LangChain文本分割器实战:递归分割、Token控制、代码处理一篇搞定
文章目录

1. 概念
1.1 为什么需要文本分割?
我们已经知道可以通过文档加载器完成各种数据源的加载,将其转换为 Document 对象。那么接下来要做的就是文档拆分。
文档拆分通常是将大文本分为更小的、易于管理的块。这对于索引数据并将其传递到模型中很有用。因为,大块更难搜索并且不适合模型的有限上下文窗口。拆分可以提高搜索结果的粒度,从而可以更精确地定位查询与相关文档部分进行匹配。
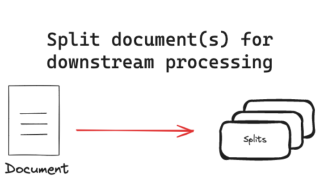
LangChain 的文本分割器便能将大文档分解为更小的块。如下图所示:
2. 根据文档长度与文档语义拆分
2.1 概述
我们可以直接根据文档的长度拆分文档,是最简单且有效的方法。可确保每个块不超过指定的大小限制。
对于长度拆分,其实也分为两种:
- 基于字符长度拆分
- 基于 Token 长度拆分
2.2 基于字符长度拆分
2.2.1 CharacterTextSplitter
根据给定的字符序列进行拆分,拆分的块长度则按字符数来衡量。
代码示例:
# 基于字符长度的文本分割器
from langchain_text_splitters import CharacterTextSplitter
from langchain_community.document_loaders.markdown import UnstructuredMarkdownLoader
# 定义加载对象,默认是single document
loader = UnstructuredMarkdownLoader("test.md", mode="elements")
# 加载文档
documents = loader.load()
# 定义文本分割器(先按照separator分割文档,再按照chunk_size和chunk_overlap分割文档)
splitter = CharacterTextSplitter(
separator="\n\n", # 分隔符
chunk_size=200, # 块大小
chunk_overlap=10, # 文档重叠长度
length_function=len, # 使用测量长度的函数
is_separator_regex=False, # 分隔符是正则表达式吗
)
# 分割文档
splits = splitter.split_documents(documents)
# 打印分割后的文档的前十个
for doc in splits[:10]:
print(doc.page_content)
print("\n ------------------\n")
参数说明:
| 参数 | 说明 | 示例 |
|---|---|---|
separator |
分隔符,用于初步分割文档 | "\n\n" 按段落分割 |
chunk_size |
每个块的最大字符数 | 200 |
chunk_overlap |
相邻块之间的重叠字符数 | 10 |
length_function |
计算长度的函数 | len |
is_separator_regex |
分隔符是否为正则表达式 | False |
注意事项:
- 可能会大于设置的
chunk_size,因为比如遇到长单词之类的,会导致文档长度超过chunk_size - 它不会死板地按照设置的
chunk_size分割文档,故会超过 Created a chunk of size 104, which is longer than the specified 100→ 只要出现得少说明分块控制得越好
2.3 基于 Token 长度拆分
2.3.1 什么是 Token?
Token 是 LLM 处理文本的基本单位。一个 Token 可以是:
- 一个单词
- 一个字符
- 一个子词
例如:
- 英文:“Hello World” ≈ 2 tokens
- 中文:“你好世界” ≈ 4 tokens(中文通常 1 个字 = 1-2 tokens)
2.3.2 CharacterTextSplitter.from_tiktoken_encoder
使用 tiktoken 编码器按 Token 数量拆分文档。
代码示例:
# 基于Token的分割方法
import tiktoken
from langchain_text_splitters import CharacterTextSplitter
from langchain_community.document_loaders.markdown import UnstructuredMarkdownLoader
# 加载文档(让 Markdown 按结构解析(标题、段落、列表分开))
loader = UnstructuredMarkdownLoader("test.md", mode="elements")
documents = loader.load()
# 设置基于token的文本分割器
splitter = CharacterTextSplitter.from_tiktoken_encoder(
encoding_name="cl100k_base", # OpenAI 的编码方式
chunk_size=120, # 每块120个token
