GEO效果归因与智能策略系统:从黑箱归因到智能决策的工程实践
当AI推荐成为黑箱,企业不仅需要知道“自己被推荐了”,更需要知道“为什么被推荐”以及“如何优化”。GEO效果归因与智能策略系统,通过两级归因分析框架(SHAP全局归因+双重机器学习因果估计)和规则-案例混合推理策略生成机制,将AI推荐黑箱转化为可量化、可解释、可行动的工程科学。
执行摘要
在生成式引擎优化(GEO)实践中,企业面临的核心难题不仅是“被AI推荐了多少次”,更是“为什么被推荐”以及“如何优化才能获得更多推荐”。针对这一痛点,《GEO效果归因与智能策略系统》软著应运而生。本系统是GEO逆向工程智能分析平台的“决策大脑”,通过独创的“两级归因分析框架”与“规则-案例混合推理策略生成机制”,实现对AI推荐黑箱的透明化拆解。
系统核心技术包括:基于LightGBM+SHAP的全局归因引擎,量化数百个特征对推荐排序的贡献度;基于双重机器学习的因果效应估计引擎,回答“如果增加某个特征,平均能带来多少效果提升”;将DSS原则(语义深度/数据支持/权威来源)操作化为三级金字塔特征体系;融合规则推理与案例检索的混合策略生成引擎,输出人类可读的策略报告和机器可读的API指令。系统设计遵循可解释性优先、决策可追溯、持续进化三大原则,所有归因结论均附带置信区间,所有策略均可回溯至原始数据和规则。本文为技术团队提供一套从黑箱归因到智能决策的完整工程实践方法论。
关键词:GEO,效果归因,SHAP,双重机器学习,策略生成,DSS原则,可解释AI
第一章 引言:GEO优化的归因困境
生成式引擎优化(GEO)的核心任务是提升企业内容在AI大模型答案中的引用率和推荐位序。然而,在实践中,企业面临一个根本性的困境:AI推荐是一个黑箱。
-
为什么竞品内容总是排在前面,而自己的内容却很少被引用?
-
是“本地化案例”不够丰富?还是“技术参数”不够详实?或是“第三方背书”权威性不足?
-
如果投入资源优化某一类内容,预期能带来多少效果提升?
传统分析工具只能回答“是什么”(提及率、排名),无法回答“为什么”和“怎么办”。《GEO效果归因与智能策略系统》软著正是为解决这一问题而设计。它通过量化归因和智能策略生成,将GEO从依赖经验的“艺术”进化为基于数据与算法的“科学”。
本文将从系统定位、总体架构、核心算法、特征体系、策略生成、技术指标等维度,全面解析这一系统的工程实现。
第二章 系统定位与核心价值
2.1 核心定位:从“数据”到“行动”的智能转换器
在GEO逆向工程智能分析平台中,本系统扮演“决策大脑”的角色:
| 环节 | 负责系统 | 核心职能 |
|---|---|---|
| 采集 | 多源智能推荐数据采集与信源分析系统 | 获取推荐项-信源关联数据 |
| 归因与决策 | 效果归因与智能策略系统 | 量化贡献度、生成优化策略 |
| 执行 | 内容管理系统、SEO/GEO工具链 | 执行策略指令 |
核心价值:将“发生了什么”的数据现象,转化为“为什么发生”的因果洞察,并最终生成“如何改变它”的行动方案。
2.2 设计哲学
-
可解释性优先原则:所有归因结果必须附带置信度与可理解的解释,拒绝“黑箱”模型。
-
DSS原则的量化贯彻:将语义深度、数据支持、权威来源解构为可计算的特征维度。
-
决策可溯源性:任何一条生成策略,均可回溯至触发它的原始数据样本、归因计算结果及具体的策略规则。
-
持续进化机制:建立策略执行效果的正/负反馈回流管道,使系统能够持续优化。
第三章 系统总体架构
3.1 逻辑架构图
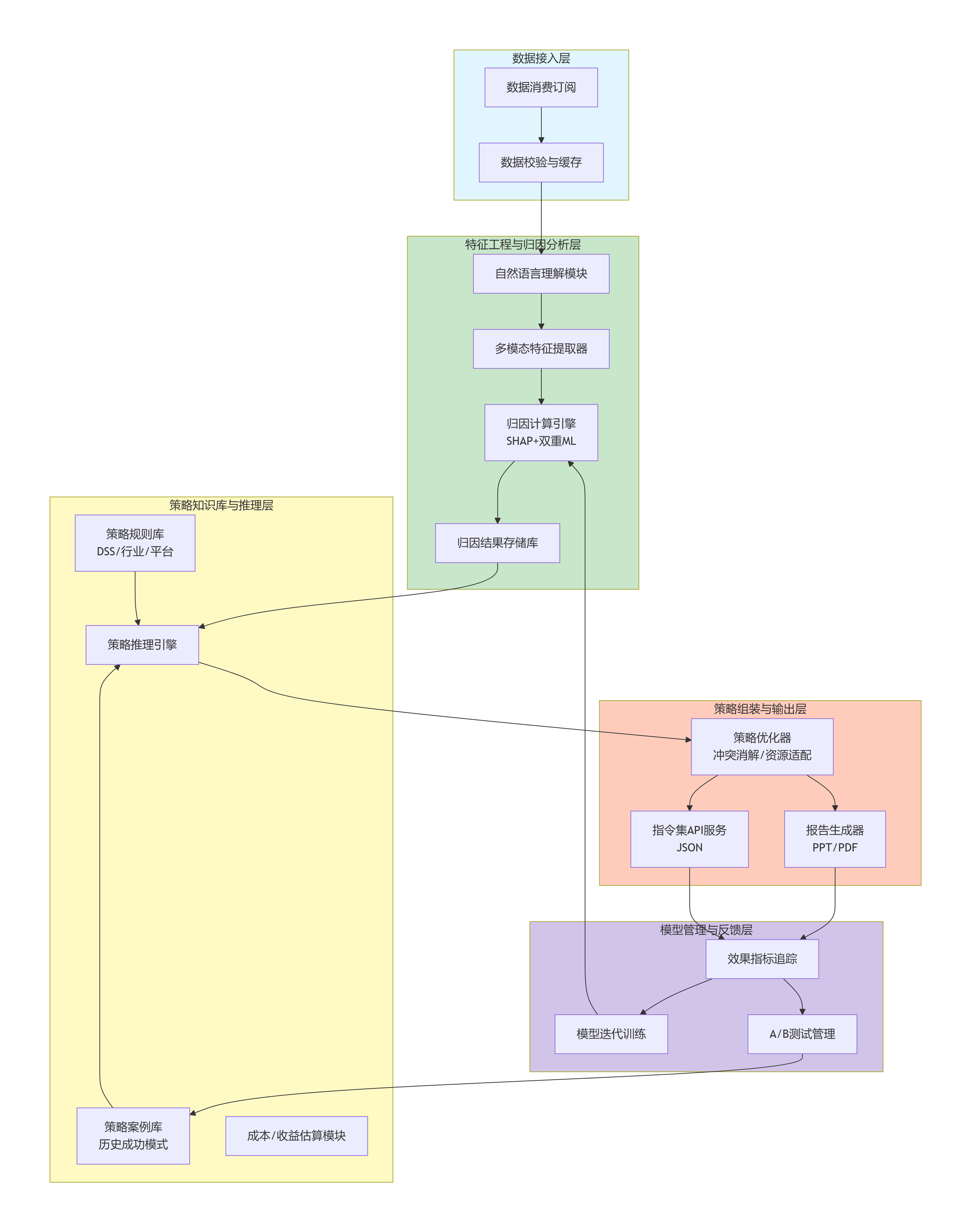
