《VLA 系列》复现 π0.5 | 数据采集 | 模型微调 | DROID
本文介绍基于DROID采集数据,来微调π0.5模型,整个过程分为三个环节:
- 数据采集 —— 参照DROID硬件平台搭建机器人系统,通过遥操作采集多视角视频、机器人状态与语言指令,为训练打下基础。
- 格式转换 —— 将DROID格式数据转换为LeRobot标准格式,让数据顺利进入训练流程。
- 模型微调 —— 基于π0.5-DROID预训练权重进行微调,重点优化策略头部分,使模型更好地适应具体任务。
整个过程涉及数据采集、格式转换和模型训练三个关键环节,为机器人操作任务提供了端到端的参考。

数据示例:
1、采集数据
我们可以参考DROID,自定义采集机器人的操作数据
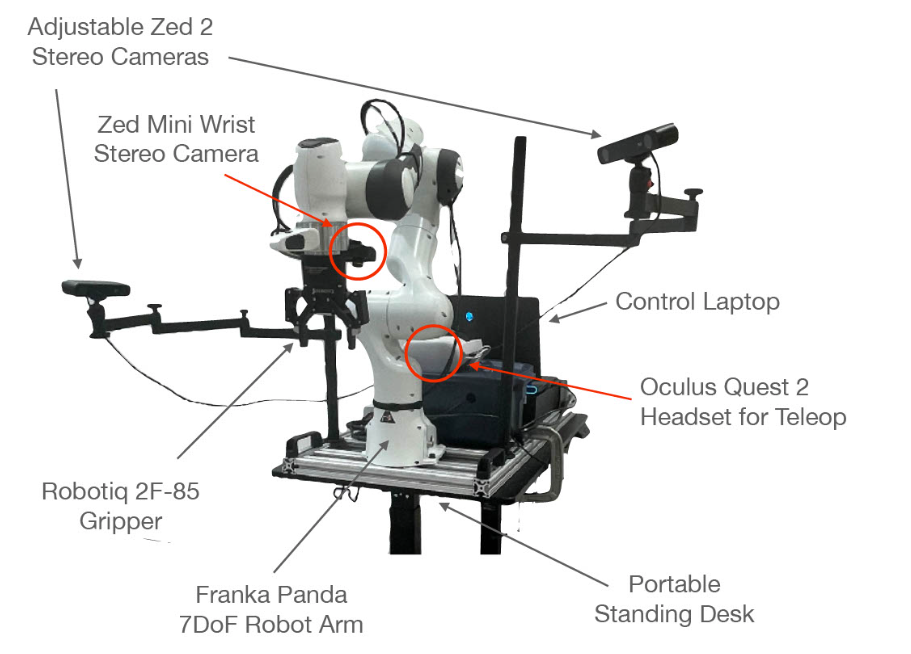
采购硬件设备、组装设备参考:https://droid-dataset.github.io/droid/docs/hardware-setup
| 组件 | 规格 |
|---|---|
| 机械臂 | Franka Emika Panda 7DoF |
| 夹爪 | Robotiq 2F-85 |
| 外部相机 | 2× ZED 2 立体相机(可调三脚架) |
| 腕部相机 | ZED-Mini 立体相机 |
| 遥操作设备 | Meta Quest 2 头显+手柄 |
| 控制器 | Polymetis(15Hz 控制频率) |
| 计算设备 | NUC(Polymetis 服务器)+ Alienware 笔记本(数据收集 GUI) |
硬件平台,如下图所示:
然后推荐在docker安装开发环境:https://droid-dataset.github.io/droid/software-setup/docker.html
遥操采集数据:https://droid-dataset.github.io/droid/example-workflows/teleoperation.html
在主机或通过 Docker 设置好DROID软件,使用 Oculus Quest 2 远程操控,来采集机械臂的操作数据。
数据采集流程:
-
场景设置:移动机器人到新场景,调整相机视角
-
相机标定:使用棋盘格和 OpenCV 进行外参标定
-
任务输入:在 GUI 中输入场景内所有可能的任务(支持选择或自由输入)
-
自动采样:GUI 随机抽取任务指令,确保任务覆盖度
-
场景增强:定期提示执行场景变化(移动底座、调整相机、改变光照、增减物品)
-
数据采集:以 15Hz 频率记录以下数据 :
采集到的数据内容:
观测数据:
3 路立体 RGB 相机流(1280×720)
机器人关节位置和速度(7D)
末端执行器位姿和速度(6D)
夹爪位置和速度(1D)
动作数据(多种动作空间):
关节空间:关节位置/速度指令
笛卡尔空间:末端位姿/速度指令 + 夹爪控制
元数据:
1-3 条自然语言指令(众包标注)
相机外参矩阵、建筑名称、采集者 ID
场景类型(GPT-4V 分类)
成功/失败标记
采集的原始数据以 HDF5 格式存储 ,每个episode 包含:
episode/
├── metadata_*.json # 场景、采集者等元数据
├── trajectory.h5 # 低维数据(动作、本体感知)
└── recordings/
├── MP4/ # 高清视频(左目/立体)
└── SVO/ # ZED 原始 SVO 文件2、下载示例数据
如果上面没有采购到硬件设备,没关系,先用示例数据进行模型微调,走通流程
openpi的环境搭建,参考我上一篇博客:《VLA 系列》复现 π0.5、π0-FAST、π0 | 环境搭建 | 模型推理
进行入openpi代码目录中,新建一个droid_examples_1_0_1文件夹,用于存放数据(1.6 GiB左右)
使用gsutil 下载示例数据:
