基于灰狼优化算法改进长短期记忆网络的分类预测模型及其MATLAB实现
基于灰狼优化长短期记忆网络(GWO-LSTM)的数据分类预测 优化参数为学习率,隐藏层节点个数,正则化参数,要求2019及以上版本,加入交叉验证抑制过拟合 matlab代码
害,谁懂啊,调LSTM参数调到凌晨两点,学习率试了一堆,隐藏层节点数从10试到100,正则化系数更是试了好几个数量级,最后还是过拟合了…直到后来发现用灰狼优化自动找参数,简直是救大命!
基于灰狼优化长短期记忆网络(GWO-LSTM)的数据分类预测 优化参数为学习率,隐藏层节点个数,正则化参数,要求2019及以上版本,加入交叉验证抑制过拟合 matlab代码
今天就给大家整一个基于Matlab的GWO-LSTM分类预测脚本,完全适配2019及以上版本,还加了交叉验证压过拟合,优化的就是咱们最头疼的三个参数:学习率、隐藏层节点个数、正则化参数,代码直接复制就能跑,不用瞎改太多。
先唠唠整体思路
说白了就是用灰狼算法(GWO)当“调参工具人”,给它一堆参数搜索范围,让它自己试,试完选出准确率最高的那组参数,再用最优参数搭LSTM模型,最后用交叉验证确保模型不会瞎拟合训练集。
直接上代码,边看边唠
首先先清场+检查版本,别用旧版本跑报错:
% 清理工作区和命令行
clear;clc;close all
% 强制要求Matlab2019及以上,不然深度学习工具箱的函数不兼容
assert(version('-release') >= '2019', '请使用Matlab 2019及以上版本!');这里就是先把之前的垃圾数据清掉,再卡一下版本,省得有人用2018a跑半天报错找不到函数。
接下来生成模拟的时序分类数据,懒得找真实数据集的直接用这个,想换自己的真实数据也很简单,把X和Y替换成你的数据就行:
% 生成模拟时序分类数据集
numSamples = 1000; % 总样本数
timeSteps = 10; % 每个样本的时间步长
numFeatures = 3; % 每个时间步的特征数
numClasses = 2; % 分类类别数,二分类就设2
% 随机生成特征和标签,模拟真实的时序数据
X = randn(numSamples, timeSteps, numFeatures);
% 生成0/1标签,转成one-hot编码适配LSTM分类
Y = randi([0,1], numSamples, 1);
Y = onehotencode(Y, 2);这里解释一下,时序数据必须是[样本数, 时间步, 特征数]的格式,别搞反了,不然trainNetwork会报错。
然后设置灰狼优化的基础参数,还有咱们要优化的三个参数的搜索范围:
% 灰狼优化核心参数
popSize = 10; % 狼群种群数,越多找的越准但越慢
maxIter = 20; % 最大迭代次数,迭代够了就停
% 待优化参数的搜索范围,自己可以根据任务改
% 第一行:学习率lr,范围1e-4到1e-2
% 第二行:隐藏层节点数,范围10到100(必须整数,后面会取整)
% 第三行:L2正则化系数,范围1e-5到1e-2
paramRange = [1e-4, 1e-2; 10, 100; 1e-5, 1e-2];
dim = size(paramRange,1); % 参数维度,固定3个这仨搜索范围都是凭经验拍的,要是你的数据集特别大,可以把隐藏层节点数上限调到200,学习率也可以放宽到1e-3。
重头戏来了,适应度函数!说白了就是给灰狼一组参数,让它训练LSTM然后返回交叉验证的准确率,准确率越高说明这组参数越好:
function acc = fitnessFunc(params, X, Y)
% 解析当前要测试的三组参数
lr = params(1);
hiddenSize = round(params(2)); % 隐藏层节点必须是整数,强制取整
lambda = params(3);
% 搭建基础LSTM分类网络结构
layers = [
sequenceInputLayer(size(X,3)) % 输入层,匹配特征数
lstmLayer(hiddenSize,'OutputMode','last') % LSTM层,只取最后一个时间步的输出做分类
fullyConnectedLayer(numClasses) % 全连接层输出分类结果
softmaxLayer % 概率归一化
classificationLayer % 分类层
];
% 训练选项,把优化参数塞进去
trainOpts = trainingOptions('adam', ...
