基于 SAM2 的通用医学图像分割基础模型研究与实现
🔥 简要概述
摘要
医学图像分割在临床诊断和治疗规划中发挥着核心作用,然而,现有模型在通用性以及对二维和三维数据的统一处理方面仍面临诸多挑战。本文聚焦于Medical SAM 2(MedSAM-2)这一前沿的开源项目,该系统基于Meta发布的Segment Anything Model 2(SAM2)框架,创新性地将所有二维和三维医学分割任务统一建模为视频目标跟踪问题。本文系统阐述了MedSAM-2的技术背景、核心架构、环境配置与详细操作流程,并通过二维和三维医学图像分割的完整实践案例进行了验证。实验结果表明,MedSAM-2在多个公开数据集上均取得了当前最佳的分割性能。本项目源码已全部开源,为医学图像分割领域的研究和应用提供了一个通用的解决方案。
关键词:医学图像分割;Segment Anything Model 2;MedSAM-2;通用分割;视频目标跟踪
一、引言
医学图像分割是一项旨在从医学图像中识别并提取特定解剖结构、病灶或感兴趣区域的计算机辅助分析技术,广泛应用于临床诊断、手术规划、放射治疗和病理研究中。精准的器官分割能够辅助医生进行定量评估,例如计算肿瘤体积、测量骨密度或评估器官形态变化,从而提升临床决策的准确性和效率。然而,现有的分割模型大多针对特定任务或特定成像模态进行设计,在面对跨模态、多器官的通用分割任务时,其泛化能力往往受限。
近年来,通用模型(Generalist Models)的兴起为医学图像分割领域带来了新的范式。Meta的SAM(Segment Anything Model)首次展示了一个可以分割“一切”的统一模型架构,其自然图像分割的成功迅速启发了大量医学分割架构的设计。SAM 2作为SAM的进化版本,不仅继承了强大的图像分割能力,还引入了流式记忆机制,首次实现了对视频对象的实时跟踪分割。
然而,SAM 2的设计初衷是处理自然场景中的图像和视频,将其直接应用于医学领域仍存在两大瓶颈:其一,医学图像具有高度专业化的纹理特征和结构差异,模型的泛化能力需要经过针对性适配才能在医学数据上发挥作用;其二,3D体积医学图像(如CT、MRI)与自然视频虽然形式上都是连续多帧的数据流,但其解剖连续性(双向依赖)与自然视频的单向时间流动存在本质差异。
正是在这一背景下,Medical SAM 2(MedSAM-2)应运而生。该项目由Jiayuan Zhu、Abdullah Hamdi、Yunli Qi、Yueming Jin和Junde Wu共同开发,于2024年8月开源,论文发布于arXiv(2408.00874),并迅速在Hugging Face上被评为“当日#1论文”。截至目前,该项目已获得超过900星标和135次复刻,成为SAM2领域最受欢迎的医学分割开源项目之一。
本文将以MedSAM-2为核心,系统介绍其技术路线、安装配置、数据集准备、训练流程和推理应用,旨在为医学图像分割领域的研究者和开发者提供一个从零开始的完整实践指南。
二、研究背景与相关工作
2.1 SAM2:从图像到视频的进化
Segment Anything Model 2是Meta AI在SAM成功基础上发布的下一代分割基础模型。与仅支持静态图像分割的SAM相比,SAM 2的核心突破在于其引入了流式记忆机制,使其能够高效地处理视频对象分割任务。该模型支持多种提示方式,包括点、框和掩膜,能够以实时处理速度(每秒30帧以上)完成零样本泛化分割。
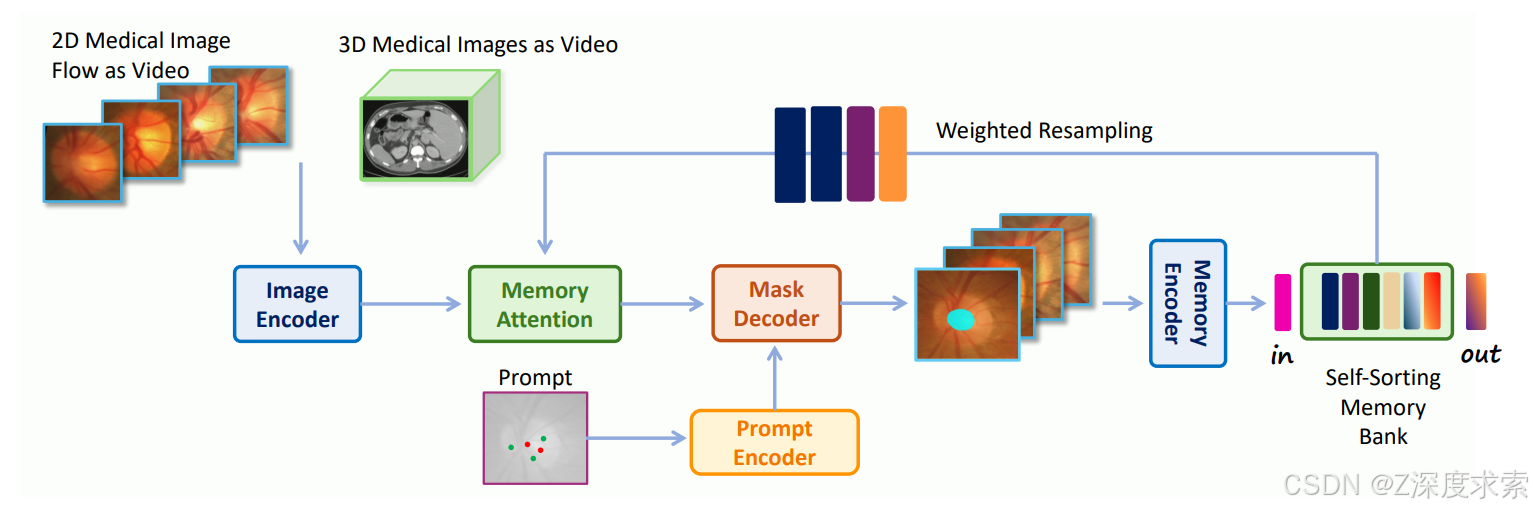
SAM 2的架构包含四个主要组件:图像编码器(Image Encoder)、提示编码器(Prompt Encoder)、记忆注意力模块(Memory Attention Module)和掩膜解码器(Mask Decoder)。其中,记忆注意力模块是SAM 2区别于前代的关键创新,它通过维护一个记忆库来存储历史帧的特征信息,使得模型能够在连续帧之间保持目标跟踪的一致性。
Meta公开了SAM 2的四种模型变体的预训练权重——tiny、small、base-plus和large——分别对应不同的推理速度和精度权衡,为开发者提供了灵活的选择空间。
2.2 医学图像分割的通用模型之路
在U-Net及其变体主导医学分割的十余年间,任务特定的专业模型一直是主流范式。然而,随着SAM的出现,“一个模型分割一切”的理念开始深刻影响医学图像分割领域。目前,主流的SAM医学适配方案已形成多个分支:零样本迁移直接应用、少量样本微调(Few-shot Finetuning)、适配器注入以及专门训练的医学通用模型等。
SAM衍生产品已在医学图像分割中展现出巨大的潜力。研究综述显示,经过有效参数优化的SAM变体在医学分割任务上可达到81–95%的Dice系数,同时将标注需求降低了56–73%。这一数据充分说明了基础模型对医学领域的重要性:它们不仅能够提供高质量的分割结果,更重要的是极大地降低了对昂贵、耗时的人工标注数据的依赖。
