TabICLv2:更好、更快、可扩展且开放的表格基础模型
论文总结
1、引入查询感知可扩展Softmax(QASSMax),缓解长序列下的“注意力衰减”问题,提升模型在大数据集上的泛化能力。使用Muon优化器和更高效的训练策略,在更短的计算时间内取得更好效果。生成多样、复杂的表格数据用于预训练,增强了模型的泛化性。
2、提出来的模型,现在大量的任务上做预训练,在新数据集上,不用再重新训练,而是将“训练样本和测试样本”一起输入模型。
摘要
表式基础模型,如TabPFNv2和TabICL,最近在预测基准测试中取代了梯度增强树的地位,展示了上下文学习对表格数据的价值。我们介绍TabICLv2,这是一个基于三大支柱的新型最先进回归和分类基础模型:(1)为高预训练多样性设计的新型合成数据生成引擎;(2)各种架构创新,包括一种可扩展的注意力软极大值,提升对更大数据集的泛化,而无需过多的长序列预训练;以及(3)优化预训练协议,特别是用μ子优化器替代了AdamW。在TabArena和TALENT基准测试中,TabICLv2无需任何调优即可超越当前最先进的RealTabPFN-2.5(基于真实数据进行超参数调优、集成和微调)。仅需中等预训练计算,TabICLv2 能够有效推广到50GB GPU内存下的百万级数据集,同时明显快于RealTabPFN-2.5。我们提供广泛的消融研究以量化这些贡献,并承诺开放研究,首先在 https://github 年发布推理代码和模型权重。 com/soda-inria/tabicl,后续会有合成数据引擎和预训练代码。
引言
表格数据,无论是存储在电子表格还是数据库中,都无处不在,涵盖从医疗到信用卡欺诈检测的各种应用(Borisov 等,2022;Jesus 等,2022;Grinsztajn 等,2025)。虽然对表格数据的监督学习长期以来一直由梯度增强决策树主导(Grinsztajn 等,2022),但预训练和从零开始训练的深度学习模型最近能够在样本量高达10万的表上匹配甚至超越其准确性(Erickson 等,2025;Ye 等,2024)。特别是从TabPFN(Hollmann等,2022)开始,表式基础模型(TFM)因其能够在基于Transformer架构的单次前向传递中完成训练和推断而受到广泛关注。更优TFMs的发展也有利于下游适应,如因果推断、生成建模、联合预测分布和基于模拟的推断(马等,2025b;Robertson等,2025年; Balazadeh 等,2025;Hollmann 等,2025;Hassan 等,2025;Vetter等,2025)。为了促进这项研究,迫切需要完全开源的TFM,以实现顶级性能的民主化,并揭开顶级TFM背后的神秘面纱
贡献
我们介绍了TabICLv2,一种SOTA表基础模型,如图1所示。我们的贡献包括架构创新(第3部分)、预训练改进(第4部分)、新颖的合成数据生成(第5节)、广泛评估(第6节)和消融研究(第7节)。
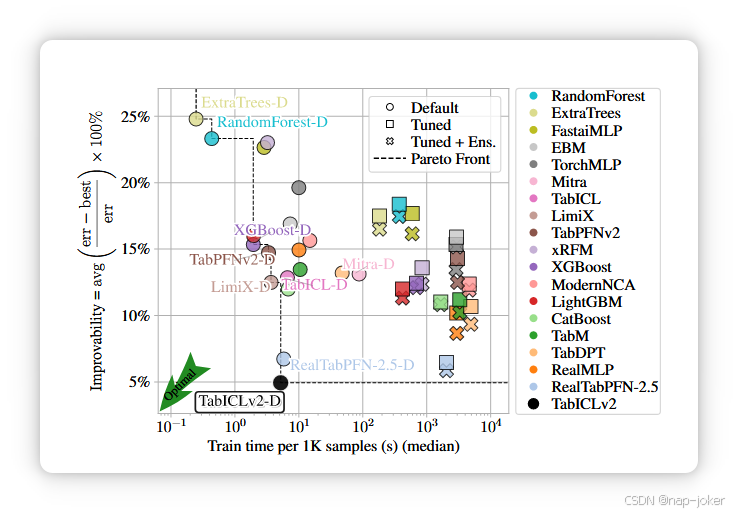
图1:TabArena上的可改进性与训练时间(Erickson 等,2025)。可改进性(越低越好)衡量了与最佳方法之间的相对误差,并对数据集进行平均。训练时间是训练+推断,采用8折交叉验证。对于基础模型,它以进行上下文学习的前向传递为主导。默认使用默认超参数;Tuned 在验证时从200种随机超参数配置中选择最佳; 调音+调音适用于所有配置的事后加权系。TabICLv2的运行时间在H100 GPU上测量,其他GPU则来自TabArena。对于不适用的模型数据集对,结果会归因于默认的RandomForest。
相关工作
表格数据基础模型
