Google Gemma 4-31B:多模态原生架构的开源突破,256K 超长上下文重新定义边缘 AI
2026 年 4 月 2 日,Google DeepMind 发布了 Gemma 4 系列开源模型。这不是一次简单的版本迭代,而是一场从架构到能力的彻底重构。旗舰模型 Gemma-4-31B-it 拥有 30.7B 参数,在多项基准测试中的表现已经超越了不少闭源商业模型,同时还保持着开源模型特有的灵活性和可部署性。

更值得关注的是,Gemma 4 是第一个原生支持文本、图像、视频、音频多模态输入的开源模型家族。它配备了高达 256K tokens 的超长上下文窗口,内置思维链推理和函数调用能力,真正把“端到端多模态智能体”从实验室概念推向了可以实际使用的产品形态。
在权威基准测试中,Gemma-4-31B-it 的表现确实令人印象深刻:MMLU Pro 达到 85.2%,AIME 2026 数学竞赛题正确率 89.2%,LiveCodeBench v6 编程测试 80.0%,Codeforces 编程竞赛 ELO 评分 2150。这些数字背后,是接近人类专家水平的推理、编程和问题解决能力。
混合注意力机制:效率与性能的平衡术

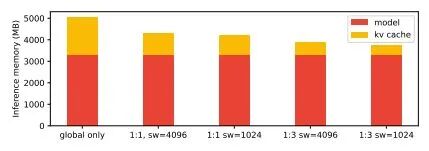
Gemma 4 的核心创新在于混合注意力机制。传统 Transformer 模型一直面临一个两难选择:要么使用全局注意力,让模型看到所有信息,但计算开销会随着序列长度平方级增长;要么使用局部滑动窗口,控制计算量,但会牺牲长距离依赖的建模能力。Gemma 4 的解决方案是把两者结合起来,让局部滑动窗口注意力与全局注意力层交替排列,最终层始终保持全局视野。
这种设计的妙处在于,模型在处理长文档时既能高效捕捉局部细节——比如段落内的语义关联,又能理解全局结构——比如跨章节的逻辑推理。对于 Gemma-4-31B 来说,滑动窗口设置为 1024 tokens,而上下文窗口则扩展到了 256K tokens,相当于大约 500 页 A4 文档或一部中篇小说的长度。
为了进一步优化长上下文的内存占用,全局注意力层还采用了统一的 Key-Value 缓存和比例位置编码技术。这些技术细节累积起来的效果相当显著:在处理 128K tokens 的文档时,Gemma 4 的内存占用比传统架构减少了约 40%,推理速度提升了 30% 以上。
原生多模态:不是拼接,而是融合
市面上不少多模态模型其实是“拼接式”的——先用一个视觉编码器处理图像,再把结果喂给语言模型。Gemma 4 走的是另一条路:从预训练阶段就把多模态数据纳入训练流程,实现真正的原生多模态理解。Gemma-4-31B-it 内置了一个 550M 参数的视觉编码器,能够以可变分辨率和宽高比处理图像输入,支持文本与图像在 prompt 中任意交错排列。
这种设计带来的提升是实实在在的。在 MMMU Pro 多模态理解测试中,Gemma-4-31B 达到了 76.9% 的准确率,超越了不少专用的视觉-语言模型。在 MATH-Vision 数学视觉推理测试中得分 85.6%,能够准确解析几何图形和函数图像中的数学问题。在 OmniDocBench 1.5 文档理解测试中,其平均编辑距离仅为 0.131,展现出卓越的 OCR 和文档结构解析能力。这意味着 Gemma 4 可以直接处理扫描的 PDF、表格、图表,不需要额外的预处理步骤。
视频理解能力同样值得一提。Gemma 4 把视频当作帧序列来处理,支持最长 60 秒的视频输入(按每秒 1 帧采样)。模型能够理解动态场景、时序变化、动作序列,这为视频问答、内容审核、视频摘要等应用提供了技术基础。
Gemma 4 系列中的小型模型 E2B 和 E4B 还支持音频输入,能够进行自动语音识别和跨语言语音翻译。虽然 31B 模型没有包含音频模态,但这展示了 Gemma 架构的可扩展性——同一套技术框架可以灵活适配不同的模态组合。
思维链推理:让模型学会“思考”
