大模型相关解析
大模型(Large‑Scale Model)是指具有超大规模参数(通常以亿为单位)的机器 学习模型,尤其是在深度学习领域。这些模型通过海量数据训练,能够处理复杂的任务, 如自然语言处理(NLP)、图像识别、语音处理等。大模型的核心优势在于其强大的泛 化能力和对复杂模式的捕捉能力,广泛应用于生成式 AI、推荐系统、自动翻译等领域。

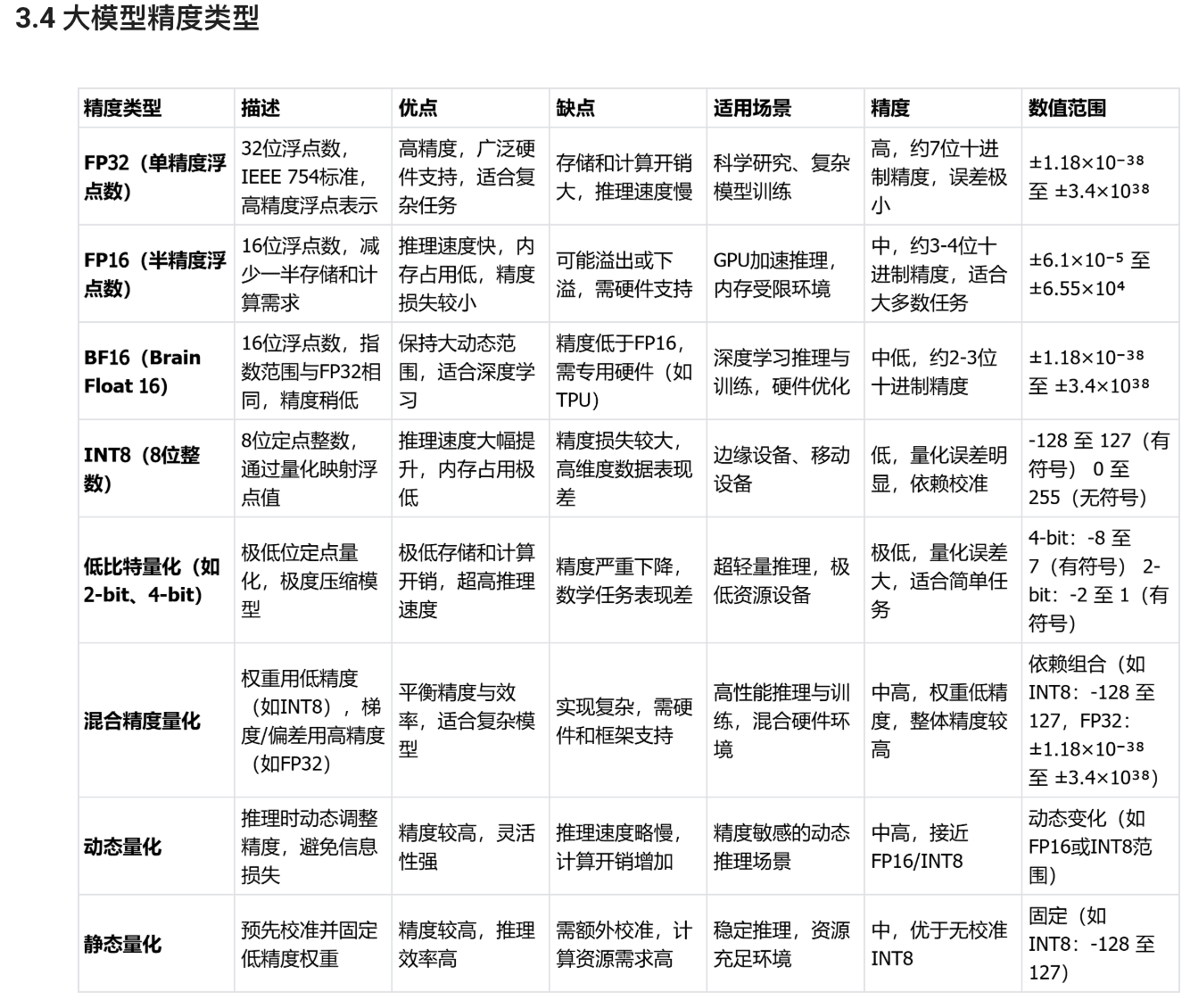
精度与数值范围关系:
高精度(如FP32)提供更细腻的数值表示,误差小,适合复杂计算。
低精度(如INT8、4-bit)范围受限,量化误差大,适合简单任务或资源受限场景。
混合精度通过高精度梯度弥补低精度权重的不足,整体精度较高。
应用场景与硬件:
FP32/FP16:GPU/CPU广泛支持,适合高精度或加速推理。
BF16:需专用硬件(如TPU、NVIDIA A100),优化深度学习。
INT8/低比特量化:边缘设备优化,需框架支持(如TensorRT)。
混合/动态/静态量化:需硬件和框架协同(如PyTorch AMP、ONNX Runtime)。
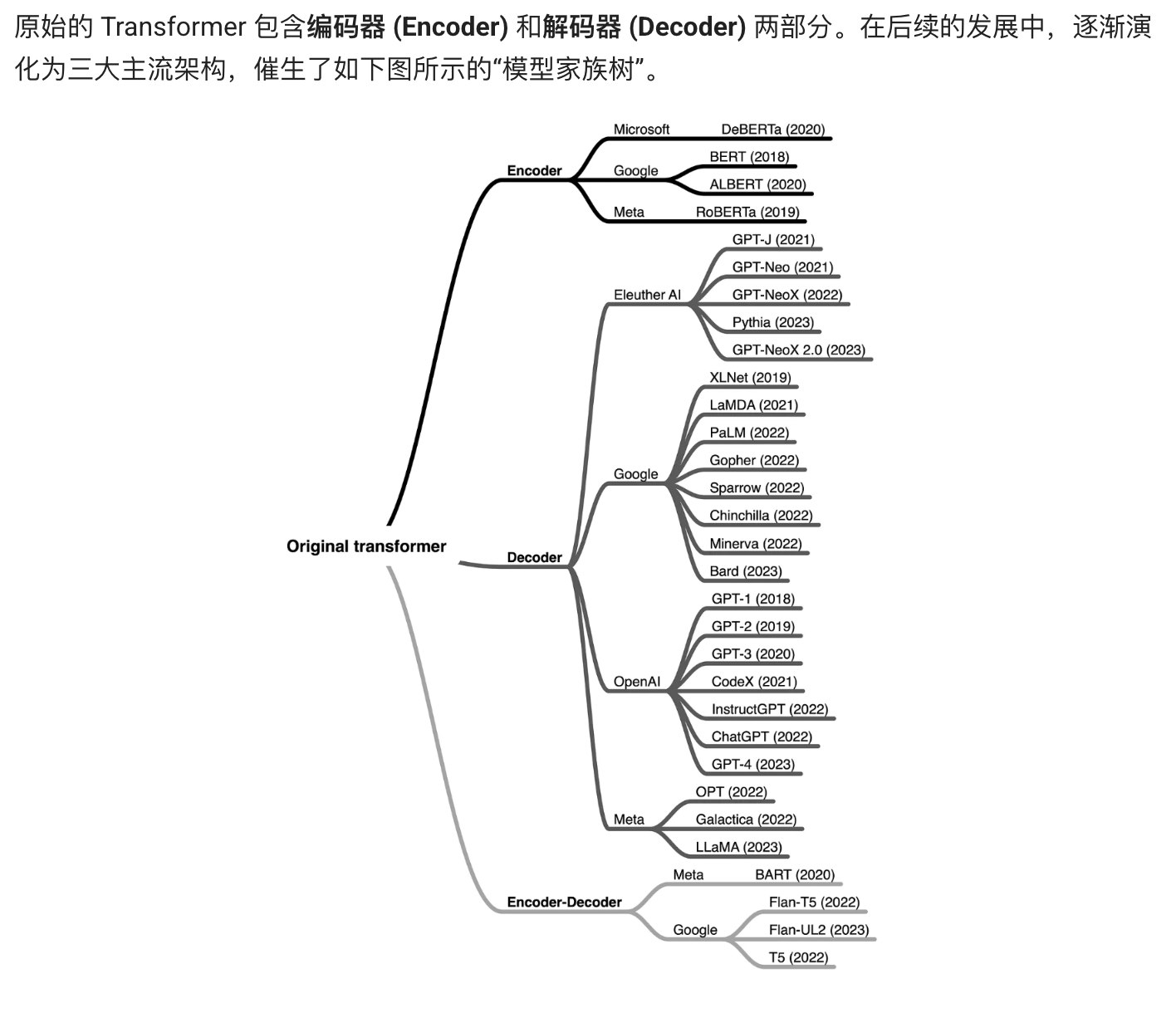
(Encoder-Only) 架构 :
代表模型:BERT, RoBERTa, DeBERTa
特点:能够同时“看到”整个输入句子的上下文(双向理解),极其擅长深度理解。
适用任务:文本分类、情感分析、命名实体识别等需要对文本进行全面理解的任务。
(Decoder-Only) 架构:
代表模型:GPT 系列, PaLM, LLaMA, ChatGPT
特点:自回归(Auto-regressive)模型,根据前面的文本预测下一个词,极其擅长内容生成。
适用任务:文章写作、聊天对话、代码生成等需要创意和流畅表达的任务。
(Encoder-Decoder) 架构:
代表模型:T5, BART, Flan-T5