gsutil -m cp -r gs://gresearch/robotics/droid_raw/1.0.1/IRIS/success/2023-12-04 droid_examples_1_0_1
运行信息:
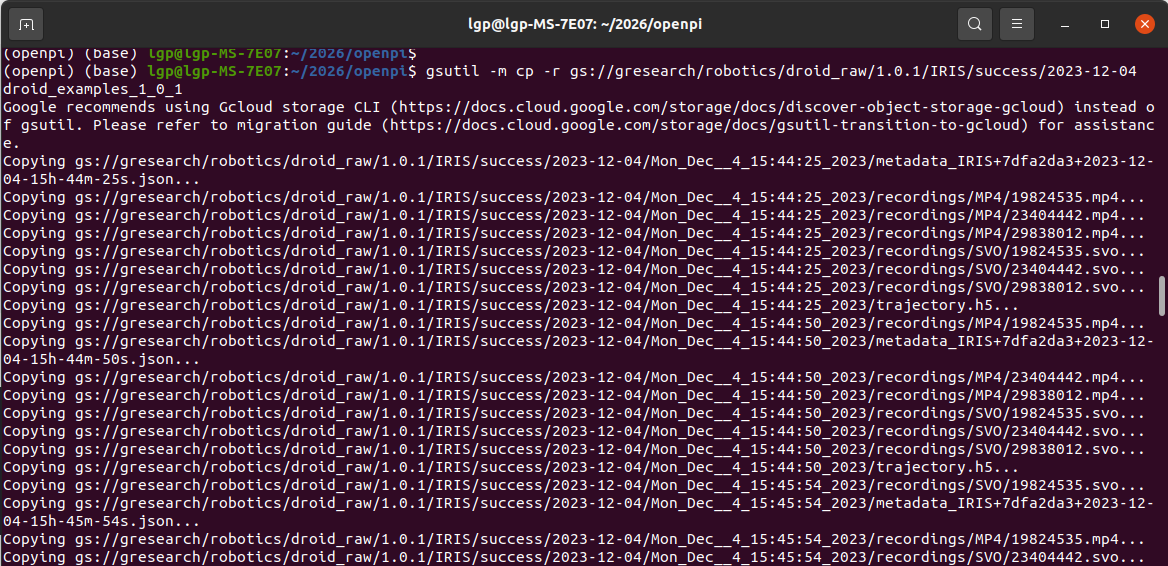
等待下载完成:
Copying gs://gresearch/robotics/droid_raw/1.0.1/IRIS/success/2023-12-04/Mon_Dec__4_16:18:46_2023/recordings/MP4/19824535.mp4...
Copying gs://gresearch/robotics/droid_raw/1.0.1/IRIS/success/2023-12-04/Mon_Dec__4_16:18:46_2023/recordings/MP4/23404442.mp4...
Copying gs://gresearch/robotics/droid_raw/1.0.1/IRIS/success/2023-12-04/Mon_Dec__4_16:18:46_2023/recordings/MP4/29838012.mp4...
Copying gs://gresearch/robotics/droid_raw/1.0.1/IRIS/success/2023-12-04/Mon_Dec__4_16:18:46_2023/recordings/SVO/19824535.svo...
Copying gs://gresearch/robotics/droid_raw/1.0.1/IRIS/success/2023-12-04/Mon_Dec__4_16:18:46_2023/recordings/SVO/23404442.svo...
Copying gs://gresearch/robotics/droid_raw/1.0.1/IRIS/success/2023-12-04/Mon_Dec__4_16:18:46_2023/recordings/SVO/29838012.svo...
Copying gs://gresearch/robotics/droid_raw/1.0.1/IRIS/success/2023-12-04/Mon_Dec__4_16:18:46_2023/trajectory.h5...
| [240/240 files][ 1.6 GiB/ 1.6 GiB] 100% Done 29.8 KiB/s ETA 00:00:00
Operation completed over 240 objects/1.6 GiB.
然后下载上面视频对应的“操作任务-语言指令”
gsutil -m cp -r gs://gresearch/robotics/droid_raw/1.0.1/aggregated-annotations-030724.json droid_examples_1_0_1
打印信息:
Google recommends using Gcloud storage CLI (https://docs.cloud.google.com/storage/docs/discover-object-storage-gcloud) instead of gsutil. Please refer to migration guide (https://docs.cloud.google.com/storage/docs/gsutil-transition-to-gcloud) for assistance.
Copying gs://gresearch/robotics/droid_raw/1.0.1/aggregated-annotations-030724.json...
\ [1/1 files][ 11.5 MiB/ 11.5 MiB] 100% Done
Operation completed over 1 objects/11.5 MiB.