图1:GEO效果归因与智能策略系统五层逻辑架构——从数据接入到归因分析,再到策略生成与反馈学习,形成完整闭环。
3.2 核心服务与技术栈
| 组件层级 | 核心服务 | 技术栈 | 选型理由 |
|---|---|---|---|
| 数据与计算层 | 归因计算引擎、特征向量服务 | Python (PyTorch, SHAP, Captum), JVM | Python在可解释AI工具上领先;JVM适合生产环境核心服务 |
| 知识推理层 | 策略规则引擎、推理服务 | Drools/自研DSL, Neo4j, Milvus | Drools管理复杂规则;知识图谱管理策略间关系;向量库支持案例检索 |
| 服务与存储层 | API网关、微服务、数据存储 | Spring Cloud, PostgreSQL, Redis, Milvus | 成熟微服务生态;PG存储关系型数据;Redis缓存热点 |
| 运维监控层 | 全链路监控、日志 | Prometheus, Grafana, ELK Stack | 行业标准,保障可观测性 |
第四章 核心模块详解
4.1 特征工程与归因分析层
4.1.1 自然语言理解与多模态特征提取器
输入:推荐摘要文本、信源元数据(URL、分类、权重)。
处理流程:
-
领域自适应分词与实体识别:使用在GEO及特定行业语料上微调的模型,识别“轻量化SaaS”“KOL测评”“ISO认证”等领域实体。
-
细粒度特征标签化:采用“本体-属性-值”三级标签体系。例如:
{本体: 服务属性, 属性: 部署模式, 值: 轻量化SaaS}。 -
情感与确定性分析:判断描述为“断言型”(“支持私有化部署”)或“模糊型”(“可能提供定制方案”),后者贡献度打折。
-
信源特征融合:将信源的分类(如“官方案例库”)和权重作为推荐项本身的强关联特征注入。
输出:每个推荐项转化为一个结构化特征向量,维度可达数百维。
4.1.2 归因计算引擎(核心算法)
系统独创“两级归因分析框架”,融合SHAP全局归因和双重机器学习因果估计。
算法框架一:基于树模型的SHAP归因(适用于复杂非线性关系)
-
使用LightGBM或XGBoost训练一个预测推荐位序的模型。
-
应用SHAP(SHapley Additive exPlanations)计算每个特征在所有可能特征组合中的边际贡献平均值。
-
输出每个样本的SHAP值矩阵,直观展示各特征如何推动预测值偏离基线。
python
import lightgbm as lgb
import shap
def shap_attribution_analysis(X_train, y_train, X_explain):
model = lgb.LGBMRegressor(num_leaves=31, max_depth=6)
model.fit(X_train, y_train)
explainer = shap.TreeExplainer(model)
shap_values = explainer.shap_values(X_explain)
return {
"global_importance": np.mean(np.abs(shap_values), axis=0),
"local_contributions": shap_values,
"expected_value": explainer.expected_value
}算法框架二:基于结构化因果模型的归因(适用于强逻辑推断场景)
-
构建因果图:基于领域知识(DSS原则)建立特征与推荐位序之间的假设性因果图。