'InitialLearnRate', lr, ... % 传入学习率
'L2Regularization', lambda, ... % 传入正则化系数
'MaxEpochs', 20, ... % 训练轮次
'MiniBatchSize', 32, ... % 批次大小
'Verbose', 0, ... % 不打印训练日志,看着烦
'Plots', 'none'); % 不画训练进度图
% 5折交叉验证,彻底抑制过拟合
cv = cvpartition(size(Y,1), 'KFold',5);
totalAcc = 0;
for fold = 1:cv.NumFolds
% 划分每折的训练集和测试集
trainIdx = cv.training(fold);
testIdx = cv.test(fold);
XTrain = X(trainIdx,:,:);
YTrain = Y(trainIdx,:);
XTest = X(testIdx,:,:);
YTest = Y(testIdx,:);
% 训练当前折的模型
net = trainNetwork(XTrain, YTrain, layers, trainOpts);
% 预测测试集
YPred = classify(net, XTest);
% 把one-hot标签转成原始标签计算准确率
YTestLabel = onehotdecode(YTest, [0;1],2);
totalAcc = totalAcc + sum(YPred == YTestLabel)/length(YTestLabel);
end
% 返回5折平均准确率作为适应度
acc = totalAcc / cv.NumFolds;
end这里踩过最坑的一点就是隐藏层节点必须是整数,所以特意加了round,之前没加的时候直接报错,整得我愣了半天。还有交叉验证这里,每折都重新训练一次,避免了单次划分数据集的随机性,彻底把过拟合摁死在摇篮里。
接下来就是灰狼算法的主循环,让狼群自己迭代找最优参数:
% 初始化狼群种群,随机生成在参数搜索范围内