特点:保留了原始 Transformer 的完整结构,适用于将一个文本序列转换为另一个文本序列的序列到序列任务。
适用任务:机器翻译、文本摘要、问答等。
LLM 的重要性在于,它们不仅仅是更强大的“语言模型”,其展现出的通用学习和推理能力,使得它们被广泛视为一条通往通用人工智能 (AGI) 的重要技术路径。

评估 大语言模型LLM 的能力至关重要,它能帮助我们了解模型的优劣、选择合适的模型以及指导模型的优化方向。
1 评估方法与指标¶
评估方法主要分为两类:人工评估 和 自动评估。
人工评估:
定义:由人类评估员根据一系列标准(如准确性、流畅性、相关性、安全性)对模型输出进行打分。
优点:最接近人类真实感受,是评估开放式、创造性任务的“金标准”。
缺点:成本高、耗时长、主观性强、难以规模化。
工业案例:在开发聊天机器人时,让人类测试员与模型进行多轮对话,并对回复的满意度进行 1-5 分的打分。
自动评估:
定义:使用算法和标准数据集来自动计算模型的性能指标。
优点:速度快、成本低、可重复、客观。
缺点:难以评估语言的创造性和细微差异,有时指标得分高但实际质量差。
常用指标:
语言模型评估:困惑度 (Perplexity, PPL):衡量语言模型预测下一个词的不确定性,值越低越好。
语言生成能力评估:
BLEU:用于机器翻译,衡量生成文本与参考文本的 N-gram 精确率。
ROUGE:用于自动摘要,衡量生成文本与参考文本的 N-gram 召回率。
METEOR / CIDEr:更复杂的评估指标,考虑了同义词、词干等。
四、大模型应用及产品形态¶
大模型(如 BERT、GPT)因其强大的语言理解和生成能力,已广泛应用于多个领域。其应用场景和产品形态根据需求和技术特性,呈现多样化发展。以下站在应用场景和产品形态两个角度来更好的理解大模型落地应用。
1 应用场景¶
大模型在实际应用中已渗透到多个行业和领域,利用其自然语言处理(NLP)能力来解决复杂问题。以下从几个典型场景出发,简要说明其落地方式。这些场景基于大模型的理解、生成和分析能力,帮助提升效率、优化决策,并创造新价值。