基于先验数据拟合网络(PFNs,M ̈uller 等,2021)的表格基础模型(TFMs)作为表格学习的范式转变出现。给定训练集和测试输入,参数θ的TFM qθ直接预测一个分布qθ(ytest | xtest, Dtrain),输入有前向传递(xtest, Dtrain)。对于单个数据集,它执行上下文学习(ICL),无需梯度更新。 对于预训练,给定一个可以采样数据集D(训练+测试)的先验p(D),TFMs会被训练以最小化:
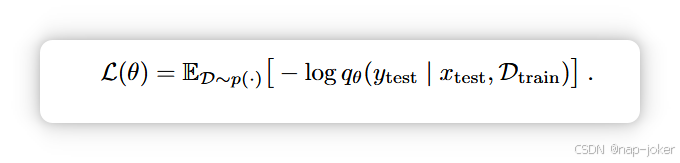
结构视角。TabPFN(Hollmann 等,2022)将每一行视为一个token,并对行执行 ICL。 TabPFNv2(Hollmann 等,2025)采用基于单元格的设计,采用交替的行和列注意,每个单元格获得独立的表示。然而,对于一个有 n 行和 m 列的表,这会产生 O(n²m + nm²) 的复杂度。TabPFN-2.5(Grinsztajn 等,2025)扩展了 TabPFNv2 的更深网络。TabICL(Qu 等,2025)通过两阶段设计将计算复杂度降至 O(n² + nm²):先以轻量级列再行注意力构造固定维行嵌入,然后对这些嵌入进行 ICL。近期研究在这些基础上持续创新,包括Mitra(Zhang等,2025a)、LimiX(Zhang等,2025b)和Orion-MSP(Bouadi等,2025)。
合成先验数据集。合成先验是PFN风格TFMs的核心。TabPFN使用结构因果模型(SCM)。TabICL和TabForestPFN(Breejen等,2024)通过混合基于树的先验来注入树的归纳偏倚来扩展这些偏置。Mitra研究了先前的设计原则,并提出了混合先验(SCM+树集合)以更好地控制决策边界。TabPFNv2 通过更复杂的 DAG 构造和计算映射丰富了先验。LimiX 引入了具有可控难度的层级 SCM。漂移韧性TabPFN(Helli等,2024)通过两级生成先验来处理时间分布变化,该先验随时间调制SCM参数。 然而,TabDPT(马等,2025a)表明,在真实数据集上进行大规模预训练可以具有竞争力,而RealTabPFN(Garg等,2025)则表明,持续在真实数据集上进行预训练可以提升TabPFNv2。
微调、检索和蒸馏。除了预训练外,TFM的适应策略还包括(a)微调,将学习的先验向目标分布移动(Feuer等,2024;Liu & Ye,2025;Garg 等,2025;Kolberg 等,2025;Rubachev 等,2025),(b) 基于检索的上下文选择以增强计算约束的可扩展性(Thomas 等,2024;Xu 等,2024;Zhang 等,2025b;Sergazinov 和 Yin,2025),以及(c)将TFMs蒸馏成致密的MLP或树(Bonet 等,2024;Mueller 等,2024;Grinsztajn 等,2025)。
基于大型语言模型的表格模型。与表原生TFM并行,大型语言模型(LLMs)通过表序列化和持续预训练被适配为表格数据(Hegselmann等,2023;Gardner等,2024年;Dong 等,2025),这些方法有前景,但在训练数据充足时表现不足。
注意力在长文本生成中遇到困难
注意力逐渐消退。注意力是PFN风格TFM的核心。 但基于softmax的标准注意力存在注意力衰落的问题(Veliˇckovi ́c 等,2024;中西,2025):随着上下文长度 n 的增加,软最大分母增加,导致注意力分布趋于平坦,阻碍对相关标记的锐利聚焦。这限制了长度泛化,因为在较短序列上训练的模型在应用到较长序列时无法维持辨别性注意力模式。