-
估计因果效应:使用双重机器学习方法,在控制其他混杂变量的前提下,估计某个特征(如“是否有本地案例”)对推荐位序的平均处理效应(ATE)。
-
输出:“在控制其他因素后,增加‘本地案例’平均可使排序提升8.5%(置信区间: 6.2%-10.8%)。”
独创性输出:系统综合两种框架的结果,生成特征贡献度报告,包含:全局重要性排序、局部归因解释(每个特征的贡献可视化)、归因置信区间。
4.2 策略知识库与推理层
4.2.1 策略知识库的构成
| 组件 | 作用 | 示例 |
|---|---|---|
| DSS规则集 | 将DSS原则转化为生产式规则 | IF 数据支持强度弱 AND 行业≠金融 THEN 添加第三方测评报告 |
| 行业合规规则集 | 编码特定行业的法规与最佳实践 | IF 行业==医疗 AND 提及疗效 THEN 强制添加“请遵医嘱”声明 |
| 平台差异化规则集 | 针对不同AI平台的信源偏好 | IF 目标平台 IN [DeepSeek, Kimi] THEN 偏好信源类型=[技术白皮书, 学术论文] |
| 案例库 | 存储历史成功优化案例(情境-策略-效果) | 基于向量相似度检索最相似的历史成功模式 |
4.2.2 策略推理引擎工作流

图2:混合推理策略生成流程——规则保证合规性,案例提供创造性,策略优化器进行冲突消解和优先级排序。
4.3 策略组装与输出层
4.3.1 策略优化器
-
冲突消解:当两条策略冲突时(如一条建议“增加技术细节”,另一条建议“简化语言”),依据预设的元规则(如“转化优先 > 深度优先”)或基于收益成本模型进行裁决。
-
资源适配:根据客户画像(如“中小企业,无技术团队”),过滤或转换需要高资源投入的策略。
-
路径排序:依据“实施难度/预期收益”矩阵,对策略进行优先级排序,形成实施路线图。
4.3.2 多模态输出
人类可读报告:自动生成结构化的PDF/PPT报告,包含数据可视化图表、归因分析、具体策略清单(含示例)、实施步骤与监测建议。
机器可读指令集:提供标准化的RESTful API输出。
json
{
"task_id": "geo_opt_20260520_001",
"recommendations": [
{
"action_type": "content_enhancement",
"action": "create_and_publish_case_study",
"parameters": {
"focus": "local_sme_success",
"required_data": ["roi_increase", "implementation_timeline"],
"target_platforms": ["Doubao", "Zhihu"],
"schema_markup": "CaseStudy"
},
"priority": "P0",
"expected_impact": {"visibility_boost": 0.15}
}
]
}第五章 DSS原则的量化特征体系
系统将DSS原则操作化为一个可计算的三级金字塔特征模型,所有特征均设计为可通过算法自动提取。
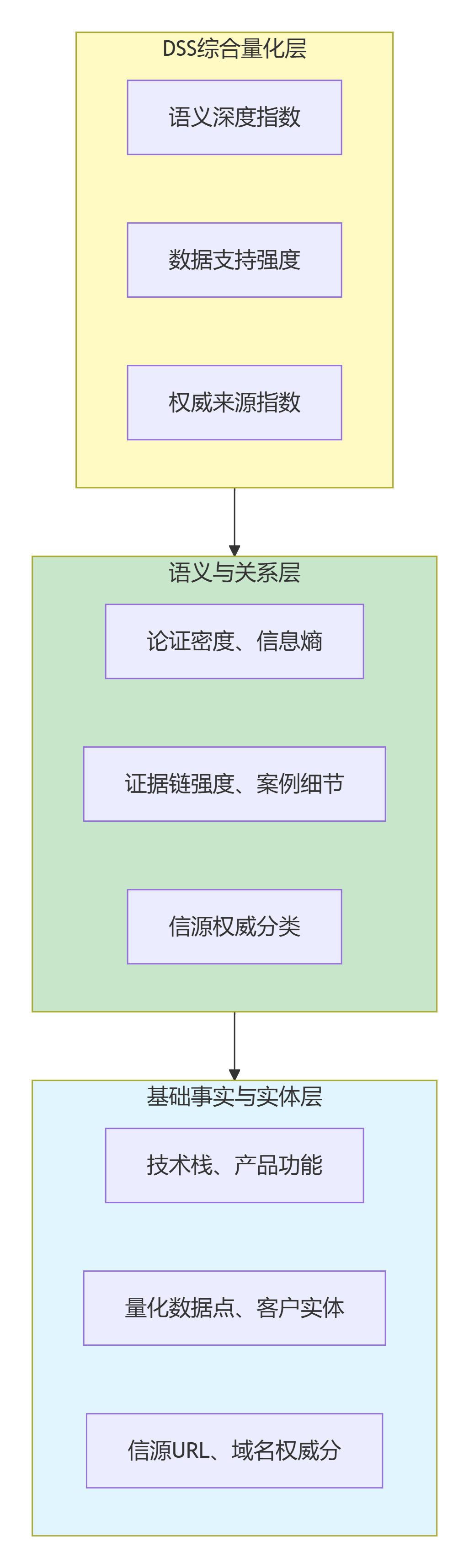
图3:DSS三级金字塔特征模型——从客观事实到综合指数,逐层抽象。
5.1 L1:基础事实与实体层
| 特征组 | 特征名 | 提取方法 |
|---|---|---|
| 技术栈 | tech_stack | 技术术语词典匹配 |