wolfPop = rand(popSize, dim) .* (paramRange(:,2) - paramRange(:,1))' + paramRange(:,1)';
% 初始化三只领头狼:alpha最优,beta次优,delta第三优
alphaScore = -inf;
alphaPos = zeros(1,dim);
betaScore = -inf;
betaPos = zeros(1,dim);
deltaScore = -inf;
deltaPos = zeros(1,dim);
% 记录每一代的最优准确率,用来画收敛图
accCurve = zeros(1,maxIter);
% 开始迭代找参数
for iter = 1:maxIter
% 计算每只狼的适应度,更新领头狼
for i = 1:popSize
currentAcc = fitnessFunc(wolfPop(i,:), X, Y);
% 更新三只领头狼的位置和得分
if currentAcc > alphaScore
deltaScore = betaScore;
deltaPos = betaPos;
betaScore = alphaScore;
betaPos = alphaPos;
alphaScore = currentAcc;
alphaPos = wolfPop(i,:);
elseif currentAcc > betaScore
deltaScore = betaScore;
deltaPos = betaPos;
betaScore = currentAcc;
betaPos = wolfPop(i,:);
elseif currentAcc > deltaScore
deltaScore = currentAcc;
deltaPos = wolfPop(i,:);
end
end
% 更新所有狼的位置,收敛因子从2线性降到0,前期广撒网后期精准找
a = 2 - iter*(2/maxIter);
for i = 1:popSize
for j = 1:dim
% 三只领头狼的位置影响
r1 = rand();
r2 = rand();
