DINO系列:从 DINOv1 到 DINOv3阅读分享
DINOv1到DINOv3
序言:从数据为王到自监督觉醒 ——DINO 系列如何重新定义视觉基础模型
在深度学习的黄金十年里,我们早已习惯一条铁律:数据为王,标签至上。想要模型效果好,海量标注少不了。以 ImageNet 为代表的有监督时代,ResNet 架构搭配千万级人工标注数据,一度成为计算机视觉(CV)领域的标准范式,也让“有监督学习”占据了绝对统治地位。
但繁荣背后藏着难以突破的瓶颈:标注成本居高不下、数据覆盖有限、泛化能力受限。现实世界的视觉信息无穷无尽,而人工标注永远只是沧海一粟。反观人类感知,婴儿无需学习数百万张带标签的“猫图”,仅通过观察、对比、探索,就能轻松识别物体、区分场景。这种无需外部标签、从海量无标注信息中自主学习规律的能力,正是人工智能长期追求的目标。
自监督学习(Self-Supervised Learning, SSL)应运而生,它的核心是抛弃人工标签,从数据本身构建监督信号,让模型像人类一样自主理解视觉世界。从早期 SimCLR、MoCo 的对比学习,到 BYOL 的自蒸馏探索,CV 领域始终在寻找摆脱标签依赖、高效利用海量无标注数据的可行路径。
直到 2021 年,Meta AI 推出 DINOv1,彻底打破僵局。它首次有力证明:Vision Transformer(ViT)完全可以在纯无监督条件下完成高效预训练。更令人震撼的是,DINOv1 展现出惊人的涌现能力——模型从未见过任何分割标注,却能在自监督训练中自发学会前景与背景分离、物体边界提取、语义区域划分,实现了无标注条件下的自发语义分割,颠覆了业界对自监督模型能力的认知。
在此基础上,DINOv2 将自监督视觉模型推向工业级基础模型高度。它在 DINOv1 框架上融合 iBOT 思想,新增图像级+Patch 级双目标训练,搭配亿级 LVD-142M 高质量去重数据集,引入 Register Tokens 净化局部特征、KoLeo 正则防止特征塌缩,同时通过 FlashAttention、FSDP 等工程优化实现大模型高效训练。DINOv2 输出的全局特征与密集局部特征兼具强鲁棒性与高泛化性,无需微调即可直接用于图像检索、商标比对、专利检测、语义分割等多场景,真正实现“一次预训练,全域通用”。
而最新的 DINOv3,则在密集特征(Dense Features)稳定性上实现极致突破。针对大模型长周期训练后 Patch 特征退化问题,DINOv3 引入 Gram Anchoring 机制锁定特征结构,搭配 Axial RoPE 位置编码适配任意分辨率,进一步强化高分辨率、密集预测任务的表现,让自监督视觉基础模型在商标侵权检测、高精度分割、深度估计等工业场景中更稳定、更实用。
从依赖百万标注的监督范式,到无需标签、自主学习的自监督革命;从验证可行性的 DINOv1,到通用化的 DINOv2,再到极致稳定的 DINOv3,DINO 系列不仅是自监督视觉模型的迭代,更标志着计算机视觉正式迈入无标注、大模型、通用特征的新时代,为商标侵权、专利比对、违规检测、内容安全等众多工业场景提供了低成本、高精度、强泛化的底层技术支撑。
第一章:DINOv1 —— 惊鸿一瞥,无监督的语义涌现
论文:Emerging Properties in Self-Supervised Vision Transformers (ICCV 2021)
1.1 核心发问:ViT 真的需要监督吗?
在 DINOv1 出现之前,自监督学习(SSL)的主流范式是对比学习(Contrastive Learning),典型代表如 SimCLR、MoCo。它们的思路高度统一:构造正负样本对,强制模型拉近正样本(同一张图的不同增强)、推开负样本(不同图片)。
但这套框架存在两个明显局限:
- 高度依赖 ResNet:当时的自监督方法几乎都是为卷积网络设计。
- 负样本与大 Batch 依赖:想要训得好,必须堆海量负样本或超大批次。
此时,DINO 团队提出了一个颠覆性问题:
如果我们放弃对比学习,改用「自蒸馏」,并把主干换成 ViT,会发生什么?