| 产品功能 | product_feature | 产品功能词典匹配 |
| 客户类型 | client_type | NER识别+行业分类表映射 |
| 量化数据点 | data_point | 正则抽取“数字+单位”模式 |
| 信源分类 | source_primary_type | 继承自数据采集系统的智能分类 |
5.2 L2:语义与关系层
| 特征名 | 计算方法 |
|---|---|
| 论证密度 | 因果连接词频次 / 总词数 |
| 信息熵 | 唯一实体数 / 总词数 |
| 证据链强度 | 数据点是否关联明确信源 |
| 案例细节等级 | 是否包含挑战、过程、量化结果 |
5.3 L3:DSS综合量化层
| 指数 | 计算公式 |
|---|---|
| 语义深度指数 | α1*论证密度 + α2*结构得分 + α3*信息熵 - α4*模糊度 |
| 数据支持强度 | β1*数据点数量 + β2*证据链强度 + β3*案例细节 + β4*信源权威性 |
| 权威来源指数 | γ1*信源类型权重 + γ2*域名权威分 + γ3*第三方背书 |
第六章 关键技术实现
6.1 SHAP全局归因
python
import lightgbm as lgb
import shap
import numpy as np
def shap_attribution_analysis(X_train, y_train, X_explain):
# 训练树模型
model = lgb.LGBMRegressor(num_leaves=31, max_depth=6, random_state=42)
model.fit(X_train, y_train)
# 创建SHAP解释器
explainer = shap.TreeExplainer(model)
shap_values = explainer.shap_values(X_explain)
# 全局重要性
global_importance = np.mean(np.abs(shap_values), axis=0)
return {
"global_importance": global_importance,
"local_contributions": shap_values,
"expected_value": explainer.expected_value
}6.2 双重机器学习因果估计
-
步骤1:用XGBoost估计倾向得分
P(T|X) -
步骤2:用XGBoost估计结果残差
Y - E[Y|X] -
步骤3:线性回归残差得到ATE估计值及置信区间
6.3 策略规则DSL示例
text
RULE R001
WHEN
$contribution_map.本地案例 > 0.2
AND $feature_map.部署模式 == "轻量化SaaS"
THEN
ADD_ACTION(
type: "CONTENT_CREATION",
params: {format: "CASE_STUDY", focus: "local_success"}
);
SET priority: "P0";
END第七章 技术指标
| 指标类型 | 目标值 |
|---|---|
| 归因准确性(与专家判断重合率) | ≥85% |
| 端到端处理效率 | 从数据到策略报告 < 30分钟 |
| 策略知识库规则数量 | 持续扩展(初始≥100条) |
| 案例库检索相似度(Top 3准确率) | ≥80% |
| 系统可用性 | ≥99.5% |
第八章 与其他系统的关系
