AI时代可观测性答案:ODD(观测驱动开发)
几个月前,我和团队里的 SRE 负责人喝咖啡。他和我吐槽说人维护系统还是太痛苦了。
聊完那天我一直在琢磨:我们是不是搞错了方向?可观测性的终点不应该是数据,而是对系统和业务的理解。而理解的前提,是数据本身带有意义——也就是我后来称之为意图(Intent)的东西。
最近读到 Finzi 等人(2026)的一篇 paper《From Entropy to Epiplexity: Rethinking Information for Computationally Bounded Intelligence》,提到了 Epiplexity(结构化信息复杂度)这个概念。读完有种"啊对对对就是这个"的感觉。今天就想聊聊我们团队在这段时间摸索着推出两个新概念:
概念 1
观测驱动开发
Observability-Driven Development
概念 2
智能体化可观测性
Agentic Observability
一、Epiplexity:你的监控数据,
AI 真的看得懂吗?
先做个小实验(其实也是我被日志整崩溃那次真实经历的简化版)。
现在你面前有两条数据:
数据 A(熟悉的 Nginx 日志)
10.0.1.23 - - [07/Mar/2026:14:32:11] "GET /api/v2/checkout" 200 1534 0.042
数据 B(我简单做了优化)
{ "business_intent": "process_user_checkout",
"critical_path": true,
"dependencies": ["fraud-detection"],
"expected_slo": "p99<500ms",
"failure_impact": "revenue_loss"
}
作为人类你肯定觉得 B 更有价值——一眼看出这是支付链路,超时影响收入。但按照经典信息论,数据 A 的"熵"反而更高(那些随机的 IP、微秒级时间戳、User-Agent 字符串,几乎不可压缩)。
数据 A
对人类是低信息量的,因为我们看不出"10.0.1.23"和"10.0.1.24"的区别,也记不住几千条日志的模式。我们的计算能力(工作记忆)太弱,所以高熵数据对我们来说是噪音。
对 AI是高信息量但低意义的。AI 能轻松发现"10.0.1.23 在 14:32 访问了 checkout 接口 47 次"这种统计模式(结构),但它问不出"这代表用户卡在了哪一步"(意义)。
数据 B
对人类(带意图的 JSON)是高信息量的,因为我们一眼就能理解业务影响。
对 AI如果没有训练过对应的业务领域,数据 B 里的 business_intent: "process_user_checkout" 就只是字符串,并不比 IP 地址更有"意义"。
数据 A & B 其实对应着两个结构:
A低阶结构(AI 擅长):相关性、模式、频次、聚类
B高阶结构(人类擅长):因果链、业务逻辑、价值判断
Finzi 的 paper 里提出的 Epiplexity(结构化信息复杂度)给了我很大启发。它的核心问题是:对计算能力有限的观察者,数据里到底有多少能被提取、理解、重用的结构化信息?原论文讨论的是训练数据的结构化程度如何影响模型学习效率,我在这里做一个类比延伸:监控数据的结构化程度同样会影响 AI Agent 的故障诊断效率。这两个场景的计算模型和约束条件并不完全相同,但核心直觉是一致的——结构化程度决定了可学习性。
可观测数据的 Epiplexity 光谱
看我们现在的数据分布:
低 Epiplexity(噪音)
随机 Trace ID、毫秒级时间戳、无规律日志文本。AI 能统计出"14:32 有 1000 条日志",但不知道这意味着什么。
中 Epiplexity(结构化但未语义化)
带标签的指标(http_requests_total{status="500"})。AI 能发现"支付服务 500 错误上升时数据库 CPU 也上升",但不知道是因果还是巧合?是核心链路还是后台任务?
