基于机器学习方法的二手车价格预测研究
基于机器学习方法的二手车价格预测研究(本科毕业论文)
本文为论文主体内容的电子稿,用于展示研究思路、方法流程与实验结果。图表与数据均来源于本文实验过程,正文中按章节引用。
摘要
二手车交易具有车辆个体差异大、信息不对称与经验定价占比高等特点,同款车型在不同车况下的价格波动明显。随着平台侧挂牌与交易数据规模不断扩大,利用机器学习方法构建价格预测模型,有助于为消费者提供估价参考,并为车商与平台提供定价辅助,从而提升交易效率与透明度。
本文以天池二手车数据集为研究对象,面向二手车价格回归预测任务,设计并实现了可复现的端到端建模流程。数据层面,对缺失值与异常值进行规则化处理,并基于注册时间与信息创建时间构造车龄等时间特征;建模层面,采用统一的“预处理—建模”流水线框架,将数值特征的填补与标准化、类别特征的填补与独热编码与模型训练整合,避免交叉验证中的数据泄露;评估层面,在统一口径下对比基线模型、线性模型、Bagging 模型与 Boosting 模型,并采用 5 折交叉验证从 MAE、RMSE 与 R² 等指标进行性能评估,并通过消融实验与误差分层分析验证关键预处理与特征工程策略的有效性;解释层面,采用 SHAP 对关键影响因素进行分析,以增强结果可解释性。
实验结果表明,Boosting 系列模型在本任务上整体表现最优,其中 XGBoost 在 5 折交叉验证中取得最低的 MAE(约 474),CatBoost 与 LightGBM 紧随其后,显著优于 Ridge(约 911)与随机森林(约 1071)。SHAP 分析显示,匿名特征 v0~v14 与车龄、动力、里程等特征对价格预测具有显著影响,符合二手车折旧与使用强度的业务认知。综上,本文验证了在结构化表格数据场景下,基于梯度提升树的模型在精度与效率方面的优势,并给出了一套可复用的建模、评估与解释流程,为二手车估价相关应用提供参考。
关键词:二手车价格预测;机器学习回归;XGBoost;交叉验证;特征工程;SHAP
Abstract
Used car trading often suffers from information asymmetry and experience-driven pricing. Even for the same model, price varies significantly due to differences in vehicle conditions. With the growing volume of listing and transaction data, machine learning-based valuation models can provide objective references for consumers and decision support for dealers and platforms.
This thesis investigates a used car price regression task using the Tianchi used car dataset and proposes a reproducible end-to-end workflow. At the data level, missing values and outliers are handled with rule-based preprocessing, and time-related features such as vehicle age are engineered from registration and listing timestamps. At the modeling level, a unified preprocessing-and-modeling pipeline is built to integrate imputation, scaling, and one-hot encoding with training, thus reducing the risk of data leakage in cross-validation. Multiple models ranging from simple baselines and linear regressors to bagging and boosting ensembles are compared and evaluated via 5-fold cross-validation using MAE, RMSE, and R². In addition, ablation studies and error stratification analyses are conducted to validate key preprocessing and feature engineering choices. For interpretability, SHAP is adopted to analyze key factors affecting prices.
Experimental results show that boosting-based models achieve the best performance on this task. In particular, XGBoost obtains the lowest MAE (~474) under 5-fold cross-validation, followed by CatBoost and LightGBM, and significantly outperforms Ridge (~911) and Random Forest (~1071). SHAP indicates that anonymous v-features as well as vehicle age, power, and mileage are among the most influential factors, which aligns with domain knowledge about depreciation and usage intensity. Overall, this work demonstrates the effectiveness of gradient boosting models on structured tabular data and provides a reusable workflow for modeling, evaluation, and interpretation in used car valuation.
Keywords: Used car price prediction; Machine learning regression; XGBoost; Cross-validation; Feature engineering; SHAP
第1章 绪论
1.1 研究背景
二手车市场具有交易频次高、车辆个体差异大、信息维度复杂等特点。对同一品牌与车型而言,车辆使用年限、里程、维修情况、排量/动力、地区等因素都会影响定价。传统定价方法往往依赖经验,难以在大规模业务中保持稳定一致[20]。
随着二手车平台积累了大量结构化车辆信息与价格数据,基于机器学习的价格预测可以从历史数据中学习规律,实现对新样本车辆的快速估价,为交易决策提供参考。近年来围绕二手车估价与价格预测的研究逐步增多,常见技术路线包括随机森林、梯度提升树(如 LightGBM/XGBoost)以及 Stacking 融合模型等[1]。
除上述方法外,亦有研究从集成融合角度进一步提升结构化回归任务性能,并讨论了多模型互补对估价精度的增益[4]。
在模型选择上,一些工作尝试将 XGBoost 等提升树方法用于二手车估价建模,并给出与传统模型的对比分析[19]。
围绕常用树模型的应用,也有研究对 LightGBM 与随机森林在二手车估价任务中的表现进行对比与讨论,为模型选型提供了经验依据[5]。
针对特定细分市场,部分研究聚焦于新能源二手车,探讨其价格形成机制与折旧差异对预测模型的影响[11]。
在影响因素层面,有研究结合车辆属性与市场信息讨论了影响二手车价格的关键因素,并在此基础上开展预测建模,为本文后续的特征解释提供了参考[7]。
在方法演进方面,近年来也有研究将神经网络等方法引入二手车价格预测,并尝试从不同建模范式角度开展估价分析,为模型路线的选择提供了补充视角9。
此外,围绕融合建模思路,相关工作讨论了 Stacking 等模型融合方法在二手车价格预测中的应用效果,为本文对融合路线的认识提供了补充[10]。
除集成学习外,部分研究还结合 BP 神经网络与群智能优化等方法对经济型二手车估价进行建模分析,体现了不同建模范式在该任务中的可行性[9]。
在本科层面的相关研究中,基于机器学习方法构建二手车价格预测模型并开展对比实验的工作也较为常见,为本文的研究设计与实验流程提供了参考[13]。
1.2 国内外研究现状
1.2.1 国外研究现状
围绕二手车估价问题,国外研究大体沿着“特征构造—模型选择—评估解释”的路径演进。早期工作多采用线性回归等方法对价格形成机制进行建模,通过将品牌、车龄、里程、排量/动力等特征纳入回归框架,实现对价格的快速估计。该类方法可解释性较强,但在特征非线性与交互效应显著的场景下往往存在精度上限。
随着机器学习方法在结构化数据上的应用成熟,集成树模型逐渐成为估价研究中的主流选择。随机森林通过 Bagging 与特征随机采样提升稳健性,能够在一定程度上刻画非线性关系;梯度提升树(GBDT)及其工程化实现(如 XGBoost、LightGBM)通过逐步拟合残差提升拟合能力,在表格数据任务中往往具有更优表现[19]。相关研究普遍指出,在合理的特征工程与数据清洗前提下,提升树模型相较线性模型与单一树模型能够带来更显著的精度收益[5]。
在模型融合与集成方面,部分研究从多模型互补角度出发,采用 Stacking 等融合策略对不同类型基模型的预测进行二次学习,以进一步提升估价精度与稳定性4。与此同时,也有研究尝试将神经网络等深度学习方法引入价格预测,或结合更丰富的信息源(如文本描述、图像等)以增强对车况差异的刻画能力,为传统表格建模路线提供补充视角[9]。
1.2.2 国内研究现状
国内研究在数据来源与任务定义上既包含公开平台数据,也包含区域市场或特定车型样本,研究重点通常聚焦于特征工程、异常值与缺失处理、以及模型对比与落地可行性。一方面,针对结构化字段的清洗与稳健预处理被认为是提升估价模型稳定性的基础;另一方面,提升树与集成融合方法(如 LightGBM、Stacking)在多项工作中表现出较强的适用性,为工程落地提供了经验依据[1]。
在影响因素层面,部分工作从车辆属性与市场信息角度分析价格关键驱动,并结合业务经验对模型输出进行解读,以提高估价模型在实际应用中的可信度与可用性[7]。针对特定细分市场(如新能源二手车),相关研究也讨论了折旧规律与影响因素差异,并据此调整建模与特征设计[11]。在本科与工程实践场景中,围绕“可复现流程 + 对比实验 + 图表化呈现”的研究与实现也较为常见,为本文的整体实验设计提供了参考[13]。
1.2.3 小结与本文研究定位
总体来看,现有研究为二手车价格预测提供了较为成熟的技术路径:在数据侧强调清洗与稳健预处理,在模型侧以集成树与提升树为主,在评估侧常采用交叉验证等策略获得更稳定的泛化估计[1]。然而,不同研究在数据规模、特征可得性与评价口径上存在差异,导致结果可比性有限;同时,模型解释往往需要与业务常识结合,避免将相关性误解为因果关系[7]。
基于上述现状,本文以公开数据集为对象,构建统一可复现的端到端流程,系统对比线性模型、集成树模型与提升树模型,并在实验章节中结合 SHAP 与误差分析给出影响因素解释,同时以置换重要性作为补充对照,以提升结论的可验证性与可读性。