结果震惊了整个 CV 领域:
ViT 在无监督下不仅能训,而且效果远超 ResNet,更涌现出监督学习无法获得的几何结构与整体物体感知能力。
1.2 架构解析:Student-Teacher 自蒸馏
DINO 的全称是 Self-Distillation with NO labels——无标签自蒸馏。
它的思想极其简洁:没有老师,就让“过去的自己”当“今天的老师”。
1.2.1 整体流程
整个训练过程就是两个网络的协同博弈: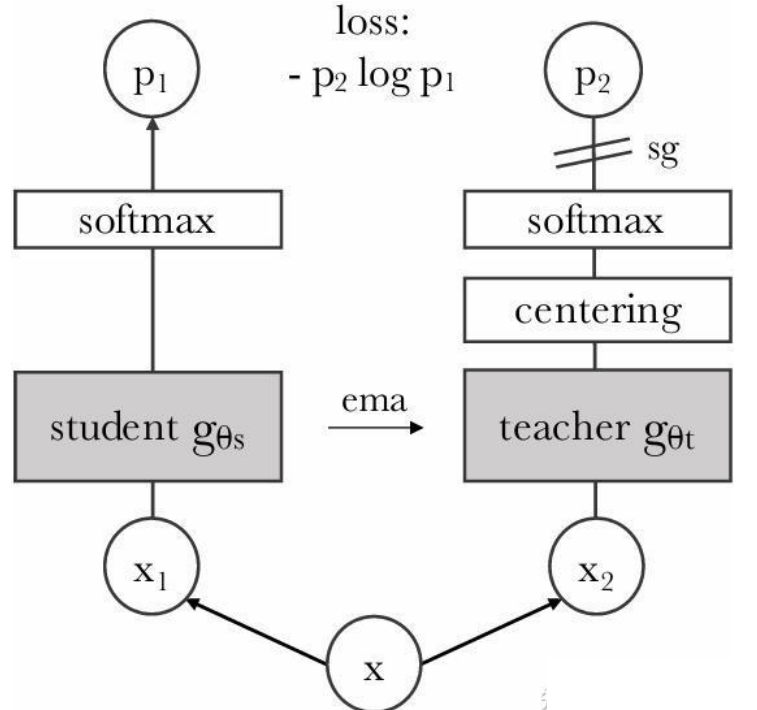
-
Student 网络 g_θs
我们真正要训练的模型,接收各种增强视图,通过反向传播更新参数。 -
Teacher 网络 g_θt
结构与 Student 完全一致,但不反向传播、不更新梯度。
它的参数来自 Student 的指数移动平均(EMA)。
1.2.2 核心公式:EMA 更新
Teacher 的稳定性是训练成功的关键。
EMA 让 Teacher 成为 Student 的“平滑历史版本”,既不会跳变太快,也不会滞后太久。
更新公式:
θt ← λ * θt + (1−λ) * θs
其中 λ 是动量系数,训练中通常从 0.996 缓慢提升到接近 1。
这让 Teacher 相当于一个高质量、超稳定的集成模型,为 Student 提供可靠的学习目标。
1.2.3 多视角裁剪(Multi-Crop)策略
DINO 使用了比 SimCLR 更强的增强策略,强制模型建立局部 ↔ 全局的关联:
-
Global Crops(2 个)
大尺寸裁剪(如 224×224),覆盖原图 50% 以上。
只有 Teacher 能看到全局视图。 -
Local Crops(6 个)
小尺寸裁剪(如 96×96),只覆盖局部细节。
Student 同时看全局 + 局部视图。
训练逻辑非常优美:
当 Student 看到一个“局部碎片”(例如一只狗的耳朵),
它必须预测出 Teacher 看到的“全局图像”(整只狗)的特征分布。
这强制模型学会从局部推断整体、从碎片理解语义。
1.3 数学之美:防止模型坍塌(Collapse)
无监督、无负样本的模型,最大死敌就是坍塌(Collapse),即:
对于任意输入,它都输出完全相同或高度相似的表示向量,Loss 极低,但完全无效。
Tips:过拟合是模型“死记硬背”了训练数据,而坍塌是模型“彻底躺平”了。
DINOv1 用两把“锁”彻底锁住坍塌路径:
Centering(中心化) + Sharpening(锐化)。