高 Epiplexity(意图嵌入)
不仅记录"发生了什么",还记录"为什么重要"。就像数据 B,AI 能理解"这是支付链路核心步骤,预期 500ms 内完成,超时会丢单"。
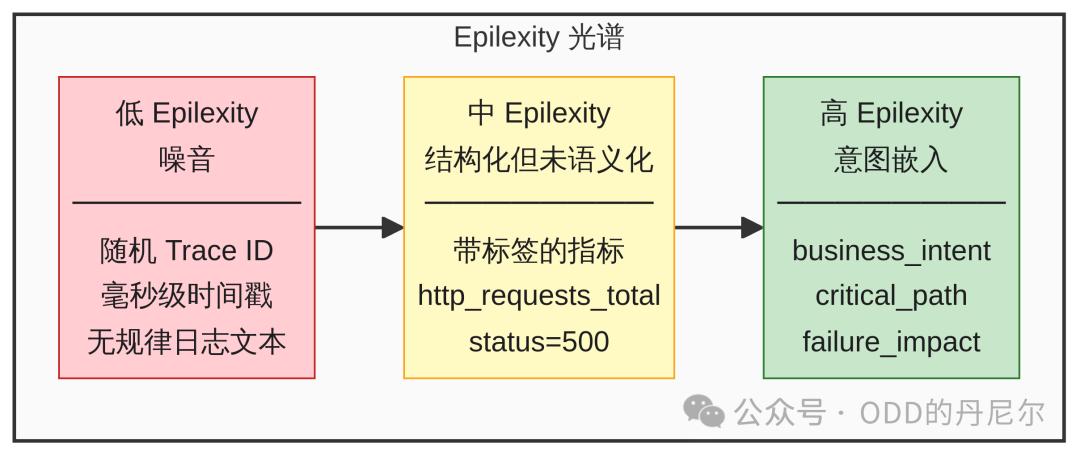
图 1:可观测数据的 Epiplexity 光谱
传统观测数据大多集中在光谱左端——高熵、低结构。AI 虽然能挖统计模式,但它不知道哪些有业务价值。
KEY INSIGHT
信息不是客观存在的,而是相对于观察者能力而言的。当 AI Agent 成为主要消费者时,数据的结构比数量重要得多。而意图(Intent),就是给数据注入结构的向导。
人负责定义因果结构(意义),AI 负责在这个结构上进行高效的演绎推理——这才是人机协作的理想模式。
让 AI 带着问题,去找答案。
二、ODD:很简单,
在设计时就把意图写进去
Observability-Driven Development(可观测性驱动开发,ODD)是我所在的团队在过去探索出的一套方法论。它的核心命题是:
可观测性不是部署之后的附属品,而是系统行为的第一性原语。在设计一个功能之前,必须先回答:这个功能的意图如何被观测?它的故障如何被推理?它的修复如何被自动化验证?
所以 ODD(观测驱动开发)在做的事情,其实是在人类的意义系统和 AI 的结构能力之间建立映射:
intent-mapping.yaml
# 对人类:这是"支付意图"business_intent: process_user_checkout
# 对AI:这是一个高阶因果节点,# 与 revenue_loss 通过逻辑门连接
AI 不需要"理解"支付,它只需要能在这个结构上进行演绎推理——如果 process_user_checkout 超时,且 failure_impact: revenue_loss,就触发熔断。
人类提供因果先验(意义),AI 执行逻辑演绎(结构处理)。Epiplexity 高,意味着这种协作是高效的;Epiplexity 低,意味着 AI 得自己从噪音里归纳出因果(往往失败)。