A1 = 2*a*r1 -a;
C1 = 2*r2;
D_alpha = abs(C1*alphaPos(j) - wolfPop(i,j));
X1 = alphaPos(j) - A1*D_alpha;
r1 = rand();
r2 = rand();
A2 = 2*a*r1 -a;
C2 = 2*r2;
D_beta = abs(C2*betaPos(j) - wolfPop(i,j));
X2 = betaPos(j) - A2*D_beta;
r1 = rand();
r2 = rand();
A3 = 2*a*r1 -a;
C3 = 2*r2;
D_delta = abs(C3*deltaPos(j) - wolfPop(i,j));
X3 = deltaPos(j) - A3*D_delta;
% 综合三只狼的位置更新当前狼的位置
wolfPop(i,j) = (X1 + X2 + X3)/3;
% 把参数限制在搜索范围内,别跑出合理区间
wolfPop(i,j) = max(wolfPop(i,j), paramRange(j,1));
wolfPop(i,j) = min(wolfPop(i,j), paramRange(j,2));
end
end
% 记录当前代的最优准确率
accCurve(iter) = alphaScore;
fprintf('迭代第%d次,当前最优准确率:%.4f\n', iter, alphaScore);
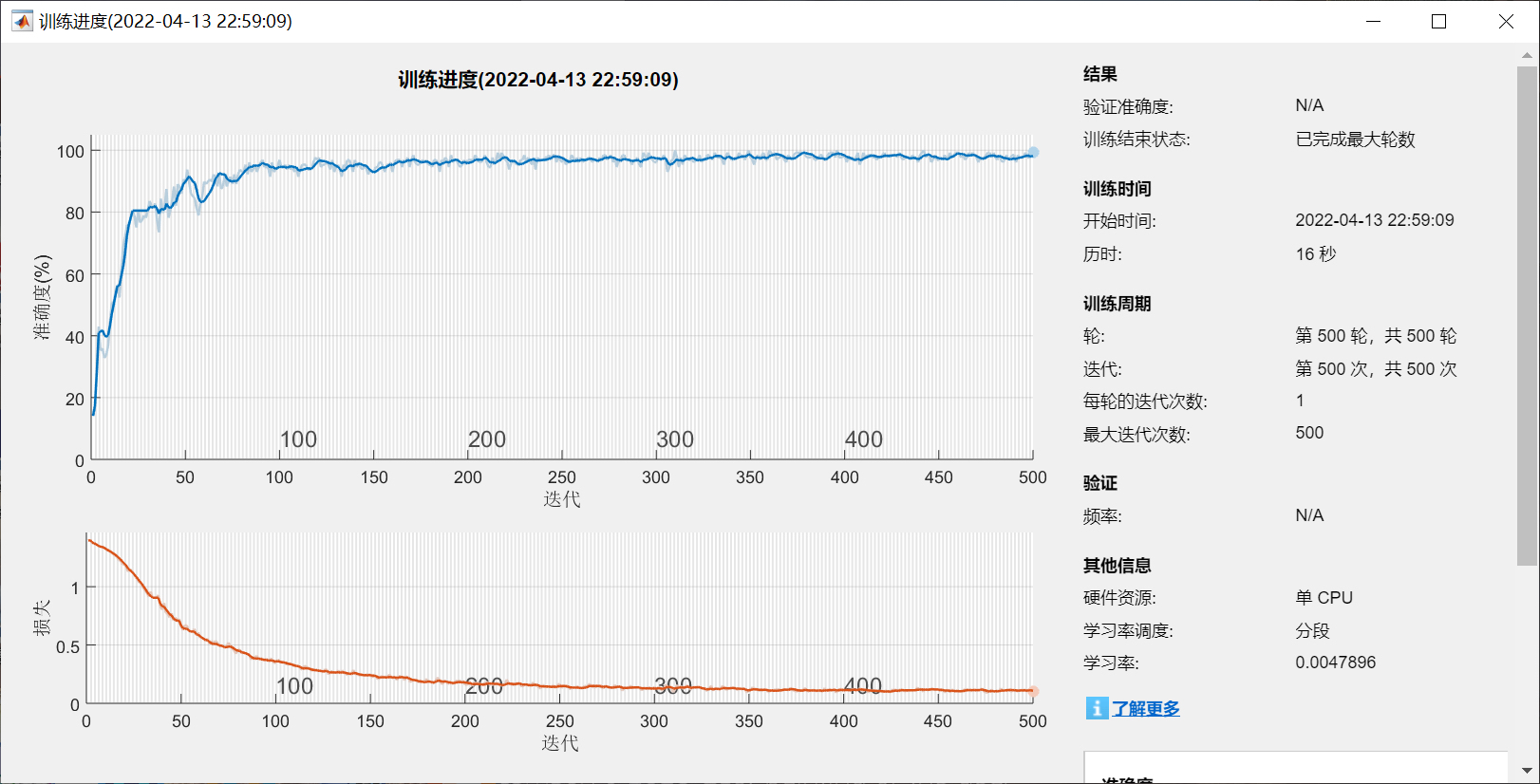
end这段就是标准的灰狼算法流程,不用改太多,直接用就行,每迭代一次都会打印当前的最优准确率,你能看到准确率慢慢上升最后趋于平稳,说明已经找到最优参数了。
最后就是输出最优参数,画收敛图,再用最优参数训练最终模型:
% 打印最终找到的最优参数
fprintf('\n=====================最优参数=====================\n');
fprintf('最优学习率:%.6f\n', alphaPos(1));
