【NLP】RNN,LSTM与BiLSTM详解
目录
萌新首次在 CSDN 发文,内容是个人学习总结 + 知识梳理,纯入门科普向~理解可能存在偏差、知识点若有疏漏 / 不准确的地方,欢迎大佬评论区指正交流🙏全程原创整理,仅供零基础同学入门参考,不做专业学术定论,共同进步!
前言
NLP-AHU-093 NLP 早期主流方法为基于统计的语言模型,其中 n-gram 模型应用最为广泛,但其存在明显的局限性。例如为了构建n-gram模型,需要计算当前词对应的条件概率
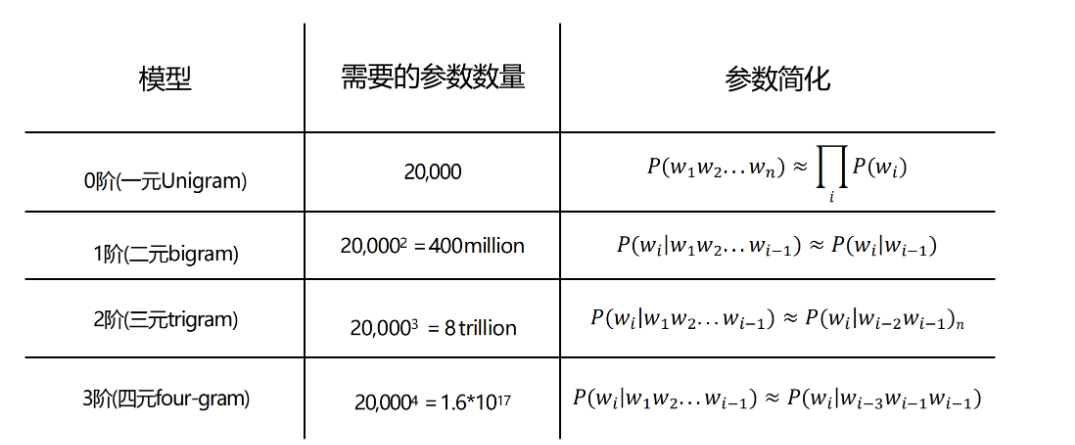
,而若要捕捉相距较远词语间的依赖关系,就需要增大 n 值,这就要求配套语料库的规模也随之扩大。与此同时,随着 n 值的增大,模型所需参数(即所有可能的词语组合对应的概率)数量及计算量会呈指数级增长,对内存与存储资源提出了极高要求,因此难以有效建模长距离上下文依赖关系。为直观理解这个参数增长的问题,我们假设词表规模为 20000 个词,下表展示了随 n 取值递增,n-gram 模型所需参数量的变化趋势:
注:上表基于词表规模为 20000 的假设(copy老师上课的ppt)
因此,当 Bengio 等人提出《A Neural Probabilistic Language Model》,首次将神经网络用于语言建模时,大家发现可通过设计更先进的神经网络模型,实现对长距离上下文依赖的有效建模,同时大幅降低计算与存储成本。本文将围绕早期深度学习在 NLP 中的三类核心模型展开介绍:循环神经网络(RNN)、长短期记忆网络(LSTM)与双向长短期记忆网络(BiLSTM)