1.3 研究意义
本研究具有一定的实践与学术价值。在实践层面,二手车价格预测模型能够为消费者提供更客观的估价参考,减少信息不对称带来的决策风险;同时也可为车商或平台提供定价与筛选线索,辅助运营人员快速识别异常标价与潜在优质车辆,从而提升交易效率与透明度。在学术层面,本文通过对线性模型、集成模型与提升模型的系统对比,展示了不同建模范式在结构化表格回归任务中的性能差异;并在可复现的实验框架下,总结了从数据清洗、特征工程到评估解释的一套流程,为同类研究提供参考[13]。
1.4 研究内容
本文围绕二手车价格回归预测任务展开研究,主要工作包括数据理解与预处理、特征工程构建、模型训练与对比、评估与解释以及最终结果输出五个部分。首先对数据进行缺失值与异常值处理,并对关键字段进行类型规范化;其次基于时间字段构造车龄等衍生特征,以增强模型对车辆折旧规律的刻画能力;随后在统一的预处理框架下对比 DummyMedian、线性模型、Bagging 模型与 Boosting 模型,并采用 5 折交叉验证对其泛化性能进行评估;最后在最优模型基础上生成测试集预测文件,并通过 SHAP 与误差分析形成可解释结论与论文图表,同时以置换重要性作为补充对照[3]。
总体技术路线可概括为:数据读取与清洗 → 特征构造与异常值处理 → 预处理(数值/类别) → 模型训练与交叉验证 → 最优模型选择 → 全量训练与预测输出 → SHAP 解释分析与误差分析(置换重要性作为补充对照) → 图表与结论整理。

图1-1 技术路线图
1.5 研究方法与创新点
本文在研究方法上强调“流程完整、可复现与可解释”。具体而言,在数据层面以规则化清洗与管道化预处理为主,尽量减少缺失与异常对模型训练的干扰;在模型层面采用“基线—对比—主力”的对比思路,分别选取 DummyMedian、线性模型、Bagging 模型与 Boosting 模型,并通过交叉验证进行客观评价;在解释层面以 SHAP 与误差分析相结合,并以置换重要性作为补充对照,既给出全局影响因素,也展示模型在不同样本区间的拟合表现,从而使结论更具可读性与可验证性。
为与第 5 章解释分析口径一致,本文以 SHAP 作为主要解释方法用于输出特征贡献与方向性结论,并结合误差分层分析形成“重要性—误差—消融”的联合证据;置换重要性作为补充对照,用于验证全局重要性排序的稳定性。
相较于仅关注单一模型或单一指标的结果汇报,本文的“创新点/贡献点”主要体现在流程设计与证据链组织上:
(1)统一的端到端流水线与评估口径。本文将预处理(缺失填补、标准化、独热编码)与模型训练封装为同一 Pipeline,并在交叉验证的每一折内仅由训练折拟合预处理参数,从而降低数据泄露风险并提升对比结论的可复现性[17]。
(2)面向可复核结论的实验组织。除模型对比外,本文围绕关键工程步骤(时间特征构造、异常值处理、字段剔除、匿名特征保留)设计消融实验,并结合误差分层分析讨论不同样本区间的风险结构,使“为什么这样处理/为什么选这个模型”的结论具备可验证依据。
(3)解释性分析与论文材料自动化导出。本文以 SHAP 为主输出全局重要性与方向性解释,并以置换重要性作为补充对照;同时围绕论文写作需求自动导出对比表格与图表,使实验结果能够直接用于论文与答辩材料整理。
1.6 论文结构安排
本文共分为 6 章,结构安排如下:第 1 章为绪论,介绍研究背景与意义、国内外研究现状、研究内容与技术路线;第 2 章给出相关理论基础与关键方法,并说明模型评价指标;第 3 章介绍数据来源与预处理流程,包括缺失值与异常值处理以及特征工程;第 4 章给出模型构建与实验设计,包含参数设置与交叉验证策略;第 5 章展示实验结果并开展分析,包括模型对比、消融实验、误差分层与 SHAP 可解释性等内容;第 6 章给出总结与展望;最后在附录中给出项目复现方式与主要输出文件清单,便于复核与复现。
第2章 相关理论基础
2.1 问题定义
给定一辆二手车的特征向量 X,预测其价格 y。该任务属于监督学习中的回归问题。
在形式化表达上,训练集提供了由特征与标签组成的样本集合:
模型学习目标是得到函数:
$$
f(\cdot)
$$
使得在未见样本上预测值尽量接近真实值:
$$
\hat{y}=f(X)
$$
由于真实业务中更关心“平均偏差大小”,本文以 MAE 作为主优化目标进行模型选择,并采用交叉验证估计模型在不同数据划分下的稳定性[16]。
进一步地,本文对目标变量采用对数变换后建模。记原始价格为 y,变换后的目标为:
$$
y^{(\log)}
$$
则有:
$$
y^{(\log)} = \log(1+y)
$$
模型训练阶段学习:
$$
f(X) \approx y^{(\log)}
$$
在评估与输出阶段再将预测值还原为原尺度:
$$
\hat{y}^{(\log)}
$$
$$
\hat{y} = \exp(\hat{y}^{(\log)}) - 1
$$
这种做法的动机是缓解价格分布的长尾与右偏问题,使模型更容易在不同价格区间取得相对均衡的误差表现,从而提升整体拟合稳定性。
在指标计算层面,本文始终在“还原后的价格尺度”上计算 MAE、RMSE 与 R²,使评估结果更符合业务直观含义(例如平均误差是多少元/多少单位)。同时,由于模型内部拟合的是对数空间的目标,预测时对数空间的小误差在高价区间可能对应更大的绝对误差,因此第 5 章将结合误差图进一步讨论不同价格区间可能存在的误差差异。
从理论上看,对数变换相当于将“相对误差”更多地纳入优化视角:在对数空间中,相同的绝对误差更接近于原空间的相同比例误差。因此该变换往往能够减少高价样本对训练目标的支配,提升低价与中价样本的拟合质量。与此同时,对数变换也可能带来一个副作用:若高价区间样本较少,模型在对数空间学习到的规律在还原到原空间后可能仍表现为高价区间的绝对误差偏大。针对这一点,本文在实验结果章节中结合散点图与残差分布进行讨论,并在展望中提出可通过分段建模或引入分位数损失等方式进一步缓解异方差。
2.2 预处理与建模框架(流水线式建模)
本文采用统一的流水线式建模框架,将数据预处理与模型训练联结为整体,确保训练与预测阶段的数据处理完全一致。在预处理部分,数值特征依次执行中位数填充与标准化,以降低量纲差异对模型的影响;类别特征依次执行众数填充与独热编码,将离散类别转换为模型可学习的稀疏向量表示。通过统一封装,能够提升实验的可复现性与工程可落地性[17]。
从数学角度看,数值特征缺失填补可视为用训练数据的统计量对缺失项进行替代。对于第 j 个数值特征,记训练集观测值集合为 {x_ij}(i=1,…,n),其填补值取中位数:
$$
\tilde{x}_j = \mathrm{median}\left(\{x_{ij}\}_{i=1}^{n}\right)
$$
对任一样本 i 的该特征,缺失值按如下规则处理:
$$
x'_{ij}=\begin{cases} x_{ij}, & x_{ij}\ \text{非缺失}\\ \tilde{x}_j, & x_{ij}\ \text{缺失} \end{cases}
$$
标准化用于消除量纲差异,令 μj、σj 分别为训练折上第 j 个特征的均值与标准差,则:
$$
z_{ij}=\frac{x'_{ij}-\mu_j}{\sigma_j}
$$
对于类别特征,独热编码将类别取值映射为 0/1 指示向量。设第 k 个类别特征在训练折上出现的类别集合为 C_k,对任一样本 i、类别 c∈C_k,其独热表示为:
$$
\mathrm{onehot}(x_{ik}=c)=\mathbb{I}(x_{ik}=c)
$$
与“先单独做预处理再训练模型”的方式相比,流水线式建模能够显著降低出错概率。一方面,在交叉验证过程中,预处理步骤会在每一折的训练数据上拟合(例如计算中位数、标准差、确定类别集合),再应用到验证数据,从而避免数据泄露;另一方面,最终训练与预测也使用同一套处理流程,保证线上/线下输入一致。对于包含类别特征的任务而言,这一点尤为重要,因为独热编码的类别集合需要由训练数据确定,否则可能出现特征空间不一致的问题。
2.3 模型说明
2.3.1 Ridge 回归(基线模型)
Ridge 回归在最小二乘损失基础上引入 L2 正则,有助于缓解多重共线性,作为线性基线模型具有训练快、可解释性较强的特点。
从优化目标角度,令样本特征与对数空间目标分别为:
$$
\mathbf{x}_i\in\mathbb{R}^d
$$
$$
y_i^{(\log)}
$$
则 Ridge 回归求解:
$$
\min_{\mathbf{w}, b}\ \sum_{i=1}^{n}\left(y_i^{(\log)}-(\mathbf{w}^\top\mathbf{x}_i+b)\right)^2+\lambda\|\mathbf{w}\|_2^2
$$
其中 λ 为正则化系数,用于抑制过大的参数幅度,从而降低过拟合风险。由于类别特征经过独热编码展开后维度可能显著增大,引入 L2 正则也有助于使模型更稳定。
从偏差-方差角度看,Ridge 模型属于高偏差、低方差方法,能够提供稳定但相对“保守”的拟合能力。在特征工程不足或数据非线性较强时,Ridge 的性能上限往往较明显,因此本文将其用于建立基线与对比,判断更复杂模型是否带来显著收益。
2.3.2 随机森林回归(对比模型)
随机森林通过对样本与特征进行随机采样并集成多棵决策树,能够拟合复杂的非线性关系。由于全量 5 折交叉验证耗时较长,本文对随机森林采用抽样策略(例如 30000 条样本)完成对比实验,以确保实验可在可控时间内运行。
随机森林可视为对 T 棵树模型的集成。记第 t 棵树对应的预测函数为:
$$
h_t(X)
$$
则随机森林的输出可写为:
$$
\hat{y}^{(\log)} = \frac{1}{T}\sum_{t=1}^{T} h_t(X)
$$
这种“平均化”思想能够有效降低单棵树的方差,使模型对训练数据扰动更不敏感。但在高维稀疏特征输入与样本量较大时,训练多棵树的成本会显著上升,因此本文将其定位为对比模型而非最终模型。
随机森林的优势在于对非线性与特征交互具备一定刻画能力,且对异常值与特征缩放不敏感;不足在于在高维稀疏特征场景下训练与预测成本较高,且类别特征往往需要通过独热编码展开,导致维度膨胀。结合本文实验环境与任务规模,随机森林更适合作为“非线性对比模型”而非最终主力模型。
2.3.3 LightGBM 回归(主力模型)
LightGBM 是基于梯度提升树的高效实现,对结构化表格数据具有较强表现。其通过叶子生长策略与直方图算法提升训练效率,并能有效捕捉非线性与特征交互[2]。
梯度提升树(GBDT)的核心思想是“加法模型 + 前向分步优化”。将模型写为多棵回归树的加和:
$$
f_M(X)=\sum_{m=1}^{M} \gamma_m h_m(X)
$$
其中第 m 棵树(弱学习器)与缩放系数分别为:
$$
h_m(X)
$$
$$
\gamma_m
$$
第 m 轮迭代通过拟合当前损失函数的负梯度(残差方向)来更新模型,从而逐步降低整体误差。对于回归任务,若使用平方损失,则负梯度可近似为残差:
$$
r_{im} \approx y_i^{(\log)} - f_{m-1}(x_i)
$$
新树通过拟合上述残差来修正上一轮模型的不足。
LightGBM 在实现上采用直方图分裂、按叶子生长(leaf-wise)策略以及多种正则手段(如最大深度、最小叶子样本、L1/L2 正则等),在保证精度的同时提升训练效率与泛化性能。
与随机森林相比,提升树模型通常能够以更少的树数量获得更强的拟合能力,并且在结构化数据任务中往往表现更优。LightGBM 同时提供对缺失值与类别特征编码后的稀疏输入的良好支持,训练速度与精度在工程实践中具有优势。本文将 LightGBM 作为 Boosting 模型的重要代表之一,并在第 5 章与 XGBoost、CatBoost 等模型在统一交叉验证口径下进行对比。