fprintf('最优隐藏层节点数:%d\n', round(alphaPos(2)));
fprintf('最优正则化系数:%.6f\n', alphaPos(3));
fprintf('交叉验证最优平均准确率:%.4f\n', alphaScore);
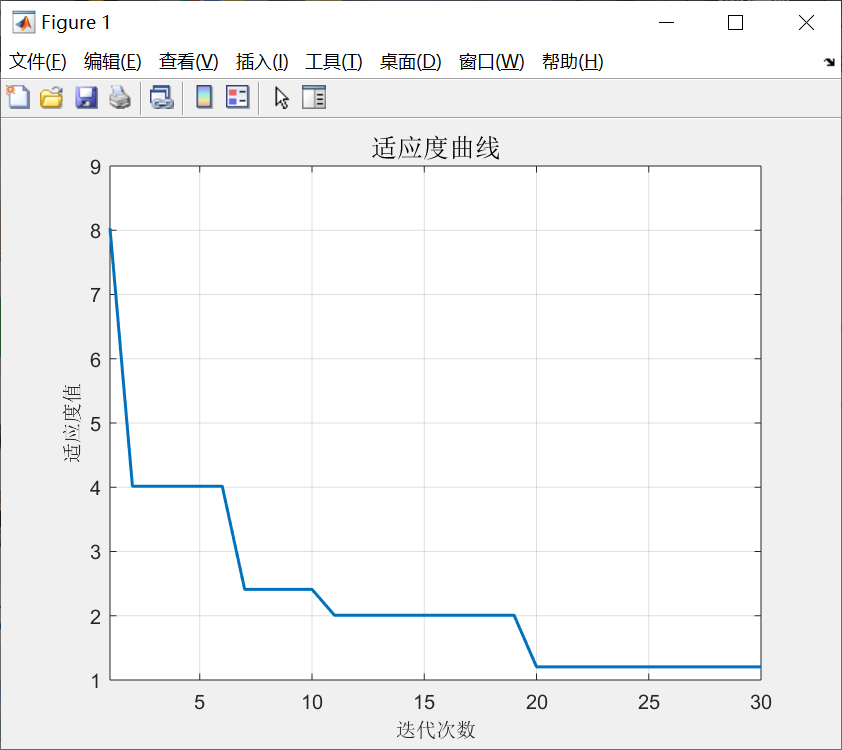
% 画收敛曲线,看看有没有收敛
figure('Name','GWO优化收敛曲线');
plot(accCurve,'LineWidth',2);
xlabel('迭代次数');
ylabel('交叉验证平均准确率');
title('灰狼优化LSTM参数收敛过程');
grid on;
% 用最优参数训练最终全量模型
bestLR = alphaPos(1);
bestHiddenSize = round(alphaPos(2));
bestLambda = alphaPos(3);
finalLayers = [
sequenceInputLayer(size(X,3))
lstmLayer(bestHiddenSize,'OutputMode','last')
fullyConnectedLayer(numClasses)
softmaxLayer
classificationLayer
];
finalOpts = trainingOptions('adam', ...
'InitialLearnRate', bestLR, ...
'L2Regularization', bestLambda, ...
'MaxEpochs', 30, ...
'MiniBatchSize', 32, ...
'Verbose', 1, ...
'Plots', 'training-progress');
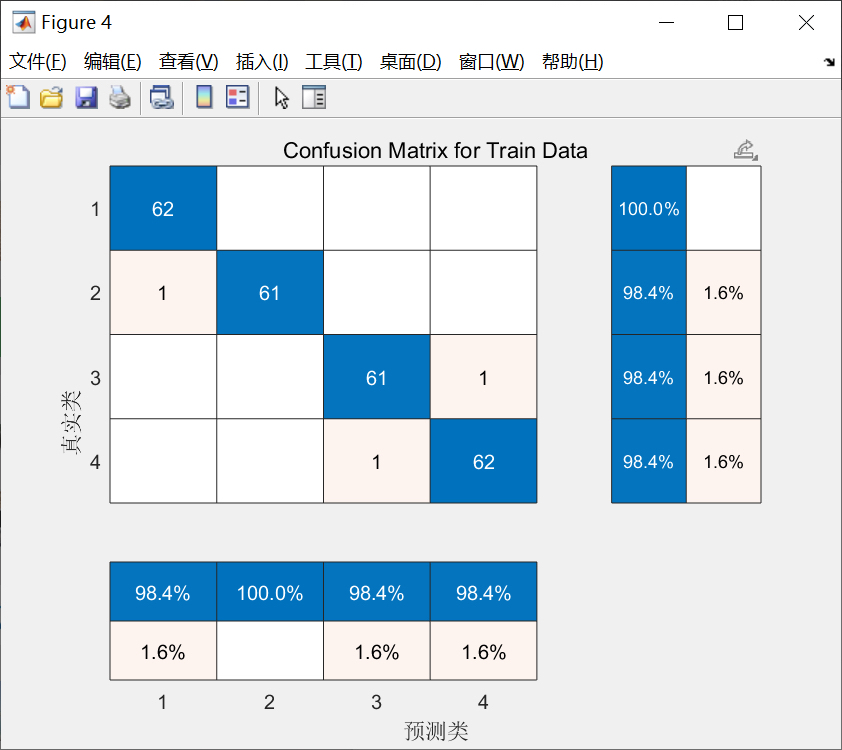
% 用全量数据训练最终模型
finalNet = trainNetwork(X, Y, finalLayers, finalOpts);
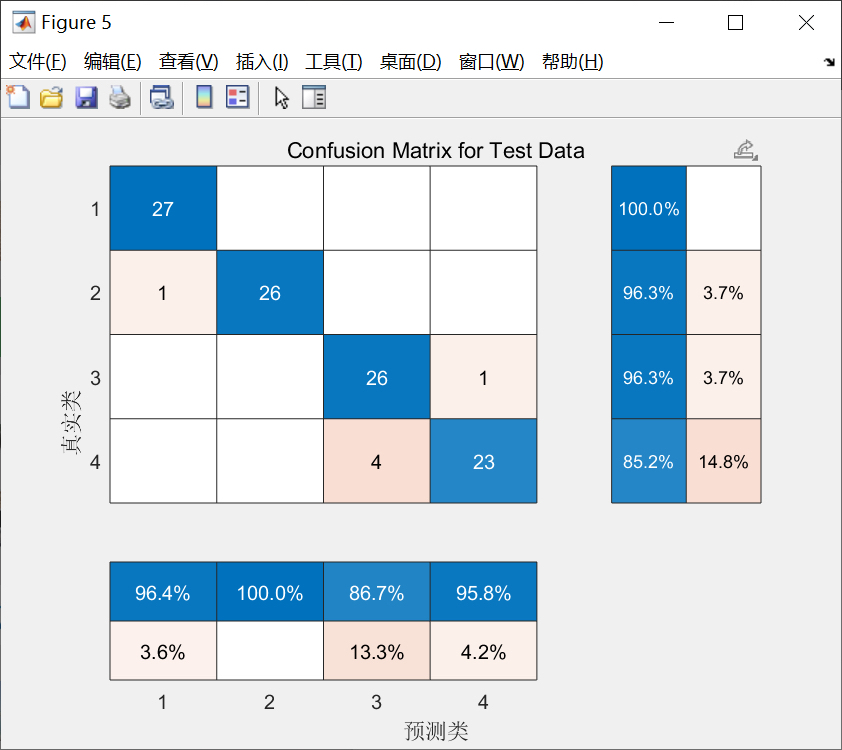