| 系统 | 关系 |
|---|---|
| 多源智能推荐数据采集与信源分析系统 | 上游输入:推荐项-信源关联数据集、信源权重 |
| GEO知识图谱智能构建系统 | 协同:提供行业知识用于特征增强和规则匹配 |
| 语义资产库构建系统 | 下游:策略可触发内容创建工单 |
| 内容管理系统/SEO工具链 | 下游:接收策略指令流(JSON API) |
第九章 未来演进
9.1 V1.1 深度强化学习策略优化
将策略生成与执行视为序列决策过程,构建强化学习智能体,自主探索最优策略生成模式。
9.2 V1.5 跨模态归因分析
扩展至对AI生成的图像、视频推荐内容的特征提取与归因分析。
9.3 V2.0 联邦学习隐私保护归因
在保护客户数据隐私的前提下,通过联邦学习聚合多客户数据,训练更强大的全局归因模型。
结语
GEO效果归因与智能策略系统,是“1+11”全栈技术资产中的“决策大脑”。它通过两级归因分析框架打开AI推荐黑箱,通过规则-案例混合推理生成可执行策略,将GEO从依赖经验的“艺术”进化为基于数据与算法的“科学”。
当企业能够精确量化“本地案例”“技术深度”等特征对推荐排序的贡献度,并基于此制定优化策略时,GEO便不再是试错游戏,而是可规划、可衡量、可预测的工程实践。
附录A:特征体系标签全集(节选)
| 本体 | 属性 | 值示例 | 描述 |
|---|---|---|---|
| 技术属性 | 技术栈 | 知识图谱、NLP、RAG | NLP识别技术关键词 |
| 服务属性 | 客户类型 | 世界500强、中小企业 | NER识别客户名称或类型 |
| 商业属性 | 定价模式 | 透明订阅制、一次性买断 | 识别价格、订阅关键词 |
| 可信度属性 | 数据支持类型 | 第三方报告、客户证言 | 识别引用和数据来源描述 |
| DSS映射 | 权威来源等级 | 官方主站、行业媒体 | 继承自信源分类 |
| DSS映射 | 语义深度指数 | 0-1 | 综合文本长度、结构复杂度计算 |
附录B:归因计算核心参数说明
-
num_leaves, max_depth:控制树模型复杂度,过拟合会降低归因的泛化可信度
-
背景数据集:SHAP解释器的expected_value基于背景数据集计算,应选择能代表总体分布的数据子集
-
特征交互:设置
feature_perturbation="interventional"以更好地估计特征独立作用
附录C:策略输出API端点说明
| 接口 | 方法 | 说明 |
|---|---|---|
| 策略生成请求 | POST /api/v1/strategy/generate | 提交分析任务,返回request_id |
| 状态查询 | GET /api/v1/strategy/status/{request_id} | 查询异步任务状态 |
| 报告下载 | GET /api/v1/strategy/report/{request_id} | 下载PDF/PPT报告 |
| 指令集获取 | GET /api/v1/strategy/instructions/{request_id} | 获取JSON指令集 |
本文基于《GEO效果归因与智能策略系统》技术文档(V1.0)及计算机软件著作权撰写,所有技术数据均来自系统实际运行验证。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 5
5 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)