2.3.4 XGBoost 回归(Boosting 代表)
XGBoost 属于梯度提升树(GBDT)的工程化实现之一,其优化思路可概括为“加法模型 + 逐步拟合残差 + 显式正则”。令第 $t$ 轮迭代的预测为 $\hat{y}_i^{(t)}$,则:
$$
\hat{y}_i^{(t)}=\hat{y}_i^{(t-1)} + f_t(x_i)
$$
其中 $f_t$ 表示第 $t$ 棵回归树。XGBoost 在目标函数上引入结构化正则项:
$$
\mathcal{L}^{(t)} = \sum_{i=1}^{n} \ell\left(y_i^{(\log)},\ \hat{y}_i^{(t-1)} + f_t(x_i)\right) + \Omega(f_t)
$$
$$
\Omega(f)=\gamma T + \frac{\lambda}{2}\sum_{j=1}^{T} w_j^2
$$
其中 $T$ 为叶子数,$w_j$ 为第 $j$ 个叶子的输出值,$\gamma$ 与 $\lambda$ 分别控制树复杂度与叶子权重幅度。
为高效求解第 $t$ 轮增量模型,XGBoost 对损失函数在 $\hat{y}_i^{(t-1)}$ 处进行二阶泰勒展开。记一阶、二阶导数分别为:
$$
g_i = \frac{\partial \ell\left(y_i^{(\log)},\ \hat{y}_i^{(t-1)}\right)}{\partial \hat{y}_i^{(t-1)}},\quad h_i = \frac{\partial^2 \ell\left(y_i^{(\log)},\ \hat{y}_i^{(t-1)}\right)}{\partial (\hat{y}_i^{(t-1)})^2}
$$
则第 $t$ 轮的近似目标可写为:
$$
\tilde{\mathcal{L}}^{(t)} \approx \sum_{i=1}^{n}\left(g_i f_t(x_i) + \frac{1}{2} h_i f_t(x_i)^2\right) + \Omega(f_t)
$$
在给定树结构的情况下,某叶子 $j$ 的最优输出为:
$$
w_j^* = -\frac{\sum_{i\in I_j} g_i}{\sum_{i\in I_j} h_i + \lambda}
$$
其中 $I_j$ 为落入叶子 $j$ 的样本集合。分裂增益可由该近似目标推导得到,用于贪心选择最优分裂,从而逐步提升模型拟合能力。
2.3.5 CatBoost 回归(Boosting 代表)
CatBoost 同样属于梯度提升树框架,但其核心特点在于对类别特征的处理与训练偏差控制。对于包含类别变量的场景,直接对类别进行目标编码可能引入目标泄露(target leakage)与预测偏移(prediction shift)。CatBoost 采用基于样本顺序的统计编码思想:对类别取值 $c$ 的编码不使用“全量数据的标签均值”,而是使用“在当前样本之前出现的同类样本标签统计量”的平滑估计,从而降低泄露风险。
在损失优化上,CatBoost 仍可写为加法模型:
$$
f_M(x)=\sum_{m=1}^{M} \eta h_m(x)
$$
其中 $\eta$ 为学习率,$h_m$ 为第 $m$ 棵树。CatBoost 在工程实现中常配合对称树(symmetric tree)等结构约束,以提升训练效率与稳定性。
2.4 模型评价指标
为评价回归模型的预测效果,本文采用 MAE、RMSE 与 R² 三个指标。其中,MAE(Mean Absolute Error,平均绝对误差)能够直观反映预测误差的平均水平;RMSE(Root Mean Squared Error,均方根误差)对较大的误差更敏感;R²(决定系数)用于衡量拟合优度与解释程度。综合考虑可解释性与业务直观性,本文以 MAE 作为主指标用于模型选择。
MAE 与 RMSE 的计算公式如下:
$$
\mathrm{MAE}=\frac{1}{n}\sum_{i=1}^{n}\left|y_i-\hat{y}_i\right|
$$
$$
\mathrm{RMSE}=\sqrt{\frac{1}{n}\sum_{i=1}^{n}\left(y_i-\hat{y}_i\right)^2}
$$
R² 的定义为:
$$
R^2 = 1-\frac{\sum_{i=1}^{n}(y_i-\hat{y}_i)^2}{\sum_{i=1}^{n}(y_i-\bar{y})^2}
$$
在二手车估价任务中,MAE 的业务解释性尤为突出:它可以直接回答“平均预测偏差是多少”,便于与实际定价容忍区间进行对照。RMSE 对大误差更敏感,能够反映模型是否存在“少数样本预测极差”的现象,因此本文同时报告 RMSE 以辅助判断模型风险。R² 更多从统计拟合角度衡量解释能力,但在长尾分布与异方差存在的情况下,其直观意义可能不如 MAE 明确。
需要说明的是,本文训练阶段在对数空间拟合目标,但在评估时将预测值还原到原价格尺度后再计算 MAE、RMSE 与 R²,使指标含义与业务口径一致。
第3章 数据来源与预处理
3.1 数据来源与字段说明
本节说明本文数据来源、字段构成以及后续预处理的对象范围。输入为天池二手车公开数据集的训练集与两份测试集(testA、testB);输出为字段类型划分、缺失情况统计表以及对应可视化结果,用于支撑后续“为何需要做缺失处理/异常值处理/编码与特征工程”等决策。
本文使用天池二手车数据集(结构化表格数据),包含训练集与两份测试集(testA、testB)。训练集中包含价格字段 price 作为预测目标,测试集不包含该价格字段[8]。
数据字段主要包括四类信息:其一为基础车辆属性(如品牌、车型、车身类型、燃油类型、变速箱类型等);其二为关键数值特征(如动力、里程等);其三为时间相关字段(用于反映车辆注册与信息创建时间);其四为匿名特征(如 v0~v14),通常由平台通过特征抽取或编码生成,能够显著提升预测精度但业务含义不一定可直接解释。
从研究角度看,选择该类公开数据集具有两方面优势:一方面,数据覆盖品牌、车型、里程、动力、时间等典型影响因素,能够较好地反映二手车定价中“折旧+配置+使用强度”的主要结构;另一方面,数据规模较大且字段形式较为标准,适合开展对比实验并检验不同机器学习模型在结构化回归任务中的适用性。需要强调的是,公开数据集与真实商业交易数据在信息维度上仍存在差异,例如真实场景往往还包含事故记录、维修保养、过户次数、配置清单、照片或文字描述等更丰富的车况信息,因此本文的研究结论更适用于“结构化信息较为完备但仍存在缺项”的估价场景。
从字段类型上看,基础车辆属性通常以离散类别形式出现,能够反映车辆的品牌定位、细分市场与供需差异;数值特征能够刻画车辆使用强度与技术参数,对价格形成直接约束;时间字段与折旧规律密切相关,特别是注册时间与信息创建时间的差异能够在一定程度上反映车辆使用年限;匿名特征则可能融合了更复杂的统计信息或平台侧特征工程结果,虽然难以直接解释,但在模型预测中往往具有较高贡献。基于上述理解,本文在数据预处理与特征工程中强调“稳健、可复现、少假设”的原则,在尽量减少噪声影响的同时保留字段的原始信息量。
从数据规模与建模难度看,该数据集具有三点典型特征:第一,样本量较大且覆盖多品牌多车型,能够支撑训练相对复杂的模型;第二,特征类型混合(数值+类别+日期+匿名特征),适合检验预处理与特征工程能力;第三,价格分布呈现明显长尾与右偏,需要通过目标变换与稳健评估策略提高模型稳定性。
为便于读者明确“初始变量与最终输入特征”的对应关系,本文将特征处理过程概括为四类:
(1)初始变量(原始字段)。原始数据包含目标列 price(仅训练集有)、基础类别属性(如品牌、车身类型、燃油类型、变速箱等)、关键数值特征(如 power、kilometer 等)、时间字段(regDate、creatDate)以及匿名特征 v0~v14。
其中,基础类别属性字段除 brand、bodyType、fuelType、gearbox、notRepairedDamage 等外,还包含用于描述车型与交易信息的 model 与 offerType 等变量。为满足“变量口径清晰”的写作要求,本文将上述字段统一视为类别变量,并在流水线中进行缺失值填补与编码处理。
(2)清洗后的变量。本文将 notRepairedDamage 字段中非规范取值统一视为缺失;对 power 中非正值按缺失处理;对 kilometer 设置上限截断;并对训练集 price 进行异常样本剔除与上侧截断,以降低极端样本对拟合的干扰。
(3)衍生特征(特征工程变量)。在启用时间特征时,本文由 regDate 与 creatDate 构造车龄天数 car_age_days,并将日期拆分为 reg_year、reg_month、creat_year、creat_month 四个更易学习的数值特征;原始日期字段不直接作为模型输入。
(4)最终输入特征集合。除目标列 price 外,本文保留清洗与衍生后的全部特征作为模型输入;同时,为避免高基数字段带来的维度膨胀与过拟合风险,删除高基数文本列 name。类别特征在建模流水线中统一进行缺失填补与独热编码,数值特征统一进行缺失填补与标准化,从而得到可供模型训练的最终特征表示。
为便于读者在通读全文时快速定位“哪些是初始变量、哪些是预处理后的变量、哪些最终进入模型”,本文将关键字段的处理口径汇总为对照表,如表3-0所示。
表3-0 初始变量—预处理/衍生变量—是否入模对照
| 字段/变量 | 变量类型(原始) | 预处理/特征工程口径 | 是否进入模型 |
|---|---|---|---|
| price | 数值(标签) | 作为回归目标;训练时做 log(1+price) 变换,评估与输出时再还原 | 否(标签) |
| SaleID | 标识列 | 仅用于样本标识与结果文件输出 | 否 |
| name | 高基数文本/编码列 | 高基数,易导致维度膨胀与过拟合风险,字段级剔除 | 否 |
| regDate、creatDate | 日期字段 | 解析为日期后构造 car_age_days、reg_year、reg_month、creat_year、creat_month;原始日期列不直接入模 | 否(原始列) |
| car_age_days、reg_year、reg_month、creat_year、creat_month | 数值(衍生) | 时间特征衍生结果;缺失按数值规则填补并标准化 | 是 |
| power | 数值(原始为字符列) | 转为数值;power≤0 置为缺失;上侧截断(分位数) | 是 |
| kilometer | 数值(原始为字符列) | 转为数值;上侧截断到 15 | 是 |
| notRepairedDamage | 类别/二元(原始为字符列) | 仅保留明确 0/1,其余置为缺失;类别列按众数填补并编码 | 是 |
| brand、bodyType、fuelType、gearbox、model、offerType、regionCode、seller | 类别(部分已数值化编码) | 不做人为重编码;在流水线中统一缺失填补;对 object 类型字段做独热编码 | 是 |
| v_0~v_14 | 数值(匿名特征) | 保留为连续数值特征;按数值规则填补并标准化 | 是 |
为增强“数据来源与预处理”部分的可复核性,本文对字段类型与缺失情况进行统计,并给出表格与可视化证据,字段级统计结果由脚本自动导出(Used-Car-Price-Forecasting/outputs/data_profile_fields_missing.csv),统计摘要如表3-1所示。