2.3 MedSAM-2:技术路线创新
现有方法面临两个核心难题:第一,2D和3D医学数据的统一处理框架缺失;第二,模型的通用性与跨数据集泛化能力不足。MedSAM-2的核心洞察在于:将所有2D和3D医学图像分割任务统一建模为视频目标跟踪问题。这一范式转化的关键优势在于,它借助了SAM 2自身卓越的视频对象跟踪能力,将医学图像序列中同类型的结构视为视频中的同一个跟踪目标,从而实现了一致性的分割预测。
为了实现这一目标,MedSAM-2创新性地提出了一个自排序记忆库机制。该机制基于特征向量的置信度和差异性分数,动态选择最具信息量的嵌入特征存入记忆库,无论这些特征来自帧序列的何种顺序位置。这一设计不仅显著提升了3D医学图像分割的性能,更为重要的是解锁了针对2D医学图像的单提示分割能力——用户仅需提供一个提示(一个点或一个框),模型即可自动将该提示传播到所有待分割的图像中,无需逐张重复标注。
在训练数据方面,MedSAM-2的训练采用了规模庞大的医学数据集,包含超过455,000个3D图像-掩膜对和76,000个视频帧。如此大规模的数据支撑使得MedSAM-2在多种器官、病灶和成像模态上均取得了优异的表现。更值得一提的是,该团队在5,000个CT病灶、3,984个肝脏MRI病灶和251,550个超声心动图视频帧上进行了人工参与的大规模用户研究,结果显示MedSAM-2可将人工标注成本降低85%以上。
三、项目核心架构与技术栈
3.1 整体架构
MedSAM-2的整体架构以SAM 2为骨架,围绕视频目标跟踪范式进行了三大方向的定制化设计:
-
自排序记忆库:这是MedSAM-2区别于原生SAM2的核心创新。原生SAM 2的记忆库基于时序顺序存储帧特征,而在3D医学图像中,CT/MRI切片的解剖学关系是双向的——第i帧与第i-1帧和第i+1帧在解剖结构上是连续变化的。MedSAM-2的自排序机制允许模型不受时间顺序限制地选取置信度最高、差异性最大的特征存入记忆库,从而更有效地学习3D体积内的解剖结构信息。
-
统一2D/3D处理框架:通过将2D图像视为单帧视频,MedSAM-2巧妙地实现了2D和3D分割任务的统一。在2D多图像场景中(如多个病人的眼底图像),模型利用单提示完成全部分割;在3D体积场景中,模型利用连续帧的解剖连续性进行一致性分割。
-
可提示交互界面:支持点、框和掩膜三种交互方式,用户可以在3D医学图像上灵活地进行交互式分割,这在实际临床应用中尤为重要——医生可以通过点击病灶区域实现快速的半自动标注。
3.2 技术栈说明
MedSAM-2的技术栈主要由以下组件构成:
| 组件类别 | 具体技术 | 版本/说明 |
|---|---|---|
| 深度学习框架 | PyTorch | ≥2.3.1,支持torch.compile优化 |
| 基础分割模型 | SAM 2 | Meta的Segment Anything Model 2官方实现 |
| 预训练权重 | SAM 2.1系列 | hiera_small / hiera_base_plus / hiera_large |
| 编程语言 | Python 3.12.4 | 项目推荐版本 |
| 系统环境 | Ubuntu 22.04 | 经过完整测试的操作系统 |
| 包管理器 | Conda 23.7.4 | 环境隔离与管理 |
| 数据加载 | PyTorch DataLoader | 自定义数据加载器,支持2D和3D医学数据 |
| CUDA支持 | CUDA 12.1+ | GPU加速训练和推理 |
3.3 仓库结构解析
MedSAM-2的GitHub仓库呈现清晰的模块化结构:
text
Medical-SAM2/ ├── checkpoints/ # SAM2预训练权重存放目录 ├── conf/ # 配置文件目录 ├── func_2d/ # 2D分割核心函数模块 ├── func_3d/ # 3D分割核心函数模块 ├── sam2_train/ # SAM2训练封装模块 ├── vis/ # 可视化辅助代码 ├── static/ # 静态文件(如项目网页) ├── cfg.py # 全局配置 ├── train_2d.py # 2D训练入口脚本 ├── train_3d.py # 3D训练入口脚本 ├── environment.yml # Conda环境配置 └── README.md # 项目说明文档
这一结构的设计兼顾了清晰性和扩展性:核心训练函数与辅助可视化分离,2D和3D流程独立封装,便于开发者快速定位并复用所需模块。项目主要由Python实现(占比约72.7%),辅以少量JavaScript和HTML用于项目网页展示,以及CUDA代码用于高性能运算。
