CrowdCLIP: Unsupervised Crowd Counting via Vision-Language Model(CVPR 2023)
基于点的半监督人群计数的点到区域损失
摘要
监督式人群计数在很大程度上依赖于成本高昂的人工标注,这种标注既困难又昂贵,尤其是在密集的场景中。为了缓解这个问题,我们提出了一个新的无监督的人群计数框架,名为CrowdCLIP。核心思想是建立在两个观察结果之上的:1)最近的对比预训练视觉语言模型(CLIP)在各种下游任务上表现出令人印象深刻的性能;2)人群补丁和计数文本之间存在自然映射。据我们所知,CrowdCLIP是第一个研究视觉语言知识来解决计数问题的。具体来说,在训练阶段,我们通过构建排名文本提示来匹配大小排序的人群补丁,从而利用多模态排名损失来指导图像编码器学习。在测试阶段,为了处理图像patch的多样性,我们提出了一种简单而有效的渐进滤波策略,首先选择高度潜在的人群patch,然后以不同的计数间隔将其映射到语言空间中。在五个具有挑战性的数据集上进行的大量实验表明,与之前的无监督计数方法相比,所提出的CrowdCLIP具有更优越的性能。值得注意的是,在跨数据集设置下,CrowdCLIP甚至超过了一些流行的全监督方法。
1. 代码和数据集
1.1 代码地址:https:// github.com/dk-liang/CrowdCLIP
1.2 数据集
1.2.1 UCF-QNRF
UCF-QNRF是一个密集计数数据集。有1535张图像, 人群编号从49到12,865不等。这些图像被分为包含1201 张图像的训练集和包含334张图像的测试集。CRCV | Center for Research in Computer Vision at the University of Central Florida
1.2.2 JHU-Crowd++
JHU-Crowd++是最大的计数数据集之一。它包含 4372张图片,1515005个注释。具体来说,2,272,500和1, 600张图像被分为训练集、验证集和测试集。在雨天和 雾天拍摄的图像占很大比例。这些退化的图像增加了人 群计数的挑战。Datasets – VIU Lab
1.2.3 ShanghaiTech
ShanghaiTech包括A部分和b部分。A部分包含482张 图片,241条注释,677条注释,训练集和测试集分别包 含300张和182张图片。B部分包含716张图像,共88,488 个标注的头部中心,其中400张图像用于训练,其余316 张图像用于测试。22033/LICENSE · 万能工具箱/ShanghaiTech数据集介绍 - AtomGit | GitCode
1.2.4 UCF-CC50
UCF-CC50是一个具有挑战性的计数数据集。它只 包含50张图像,但有63,075个带注释的个体,其中人群 数量从94到4,543不等。