表3-1 训练集字段缺失率统计(Top8,按缺失率降序)
| 字段 | 数据类型 | 缺失率 |
|---|---|---|
| car_age_days | float64 | 13.53% |
| v_14 | float64 | 9.41% |
| creat_month | float64 | 9.41% |
| creat_year | float64 | 9.41% |
| reg_year | float64 | 7.56% |
| reg_month | float64 | 7.56% |
| v_13 | float64 | 2.39% |
| v_12 | float64 | 0.98% |
为直观展示缺失主要集中在哪些字段、缺失率大致处于何种水平,本文绘制字段缺失率 Top20 柱状图,如图3-1所示。
图3-1 训练集字段缺失率Top20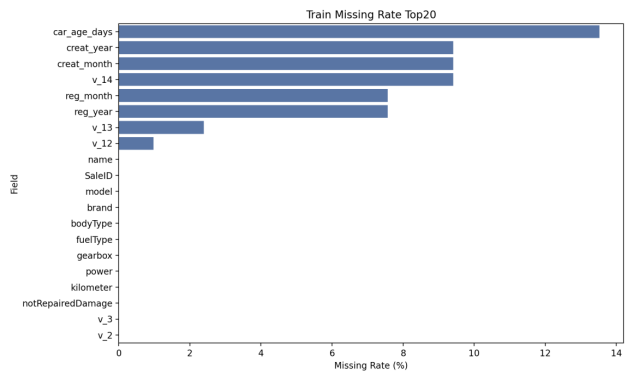
进一步地,为观察缺失是否呈现“成组缺失/结构性缺失”等模式,本文对训练集进行抽样并绘制 Top30 字段缺失热力图,如图3-2所示。
图3-2 缺失分布热力图(训练集抽样,Top30字段;)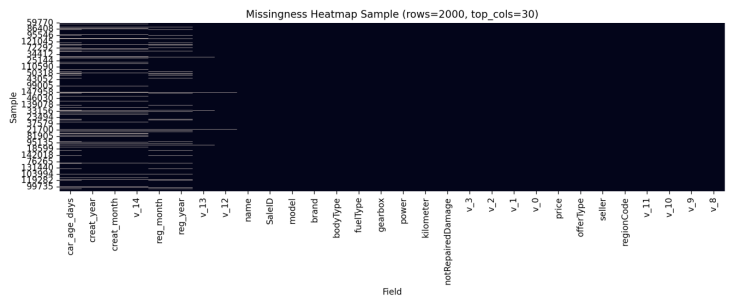
3.2 缺失值处理
本节说明缺失值处理的目标与实施口径。输入为包含缺失值与非规范取值的原始特征列,输出为完成缺失值规范化与填补后的特征矩阵,并保证训练、交叉验证与最终预测阶段使用一致的填补策略。
缺失值处理遵循“尽量不丢样本、同时避免引入明显偏差”的原则。对于维修损伤相关字段,仅保留明确的二元取值,其它非规范取值统一视为缺失;对于数值特征,使用中位数填充以降低离群点对填充值的影响;对于类别特征,使用众数填充以保持类别分布的稳定性。
需要说明的是,缺失值填充并不是为了“恢复真实值”,而是为了让模型在训练与预测阶段保持一致的输入空间。本文将缺失值处理作为预处理流程的一部分,使其在交叉验证的每一折中仅使用训练折的数据估计填充值,再应用于验证折,从而避免将验证折信息泄露到训练过程。
在缺失机制方面,二手车数据的缺失值通常并非完全随机:一部分缺失可能来自信息采集环节(例如卖家未填写或平台未抓取到),另一部分缺失则可能具有业务含义(例如某些配置缺失与低配车型相关,或某些字段缺失与车辆来源渠道相关)。在本科论文的研究范围内,本文以稳健处理为主,避免在缺失机制未知的前提下做过多因果推断。采用中位数/众数等简单策略的优点是可解释、稳定、实现成本低,能够保证模型在不同数据划分下具有一致表现;不足在于可能低估缺失背后的结构信息。未来工作可进一步引入缺失指示变量或更复杂的插补方法,以探索缺失本身是否对价格具有额外解释力。
在已有研究中,缺失与噪声往往被视为影响估价精度的重要因素之一,针对缺失机制的稳健处理有助于提高模型的可迁移性与稳定性[12]。
3.3 异常值处理与截断规则
本节说明异常值处理与截断规则的目的、对象与输出。输入为包含离群点与明显不合理取值的训练集/测试集字段,输出为经规则化清洗后的训练集(用于模型拟合)以及经一致截断后的测试集特征(用于预测),从而降低极端值对模型分裂与拟合的干扰。
考虑到二手车数据中存在明显离群与异常值,为提高模型稳健性,本文对部分特征进行规则化处理(具体阈值来源于数据分布观察与工程经验):
具体而言,针对训练集中的价格字段,对过小、过大或明显不合理的样本进行清洗或截断处理,以降低离群样本对模型拟合的干扰;针对动力字段,将非正值视为缺失,从而避免不合理动力值破坏模型的数值规律;针对里程字段,对极端大里程设置上限截断(例如上限 15),使该特征在合理范围内变化,从而提升模型的稳定性与泛化能力。
从数学形式上,截断(clipping/winsorization)可表示为将特征限制在给定上界(或区间)内。以第 j 个数值特征为例,若设其上界为 u_j,则:
$$
x'_{ij}=\min(x_{ij},\ u_j)
$$
若上界由训练数据分位数确定(例如 99% 分位数),则:
$$
u_j = Q_{0.99}(\{x_{ij}\}_{i=1}^{n})
$$
异常值处理在回归任务中尤其重要。若存在极少量异常高价或异常低价样本,模型可能为了拟合这些点而牺牲大多数样本的拟合效果,最终导致 MAE 等指标劣化。通过清洗或截断,可以将极端样本的影响控制在合理范围内,使模型更关注主要样本分布,从而提升泛化能力[20]。
从统计学习角度看,异常值会显著影响以平方损失为代表的优化目标,使模型在训练过程中对少数点施加过高权重,进而造成参数估计偏移;即便使用 MAE 作为主要评价指标,异常值也会在模型结构学习阶段引入噪声,使树模型更容易产生“专门拟合极端点”的分裂。本文采用规则化处理的目的并非“美化数据”,而是将训练数据的取值范围约束在业务可接受的区间内,使模型学习到更通用的价格规律。
为提高数据处理过程的透明度,本文统计预处理前后的样本保留情况,并将训练集与两份测试集在“样本数/字段数”层面进行对照:训练集原始样本量为 150000,经缺失值填补、数值截断与字段规范化等步骤后样本量不变;在异常值处理规则启用时,对训练集进行异常样本剔除与截断后,最终用于建模的训练样本量为 148429。上述规模对照汇总如表3-2所示。
表3-2 数据集规模与异常值处理前后样本量对照(导出文件:Used-Car-Price-Forecasting/outputs/data_profile_dataset_sizes.csv)
| 数据集 | 样本数 | 字段数 |
|---|---|---|
| train_raw | 150000 | 34 |
| train_after_outlier_rules | 148429 | 34 |
| testA_raw | 50000 | 33 |
| testB_raw | 50000 | 33 |
可以看出,异常值规则启用后训练集样本数由 150000 变为 148429,共剔除 1571 条样本(约占 1.05%),保留率约为 98.95%。该比例相对较小,说明本文的异常值处理主要用于去除极少量明显不合理样本,以降低极端值对模型拟合与指标评估的干扰,而不会显著改变训练数据的整体分布。
3.4 特征工程与编码策略
本节说明本文的特征工程与编码策略,并明确最终输入特征的形成过程。输入为完成缺失处理与异常值规则后的原始字段,输出为可供模型学习的数值特征与稀疏类别特征表示(通过流水线自动完成编码与标准化),并在不引入主观阈值筛选的前提下保留字段信息量。
为增强模型对车辆折旧规律的刻画能力,并降低原始日期字段带来的非线性与不可解释性影响,本文对时间字段进行拆分与重构,构造了注册年份与月份、创建年份与月份以及车龄天数(由创建时间与注册时间差得到)等衍生特征。上述特征能够更直接反映车辆使用年限与信息时间维度,对价格预测具有重要意义[14]。此外,为避免高基数文本类特征造成维度膨胀与训练开销增加,本文对文本识别度较低且不利于泛化的字段进行剔除处理。
除时间特征外,本文采用“让模型自行学习”的思路处理多数原始字段,即通过独热编码将类别特征展开为稀疏向量,使模型能够区分不同品牌、车身类型与燃油类型等对价格的影响。对于匿名特征(如 v0~v14),本文不做过度人为干预,而是将其作为连续数值特征直接输入模型,以保留其潜在信息量。
在编码口径上,本文在代码实现中采用“自动识别 + 统一流水线”的策略:仅将数据类型为 object 的字段识别为类别列并进行独热编码,其余字段全部按数值列处理(包括 0/1 编码字段、匿名特征 v0~v14、以及由日期拆分得到的年/月与车龄等特征)。对于已被数值化编码的离散字段,本文不再进行二次类别编码,避免重复编码导致维度膨胀与语义混乱。独热编码采用 OneHotEncoder,并设置 handle_unknown="ignore",以保证训练集中未出现的新类别在预测阶段不会导致特征维度不一致或报错。
需要强调的是,独热编码、缺失值填补与标准化均被封装在同一 Pipeline/ColumnTransformer 中,并在交叉验证的每一折内仅使用训练折拟合(例如确定类别集合、计算众数与标准差),再应用到验证折,从而避免“用验证折信息确定编码空间”造成的数据泄露。
特征选择方面,本文采用“字段级剔除 + 模型隐式选择 + 事后解释”的策略,而非单独的显式特征筛选算法(如逐步回归、过滤式相关系数筛选等)。具体而言:
(1)字段级剔除。仅对明显不利于泛化或会导致维度膨胀的字段进行剔除,包括删除高基数文本列 name,以及将原始日期列 regDate、creatDate 转换为车龄与年/月后不再直接输入模型。
(2)模型隐式选择。本文对比的模型本身具有一定的“弱特征自动选择”能力:Ridge 通过 L2 正则抑制不稳定系数;随机森林在每次分裂仅使用部分特征子集(max_features)以降低相关特征的冗余影响;LightGBM 在分裂时基于增益选择最优特征与阈值,因此弱相关特征往往难以被重复选择进入高层节点。
(3)事后解释。为避免在训练前引入主观阈值,本文保留其余字段统一输入模型,并在第 5 章以 SHAP 为主对最优模型的关键特征贡献进行解释,同时以置换重要性作为补充对照,从而回答“最终模型主要依赖哪些信息完成预测”。
需要强调的是,本文的“特征选择”主要体现为字段口径的工程化约束与证据链验证,而非通过单独的特征筛选算法在训练前对特征做大规模剔除。具体选择依据包括:
(1)可泛化性:对高基数文本类字段(如 name)优先剔除,以降低维度膨胀与稀有类别导致的不稳定;
(2)可复现性:对日期字段先做明确的衍生与替换(车龄/年/月),避免直接输入不可控的 datetime 对象;
(3)可验证性:通过第 5 章消融实验与重要性分析检验“保留/删除某类字段或工程步骤”是否真实影响 MAE/RMSE,从而避免仅凭直觉做筛选。
需要指出的是,特征工程并不追求越多越好,而是强调与业务规律一致且可复现。在本科阶段的工程实践中,构造车龄等关键强特征往往比堆叠大量复杂交互更可靠。
进一步地,车龄特征之所以被认为是“强特征”,本质原因在于二手车价格具有较明显的折旧规律:车辆使用年限越长,通常折旧越明显;但折旧并非线性过程,往往呈现“新车阶段贬值更快、后续趋于平缓”的特点。将时间字段拆分为年、月并引入车龄天数,一方面能够使树模型捕捉到非线性折旧结构,另一方面也有助于在误差分析中讨论不同车龄区间的预测偏差来源。
除车龄外,类别特征的处理同样影响模型上限。二手车市场的品牌溢价、地区供需差异、能源类型政策等因素往往通过类别字段体现。本文采用独热编码将类别信息显式展开,使模型能够学习到不同类别对价格的平均偏移。需要注意的是,当类别基数较大时,稀有类别会导致统计不稳定,模型在这些类别上的预测方差可能更大。后续可以通过合并稀有类别、引入目标编码或分层建模等方式进一步提升稳定性,但这些方法往往需要更严格的验证策略以避免泄露。
围绕新能源与传统燃油车型的折旧差异、以及不同市场细分下的价格波动特征,已有研究也普遍强调车龄与品牌等关键因素的重要性[6]。
3.5 目标变量变换
本节说明目标变量 price 的变换方式及其对训练与评估口径的影响。输入为原价格尺度的目标变量 price,输出为用于模型拟合的对数空间标签 y(log) 以及用于评价与最终提交的原价格尺度预测值 y_hat。
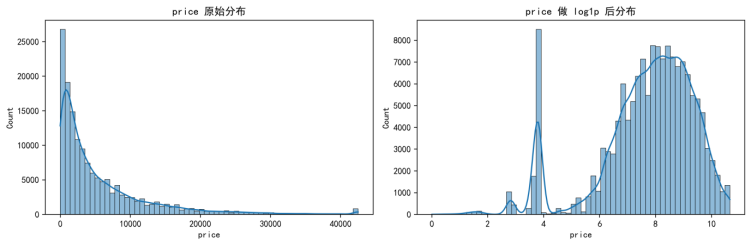
在进行变换之前,本文先对训练集 price 的经验分布进行可视化检验。结果显示,price 在原尺度下呈现明显右偏与长尾:大多数样本集中在较低价格区间,而少量高价样本将分布右尾显著拉长,导致均值与方差更容易被极端样本主导。对数变换后分布右尾被压缩,整体更接近对称形态,且不同价格区间的尺度差异明显缩小,原始分布与对数分布的对比如图3-3所示。