一、循环神经网络(RNN)
1.基本思想
RNN(Recurrent Neural Network)是一种专门用于处理序列数据的神经网络。在NLP中,序列数据可以理解成文本对应的每一个单词。下面举一个NLP的例子来展现其基本思想。Nour was supposed to study with me.I called her but she did not __,我们需要预测not后面的词是什么,如果使用三元语法模型,我们首先会比较不同词的概率选择最有可能跟在did not后的词,而在典型的文本语料库里have对应的概率很高,也就是说trigram最有可能输出的是have。但是通过分析句子中的called,我们可以很容易判断模型输出的应该是answer,因此模型需要学习call才能输出合适的单词。使用n-gram的话我们需要考虑至少6个词长的序列,这显然不可行。
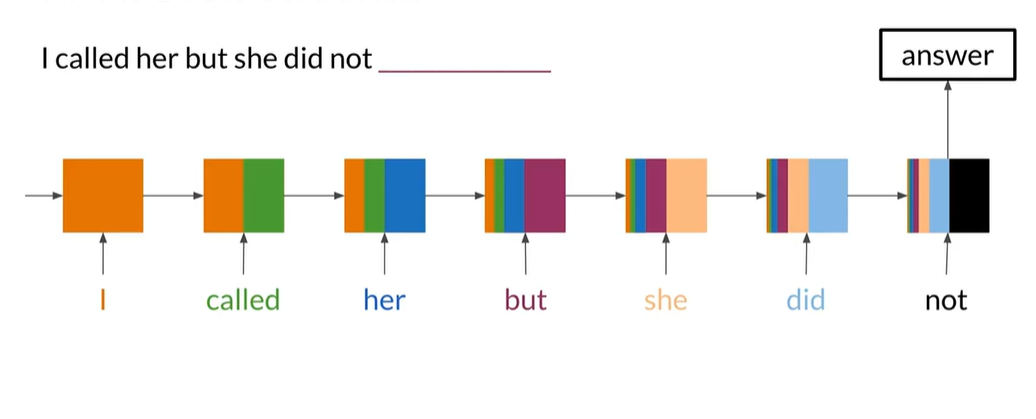
而使用RNN去做的话,就能很轻易完成这个任务。RNN并不受限于只看前n个单词,它会从句子的开头到结尾传播信息。RNN首先从句首I开始计算,然后它会传播一些计算出来的信息到下一个时间步(也就是下一步计算),取第二词called获得新值(其中橙色的表示第一个词I计算的值,绿色表示第二个单词),第二个传播的信息由橙色中的旧值与绿色中的新词计算出来的。之后,再取第三个单词her和传播过来的信息计算下一组传播的值,以此类推,到了最后一步计算,已经包含了整个句子的信息,因此RNN就能够预测出来answer这个词。
- 图中每一个框表示每一步计算,每个颜色表示每次计算的信息
