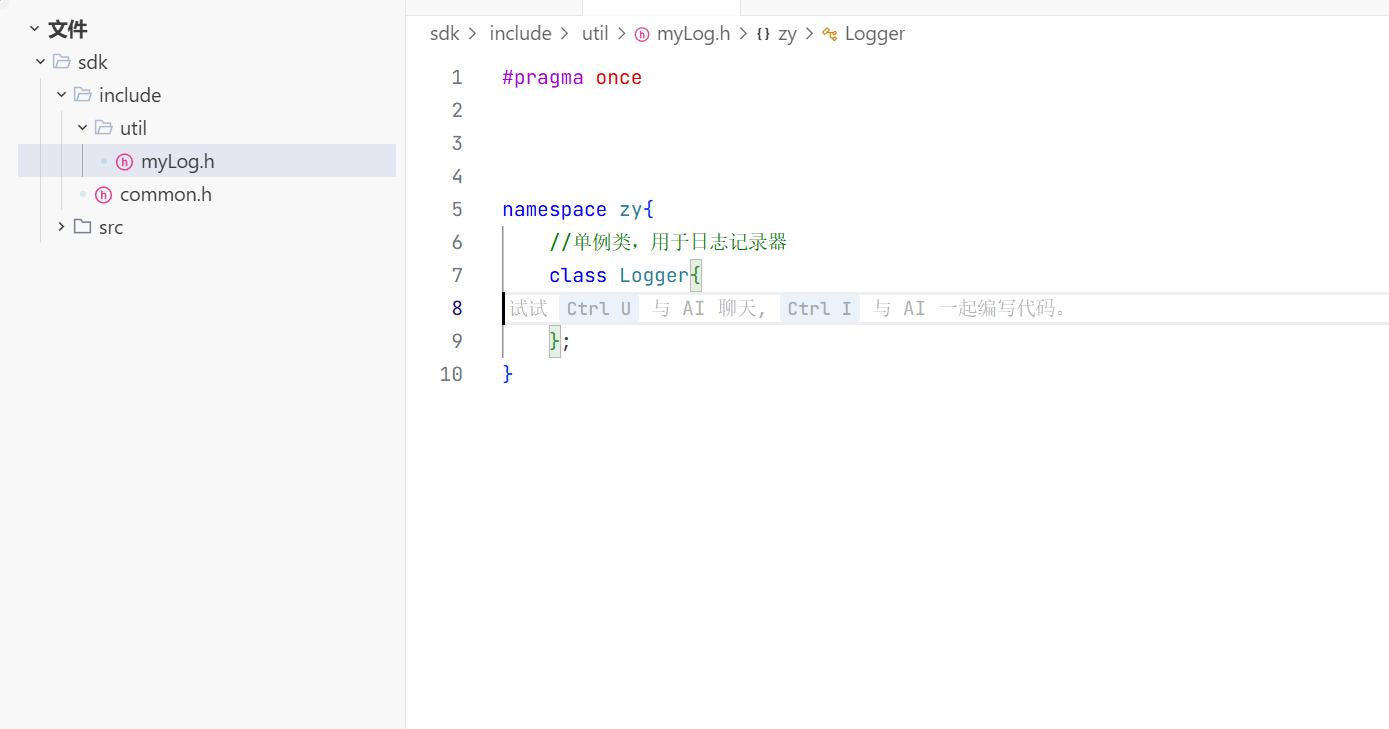
封装这个myLog.h时我们要用单例类去封装



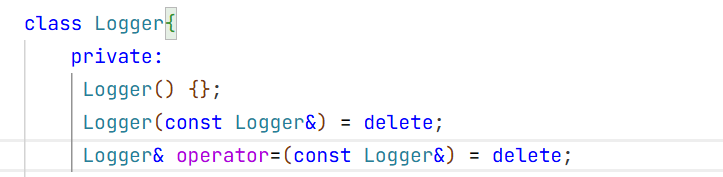
构造函数私有化并且 赋值重载和拷贝构造要被禁用掉。
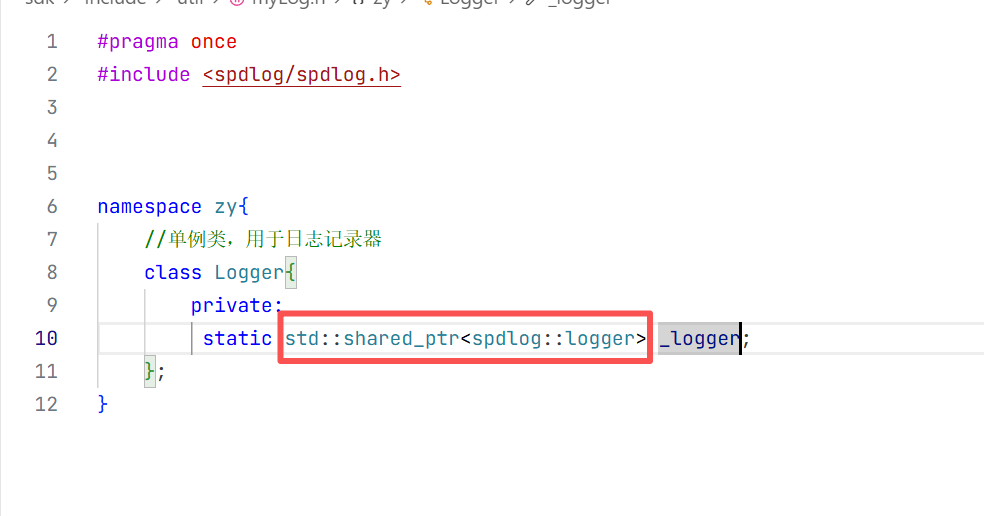
这里智能指针去管理spdlog去实现的日志器


还要去封装日志的初始化 第一个参数是日志名称 第二个参数是到达什么级别输入到哪个文件中,第三个参数是日志的级别。

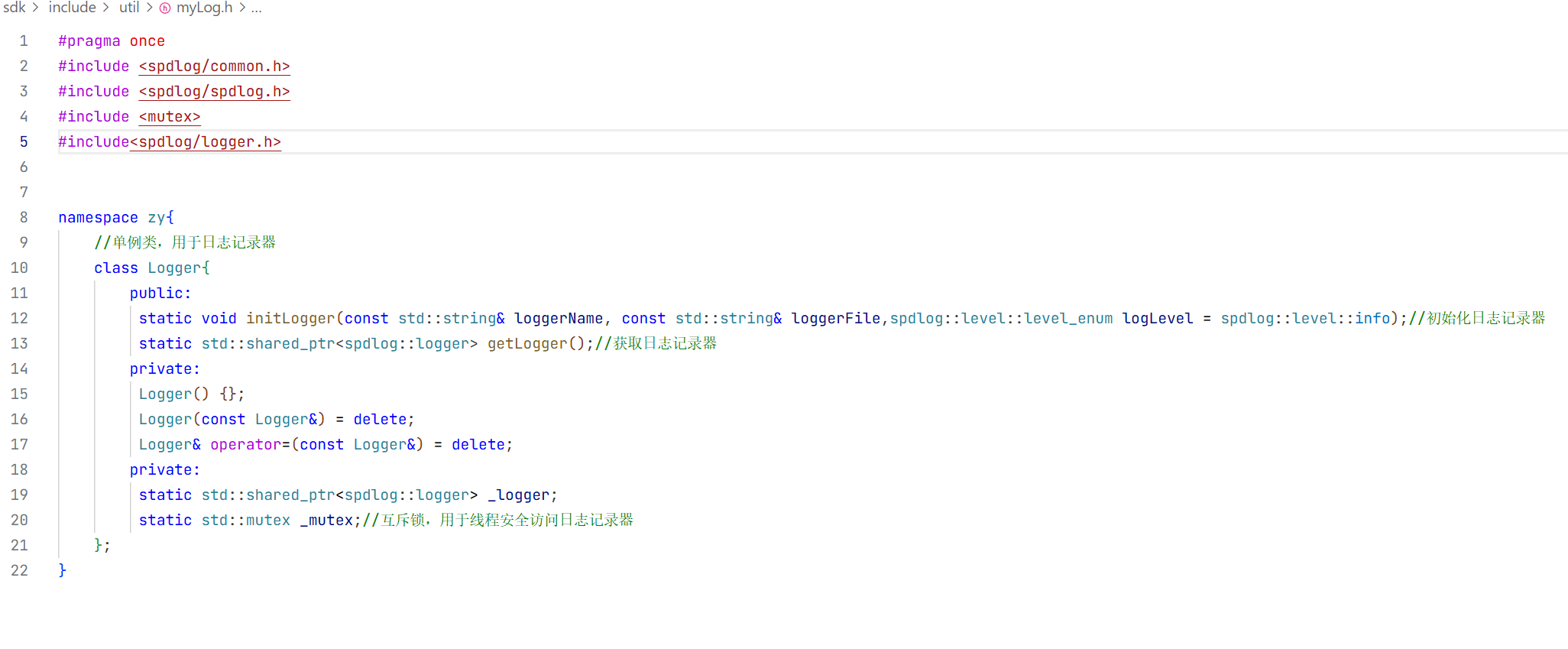
这样我们日志库的头文件就封装好了
接下来就要去封装源文件了:
2.日志库源文件的封装:
因为头文件和源文件我们要分开封装所以我们这里还要让他去指定路径找这个头文件
日志格式的设置:

调用fmt的库 这样你打印的

花括号就是占位符 这就是对应日志格式设置里对应的行号+名称
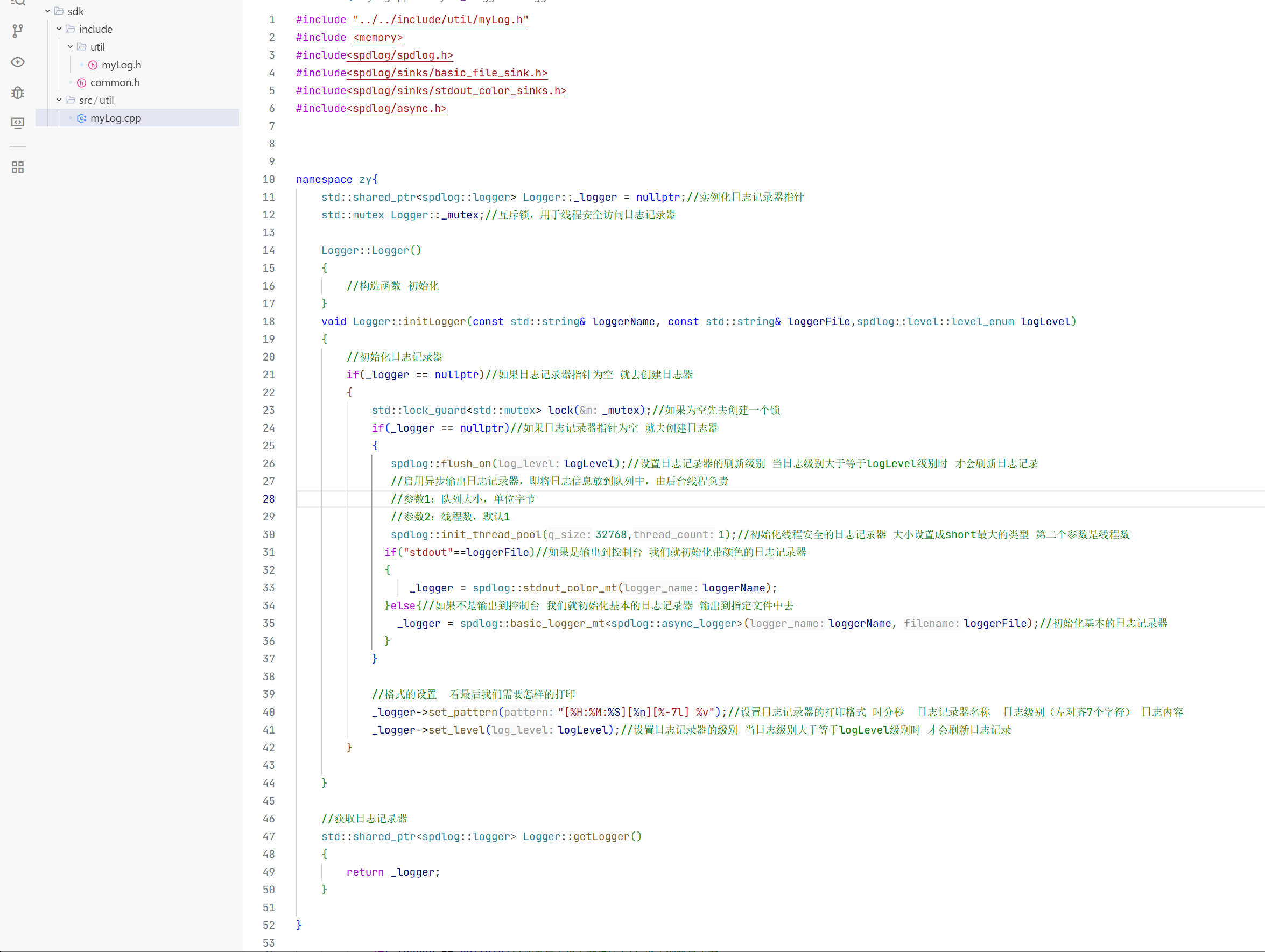