温度调节。为了解决注意力减退问题,一些研究聚焦于软极限方案(Peters 等,2019; Ramapuram 等,2024),但这需要与 softmax 生态系统不兼容的专用实现,例如 FlashAttention(Dao 等,2022)。因此,我们专注于一种侵入性更小的解决方案:温度测定。标准关注(Vaswani 等,2017)已包含固定的缩放温度因子 1/√d 以防止点积大小随维数增长,但这并未解决长度依赖的衰落问题。YaRN(Peng 等,2023)根据上下文长度对 RoPE(Su 等,2021)扩展进行温度的缩放,但缩放是固定的,需要位置编码。近期研究提出了动态替代方案。 可扩展软极限(SSMax,Nakanishi 2025)通过 s log n 来扩展注意力日志,其中 s 是可学习的每个头参数。 并行理论分析(Chen 等,2025b)证明,随着上下文长度 n 的增长,log n 的缩放对于保持注意力敏锐度是必要的。自适应可扩展 Entmax(ASEntmax,Vasylenko 等,2025)通过内容感知缩放扩展到 δ + β(log n)γ,其中 δ 是长度无关的常数偏移,β = softplus(MLP(X)) 和 γ = tanh(MLP(X)) 依赖输入。选择性注意力(Zhang 等,2024)采取了不同的方法,通过轻量级MLP引入了查询相关的温度τ(q),完全将缩放与上下文长度解耦。
结构
TabICLv2 的架构如图 2 所示。继TabICL之后,TabICLv2链上了列嵌入、行交互和数据集ICL,从而在n行m列表中保持了运行复杂度O(n² + nm²)的TabICL效率。此外,我们还引入了若干改进,显著提升了性能而不增加模型规模(参见第7节的消融研究)。在下文中,我们用 标记这些改进▶。我们下面重点介绍架构创新。关于模型配置的详细信息(例如层数),请参见附录A.4。我们提供了一个简短的自包含实现,用于教育和实验目的,灵感来自nanoTabPFN(Pfefferle等,2025),https://github.com/soda-inria/nanotabicl。
▶ 重复的特征分组。TabICL独立嵌入每个特征,当特征分布相似时,可能导致表示崩溃。TabPFNv2 和 TabPFN-2.5 通过将多列分组为单一令牌来缓解这种崩溃,这也减少了有效特征数量以提升效率,但这种减少可能会丢失细粒度的特征信息。我们提出重复特征分组,通过循环平移将每个特征分组,同时保持有效特征数量。具体来说,对于有 m 列的表,我们创建 m 组,其中第 j 组包含 mod m 位置 (j, j + 1, j + 3) 的列。每个群由共享的线性层 Lin : R3 编码 → Rd: E1[i, j] = Lin 习,j , 习,(j+1) mod m, 习,(j+3) mod m 。 移位模式(0, 1, 3)确保≥7列中,没有一对列出现在多个组中。 我们在附录A.1中展示了该模式可推广至任意组规模,尽管我们未观察到较大组持续的改善。
▶ 目标感知嵌入。我们发现早期注入目标信息是有益的。在反复进行特征分组生成输入数据表示 E1 ∈ Rn×m×d 后,我们会为每个训练标记添加目标嵌入:E2[i, j] = E1[i, j] + EmbedTAE(yi), i ∈ Dtrain,其中 EmbedTAE 是用于回归的线性层或可学习的分类查找表。与 TabPFNv2 将目标作为附加列不同,我们直接为所有特征添加目标嵌入。这也有助于减轻表示崩溃,因为即使两个特征分布相似,它们与目标值的关联在不同样本中也常常存在差异。 先做压迫,然后做ICL。TabICLv2 将 E2 分三个阶段处理:(1) 逐列嵌入应用集合变换器TFcol(Lee 等,2019)对每列进行;(2)行交互使用带有[CLS]令牌的变换器TFrow将每行的特征嵌入合并为单一向量;(3)在数据集上,ICL结合行嵌入与目标嵌入,并使用变换器TFicl,测试样本关注训练样本以进行预测。详情见附录A.2。