四、环境配置与安装指南
4.1 硬件要求
MedSAM-2的训练和推理对计算资源有一定要求,具体推荐配置如下:
| 硬件组件 | 最低要求 | 推荐配置 |
|---|---|---|
| GPU | 8 GB显存 | 16 GB以上(如NVIDIA RTX 3080/4080/A6000) |
| CPU | 4核 | 8核以上 |
| RAM | 16 GB | 32 GB以上 |
| 存储空间 | 50 GB | 100 GB以上(含数据集和模型权重) |
4.2 环境安装步骤
第一步:克隆仓库
bash
git clone https://github.com/ImprintLab/Medical-SAM2.git cd Medical-SAM2
第二步:创建Conda环境
MedSAM-2提供了完整的environment.yml配置文件,可以通过以下命令一键创建运行环境:
bash
conda env create -f environment.yml conda activate medsam2
环境创建完成后,建议验证PyTorch是否正确安装并能够调用GPU:
python
import torch print(torch.__version__) print(torch.cuda.is_available())
若输出True,则说明GPU环境配置正确。
第三步:下载SAM 2预训练权重
MedSAM-2需要SAM 2官方的预训练权重作为初始化。项目提供了自动化下载脚本:
bash
bash download_ckpts.sh
该脚本会从Hugging Face下载SAM 2的多个模型变体权重文件。以sam2_hiera_small.pt为例,这是一个平衡推理速度和分割精度的小型模型权重,文件大小约为1GB。如需更高精度,可在后续训练命令中将-sam_ckpt参数指向sam2_hiera_large.pt。
同时,MedSAM-2团队也在Hugging Face上提供了经过医学数据预训练后的权重,可直接用于推理而无需重新训练:
bash
# 从Hugging Face下载预训练权重 pip install huggingface_hub huggingface-cli download jiayuanz3/MedSAM2_pretrain --local-dir ./medsam2_pretrain
第四步:验证安装
完成上述步骤后,可以快速验证环境是否正确配置。在Python交互环境中运行以下代码,检查是否能成功导入MedSAM-2的核心模块:
bash
python -c "import torch; import sam2; print('SAM2 imported successfully')"
若输出无报错信息,则说明环境配置已完成,可以进入下一步的数据准备阶段。
五、数据集准备与预处理
5.1 2D数据集:REFUGE眼底图像分割
REFUGE(Retinal Fundus Glaucoma Challenge)数据集是一个公开的眼底图像分割基准集,用于视盘和视杯的分割任务。在青光眼的临床诊断中,视杯与视盘的直径比(CDR)是一个核心评估指标,因此对该区域的精准分割具有重要的临床意义。
MedSAM-2项目提供了经过预处理的REFUGE数据集,可以直接通过以下命令从Hugging Face下载:
bash
# 下载预处理后的REFUGE数据集 wget https://huggingface.co/datasets/jiayuanz3/REFUGE/resolve/main/REFUGE.zip unzip REFUGE.zip # 将解压后的数据移动到data目录 mkdir -p ./data mv REFUGE ./data/
下载完成后,数据目录结构应当类似于:
text
data/REFUGE/ ├── images/ # 眼底图像(如.jpg或.png格式) ├── masks/ # 对应的分割掩膜 └── ... # 其他标注文件
数据集包含训练集、验证集和测试集三部分,每张图像均已与对应的分割掩膜对齐。这一预处理格式使得开发者可以直接运行训练脚本,无需额外的数据格式转换工作。
5.2 3D数据集:BTCV腹部分割
BTCV(Beyond the Cranial Vault)腹部多器官分割数据集是3D医学图像分割领域的经典基准之一。该数据集包含多例腹部CT扫描,每个体积具有多个器官的标注掩膜,是评估3D分割模型性能的理想选择。
MedSAM-2同样提供了预处理后的BTCV数据集下载:
bash