1.3.1 Centering:打破单一主导
为避免模型总倾向于某一个固定输出,DINO 对 Teacher 输出做中心化:
gt(x) ← gt(x) − c
其中 c 是 Teacher 输出均值的滑动平均: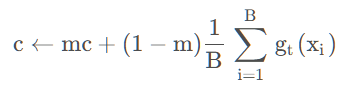
不加中心化会出现:模型偷懒,全部图片特征扎堆在同一个维度,全部输出近似向量,模型坍塌。
举个直白例子:特征是1024维向量,模型学到最优捷径——永远只激活第50维,剩下所有维度全为0。不管输入猫、狗、背景,特征大同小异,Student和Teacher分布天然对齐,损失直接归零,但模型完全没学到任何语义,这就是维度垄断式坍塌。
Centering核心操作:滑动平均统计整Batch所有样本的Teacher特征均值 c c c,每个输出特征统一减去均值 c c c: g t ( x ) ← g t ( x ) − c g_t(x)\leftarrow g_t(x)-c gt(x)←gt(x)−c。
- 某一维度全员偏大 → 减掉均值后整体被拉低
效果:强制所有特征维度的整体期望趋近于0,杜绝单个维度持续独占激活,打破模型锁定单一通道偷懒的可能性。
配合后面Sharpening(锐化),既不能全挤在一处,也不能平铺均匀分布,逼迫特征根据图像语义自动聚类分开。
1.3.2 Sharpening:制造置信度
只有 Centering 还不够,均匀分布同样会导致坍塌。
我们需要模型输出尖锐、高置信度的分布,而不是模糊的均匀概率。
这通过 Softmax 温度系数 τ 实现: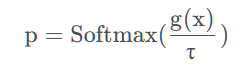
- Teacher:使用极低温度(τt < 0.07),输出接近 one-hot 伪标签,高度尖锐。
- Student:使用稍高温度(τs = 0.1),保持平滑与稳定性。
总结:
- Centering 防止所有样本聚成一类
- Sharpening 防止特征变成均匀噪声
两者结合,让模型自动把图片聚成清晰、分离、有语义的簇。
1.4 涌现属性:Attention Maps 的魔法
DINOv1 最震撼、最广为人知的,就是它的 Attention 注意力图。
当你查看训练好的 ViT 最后一层自注意力,会发现:
它自动精准勾勒出物体的完整轮廓、边界、前景与背景。
与监督学习 ViT 只关注“最具判别力的纹理”不同,
DINO 的注意力关注整个物体,而不是局部花纹。
这意味着什么?