- 内容生成与创作:大模型可用于自动生成文章、代码、营销文案或创意内容。例如,在媒体行业,GPT系列模型可以辅助记者快速起草新闻草稿;在编程领域,类似Copilot的工具能根据用户描述生成代码片段,提高开发效率。这种场景强调生成能力的创意性和准确性,适用于需要大量文本输出的工作。
- 客户服务与聊天机器人:在电商、金融和客服领域,大模型驱动的聊天机器人(如基于BERT的意图识别系统)能处理用户查询、提供个性化推荐或解决问题。例如,银行App中的虚拟助手可以解答账户问题,减少人工干预。这种应用利用模型的对话理解能力,实现24/7服务,降低成本并提升用户体验。
- 搜索与信息检索:搜索引擎如Google或Bing整合大模型来提升搜索精度,例如通过语义理解返回更相关的结果。在企业内部知识管理系统中,模型可分析文档并回答查询,帮助员工快速找到信息。这种场景依赖模型的语义匹配能力,适用于海量数据处理的场合。
- 医疗与生物信息:大模型应用于药物发现、诊断辅助和患者咨询。例如,BERT变体可分析医学文献以识别潜在药物交互;在聊天界面中,模型能提供初步健康建议(需结合专业监督)。这种应用强调准确性和伦理性,帮助加速研究并改善医疗。
- 教育与个性化学习:在在线教育平台,大模型可生成定制化学习材料、批改作业或作为虚拟导师。例如,GPT模型能根据学生水平解释复杂概念。这种场景利用适应性生成能力,促进个性化教育,适用于K-12和职业培训。
- 金融与风险分析:大模型用于欺诈检测、股票预测或报告生成。例如,通过分析交易数据和新闻,模型可识别异常模式。这种应用结合了预测和生成能力,帮助金融机构管理风险并自动化报告。
这些场景展示了大模型的通用性,但实际部署需考虑数据隐私、偏见 mitigation 和计算资源等挑战。
2 产品形态¶
大模型的产品形态多样化,从底层技术到用户友好界面,旨在便于集成和使用。以下分类说明常见形态,每种形态根据用户需求和技术成熟度而设计,强调易用性和可扩展性。