出处:b站(双语字幕)吴恩达【自然语言处理(NLP)】系列课程,从入门到进阶,全程无尿点!--人工智能/NLP 7_循环神经网络
2.核心框架
上面例子的传播的信息,在RNN被称为隐状态h,隐状态h可以对序列形的数据提取特征,接着再转换为输出。我们先来看的计算,
- 圆圈或方块表示的是向量。
- 一个箭头就表示对该向量做一次变换。如上图中
和
分别有一个箭头连接,就表示对
- 这里的
一般是tanh、sigmoid、ReLU等非线性的激活函数
出处:v_JULY_v的博文《如何从RNN起步,一步一步通俗理解LSTM》
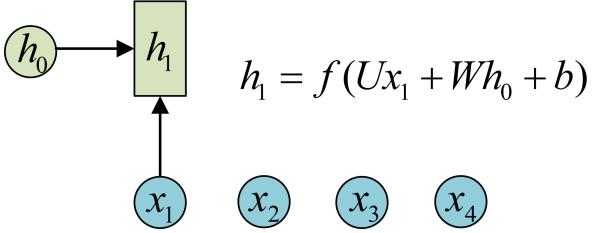
同理,与
计算类似,但是在计算时,每一步使用的参数U、W、b都是一样的,也就是说每个步骤的参数都是共享的,也就是说
,依次计算,就可以求出对应所有隐状态的值。
RNN得到输出的值是直接通过来进行计算的,对h1进行一次变换,得到输出y1
出处:v_JULY_v的博文《如何从RNN起步,一步一步通俗理解LSTM》
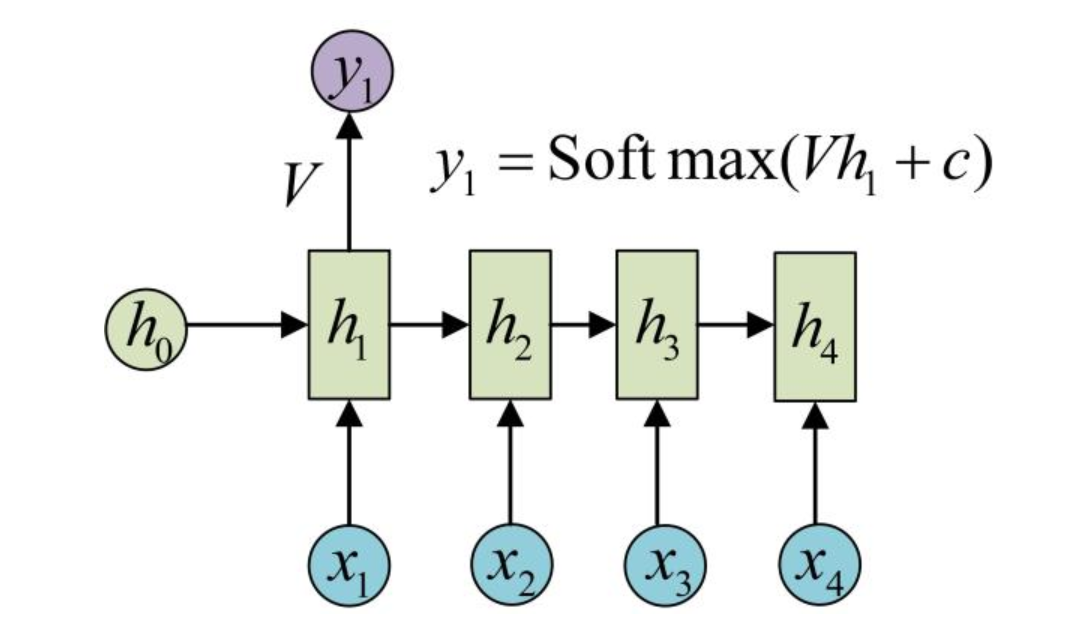
剩下的输出类似进行(使用和y1同样的参数V和c):
出处:v_JULY_v的博文《如何从RNN起步,一步一步通俗理解LSTM》
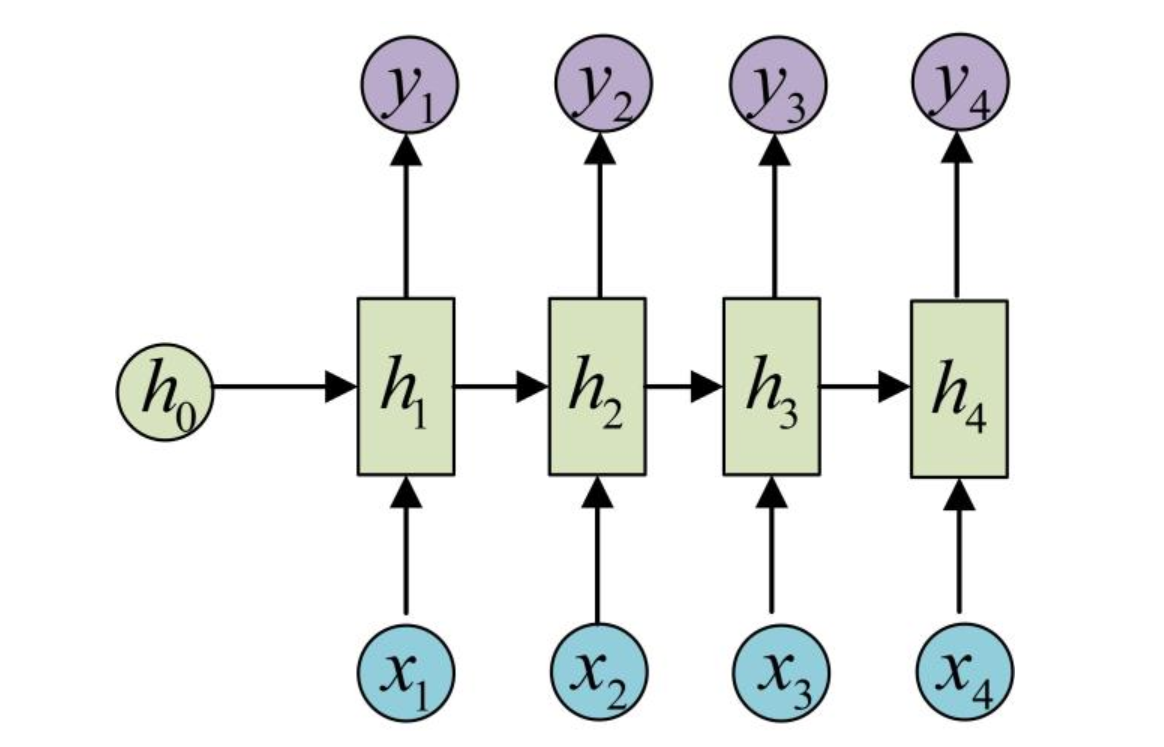
这就是最经典的RNN的模型框架。
3.RNN的局限