chunk_overlap=50, # 文档重叠长度50个token
)
# 原始文本(一个document的page_content) → 编码成 token 序列 → 滑动窗口切分 → 解码成 chunk
# [0,1,...,119][70,...,189][140,...,299] → "chunk1" "chunk2" "chunk3"
# 分割文档
splits = splitter.split_documents(documents)
# 打印分割后的文档前20个
for split in splits[:20]:
print(len(split.page_content))
print(split.page_content)
print("\n------\n")
工作原理:
- 编码:将原始文本编码成 token 序列
- 滑动窗口切分:按照
chunk_size和chunk_overlap切分 - 解码:将 token 序列解码回文本
原始文本 → [0,1,...,119] → "chunk1"
[70,...,189] → "chunk2"
[140,...,299] → "chunk3"
参数说明:
| 参数 | 说明 | 示例 |
|---|---|---|
encoding_name |
编码器名称 | "cl100k_base" (GPT-3.5/4) |
chunk_size |
每个块的最大 token 数 | 120 |
chunk_overlap |
相邻块之间的重叠 token 数 | 50 |
常用编码器:
cl100k_base:GPT-3.5-turbo、GPT-4p50k_base:Codex、text-davinci-002/003r50k_base:GPT-3 (davinci)
3. 递归字符文本分割器
3.1 RecursiveCharacterTextSplitter
这是推荐的文本分割方式。它通过一系列字符递归地分割文本,尝试保持相关的文本片段在一起。
核心思想:
- 首先按照
\n\n分割文档 - 如果分割后的块仍然大于
chunk_size,再按照\n分割 - 如果还大,继续按照其他字符(如
。、!、?等)分割 - 直到符合
chunk_size
代码示例:
# 基于字符长度的文本分割器
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.document_loaders.markdown import UnstructuredMarkdownLoader
# 定义加载对象,默认是single document
loader = UnstructuredMarkdownLoader("test.md", mode="elements")
# 加载文档
documents = loader.load()
# 定义文本分割器(先按照separators分割文档,再按照chunk_size和chunk_overlap分割文档)
splitter = RecursiveCharacterTextSplitter(
# 递归式;首先按照\n\n分割文档,再按照\n分割文档,最后按照其他字符分割文档:
# \n\n:拿到第一块,然后如果大于chunk,就接着从末尾,往前走找。
# 如果还大就,再次基础上找叹号 .........,,直到符合chunk_size。
separators=["\n\n", "\n", "。", "!", "?", ";", ",", ":", " "],
chunk_size=100,
chunk_overlap=10, # 文档重叠长度
length_function=len, # 使用测量长度的函数
is_separator_regex=False, # 分隔符是正则表达式吗
)
# 分割文档
splits = splitter.split_documents(documents)
print(f"总共分割成 {len(splits)} 个块\n")
print("="*80)
# 打印分割后的文档的前10个
for i, doc in enumerate(splits[:10], 1):
print(f"\n【块 {i}】 长度: {len(doc.page_content)} 字符")
print("-"*80)
print(doc.page_content)
print("-"*80)
递归分割流程:
1. 尝试用 "\n\n" 分割
↓ (如果块仍然太大)
2. 尝试用 "\n" 分割
↓ (如果块仍然太大)
3. 尝试用 "。" 分割
↓ (如果块仍然太大)
4. 尝试用 "!" 分割
↓ (继续...)
5. 直到符合 chunk_size
优势:
- 保持文本的语义完整性
- 优先按照自然的分隔符(段落、句子)分割
- 适合中文和英文混合文本
4. 特殊文档结构拆分
4.1 概述
若对于代码等特殊文本,可以尝试使用 Language 提供的不同的分割器(如 PythonCodeTextSplitter、HTMLHeaderTextSplitter 等),效果会更好,它会理解代码的语法结构。
这里了解下常见的拆分原则即可:
- Markdown:根据标头拆分(例如,
#、##、###) - HTML:使用标签拆分