图3-3 训练集价格分布:原始尺度与对数变换后对比(Used-Car-Price-Forecasting/outputs/figures/fig1_price_dist_raw_vs_log.png)
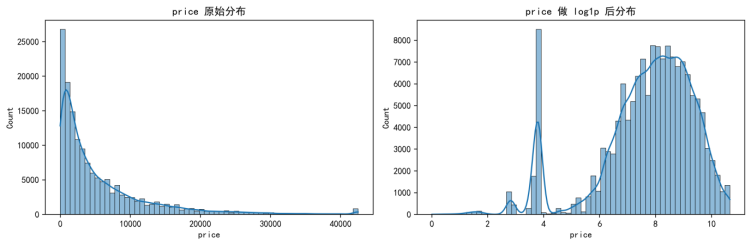
从图3-3可以看出,对数变换能够显著压缩高价区间的跨度,使分布在视觉上更集中,便于模型在训练时同时关注中低价与高价样本,从而缓解长尾分布下“少量高价样本对平方损失更敏感”的问题。
如第 5 章数据分布分析所示(见图5-1),训练集 price 的原始分布呈现明显长尾与右偏:少量高价样本会拉长右尾,使得模型在以平方损失等目标优化时更容易被极端样本主导。为缓解该问题,本文对目标变量采用对数变换:
$$
y^{(\log)} = \log(1+y)
$$
训练阶段在对数空间进行拟合,评估与输出阶段再将预测值还原到原价格尺度:
$$
\hat{y} = \exp(\hat{y}^{(\log)}) - 1
$$
该处理能够缓解价格分布的长尾与右偏问题,使模型更容易在不同价格区间取得相对均衡的误差表现,从而提升整体拟合稳定性[18]。
在指标计算层面,本文始终在“还原后的价格尺度”上计算 MAE、RMSE 与 R²,使评估结果更符合业务直观含义(例如平均误差是多少元/多少单位)。同时,由于模型内部拟合的是对数空间的目标,预测时对数空间的小误差在高价区间可能对应更大的绝对误差,因此第 5 章将结合误差图进一步讨论不同价格区间可能存在的误差差异。
第4章 模型构建与实验设计
本章在第 3 章数据预处理与特征工程基础上,给出模型构建的整体流程与关键实现要点。本文强调端到端的一致性:训练与预测阶段使用同一套数据处理口径,并在交叉验证框架下完成模型对比与最优模型选择。
4.1 建模流程概述
本节给出本文的端到端建模流程,并明确每一步的输入输出。输入为第 3 章完成清洗与特征工程后的训练集与测试集;输出包括两类产物:
(1)对比产物:在统一交叉验证口径下得到各候选模型的 MAE/RMSE/R² 均值与标准差,用于模型选型;
(2)交付产物:在全量训练集上训练最优模型,并对测试集生成预测文件,同时导出用于论文展示的图表与表格。
整体流程按“数据处理—统一建模—公平评估—最终输出”的顺序执行:先在结构化字段上完成缺失值与异常值处理并构造车龄等关键特征,再通过统一预处理流水线将数值特征与类别特征转换到模型可学习的输入空间,随后在相同划分与相同指标口径下完成模型对比,最终在全量训练集上训练最优模型并生成预测输出。
4.1.1 数据划分与交叉验证口径
本节说明模型评估时的数据划分方式与“公平比较”口径。输入为训练集特征与对数空间标签,输出为 5 折交叉验证下各指标的均值与标准差,并用于本章模型对比与选型。
为获得更稳定的泛化性能估计,本文采用 5 折交叉验证评估每个候选模型。具体做法为将训练集划分为 5 份,轮流使用其中 1 份作为验证集、其余作为训练集,最终对各折的 MAE、RMSE 与 R² 取均值与标准差作为汇总结果。
从估计角度看,交叉验证是在不同训练/验证划分下对泛化误差的蒙特卡洛近似。记第 k 折的评价指标为 m_k(例如 MAE),则交叉验证的均值与标准差为:
$$
\bar{m}=\frac{1}{K}\sum_{k=1}^{K} m_k
$$
$$
s_m=\sqrt{\frac{1}{K}\sum_{k=1}^{K}(m_k-\bar{m})^2}
$$
在实验过程中,本文在每一折中先在对数空间进行模型拟合与预测,再将预测值还原到原价格尺度计算评价指标,保证不同模型在同一评估口径下比较。考虑到随机森林模型在全量样本上进行 5 折交叉验证耗时较高,本文对其采用固定规模子集进行交叉验证对比,以在计算资源约束下获得可用的性能水平估计。
为保证可复现性,本文在数据划分与随机抽样等关键环节固定随机种子,并将预处理与模型训练封装在同一流水线中,使交叉验证的每一折均严格在训练折上拟合预处理参数后再应用到验证折,从而降低数据泄露风险。
为便于读者快速把握实验的输入输出与关键步骤,建模流程示意如图4-1所示。
图4-1 建模流程示意图
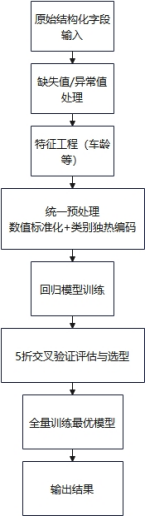
为避免训练集与验证集处理口径不一致带来的偏差,本文将预处理步骤与模型训练封装为统一流水线,并在交叉验证中对每一折独立拟合预处理参数(仅使用训练折),再将变换应用到验证折,以降低数据泄露风险并保证不同模型对比的公平性。
4.2 统一预处理—建模流水线
本节说明统一预处理流水线的具体做法与其输出形式。本文将特征按数值列与类别列分组,并在同一流水线内完成特征转换:
(1)数值特征:缺失值填补后进行标准化,使不同量纲的特征处于可比尺度;
(2)类别特征:缺失值填补后进行独热编码,将离散取值转换为稀疏指示向量,并设置未知类别处理策略以保证训练与预测阶段特征维度一致。
该小节的输出是一套在训练、交叉验证与最终预测阶段可复用的转换规则,而非单次实验结果。其实现要点是:交叉验证的每一折均先在训练折拟合预处理参数(例如填补值、标准差与类别集合),再应用到验证折,从而保证特征空间一致并降低泄露风险。
4.3 模型训练与选型策略
本节说明候选模型集合、训练过程以及最终选型依据。候选模型覆盖不同复杂度与不同归纳偏置:
(1)基线:DummyMedian,用于给出不学习特征时的性能下限;
(2)线性模型:Ridge 与普通线性回归,用于对比“仅线性关系”可达到的误差水平;
(3)Bagging:随机森林与极端随机树,用于对比基于多树集成的非线性方法;
(4)Boosting:XGBoost、CatBoost 与 LightGBM,用于对比提升树在表格回归任务中的表现。
训练与评估按如下流程执行:对每个候选模型,在相同的 5 折划分上重复“训练折拟合流水线与模型—验证折预测—还原到原价格尺度计算指标”,最终对 5 折指标取均值与标准差。模型选型以 MAE 为主,同时参考 RMSE、R² 与标准差,并综合训练耗时与资源消耗确定最终方案。
4.3.1 模型参数配置
为保证对比公平性,本文在统一预处理流水线下仅调整各模型的关键超参数,并保持交叉验证策略、评价指标与随机种子一致。各模型最终采用的参数配置如下(与训练脚本保持一致):
(1)DummyMedian(朴素基线)。
DummyMedian 作为无特征学习能力的下限基线,其参数配置如表4-1所示。
表4-1 DummyMedian 参数配置
| 参数 | 取值 | 说明 |
|---|---|---|
strategy |
median | 以训练集标签中位数作为恒定预测 |
(2)Ridge 回归(线性基线)。
Ridge 回归用于刻画线性可达的基准性能,其参数配置如表4-2所示。
表4-2 Ridge 回归参数配置
| 参数 | 取值 | 说明 |
|---|---|---|
alpha |
10.0 | L2 正则化强度 |
random_state |
42 | 固定随机种子,保证复现 |
(3)随机森林回归(对比模型)。
随机森林作为 Bagging 代表用于对比非线性模型的性能边界,其参数配置如表4-3所示。
表4-3 随机森林回归参数配置
| 参数 | 取值 | 说明 |
|---|---|---|
n_estimators |
120 | 树的数量 |
max_depth |
18 | 单棵树最大深度 |
min_samples_leaf |
10 | 叶节点最小样本数,用于抑制过拟合 |
max_features |
sqrt | 每次分裂可用特征子集 |
random_state |
42 | 固定随机种子 |
n_jobs |
-1 | 使用全部 CPU 线程 |
(4)XGBoost 回归(主力模型)。
XGBoost 为本文最终选定的主力模型,其参数配置如表4-4所示。
表4-4 XGBoost 回归参数配置
| 参数 | 取值 | 说明 |
|---|---|---|
n_estimators |
2500 | 迭代轮数(树的数量) |
learning_rate |
0.05 | 学习率,控制每轮更新幅度 |
max_depth |
8 | 树的最大深度 |
subsample |
0.8 | 行采样比例,用于提升泛化 |
colsample_bytree |
0.8 | 列采样比例,用于提升泛化 |
reg_alpha |
0.0 | L1 正则系数 |
reg_lambda |
1.0 | L2 正则系数 |
objective |
reg:squarederror | 回归目标函数 |
random_state |
42 | 固定随机种子 |
n_jobs |
-1 | 使用全部 CPU 线程 |
(5)普通线性回归(线性基线)。
普通线性回归用于对比“无正则线性模型”的基准性能,其参数配置如表4-5所示。
表4-5 普通线性回归参数配置
| 参数 | 取值 | 说明 |
|---|---|---|
fit_intercept |
True | 是否拟合截距项(默认) |
positive |
False | 是否约束系数为非负(默认) |
n_jobs |
None | 并行线程数(默认) |
(6)极端随机树回归(对比模型)。
极端随机树作为 Bagging 代表模型之一,其参数配置如表4-6所示。
表4-6 极端随机树回归参数配置
| 参数 | 取值 | 说明 |
|---|---|---|
n_estimators |
400 | 树的数量 |
max_depth |
None | 不限制深度(由分裂停止条件控制) |
min_samples_leaf |
2 | 叶节点最小样本数 |
max_features |
sqrt | 每次分裂可用特征子集 |
random_state |
42 | 固定随机种子 |
n_jobs |
-1 | 使用全部 CPU 线程 |
(7)CatBoost 回归(Boosting 对照模型)。
CatBoost 作为提升树对照模型之一,其参数配置如表4-7所示。
表4-7 CatBoost 回归参数配置
| 参数 | 取值 | 说明 |
|---|---|---|
iterations |
4000 | 迭代轮数(树的数量) |
learning_rate |
0.05 | 学习率 |
depth |
8 | 树深度 |
loss_function |
RMSE | 回归损失函数 |
random_seed |
42 | 固定随机种子 |
verbose |
False | 关闭训练日志输出 |
(8)LightGBM 回归(Boosting 对照模型)。
LightGBM 作为提升树对照模型之一,其参数配置如表4-8所示。
表4-8 LightGBM 回归参数配置
| 参数 | 取值 | 说明 |
|---|---|---|
n_estimators |
3000 | 迭代轮数(树的数量) |
learning_rate |
0.03 | 学习率 |
num_leaves |
64 | 叶子结点数(控制模型复杂度) |
subsample |
0.8 | 行采样比例 |
colsample_bytree |
0.8 | 列采样比例 |
random_state |
42 | 固定随机种子 |
n_jobs |
-1 | 使用全部 CPU 线程 |
4.3.2 调参策略与复现设置
在本科毕设的计算资源约束下,本文未进行大规模网格搜索或贝叶斯优化,而采用“基于经验的固定参数 + 交叉验证检验”的策略:先在结构化表格回归任务中常见且稳健的参数范围内选取候选配置,再通过 5 折交叉验证观察 MAE/RMSE/R² 的均值与标准差,以指标与稳定性共同约束参数选择,最终得到可复核的实验配置。