RNN理论上是可以将先前的信息运用在当前任务中,但实际上还存在一定的局限。接着第一小节的例子,Nour was supposed to study with me.I called her but she did not __,RNN想要预测出answer,只需要知道called这个单词即可,在这样的场景中,相关的信息和预测的词位置之间的间隔是非常小的,RNN可以学会使用先前的信息。
但在实践中,当相关信息和当前预测位置之间的间隔不断增大的时候,RNN会丧失学习到连接如此远的信息的能力。Bengio,etal.(1994)等人对该问题进行了深入的研究,他们发现一些使训练RNN变得非常困难的相当根本的原因。
在反向传播中,RNN存在梯度消失的问题。如果时序很长的话,则
,靠前的时间步对应梯度会随着时间的推移不断下降减少,而当梯度值变得非常小时,就不会继续学习。由于这些较早的层不学习,RNN会忘记它在较长序列中以前看到的内容,因此RNN只具有短时记忆。
较少情况,RNN也存在梯度爆炸问题。
二、长短期记忆网络(LSTM)
鉴于上述RNN存在的问题,Sepp Hochreiter 与 Jürgen Schmidhuber 于 1997 年共同提出LSTM,他们引入了细胞状态cell以及门控机制,在一定程度上解决梯度消失和梯度爆炸这两个问题。核心思想就是,因记忆能力有限,记住重要的,忘记无关紧要的。就像我们平常阅读一篇文章,但你不会记住所有内容,只会记住比较核心的内容。实际上,Long ShortTerm 网络就是一种RNN特殊的类型。
1.主要框架
所有RNN都具有一种重复神经网络模块的链式的形式。在标准的RNN中,这个重复的模块只有一个非常简单的结构——隐含层,比如tanh层。LSTM同样是这样的结构,但是重复的模块拥有一个不同的结构,包含四个交互的层,三个Sigmoid 和一个tanh层,并以一种非常特殊的方式进行交互。