- JSON:按对象或数组元素拆分
- Code 代码:按函数、类或逻辑块拆分
4.2 Python 代码分割器
4.2.1 PythonCodeTextSplitter
专门用于分割 Python 代码,会按照 Python 的语法结构进行分割。
代码示例:
# python代码分割器
from langchain_text_splitters import PythonCodeTextSplitter
# 定义一个python代码示例
python_code = """
def add(a, b):
'''加法函数'''
return a + b
def subtract(a, b):
'''减法函数'''
return a - b
class Calculator:
'''计算器类'''
def __init__(self):
self.result = 0
def multiply(self, a, b):
'''乘法'''
return a * b
def divide(self, a, b):
'''除法'''
if b == 0:
raise ValueError("除数不能为0")
return a / b
# 测试代码
if __name__ == "__main__":
print(add(1, 2))
print(subtract(5, 3))
calc = Calculator()
print(calc.multiply(3, 4))
print(calc.divide(10, 2))
"""
# 设置python代码分割器
# 按照python代码结构风格进行切分,再者就是按照chunk(次要)
splitter = PythonCodeTextSplitter(
chunk_size=100,
chunk_overlap=10, # 文档重叠长度
)
# 进行分割(create_documents 用于文档列表)
splits = splitter.create_documents([python_code])
print(f"总共分割成 {len(splits)} 个代码块\n")
print("="*80)
# 打印分割后的python代码
for i, split in enumerate(splits, 1):
print(f"\n【代码块 {i}】 长度: {len(split.page_content)} 字符")
print("-"*80)
print(split.page_content)
print("-"*80)
分割原则:
- 优先按照代码结构:函数、类、方法
- 次要按照 chunk_size:如果代码块太大,再按照大小分割
优势:
- 保持代码的完整性
- 不会在函数或类的中间分割
- 适合代码检索和分析
5. 文本分割器对比
5.1 各种分割器对比表
| 分割器 | 分割依据 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|---|
| CharacterTextSplitter | 字符数 | 通用文本 | 简单直接 | 可能破坏语义 |
| Token-based Splitter | Token 数 | LLM 输入 | 精确控制 token 数 | 需要编码器 |
| RecursiveCharacterTextSplitter | 递归分隔符 | 通用文本(推荐) | 保持语义完整性 | 稍复杂 |
| PythonCodeTextSplitter | Python 语法 | Python 代码 | 保持代码结构 | 仅限 Python |
| MarkdownHeaderTextSplitter | Markdown 标题 | Markdown 文档 | 按章节分割 | 仅限 Markdown |
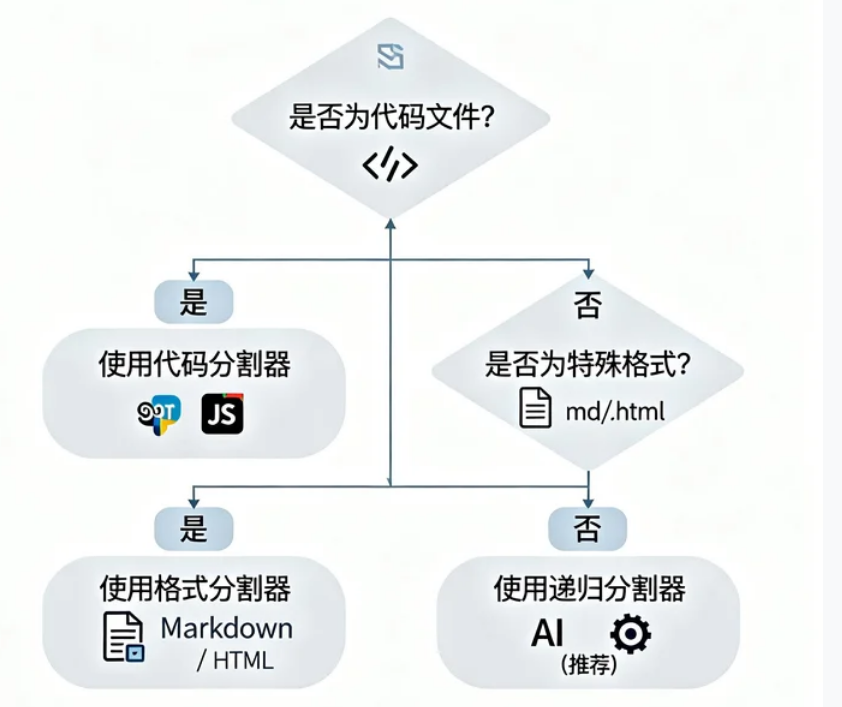
5.2 选择建议
6. 重要参数详解
6.1 chunk_size(块大小)
含义:每个文本块的最大长度。
选择建议:
- 小块(100-200):适合精确检索,但可能丢失上下文
- 中块(500-1000):平衡检索精度和上下文
- 大块(2000+):保留更多上下文,但检索不够精确
示例:
# 小块:精确检索
splitter = CharacterTextSplitter(chunk_size=200)
# 中块:平衡(推荐)
splitter = CharacterTextSplitter(chunk_size=500)
# 大块:保留上下文
splitter = CharacterTextSplitter(chunk_size=2000)
6.2 chunk_overlap(块重叠)
含义:相邻块之间重叠的字符数或 token 数。
作用:
- 确保上下文连贯性
- 避免重要信息被分割到两个块的边界
选择建议:
- 通常设置为
chunk_size的 10-20% - 例如:
chunk_size=500,chunk_overlap=50-100
示例:
splitter = CharacterTextSplitter(
chunk_size=500,
chunk_overlap=50 # 10% 重叠
)
重叠示意图:
块1: [0-500]