意味着我们可以直接用 Attention Map 做无监督物体分割,
或作为弱监督分割、目标检测、商标匹配的“天然种子区域”。
这也是 DINO 能在工业界(侵权检测、违规识别、内容安全)快速落地的核心原因。
第二章:DINOv2 —— 工业级基座,规模即真理
论文:DINOv2: Learning Robust Visual Features without Supervision (2023)
2.1 从“玩具”到“基建”:DINOv2 的诞生使命
DINOv1 用惊艳的涌现能力证明了自监督 + ViT的巨大潜力,但在 2021 年的工业落地场景中,它仍存在明显短板,难以直接替代 CLIP 与有监督 ResNet 成为通用视觉主干:
- 数据规模受限:仅在 ImageNet-1K(约128万张)上训练,数据多样性与覆盖度不足,模型泛化能力有限。
- 特征通用性弱:全局分类表现优异,但面向分割、深度估计等密集预测任务的局部特征质量一般。
- 大模型训练不稳定:ViT-g 等十亿参数量级模型在自监督框架下难以收敛,训练成本与风险极高。
为此,DINOv2 应运而生。它的核心目标不再是“验证可行性”,而是打造全能、鲁棒、可直接落地的工业级视觉基础模型,让无监督特征真正具备比肩甚至超越有监督特征的实用价值。
2.2 数据核武器:LVD-142M 高质量数据集构建
DINOv2 团队深刻意识到:自监督学习,数据质量远大于数据数量。直接爬取的网络原始数据充斥噪声、重复与低质样本,无法支撑高质量预训练。
为此,团队构建了一套自动化、高纯净度的数据处理 pipeline,最终产出 LVD-142M(Large Visual Data,1.42亿样本) 数据集,成为模型强大的基础保障。
数据 pipeline 核心步骤
- 高质量种子集
选取 ImageNet-22K、ADE20K、Google Landmarks 等权威、干净、标注完善的数据集作为“语义种子”,确保数据起点高质量。 - 海量网络数据特征化
用预训练 ViT 对大规模网络图片提取特征,建立特征索引库。 - 精准去重
采用图像拷贝检测技术,剔除高度重复、低信息量冗余图片,大幅降低数据噪声。 - 语义检索扩充
以种子图片为查询,在网络数据中检索语义相似但形态多样的图片,既扩充规模,又保证数据分布覆盖分类、分割、细粒度识别、关键点等多种任务场景。
2.3 算法升级:DINO + iBOT 双引擎联合
DINOv1 仅聚焦全局图像级对齐,而 DINOv2 引入 iBOT 思想,实现全局 + 局部双监督,让模型同时拥有强语义与细粒度结构信息。
总损失由三部分构成:
L = λ 1 L DINO + λ 2 L iBOT + λ 3 L KoLeo L = \lambda_1 L_{\text{DINO}} + \lambda_2 L_{\text{iBOT}} + \lambda_3 L_{\text{KoLeo}} L=λ1LDINO+λ2LiBOT+λ3LKoLeo
2.3.1 DINO Loss(全局监督)
完全继承 DINOv1 的师生自蒸馏框架,专注全局 CLS token 对齐。
- 学生网络学习预测教师网络的全局特征分布
- 保证图像级语义一致性,维持分类与检索能力
2.3.2 iBOT Loss(局部 Patch 监督)
这是 DINOv2 具备强大密集预测能力的核心关键。
- 操作:对学生网络输入进行随机 Patch 遮蔽(Masking),类似 MAE。
- 目标:学生网络仅根据未遮挡区域,预测被遮蔽 Patch 的教师网络特征分布。
- 与 MAE 关键区别:MAE 预测像素,iBOT 预测特征分布,模型学习的是高级语义关联,而非低级像素纹理。
2.3.3 KoLeo 正则化
为避免特征空间拥挤、部分区域塌陷,DINOv2 加入 KoLeo(Kozachenko-Leonenko)差分熵正则。
- 作用:强制一个 batch 内的样本特征在空间中均匀铺开。
- 直观效果:特征不扎堆、不塌陷,利用率更高,下游任务泛化性更强。
2.4 工程奇迹:十亿参数大模型训练方案
DINOv2 首次将自监督 ViT 推至 1B+ 参数规模,并实现稳定训练,依赖四大工程优化:
- FlashAttention