能看到目录结构:
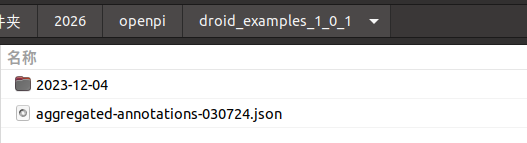
数据目录内容:
droid_examples_1_0_1/
├── aggregated-annotations-030724.json # 操作任务-语言指令 标注文件
└── <dataset_name>/
├── recordings/
│ └── MP4/
│ ├── <camera_id>.mp4 # 相机视频文件(三个相机)
│ └── ...│ └── SVO/ # ZED 原始 SVO 文件
├── trajectory.h5 # 轨迹数据(HDF5格式)
└── metadata_<episode_id>.json # 元数据文件
mp4示例数据:
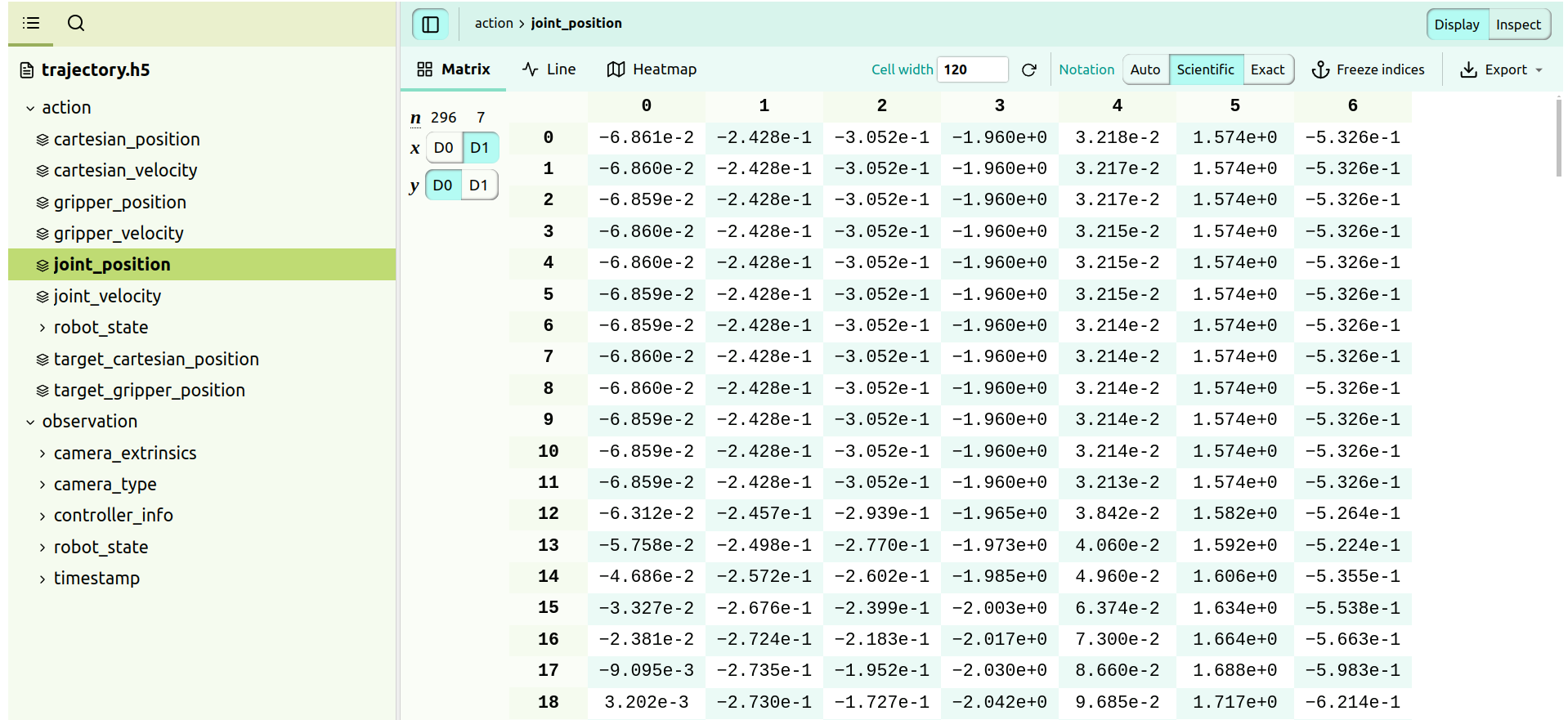
重点看一下trajectory.h5 的轨迹数据,可以在VScode安装一个“H5Web”插件,很好可视化.h5的数据
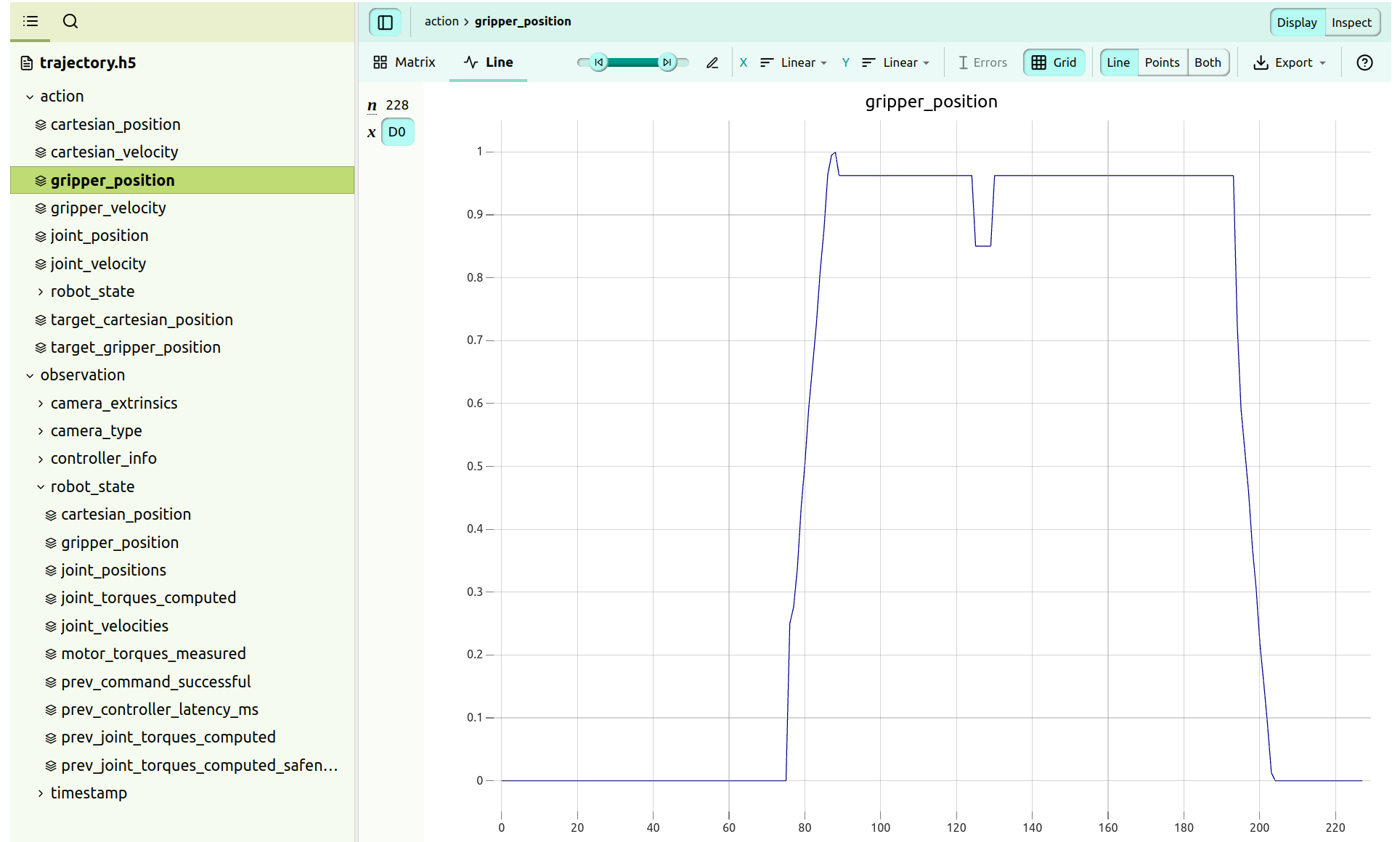
比如,查看夹爪的情况,能可视化看的:
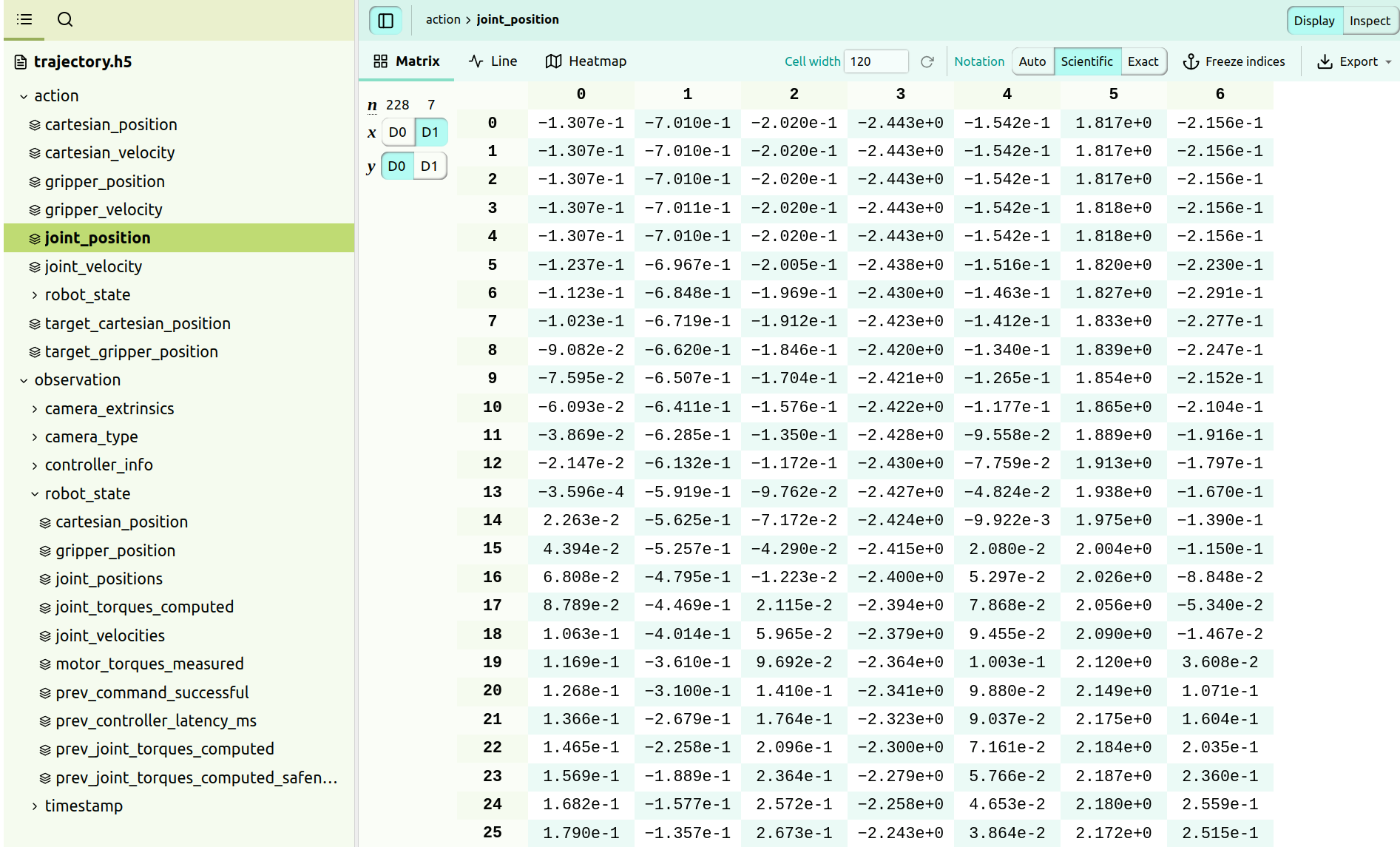
或者查看关节电机的具体数值:
3、数据格式转换(转为LeRobot 格式)
原始数据,包含的关键内容:
| 数据类型 | 来源 | 说明 |
|---|---|---|
| 视频帧 | recordings/MP4/*.mp4 |
多视角相机图像(手腕相机、外部相机) |
| 机器人状态 | trajectory.h5 |
关节位置 joint_positions (7维) |
夹爪位置 gripper_position (1维) |
||
| 动作 | trajectory.h5 |
关节速度 joint_velocity (7维) + 夹爪位置 (1维) |
| 语言指令 | aggregated-annotations-030724.json |
文本任务描述 |
| 时间戳 | trajectory.h5 |
各相机帧的时间戳信息 |
转换后的数据格式(LeRobot格式),是 使用 LeRobotDataset.create() 定义的特征结构:
{
# 图像数据(3个视角,分辨率 180×320)
"exterior_image_1_left": image (180, 320, 3) # 外部相机1
"exterior_image_2_left": image (180, 320, 3) # 外部相机2
"wrist_image_left": image (180, 320, 3) # 手腕相机
# 状态数据
"joint_position": float32 (7,) # 7维关节位置
"gripper_position": float32 (1,) # 1维夹爪位置
# 动作数据(用于训练)
"actions": float32 (8,) # 7维关节速度 + 1维夹爪
}
关键转换处理:
| 处理步骤 | 说明 |
|---|---|
| BGR → RGB | [..., ::-1] 翻转颜色通道 |
| 图像缩放 | 使用 Image.BICUBIC 缩放到 320×180 |
| 动作拼接 | joint_velocity (7D) + gripper_position (1D) = 8D |
| 帧率 | 15 FPS |
思路流程:

转换后的数据路径:~/.cache/huggingface/lerobot/your_hf_username/my_droid_dataset
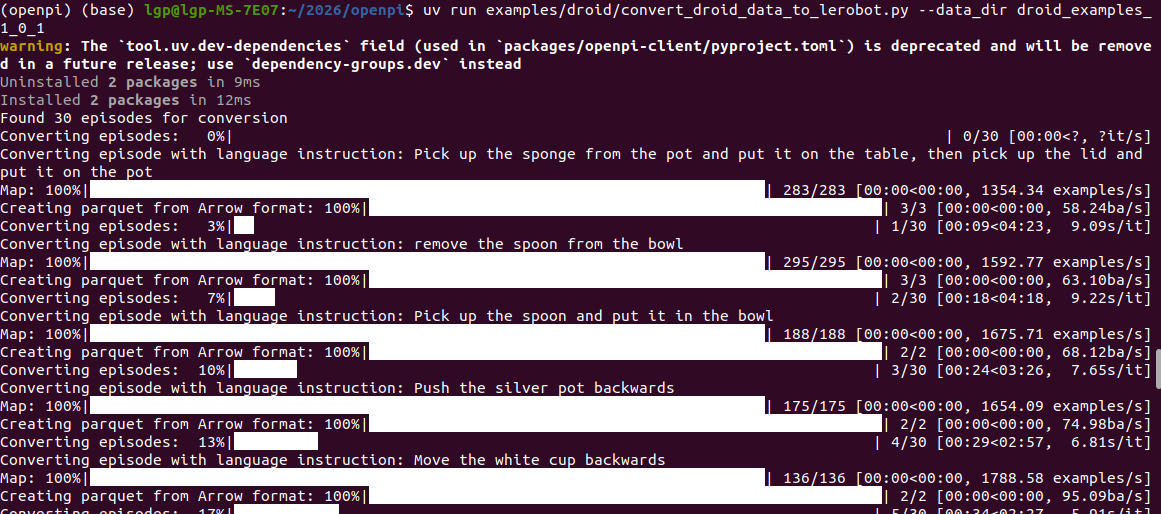
以上面的示例数据为例,运行指令:
uv run examples/droid/convert_droid_data_to_lerobot.py --data_dir droid_examples_1_0_1
运行信息:
参考代码:
"""
将DROID平台采集的数据,转换为LeRobot格式的最小示例
"""
from collections import defaultdict
import copy
import glob
import json
from pathlib import Path
import shutil
import cv2
import h5py
from lerobot.common.datasets.lerobot_dataset import HF_LEROBOT_HOME
from lerobot.common.datasets.lerobot_dataset import LeRobotDataset
import numpy as np
from PIL import Image
from tqdm import tqdm
import tyro
# 输出数据集的名称,也用于Hugging Face Hub
REPO_NAME = "your_hf_username/my_droid_dataset"
def resize_image(image, size):
"""调整图像大小"""
image = Image.fromarray(image)
return np.array(image.resize(size, resample=Image.BICUBIC))
def main(data_dir: str, *, push_to_hub: bool = False):
# 清理输出目录中任何现有的数据集
output_path = HF_LEROBOT_HOME / REPO_NAME
if output_path.exists():
shutil.rmtree(output_path)
data_dir = Path(data_dir)
# 创建LeRobot数据集,定义要存储的特征
# 这里我们将遵循DROID数据的命名约定
# LeRobot假设图像数据的dtype为`image`
dataset = LeRobotDataset.create(
repo_id=REPO_NAME,
robot_type="panda",
fps=15, # DROID数据通常以15fps录制
features={
# 我们称之为"left",因为只使用左立体相机(遵循DROID RLDS约定)
"exterior_image_1_left": {
"dtype": "image",