Gemma 4 原生支持 Thinking Mode,也就是思维链推理模式。与 Gemma 3 不同,Gemma 4 使用标准的 system、assistant、user 角色,并通过特殊控制 token 来管理思维过程。开发者只需要设置 enable_thinking=True,就能让模型在给出最终答案前进行显式的逐步推理。
这种能力在复杂问题求解中的作用非常明显。在 AIME 2026 美国数学邀请赛测试中,Gemma-4-31B 在没有任何工具辅助的情况下达到了 89.2% 的正确率,远超 Gemma 3 的 20.8%。在 GPQA Diamond 研究生级别物理问答中得分 84.3%,在 Tau2 多步骤推理测试中平均得分 76.9%。这些成绩说明,Thinking Mode 不是简单的 prompt 技巧,而是模型架构层面的能力提升。
函数调用能力则为智能体应用打开了新的可能性。Gemma 4 原生支持结构化工具使用,能够理解函数定义、生成符合 schema 的调用参数、处理返回结果。开发者可以轻松构建能够查询数据库、调用 API、操作外部系统的 AI Agent,不需要复杂的 prompt 工程或后处理逻辑。
编程能力:从代码生成到算法竞赛
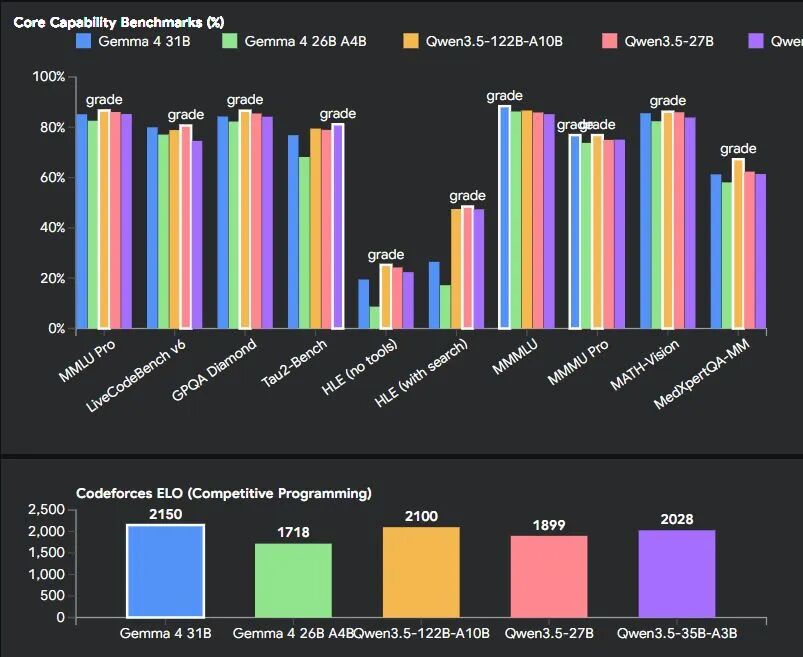
对于开发者来说,Gemma-4-31B 的编程能力可能是最吸引人的特性。在 LiveCodeBench v6 实时编程基准测试中,模型达到了 80.0% 的通过率。这个测试集包含最新的编程问题,专门用来评估模型的泛化能力而不是记忆能力。
更让人惊讶的是它在 Codeforces 竞赛中的表现。Codeforces 是全球最大的算法竞赛平台,ELO 评分 2150 意味着这个模型已经达到了 Candidate Master(候选大师)级别,相当于全球前 5% 的竞赛选手水平。这不仅需要代码生成能力,还需要算法设计、复杂度分析、边界条件处理等综合技能。
在实际应用中,Gemma 4 的超长上下文窗口让它能够理解整个代码库的结构,进行跨文件的重构和优化建议。配合函数调用能力,它可以作为编程助手,自动执行测试、查询文档、生成示例代码。
安全性:与 Gemini 同等标准
作为开源模型,Gemma 4 在安全性方面采用了与 Google 闭源 Gemini 模型相同的评估标准。开发团队与内部安全和负责任 AI 团队紧密合作,进行了大量的自动化和人工评估,确保模型符合 Google AI 原则。
评估覆盖了仇恨言论、危险内容、性相关内容、暴力内容、儿童安全、隐私泄露、虚假信息等多个关键领域。测试结果显示,Gemma 4 在所有内容安全类别中相比 Gemma 3 都有显著改进,同时把“不当拒绝”(过度审查)保持在较低水平。所有测试都是在没有安全过滤器的条件下进行的,评估的是模型的原生能力和行为。
在图像-文本任务中,Gemma 4 产生的政策违规内容极少,并且在所有模型规模上都展现出比前代模型更好的安全性能。这种安全性不是通过简单的关键词过滤实现的,而是深度融入了模型的训练数据选择、预训练目标和后训练微调过程。
部署:从云端到边缘的完整覆盖
Gemma 4 系列的设计理念是“民主化 AI”,让最先进的 AI 能力在各种设备上都能运行。31B 模型虽然是旗舰版本,但通过优化的架构和量化技术,可以在消费级 GPU 上高效运行。官方提供了完整的 Transformers 库支持,开发者只需要几行代码就能加载模型:
from transformers import AutoProcessor, AutoModelForCausalLM
MODEL_ID = "google/gemma-4-31B-it"
processor = AutoProcessor.from_pretrained(MODEL_ID)
model = AutoModelForCausalLM.from_pretrained(
MODEL_ID,
dtype="auto",
device_map="auto"
)