CRCV | Center for Research in Computer Vision at the University of Central Florida
2. 文章主要存在问题
监督式人群计数在很大程度上依赖于成本高昂的人工标注,这种标注既困难又昂贵,尤其是在密集的场景中。
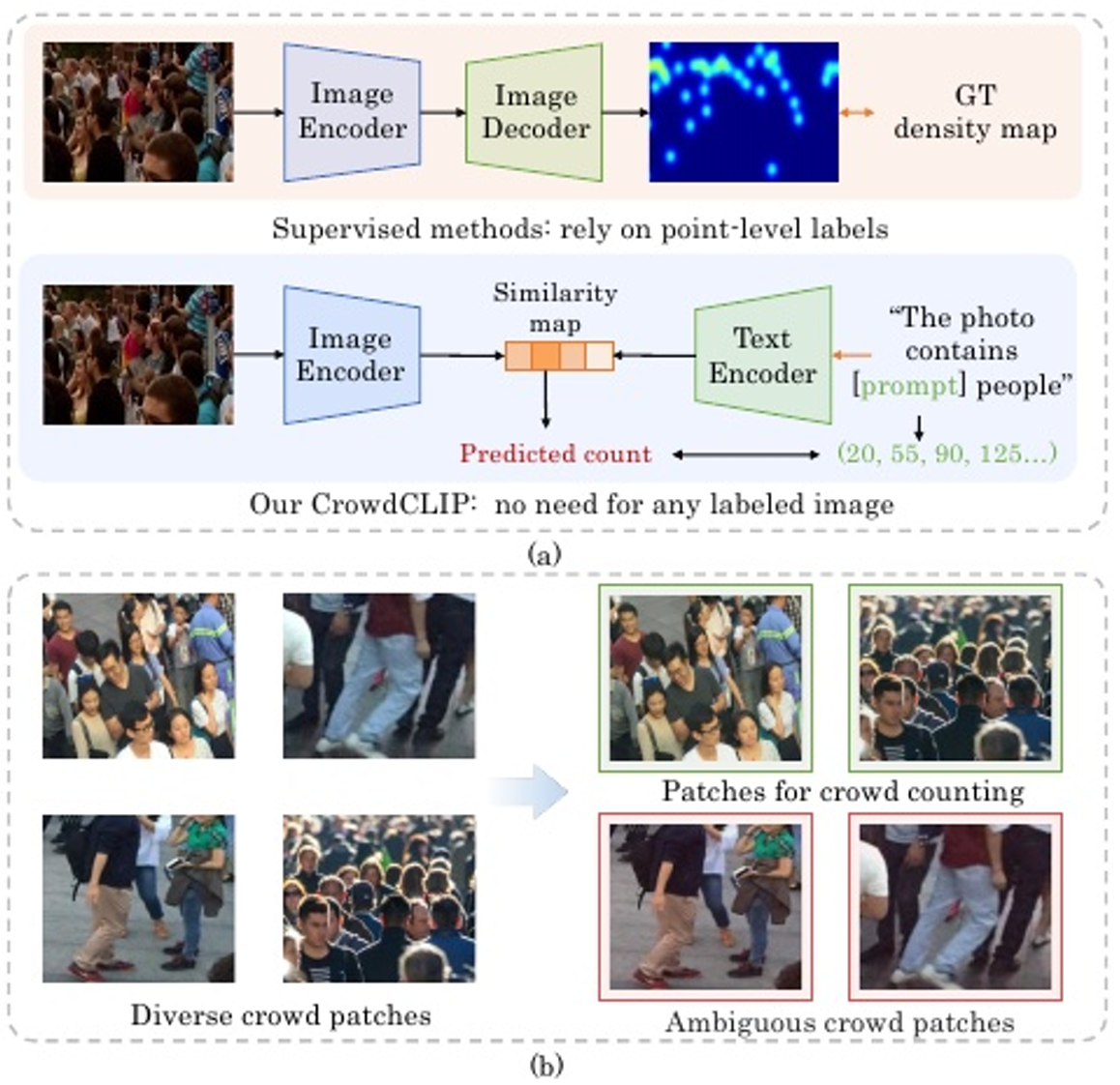
对比语言图像预训练(contrast Language-Image Pre-Training, CLIP)作为一种新的训练模式,因其强大的迁移能力而受到越来越多的关注。 通过使用大规模噪声图像-文本对学习视觉表示,CLIP 在各种下游视觉任务(例如,目标检测,语义分割 ,生成)上取得了令人满意的性能。然而,如何将这样一个语言驱动的模型应用于人群计数还没有被探索。显然,CLIP不能直接应用于计数任务,因为 在CLIP的对比预训练中没有计数监督。
一种自然利用视觉-语言知识的方式是将人群数量离散化为一系列区间,从而将人群计数任务从回归问题转化为分类问题。随后,可以直接计算图像编码器提取的图像嵌入与文本编码器提取的文本嵌入之间的相似度,并选择最相似的图像-文本对作为预测计数结果(称为零样本CLIP方法)。然而,我们发现零样本CLIP的表现不尽如人意,这主要归因于两个关键原因:1)零样本CLIP难以充分理解人群语义,因为原始CLIP模型主要针对单物体图像识别进行训练;2)由于人群分布不均匀,图像块之间存在高度多样性,而计数任务需要计算每个图像块中的人头数量。某些不包含人头的群体图像块可能会对CLIP模型产生歧义,如图1(b)所示。
3. 所提创新点及方法
3.1 文章创新点
为了解决上述问题,本文提出了CrowdCLIP,它 将CLIP强大的视觉类别对应能力用于无监督的人群计数,如图1(a)所示。具体来说,首先,我们在训练阶段构建排序文本提示来描述一组大小排序的图像补丁。 因此,可以对图像编码器进行微调,通过多模态排序 损失更好地捕捉人群语义。其次,在测试阶段,我们提出了一种简单而有效的渐进式滤波策略,该策略由三个阶段成,以选择高相关性的人群补丁。特别是,前两个阶 段的目标是用粗到精的分类范式选择高相关性的人群补丁,最后一个阶段是利用相应的人群补丁映射到适当的计数。得益于这样一种渐进式推理策略,我们可以有效地降低模糊人群补丁的影响。
主要贡献如下:1)本文提出了一种新的无监督人群 计数方法——CrowdCLIP,将人群计数创新地视为一个图像-文本匹配问题。据我们所知,这是第一个将视觉语言知识转移到人群计数的工作。2)我们引入了基 于排名的对比微调策略,使图像编码器更好地挖掘潜 在的人群语义。此外,提出了一种渐进式滤波策略, 在测试阶段选择相关度高的人群补丁映射到合适的计数区间。