- API 接口:最基础的产品形式,如OpenAI的GPT API或Google的BERT API。开发者通过HTTP请求调用模型,实现文本生成、翻译或分类功能。这种形态灵活,适用于自定义应用开发,例如集成到移动App中进行实时翻译。优势在于低门槛接入,但需处理API调用费用和延迟。
- 聊天机器人与虚拟助手:以对话界面呈现的产品,如ChatGPT或企业级助手(如Salesforce的Einstein)。用户通过自然语言交互获取响应。这种形态通俗易懂,适用于消费者端产品,强调多轮对话能力和上下文记忆,帮助用户解决问题或娱乐。
- 嵌入式工具与插件:集成到现有软件中的形态,例如Microsoft Office中的Copilot插件,能在Word中自动生成内容。这种产品无缝嵌入工作流,适用于办公、生产力工具,优势是提升现有系统的智能性,而非独立应用。
- 专用平台与SaaS服务:云端订阅服务,如Hugging Face的模型库或企业AI平台。用户可上传数据训练或微调模型,用于特定任务如情感分析。这种形态提供端到端解决方案,适用于中小企业,强调无代码操作和安全性。
- 开源模型与框架:如BERT的开源版本,用户可下载并本地部署。这种形态适合研究者和开发者,允许自定义优化,但需硬件支持。优势在于免费和透明性,适用于隐私敏感场景。
- 多模态产品:结合文本、图像和语音的产品形态,例如支持图片描述的GPT-4o。用户可输入多类型数据获取综合输出。这种新兴形态扩展了应用边界,适用于创意设计或多媒体分析。
总体而言,产品形态从技术导向(如API)向用户导向(如聊天界面)演进,未来可能更注重边缘计算和隐私保护,以适应多样化需求。


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 7
7 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)