既然 Epiplexity 衡量的是可学习性,那提升它的第一战场不该在数据处理环节(那时候已经晚了),而应该在数据生产环节。
在 ODD 的世界里,软件工程的生命周期会是这样重构:
传统模型
Design → Develop → Test → Deploy → Monitor(监控是终点)
ODD 模型
Observe → Reason → Design → Develop → Deploy → Observe(观测是起点也是终点)
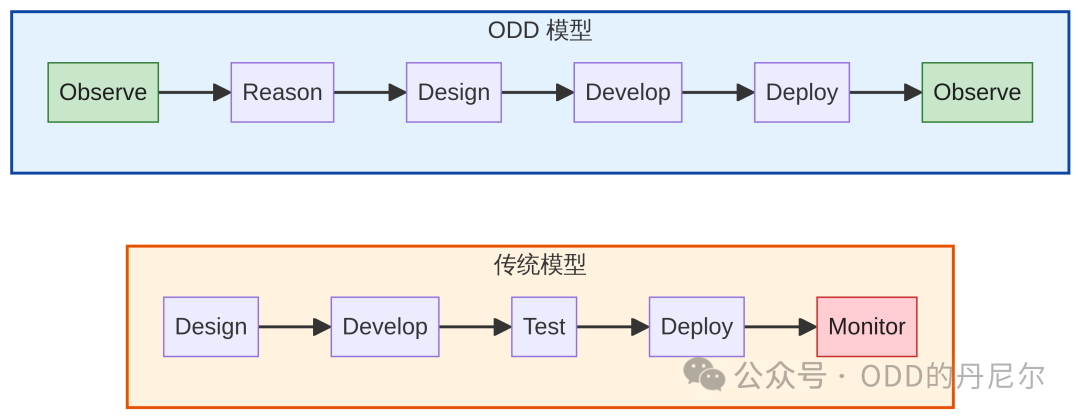
图 2:传统模型 vs ODD 模型生命周期对比
传统可观测性是"事后贴标签":系统先产生无结构日志,我们再通过正则解析、字段提取,试图恢复语义。这就像把整理好的书撕碎扔进纸篓,再让 AI 拼贴还原——熵已经增加了,Epiplexity 已经损失了。
观测驱动开发(ODD)的核心是逆向这个过程:在写代码的时候,就把意图(Intent)作为一等公民编码进去。我们现在的做法是要求每个服务维护一个 Context Schema,用 YAML 显式声明业务意图:
context-schema.yaml
service: payment-gateway
business_intent:
name: charge
description: 处理用户扣款
critical_path: true
slo: { latency_p99: 500ms }
dependencies:
- service: fraud-detection
required: true
failure_modes:
- timeout:
impact: revenue_loss
mitigation: retry with backoff
这个 Schema 有两重属性:
👤 对人类:人类也能轻松看懂,它是活的文档,回答了"这个服务为什么存在"