"shape": (180, 320, 3), # 这是DROID RLDS数据集使用的分辨率
"names": ["height", "width", "channel"],
},
"exterior_image_2_left": {
"dtype": "image",
"shape": (180, 320, 3),
"names": ["height", "width", "channel"],
},
"wrist_image_left": {
"dtype": "image",
"shape": (180, 320, 3),
"names": ["height", "width", "channel"],
},
"joint_position": {
"dtype": "float32",
"shape": (7,),
"names": ["joint_position"],
},
"gripper_position": {
"dtype": "float32",
"shape": (1,),
"names": ["gripper_position"],
},
"actions": {
"dtype": "float32",
"shape": (8,), # 这里使用关节*速度*动作(7维)+ 夹爪位置(1维)
"names": ["actions"],
},
},
image_writer_threads=10,
image_writer_processes=5,
)
# 加载语言标注
# 注意:本示例加载DROID语言标注,但你可以为自己的数据手动定义
with (data_dir / "aggregated-annotations-030724.json").open() as f:
language_annotations = json.load(f)
# 遍历原始DROID微调数据集,将片段写入LeRobot数据集
# 我们假设以下目录结构:
# RAW_DROID_PATH/
# - <...>/
# - recordings/
# - MP4/
# - <camera_id>.mp4 # 左立体相机对的单视角视频
# - trajectory.hdf5
# - <...>/
episode_paths = list(data_dir.glob("**/trajectory.h5"))
print(f"找到 {len(episode_paths)} 个片段用于转换")
# 遍历每个数据集名称,将片段写入LeRobot数据集
for episode_path in tqdm(episode_paths, desc="转换片段中"):
# 加载原始数据
recording_folderpath = episode_path.parent / "recordings" / "MP4"
trajectory = load_trajectory(str(episode_path), recording_folderpath=str(recording_folderpath))
# 为了加载语言指令,需要从元数据文件中解析出episode_id
# 同样,你可以为自己的数据修改此步骤,加载你自己的语言指令
metadata_filepath = next(iter(episode_path.parent.glob("metadata_*.json")))
episode_id = metadata_filepath.name.split(".")[0].split("_")[-1]
language_instruction = language_annotations.get(episode_id, {"language_instruction1": "Do something"})[
"language_instruction1"
]
print(f"正在转换带有语言指令的片段: {language_instruction}")
# 写入LeRobot数据集
for step in trajectory:
camera_type_dict = step["observation"]["camera_type"]
wrist_ids = [k for k, v in camera_type_dict.items() if v == 0]
exterior_ids = [k for k, v in camera_type_dict.items() if v != 0]
dataset.add_frame(
{
# 注意:加载的图像需要从BGR翻转为RGB
"exterior_image_1_left": resize_image(
step["observation"]["image"][exterior_ids[0]][..., ::-1], (320, 180)
),
"exterior_image_2_left": resize_image(
step["observation"]["image"][exterior_ids[1]][..., ::-1], (320, 180)
),
"wrist_image_left": resize_image(step["observation"]["image"][wrist_ids[0]][..., ::-1], (320, 180)),
"joint_position": np.asarray(
step["observation"]["robot_state"]["joint_positions"], dtype=np.float32
),
"gripper_position": np.asarray(
step["observation"]["robot_state"]["gripper_position"][None], dtype=np.float32
),
# 重要:这里使用关节速度动作,因为pi05-droid是在关节速度动作上预训练的
"actions": np.concatenate(
[step["action"]["joint_velocity"], step["action"]["gripper_position"][None]], dtype=np.float32
),
"task": language_instruction,
}
)
dataset.save_episode()
# 可选:推送到 Hugging Face Hub
if push_to_hub:
dataset.push_to_hub(