#include "../../include/util/myLog.h"
#include <memory>
#include<spdlog/spdlog.h>
#include<spdlog/sinks/basic_file_sink.h>
#include<spdlog/sinks/stdout_color_sinks.h>
#include<spdlog/async.h>
namespace zy{
std::shared_ptr<spdlog::logger> Logger::_logger = nullptr;//实例化日志记录器指针
std::mutex Logger::_mutex;//互斥锁,用于线程安全访问日志记录器
Logger::Logger()
{
//构造函数 初始化
}
void Logger::initLogger(const std::string& loggerName, const std::string& loggerFile,spdlog::level::level_enum logLevel)
{
//初始化日志记录器
if(_logger == nullptr)//如果日志记录器指针为空 就去创建日志器
{
std::lock_guard<std::mutex> lock(_mutex);//如果为空先去创建一个锁
if(_logger == nullptr)//如果日志记录器指针为空 就去创建日志器
{
spdlog::flush_on(logLevel);//设置日志记录器的刷新级别 当日志级别大于等于logLevel级别时 才会刷新日志记录
//启用异步输出日志记录器,即将日志信息放到队列中,由后台线程负责
//参数1:队列大小,单位字节
//参数2:线程数,默认1
spdlog::init_thread_pool(32768,1);//初始化线程安全的日志记录器 大小设置成short最大的类型 第二个参数是线程数
if("stdout"==loggerFile)//如果是输出到控制台 我们就初始化带颜色的日志记录器
{
_logger = spdlog::stdout_color_mt(loggerName);
}else{//如果不是输出到控制台 我们就初始化基本的日志记录器 输出到指定文件中去
_logger = spdlog::basic_logger_mt<spdlog::async_logger>(loggerName, loggerFile);//初始化基本的日志记录器
}
}
//格式的设置 看最后我们需要怎样的打印
_logger->set_pattern("[%H:%M:%S][%n][%-7l] %v");//设置日志记录器的打印格式 时分秒 日志记录器名称 日志级别(左对齐7个字符) 日志内容
_logger->set_level(logLevel);//设置日志记录器的级别 当日志级别大于等于logLevel级别时 才会刷新日志记录
}
}
//获取日志记录器
std::shared_ptr<spdlog::logger> Logger::getLogger()
{
return _logger;
}
}
这样日志库源文件的封装就结束了。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 8
8 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)