3.2 采取的方法
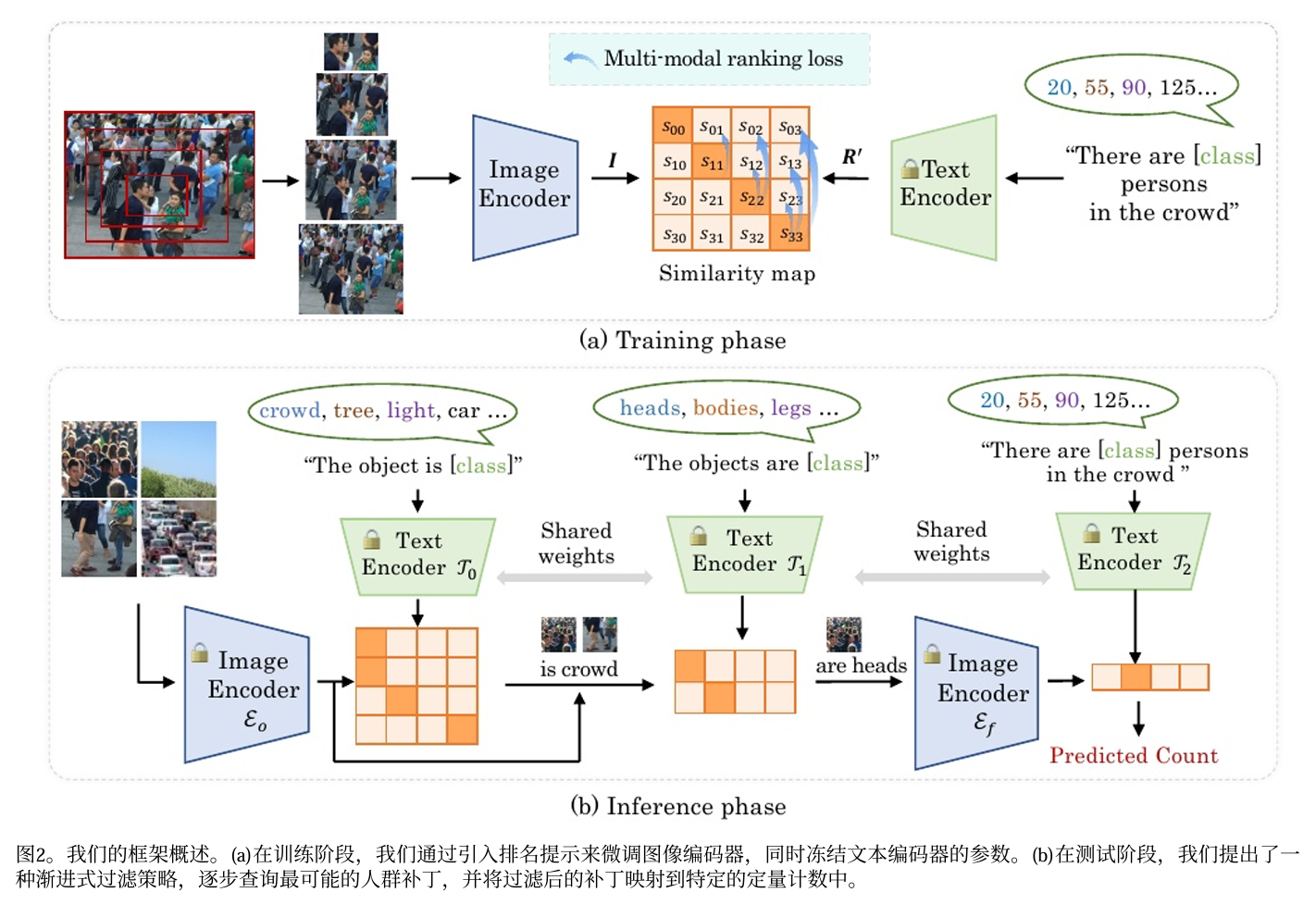
我们的方法概述如图2所示。在训练阶段,我们通 过引入排序文本提示来微调图像编码器,同时冻结文本 编码器的参数。在测试阶段,我们提出了一种渐进式过滤策略,逐步查询高度潜在的人群补丁,并将过滤后的 补丁映射到特定的人群间隔中。
3.2.1 基于排序的对比微调
原始的CLIP模型需要图像-文本对来完成其对比预训练过程。然而,在无监督的设置下,我们没有任何可用标签,也就是说,微调过程缺乏对应的文本模态作为监督信息。为此,我们利用计数区间文本构建了排序提示,用以描述按人群规模排序的输入图像,如图2(a)所示。这样一来,我们就可以通过多模态排序损失来对图像编码器进行微调。
图像分块处理:给定一张输入的人群图像,我们首先裁剪出一组正方形图像块集合 {OM},其中M是预定义的图像块数量。
尺寸排序:对于任意两个裁剪出的图像块(Oi 与 Oj,其中 0 ≤ i < j ≤ M−1),Oi的尺寸均小于Oj的尺寸。
中心共享与统一处理:所有从同一图像中裁剪出的块共享相同的图像中心。在训练时,所有块会被调整至相同尺寸,并输入图像编码器,生成图像排序嵌入I = [I0, I1, ..., IM−1],其中 I ∈ ℝ^{M × C}(M 为块数量,C 为嵌入维度)。
提示词设计。原始的 CLIP [34] 并非为计数任务设计。如何定制可行的文本提示词需要加以研究。如上所述,我们已成功收集了一系列具有尺寸排序关系的图像块。显然,不同图像块中的人头数量也具有顺序性,较大的图像块对应着更多或相等的人头数量。因此,我们设计排序文本提示词来描述图像块之间的序数关系。具体而言,我们提出学习排序嵌入,以在语言隐空间中保持图像块的顺序。文本提示词定义为 “There are [class] persons in the crowd”,其中 [class]代表一组基础的排序数字 R = [R₀, R₀+K, ..., R₀+(N-1)K]。这里,R₀、K和 N分别表示基础参考数量、计数间隔和类别数量。这些文本提示词将被输入文本编码器。
图像编码器优化。假设我们已获得一组图像排序嵌入 I ∈ ℝ^{M×C} 和文本排序嵌入 R′ ∈ ℝ^{N×C},其中 I 和 R′ 分别由图像编码器和文本编码器生成。对于图像编码器的优化,我们的目标是利用多模态排序损失来调整其参数,使得图像块嵌入 I 与文本提示嵌入 R′ 之间的相似度矩阵 S 呈现出理想的序数关系。对于图像-语言匹配流程中,我们通过内积计算图像嵌入 I 与文本嵌入 R′之间的相似度得分,
3.2.2 渐进式过滤策略
在这一部分中,我们详细介绍了所提出的由三个阶段组成的进度过滤策略,用于在推理阶段选择真实的人群补丁并将其映射到适当的计数间隔,如图2(b)所示。为简单起见,我们将原始图像编码器和微调图像编码器分别命名为Eo和Efo,Eo用于选择高置信度的人群补丁,Efo用于最终计数。