# 下载预处理后的BTCV数据集 wget https://huggingface.co/datasets/jiayuanz3/btcv/resolve/main/btcv.zip unzip btcv.zip # 将解压后的数据移动到data目录 mkdir -p ./data mv btcv ./data/
值得说明的是,MedSAM-2对BTCV数据集的处理方式是将每一例3D CT体积视为一段视频——每一个轴向切片是一帧,连续切片构成整个视频序列。这种处理方式完美契合了项目的核心思想:将3D医学图像的分割任务转化为视频目标跟踪任务。
5.3 自定义数据集准备
对于希望将MedSAM-2应用于自有数据的用户,数据集需遵循一定的格式规范。MedSAM-2的数据加载逻辑期望以下目录结构:
text
data/YOUR_DATASET/ ├── images/ │ ├── case_001/ │ │ ├── slice_001.png │ │ ├── slice_002.png │ │ └── ... │ ├── case_002/ │ │ └── ... │ └── ... ├── masks/ │ ├── case_001/ │ │ ├── slice_001.png │ │ └── ... │ └── ... └── dataset_info.json # 可选的元数据文件
数据预处理的关键要点包括:
-
图像归一化:医学图像(如CT)的像素值通常是Hounsfield单位,范围较大(-1000至+1000),建议归一化到[0,1]或[-1,1]区间。
-
尺寸统一:建议将所有图像统一缩放到固定的尺寸(如1024×1024),这是SAM 2图像编码器的默认输入尺寸。
-
掩膜格式:分割掩膜应为单通道图像,每个像素的整数值代表该位置所属的类别ID(0表示背景)。
-
提示准备:训练过程中,模型需要提示信息。对于2D任务,系统会自动从训练掩膜中提取边界框作为提示;对于3D任务,可以通过
-prompt和-prompt_freq参数控制提示的生成方式和频率。
六、模型训练与实验
6.1 2D医学分割训练
以REFUGE眼底图像的视杯分割为例,2D训练的命令如下:
bash
python train_2d.py -net sam2 \ -exp_name REFUGE_MedSAM2 \ -vis 1 \ -sam_ckpt ./checkpoints/sam2_hiera_small.pt \ -sam_config sam2_hiera_s \ -image_size 1024 \ -out_size 1024 \ -b 4 \ -val_freq 1 \ -dataset REFUGE \ -data_path ./data/REFUGE
各参数的含义与作用:
-
-net sam2:指定使用SAM 2作为基础模型架构。 -
-exp_name REFUGE_MedSAM2:实验名称,系统将自动创建以该名称命名的目录用于保存日志、检查点和可视化结果。 -
-vis 1:开启可视化功能,系统会在训练过程中生成分割结果的可视化图像,便于观察模型的收敛情况。 -
-sam_ckpt:SAM 2预训练权重的路径。此处使用sam2_hiera_small.pt,约为1GB的平衡型权重。 -
-sam_config sam2_hiera_s:配置SAM 2的模型配置文件,对应于sam2_hiera_s这一变体(hierarchical transformer架构,small规模)。 -
-image_size 1024:输入图像的尺寸。SAM 2的图像编码器通常接受1024×1024的输入,该尺寸在精度和计算量之间取得了较好的平衡。 -
-out_size 1024:输出分割掩膜的尺寸。通常与输入尺寸一致,确保输出的分割结果与原图分辨率匹配。 -
-b 4:批处理大小(batch size)。在当前GPU显存条件下,4是一个较为稳妥的选择。若GPU显存充裕(如24GB以上),可以适当增加批大小以加速训练。 -
-val_freq 1:每隔多少个epoch进行一次验证。值为1表示每个epoch结束后均在验证集上评估模型性能。 -
-dataset REFUGE:数据集名称,系统会基于此名称在data_path下寻找对应的子文件夹。 -
-data_path ./data/REFUGE:数据集的根目录路径。
训练流程概述:
-
数据加载:系统根据
-dataset和-data_path参数定位并加载数据集。 -
提示生成:从训练掩膜中自动提取边界框,作为SAM 2的提示输入。
-
前向传播:图像与边界框提示同时输入到SAM 2网络中,生成预测分割掩膜。
-
损失计算:将预测掩膜与真实掩膜进行逐像素比较,计算Dice损失和二元交叉熵损失。
-
反向传播:计算梯度并更新模型参数。
-
验证:每个epoch结束后,在验证集上评估模型的Dice系数和IoU指标。
-
检查点保存:保存每个epoch的模型权重,用户可在早期停止训练时恢复已训练好的权重。