为保证复现性,本文在数据划分(KFold)、随机抽样(随机森林对比用子集)与模型训练(random_state)等关键环节固定随机种子;同时使用统一预处理流水线并在每折训练折拟合预处理参数,以降低数据泄露风险,确保不同模型的对比结论更可靠。
4.4 实验环境
本节说明实验运行的软硬件条件与可复现约束。实验在 Windows 平台完成,Python 版本为 3.9。数据处理与建模依赖常用的数据分析与机器学习工具包,图表绘制使用通用可视化工具。为保证结果可重复,本文在数据划分、抽样与置换重要性计算等环节固定随机状态,并在实验过程中记录各模型在不同折上的训练与预测耗时及对应评价指标结果。
在实验组织上,本文遵循“同一数据、同一预处理口径、同一评价指标”的对比原则。考虑到不同模型对特征尺度、缺失值与类别变量的敏感性差异,若不采用统一流水线,容易造成不公平比较或引入数据泄露。因此,本文将预处理步骤与模型训练视为整体流程,并在交叉验证框架下重复执行,使每一折验证均基于训练折拟合得到的预处理参数,从而使评估结果更接近真实泛化性能。
4.5 评估指标
本节给出用于模型对比与选型的评价口径。指标定义见第 2 章“2.4 模型评价指标”,本章在实现上统一采用以下口径:
(1)主指标为 MAE,同时报告 RMSE 与 R² 作为补充;
(2)训练阶段在对数空间拟合,但评价阶段将预测值还原到原价格尺度后计算 MAE、RMSE 与 R²,保证不同模型在同一价格尺度下可比;
(3)对交叉验证的 5 折结果同时报告均值与标准差,用于刻画指标的稳定性。
4.6 交叉验证策略
本节说明模型对比所采用的交叉验证实施方式。交叉验证的基本口径见第 3 章“3.6 数据划分与交叉验证口径”,本章在执行层面统一采用以下规则:
(1)所有候选模型使用相同的 5 折划分与相同随机种子,确保模型间可公平比较;
(2)每一折均先在训练折拟合预处理参数与模型,再对验证折生成预测并在原价格尺度计算指标;
(3)最终对 5 折指标取均值与标准差作为模型性能估计;
(4)对训练开销较大的模型,在不改变其余口径的前提下使用固定规模子样本完成对比实验,以保证在有限算力下能够完成多模型评估。
第5章 实验结果与分析
5.1 数据分布与预处理效果
本节先从数据分布出发,说明本文关键预处理策略(目标对数变换、部分字段缺失化与截断)的必要性。价格变量存在明显长尾与右偏,若直接在原尺度拟合,模型容易被极端高价样本主导。对数变换的目的在于压缩右尾、降低异方差,使不同价格区间的误差更均衡。对数变换前后分布的差异如图5-1所示。
图5-1 价格原始分布与对数变换分布对比(文件名:fig1_price_dist_raw_vs_log.png)
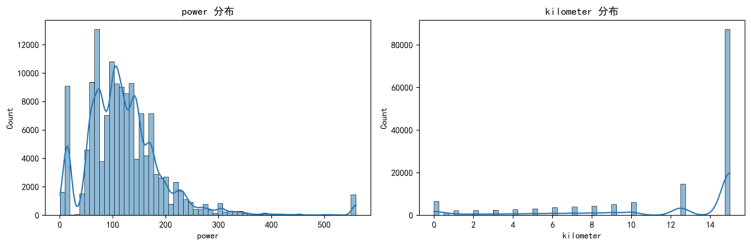
动力与里程属于与车辆性能和使用强度直接相关的关键特征,但原始数据中可能出现非正动力值或极端里程值。对非正动力值进行缺失化、对里程进行上限截断,目的是剔除明显不合理取值对模型分裂与拟合的干扰。动力与里程的分布特征如图5-2所示。
图5-2 动力与里程分布(文件名:fig2_power_kilometer_dist.png)
为从统计角度快速了解“哪些数值变量与价格可能存在关联”,本文计算数值特征与价格的相关系数并绘制热力图,结果如图5-3所示。
图5-3 数值特征与价格相关性热力图(Top20+price)(文件名:fig3_corr_heatmap_top20.png)
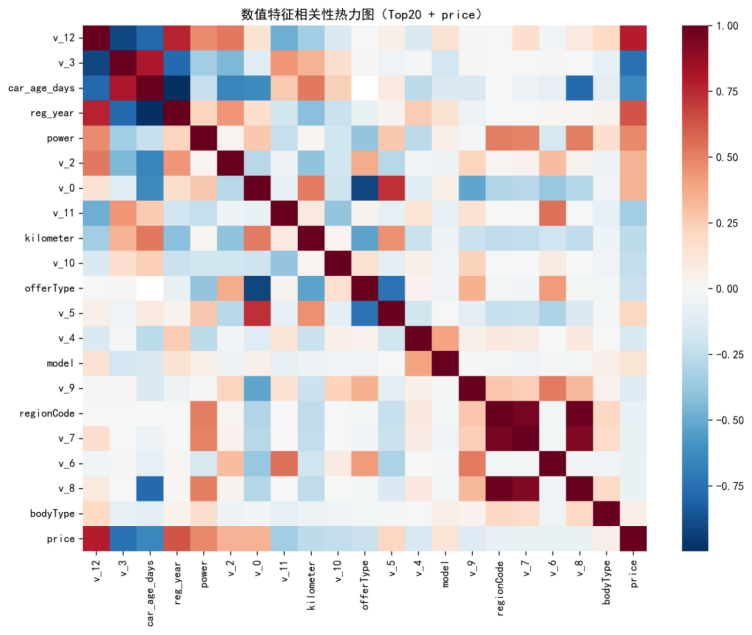
需要强调的是,相关性仅反映线性关联,难以覆盖非线性与交互效应;因此该图主要用于辅助理解与后续解释,不作为特征筛选的唯一依据。
5.2 模型对比结果
在统一的预处理与 5 折交叉验证口径下,本文对基线、线性模型、Bagging 模型与 Boosting 模型进行对比。各模型在 MAE/RMSE/R² 上的均值与标准差汇总如表5-1所示,其中 MAE 作为本文主指标用于选型。
表5-1 不同模型的 5 折交叉验证对比结果(MAE/RMSE/R²)
| 模型 | MAE(均值) | MAE(标准差) | RMSE(均值) | RMSE(标准差) | R2(均值) | R2(标准差) |
|---|---|---|---|---|---|---|
| XGBoost | 474.2258 | 7.5023 | 1098.4522 | 45.9166 | 0.9753 | 0.0019 |
| CatBoost | 476.2152 | 8.5061 | 1079.7982 | 48.8548 | 0.9761 | 0.0020 |
| LightGBM | 485.2061 | 8.3184 | 1098.1415 | 42.5496 | 0.9753 | 0.0017 |
| Ridge | 910.6865 | 9.8078 | 2183.8527 | 48.1781 | 0.9024 | 0.0033 |
| LinearRegression | 911.2885 | 9.7463 | 2187.5614 | 49.0258 | 0.9021 | 0.0034 |
| RandomForest | 1070.5073 | 70.0888 | 2457.3665 | 173.6033 | 0.8775 | 0.0146 |
| ExtraTrees | 1338.0213 | 70.6466 | 2920.6530 | 156.8836 | 0.8272 | 0.0148 |
| DummyMedian | 4439.5156 | 27.9054 | 7467.2772 | 70.4856 | -0.1408 | 0.0012 |
为便于直观比较不同模型的误差水平,本文绘制 MAE 对比柱状图。不同模型的 MAE 结果对比如图5-4所示。
图5-4 模型对比(MAE 越小越好)(文件名:fig4_model_compare_mae.png)
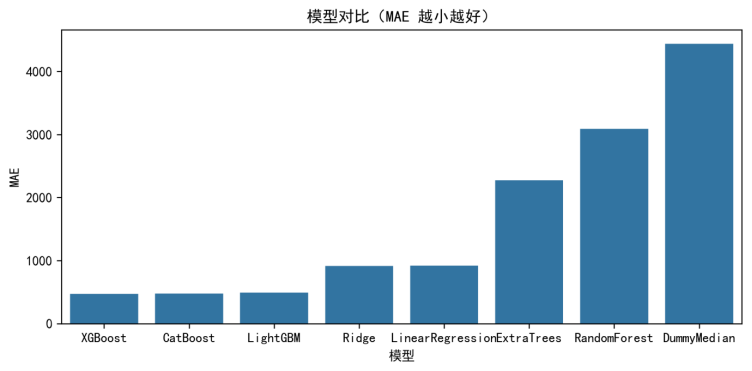
从表5-1可以看出,Boosting 系列模型的 MAE 明显更小且标准差较低,说明其在不同折划分下更稳定。其中 XGBoost 在 MAE 上最优(约 474),CatBoost 与 LightGBM 紧随其后,三者性能差距较小;线性模型(Ridge/LinearRegression)由于只能表达线性关系,难以捕捉复杂交互,误差显著偏大;Bagging 模型(RandomForest/ExtraTrees)虽然具备非线性能力,但在“高维稀疏(独热编码)+ 大样本”的设置下更易出现训练成本上升与泛化波动。综合误差水平与稳定性,本文选择 XGBoost 作为后续预测输出与解释分析的最优模型,并保留 CatBoost/LightGBM 用于横向对照。
5.3 最优模型拟合诊断
为进一步验证最优模型的拟合质量,本文从“预测一致性”和“残差结构”两个角度进行诊断:其一考察预测值与真实值是否整体贴近对角线、是否存在系统性偏差;其二考察残差分布是否近似对称、是否存在长尾与异常大误差样本。
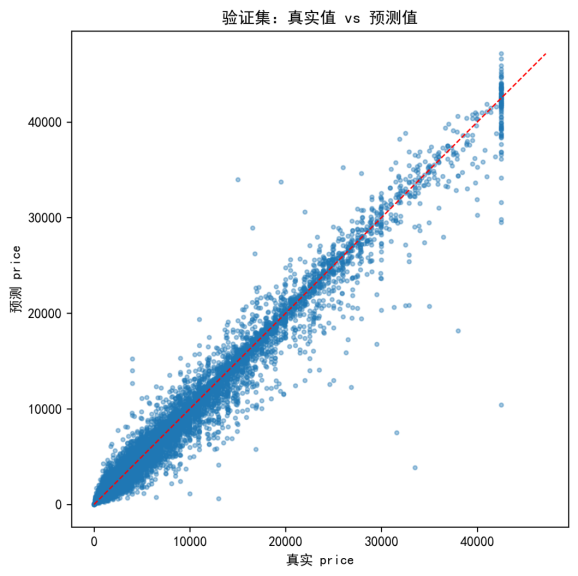
首先,为观察模型在不同价格水平上的拟合一致性与潜在偏差结构,本文绘制真实值—预测值散点图,如图5-5所示。
图5-5 真实值—预测值散点图(文件名:fig6_true_vs_pred_scatter.png)
其次,为检验误差是否存在系统性偏移以及大误差样本占比,本文绘制残差分布图,如图5-6所示。
图5-6 残差分布图(文件名:fig7_residual_distribution.png)
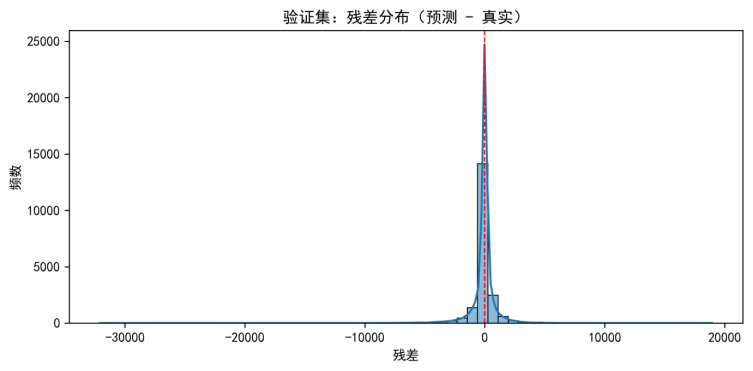
综合两图可以得到如下结论:模型在大多数样本上拟合较为合理,整体不存在明显的系统性偏差;但在高价区间散点离散度增大,提示误差随价格上升而增大的异方差现象,同时残差分布虽整体近似对称但仍存在一定长尾,说明仍有少量难样本可能对应“同款不同况”等未观测信息差异。这一诊断结论与后续误差分层分析中“高价区间误差更大”的发现相互印证。
5.4 消融实验
为验证关键预处理与特征工程环节对模型性能的贡献,本文在保持模型与评估口径一致(相同训练/验证划分策略、相同评价指标、相同随机状态)的前提下,设计消融实验(Ablation Study),分别考察车龄特征构造与异常值处理对预测性能的影响。该实验的目的在于回答“本文哪些工程步骤确实带来收益”,从而增强结论的可验证性。
5.4.1 车龄特征消融
该实验对比“未构造车龄(仅使用原始时间字段或不引入时间差特征)”与“构造车龄(以创建时间与注册时间差得到车龄天数等)”两种设置,在相同模型与相同交叉验证策略下报告 MAE、RMSE 与 R² 的均值与标准差。
为保证对比公平性,两组实验除时间特征开关外,其余数据清洗、特征集合、预处理流水线与 XGBoost 参数均保持一致。两种设置下的交叉验证结果汇总如表5-2所示。
表5-2 车龄特征消融实验结果(5 折交叉验证,最优模型 XGBoost)
| 设置 | MAE(均值) | MAE(标准差) | RMSE(均值) | RMSE(标准差) | R²(均值) | R²(标准差) |
|---|---|---|---|---|---|---|
| 不构造车龄(--disable_time_features) | 466.4964 | 8.1829 | 1092.7502 | 44.1433 | 0.9755 | 0.0018 |
| 构造车龄(full) | 474.2258 | 7.5023 | 1098.4522 | 45.9166 | 0.9753 | 0.0019 |
从对比结果看,关闭时间特征并未使误差变差,反而在 MAE 上出现了小幅下降(约 466.5 vs 474.2),RMSE 与 R² 的差异也较小。该现象说明:在当前数据集与特征表达口径下,时间特征的边际收益并不显著,甚至可能引入额外噪声。需要强调的是,该对比并不意味着“车龄无效”,更合理的解释是“在该数据与实现条件下,显式时间特征的增益有限”。其可能原因包括:
(1)时间字段存在缺失或噪声,使车龄计算误差引入额外波动;
(2)匿名特征 v0~v14 已编码了部分与折旧相关的信息,使显式车龄特征的边际贡献下降;
(3)车龄效应与里程、动力、品牌等变量存在相关性,部分作用被其它特征吸收。
尽管如此,本文仍在最终方案中保留时间特征:一方面其符合领域常识并有助于后续解释分析(例如按车龄分层讨论误差);另一方面从工程复现角度,保留“可解释强特征”也便于后续在更丰富数据(包含更真实车况信息)下迁移与对比。与此同时,本文也据此提醒读者:特征工程应以消融实验为准进行验证,避免仅凭直觉判断其有效性。
5.4.2 异常值处理消融
该实验对比“未进行异常值处理”与“按本文规则进行清洗/截断”两种设置,观察异常值处理对模型稳定性(标准差)与整体误差水平(MAE/RMSE)的影响。
同样地,两组实验除异常值规则开关外,其余设置保持一致;对比结果汇总如表5-3所示。
表5-3 异常值处理消融实验结果(5 折交叉验证,最优模型 XGBoost)
| 设置 | MAE(均值) | MAE(标准差) | RMSE(均值) | RMSE(标准差) | R²(均值) | R²(标准差) |
|---|---|---|---|---|---|---|
| 不做异常值处理(--disable_outlier_rules) | 509.6993 | 9.0060 | 1265.2209 | 70.7861 | 0.9714 | 0.0031 |
| 按规则处理异常值(full) | 474.2258 | 7.5023 | 1098.4522 | 45.9166 | 0.9753 | 0.0019 |