- 上图中,σ表示的Sigmoid 激活函数,有助于更新或忘记信息,如果输出是0则与cell相乘即为0,说明我们需要忘记这部分信息;如果输出是1,说明我们需要保留这部分信息并及时更新
- 对于图中使用的各种元素的图标中,每一条黑线传输着一整个向量,从一个节点的输出到其他节点的输入。粉色的圈代表pointwise的操作,诸如向量的和,而黄色的矩形就是学习到的神经网络层。合在一起的线表示向量的连接,分开的线表示内容被复制,然后分发到不同的位置。
出处:v_JULY_v的博文《如何从RNN起步,一步一步通俗理解LSTM》
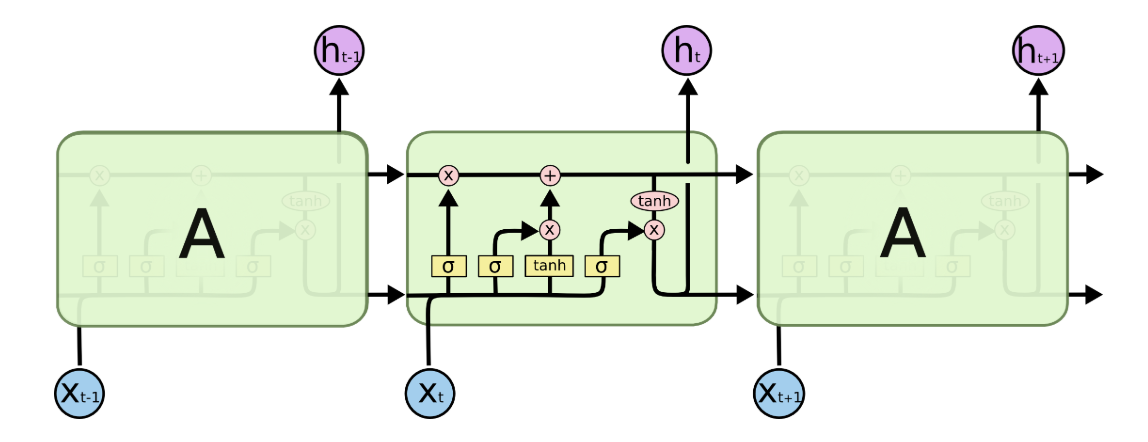
2.核心框架
2.1 忘记门
由于LSTM核心思想就是忘记不重要的,所以我们首先第一步就是要筛选信息,将不重要的信息剔除,这个功能由一个称为“忘记门”的结构完成。它会读取上一个输出和当前输入
,做一个Sigmoid 的非线性映射,然后输出一个向量
 (1表示完全保留,0表示完全舍弃),最后与cell相乘,将cell中不重要的信息丢弃。
(1表示完全保留,0表示完全舍弃),最后与cell相乘,将cell中不重要的信息丢弃。
- 注意:此处
对于
和
并不是共享的,也就是说它们对应的权值是不同的,将式子再展开来就是
出处:v_JULY_v的博文《如何从RNN起步,一步一步通俗理解LSTM》
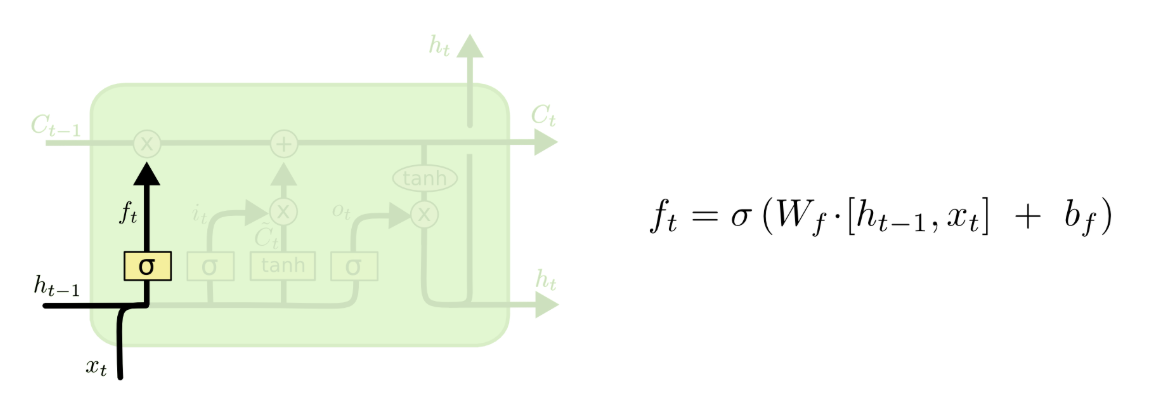
2.2 输入门