🤖 对 AI:它是结构化的因果先验,直接把 Epiplexity 从"低"拉到"高"
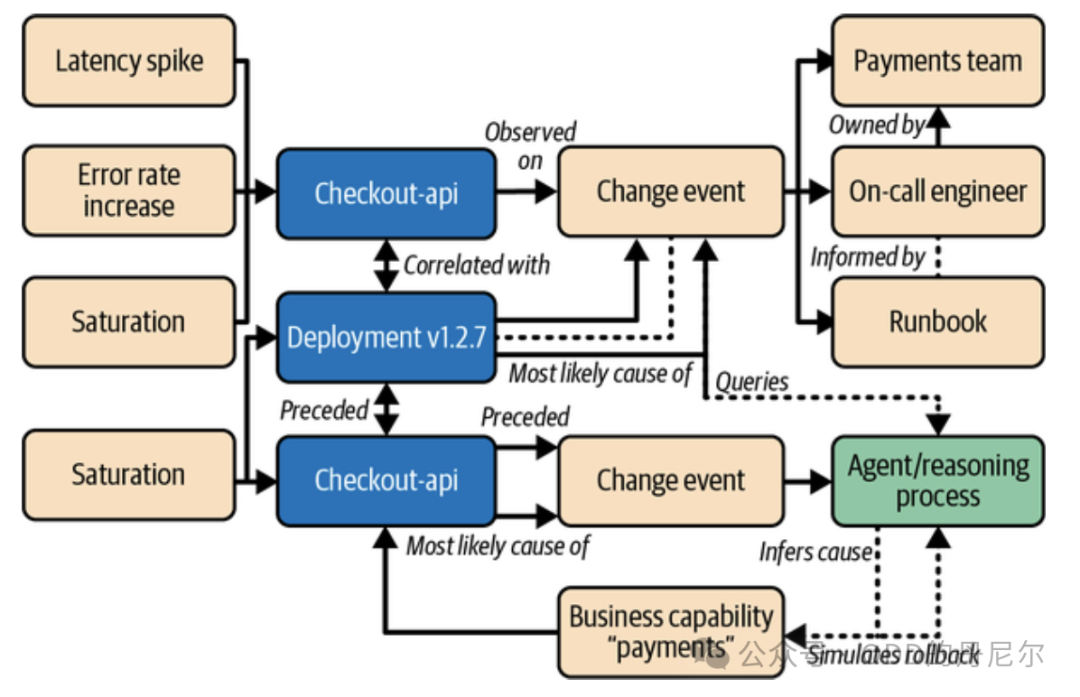
图 3:一张简化的 Context Graph
实际运行时,每笔交易都携带这份意图的引用。AI Agent 看到的不再是"10.0.1.23 访问了 /api/v2/checkout",而是"这是关键支付链路,依赖风控,预期 500ms 完成,超时直接造成收入损失",再带着这个意图(Intent),去进行它最擅长的低阶结构处理,他会发现很多人类发现不了,排查困难的问题。
一旦 Epiplexity 在设计时被锁定,AI 的推理搜索空间就会被大幅压缩,运行时的理解成本显著降低。
当然,文档是需要维护的。我们正在搞的治理闭环包括:
代码即 Schema
Schema 放代码仓库,跟源码一起受版本控制,CI 检查完整性
运行时验证
主动遥测校验实际行为与声明意图是否匹配(比如 P99 持续超过 500ms 就触发"意图漂移"告警)
意图驱动的混沌工程
在预发环境模拟故障,验证系统行为是否符合 Schema 定义的降级路径
那么我们设计时植入的高 Epiplexity 数据,怎么在运行时被 AI 高效消费?这引出了下一步。
三、什么是 Agentic Observability?
如果说 ODD 是软件工程的方法论,那么 Agentic Observability(智能体化可观测性)就是支撑这套方法论的基础设施范式。它的核心主张是:
可观测性系统的主要消费者不再是人类,而是 AI Agent。因此,观测数据必须被组织成 Agent 可以高效消费的形式——结构化、语义化、可推理。
当 AI Agent 成为消费者,整个平台的架构逻辑必须重构。这需要四大转变:
1 从仪表盘到上下文接口
仪表盘是给人类视觉优化的(颜色、曲线、布局),但对 AI 是噪音。Agent 需要的是可通过 API 查询的统一资源目录、因果链图谱——高 Epiplexity 数据的原始结构必须无损传递,别给我渲染成 PNG 图表。