一般而言,异常值处理可能带来两类收益:其一是降低极端样本对训练目标的干扰,从而降低整体 MAE/RMSE;其二是降低不同折划分下的波动,使标准差更小、评估更稳定。若发现异常值处理使 R² 略有下降但 MAE 降低,也可从“业务更关注绝对误差”角度解释该折中。
结合表5-3可以看出,关闭异常值处理后 MAE 明显上升(约从 474 上升到 510),RMSE 也显著增大,同时标准差扩大,说明模型在不同折划分下的波动更大。由此可见,规则化异常值处理能够有效降低极端样本的干扰,提升模型的稳健性与泛化性能。
进一步地,本文对字段级剔除与匿名特征也进行了补充消融验证:
(1)name 字段:默认设置删除 name,与保留 name(--keep_name)相比,XGBoost 的 MAE 几乎无变化(474.2258 vs 474.2300),说明 name 并未提供稳定增益。考虑其高基数带来的维度膨胀与训练成本,本文在最终特征集合中删除 name。
(2)匿名特征 v0~v14:删除 v 特征(--drop_v_features)后,XGBoost 的 MAE 从约 474 上升到约 1083,性能断崖式下降,表明匿名特征蕴含了与价格高度相关的关键信息,是提升模型精度的重要来源。该结论也与置换重要性中 v 特征排名靠前相互印证。
5.5 误差分层分析
在总体指标之外,本文进一步进行误差分层分析(Error Stratification),以观察模型在不同样本子群上的误差结构。该分析有助于回答“模型在哪些区间更可靠、在哪些区间风险更高”,并为后续改进提供方向。
5.5.1 按价格区间分层
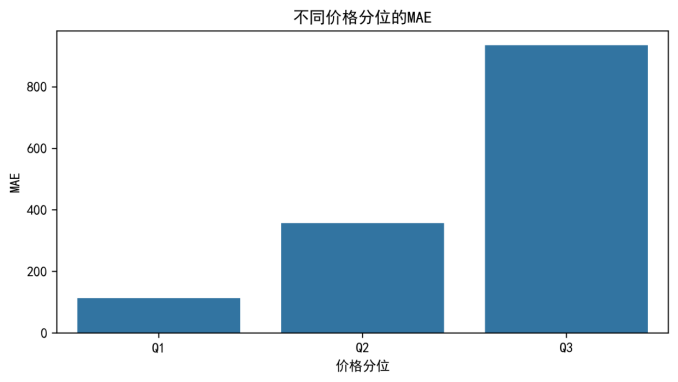
为刻画模型在不同价格段的误差差异,本文按真实价格对样本进行分层,并分别统计各层的 MAE 与 RMSE。分层方式采用分位数划分(Q1/Q2/Q3),以保证各层样本量大致相当,从而便于比较。各价格区间的误差统计如表5-4所示。
表5-4 按价格区间的误差分层统计
| 价格区间 | 样本数 | MAE | RMSE |
|---|---|---|---|
| Q1(低价) | 6700 | 112.7137 | 274.9145 |
| Q2(中价) | 6747 | 357.6636 | 680.0465 |
| Q3(高价) | 6553 | 934.1839 | 1785.2366 |
为便于直观比较不同价格层的 MAE 差异,本文将表5-4中的 MAE 绘制为柱状图,如图5-7所示。
图5-7 不同价格分位的 MAE(文件名:full_error_strat_by_price_mae.png)
进一步地,为观察不同价格层的 RMSE 差异,本文将表5-4中的 RMSE 绘制为柱状图,如图5-8所示。
图5-8 不同价格分位的 RMSE(文件名:full_error_strat_by_price_rmse.png)
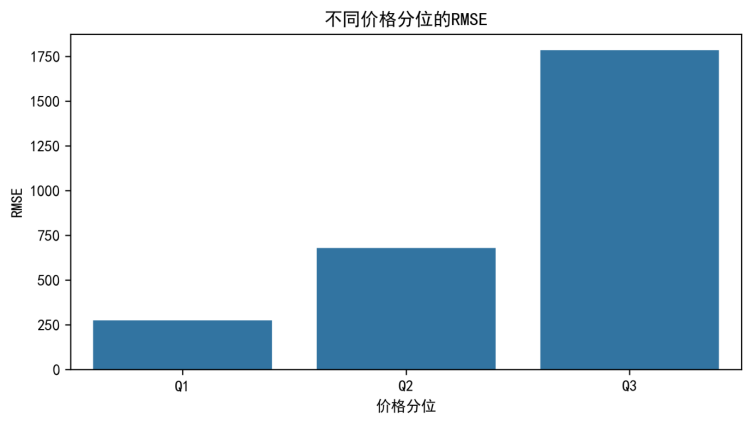
从表5-4与图5-7/图5-8可以看出,误差随价格区间升高而显著增大,高价层(Q3)的 MAE/RMSE 明显高于低价层(Q1)。这表明模型在高价样本上的绝对误差更大,主要原因可能包括:高价样本占比相对更低导致学习不足、同价位车辆配置差异与车况差异更大、以及事故/保养/营运等关键变量缺失使得“同款不同况”难以被当前字段充分刻画。该结论提示后续可考虑分段建模、引入分位数损失或补充更丰富的车况信息,以降低高价区间误差风险。
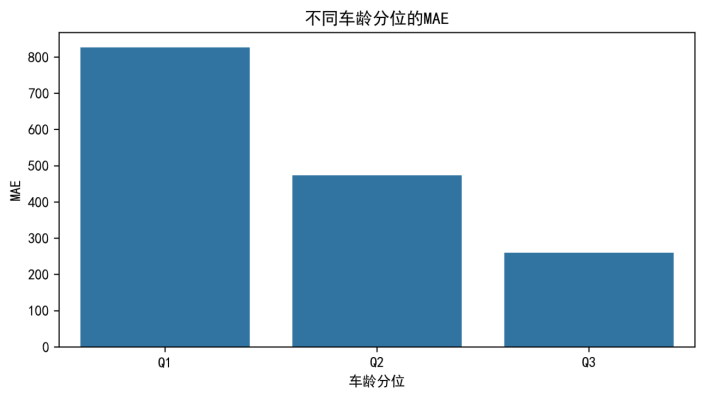
5.5.2 按车龄区间分层
为进一步分析折旧相关因素对误差结构的影响,本文将样本按车龄(由时间特征计算得到)进行分位数分层,并分别统计各层的 MAE 与 RMSE。各车龄区间的误差统计如表5-5所示。
表5-5 按车龄区间的误差分层统计
| 车龄区间 | 样本数 | MAE | RMSE |
|---|---|---|---|
| Q1(车龄最小) | 5815 | 827.0360 | 1612.8860 |
| Q2(中间车龄) | 5804 | 469.9416 | 1035.3332 |
| Q3(车龄最大) | 5810 | 262.1460 | 693.5849 |
为直观展示不同车龄层的 MAE 差异,本文将表5-5中的 MAE 绘制为柱状图,如图5-9所示。
图5-9 不同车龄分位的 MAE(文件名:full_error_strat_by_age_mae.png)
进一步地,为观察不同车龄层的 RMSE 差异,本文将表5-5中的 RMSE 绘制为柱状图,如图5-10所示。
图5-10 不同车龄分位的 RMSE(文件名:full_error_strat_by_age_rmse.png)
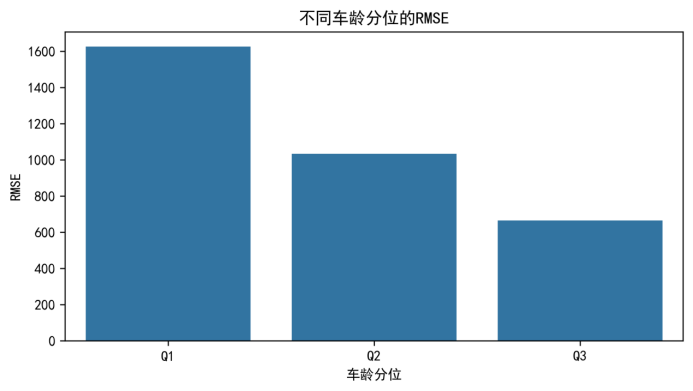
从表5-5与图5-9/图5-10可以看出,车龄越小(越“新”)误差越大,而车龄较大的样本误差相对更小。该现象表明:新车/准新车价格更容易受到配置差异、促销与短期市场供需波动影响,而这些差异未必能被当前字段充分刻画,从而导致预测不确定性更高;相比之下,车龄较大的车辆折旧规律更稳定,且价格区间相对更集中,模型更容易取得较小的绝对误差。
5.6 特征重要性与影响因素分析
5.6.1 置换重要性方法说明
置换重要性(Permutation Importance)的核心思想是:在验证集上随机打乱某一特征列的取值,观察模型性能(本文以 MAE 为主)变差程度。若打乱后 MAE 明显变差,则说明该特征对预测结果贡献较大。
本文在固定子样本(最多 20000 条)上进行置换重要性计算,并选取排名靠前的特征进行展示与分析。
为使重要性定义更明确,本文将第 j 个特征的重要性定义为“置换后指标的劣化量”。设基准评价指标为 MAE_base,将第 j 个特征置换后得到 MAE_perm^(j),则:
$$
I_j = \mathrm{MAE}_{\mathrm{perm}}^{(j)} - \mathrm{MAE}_{\mathrm{base}}
$$
考虑到置换存在随机性,实际计算通常重复置换 R 次并取均值与标准差,用以刻画估计的不确定性:
$$
\bar{I}_j = \frac{1}{R}\sum_{r=1}^{R} I_j^{(r)},\quad s_{I_j}=\sqrt{\frac{1}{R}\sum_{r=1}^{R}(I_j^{(r)}-\bar{I}_j)^2}
$$
相较于基于树结构的特征重要性,置换重要性更直接衡量“该特征对预测性能的边际贡献”,并且能够在统一评价指标下进行解释,因而更适合用于论文中的影响因素分析。然而,置换重要性也存在局限性:当特征之间存在较强相关性时,打乱其中一个特征可能被其它相关特征部分“替代”,从而低估其真实贡献;反之,若某特征与目标高度相关但只在少数样本上起作用,置换重要性也可能因整体平均而被稀释。因此,本文在解释重要性结果时强调与业务常识结合,避免将其误解为严格的因果结论。
在二手车估价研究中,模型解释往往需要与业务经验结合,以避免将相关性误解为因果关系,这也是本文采用置换重要性并进行谨慎解读的重要原因[7]。
5.6.2 SHAP 方法与结果
为进一步增强可解释性并给出“方向性”解释,本文在最优模型(XGBoost)上引入 SHAP(SHapley Additive exPlanations)进行解释分析。SHAP 基于合作博弈论的 Shapley 值,将模型预测分解为各特征对预测结果的加性贡献,能够同时回答两类问题:一是“哪些特征总体最重要”(通过平均绝对 SHAP 值排序),二是“特征取值增大时对预测的影响方向”(通过散点分布观察正负贡献)。
从形式化角度看,设模型为 f(x),基准值(期望预测)为 E[f(x)]。对单一样本 x,SHAP 将预测分解为:
$$
f(x)=E[f(x)]+\sum_{j=1}^{M}\phi_j
$$
其中 $\phi_j$ 为第 j 个特征对该样本预测的贡献值。其定义来自 Shapley 值:令特征集合为 $\mathcal{F}$,任意子集 $S\subseteq \mathcal{F}\setminus{j}$,则
$$
\phi_j=\sum_{S\subseteq \mathcal{F}\setminus\{j\}}\frac{|S|!(M-|S|-1)!}{M!}\left[f_{S\cup\{j\}}(x)-f_S(x)\right]
$$
其中 $f_S(x)$ 表示“仅使用特征子集 S 的条件下”的模型输出(其余特征边缘化/积分掉),该定义保证了贡献分解的公平性与可加性。
需要说明的是,由于本文建模采用 Pipeline 并对类别特征进行独热编码,SHAP 的计算实际发生在“预处理后的特征空间”(即独热展开后的稀疏特征)。为保证计算稳定性,本文在抽样子集上计算 SHAP,并输出 Top20 特征的可视化结果。
在实现口径上,本文对树模型(XGBoost)采用 TreeSHAP 的快速算法计算贡献值,并在固定随机种子下对验证集抽样以控制计算开销。需要强调的是:当特征之间存在较强相关性时,SHAP 的边际化假设可能导致贡献在相关特征之间分摊,从而出现“单个特征贡献被稀释”的现象;此外,由于独热编码会将一个原始类别字段拆分为多个稀疏列,因此解释时应结合字段语义进行汇总,避免将单个独热列误解为“原始字段整体影响”。
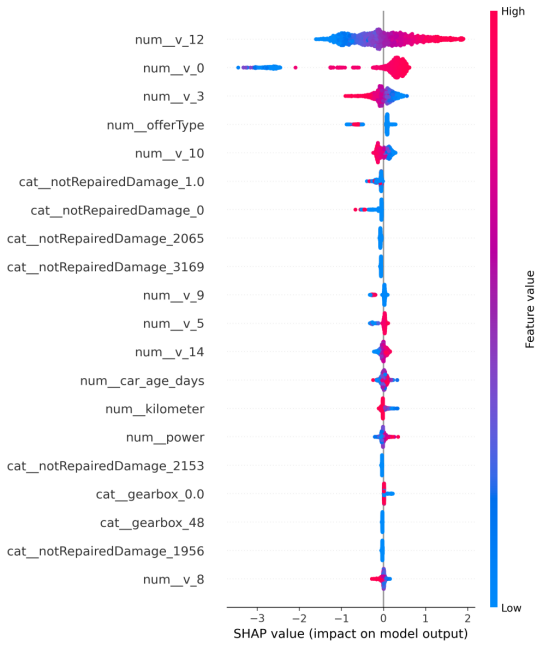
其中,SHAP beeswarm 用于同时展示重要特征的贡献大小与方向分布,如图5-11所示。
图5-11 SHAP beeswarm(Top20,文件名:fig8_shap_beeswarm_top20.png)
为从全局角度汇总各特征的平均绝对贡献,本文进一步绘制 SHAP 平均绝对贡献 Top20 条形图,如图5-12所示。
图5-12 SHAP 平均绝对贡献 Top20(文件名:fig9_shap_bar_top20.png)
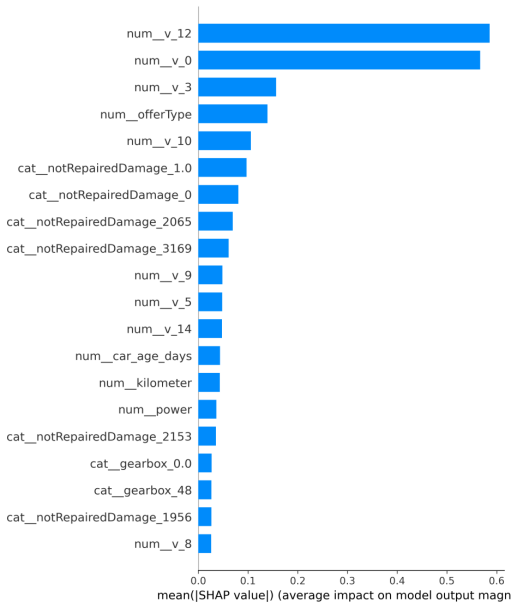
从图5-11与图5-12可以看出,匿名特征 v 系列以及车龄、动力、里程等业务可解释特征在 SHAP 口径下排名靠前。与置换重要性相比,SHAP 还能进一步呈现“方向性”:在 beeswarm 图中,特征取值的高低与 SHAP 值的正负共同反映了对预测价格的抬升或压低趋势。例如,车龄增大通常对应折价,其 SHAP 贡献倾向于为负;动力更强往往对应配置与溢价,其 SHAP 贡献倾向于为正。需要强调的是,SHAP 反映的是“在当前数据与模型下对预测的边际贡献”,属于相关性层面的解释,应结合业务常识进行解读。
5.6.3 重要特征 Top20
置换重要性 Top20 结果如下:
为便于查阅,本文将置换重要性 Top20 的均值与标准差整理如表5-6所示。
表5-6 置换重要性 Top20 特征(均值与标准差)
| 特征 | 重要性(均值) | 重要性(标准差) |
|---|---|---|
| v_12 | 3168.436194 | 14.923187 |
| v_0 | 1486.633611 | 11.979899 |
| v_3 | 1415.987616 | 6.201178 |
| 车龄天数 | 952.095857 | 5.331034 |
| v_10 | 786.213015 | 5.185233 |
| 动力 | 411.156058 | 1.238944 |
| v_14 | 392.367223 | 2.668286 |
| v_6 | 364.488273 | 5.674988 |
| 里程 | 350.51956 | 1.188565 |
| v_1 | 218.754448 | 0.922178 |
置换重要性 Top20 条形图如图5-13所示。
图5-13 置换重要性 Top20(文件名:fig5_permutation_importance_top20.png)
