【无标题】
NLP-AHU-017
- RNN简介:
RNN,即循环神经网络,一般以序列数据为输入,通过网络内部的结构设计有效捕捉序列之间的关系特征,以序列形式进行输出.由于其能敏锐捕捉针对自然界具有连续性的逻辑性输入序列(如人类语言)之间的关系故此常用于NLP之中。
PS:循环指的是其特有的循环机制
使模型隐层上一时间步产生的结果,加上此节点的输入能够作为当下时间步输入的一部分对当下时间步的输出产生影响.
三层结构:,输入、输出、隐藏层(循环在隐藏层)
1.1RNN原理及来源
RNN源自于1982年由Saratha Sathasivam 提出的霍普菲尔德网络。其设计主要受到了两个领域的启发:认知神经科学和控制理论。
在控制理论(如飞机自动驾驶)中,系统的行为不仅仅取决于当前的输入,还取决于系统的内部状态(如飞机当前的姿态、速度)。这个内部状态是历史输入的累积效应。这一核心原理和一些自然语言处理任务如简单的文本生成原理高度拟合。而认知脑科学研究大脑如何工作,利用这一知识和智能控制理论建模动态系统让神经网络拥有了模拟任何随时间变化的过程的能力。
Eg;我下午要上课
和普通的全连接网络(DNN)对比,‘我’,‘下午’,‘要’,‘上课’,对于这几个输入,普通网络认为它们之间是独立的,忽视处理输入之间的关系,在中文词‘我’后面加入词语‘李华’和‘下午’对于DNN而言是没有区别的,而RNN却会推测出‘李华’这一词在主语‘我’的后面不加其他成分词语就出现的概率极低,‘下午’这一词语出现的概率则比较高。这就是区别,根本来源于RNN机制当中的循环特性即‘当下时间步的输出’受到‘上一时间步产生的结果,加上此节点的输入的影响’
图解:
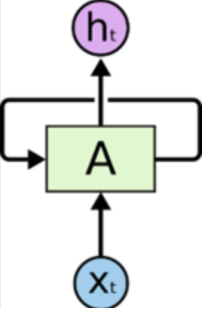
(源于网络)
1.2 RNN公式
关键点在于“循环”是怎么实现的:
输入:当前时刻的输入
(比如句子中的第 t 个词)
记忆:上一时刻传递过来的隐藏状态 ht
也就是处理上一个词后留下的记忆)
计算:通过一个激活函数(通常是计算当前的输出![]() 和更新后的记忆
和更新后的记忆![]() 。传递:把
。传递:把 ![]() 传递给下一个时刻。
传递给下一个时刻。
公式:
![]() = 激活函数
= 激活函数![]()
1.3 RNN训练原理
比之普通的神经网络(每计算完一个样本的误差,使用反向传播算法修正一次),RNN使用的是 BPTT (随时间反向传播) 算法。
Eg:s首先处理完成整个序列(本例中是“我 下午 要 上课”),计算整个序列的总误差。然后,沿着时间反向,把误差从最后一个时刻(“上课”)一路传回第一个时刻(“我”),统一修正网络参数。
1.4 RNN算法的弊端—‘梯度消失’与‘梯度爆炸’
RNN算法为了达到较好的性能需要多次一路反向传播,但是普通RNN本身不可并行计算,故当数据量和模型体量过大会制约其发展
当序列过长时(比如1000个字),误差要反向传播1000步。倘若所有的梯度都比较小,那么反向传播计算误差时,每一步传播过程中,梯度都要被乘以一个小于1的数(激活函数的导数)。乘1000次后,梯度会变得无限接近于0,导致最前面时刻的参数几乎不更新—即‘梯度消失’,网络无法学习长距离的依赖关系。
同理当所有的梯度都比较大时,反向传播计算误差时,每一步传播过程中,梯度![]()
。当W>1时,每一次的梯度随着时间步的推移呈指数级增长,导致最前面时刻的参数更新过大,难以收敛—即“梯度爆炸”
因此RNN适用场景有限:多用于短序列预测。
eg:简单的文本生成、小型时间序列。
2.LSTM
LSTM也称长短期记忆网络,是传统RNN的变式,其产生于为了解决RNN的根本性缺陷,通过引入“门控”结构和“细胞状态”,让网络选择性‘筛选’和‘遗忘’,从而缓解‘梯度消失’与‘梯度爆炸’,提高RNN性能的一种变体。
- LSTM的核心结构
定义参数
![]() :当前时刻的输入向量
:当前时刻的输入向量
![]() :上一时刻的隐藏状态
:上一时刻的隐藏状态
![]() :上一时刻的细胞状态
:上一时刻的细胞状态
![]() :Sigmoid 激活函数(输出 0 到 1,控制“门”打开的程度)
:Sigmoid 激活函数(输出 0 到 1,控制“门”打开的程度)
![]() :双曲正切激活函数(输出 -1 到 1,生成候选信息)
:双曲正切激活函数(输出 -1 到 1,生成候选信息)
![]() :逐元素相乘(Hadamard 积)
:逐元素相乘(Hadamard 积)
![]() :对应门和候选状态的权重矩阵
:对应门和候选状态的权重矩阵
![]() :对应门和候选状态的偏置项
:对应门和候选状态的偏置项
相比 RNN,LSTM 的每个单元内部更复杂,包含三个门和细胞状态:
遗忘门:
决定丢弃哪些旧信息。决定从上一时刻的细胞状态
输入门:
决定将哪些新信息存入细胞状态。
细胞状态:
输出门:决定基于当前细胞状态输出什么。
2.LSTM优缺点;
2.5.1 LSTM优点
1.解决长期依赖问题
通过精巧的门控机制(遗忘门、输入门)和独立的细胞状态,LSTM能有效地将信息传递很远(上百个时间步)。它知道什么时候该记住老信息(比如段落开头的主题),什么时候该忘记不重要的内容。
2.缓解梯度消失/爆炸
能够稳定地训练长序列,而RNN在序列稍长时就会训练失败。
3.序列建模能力强大
2.5.2 LSTM 的主要缺点
1.计算复杂,训练慢
每个LSTM单元内部有4个全连接层(遗忘门、输入门、输出门、候选状态),而普通RNN只有1个。参数量大,训练时间长,对硬件要求高。难以并行计算。
2.容易过拟合
由于参数量大,在小数据集上LSTM很容易过拟合。需要配合Dropout、正则化等技巧导致训练难度仍高于前馈网络
3.LSTM仍有梯度爆炸的可能
虽然缓解了梯度消失,但LSTM仍有梯度爆炸的可能。而且门控机制导致损失曲面不平滑,调参(学习率、初始化)比普通网络更敏感。
3.BI-LSTM
受人类阅读启发,人类在阅读时往往下文对当前文本依旧有不可忽视的影响,然而标准LSTM是单向性的。为了解决这一核心缺陷,Bi-LSTM顺势而生。
Bi-LSTM的核心目标是:让每个时刻的输出,同时融合过去和未来的信息。即使用两个独立的LSTM,一个作为正向,一个作为反向。
- BI-LISM原理
设计上分为三步:
按顺序处理序列:
- 数学表达式

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)