预期效果:在REFUGE数据集上,经过充分微调后的MedSAM-2能够在视杯分割上达到与当前最优方法相当甚至更好的Dice系数。
6.2 3D医学分割训练
以BTCV腹部多器官分割为例,3D训练的命令如下:
bash
python train_3d.py -net sam2 \ -exp_name BTCV_MedSAM2 \ -sam_ckpt ./checkpoints/sam2_hiera_small.pt \ -sam_config sam2_hiera_s \ -image_size 1024 \ -val_freq 1 \ -prompt bbox \ -prompt_freq 2 \ -dataset btcv \ -data_path ./data/btcv
3D训练与2D训练的关键差异:
-
3D数据的视频化处理:MedSAM-2将每一例3D CT体积视为一段视频——每一张轴向切片为一帧,连续切片构成整个视频序列。在训练时,系统会跨越切片地选取帧进行训练和记忆库构建,从而让模型学习到体积内的解剖结构依赖关系。
-
-prompt bbox:指定在3D训练中使用边界框作为提示信号。边界框从帧对应的分割掩膜中自动提取,模型在给定的边界框区域内搜索目标边界。 -
-prompt_freq 2:每隔2帧生成一个提示。这一设计的考量在于:在前一帧已经提供了提示并得到了分割结果后,SAM 2的记忆注意力模块能够利用记忆库中的信息对后续帧进行自动追踪和分割。因此,无需在每一帧都提供人工提示,仅需在部分帧上提供提示,模型就能自主完成其余帧的分割。
这一设计极大地降低了3D医学图像分割的交互成本。以100帧的CT体积为例,若每一帧都需要人工标注,即便是点提示也需要100次点击;而通过提示频率设置为2,只需标注约50帧即可,节省了约50%的交互成本。更进一步,记忆库机制的有效性甚至可以允许更低的提示频率——在3D医学图像中,只要连续帧之间的解剖结构是平滑渐变的,模型往往只需在首帧提供一个提示,就能追踪分割整个体积。
6.3 超参数调优建议
除了上述命令中明确的参数外,还有一些超参数可以进行调整以优化训练效果:
-
学习率(代码中的
-lr参数,默认为1e-4):若训练过程中损失下降缓慢,可尝试增加学习率至5e-4;若损失振荡明显或不收敛,可降低学习率至5e-5。 -
批处理大小(
-b参数):受限于GPU显存,小型GPU可尝试批大小为2或1;大型GPU可尝试增加批大小以加速训练。 -
训练轮数(
-epoch参数,默认可设50-200):较小的数据集不需要太多轮数,50轮即可收敛;较大的数据集可适当增加。 -
自排序记忆库大小(代码中的记忆库容量参数):可根据3D体积的深度适当调整。对于切片数较多的体积(如200+层),更大的记忆库有助于模型捕获更远的空间依赖关系。
七、模型推理与应用
7.1 加载训练好的模型
训练完成后,可以通过以下步骤加载MedSAM-2模型进行推理:
python
import torch from sam2.build_sam import build_sam2 from sam2.sam2_image_predictor import SAM2ImagePredictor # 加载训练好的模型权重(微调后的MedSAM-2) checkpoint_path = "./checkpoints/BTCV_MedSAM2/best_model.pt" model_cfg = "sam2_hiera_s.yaml" # 构建模型 sam2_model = build_sam2(model_cfg, checkpoint_path, device="cuda") predictor = SAM2ImagePredictor(sam2_model)
7.2 单张图像推理示例
以下代码展示了如何使用训练的模型对单张医学图像进行分割:
python
import cv2
import numpy as np
# 读取医学图像(如CT切片或眼底图像)
image = cv2.imread("path/to/medical_image.png")
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# 设定提示(例如,边界框)
input_box = np.array([x_min, y_min, x_max, y_max])
# 设置图像
predictor.set_image(image)
# 执行预测
masks, scores, logits = predictor.predict(
box=input_box,
multimask_output=False
)
# masks 为分割掩膜,scores 为每个掩膜的置信度分数
7.3 3D体积推理