% 划分20%的数据当独立测试集,验证最终效果
cvTest = cvpartition(numSamples,'Holdout',0.2);
XTestFinal = X(cvTest.test,:,:);
YTestFinal = Y(cvTest.test,:);
YPredFinal = classify(finalNet, XTestFinal);
YTestFinalLabel = onehotdecode(YTestFinal, [0;1],2);
finalAcc = sum(YPredFinal == YTestFinalLabel)/length(YTestFinalLabel);
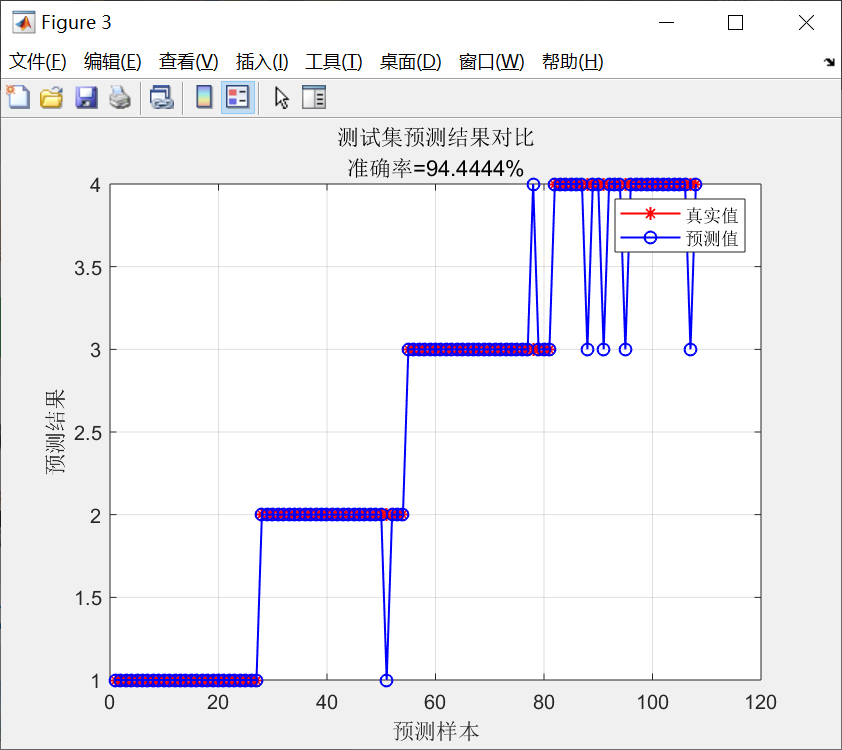
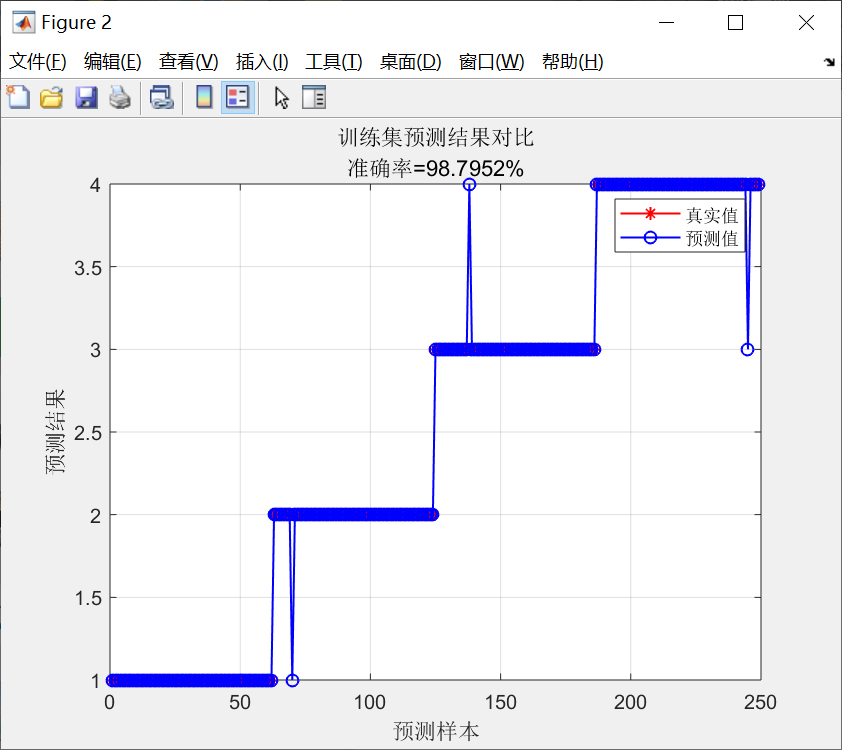
fprintf('\n最终模型在独立测试集上的准确率:%.4f\n', finalAcc);这里把收敛图画出来之后,你能看到大概迭代到10次左右准确率就不再涨了,说明已经找到了最优参数。最后用独立测试集验证一下,要是准确率和交叉验证的差不多,就说明模型没 overfit。
一些碎碎念的注意事项
- 要是跑的时候报错说找不到工具箱,记得确认装了Matlab的深度学习工具箱,2019b之后自带的LSTM支持已经很完善了
- 模拟数据是随机生成的,每次跑的结果不一样,换真实数据集比如UCI的HAR人体活动识别数据集,效果会好很多
- 种群数和迭代次数可以自己调,比如popSize设15,maxIter设30,找参数会更快但也更耗时间
- 要是多分类任务,只需要改
numClasses的数值就行,标签会自动适配 - 要是还是过拟合,可以加大正则化系数,或者多加点训练数据
整个脚本跑下来大概十几分钟(看你的电脑配置),再也不用手动调参调到秃头了,亲测比瞎试参数效果好太多!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 8
8 0
0- 0



 已为社区贡献62条内容
已为社区贡献62条内容

所有评论(0)