▶ 与TabICL相比,我们这里的关键创新是对TFicl以及TFcol中诱导点汇总输入信息的部分应用了一种新颖的可扩展软最大标准。
▶ 查询感知的可扩展软最大空间。为了更好地推广到更大数据集,我们扩展了可扩展软极限(SSMax,Nakanishi 2025),这是一种温度尺度方法,通过在计算logit前重新调整查询来增强注意力分布。设qh = (qhi)为头部h处的查询向量,头维数由i索引,n为训练集大小。SSMax 通过可学习的每头标量 sh 重新缩放查询:q ̃hi = qhi ·SH 日志 n 。 我们提出了查询感知的可扩展软max(QASSMax),该方法将每个查询元素重新缩放为:

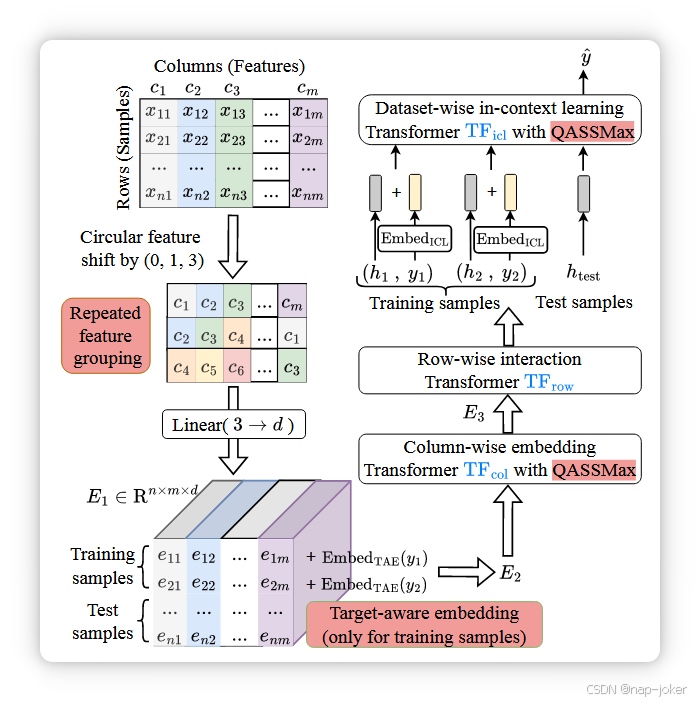
图2。TabICLv2 的架构。给定输入 X ∈ Rn×m,重复特征分组通过循环平移将列编码为多个组以破坏特征对称性,目标感知嵌入则从一开始注入目标信息。TFcol通过集合变换器嵌入每个特征,TFrow将特征聚合到行表示h中,TFicl进行上下文学习以预测测试目标yˆ。QASSMax,我们的查询感知型可扩展软最大值,应用于TFcol中诱导点汇总输入信息的部分,TFicl则减少注意力减弱并提升长上下文泛化能力。
我们设计QASSMax基于以下理由:(a)log n因子至关重要,因为它抵消了软极大分母相对于n的线性增长(Nakanishi, 2025;Chen 等,2025b);(b) ASEntmax(Vasylenko 等,2025)使用可学习的δ + β(log n)γ,启发我们推广到 MLPbase(log n);(c) 元素尺度提升表现力,超越每个头的标量;(d) 选择性关注(Zhang 等,2024)引入了温度尺度中的查询意识,这促使我们使用有界查询感知∈门控 (0, 2) 来调节基准尺度而不主导 log n 趋势。
此外,我们的门控设计与门控注意力(Qu 等,2025)有相似见解,后者将门控应用于注意力输出,发现依赖查询、按元素的门控最有效。 将QASSMax应用于TFcol和TFicl,性能显著提升,正如消融研究(第7节)所示。为了研究其对注意力淡化的影响,我们设计了一个玩具大海捞针分类任务(见图3):模型必须聚焦于一个锚点样本(针),而在逐渐增加的负样本(干草堆)中。没有可扩展的软最大值,注意力熵上升而准确率下降。 然而,QASSMax即使在15K负片下仍保持低熵和100%准确率,优于在极端尺度下主要降解的SSMax。 多级分类。像许多TFM一样,TabICLv2预训练最多可有10个类。我们在ICL阶段使用层级分类(Qu等,2025年)。然而,目标感知嵌入在分层划分之前引入了标签。
▶ 为此,我们提出混合基类:对于 C> 10 类,计算平衡基 [k0, . . . , kD−1],每个 ki ≤ 10,Q i ki ≥在 C,然后通过混合基表示将每个标签 y 分解为 D 个数字 y(i) ∈ {0, . . . , ki−1}。每个数字定义了原始类别的更粗略分组。我们每位数运行一次TFcol,并对输出进行平均:

回归的分位数预测。现有TFM采用不同的回归策略:TabPFNv2和TabPFN-2.5通过将目标空间离散化为多个箱并应用交叉熵损失来建模完整预测分布,而Mitra和TabDPT则利用MSE损失预测点估计。此外,像大多数TFMs(除LimiX外)一样,我们训练独立的分类和回归模型。 TabICLv2 则预测 999 个概率α ∈水平为 {0.001, 0.002, ... . , 0.999} 的分位数,这些分位数是通过弹珠台丢失在所有分位数上加和训练的。在使用RMSE评估的初步实验中,我们发现分位数回归优于MSE和基于bin的TabPFNv2方法。 在推断时,对于点估计,我们只需将预测分位数,这既快速又有效。 对于概率预测,我们通过排序(默认)或等张回归来强制单调性,从分位数构造出完整分布(Barlow 和 Brunk,1972; Busing, 2022),通过参数指数模型推算尾部,并推导出闭式PDF、CDF和矩。详情见附录一。