2 从被动存储到主动感知
传统平台被动等查询(Pull 模式),Agent 需要事件驱动(Push):异常发生时主动打包相关上下文推送给 Agent,别让它在 PB 级日志里自己捞针——那太浪费算力了。
3 从单一信号到因果图谱
AI 理解故障需要归纳(Induction),但在缺乏先验知识的情况下,归纳的搜索空间会随问题规模指数级膨胀。平台得预先把 Trace、Metric、变更事件编织成因果图谱,把归纳问题转化为演绎问题。
4 从数据到意图(Intent)
所有遥测数据必须携带 Schema 里定义的意图标签(critical_path: true, business_impact: revenue),让 Agent 能立即区分核心信号和边缘噪音。
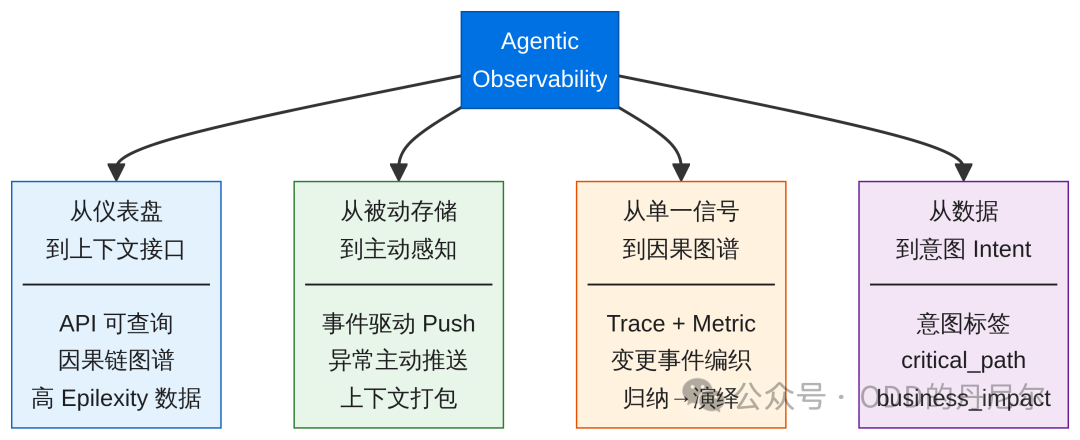
图 4:Agentic Observability 四大转变
说白了,Agentic Observability 是 ODD 的必然延伸:ODD 确保生产时 Epiplexity 最大化,Agentic 架构确保这些高 Epiplexity 数据能被 AI 完美消费。
ODD 与 Agentic Observability 的关系
ODD 是设计方法论:它指导工程师如何构建系统,使得可观测性成为第一性原语,意图被显式编码。
Agentic Observability 是基础设施:它提供了运行时环境,让带有意图的遥测数据可以被 AI Agent 消费,并驱动自主决策。
没有 ODD,Agentic Observability 就会缺乏高质量的意图数据,Agent 仍然在"盲人摸象"。没有 Agentic Observability,ODD 就只能停留在设计文档层面,无法在运行时产生价值。
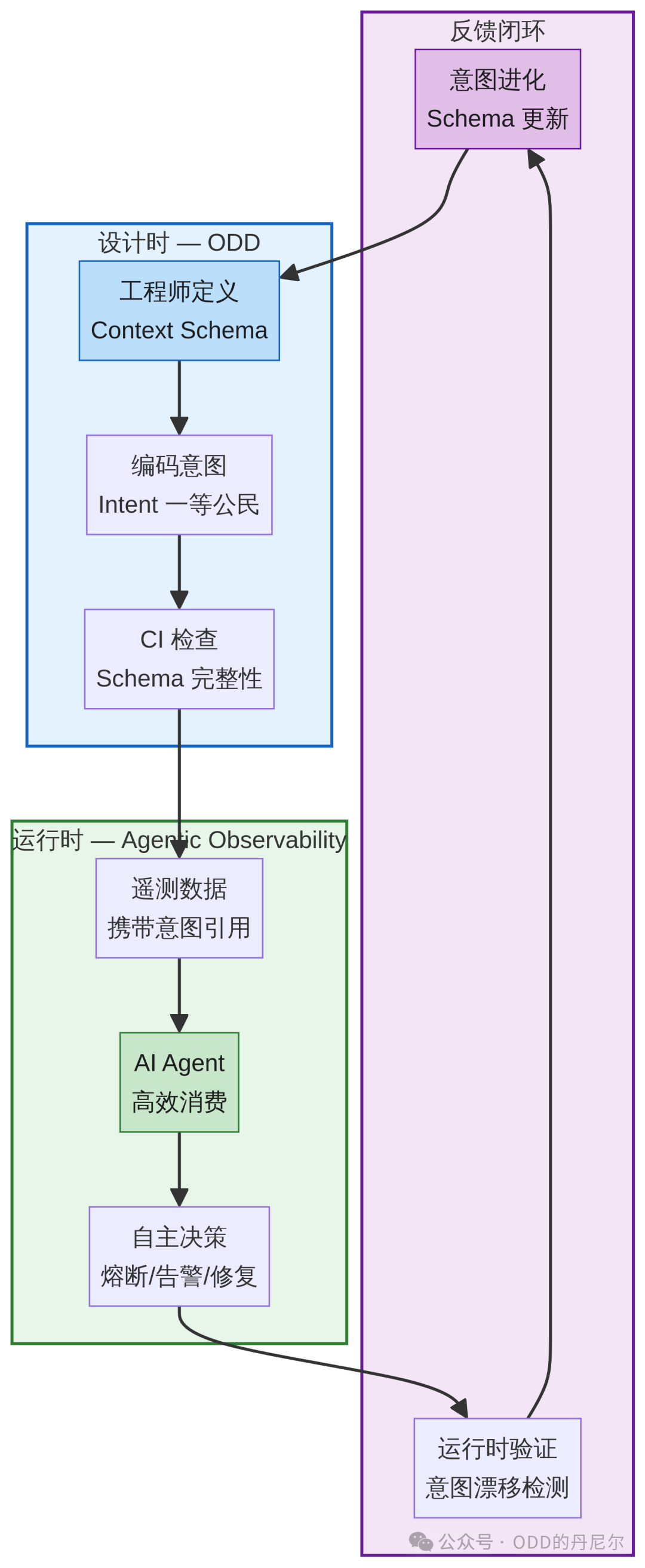
图 5:ODD + Agentic Observability 完整闭环