对于需要处理图像、视频的场景,可以使用 AutoModelForMultimodalLM 类,同样简单易用。模型支持可变图像分辨率,通过可配置的视觉 token 预算来控制计算开销。高预算保留更多视觉细节,低预算则加速推理,开发者可以根据具体任务灵活调整。
Gemma 4 系列还包括更小的模型。26B A4B MoE 采用混合专家架构,激活参数仅 3.8B,在保持接近 31B 性能的同时,推理速度几乎与 4B 模型相当。E4B 和 E2B 的有效参数分别为 4.5B 和 2.3B,专为移动设备和边缘计算设计,甚至可以在高端手机上运行。这种多层次的模型家族覆盖了从数据中心到终端设备的完整部署场景。
开源生态:真正的商业友好
Gemma 4 采用 Apache 2.0 许可证,这是最宽松的开源许可之一,允许商业使用、修改、分发,不需要公开源代码。这与某些“伪开源”模型形成了鲜明对比——后者虽然公开权重,但通过限制性许可阻止商业应用。
所有模型权重已经同步发布在 Hugging Face、GitHub 和 Google AI 平台,配套完整的文档、示例代码和最佳实践指南。社区响应很热烈,已经有开发者把 Gemma 4 集成到 LangChain、LlamaIndex 等主流框架,以及 Ollama、vLLM 等推理引擎。
Google 还提供了云端 API 服务,通过 Google AI Studio 和 Vertex AI 平台,开发者可以直接调用 Gemma 4 而不需要自行部署。这种“开源 + 云服务”的双轨策略,既保证了技术的开放性,又降低了使用门槛。
应用场景:从文档处理到智能体开发
Gemma-4-31B 的能力组合让它在很多领域都能派上用场。256K 上下文窗口让它能够直接处理长篇报告、法律文档、学术论文。配合多模态能力,可以解析包含图表、表格、公式的复杂文档,提取结构化信息,生成摘要和问答。
在代码开发领域,竞赛级的编程能力让它成为理想的 AI 编程助手。它能够理解整个项目的代码库,提供重构建议,自动生成测试用例,甚至进行漏洞检测和性能优化。
多模态内容创作方面,它能够理解图像和文本的交错输入,生成配图说明、图像描述、视觉问答。这可以用于电商产品描述生成、社交媒体内容创作、无障碍辅助(为视障用户描述图像)。
Thinking Mode 让它能够处理复杂的多轮对话,进行逐步推理。Function Calling 能力让它可以查询数据库、调用业务系统,真正成为能够执行任务的智能体。在教育领域,它在数学、物理等 STEM 学科中表现出色,可以作为个性化学习助手,解答问题、提供详细解题步骤、生成练习题。
对于科研工作者来说,长上下文和多模态能力让它适合作为科研辅助工具,可以阅读大量文献、分析实验数据、生成研究报告。
Gemma 4 的发布标志着开源 AI 进入了新的发展阶段。它不再只是闭源模型的“平替”,而是在某些维度上实现了超越。当 256K 上下文、原生多模态、思维链推理、函数调用这些能力以 Apache 2.0 许可开放给全球开发者时,AI 应用的创新边界又被推得更远了。
社区地址
OpenCSG社区:https://opencsg.com/models/google/gemma-4-31B-it
hf社区:https://huggingface.co/google/gemma-4-31B-it
关于 OpenCSG
OpenCSG 是全球领先的开源大模型社区平台,致力于打造开放、协同、可持续生态,AgenticOps是人工智能领域的一种AI原生方法论,由OpenCSG(开放传神)提出。AgenticOps是Agentic AI的最佳落地实践也是方法论。核心产品 CSGHub 提供模型、数据集、代码与 AI 应用的 一站式托管、协作与共享服务,具备业界领先的模型资产管理能力,支持多角色协同和高效复用。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 1
1 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)