预训练和推理
预训练的配置
与TabICL(带开放预训练的参考TFM)相比,我们显著改进了预训练设置。
三个预训练阶段。我们保留了TabICL的三阶段结构,逐步扩展预训练数据集的规模,所有阶段最多可包含100个特征。然而,在TabPFNv2之后,我们将批次规模减少到64,从而允许比TabICL(≈83M)和TabPFNv2(≈130M)更多的步骤和更少的数据集(≈35M)。
三个阶段分别是:
• 第一阶段:50万步,数据集1,024个样本,30–90%用于训练,最大学习率8e-4。
• 第二阶段:数据集4万步,样本数为400–10,240(对数均匀),80%用于训练,最大学习率1e-4。
• 阶段3:数据集1万步,样本400–6万(对数均匀),训练时80%,最大学习率2e-5。 在附录B.1中,我们展示了第2和第3阶段性能的渐进性提升,尤其是在大型数据集上。
优化器。我们使用基于Schaipp(2025)实现的Muon优化器(Jordan 等,2024b),而非TabICL(或称 Adam)使用的 AdamW(或称 Adam)。 TabPFNv2)。按照Moonlight(Liu等,2025)的做法,该实现将每个参数W∈Rn×m的学习率乘以0.2·pmax{n, m}。我们发现 Muon 学习率更高更为理想。因此,我们对第一阶段的最大学习率为8e-4,而TabICL中AdamW为1e-4。我们采用参数0.01的谨慎权重衰减(Chen 等,2025a),仅在更新和参数符号相同时才应用衰减,避免与有利梯度方向的干扰。我们还将第一阶段和第二阶段的梯度削波从1增加到10,每个微批次采样不同的列车/测试尺寸,并在所有阶段使用余弦学习率计划。 预培训费用。在配备80GB内存的H100 GPU上,第一阶段大约需要20 GPU日,第二阶段大约2.5 GPU日,第三阶段大约2 GPU日,每个型号总共需要24.5 GPU日。考虑到一个H100小时大致相当于我们的预培训费用低于TabICL(60小时A100)。
推理优化
我们实现了磁盘卸载(附录 H.2),将 CPU 和 GPU 需求降低至 24 GB 以下,以在 450 秒内处理包含 100 万样本和 500 个特征的表(见图 H.2)。结合QASSMax进行长上下文泛化,TabICLv2能够原生处理百万尺度表,无需检索和蒸馏。此外,我们通过选择性计算 Q/K/V 投影(附录 H.1)减少了冗余计算。
合成数据先验
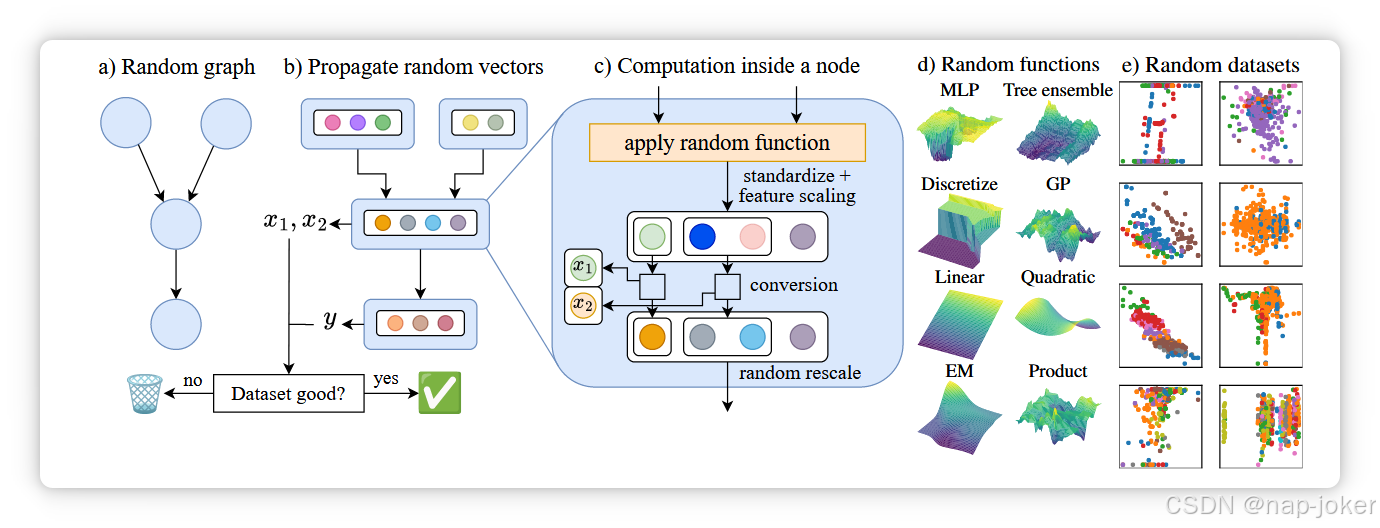
图4。合成数据集生成的高级结构。随机向量(每个样本一个)通过随机生成的图传播,每个节点计算其父节点的随机函数。最终数据集的列从随机分配的节点中提取。根据不同的过滤标准,所得数据集可以被拒绝。(d) 应用的8个随机函数列表:(MLP)多层感知器,(树系)受CatBoost启发的对称树集合(Prokhorenkova 等,2018),(离散)随机集中向最近邻的离散化;(全科医生)多元高斯过程函数;(线性) 线性函数;(二次方程)多元二次函数;(EM)具有平台期的函数,灵感来自EM算法中的簇赋值;(乘积)其他随机函数的乘积。(e) 生成的二维分类数据集示例(参见图F.1)。