两者结合,才能构成一个完整的闭环:设计时注入意图,运行时消费意图,异常时基于意图推理,修复后反馈意图进化。
四、为什么一定一定要这么做
这里要引入一个关键的计算复杂性视角。在缺乏先验结构的情况下,归纳推理(Induction)——即从观察到的现象反推根因——其搜索空间会随着问题维度指数级膨胀;而在给定因果先验(如 Context Schema)的条件下,演绎推理(Deduction)的搜索空间被大幅压缩,通常可在多项式时间内完成。但在工程实践中,核心直觉成立:先验结构越多,搜索空间越小,推理效率越高*。
Finzi 等人的论文通过细胞自动机实验验证了类似的直觉:遮住输入的一部分比特,让模型从剩余信息反推被遮住的内容,所需计算量随遮住比例急剧增长。这对应了 Ilya Sutskever 那个比喻——推理小说作者只需要演绎(按逻辑写下去),但读者必须从线索中归纳出凶手。
传统可观测性就是把 AI 置于"读者"的困境:面对低 Epiplexity 的原始日志(数据 A 那种),AI 必须进行归纳——从现象反推根因。由于缺乏因果先验,它得在指数级假设空间(网络问题?代码 bug?依赖故障?)里搜索,还极易被虚假相关误导。
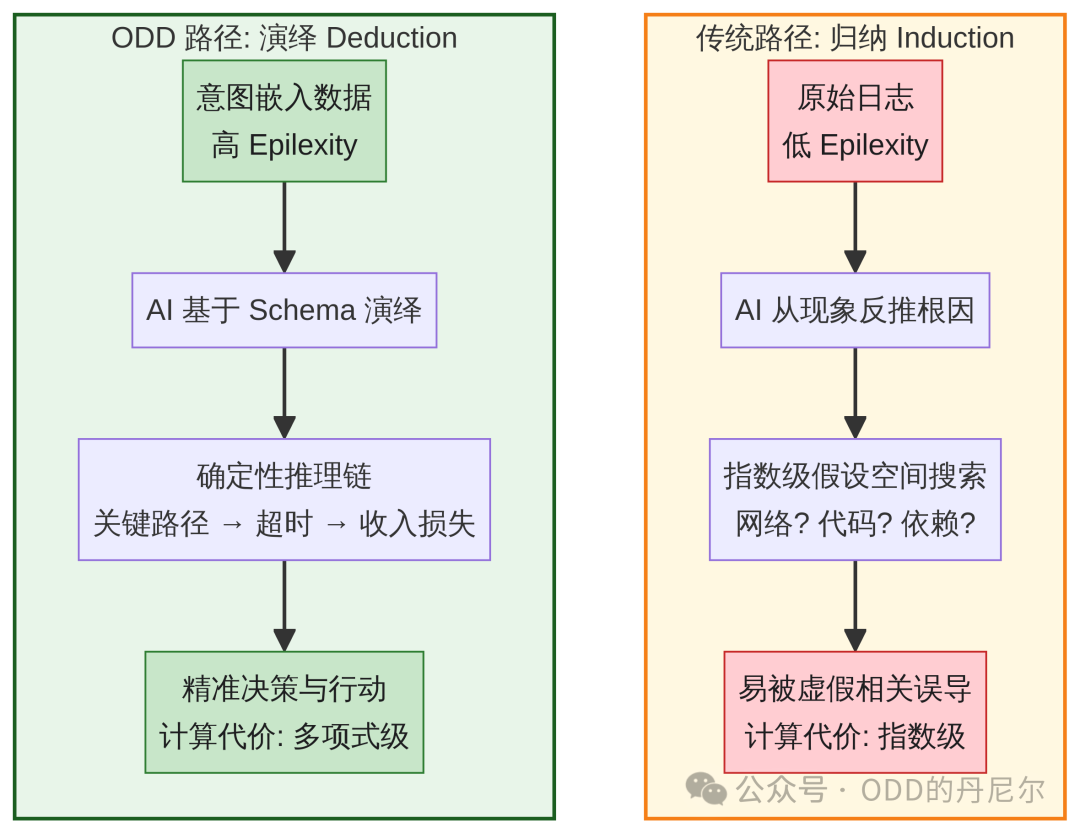
图 6:归纳 vs 演绎——计算代价的本质差异
ODD + Agentic Observability 的革命性
通过 Context Schema 和因果图谱,我们把归纳(Induction)问题转化为演绎(Deduction)问题。
当 AI 看到"支付链路超时",不需要从日志里归纳"这可能影响收入",而是直接演绎:Schema 表明这是关键路径,failure_impact 是 revenue_loss,于是立即触发熔断并通知财务团队。
现在再加上共识的维度:当多个 AI Agent 需要协作时,如果它们基于低 Epiplexity 的原始数据进行"讨论",相当于在庞大的假设空间中叠加各自的不确定性——这不仅计算代价高昂,而且可能难以收敛。Berdoz 等人在《Can AI Agents Agree?》中的实验也印证了这一点:即使在完全良性的环境下,LLM Agent 群体的共识达成也并不可靠。