降低注意力计算复杂度,显著节省显存、提升训练速度。 - Sequence Packing
将不同长宽比的图像 Patch 打包为固定长度序列,消除无效 Padding,提升计算效率。 - FSDP(Fully Sharded Data Parallel)
对参数、梯度、优化器状态进行切分分布式存储,突破单卡显存上限。 - 高分辨率微调
先在低分辨率(224)高效预训练,末期在高分辨率(518)短暂微调,兼顾成本与精度。
这套工程体系让 DINOv2 真正具备工业级训练、落地、部署的完整能力。
第三章:DINOv3 —— 极致精细,守住密集特征与几何结构底线
参考:Meta AI 2024~2025 DINOv3 系列技术文档
3.1 盛世隐患:大模型扩容带来密集特征退化
DINOv2依靠海量数据与多目标损失,实现了工业级通用视觉特征,但继续扩大模型参数量、拉长训练周期后出现了典型矛盾:ImageNet 的分类精度(Linear Probe)还在涨,但是分割和深度估计的性能(Dense Tasks)却开始下降了。
背后根源在于训练优化导向失衡:模型为了优化全局CLS特征对齐,不断凝练高层类别语义(比如判别图片为汽车、猫狗),逐步弱化Patch之间的空间关联、边缘轮廓、局部几何细节。全局语义越来越好,但像素级、区块级的空间一致性被破坏。
随着训练进行,模型越来越“聪明”,它学会了像人一样去抓“大概念”(比如“这是一辆车”),而忽略了“底层结构”(比如“车的轮廓在哪里”)。模型在追求 Global 语义对齐的过程中,牺牲了 Patch 级别的几何一致性。
而在实际工业落地场景:语义分割、目标追踪ReID、自动驾驶深度感知、缺陷检测全都依赖高质量密集特征,几何结构丢失直接限制模型落地价值,这也是DINOv3重点优化的出发点。
3.2 核心创新:Gram Anchoring,用Gram矩阵锚定空间几何
为约束模型不丢失局部结构,DINOv3新增Gram Anchoring Loss,从特征通道相关性维度锁定图像固有几何与纹理信息。
3.2.1 Gram矩阵基础原理
早在风格迁移任务中,Gram矩阵 G = X X ⊤ G=XX^\top G=XX⊤ 就是表征特征空间关系的核心算子,它统计特征通道两两之间的共现关联,等价于编码图像纹理排布、像素空间相对位置,完整承载原图几何结构信息。
3.2.2 锚定约束实现思路
- 训练中期,密集特征性能抵达最优拐点时,缓存当前Teacher网络作为固定Gram Teacher锚点;
- 后续全周期训练新增正则损失,约束Student的Patch特征Gram矩阵和锚点Gram矩阵保持接近:
L Gram = ∥ G student − G teacher ∥ F 2 L_{\text{Gram}} = \| G_{\text{student}} - G_{\text{teacher}} \|_F^2 LGram=∥Gstudent−Gteacher∥F2
通俗理解:该损失如同给图像空间打下固定地桩。模型依旧可以自由迭代优化全局分类语义、缩小DINO与iBOT主损失,但不能随意改动Patch间的空间排布与几何关联,从数学层面杜绝密集特征退化。
3.3 主干架构升级:适配任意高分辨率输入
除损失函数优化外,DINOv3对ViT主干两处关键改造,针对性解决高分辨率推理、特征噪声伪影两大痛点。
3.3.1 Axial RoPE轴向旋转位置编码
传统绝对位置编码适配固定分辨率,推理时从224切换至800、1024等高分辨率,位置编码需要插值,极易引发性能暴跌。
DINOv3替换为轴向RoPE,搭配位置抖动Jitter增强训练,编码基于相对位置生成,推理支持任意尺寸图片,无需插值微调,天然适配分割任务多变输入分辨率。
3.3.2 Register Tokens寄存器令牌
原生ViT做密集特征提取时,背景杂波、无效高频细节容易污染物体Patch Token,注意力图频繁出现无意义高亮伪影。
DINOv3在输入序列额外插入少量空白Register Token,模型会把零散背景噪声、无关全局冗余信息寄存至寄存器令牌中,有效提纯有效Patch的特征纯度,进一步优化注意力图与分割效果。
3.4 预训练后拓展:开箱即用的全链路落地方案