我们的预训练数据完全是合成的,采用了TabPFN开创的方法(Hollmann等,2022)。该数据生成机制称为先验,因为它隐含定义了数据集上的贝叶斯先验。对于TabICLv2,我们设计了一个新的先验,保留了Hollmann等(2022)中使用的结构因果模型框架,融合了TabICL和TabPFNv2先验带来的创新,并增加了许多新颖的设计选项和采样机制(见附录E.1)。与架构和预训练选择不同,新的先验大多在没有实验反馈的情况下开发,因为细粒度消融不切实际且容易对验证数据集进行过拟合。相反,先前的开发遵循一般设计原则(Wilson 和 Izmailov,2020),最大化数据集多样性(如变量依赖关系和类别基数),同时编码有用的归纳偏差并保持计算效率。这一新先验对最终性能至关重要:用TabICL先验预训练TabICLv2的性能显著降低(图10,灰色)。 由于 TabPFNv2 非开源,无法进行消融。我们在下方提供了高层次的先前描述,详情请见附录E和F。高层次结构。图4总结了TabICLv2先验。我们首先抽样全局数据集属性,如数值和类别特征数量,以及数据集大小。随后,我们采样一个有向无环图和定义父子关系的随机函数,得到一个因果数据生成模型。为了获得包含n个样本的数据集,在每个根节点i处采样一个矩阵X∈,Rn×di,包含n个随机向量,并传播到图中。每个数据集特征均从随机分配的节点中提取。每个特征只使用节点维度的子集,其他维度未被观察,从而在数据集中引入噪声。与以往工作不同,我们在节点层面不添加高斯噪声。对于数值特征(例如x1),特征值从单个节点维度中提取。对于范畴特征(例如,x2),通过最近邻赋值或应用软极大值(softmax)提取并离散化多个节点维度,获得分类分布。 新采样机制由于Hollmann等人(2025)使用的随机图抽样机制只能生成树状图,我们引入了一种“随机柯西图”机制,用于建模不同的全局和局部节点连通性,详见附录E.4。 子节点与其父节点之间的关系通过图4(c)所示的多个步骤生成。关键步骤是抽样多种随机函数以应用于父数据。我们使用八种随机函数类型,如图4(d)所示。前三个是改编自TabPFNv2,另外五个是全新版本。这些函数被选择用于覆盖不同水平的光滑性(我们已证明高斯过程函数的光滑度)以及不同类型的归纳偏置(例如平台或轴对齐)。为了处理多个父节点的情况,我们随机选择两种选项:将所有父矩阵串接并应用单一随机函数,或者对每个父矩阵应用随机函数,并用和、积、最大值或对数矩阵汇总结果。即使在每种函数类型内,我们也通过新的或扩展的构建模块来丰富生成的函数,包括多种随机矩阵类型(针对MLP、线性、二次函数等)、随机权重向量(用于奇异值、特征重要性等)以及随机激活(针对MLP的随机矩阵),详见附录E。 应用随机函数后,我们标准化X并随机重新调整其列以模拟不同的特征重要性。随机转换器提取特征值,同时也可以修改节点值,对标量应用扭曲函数或对子向量施加离散化机制(见附录E.6)。最后,节点数据X乘以一个模拟“节点重要性”的随机标量。
后期处理。我们应用了一些类似TabICL的后处理(Qu等,2025),包括丢弃有问题的列和数据集、置换列和类标签,以及预处理特征和目标。
数据过滤。受 Dong 等人(2025)和 Zhang 等人(2025b)启发,我们过滤掉了那些简单的 ExtraTrees 模型无法通过自举测试在常数基线上改进的数据集。此外,我们直接过滤与 x 相关的节点与 y 节点没有共同祖先的图,这意味着 y 与 x 无关。在预训练阶段1,大约35%的分类数据集和25%的回归数据集被过滤。 图10显示过滤改善了预训练的收敛性。
对相关标量进行采样。我们经常从同一分布中多次采样数值或类别标量(“超参数”),例如一列内的类别数量。我们引入了一种相关的抽样方式,例如,为了更有可能采样多列类别数量相同的数据集。
实验