下一步就是确定什么信息需要更新,由输入门这个结构完成。更新这个操作一般分为两步,第一步就是sigmoid层(称“输入门层”)决定什么值我们将要更新;第二步就是,一个tanh层创建一个新的候选值向量,会被加入到cell状态中
- 为便于理解图中右侧的两个公式,我们展开下计算过程,即
、
出处:v_JULY_v的博文《如何从RNN起步,一步一步通俗理解LSTM》
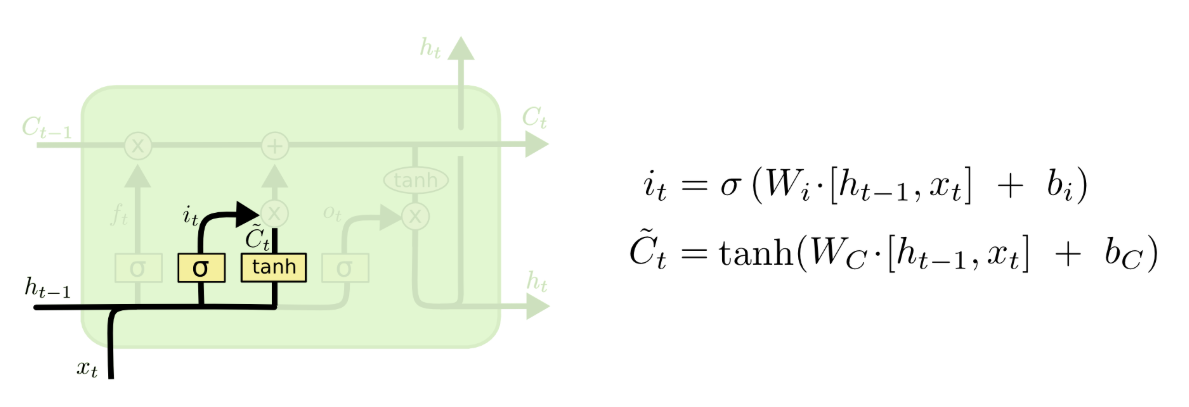

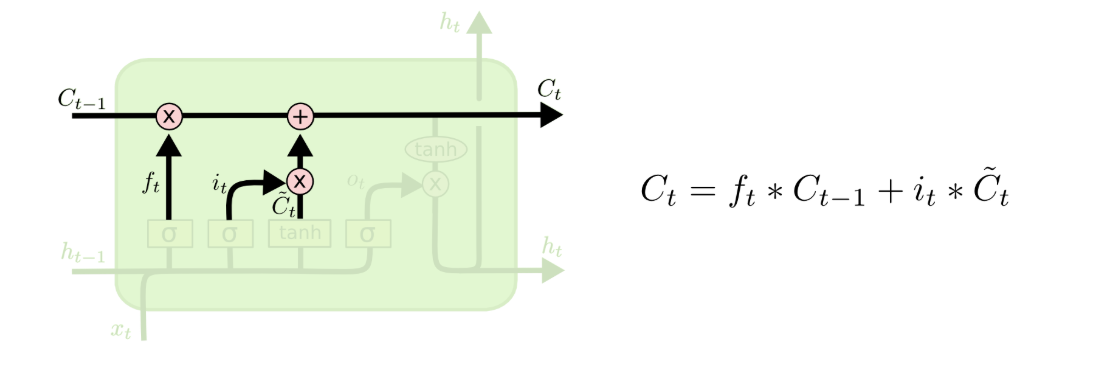
2.3 细胞状态cell
然后就是需要我们更新旧细胞状态,更新为
。前面的步骤已经决定了将会做什么,我们现在就是实际去完成。旧状态与
相乘,丢弃掉我们确定需要丢弃的信息,接着加上
。这就是新的候选值,根据我们决定更新每个状态的程度进行变化。
出处:v_JULY_v的博文《如何从RNN起步,一步一步通俗理解LSTM》
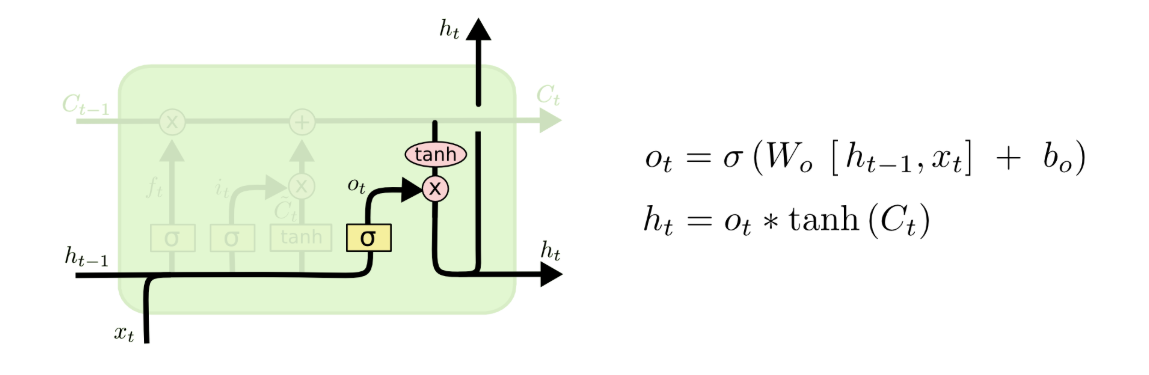
2.4 输出门
最后,我们需要输出处理好的隐状态。运行一个sigmoid层来确定细胞状态的哪个部分将输出出去并输出多大的强度,把细胞状态通过tanh进行处理并将它和sigmoid门的输出相乘,最终输出我们确定输出的那部分。
出处:v_JULY_v的博文《如何从RNN起步,一步一步通俗理解LSTM》
三、双向长短期记忆网络(BiLSTM)
1.基本思想
普通的LSTM只能记住前文信息,而对于需要同时考虑上文与下文的任务,这显然还不够,因此BiLSTM应运而生。它是在LSTM基础上构建的,在每个时间步上同时运行两个 LSTM,一个按照序列的正向顺序处理数据,另一个按照反向顺序处理数据。