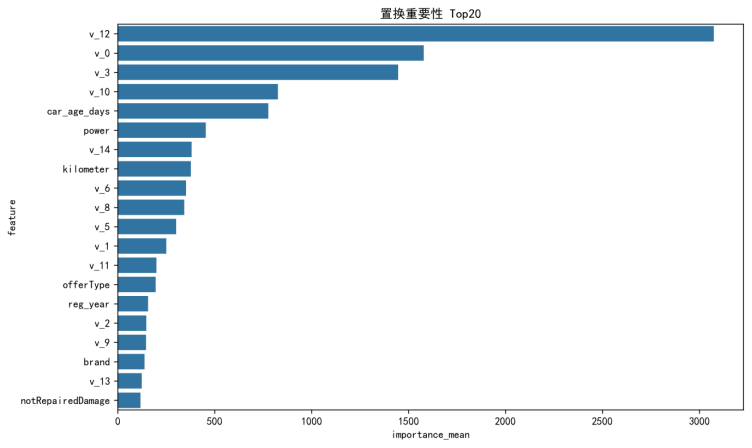
5.6.4 影响因素结论
结合 SHAP(图5-11、图5-12)与置换重要性(表5-6、图5-13)的结果可以看出,模型预测主要依赖两类信息:
(1)强相关的匿名特征 v 系列,其重要性在两种口径下均显著领先;
(2)具有明确业务含义的折旧与使用强度变量(车龄、里程、动力等),以及部分反映市场细分的类别属性(如品牌相关字段)。
需要强调的是,重要性仅反映“在当前数据与模型下对预测性能的边际贡献”,并不等同于严格因果关系;但在与领域常识一致时,仍可作为影响因素分析的主要依据。
为使结论更贴近业务逻辑,本文将“重要性结果”转化为可解释的机制表述如下。
上述“价值评估—影响因素—预测建模”的思路也与相关二手车价值评估研究的结论一致[22]。
为进一步说明上述特征与价格之间的“影响机制”,可从二手车定价的典型业务逻辑出发进行解释。
(1)车龄(折旧机制)。车龄相关特征在 SHAP 与置换重要性中均排名靠前,说明模型对折旧信息具有较强依赖。车龄刻画车辆使用年限与技术贬值过程,通常呈现“新车阶段折旧更快、后期折旧趋缓”的非线性规律。该机制也与第 5.5 节结果一致:在车龄较小样本中误差更大,提示该区间更易受到配置差异与短期市场波动等未观测因素影响。
(2)里程(使用强度机制)。里程在两类重要性口径下同样位于前列,表明“使用强度”是影响价格的重要线索。里程越高通常对应磨损风险与维护成本上升,从而形成折价;同时里程与车龄存在交互:同等车龄下更高里程往往代表更重度使用,树模型能够通过分裂学习这种非线性与交互效应。
(3)动力与配置(性能溢价机制)。动力特征在重要性结果中排名靠前,说明模型能够从性能参数中学习到一定的溢价规律:动力更强往往对应更高配置与更高级别车型,预测价格倾向于更高。与此同时,第 5.5.1 节显示高价区间误差更大,说明在高价段“同款不同况”(事故/保养/营运等信息缺失)会放大预测不确定性。
(4)品牌与类别属性(市场溢价与供需机制)。在独热编码设定下,品牌、地区、燃油类型等类别信息会被拆分为多列稀疏特征,其单列重要性未必极高,但整体能够为模型提供“市场细分”的基准偏移。品牌通常综合反映保值率、可靠性口碑与市场偏好;地区与能源类型可能通过供需结构、政策约束与使用成本影响成交价格。
(5)匿名特征 v0~v14(综合信息机制)。匿名特征在 SHAP 与置换重要性中均占据前列,且消融实验中移除 v 特征后 MAE 显著恶化,说明其包含大量与价格强相关的信息。由于 v 特征缺乏可直接解释的语义,本文将其理解为平台侧综合编码(可能融合车型细分、配置组合、区域统计或历史行为等),用于弥补显式字段对车况与市场状态刻画不足的问题。
综上,本文的影响因素结论可概括为:匿名特征提供高信息量的综合刻画,车龄/里程/动力等变量提供可解释的折旧与使用强度机制,类别属性提供市场细分与偏移信息。重要性结论可用于实际估价场景的重点信息采集与质量控制:优先保证车龄、里程、动力、关键类别字段及平台侧综合编码信息的完整性与一致性。
5.6.5 可解释性增强:重要性—误差—消融的联合验证框架
仅给出单一口径的重要性排序容易造成“只解释了模型在平均意义上依赖什么”的局限。为提高结论的可复核性,本文采用“重要性—误差—消融”的联合证据链:
(1)重要性证据:用 SHAP 给出全局重要性与方向性解释,并以置换重要性提供边际贡献的补充对照;
(2)误差证据:用误差分层分析定位模型在哪些区间更可靠、在哪些区间风险更高,并解释重要特征与误差结构之间的联系;
(3)消融证据:用消融实验验证关键工程步骤对指标的影响,避免“重要性结论仅在特定处理口径下成立”。
通过上述证据链的互相印证,本文将“特征重要性”从单一排序扩展为“重要性—风险区间—工程有效性”的综合解释框架,使影响因素结论更具说服力。
第6章 总结与展望
6.1 总结
本文围绕二手车价格回归预测任务,构建了可复现的端到端机器学习流程,并在统一预处理与 5 折交叉验证口径下对比了 DummyMedian、线性模型、Bagging 模型与 Boosting 模型等多类方法。实验结果表明 Boosting 系列模型在该结构化表格任务上整体最优,其中 XGBoost 取得最低 MAE(约 474),并结合 SHAP 与误差分析输出可用于论文“影响因素分析”的解释结论,同时以置换重要性作为补充对照。
从实验结果看,本文的流程能够稳定产出交叉验证对比表、预测文件以及重要性分析结果,并自动生成分布图、相关性热力图、模型对比图与误差分析图。这些材料不仅支撑了模型选择的客观依据,也使论文能够从“数据—方法—实验—解释”完整呈现研究过程。总体而言,本文实现了本科阶段“可复现、可解释、能展示”的目标。
6.2 展望
尽管本文在结构化表格数据上取得了较好结果,但仍存在可进一步改进的空间。首先,数据字段对车辆真实车况的刻画仍不够充分,例如事故记录、维修保养记录、使用性质等信息缺失,会限制模型对“同款不同车况”的识别能力。若能获取更丰富的车况或文本描述信息,模型可能进一步提升精度与解释力。
其次,在异常值处理与建模策略上,可尝试更精细的分段建模,例如按品牌或价格区间训练子模型,或引入分位数回归思想分析不同区间误差结构。此外,本文参数选择以可复现与运行效率为导向,未来可在算力允许时采用更系统的超参数搜索方法(如随机搜索或贝叶斯优化),并探索模型融合以提升稳定性。
最后,可解释性方面仍有提升空间。本文主要采用 SHAP 给出全局解释,并以置换重要性作为补充对照;未来可进一步结合分组统计、误差分层、特征与预测关系曲线等方式,形成更贴近业务决策的解释与分析,从而提高模型在实际应用中的可用性。
参考文献
[1] 叶亮. 基于机器学习的二手车价格预测研究[D]. 武汉: 武汉轻工大学, 2025. DOI:10.27776/d.cnki.gwhgy.2025.000635.
[2] 陈雪. 基于贝叶斯优化LightGBM算法的二手乘用车价值评估研究[D]. 重庆: 重庆理工大学, 2025. DOI:10.27753/d.cnki.gcqgx.2025.000898.
[3] 王中举. 二手车交易价格机器学习建模预测[D]. 柳州: 广西科技大学, 2024. DOI:10.27759/d.cnki.ggxgx.2024.000301.
[4] 廖亚茹. 基于特征加权Stacking集成模型的二手车交易价格预测研究[D]. 武汉: 华中师范大学, 2024. DOI:10.27159/d.cnki.ghzsu.2024.001260.
[5] 代金辉, 仲璇, 王梦恩. 基于LightGBM和随机森林算法的二手车估价[J]. 高师理科学刊, 2022, 42(12): 15-22.
[6] 丛培斌. 新能源二手车价格预测研究[D]. 武汉: 中南财经政法大学, 2024. DOI:10.27660/d.cnki.gzczu.2024.002709.
[7] 江乐. 二手车价格影响因素研究与预测[D]. 武汉: 湖北大学, 2024. DOI:10.27130/d.cnki.ghubu.2024.000754.
[8] 唐宇. 基于机器学习的二手车价格预测模型研究[D]. 上海: 上海财经大学, 2024. DOI:10.27296/d.cnki.gshcu.2024.000691.
[9] 蔡云, 张又水, 吴澳琪, 等. 基于PSO-BP神经网络的经济型二手车估价分析[J]. 内燃机与配件, 2024(01): 109-112. DOI:10.19475/j.cnki.issn1674-957x.2024.01.007.
[10] 赵楠. 基于Stacking模型融合的二手车价格预测研究[D]. 福州: 福建师范大学, 2023. DOI:10.27019/d.cnki.gfjsu.2023.001130.
[11] 袁嘉骏. 基于机器学习的比亚迪新能源二手车价格预测[D]. 重庆: 重庆大学, 2023. DOI:10.27670/d.cnki.gcqdu.2023.001576.
[12] 杨晓娜. 基于融合模型的二手车交易价格预测[D]. 武汉: 华中农业大学, 2023. DOI:10.27158/d.cnki.ghznu.2023.001600.
[13] 任武彬. 基于机器学习方法的二手车价格预测[D]. 湘潭: 湘潭大学, 2023. DOI:10.27426/d.cnki.gxtdu.2023.001146.
[14] 宋罗瑶. 基于Lasso与集成学习的川渝地区二手车价格预测分析[D]. 重庆: 西南大学, 2023. DOI:10.27684/d.cnki.gxndx.2023.001427.
[15] 周远. 基于GWO优化混合模型的二手车估价研究[D]. 武汉: 武汉邮电科学研究院, 2022. DOI:10.27386/d.cnki.gwyky.2022.000008.
[16] 胡诣文, 张天佑, 张旭, 等. 基于机器学习的二手车价格预测算法研究[J]. 信息技术与信息化, 2022(10): 52-55.
[17] 黄文武. 基于集成学习的二手车价格预测研究[D]. 武汉: 华中师范大学, 2022. DOI:10.27159/d.cnki.ghzsu.2022.000362.
[18] 刘凡. 基于模型融合的二手车交易价格预测[D]. 西安: 长安大学, 2022. DOI:10.26976/d.cnki.gchau.2022.000233.
[19] 汪琪. 基于XGBoost算法的二手车估价模型的构建与应用研究[D]. 重庆: 重庆理工大学, 2022. DOI:10.27753/d.cnki.gcqgx.2022.000122.
[20] 邓志雄. 基于特征价格理论和机器学习技术的国内二手车价格影响因素研究[D]. 北京: 北京邮电大学, 2022. DOI:10.26969/d.cnki.gbydu.2022.001962.
[21] 李富强, 彭海丽, 杨熙, 等. 基于深度学习的二手车价格预测模型及影响分析[J]. 汽车工程学报, 2021, 11(05): 379-385.
[22] 刘畅. 基于机器学习的二手车价值评估研究[D]. 重庆: 重庆大学, 2021. DOI:10.27670/d.cnki.gcqdu.2021.000573.
附录A:项目复现说明
A.1 运行方式
在配置好运行环境后,运行实验程序即可完成模型训练、评估、可视化与结果导出。
推荐在项目目录 Used-Car-Price-Forecasting 下使用虚拟环境解释器运行:
(1)完整训练与导出(包含模型对比、预测文件、图表与表格):
./.venv/Scripts/python.exe ./run_train_predict.py
(2)仅导出第 3 章数据概况证据(字段缺失统计、样本量对照、缺失可视化):
./.venv/Scripts/python.exe ./run_train_predict.py --export_data_profile --only_export_data_profile
(3)导出最优模型的 SHAP 可解释性图(beeswarm + bar):
./.venv/Scripts/python.exe ./run_train_predict.py --export_shap --shap_sample_size 2000
A.2 输出文件清单
运行完成后将导出交叉验证结果、测试集预测结果、特征重要性结果,以及论文所需的图表与表格,便于引用与复核。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 10
10 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)