而高 Epiplexity 的数据(带有确定性 Schema)提供了共识的锚点——当所有 Agent 都引用同一个 business_intent 和 slo 时,它们的推理就有了共同的 ground truth,不确定性被约束在确定性框架内。这不是说 Schema 能彻底解决多智能体共识问题(那仍然是一个开放的研究挑战),但它至少把问题从“在无结构数据上达成共识”降维为“在共享语义框架下达成共识”。
这就是 ODD 的真正价值:它不仅是数据的度量衡,更是降低共识复杂度的工程手段。把 AI 从"猜测者"变成"验证者"——从在噪音里找模式,到在意图框架下验证假设。
意图的本质,是给 AI 提供因果先验,
把不可学习的噪音变成可迁移的结构。
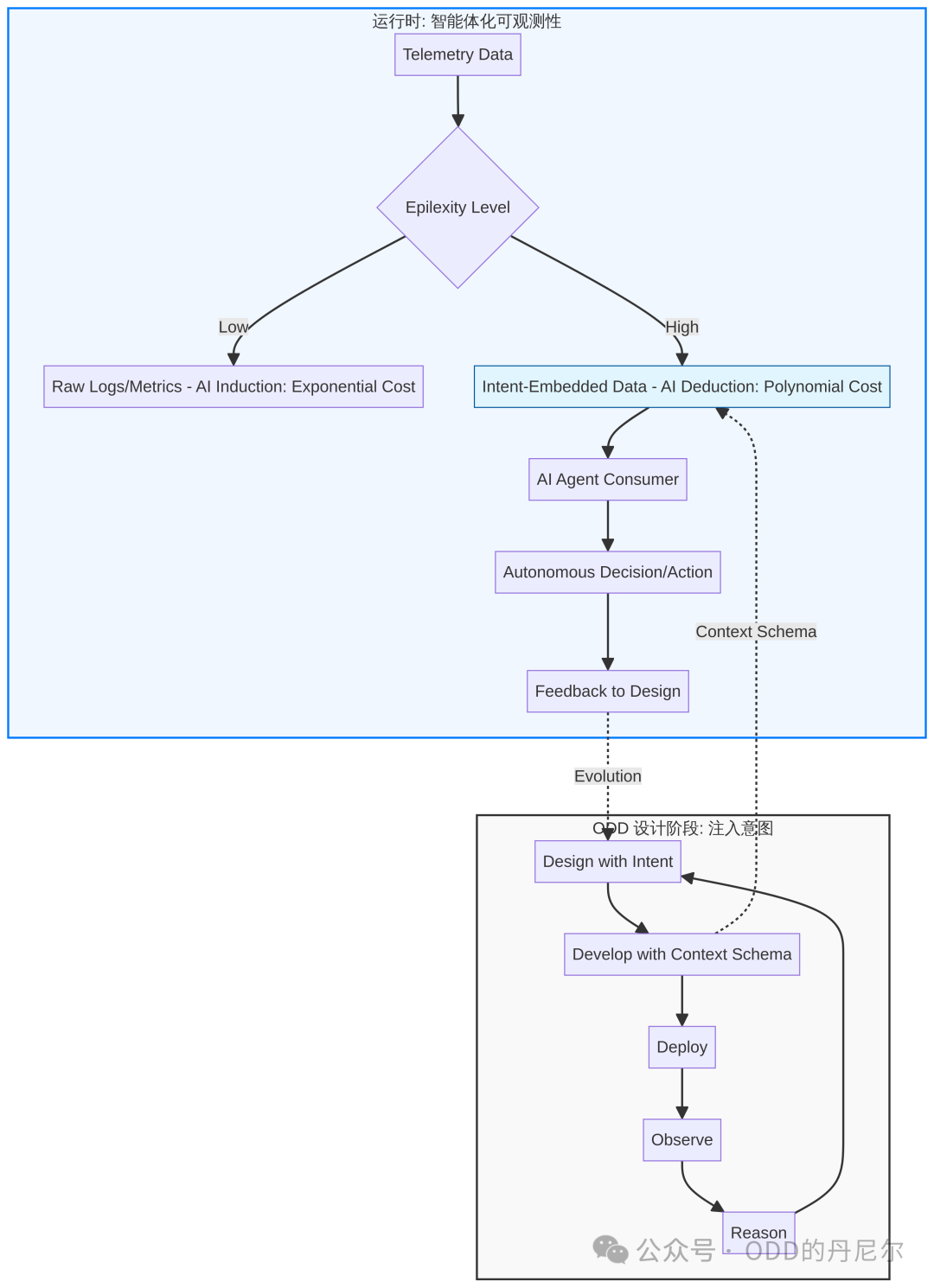
图 7:ODD + Agentic Observability 完整技术架构
*并非严格的计算复杂性定理——事实上,即便是给定完整先验的演绎推理(如 SAT 问题)本身也可能是 NP-hard 的。
五、写在最后:还在探索中
上面这些——ODD、Agentic Observability、Context Schema、归纳到演绎的转换——很多还停留在我们团队的实验阶段,很多代码还在 feature branch 里没 merge。
从意图到落地,横亘着一堆棘手的工程现实:Agent 执行环境的安全隔离、多智能体协同的协议标准化、集体记忆的错误污染(一个 Agent 的误判经验沉淀到知识图谱里会误导所有人)、重型 CLI 与轻量 MCP 工具链的混合调度……
这些细节决定能不能真正跑通,我们还在探索,踩坑和验证是接下来的主旋律。
但有一点越来越清晰:只有当系统能够解释自己,AI 才能真正成为可靠的伙伴。
如果你赞同我提出的两个概念和方向,欢迎来交流——后续我会陆续写一些根据这个理论落地的具体产品设计,实现,踩过的坑和思考。
这次先写这么多。
参考文献
[1] Finzi, M., Qiu, S., Jiang, Y., Izmailov, P., Kolter, J. Z., & Wilson, A. G. From Entropy to Epiplexity: Rethinking Information for Computationally Bounded Intelligence. arXiv preprint arXiv:2601.03220, 2026.
[2] Sutskever, I. An observation on Generalization. Simons Institute Lecture, 2023.
[3] Papadopoulos, V., et al. Arrows of Time for Large Language Models. Proceedings of ICML, 2024.
[4] Google. Announcing the Agent2Agent Protocol (A2A), 2025.
[5] Anthropic. Introducing the Model Context Protocol (MCP), 2024.
[6] Berdoz, F., Rugli, L., & Wattenhofer, R. Can AI Agents Agree? On the Convergence of Multi-Agent Reasoning under Epistemic Uncertainty. arXiv preprint arXiv:2603.01213, 2026.

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 15
15 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)