对于3D医学CT/MRI体积的推理,MedSAM-2将其作为视频流处理,利用记忆库实现连续帧的跟踪分割:
python
from sam2.sam2_video_predictor import SAM2VideoPredictor
# 初始化视频预测器
video_predictor = SAM2VideoPredictor(sam2_model)
# 将3D体积作为视频帧序列加载(假设帧图像按顺序命名)
video_dir = "path/to/ct_volume_slices/"
# 执行分割
with torch.inference_mode():
video_segments = video_predictor.predict(
video_dir,
box_inputs={0: input_box}, # 仅在第一帧提供提示
)
# video_segments 中包含每一帧的分割结果
这里的关键在于,提示只需在第一帧提供一次,模型利用记忆库中的特征信息即可自动将目标跟踪到后续所有帧中,实现了高效、低交互的3D体积分割。
7.4 可视化与结果展示
MedSAM-2提供了vis目录下的可视化辅助代码,可生成分割结果的可视化对比图:
python
import matplotlib.pyplot as plt
def visualize_segmentation(image, mask, alpha=0.5):
"""可视化分割掩膜覆盖在原图上的效果"""
overlay = image.copy()
# 将掩膜叠加到原图上(使用半透明叠加)
overlay[mask > 0] = overlay[mask > 0] * (1 - alpha) + np.array([0, 255, 0]) * alpha
plt.subplot(1, 2, 1)
plt.imshow(image)
plt.title("Original Image")
plt.subplot(1, 2, 2)
plt.imshow(overlay)
plt.title("Segmentation Overlay")
plt.show()
对于3D分割结果的可视化,可以沿Z轴方向展示多个层级的切片分割结果,形成类似于“连续切片叠层”的可视化效果。这一可视化方式能够直观地展示模型在整个3D体积上的分割一致性。
八、性能评估与前沿探讨
8.1 实验评估结果
MedSAM-2在多个公开数据集上进行了全面的性能评估。论文中的实验覆盖了5个2D任务和9个3D任务,包括白细胞、视杯、视网膜血管、下颌骨、冠状动脉、肾脏肿瘤、肝脏肿瘤、乳腺癌、鼻咽癌等多种医学对象的精确分割。
2D任务:在眼底图像分割中,MedSAM-2相比于其他SAM变体在视盘和视杯分割上表现出了更优的Dice系数。
3D任务:在腹部多器官、心脏、脑结构等分割任务上,MedSAM-2超越了多个现有的最优模型。尤其是在存在低对比度、模糊边界或小目标器官的分割任务中,自排序记忆库机制带来的收益最为显著。
🩻 三维腹部分割可视化
消融研究:论文中对自排序记忆库机制进行了系统性的消融实验。结果显示,引入该机制后,模型在多个3D分割任务上的Dice系数提升了约3-5个百分点,尤其是在结构复杂的器官(如胰腺)分割中提升尤为显著。
用户研究:MedSAM-2团队进行了大规模的人工参与实验,涉及5,000个CT病灶、3,984个肝脏MRI病灶和251,550个超声心动图视频帧的标注,结果表明MedSAM-2可将人工标注成本降低85%以上。
8.2 与相关工作的对比
下表从多个维度对比了MedSAM-2与其他代表性医学分割模型:
| 模型 | 支持2D | 支持3D | 支持视频 | 提示方式 | 开源 | 标注成本降低 |
|---|---|---|---|---|---|---|
| U-Net | ✅ | ⚠️(需3D扩展) | ❌ | 无 | ✅ | 无 |
| nnU-Net | ✅ | ✅ | ❌ | 无 | ✅ | 无 |
| SAM | ✅ | ❌ | ❌ | 点/框/掩膜 | ✅ | 约50% |
| SAM 2 | ✅ | ❌ | ✅ | 点/框/掩膜 | ✅ | 约60% |
| MedSAM | ✅ | ❌ | ❌ | 点/框/掩膜 | ✅ | 约70% |
| MedSAM-2 | ✅ | ✅ | ✅ | 点/框/掩膜 | ✅ | >85% |
值得特别说明的是MedSAM与MedSAM-2的区别:MedSAM是在SAM基础上专门针对医学图像进行微调的版本,但其处理3D医学图像时只能逐2D切片处理,忽略了切片间的解剖连续性;而MedSAM-2基于SAM 2的视频跟踪能力,天然地将3D体积视为视频序列来处理,实现了在3D体积上的统一分割。
8.3 当前局限性与改进方向
尽管MedSAM-2展现了卓越的性能,但仍存在一些值得进一步探索的方向:
-
语义类别标注缺失:MedSAM-2目前输出的掩膜是二值化的目标掩膜,不包含语义类别信息。在实际临床场景中,医生通常需要知道分割出的区域具体是哪个器官或病灶,而非仅仅知道“有目标存在”。
-
提示依赖:MedSAM-2仍然需要至少一个初始提示(一个点或一个边界框)来启动分割。这意味着模型还无法实现完全的自动化——用户必须参与到分割流程中提供交互。
-
3D连续性建模的优化:虽然自排序记忆库机制有效捕捉了3D体积内的解剖结构,但一些研究指出,医学3D体积的双向解剖连续性与自然视频的单向时间流动之间存在固有差异,完全的端到端3D适应仍有优化空间。
针对这些局限,近期的研究提供了多个有价值的改进思路:
-
文本提示引导:MICCAI 2025接收的TGSAM-2工作在SAM-2中引入了文本引导机制,利用文本描述作为分上下文提示来指导医学图像分割,为无提示的全自动分割提供了新思路。
-
边界感知增强:SAM2-3dMed引入了切片相对位置预测模块和边界检测模块,分别建模了双向切片间依赖关系和增强了边界分割的精度。
-
轻量化微调:有研究工作探索了在Google Colab平台上对SAM2进行轻量级微调,无需专业GPU即可完成对特定医学领域(如显微镜图像)的适配。
-
自提示驱动:一些前沿研究试图设计自提示机制,使SAM2能够从原始医学图像数据中自动生成最可靠的提示模板,从而完全摆脱对外部人工提示的依赖。
可以预见,这些工作与MedSAM-2的理念相结合,将催生出新一代更智能、更实用的医学分割基础模型。通用分割模型在满足监管框架、隐私安全、可信AI等要求后,有望在临床环境中实现真正的落地应用。
九、总结与展望
9.1 主要贡献总结
本文系统介绍了MedSAM-2这一基于SAM 2框架的通用医学分割系统,其核心贡献可以归纳为以下三点:
-
范式创新:开创性地将所有2D和3D医学分割任务统一建模为视频目标跟踪问题,利用SAM 2天然的视频对象跟踪能力实现了医学图像分割的统一框架。
-
自排序记忆库机制:设计了不受时间顺序限制的记忆库更新策略,动态选择最具信息量的特征嵌入,显著提升了3D医学图像分割的性能。
-
单提示分割能力:在2D医学图像上实现了跨图像的单提示分割能力,用户仅需在一个实例上提供一次提示,模型即可自动分割同类所有图像。
从实践层面来看,MedSAM-2提供了完整的环境配置、数据准备和训练流程,从2D眼底图像分割到3D腹部多器官分割均有开箱即用的示例。项目源码、预训练权重均已开源,极大地降低了医学图像分割领域的科研门槛。
9.2 未来研究方向展望
尽管MedSAM-2已取得显著成果,计算机视觉和医学图像分析领域仍在快速发展,以下几个方向尤为值得关注:
-
多模态大模型的深度融合:如何更好地融合CT/MRI的影像信息与患者的临床文本记录,构建真正的多模态医学诊断助手,是一个极具价值的前沿方向。CLIP等视觉-语言模型的成功为这一方向提供了技术基础。
-
自我进化能力:在获取新的医学数据后,如何让模型通过持续学习不断进化,而非完全重新训练,是降低部署成本的关键课题。
-
临床落地合规性:在满足监管框架、隐私安全、可解释性AI等要求后,通用分割模型有望在临床环境中真正落地,辅助医生提高诊断效率和准确性。
-
从分割到诊疗一体化:分割只是医学图像分析的第一步,如何将精准分割的结果无缝接入下游的疾病诊断、风险评估和手术导航系统,实现从“看得准”到“治得好”的能力跃迁,是下一个阶段的突破重点。
Medical SAM 2的发布标志着通用医学分割模型迈入了一个新的时代。对于致力于医学图像分析的研究者和开发者而言,这个开源项目不仅提供了现成的分割工具,更提供了一种统一化的方法论范本。如果你希望参与这一前沿领域的建设,不妨从克隆MedSAM-2的代码仓库开始,用自己的数据微调一个专属于特定应用场景的医学分割模型——而这,正是“Segment Anything”愿景在医学领域最激动人心的落地实践。
模型下载:
https://huggingface.co/jiayuanz3/MedSAM2_pretrain/tree/main
https://huggingface.co/datasets/jiayuanz3/REFUGE/tree/main
数据集:www.synapse.org![]() https://www.synapse.org/#!Synapse:syn3193805/wiki/217752
https://www.synapse.org/#!Synapse:syn3193805/wiki/217752
项目代码实现:
Medical-SAM2/
├── train_2d.py # 2D训练入口脚本
├── train_3d.py # 3D训练入口脚本
├── cfg.py # 全局配置参数解析
├── environment.yml # Conda虚拟环境配置