tags=["libero", "panda", "rlds"],
private=False,
push_videos=True,
license="apache-2.0",
)
##########################################################################################################
################ 本文件其余部分是解析原始DROID数据的函数 #########################
################ 不需要理解这部分 #########################
################ 复制自: https://github.com/JonathanYang0127/r2d2_rlds_dataset_builder/blob/parallel_convert/r2_d2/r2_d2.py
##########################################################################################################
camera_type_dict = {
"hand_camera_id": 0,
"varied_camera_1_id": 1,
"varied_camera_2_id": 1,
}
camera_type_to_string_dict = {
0: "hand_camera",
1: "varied_camera",
2: "fixed_camera",
}
def get_camera_type(cam_id):
if cam_id not in camera_type_dict:
return None
type_int = camera_type_dict[cam_id]
return camera_type_to_string_dict[type_int]
class MP4Reader:
def __init__(self, filepath, serial_number):
# 保存参数 #
self.serial_number = serial_number
self._index = 0
# 打开视频读取器 #
self._mp4_reader = cv2.VideoCapture(filepath)
if not self._mp4_reader.isOpened():
raise RuntimeError("损坏的MP4文件")
def set_reading_parameters(
self,
image=True, # noqa: FBT002
concatenate_images=False, # noqa: FBT002
resolution=(0, 0),
resize_func=None,
):
# 保存参数 #
self.image = image
self.concatenate_images = concatenate_images
self.resolution = resolution
self.resize_func = cv2.resize
self.skip_reading = not image
if self.skip_reading:
return
def get_frame_resolution(self):
width = self._mp4_reader.get(cv2.cv.CV_CAP_PROP_FRAME_WIDTH)
height = self._mp4_reader.get(cv2.cv.CV_CAP_PROP_FRAME_HEIGHT)
return (width, height)
def get_frame_count(self):
if self.skip_reading:
return 0
return int(self._mp4_reader.get(cv2.cv.CV_CAP_PROP_FRAME_COUNT))
def set_frame_index(self, index):
if self.skip_reading:
return
if index < self._index:
self._mp4_reader.set(cv2.CAP_PROP_POS_FRAMES, index - 1)
self._index = index
while self._index < index:
self.read_camera(ignore_data=True)
def _process_frame(self, frame):
frame = copy.deepcopy(frame)
if self.resolution == (0, 0):
return frame
return self.resize_func(frame, self.resolution)
def read_camera(self, ignore_data=False, correct_timestamp=None): # noqa: FBT002
# 如果不需要读取则跳过 #
if self.skip_reading:
return {}
# 读取相机 #
success, frame = self._mp4_reader.read()
self._index += 1
if not success:
return None
if ignore_data:
return None
# 返回数据 #
data_dict = {}
if self.concatenate_images or "stereo" not in self.serial_number:
data_dict["image"] = {self.serial_number: self._process_frame(frame)}
else:
single_width = frame.shape[1] // 2
data_dict["image"] = {
self.serial_number + "_left": self._process_frame(frame[:, :single_width, :]),
self.serial_number + "_right": self._process_frame(frame[:, single_width:, :]),
}