给定一个输入图像,我们首先将其划分为PxP块的网格,然后将这些块和相应的文本提示分别馈送到E和第一个文本编码器T,中,生成用于粗分类的相似度分数。T,的文本提示设置为“The objectis[class]”,其目的是将patch划分为不同的类别,并有明确的区分(例如、“tree”、“car”)。crowd”
从第一阶段选择的人群补丁可能包含人的不同组成部分,如人的头部、身体和腿。然而,人群计数任务的目的是估计人类头部的数量,而不是其他组成部分,因为只有头部与其他组成部分相比不容易被遮挡。
在第二阶段,我们采用细粒度的文本提示,并将其馈送到第二个文本编码器T,中,以进一步过滤补丁。细粒度文本提示被定义为“对象是[类]”,其中[类]是一些细粒度的类别(例如,“人头”“人体”)。因此,获得了具有人头的高置信度人群补丁。注意,在这个阶段,我们仍然使用非微调的图像编码器E.来计算相似度。
在第三阶段,我们采用微调后的E,作为图像编码器第三个T的文本提示,与微调阶段相同,即将排名文本提示定义为“人群中有[类]人”,其中[class]为预定义的排名数r。最终的计数可以通过基于Ef,和T2,的图像嵌入和类嵌入来选择最相似的图像-文本对来获得注意,在实践中,T0,T1和T2,共享相同的参数,所有图像共享相同的文本提示。换句话说,我们可以提前得到文本嵌入,而不是在每个推理阶段处理文本提示从而保持效率。
四、总结与不足
4.1 文章总结
在不同数据设置的五个具有挑战性的数据集上进 行的大量实验证明了我们方法的有效性。特别是,在 具有挑战性的UCF-QNRF数据集上,我们的CrowdCLI P在MAE指标方面显著优于当前无监督的最先进方法 CSS-CCNN[3] 35.2%。在交叉数据集验证下,我们的 方法甚至超过了一些流行的全监督作品[40,62]。
主要贡献如下:1)本文提出了一种新的无监督人群 计数方法——CrowdCLIP,将人群计数创新地视为一 个图像-文本匹配问题。据我们所知,这是第一个将视 觉语言知识转移到人群计数的工作。2)我们引入了基 于排名的对比微调策略,使图像编码器更好地挖掘潜 在的人群语义。此外,提出了一种渐进式滤波策略, 在测试阶段选择相关度高的人群补丁映射到合适的计 数区间。
4.2 存在的不足
其主要局限性在于本方法仅为给定图像提供计数级信息。然而,点级信息同样有助于辅助人群分析。未来,我们将探索在无监督模式下进行人群定位的方法。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 5
5 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)