基准测试。我们使用TabArena(Erickson等,2025)和TALENT(Ye等,2024)基准测试。TabICLv2 通过随机列/类洗牌和不同的预处理器进行预测,类似于 TabICL。TabArena包含51个数据集(38个分类,≤10个类别,13个回归),通过重复交叉验证ROC AUC进行二元验证,log-loss用于多分类,RMSE进行回归分析。 我们使用 8 个估计器来匹配 TabICLv2 中的 RealTabPFN2.5。TALENT 包含 300 个数据集(120 个二元数据集,80 个多类数据集,100 个回归数据集),训练/验证/测试比例分别为 64%/16%/20%。超参数在验证集中选择,分类时使用准确率,回归时使用RMSE。我们在TALENT中为TabICLv2和TabPFN-2.5/RealTabPFN-2.5使用了32个估计器。 我们主要报告可改进性,即衡量每个数据集上最佳方法的平均相对误差差距,使最佳方法能够在不同数据集间变化。可改进性反映了与基于排名指标的绩效差异的大小。我们在附录J和K中提供了其他指标。 此外,在TabArena和TALENT之后,我们使用TabICLv1.1检查点(Qu等,2025),这是基于我们之前版本的TabICL后期训练。 TabICLv2在两个基准测试中都是最先进的。如图1和图5所示,TabICLv2在可改进性与运行时间的帕累托战列中占据主导地位。无需调校,TabICLv2 超越了 RealTabPFN-2.5(调谐 + 集成),后者是目前尚未完全开源的先进技术。 尽管训练时间少了几个数量级,TabICLv2 也远远优于经过高度调校的传统方法,如 CatBoost 和 XGBoost。
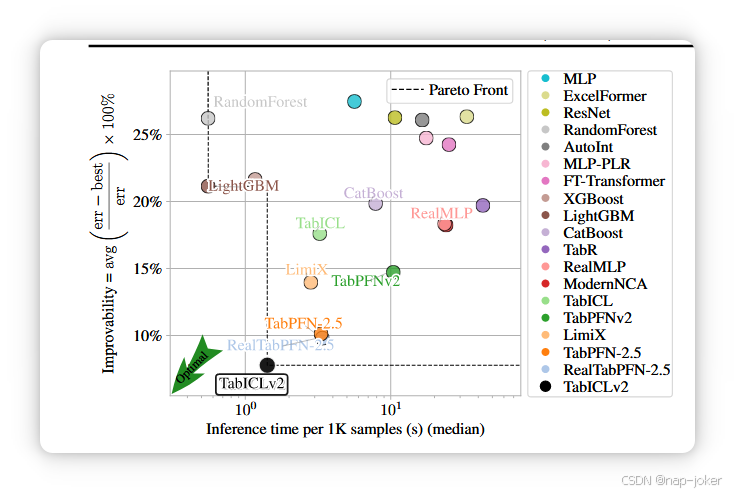
图5。TALENT中的可改进性与推理时间(Ye等,2024)。TabICLv2的运行时间是在H100 GPU上测量的,而其他运行时间则取自TALENT。
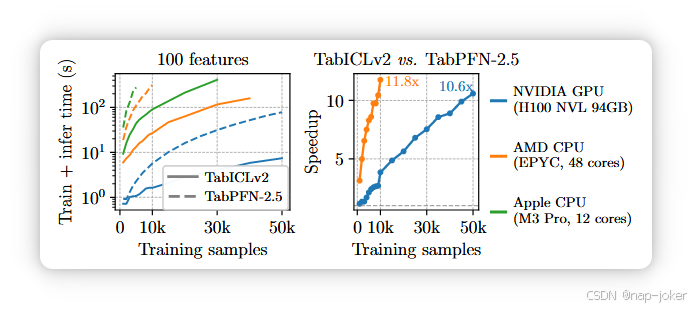
图6。TabICLv2 与 TabPFN-2.5 在训练样本和硬件数量上的运行时比较。两者都使用8个估计量。我们使用500个检测样本进行分类。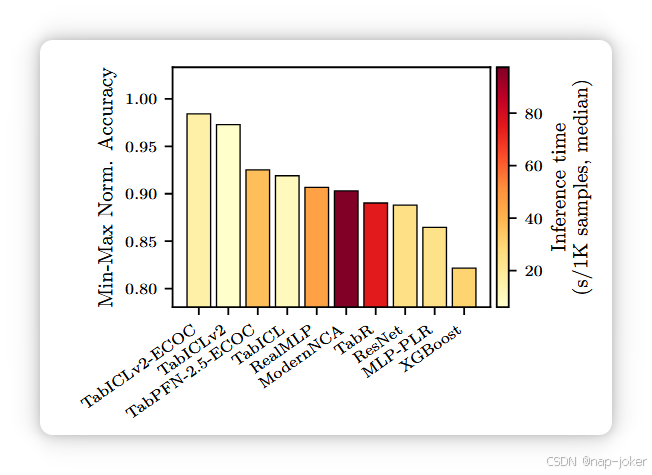
图7。在TALENT基准中,12个数据集中超过10个类别的归一化准确率。
TabICLv2 的速度始终快于 TabPFN-2.5。如图6所示,对于100个特征,TabICLv2在所有硬件上都快于TabPFN-2.5,且在更大尺度上加速更快:在H100 GPU上,5万采样时速度为10.6×。CPU 的效率差距更明显,仅用 10K 采样就达到 11.8×。
TabICLv2在多类分类方面表现出色。结合TabPFNv2的纠错输出码(ECOC)包装和我们原生的混合基集合,在拥有10类的TALENT数据集上,TabICLv2的表现显著优于所有基线>10类(见图7)。ECOC包装稍微好一点,但比我们原生的操作慢了3×。
TabICLv2 可扩展到大型数据集。如图8所示,TabICLv2在所有数据集大小(103至105)中均位居顶尖,在更大数据集(>20K)中表现优于RealTabPFN-2.5。在TALENT扩展的更大数据集(60万)上,TabICLv2依然表现强劲(见图9)。这些结果表明,TabICLv2进一步拓展了TFM在原生处理大规模数据方面的前沿。
消融实验
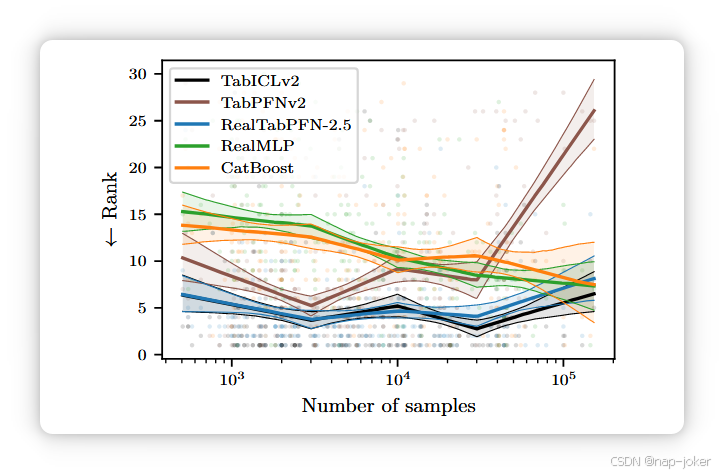
图8。模型排名基于样本量,适用于TALENT。这些线显示了分段线性拟合的自助中位数和10% / 90%自助信赖区间(Qu等,2025)。
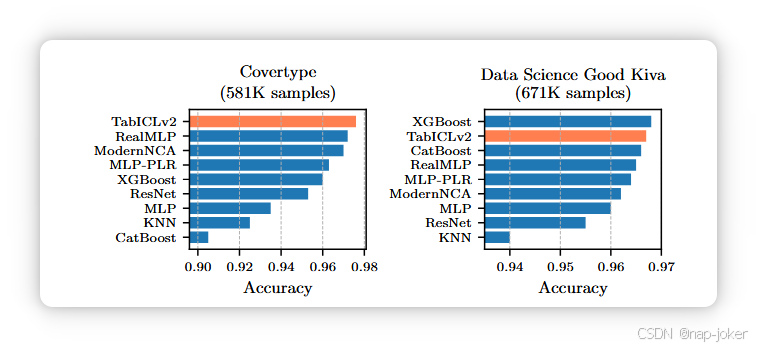
图9。TALENT扩展中两个庞大分类数据集的准确性。TabICLv2 依然表现良好。TabPFN2.5 导致内存不足错误
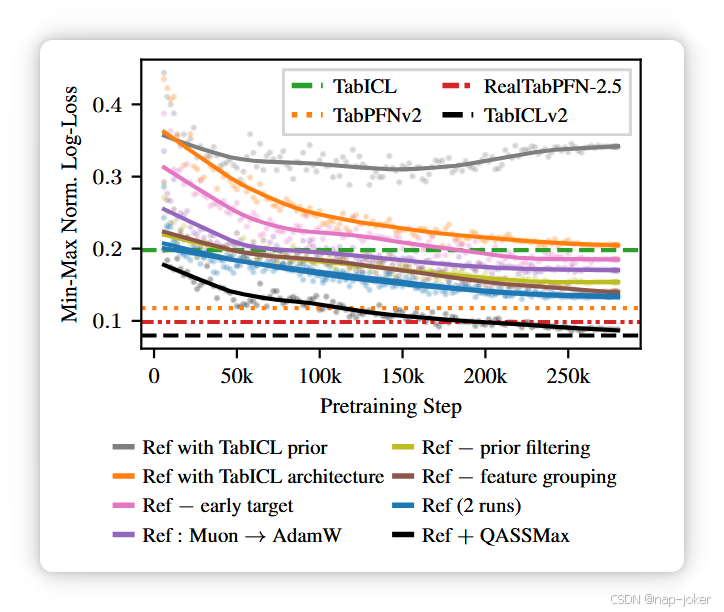