return data_dict
def disable_camera(self):
if hasattr(self, "_mp4_reader"):
self._mp4_reader.release()
class RecordedMultiCameraWrapper:
def __init__(self, recording_folderpath, camera_kwargs={}): # noqa: B006
# 保存相机信息 #
self.camera_kwargs = camera_kwargs
# 打开相机读取器 #
mp4_filepaths = glob.glob(recording_folderpath + "/*.mp4")
all_filepaths = mp4_filepaths
self.camera_dict = {}
for f in all_filepaths:
serial_number = f.split("/")[-1][:-4]
cam_type = get_camera_type(serial_number)
camera_kwargs.get(cam_type, {})
if f.endswith(".mp4"):
Reader = MP4Reader # noqa: N806
else:
raise ValueError
self.camera_dict[serial_number] = Reader(f, serial_number)
def read_cameras(self, index=None, camera_type_dict={}, timestamp_dict={}): # noqa: B006
full_obs_dict = defaultdict(dict)
# 随机顺序读取相机 #
all_cam_ids = list(self.camera_dict.keys())
# random.shuffle(all_cam_ids)
for cam_id in all_cam_ids:
if "stereo" in cam_id:
continue
try:
cam_type = camera_type_dict[cam_id]
except KeyError:
print(f"{self.camera_dict} -- {camera_type_dict}")
raise ValueError(f"在camera_type_dict中未找到相机类型 {cam_id}") # noqa: B904
curr_cam_kwargs = self.camera_kwargs.get(cam_type, {})
self.camera_dict[cam_id].set_reading_parameters(**curr_cam_kwargs)
timestamp = timestamp_dict.get(cam_id + "_frame_received", None)
if index is not None:
self.camera_dict[cam_id].set_frame_index(index)
data_dict = self.camera_dict[cam_id].read_camera(correct_timestamp=timestamp)
# 处理返回的数据 #
if data_dict is None:
return None
for key in data_dict:
full_obs_dict[key].update(data_dict[key])
return full_obs_dict
def get_hdf5_length(hdf5_file, keys_to_ignore=[]): # noqa: B006
length = None
for key in hdf5_file:
if key in keys_to_ignore:
continue
curr_data = hdf5_file[key]
if isinstance(curr_data, h5py.Group):
curr_length = get_hdf5_length(curr_data, keys_to_ignore=keys_to_ignore)
elif isinstance(curr_data, h5py.Dataset):
curr_length = len(curr_data)
else:
raise ValueError
if length is None:
length = curr_length
assert curr_length == length
return length
def load_hdf5_to_dict(hdf5_file, index, keys_to_ignore=[]): # noqa: B006
data_dict = {}
for key in hdf5_file:
if key in keys_to_ignore:
continue
curr_data = hdf5_file[key]
if isinstance(curr_data, h5py.Group):
data_dict[key] = load_hdf5_to_dict(curr_data, index, keys_to_ignore=keys_to_ignore)
elif isinstance(curr_data, h5py.Dataset):
data_dict[key] = curr_data[index]
else:
raise ValueError
return data_dict
class TrajectoryReader:
def __init__(self, filepath, read_images=True): # noqa: FBT002
self._hdf5_file = h5py.File(filepath, "r")
is_video_folder = "observations/videos" in self._hdf5_file
self._read_images = read_images and is_video_folder
self._length = get_hdf5_length(self._hdf5_file)
self._video_readers = {}
self._index = 0
def length(self):
return self._length