├── download_ckpts.sh # SAM2预训练权重下载脚本
├── checkpoints/ # 存放SAM2预训练权重
├── conf/ # 模型配置文件目录
├── func_2d/ # 2D分割核心函数模块
│ ├── train_2d.py # 2D训练核心逻辑 ⭐
│ ├── dataset.py # 2D数据集加载器
│ ├── function.py # 2D训练/验证核心函数 ⭐
│ └── utils.py # 2D工具函数
├── func_3d/ # 3D分割核心函数模块
│ ├── train_3d.py # 3D训练核心逻辑 ⭐
│ ├── dataset.py # 3D数据集加载器(视频格式)
│ ├── function.py # 3D训练/验证核心函数 ⭐
│ └── utils.py # 3D工具函数
├── sam2_train/ # SAM2训练封装模块
│ ├── sam2/ # SAM2官方库封装
│ └── ... # 模型构建和训练辅助函数
└── vis/ # 可视化辅助代码
参考文献
[1] Zhu J, Hamdi A, Qi Y, Jin Y, Wu J. Medical SAM 2: Segment medical images as video via Segment Anything Model 2. arXiv preprint arXiv:2408.00874, 2024.
[2] Ravi N, Gabeur V, Hu YT, et al. SAM 2: Segment Anything in Images and Videos. arXiv preprint, 2024.
[3] Moglia A, Leccardi M, Cavicchioli M, et al. Generalist models in medical image segmentation: A survey and performance comparison with task-specific approaches. Information Fusion, 2025.
[4] Koishiyeva D, Mukhammejanova D, Kang JW, Mukasheva A. A Review of Deep Learning Approaches Based on Segment Anything Model for Medical Image Segmentation. Bioengineering, 2025, 12.
[5] Noh S, et al. A narrative review of foundation models for medical image segmentation: zero-shot performance evaluation on diverse modalities. Quantitative Imaging in Medicine and Surgery, 2025, 15(6): 5825-5858.
[6] RadSam2 Team. Improving medical image segmentation with SAM2: analyzing the impact of object characteristics and finetuning on multi-planar datasets. ScienceDirect, 2025.
[7] Yang Y, et al. SAM2-3dMed: Empowering SAM2 for 3D Medical Image Segmentation. arXiv preprint arXiv:2510.08967, 2025.
[8] Yuan R, Zhou L, Xu J, et al. TGSAM-2: Text-Guided Medical Image Segmentation using Segment Anything Model 2. MICCAI 2025.
[9] Wong KK, et al. A fine-tuned foundational model SurgiSAM2 for surgical video anatomy segmentation and detection. PubMed, 2025.
[10] Lightweight open-source fine-tuning of SAM2 enables domain-specific microscopy segmentation. bioRxiv, 2025.

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)