图10。消融TabICLv2的不同成分。非实心水平线表示官方检查点的执行; 实线表示预训练28万步的蚀刻模型。每次消融都会通过添加(+)、去除(−)或替换(→)来修改参考模型中的一个分量(蓝色)。参考模型对应于 TabICLv2,但没有 QASSMax,且 TFcol 和 TFicl 的磁头由 4 个而非 8 个。性能指标基于用于 TabPFNv2 开发的 60 个验证数据集计算(Hollmann 等,2025,补充表 5)。每个数据集使用最多2,048个训练样本(数据集较小时样本更少),并使用两个训练/测试拆分。AdamW消融使用规律的重量衰减,并在TabICL后学习率为1e-4。散点图显示每步验证性能,并显示随着学习率下降噪声的减少。
我们进行消融研究,以评估架构、先验和预训练选择的影响(见图10)。参见附录C有更多消融结果。参考TabICLv2检查点(虚黑)与消融(实心黑色)之间的性能差距,可以用预训练长度解释:消融训练为28万步,而官方检查点预训练更多步(第一阶段加第二和第三阶段50万步),并且TFcol和TFrow使用8个注意力头而非4个。有趣的是,TabICLv2在20万步后与RealTabPFN-2.5≈对数丢失,以及<10万步的归一化精度。 首先,我们观察到建筑与先验之间存在强烈的相互作用。预训练TabICLv2且先验TabICL失败(灰线):性能仍低于TabICL,且验证丢失在预训练后半段下降。 这表明TabICLv2架构需要更高的先验多样性才能泛化,这或许类似于马等人的观点。 (2025a)观察到,缩放定律在弱合成数据生成器下可能失效。此外,用 TabICLv2 先验(橙色)预训练 TabICL 架构时,仅与 TabICL 匹配,表明 TabICL 架构在利用更高先验多样性方面能力有限。 在包括归一化准确率、Elo和对数损失在内的指标(图C.1)中,消融的排序是一致的。 先注效应最大。三个组成部分提供可比且显著的收益(≈100 段位,64% 胜率早期目标包含,Muon代替AdamW,以及QASSMax。反复进行特征分组和预先过滤则带来的增益更小
局限性
TabICLv2 与相关模型有共同局限:它无法原生利用列名或文本特征的语义信息,这被证明有价值(Spinaci 等,2025),但其对大量特征的可扩展性表明,结合文本嵌入模型时应保持较快。此外,尽管可扩展性有所提升,拥有数百万样本的数据集依然充满挑战。许多扩展,如多输出回归或处理分布转移(Helli 等,2024),也留待未来研究。由于缺乏成熟基准测试,TabICLv2的分布回归能力仅用于玩具数据集(附录I.9)。在预训练阶段添加缺失指标(Le Morvan 和 Varoquaux,2025)或引入缺失,可能有助于改善目前由均值归算但尚未深入探讨的缺失值处理。 最后,超参数调谐或微调(Rubachev)等人,2025)可能进一步提升性能,但代价是会增加运行时间,但本文不予探讨。
总结
TabICLv2 代表了表格基础模型(TFM)领域的重大进步,实现了最先进的性能,并重新定义了 TFM 的原生可扩展性。我们承诺全面开源所有内容,以实现对最先进 TFM 的普及化。凭借适中的预训练和推理成本,TabICLv2为未来适应提供了极佳的基础。此外,我们优先考虑开箱即用的性能和原则创新,而不是对真实数据进行微调(Garg 等,2025)或通过更深层次(Grinsztajn 等,2025)或更广泛的数据进行扩展(马 等,2025a;Zhang 等,2025a)架构。我们希望TabICLv2能激励持续创新,推动更小、更快、更优的模型。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 11
11 0
0- 0



 已为社区贡献28条内容
已为社区贡献28条内容

所有评论(0)