def read_timestep(self, index=None, keys_to_ignore=[]): # noqa: B006
# 确保在范围内读取 #
if index is None:
index = self._index
else:
assert not self._read_images
self._index = index
assert index < self._length
# 加载低维数据 #
keys_to_ignore = [*keys_to_ignore.copy(), "videos"]
timestep = load_hdf5_to_dict(self._hdf5_file, self._index, keys_to_ignore=keys_to_ignore)
# 递增读取索引 #
self._index += 1
# 返回时间步 #
return timestep
def close(self):
self._hdf5_file.close()
def load_trajectory(
filepath=None,
read_cameras=True, # noqa: FBT002
recording_folderpath=None,
camera_kwargs={}, # noqa: B006
remove_skipped_steps=False, # noqa: FBT002
num_samples_per_traj=None,
num_samples_per_traj_coeff=1.5,
):
read_recording_folderpath = read_cameras and (recording_folderpath is not None)
traj_reader = TrajectoryReader(filepath)
if read_recording_folderpath:
camera_reader = RecordedMultiCameraWrapper(recording_folderpath, camera_kwargs)
horizon = traj_reader.length()
timestep_list = []
# 选择要保存的时间步 #
if num_samples_per_traj:
num_to_save = num_samples_per_traj
if remove_skipped_steps:
num_to_save = int(num_to_save * num_samples_per_traj_coeff)
max_size = min(num_to_save, horizon)
indices_to_save = np.sort(np.random.choice(horizon, size=max_size, replace=False))
else:
indices_to_save = np.arange(horizon)
# 遍历轨迹 #
for i in indices_to_save:
# 获取HDF5数据 #
timestep = traj_reader.read_timestep(index=i)
# 如果适用,获取录制的数据 #
if read_recording_folderpath:
timestamp_dict = timestep["observation"]["timestamp"]["cameras"]
camera_type_dict = {
k: camera_type_to_string_dict[v] for k, v in timestep["observation"]["camera_type"].items()
}
camera_obs = camera_reader.read_cameras(
index=i, camera_type_dict=camera_type_dict, timestamp_dict=timestamp_dict
)
camera_failed = camera_obs is None
# 如果成功,将数据添加到时间步 #
if camera_failed:
break
timestep["observation"].update(camera_obs)
# 过滤步骤 #
step_skipped = not timestep["observation"]["controller_info"].get("movement_enabled", True)
delete_skipped_step = step_skipped and remove_skipped_steps
# 保存过滤后的时间步 #
if delete_skipped_step:
del timestep
else:
timestep_list.append(timestep)
# 移除多余的过渡帧 #
timestep_list = np.array(timestep_list)
if (num_samples_per_traj is not None) and (len(timestep_list) > num_samples_per_traj):
ind_to_keep = np.random.choice(len(timestep_list), size=num_samples_per_traj, replace=False)
timestep_list = timestep_list[ind_to_keep]
# 关闭读取器 #
traj_reader.close()
# 返回数据 #
return timestep_list
if __name__ == "__main__":
tyro.cli(main)4、模型微调
这里默认使用 pi05_droid (π0.5-DROID)权重进行微调,也可以选择其他模型
| 模型 | 用例 | 描述 | 检查点路径 |
|---|---|---|---|
| π0-FAST-DROID | 推理 | π0-基于DROID数据集微调的FAST模型:能够在DROID机器人平台上执行各种简单的桌面操作任务,无需在新场景中进行任何测试。 | gs://openpi-assets/checkpoints/pi0_fast_droid |
| π0-DROID | 微调 | π0在DROID 数据集上微调的模型:推理速度比以往更快π0-FAST-DROID,但可能无法很好地遵循语言命令。 | gs://openpi-assets/checkpoints/pi0_droid |
