sdu软件学院创新实训(二)
·
RAG测试
在上一周学习rag的过程中,我使用python开发了一个针对“老年便秘知识”的智能ai助手的一个小型原型。
在这里测试的时候使用的是text-embedding-v4作为embedding模型以及qwen3.5-falsh
该原型系统使用的其他组件如下
- 文档解析 (PDF Loader):使用 PyMuPDF 解析医学 PDF 文档。
- 向量数据库 (Vector Store):利用 ChromaDB进行持久化存储。
Prompt 注入
现在构建了如下提示词,将检索到的文本块和用户问题动态注入
user_prompt = f"""请基于以下参考资料回答用户问题。
【用户问题】: {question}
【参考资料】: {context}
要求:
- 优先依据参考资料回答
- 不要编造资料中没有的信息
- 尽量使用用户容易理解的语言
- 最后列出参考来源(文件名+页码)
"""
测试结果
目前系统测试结果如下图所示,可以实现基本的文件解析向量化存储、检索、以及根据其进行回答并给出了回答的来源确保其准确性。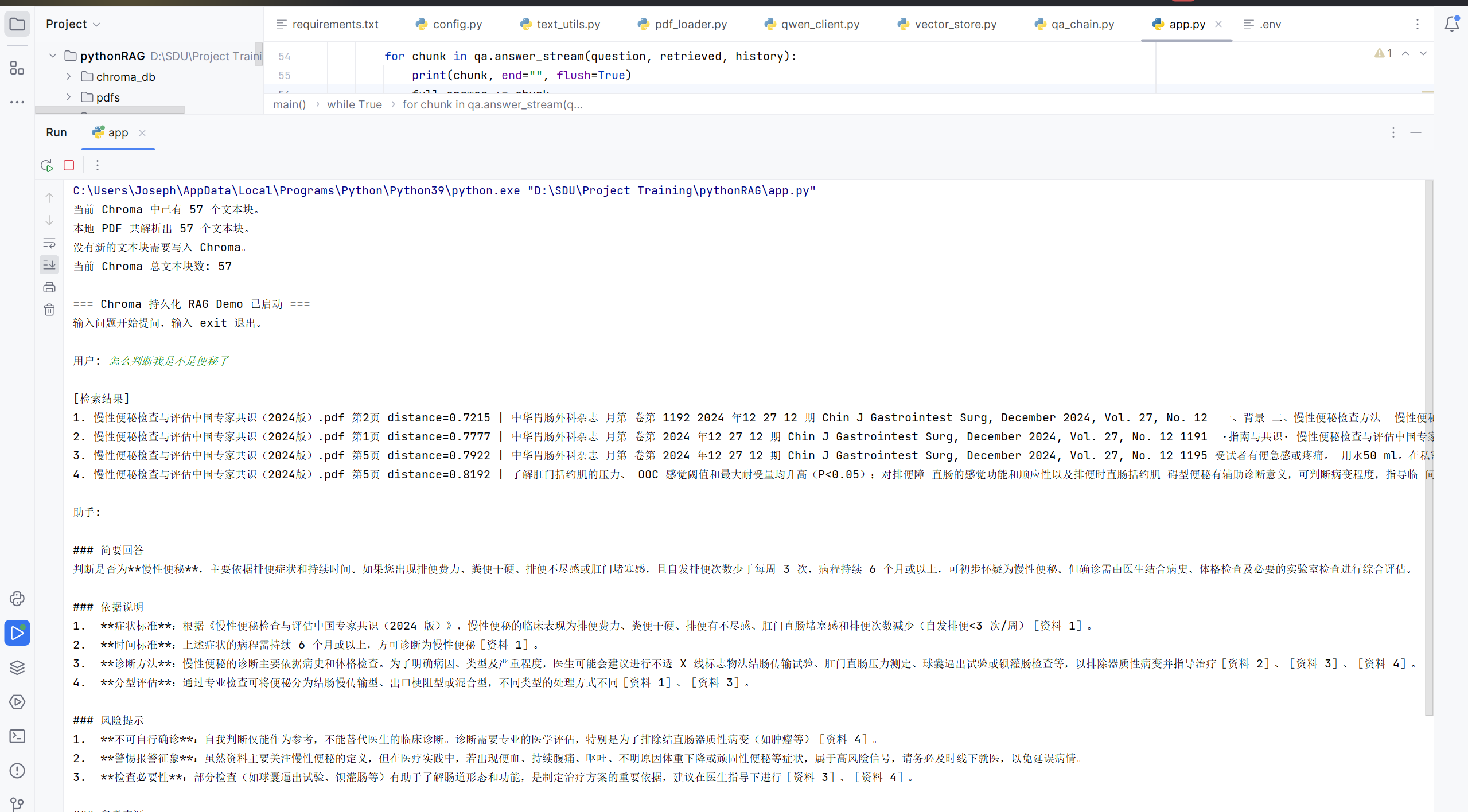
目前的问题在于,即使有流式输出,但从提问到结果开始输出的时间还是太长,在10秒左右,需要想办法进行优化以适应后续的语音交互。
下一步工作方向:
- 添加更多的知识库文件包括对原始的文件进行更加细致高效的分块处理以便于增强检索的准确性。
- 意图识别目前的系统会在每次回答的时候都进行rag检索,需要判断问题否需要进行检索,同时为后面的工具调用做准备。
- 语音交互在解决以上问题后开始集成 ASR和 TTS。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)