DINOv3不再只输出单一视觉特征,配套完善后置拓展方案,兼顾开放词汇应用与轻量化部署。
- dino.txt 图文对齐
冻结主干权重,仅微调小型投影头,将DINO视觉特征映射至文本嵌入空间,复刻CLIP跨模态能力,原生支持开放词汇分割、开放集目标检测。 - 多尺度模型蒸馏流水线
官方配套成熟蒸馏方案,可把超大ViT-g教师模型的全局+密集特征能力无损迁移至ViT-S、ConvNeXt等轻量架构,大幅降低算力开销,适配嵌入式、端侧设备部署。
第四章:三代同堂 —— 横向对比与工程选型指南
从 DINOv1 首次实现无监督语义涌现,到 DINOv2 成为工业级通用视觉基座,再到 DINOv3 修复密集特征退化、守住几何结构底线,三代模型并非简单迭代升级,而是分工明确、各有所长。不同版本适配的下游任务、落地场景差异巨大,在工程落地中,按需选型远比盲目使用最新版本更为重要。
为了让开发者快速理清三代模型的区别,下面整理 DINOv1 / DINOv2 / DINOv3 终极对比与落地选型方案。
4.1 三代模型核心能力对比
| 维度 | DINOv1 | DINOv2 | DINOv3 |
|---|---|---|---|
| 发布时间 | 2021 | 2023 | 2024/2025 |
| 核心理念 | 无标签自蒸馏,验证ViT无监督可行性 | 大规模数据构建工业级通用视觉基座,强化密集预测 | 解决大模型长训练后的几何结构退化问题 |
| Loss组合 | Global CE | Global CE + iBOT局部损失 + KoLeo正则 | Global CE + iBOT + KoLeo + Gram结构锚定损失 |
| 训练数据 | ImageNet-1K(128万) | LVD-142M(1.42亿高质量清洗数据) | 超大规模精选Web数据(17亿+) |
| 密集预测能力 | 可自发分割,但不稳定、泛化差 | 能力强劲,适配分割、深度等密集任务 | SOTA级别,彻底锁定几何结构、细节极致稳定 |
| 位置编码 | 传统绝对位置编码 | 绝对位置编码 | Axial RoPE旋转位置编码+抖动增强,支持任意分辨率 |
| 工程特性 | 结构极简,适合学术复现 | FlashAttention、FSDP分布式、高分辨率微调 | FSDP2、fp8训练、极致推理优化 |
| 典型场景 | 学术实验、无监督分割Demo | 图像检索、ReID、通用分类、特征提取 | 高精度分割、深度估计、缺陷检测、多模态对齐 |
4.2 工程师落地选型指南
1、做图像检索、ReID、商品/人脸比对 —— 优先 DINOv2
DINOv2 的全局特征判别力极强,经过亿级干净数据打磨,特征分布均匀、区分度高。
同时 HuggingFace 生态完善、推理速度快、稳定性高,是目前工业界检索、比对、细粒度任务性价比最高的选择。
2、做语义分割、深度估计、工业缺陷检测 —— 优先 DINOv3
这类任务极度依赖 Patch密集特征 + 几何结构信息。
DINOv2 存在致命问题:训练后期全局语义变强,但物体轮廓、边缘、空间结构会退化。
DINOv3 通过 Gram 锚定损失强行锁住图像空间结构,边缘、细节、几何完整性大幅碾压 v2,是所有密集预测任务的最优解。
3、端侧部署、嵌入式设备、轻量化场景 —— 基于 DINOv3 蒸馏
不需要直接使用超大模型。
利用 DINOv3 官方配套的多尺度蒸馏方案,用高精度大模型作为 Teacher,把优质几何与语义特征蒸馏到 ViT-S、ConvNeXt、轻量模型中,兼顾精度与速度。
4.3 三代迭代总结
- DINOv1:从0到1的突破
证明了 ViT 不需要标签也能学语义,让无监督分割“凭空涌现”。 - DINOv2:从实验到工业的落地
靠海量高质量数据 + 全局+局部双监督,成为通用视觉主干。 - DINOv3:从通用到极致的补全
解决大模型通病:只学语义、丢结构,守住了视觉任务最底层的几何底线。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 7
7 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)