| π0-ALOHA-towel | 推理 | π0基于ALOHA内部数据微调的模型:可在ALOHA机器人平台上零次折叠各种毛巾 | gs://openpi-assets/checkpoints/pi0_aloha_towel |
| π0-ALOHA-tupperware | 推理 | π0基于ALOHA内部数据微调的模型:可以从特百惠容器中取出食物 | gs://openpi-assets/checkpoints/pi0_aloha_tupperware |
| π0-ALOHA-pen-uncap | 推理 | π0基于公开的ALOHA数据微调的模型:可以打开笔帽 | gs://openpi-assets/checkpoints/pi0_aloha_pen_uncap |
| π0.5-LIBERO | 推理 | π0.5针对LIBERO基准测试进行了微调的模型:获得了最先进的性能(参见LIBERO README) | gs://openpi-assets/checkpoints/pi05_libero |
| π0.5-DROID | 推理/微调 | π0.5在DROID数据集上进行微调并实现知识隔离的模型:推理速度快,语言跟随性能好 | gs://openpi-assets/checkpoints/pi05_droid |
微调命令:
uv run scripts/train.py pi05_droid_finetune --exp-name=my_experiment --overwrite关键参数:
| 配置项 | 推测值 | 说明 |
|---|---|---|
model |
PI0.5架构 | 扩散策略或流匹配VLA模型 |
weight_loader |
预训练PI0.5权重 | 从基础模型加载 |
freeze_filter |
可能冻结视觉编码器 | 只微调策略头/LoRA |
trainable_filter |
策略相关参数 | 指定可训练部分 |
optimizer |
AdamW | 带权重衰减 |
lr_schedule |
余弦退火/常数 | 微调学习率 |
ema_decay |
0.9999 | 模型参数平滑 |
batch_size |
需整除GPU数 | FSDP数据并行 |
data_loader |
DROID格式 | LeRobot格式加载 |
打印信息:
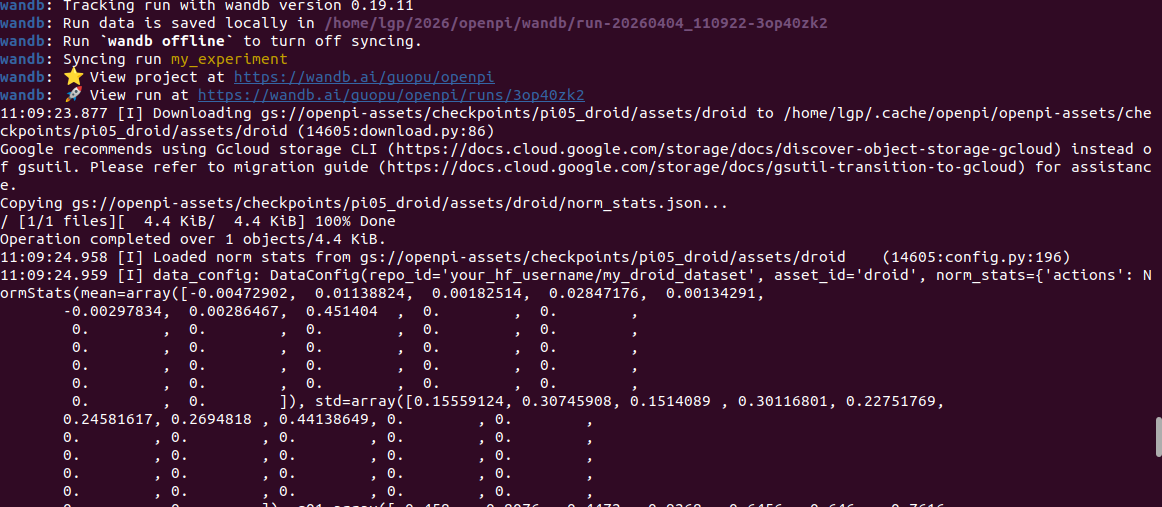
等待微调完成:
repack_transforms=Group(inputs=[RepackTransform(structure={'observation/exterior_image_1_left': 'exterior_image_1_left', 'observation/exterior_image_2_left': 'exterior_image_2_left', 'observation/wrist_image_left': 'wrist_image_left', 'observation/joint_position': 'joint_position', 'observation/gripper_position': 'gripper_position', 'actions': 'actions', 'prompt': 'prompt'})], outputs=()), data_transforms=Group(inputs=[DroidInputs(model_type=<ModelType.PI05: 'pi05'>)], outputs=[DroidOutputs()]), model_transforms=Group(inputs=[InjectDefaultPrompt(prompt=None), ResizeImages(height=224, width=224), TokenizePrompt(tokenizer=<openpi.models.tokenizer.PaligemmaTokenizer object at 0x7f8fd525c210>, discrete_state_input=True), PadStatesAndActions(model_action_dim=32)], outputs=()), use_quantile_norm=True, action_sequence_keys=('actions',), prompt_from_task=True, rlds_data_dir=None, action_space=None, datasets=()) (14605:data_loader.py:243)
Resolving data files: 100%|█████████████████████████████████████████████████████████████████| 30/30 [00:00<00:00, 391991.03it/s]
Downloading data: 100%|██████████████████████████████████████████████████████████████████| 30/30 [00:00<00:00, 466033.78files/s]
Generating train split: 7726 examples [00:01, 5662.68 examples/s]
11:09:27.192 [I] local_batch_size: 32 (14605:data_loader.py:324)
2026-04-04 11:09:29.646418: E external/local_xla/xla/stream_executor/cuda/cuda_fft.cc:477] Unable to register cuFFT factory: Attempting to register factory for plugin cuFFT when one has already been registered
........
分享完成~

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 7
7 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)