块2: [450-950] ← 重叠50个字符
块3: [900-1400]
6.3 separator(分隔符)
含义:用于初步分割文档的字符或字符串。
常用分隔符:
"\n\n":段落分隔"\n":行分隔"。":句子分隔(中文)". ":句子分隔(英文)" ":词分隔
递归分隔符列表:
separators=["\n\n", "\n", "。", "!", "?", ";", ",", ":", " "]
7. 实践建议
7.1 通用文本分割
推荐方案:
from langchain_text_splitters import RecursiveCharacterTextSplitter
splitter = RecursiveCharacterTextSplitter(
separators=["\n\n", "\n", "。", "!", "?", ";", ",", ":", " "],
chunk_size=500,
chunk_overlap=50,
length_function=len,
)
7.2 代码文档分割
推荐方案:
from langchain_text_splitters import PythonCodeTextSplitter
splitter = PythonCodeTextSplitter(
chunk_size=1000, # 代码块通常较大
chunk_overlap=100,
)
7.3 LLM 输入分割
推荐方案:
from langchain_text_splitters import CharacterTextSplitter
splitter = CharacterTextSplitter.from_tiktoken_encoder(
encoding_name="cl100k_base",
chunk_size=500, # 根据模型上下文窗口调整
chunk_overlap=50,
)
7.4 性能优化建议
-
合理设置 chunk_size:
- 太小:检索精确但丢失上下文
- 太大:保留上下文但检索不精确
- 推荐:500-1000 字符
-
设置适当的 chunk_overlap:
- 确保上下文连贯
- 通常为 chunk_size 的 10-20%
-
选择合适的分隔符:
- 优先使用自然分隔符(段落、句子)
- 避免在词中间分割
-
针对特殊格式使用专用分割器:
- 代码:PythonCodeTextSplitter
- Markdown:MarkdownHeaderTextSplitter
- HTML:HTMLHeaderTextSplitter
8. 常见问题
8.1 为什么分割后的块大小超过了 chunk_size?
原因:
- 遇到长单词或长句子时,分割器不会强制在中间切断
- 为了保持文本的完整性
解决方案:
- 这是正常现象,只要超出不多就可以接受
- 如果经常超出很多,考虑减小 chunk_size
8.2 如何选择合适的 chunk_size?
考虑因素:
- 模型的上下文窗口:不要超过模型限制
- 检索精度要求:精确检索用小块,保留上下文用大块
- 文档类型:代码用大块,普通文本用中块
推荐值:
- 普通文本:500-1000
- 代码:1000-2000
- 短文本:200-500
8.3 chunk_overlap 设置多少合适?
推荐:
- 通常为 chunk_size 的 10-20%
- 例如:chunk_size=500,chunk_overlap=50-100
注意:
- 太小:可能丢失边界信息
- 太大:浪费存储空间和计算资源
9. 总结
9.1 核心要点
-
文本分割是 RAG 的关键步骤:影响检索精度和上下文完整性
-
选择合适的分割器:
- 通用文本:RecursiveCharacterTextSplitter(推荐)
- 代码:PythonCodeTextSplitter
- 特殊格式:对应的专用分割器
-
合理设置参数:
- chunk_size:500-1000(通用)
- chunk_overlap:chunk_size 的 10-20%
- separators:优先使用自然分隔符
-
理解工作原理:
- 字符分割:按字符数
- Token 分割:按 token 数
- 递归分割:按分隔符递归
9.2 最佳实践
# 推荐的通用配置
from langchain_text_splitters import RecursiveCharacterTextSplitter
splitter = RecursiveCharacterTextSplitter(
separators=["\n\n", "\n", "。", "!", "?", ";", ",", ":", " "],
chunk_size=500,
chunk_overlap=50,
length_function=len,
is_separator_regex=False,
)
# 分割文档
splits = splitter.split_documents(documents)
10. 参考资源

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 25
25 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)