2.核心框架
出处: 池央的博文《深度学习模型:BiLSTM (Bidirectional LSTM) - 双向长短时记忆网络详解》
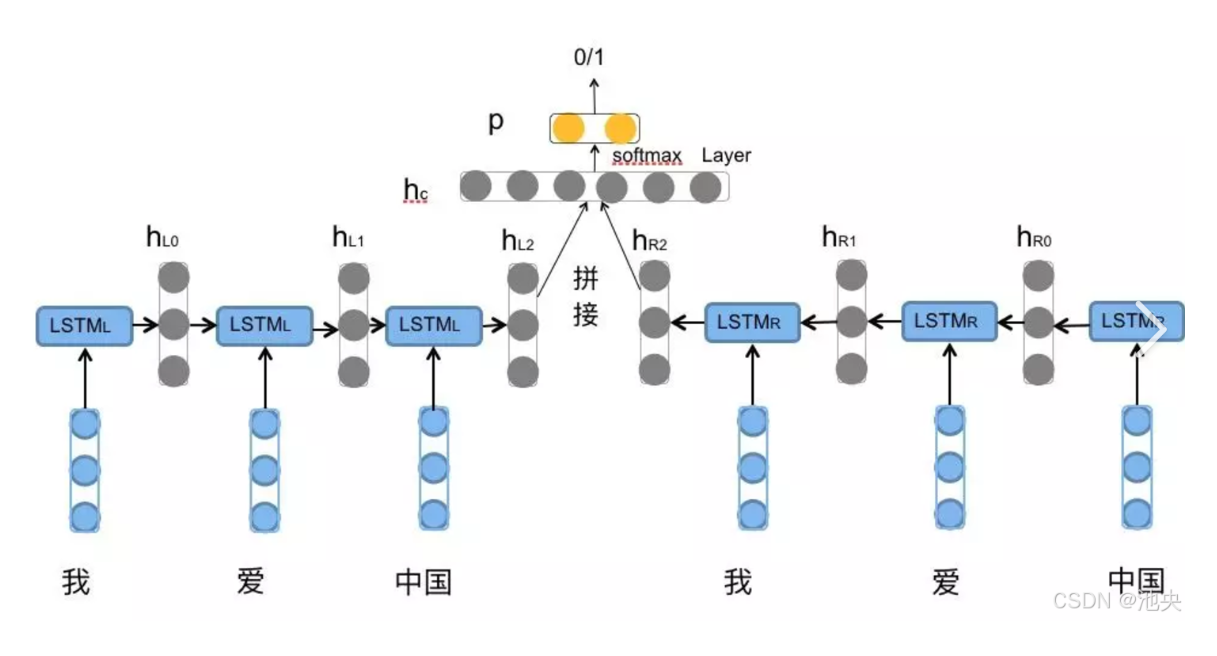
对于一个输入序列,正向 LSTM 从x1开始依次处理到 xt,得到一系列正向隐状态
。反向 LSTM 则从xt开始依次处理到x1,得到一系列反向隐状态
在每个时间步 ,BiLSTM 将正向隐状态和反向隐状态 进行拼接或其他融合操作,得到该时间步的最终隐状态表示 。
参考文献
1.v_JULY_v的博文《如何从RNN起步,一步一步通俗理解LSTM》
2.池央的博文《深度学习模型:BiLSTM (Bidirectional LSTM) - 双向长短时记忆网络详解》
3.b站(双语字幕)吴恩达【自然语言处理(NLP)】系列课程,从入门到进阶,全程无尿点!--人工智能/NLP
总结
本文围绕早期深度学习在 NLP 中的三类核心模型展开介绍:循环神经网络(RNN)、长短期记忆网络(LSTM)与双向长短期记忆网络(BiLSTM)
个人认为大佬 v_JULY_v 的经典博文《如何从 RNN 起步,一步一步通俗理解 LSTM》对 LSTM 的讲解深入浅出、非常易懂。本文仅做核心知识点的精简梳理与归纳,想吃透完整细节的小伙伴,强烈推荐去阅读原文深度学习~

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 19
19 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)